
基于NLP 的文本相似度檢測方法
2021-11-14 08:23:24代曉麗劉世峰宮大慶
通信學報 2021年10期
代曉麗,劉世峰,宮大慶
(1.北京交通大學經濟管理學院,北京 100044;2.北京信通傳媒有限責任公司,北京 100078)
1 引言
互聯網的發展給網絡平臺帶來了海量的數據,其中文本數據是主要的數據形式,如何處理網絡中的大量文本數據是一個急需解決且復雜的問題。文本相似度檢測是文本處理領域的一個關鍵技術,通過文本間的對比計算兩篇或多篇文本間的相似程度,在信息檢索[1]、文本分類[2]、機器翻譯[3]、自動問答[4]等自然語言處理(NLP,natural language processing)領域的任務中具有廣泛應用。
由于文本格式、類型繁多,很難對文本的各種特征進行捕捉,使設計一個準確性較高的文本相似度檢測方案面臨一定的挑戰。基于統計和基于語義的文本相似度檢測方法是學者們研究的熱點[5]。
基于統計的文本相似度檢測方法主要是基于字符匹配和基于詞頻特征的相似比較,基于字符匹配的方法將文本分解為字的集合,以字符間的變化程度作為相似度結果,最長公共子串(LCS,longest common substring)[6]、編輯距離[7]、Jaccard 系數[8]、Dice 系數[9]等是較常用的方法;基于詞頻特征的方法以 TF-IDF(term frequency-inverse document frequency)方法為主,該方法將文本分解為詞語的集合,以詞頻作為向量,通過計算向量距離得到文本相似度,如歐氏距離、曼哈頓距離、余弦距離[10]等。這些方法僅衡量了文本表面的相似度,而沒有考慮文本的語義相似度,使得到的結果缺乏一定的準確性。
針對語義缺失的問題,出現了基于語義的方法,該方法通過引入外部知識來使文本具有語義信息[11],其中基于詞典和基于向量空間模型(VSM,vector space model)是較常見的方法。基于詞典的方法利用通用詞典構建詞語的概念語義樹,兩詞語在樹中的距離即為它們之間的相似度[12];基于向量空間模型的方法利用外部語料庫來構建具有語義的詞向量,通過度量詞語的重要性提取特征詞來表示文本,然后將特征詞向量綜合表示為文本向量,最后以文本向量間的距離作為相似度結果[13]。在基于向量空間模型的方法中,對于特征詞提取,多數方法只依據詞語的詞頻信息,沒有考慮文本的結構信息;同時,文本向量表示沒有考慮詞語間的語義關聯性,導致相似度檢測結果的準確率較低。
為了解決上述問題,本文提出了面向文本的相似度檢測方案,基于文檔結構特征將詞語位置權重與詞頻權重作為特征詞提取的依據,并將詞語間的語義關系融入相似度計算的過程,在提升特征詞提取精度的同時提高相似度計算的準確性。本文的主要貢獻如下。
1) 針對特征詞提取階段詞語位置加權方法主觀性較強導致提取結果缺少代表性的情況,提出了基于層次分析法(AHP,analytic hierarchy process)的詞語位置加權方法,利用成對比較法基于文本結構設置詞語位置權重,提高了特征詞提取結果的精確度。
2) 針對相似度計算階段的文本向量表示法未考慮詞語間語義關系導致計算結果不夠準確的情況,提出了基于Pearson 相關系數和廣義Dice 系數的相似度計算方法,利用相關系數衡量詞語間語義關系,改進廣義Dice 系數公式,提高了相似度計算結果的準確性。
3) 對本文提出的面向文本的相似度檢測方案與經典方法、未做出改進的原始方法在準確率、精確率、召回率、F1 值方面進行對比,實驗結果顯示,本文方案有效提高了相似度計算的準確率。
2 相關工作
關鍵詞提取是從文本中提取出最能代表該文本信息的詞語,文本相似度的計算與關鍵詞的提取有著密切的關系,關鍵詞提取的準確率間接地影響相似度計算結果。最常用的關鍵詞提取技術有TF-IDF[14]、線性判別分析(LDA,linear discriminant analysis)[15]、圖模型[16],許多學者在此基礎上做出了改進。傳統的TF-IDF 算法只在處理不同類文本時效果較好,文獻[17]在TF-IDF 算法的基礎上提出TF-IWF(term frequency-inverse word frequency),將逆文檔頻率改為逆詞語頻率并設置詞語位置權重,能夠更好地處理語料庫中同類型文本較多的情況以及利用詞語位置信息,但文中詞語位置權重為作者的主觀設置,缺少客觀性。LDA 利用詞語的概率分布推測文檔的主題概率,文獻[18]結合TF-IDF和LDA 算法,利用LDA 提取的主題構建關鍵詞詞典,基于該詞典采用TF-IDF 算法從文章的摘要中提取最終的關鍵詞用于文章分類,提高了文本分類的精度,但關鍵詞之間沒有語義關聯。文獻[19]提出了基于LDA 和圖模型的關鍵詞挖掘方法,采用兩級語義關聯模型,將主題之間的語義關系與主題下詞語之間的語義關系聯系起來,并根據組合作用提取關鍵詞,該方法提高了從文本中提取關鍵詞的準確性,但計算的復雜度較高。
針對文本相似度計算,現有方法從降低復雜度和提高準確率方面進行研究。文獻[20]利用哈希將文本轉化為數字指紋,使用Jaccard 系數來度量指紋間的相似值,適用于檢測字符級改變的文本。文獻[21]提出了基于VSM 的相似度計算方法,利用特征項權重加權TF-IDF,提高了相似度計算的精度。文獻[22]使用VSM 和TF-IDF 加權模式以及哈希特征提取技術提高了大規模文本相似度計算的速度。這些方法生成的都是高維稀疏的向量且不包含文本語義。文獻[23]提出了基于雙向空間模型的相似度計算,分別利用維基百科的數據鏈接和構建依賴樹來計算詞語相似度和文本結構相似度,雙向結合得到文本相似。文獻[24]提出了一種基于TF-IDF 和LDA 的混合模型來計算文本相似度,能夠利用文本本身包含的語義信息并反映文本關鍵詞的權重,但LDA 包含的文本語義較稀疏。文獻[25]提出了一種結合HowNet 語義知識詞典和VSM 的文本相似度計算方法,在詞匯層面使用HowNet 計算相似度避免了語義信息丟失,在文本層面使用VSM 計算相似度保證了表達信息的完整性,但是HowNet 等已構建好的通用詞典較少,更新慢、具有獨立性,跨領域或新領域的應用效果較差。文獻[26]結合Word2vec 詞向量轉換技術,利用其語義分析能力構建優化的LDA 模型,最后使用余弦相似度來計算文本相似度,充分表達了文本語義,理想地實現了對重復文本的語義分析,但其訓練語料需要經過Word2vec 模型轉換為詞向量,再將向量作為輸入訓練LDA 模型,導致模型訓練成本較高。
3 基于NLP 的文本相似度檢測框架
本節介紹了文本相似度檢測框架以及各個步驟的具體方法,并分析了流程中存在的問題。
3.1 文本相似度檢測框架
圖1 是本文結合基于向量空間模型和基于分布式表示方法[13,27-31]提出的文本相似度檢測框架,利用分布式詞向量將文本映射到向量空間中,以此計算文本在向量空間上的相似度。該框架是一種較通用的相似度計算流程,研究者常在其中的一個或多個步驟中進行研究改進,以提高檢測性能。本文所使用的具體方法和步驟如下。
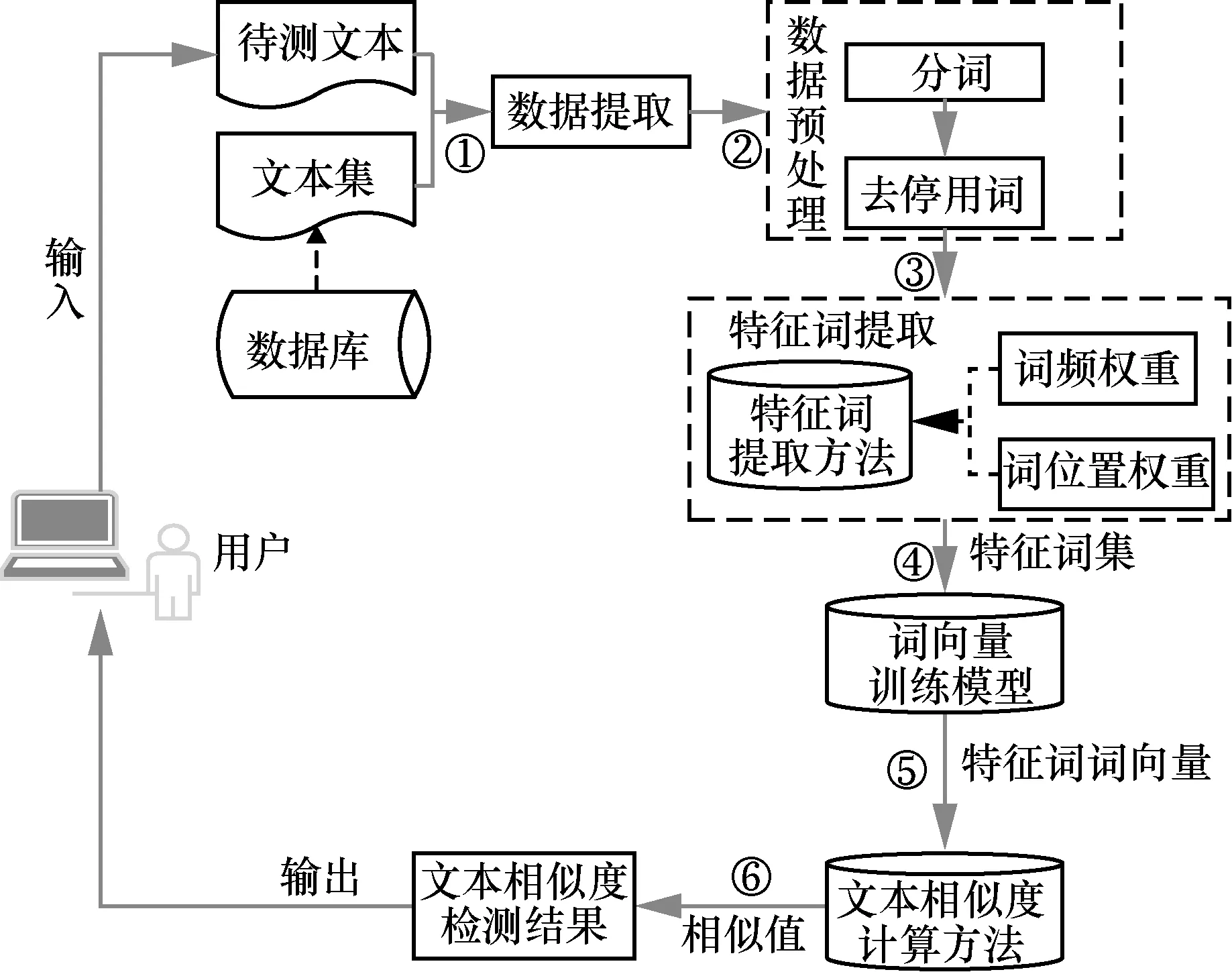
圖1 文本相似度檢測框架
①數據提取。用戶將待測文本數據輸入系統,系統從數據庫中提取相應的文本集數據。
② 數據預處理。合并提取文本內容并對其分詞、去停用詞。首先使用分詞工具將文本內容分割為詞語集,由于詞語集中會存在對文本表達無語義影響但會影響特征詞提取結果的詞語和符號,因此,使用停用詞表,將這些詞語和符號從詞語集中刪除。
③特征詞提取。數據預處理結束后,接下來要從2 個方面計算每個詞語的總權重并作為特征詞提取的依據。首先,使用TF-IWF[17]算法計算詞語的頻率權重,如式(1)所示。
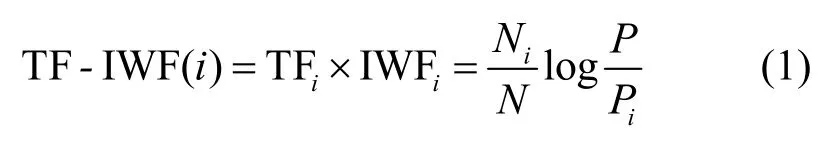
其中,Ni為詞語i在單文本中的數量,N為單文本詞語總數,P為語料庫的詞語總數,Pi為詞語i在語料庫中的數量。這種方法能夠有效降低文本集中文本數量少、同類型文本多等情況對詞語權重的影響。其次,根據文本的結構特征設置詞語的位置權重,表示為Wloc(i),對出現在文本標題、關鍵詞、摘要中的詞語分別賦予權值3、2、1。最后,將詞頻權重和詞位置權重加權和得到詞語總權重,由大到小排序,提取一定比例的詞語構成特征詞集代表文本。詞語i總權重計算式為
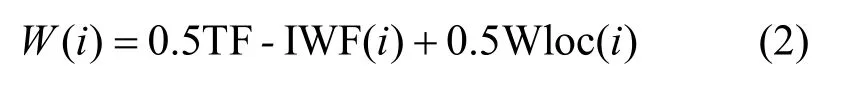
④ 詞向量生成。詞向量生成是將詞語轉換為計算機可識別、可計算的過程。Word2vec 是一種詞向量生成工具,由Mikolov 等[32]于2013 年開發,作為深度學習模型中的一種分布式表達。Word2vec有CBOW(continuous bag-of-words)和Skip-gram(continuous skip-gram)2 種訓練模式,CBOW 使用詞語的上下文來預測詞語本身,而Skip-gram 則使用當前詞來預測上下文詞語。Word2vec 模型能夠從大規模未經標注的語料中訓練得到具有語義、低維、稠密的詞向量,可以較好地應用于文本相似度中的詞語表示。
⑤ 文本相似度計算。通過Word2vec 模型得到特征詞向量,利用式(3)的2 種方式將其轉換為文本向量,前者為疊加所有特征詞向量,后者取疊加后詞向量的平均值。然后使用廣義Dice 系數[33]計算2 個文本向量的相似度表示為最終的文本相似度,如式(4)所示。
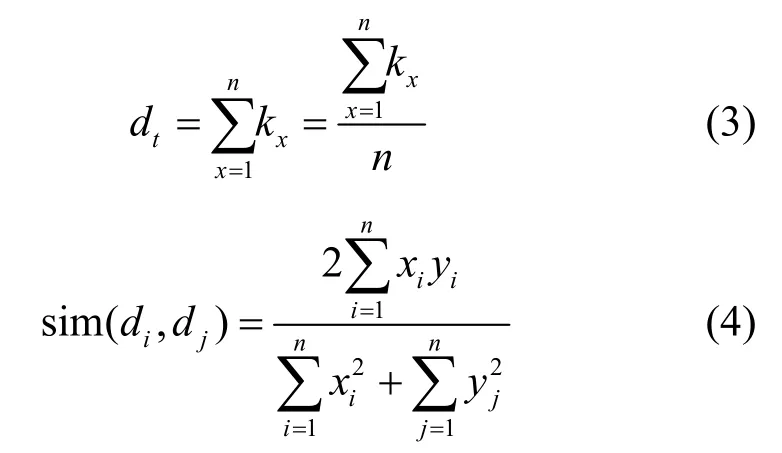
其中,kx表示詞語x的詞向量;di和dj分別表示通過式(3)得到的文本i和文本j的向量;sim(di,dj)表示文本i和j的相似值,相似值越接近1 表示兩篇文本越相似。
⑥ 輸出結果。依據文本間相似值和給定閾值t判斷該文本是否相似,并將結果返回給用戶。
3.2 問題描述
文本相似度檢測框架中存在以下2 個方面的問題。
1) 提取的特征詞缺乏代表性。在提取特征詞階段,對詞位置權重的設置僅按照文本結構簡單的設為具有差異的數值,存在較強的主觀性且沒有合理依據,從而影響詞語的總權重,使提取到的特征詞不能更準確地表達文本,因此需要設計合理的詞位置權重計算方法。
2) 相似度計算結果不夠準確。在計算文本相似度階段,對特征詞向量進行疊加或加權平均構建文本向量,將文本相似度計算轉化為向量空間相似度度量,這種方法沒有考慮到詞語之間的語義關聯,不能表達文本的深層語義,容易導致計算結果存在偏差,因此需要設計一個融合詞語語義關系的相似度計算方法。
4 面向文本的相似度檢測方案
針對3.2 節描述的提取的特征詞缺乏代表性、相似度計算結果不夠準確這2 個問題,本文分別提出了基于層次分析法的詞語位置加權方法和基于Pearson 和廣義Dice 系數的相似度計算方法。
4.1 基于層次分析法的詞語位置加權方法
層次分析法設置文本各部分對詞語重要性影響的權值,通過提高詞語位置權重的合理性來提升提取特征詞的準確度。AHP 是結合定性和定量分析的綜合評估方法,根據決策將問題分解為不同層次的因素,使用定性分析確定元素間的相對重要性,再結合定量分析確定各層次以及各因素的權值,為決策者提供依據,適用于存在主觀性和不確定性信息的情況[34-35]。本文利用層次分析法設置文本各部分對詞語重要性影響的權值,改進文本相似度檢測框架中,特征詞提取階段的詞語總權重計算式,通過提高詞語位置權重的合理性來提升特征詞提取的準確度。該方法的具體步驟如下。
1) 詞語位置重要性參數設計
本文設計的相似度檢測方案面向的文本類型為學術論文,該類型文本的統一結構包含了論文標題T、論文摘要A、論文關鍵詞K 等,詞語位置的重要程度主要由這3 個因素決定,如式(5)所示。
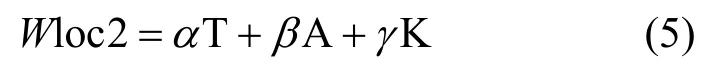
其中,α、β、γ為各因素在決定詞語位置重要性時所占的比例。
2) 詞語位置重要性計算
論文標題通常包含了文章的研究主題、使用方法和應用場景,是論文圍繞的核心;論文關鍵詞是作者總結文章重要內容的詞語,其對文章的重要性略低于論文標題;論文摘要是從背景、目標、過程、結果對論文的簡短概述,包含的詞語相對較多,其對文章的重要性相對來說低于論文標題和論文關鍵詞。經分析發現,文本各結構部分對其內容的重要性存在差異,根據AHP 將論文標題、關鍵詞、摘要作為3 個因素,計算其成對比較值,即可確定每個因素對文本的重要性。表1 是由Saaty 給出的9 個重要性等級及其量化值,依此構造的成對比較矩陣如表2 所示。

表1 9 個重要性等級及其量化值
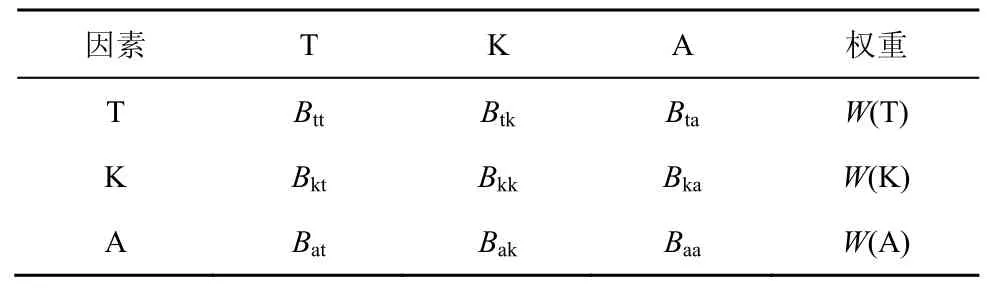
表2 成對比較矩陣
表2 中,Btt表示因素T 與T 的重要性比值,各因素與其自身的重要性是一樣的;Btk表示因素T與K 的重要性比值,Btk與Bkt互為倒數,依次類推,可得到其他兩兩因素的重要性比值。W(T)、W(K)、W(A)分別表示論文標題、關鍵詞、摘要在決定詞語位置重要性時所占的比例,如式(6)所示。
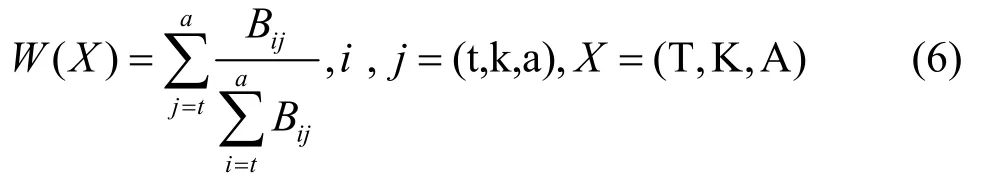
3) 改進的詞語總權重計算
根據式(6)計算得到文本各結構對詞語位置的重要性W(T)、W(K)、W(A),將其代入式(5)中可得到式(7),即得到詞語i的位置權重,計算式為
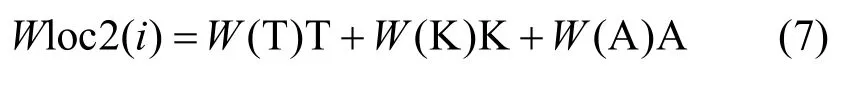
將Wloc2(i)代入原詞語總權重計算式(2)中的位置權重Wloc(i),得到改進后的詞語總權重計算式為
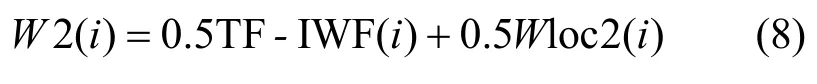
W2(i)作為新的詞語總權重用于提取特征詞,以在文本相似度檢測框架的后續步驟中使用。
4.2 基于Pearson 和廣義Dice 系數的相似度計算方法
Pearson 相關系數用于衡量2 個變量之間的線性相關程度,對數據分布比較敏感,適用于正態分布的變量。文獻[36]表明語義相似的詞向量呈線性關系,且Word2vec 模型訓練的向量更傾向于正態分布。文本相似度檢測框架的步驟④采用了Word2vec 來生成詞向量,因此,本文利用Pearson相關系數來度量詞語間的語義關系,并將其作為廣義Dice 系數的權重改進相似度計算公式。該方法同時考慮了單文本內部和跨文本間的語義關系,提高了文本相似度計算結果的準確性,具體步驟如下。
1) 詞語間語義關系度量
特征詞提取之后,文本的內容由其特征詞代替表示。將特征詞輸入Word2vec 模型,每個詞被轉化為固定維度的向量,每個維度都表示該詞語在不同方面的語義信息,例如(v1,v2,...,v400)。記ki和kj分別為文本di和dj的特征詞,使用Pearson 相關系數計算詞語間語義相似度,如式(9)所示。
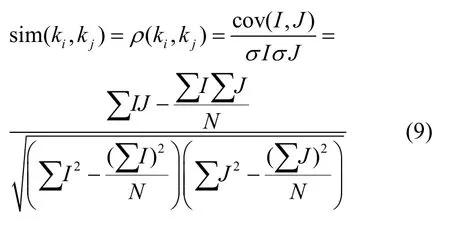
其中,ρ(ki,kj)表示詞語ki和kj的相關系數;cov(I,J)表示樣本協方差;σI和σJ表示樣本方差;ρ的取值范圍為[-1,1],若相關系數接近1,兩向量之間呈正相關,意味著2個詞語在語義上越相似,反之,兩向量之間呈負相關,意味著2 個詞語在語義上越不相似。
2) 改進的文本相似度計算
該方法中沒有將特征詞轉化為文本向量,而是將式(9)計算的特征詞之間的Pearson 相關系數作為廣義Dice 系數的權重,利用單文本內詞語間的不相關性和跨文本間詞語的語義相關性,通過兩者之間的相對關系得到文本的相似度。由此,改進原始的廣義Dice 系數式(4),得到式(10)為新的相似度計算式。
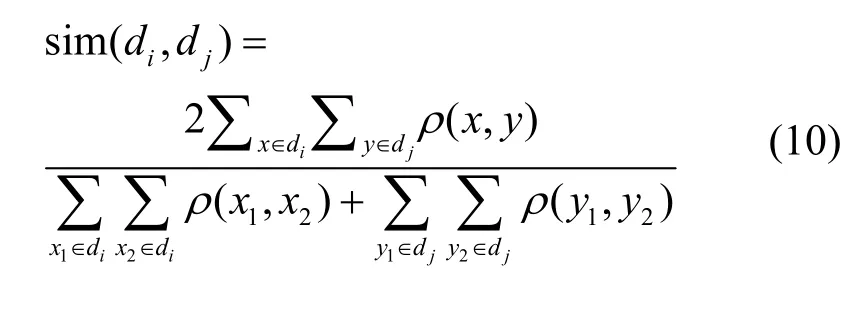
其中,x和y分別表示文本di和dj的特征詞組,sim(di,dj)表示文本di和dj的相似度。具體的含義為:一組特征詞內部兩兩詞語間的相似度越小,該特征詞組越能夠從多方面充分表達文本內容;同時,兩組特征詞之間兩兩詞語間的相似度越大,該兩組特征詞表達的兩篇文本內容也越相似。因此,當根據式(10)計算的相似度大于閾值t時,表示該兩篇文本是相似的。
5 實驗與分析
針對本文提出的特征詞提取方法和相似度計算方法,分別設計了2 個對應的實驗,來驗證本文提出的相似度檢測方案的有效性。
5.1 實驗1:特征詞提取
1) 實驗數據
實驗1 是由復旦大學提供的包含20 個不同文本類別的中文分類語料。本文從中隨機選取已經由人工標注出關鍵詞的農業(agriculture)、藝術(art)、計算機(computer)、經濟(economy)、環境(environment)、歷史(history)、政治(politics)、航空(space)等8 類不相關文本各20 篇以及由這8 類中每類的兩篇文本組成混合文本(mix)16 篇,作為測試數據集。數據集中的每個數據項包括論文標題、摘要、關鍵詞,實驗中使用數據集中的關鍵詞字段作為對比項,與實驗所提取的特征詞相比較來評估各方法的性能。
2) 對比方法及評價指標
實驗中選取了經典的 TF-IDF 算法和基于TF-IDF 改進的 TF-IWF[17]算法與本文方法(TF-IWF-Location)進行對比。
本文將采用關鍵詞提取領域常用的精確率P(precision)、召回率R(recall)、綜合指標F1 值(F1-score)來評測實驗結果,其定義分別如式(11)、~式(13)所示。
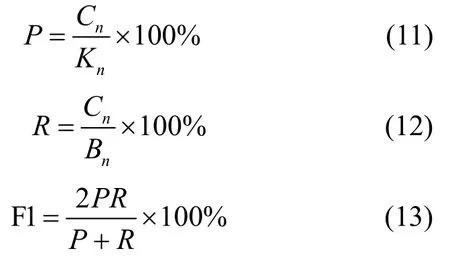
其中,Cn表示正確提取到的特征詞個數,Kn表示提取的所有特征詞個數,Bn表示語料中標注的特征詞個數。
3) 實驗設置
首先提取論文標題、摘要、關鍵詞的內容,并將其合并為一段。然后使用jieba 分詞和哈工大停用詞表對合并后的內容分詞、去停用詞,構建特征詞候選詞集。
特征詞提取是將候選詞集中重要度靠前的K個詞語輸出為特征詞。由于數據集中各類文本的長度不一樣,且標注的關鍵詞個數不同,為了使實驗結果更加客觀準確,實驗中根據每類文本中標注的關鍵詞個數來調整提取的特征詞個數,保證兩者之間的差值在10 之內,通過實驗調試,得出每類語料對應所提取合適的特征詞個數,如表3 所示。
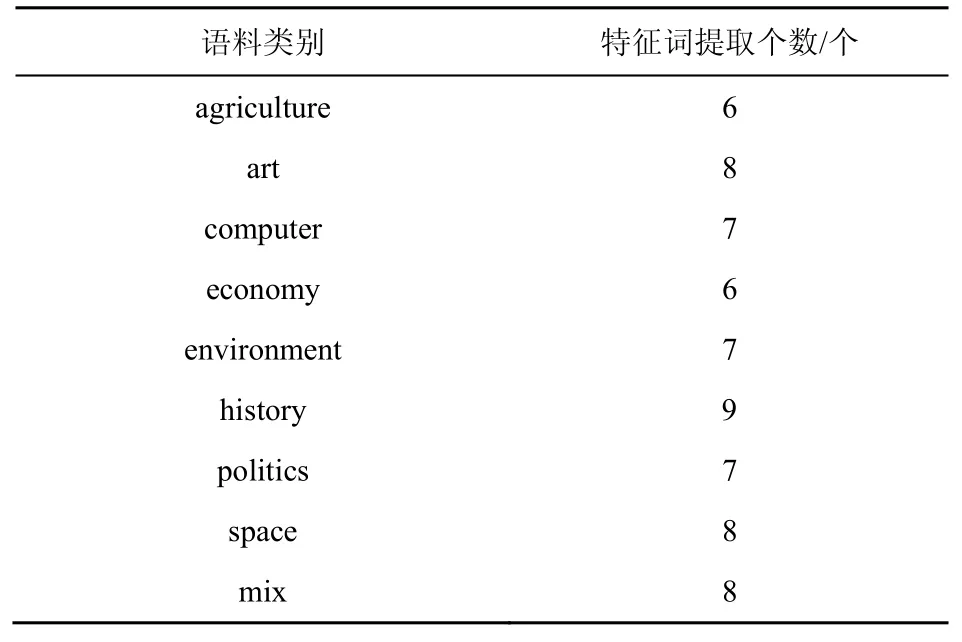
表3 語料類別與特征詞提取個數
在本文所提方法TF-IWF-Location 中引入了層次分析法,將論文標題表示為T、關鍵詞表示為K、摘要表示為A,根據4.3 節的分析以及表1 的比例標度,T 比K 稍微重要,K 比A 稍微重要,T 比A較強重要,通過構造T、K、A 間的成對比較矩陣得出論文各結構的位置權重參數,如表4 所示。
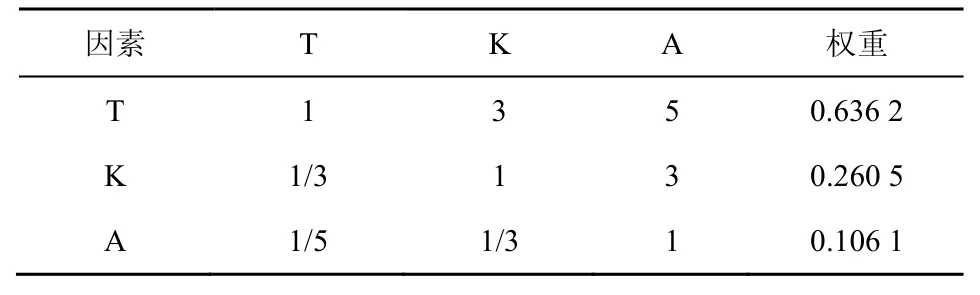
表4 T、K、A 間的成對比較矩陣
4) 實驗結果分析
按照以上實驗設置進行特征詞提取,將不同算法的各項指標以折線圖呈現,圖2~圖4 分別是TF-IDF、TF-IWF、TFIWF-Location 算法的精確率、召回率、F1 值的比較結果。
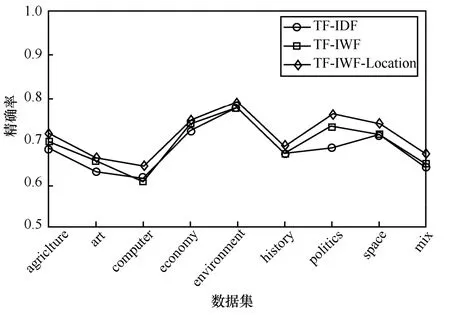
圖2 TF-IDF、TF-IWF、TF-IWF-Location 算法之間的精確率比較
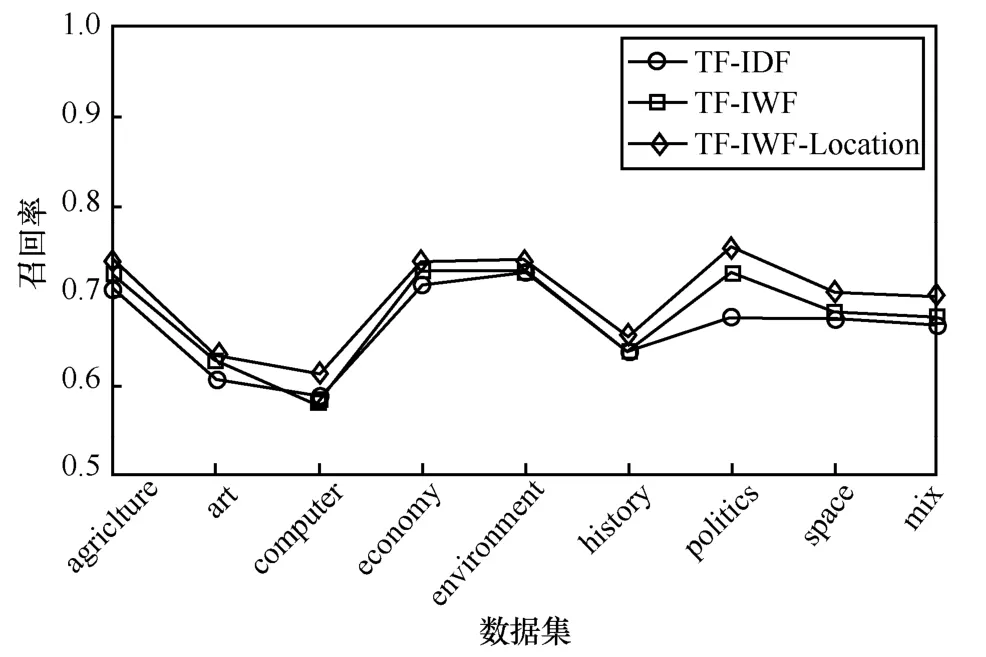
圖3 TF-IDF、TF-IWF、TF-IWF-Location 算法之間的召回率比較
通過圖2~圖4 可知,TF-IWF 算法在computer語料上的精確率、召回率和F1 值略低于TF-IDF 算法,在environment 和history 語料上與TF-IDF 算法的性能相等,總體上優于TF-IDF 算法,表明TF-IWF 算法能夠有效地提高提取同類文本集中特征詞的準確性。
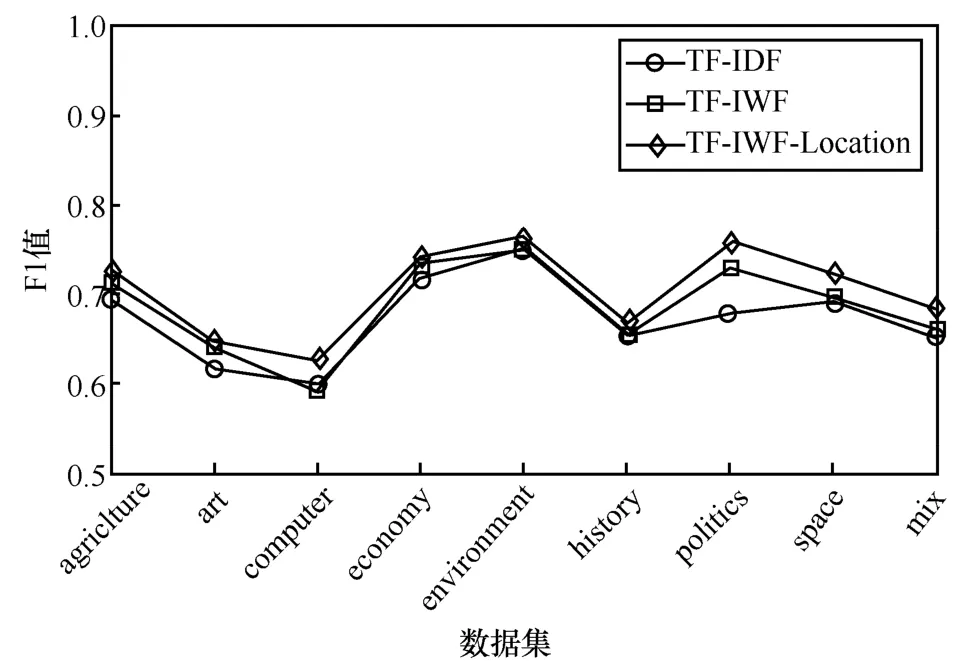
圖4 TF-IDF、TF-IWF、TF-IWF-Location 算法之間的F1 值比較
本文所提方法TF-IWF-Location 與TF-IDF、TF-IWF 相比,在精確率、召回率、F1 值等各項指標上均有所提高,特別是在computer、politics、space、mix 語料上的提高幅度較大,其中,精確率、召回率、F1 最高分別提高了7.9%、10.7%、7.8%。結果表明,詞語在文章中的結構位置對詞語的重要性具有一定的影響,該方法能夠較好地提高對學術論文進行特征詞提取的準確率。
5.2 實驗2:文本相似度檢測
1) 實驗數據
維基百科中文語料庫,由中文維基百科中的新聞文章組成,具有質量高、領域廣泛且開放的特點。實驗中使用的是截至2021 年5 月5 日的中文維基百科語料,大小約2 GB,包含392 515 篇文章,以xml格式存儲。本文以該語料庫來訓練Word2vec 模型。
LCQMC 問題語義數據集包含238 766 對訓練文本、8 802 對驗證文本和12 500 對測試文本,這些文本來自百度問答中不同領域的高頻相關問題,由人工判定相似的句子對標簽為1,不相似的標簽為0。本文以測試集的12 500 對句子作為實驗的測試數據,通過設置相似度閾值來將計算結果分為相似(1)與不相似(0)兩類,與數據集中的標簽對比得到實驗方法的各項指標對比結果。
2) 對比方法及評價指標
實驗中選取了 2 種方法來與本文方法Pearson-Dice 做對比,一種是傳統的基于余弦相似度的方法Base-Cosine[37],以特征詞疊加后的平均向量表示文本,再計算文本向量之間的余弦相似度;另一種是本文改進之前的方法Base-Dice,該方法在Base-Cosine 的基礎上,使用廣義的Dice 系數來替代余弦相似度計算文本相似度。
本文將文本相似度檢測抽象為相似或不相似的二分類問題。采用二分類領域中常用的準確率(accuracy)和綜合指標F1 值(F1-score)來評估各方法的性能,其定義分別如式(14)和式(15)所示。

其中,TP 表示被正確計算為相似句子對的數量,TN 表示被正確計算為不相似的句子對數量,FP 表示被錯誤計算為相似句子對的數量,FN 表示被錯誤計算為不相似的句子對數量,P和R分別表示二分類問題中的精確率和召回率,如式(16)和式(17)所示。

3) 實驗設置
下載的維基百科語料為xml 壓縮格式且有較多的不可用數據,不可直接用于訓練Word2vec。先使用WikiCorpus 方法將文件格式轉換為txt,再通過Opencc 將文本中的繁體字轉為簡體字,然后基于正則表達式去除數據中的英文和空格,最后使用jieba將分詞后的文本輸入Word2vec 模型進行訓練。
訓練Word2vec 模型時,有多個參數需要設置。在模式選擇上,COWB 模式的速度更快,Skip-gram模式的效果更好,實驗中使用Skip-gram 模式;滑動窗口的大小為5,以此構建訓練集;最低詞頻為5,過濾數據中出現次數低于5 的詞語;詞向量維度為400,官方推薦值為300~500,此處取中間值;其余參數均為默認。
文本之間的相似性由其相似分布值與閾值的相對大小決定。如果一對不相似文本和一對相似文本的相似值分別為0.7 和0.8,那么將相似度閾值設置為0.75,就能夠正確地區分相似和不相似文本。由于數據集和各相似度計算方法會使輸出的相似值的分布情況有所差異,因此,實驗中分別將相似度閾值設置為0.50、0.55、0.60、0.65、0.70、0.75、0.80、0.85、0.90 來比較結果。
4) 實驗結果分析
按照以上的實驗設置進行文本相似度檢測,將不同方法的各項指標以折線圖展示,圖5 和圖6 分別為Base-Cosine、Base-Dice、Pearson-Dice 的準確率和F1 值的比較結果。
由圖5 可知,當相似閾值設置為0.50、0.55、0.60、0.65、0.70 時,Base-Dice 方法的準確率高于其他2 種方法;當相似度閾值為0.75、0.80、0.85、0.90 時,本文方法的準確率高于其他方法,閾值設置為0.85時準確率最高為75.9%,與Base-Dice、Base-Cosine方法相比分別提高了2.08%和11.4%。由圖6 可知,僅在相似閾值為0.9 時,Base-Cosine 方法的F1 值略高于本文方法的F1 值,在其余相似度閾值的情況下,均為本文方法F1 值最高。本文方法在閾值為0.80 和0.85 時達到75.7%和75.6%,最高值與Base-Dice、Base-Cosine 方法相比分別提高了2.8%和7.1%。
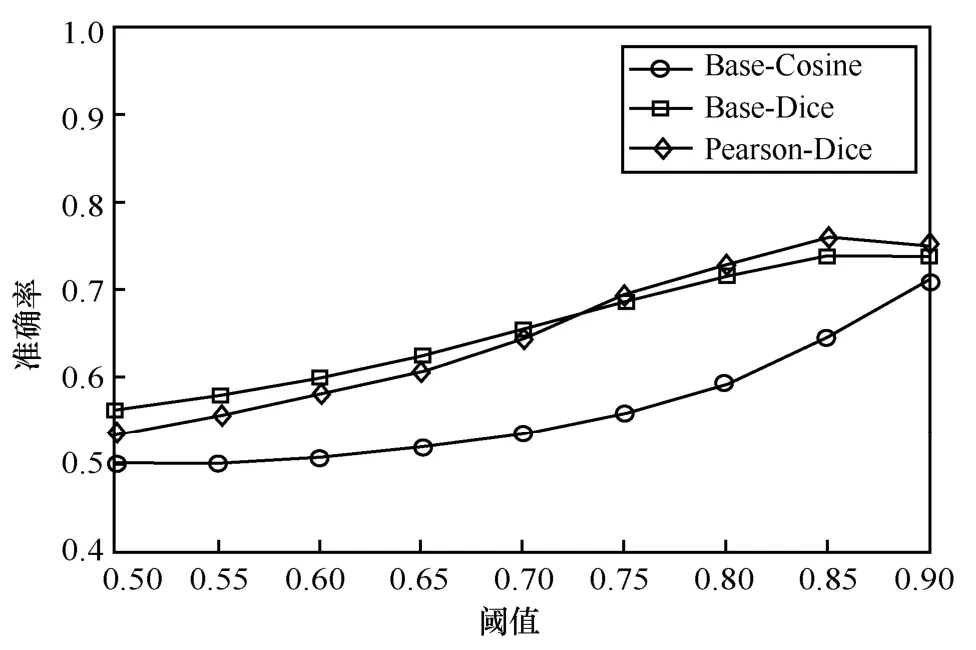
圖5 Base-Cosine、Base-Dice、Pearson-Dice 的準確率比較
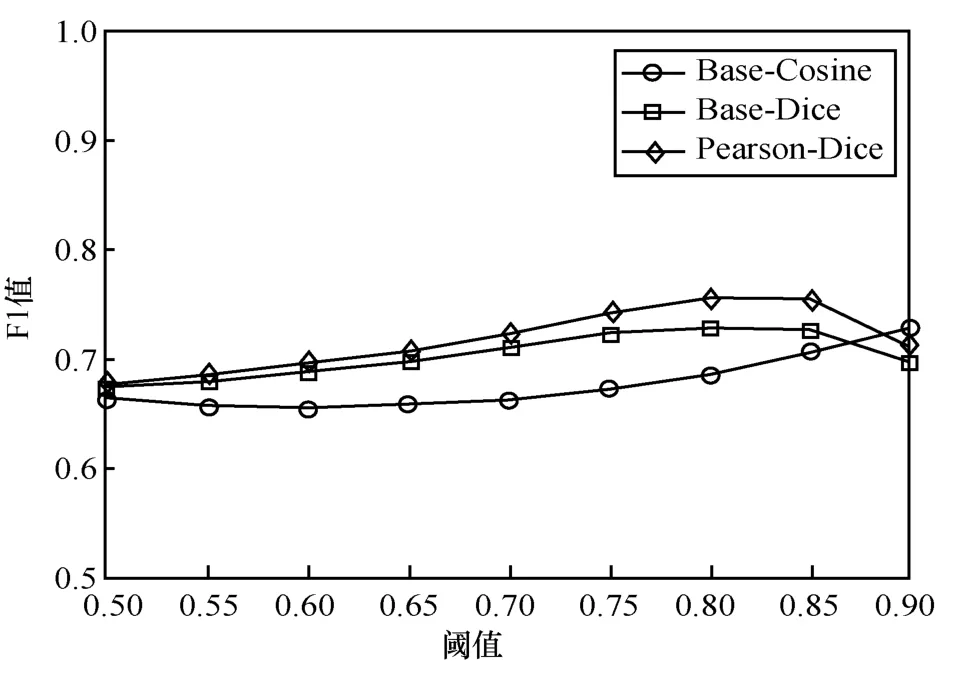
圖6 Base-Cosine、Base-Dice、Pearson-Dice 的F1 值比較
結果顯示,無論是在準確率還是在F1 值方面,各方法的變化趨勢總體上一致,各方法在閾值為0.80 和0.85 時對應的準確率、F1 值均達到最高。這表明,該數據集的相似值分布在0.80~0.85,當閾值設置在這個范圍里,能夠最好地區分相似或不相似文本,并且均為本文方法性能最優。綜上所述,詞語間的語義關系在文本相似度計算中發揮了一定的作用,本文所提出的方法是有效可行的。
6 結束語
本文基于向量空間模型的相似度檢測算法,在特征詞提取階段提出了基于層次分析法的詞語位置加權方法,利用層次分析法確定文本位置對詞語的重要性,使提取的特征詞更能代表文本;在相似度計算階段提出了基于Pearson 和廣義Dice 系數的相似度計算方法,引入了詞語語義相似度作為廣義Dice 系數的權重,從而解決了傳統方法忽略詞語間語義關系的問題。并針對這兩點進行改進,分別設計了2 個對應的實驗,與傳統方法以及改進前的方法相比,本文提出的方法能夠有效地提高計算結果的準確率。下一步將以提高分詞準確性繼續改進,并進一步探索跨語言的相似度檢測,繼續提升相似度計算的準確率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
