面向非協作多功能雷達的波形單元提取方法
2021-11-11 05:59:14朱衛綱呂守業
系統工程與電子技術 2021年10期
陽 榴, 朱衛綱, 呂守業, 馬 爽
(1. 航天工程大學電子與光學工程系, 北京 101416; 2. 北京遙感信息研究所, 北京 100192)
0 引 言
隨著相控陣技術的發展,多功能雷達(multi-function radar,MFR)廣泛部署于各軍事系統中,戰場電磁環境日益復雜。MFR的行為分析與辨識[1-2]成為電子偵察領域近年來的研究熱點。其中,波形單元作為MFR信號的基本構成,其提取效果直接影響到后續MFR“雷達字”集構建、工作模式識別、威脅等級判定等環節的準確性,具有重要的研究意義。
當前MFR波形單元提取的方法主要有以下兩類。一類是有監督學習框架下的匹配分類技術,Visnevski等[3]在波形庫已知的條件下,對MFR不同“雷達字”分別建立隱馬爾可夫鏈模板,通過計算與模板的匹配程度提取波形單元。劉海軍[4]利用三級匹配的方法進一步提高了匹配精度。文獻[5]將降噪編碼器與分類算法結合獲取了較好的魯棒性。文獻[6]利用已知標簽的訓練數據對循環神經網絡(recurrent neural network, RNN)模型調參,再通過RNN分類提取波形單元。另一類方法是在缺乏先驗信息的條件下,利用不同波形單元間脈沖列的參數變化進行提取。文獻[7]通過檢測單一脈幅序列的多個統計變化點,實現了波形庫未知的MFR波形單元提取。文獻[8]用定長的滑窗遍歷MFR脈沖描述字序列,尋找滑窗數據的變化來劃分脈沖列,但算法中如何選取滑窗長度及步長缺乏相應的參考依據。除此之外,文獻[2]通過數值點上的聚類提取MFR波形單元,但難以應用于采用隨機調制的雷達。文獻[9]結合脈沖到達時間和脈寬,提出一種事件驅動的波形單元提取方法,對虛假脈沖和漏脈沖有較好的適應性。
上述研究取得了一定的成果,但在實際應用中探測目標多為非協作MFR,事先難以獲取雷達的波形單元集合。因此,在缺乏匹配標準或標簽數據的條件下,基于有監督學習的匹配分類算法將難以適用。另一方面,尋找序列變化點的方法需要多次重復遍歷、統計、判決的步驟,計算復雜度隨著脈沖個數的增加迅速上升。同時,變化點檢測依據的是序列的局部變化規律,沒有充分利用整個序列的數據分布特點,加上目前較多算法只對單一參數序列進行統計判決,因此在具有測量誤差和脈沖丟失的實際應用場景中提取效果往往不太理想。
針對以上問題,首先構建了一種基于MFR多參數序列的二分類模型,將多個變化點檢測問題轉化成了一個二分類問題。在此基礎上針對實際應用中非協作MFR缺乏先驗知識的問題,提出了一種參數自適應的密度聚類算法(density adaptive density-based spatial clustering of applications with noise,DA-DBSCAN)進行分類,能夠有效地提取非協作MFR的波形單元。
1 MFR波形單元提取模型構建
多功能雷達信號具有功能(function,F)、任務(progress,P)、波形(waveform,W)的層級結構模型[7],如圖1所示。

圖1 MFR信號的層級模型Fig.1 Hierarchical model of MFR signal
MFR通過執行一系列雷達任務P來實現搜索、目標跟蹤、制導等功能F。執行任務時,MFR從波形庫[10]中選擇合適的波形W在指定方向上發射出去,從而在波束駐留時間內對目標完成相應的動作。MFR波形單元提取則是指從偵收的脈沖列中獲取上述波形單元的過程。
由于任務需求和波位指向的差異,不同的波形單元在射頻(radio frequency,RF)、脈寬(pulse width,PW)、脈沖重復間隔(pulse repetition interval,PRI)、脈幅(pulse amplitude,PA)等參數上將發生變化[11]。以往的研究大多采用脈幅作為劃分雷達波形單元的依據[7]。但實際探測過程中伴隨著雜波、干擾和噪聲,在功率維度具有較強干擾性,脈幅出現較大畸變,單一的脈幅數據難以準確地反映波形單元的變化情況。
通過分析某探測系統實際獲取的MFR信號,發現對于采用隨機調制的新體制雷達,同一波形單元內其RF和PRI也存在一定程度的隨機波動,具有更高的抗干擾性能。但由于各波形單元在特定波位指向上完成不同的任務,波形單元轉換時其參數波動更為劇烈。因此,形成了整體震蕩劇烈、局部呈“簇”狀的時序特點。如圖2所示,根據某探測系統對某二維相控陣雷達的實際獲取數據特點,仿真得到其脈沖列時序圖。其中,PRI、RF、PW時序圖整體震蕩劇烈。對范圍在500~750 μs 的PRI時序圖放大,可以明顯看到局部呈“簇”狀的時序特點,如圖2(b)所示。由于波形單元內部的隨機調制,RF在遍歷整個參數范圍上取值,難以通過數值點上的聚類達到提取波形單元的目的,如圖2(c)所示。基于以上分析,本文將利用PRI、RF、PW以及參數間的聯合變化規律作為衡量波形單元轉換的依據,采用數據驅動的思路,從數據集本身的特點出發構建波形單元提取的二分類模型。


圖2 某二維相控陣雷達脈沖列的時序圖Fig.2 Pulse sequencediagram of a two dimensional phased array radar
假設某多功能雷達偵收脈沖列P={p1,p2,…,pn}由三元時間序列{PRI,RF,PW}構成,包含n個脈沖和m個波形單元。其中:
{
PRI={x1,x2,…,xn}
RF={y1,y2,…,yn}
PW={z1,z2,…,zn}
(1)
令label={l1,l2,…,ln},l1=1,
(2)
其中,i=2,3,…,n。
若脈沖pi對應的li=1,則該脈沖為某波形單元的起始脈沖;若脈沖pi對應的li=0,則該脈沖為位于某波形單元內部的非起始脈沖。于是,將從脈沖列中尋找m個統計變化點的問題轉化成一個二分類問題。
基于不同波形單元轉換時參數波動大,整體震蕩劇烈,波形單元內部參數波動較小,局部呈“簇”狀的數據特點,利用相鄰脈沖間參數的差值{ΔPRI,ΔRF,ΔPW}來衡量脈沖列時序變化的波動程度。其中:
(3)


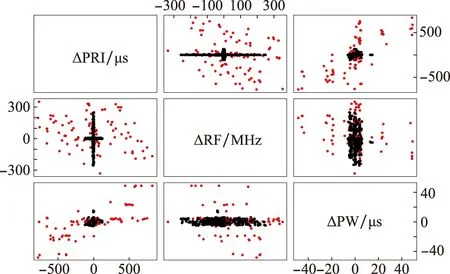
圖3 某二維相控陣雷達聯合分布情況Fig.3 Distribution map of a two dimensional phased array radar
圖3中,紅點是label值為1的波形單元的起始脈沖,黑點是label值為0的波形單元內部脈沖。由于波形單元轉換時參數波動劇烈,ΔPRI、ΔRF、ΔPW數值較大,因而紅點分布分散、密度小;波形單元內參數波動較小,黑點分布集中、密度大。同時可以看到,圖3中黑點聚集內部和邊界也都分布著些許紅點,這是因為波形單元轉換時部分起始脈沖的某個或某兩個參數變化較小,從而在二維的分布圖中難以與黑點分離,因此二分類時需要同時考慮ΔPRI、ΔRF、ΔPW,利用參數間的聯合變化規律獲取更高的準確率。
2 參數自適應的DA-DBSCAN聚類算法
針對非協作MFR缺乏匹配標準和標簽數據的問題,采用密度聚類的無監督學習算法,將非起始脈沖構成的大密度“簇”從起始脈沖構成的噪聲背景中分離出來,實現二分類,從而提取MFR波形單元。
2.1 自適應確定參數Density
根據鄰域半徑Eps和鄰域點數MinPts的輸入參數,DBSCAN聚類算法[12]將高密度數據集合從低密度區域中劃分出來。傳統的DBSCAN聚類算法需要人為設置兩個輸入參數,文獻[13]采用密度閾值Density綜合考量Eps和MinPts,定義Density為以Eps為半徑的圓存在MinPts個數據點,即
(4)
Density太大可能導致同簇集合內部被劃分為多個簇,太小則會帶來不同簇合并的問題,因此選取適應于待聚類數據集的參數尤為重要。
在此基礎上,本文提出了DA-DBSCAN聚類算法自適應確定密度閾值Density。由式(4)可知,Density由MinPts和Eps共同確定。對任意固定的MinPts值,可以通過尋找最優的Eps值獲取合適的密度閾值Density。其中,MinPts一般不小于待聚類數據點的維度,綜合考慮計算復雜度,現固定MinPts=3尋找最優的Eps,從而獲取適應于待聚類數據集密度閾值Density。

(5)
3-dist值是指對象q∈D與數據集中到q第3近的對象p之間的距離值。3-dist排序圖是所有對象的3-dist值升序排列構成的有序圖[12]。數據集D的3-dist排序圖如圖4(a)所示,“簇”中數據點密度大3-dist值小,而噪聲點密度小3-dist值大,曲線由平緩到突增存在著明顯突變,因此突變區域中存在著某個閾值點將數據集的對象分為密度差異較大的兩部份,該閾值便是最優的Eps值。
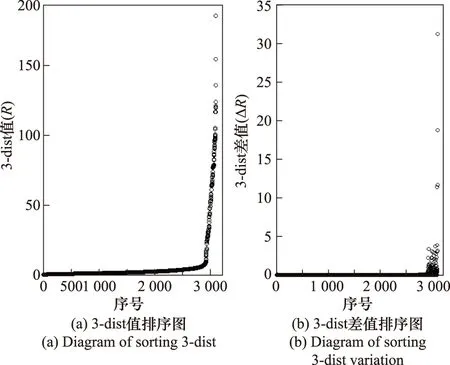
圖4 3-dist值及3-dist差值排序曲線Fig.4 3-dist value and 3-dist variation sorting curve

(6)
如圖4(b)所示,初期ΔR小范圍內波動,隨著序號增加,ΔR開始劇烈波動。ΔR依次表征了該簇的核心點、簇邊界點以及噪聲點3-dist值遞增的速度。不規則的簇邊界導致邊界點對應的ΔR差異較大,因此當橫軸序號遍歷到邊界點時,ΔR開始劇烈波動。
計算方差Var刻畫ΔR的波動程度。令Var={v1,v2,…,vn},其中:
(7)
方差Var的分布如圖5(a)所示,曲線突變點以前對應著簇的核心點和邊界點,突變點以后對應著噪聲點,因此該突變點即為所求閾值點。現引入熵E={e2,e3,…,en}來求解該突增點,設數據集的集合M={D2,D3,…,Dn-1},其中Di={v2,v3,…,vi},i=2,3,…,n。令

圖5 方差和熵的分布圖Fig.5 Diagram of variance and entropy
(8)
(9)
熵E的分布如圖5(b)所示,假設突變點序號為m,由于{v2,v3,…,vm-1}在0附近小范圍波動,?j∈{2,3,…,i},Pij(i={2,3,…,m-1})分布較均勻,因此隨著序號i的增大,Pij的個數增多,熵ei增大。
當i=m時,vm?vj(j={2,3,…,m-1}),則Pmm?Pmj(j={2,3,…,m-1}),熵ei開始減小,于是有m=arg max(E)。E取最大值對應的序號即為所求閾值點的序號,因此最優的Eps值為
Epsbest=rarg max(E)
(10)
至此DA-DBSCAN算法的兩個輸入參數已確定,聚類后得到簇Ci和噪聲點N。對于二分類模型,只有波形單元非起始脈沖構成的一個簇,因此將簇Ci都合并為一個簇C。序號屬于簇C對應非起始脈沖,而序號屬于噪聲點集合N則為起始脈沖。
2.2 波形單元提取的評價指標
對于二分類問題,真正例(true positive,TP)是指正例的數據點被標記為正例;假正例(false positive,FP)是指反例的數據點被標記為正例;真反例(true negative,TN)是指反例的數據點被標記為反例;假反例(false negative,FN)是指正例的數據點被標記為反例。
通過真正率(true positive rate,TPR)、假正率(false positive rate,FPR)、F-值(F-score)[14]3個指標來度量波形單元提取模型及算法的性能。相關定義如下:
(11)
(12)
F-score是一種常用于評價聚類結果的指標[15],公式如下:
(13)
TPR衡量了模型將波形單元起始脈沖檢測出來的能力,FPR衡量了模型將非起始脈沖誤判為起始脈沖的虛警率,而F-score綜合評價了聚類的分類結果對實際數據類型標簽的逼近能力。
2.3 調節TPR和FPR平衡的輸入參數λ
在檢測波形單元起始脈沖的問題中,檢測率和虛警率難以同時優化,強檢測能力對應著高虛警,而降低虛警也會導致檢測能力的下降。具體到聚類算法中,第2.1節中選取MinPts=3,Eps=Epsbest作為輸入參數,若增大Eps的取值,Density將減小。DA-DBSCAN算法通過密度可達形成簇,此時過渡區域的對象更容易被判定屬于簇,模型FPR減小,具有較低的虛警率,同時TPR也減小,檢測能力也將下降。因此,可以針對實際應用場景調節Eps獲得預期的用戶偏向需求。
設L為熵的最大序號m′與最大值點em的序號差m′-m,如圖5(b)中紅色部分的序號長度。輸入參數λ∈(-1,1),則
Eps=r(m+λ L)
(14)
當λ=0時,模型不體現額外的需求偏向;當λ為負時,模型偏向具有更高的TPR和檢測能力;當λ為正時,模型偏向具有更低的FPR和虛警率。且有
(15)
2.4 算法實現
MFR波形單元提取算法的實現步驟如表1所示。

算法 1 MFR波形單元提取算法輸入 多功能雷達脈沖列P,參數λ(默認為0)輸出 波形單元的起始脈沖和非起始脈沖1.計算多功能雷達脈沖列P的{ΔPRI,ΔRF,ΔPW},建立數據集D;2.計算數據集D中所有對象的3-dist值,由小到大排序后得到R;3.對R做差得到ΔR;4.計算ΔR的區間方差Var;5.根據Var計算熵E,并尋找最大熵值對應的序號m;若λ≠0,計算熵E最大序號m′與最大熵值點的序號差L=m′-m;6.確定聚類算法的輸入參數Eps=r(m+λL)和MinPts=3;7.對數據集D進行密度聚類,得到簇Ci和噪聲點集合N;8.將簇Ci合并為一個簇C,令序號屬于簇C的脈沖label值為0,即為非起始脈沖;令序號屬于噪聲點集合N的脈沖label值為1,即為起始脈沖。
3 實驗與結果分析
MFR波形單元提取算法采用R語言實現,為了驗證其有效性、適應性,現通過以下實驗分別研究脈沖缺失、測量誤差和參數選擇對提取效果的影響。上述二維相控陣雷達的仿真波形庫如表1所示,共包含5個類型40種波形單元。從波形庫中隨機均勻地選取100個波形單元構成脈沖列進行實驗。

表1 某二維相控陣雷達的仿真波形庫Table 1 Simulation waveform library of a two dimensional phased array radar
3.1 波形單元提取效果的對比實驗
為驗證本文構建的二分類模型和DA-DBSCAN聚類算法的性能,現進行以下對比實驗。一方面,將DA-DBSCAN聚類算法與傳統DBSCAN、層次聚類算法進行性能對比,從而驗證DA-DBSCAN聚類算法的有效性。另一方面,對同一聚類算法分別將D′={PRI,RF,PW}和D={ΔPRI,ΔRF,ΔPW}作為輸入數據集,驗證所提二分類模型的科學性。其中,傳統DBSCAN算法的參數MinPts設置為6時,參數Eps的取值范圍大致位于區間[5,9](數據集為D′)和[3,8](數據集為D),隨機選取該區間內3組距離值進行實驗。提取效果的相關指標如表2所示。

表2 不同聚類算法提取性能對比Table 2 Performance comparison of different clustering algorithms
由表2可知,同一聚類算法采用二分類模型后,其F-score都得到了明顯提高。二分類模型將波形單元內部和轉換時的波動差異作為先驗知識引入到無監督聚類算法中,充分利用了數據集的整體分布信息,從而大幅優化了提取效果。另一方面,傳統DBSCAN聚類算法的輸入參數依賴人為設置,參數設置質量直接影響了聚類精度,難以應用于工程實踐。DA-DBSCAN聚類算法能夠根據數據集的分布特點,自適應確定輸入參數,實現了波形單元的全自動提取。同時,與傳統DBSCAN和層級聚類算法相比,F-score達到0.979,具有最高的聚類精度。
3.2 脈沖缺失和測量誤差對提取效果的影響
脈沖丟失率(ratio of dropped pulses,RDP)[4]和誤差偏離水平(error deviation level,EDL)[4]的定義如下:
(16)
(17)
RDP和EDL取值為0%~50%,MinPts=3,λ=0,Eps=Epsbest,重復1 000次實驗的結果如表3和圖6所示。

表3 不同RDP/EDL下的提取結果Table 3 Extraction results under different RDP/EDL

圖6 不同RDP/EDL下的提取效果Fig.6 Extraction effect under different RDP/EDL
總體上隨著RDP和EDL的增加,算法檢測能力下降,虛警升高,聚類結果的F-score下降。但脈沖缺失時,模型將采用缺失脈沖前后脈沖的參數差值表征波形單元,依然能夠較好地刻畫波形單元內部和轉換時的差異。因此,當RDP取到50%,TPR仍在91.9%以上,FPR低于2.2%,F-score大于0.97,算法在高脈沖缺失率的條件下仍有較好的表現。相似地,算法對測量誤差也有良好的適應性。
3.3 輸入參數對提取效果的影響
本實驗通過研究不同參數下的提取效果來考察算法分類結果對實際數據標簽的逼近能力,從而驗證算法自適應確定參數的合理性。EDL為10%,RDP為20%,Eps取值為(r(m-L),r(m+L))的實驗結果如圖7所示。

圖7 不同Eps值下的提取效果Fig.7 Extraction results under different Eps values
由于檢測能力和虛警無法同時優化,隨著Eps增大,TPR和FPR都下降,F-score綜合評價了算法性能,呈現先增大后減小的趨勢。圖7中,紅線相交處為Eps=Epsbest時對應的評價指標,此時F-Score臨近最大值,驗證了算法自適應確定Eps的合理性。此次實驗Eps=Epsbest時聚類算法的結果如圖8所示,算法有效地將非起始脈沖構成的大密度“簇”(黑色)從起始脈沖構成的噪聲背景(紅色)中分離出來,實現了二分類從而提取非協作MFR的波形單元。

圖8 Eps=Epsbest的聚類結果Fig.8 Clustering result of Eps=Epsbest
另外,在第2.3節中提出通過輸入參數λ調節Eps值獲得預期的性能偏向。現以1/10的步長遍歷參數區間λ∈[-1,1],令EDL為10%,RDP為20%,1 000次實驗的結果如圖9和表4所示。

圖9 不同參數λ下的提取效果Fig.9 Extraction results under different λ values

表4 不同參數λ下的提取效果
當λ=0(Eps=Epsbest)時,起始脈沖的平均檢測能力達到88.59%,平均虛警率為3.36%,算法在具有測量誤差和丟失脈沖的條件下仍然表現出較好的提取性能;當λ∈[-1,0)時,TPR和FPR都增大,模型偏向犧牲虛警率獲取更高檢測率;當λ∈(0,1]時,TPR和FPR都減小,模型偏向犧牲檢測率獲取更低虛警率,且偏向程度與|λ|呈正比。因此在實際應用中,用戶可以根據當前提取效果和表中評價指標的變化,選取合適的參數λ獲得預期的算法性能偏向。
4 結束語
本文對MFR波形單元提取的問題展開了研究,首先構建了基于PRI、RF、PW序列的二分類模型,該模型充分利用了數據集的整體分布信息和多參數間的聯合變化,能夠較好地適應實際探測過程中的脈沖丟失和測量誤差。然后,針對該模型提出了一種參數自適應確定的DA-DBSCAN聚類算法進行分類,從而對非協作MFR實現了波形單元提取。最后,通過引入輸入參數λ可針對不同的用戶需求調整算法性能。
仿真實驗表明,所提方法有效提取了非協作MFR的波形單元,較好地應對了實際工程應用中缺乏波形庫先驗知識的問題。同時,能夠適應測量誤差和脈沖丟失帶來的干擾,具有良好的準確性和魯棒性,因而對實際探測獲取的數據有較好地適用基礎,具有重要的現實意義。另外,由于實際獲取的MFR脈沖列還具有不同程度的虛假脈沖,在對實際獲取數據進行波形單元提取前可以通過如TTP變換等參數過濾的預處理剔除虛假脈沖,降低算法的虛警率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
