基于二維卷積神經網絡高層數據特征學習的過程故障檢測
2021-11-18 03:26:10楊東昇李大舟
沈陽化工大學學報 2021年3期
李 元, 楊東昇, 李大舟
(沈陽化工大學 信息工程學院, 遼寧 沈陽 110142)
化工生產過程系統正快速向著大型化、復雜化發展,在帶來經濟效益的同時也使得設備故障和人員受傷的幾率增大.與傳統工業環境相比,這些系統發生故障,一方面帶來經濟方面的損失,另一方面還有可能引起爆炸、火災、毒氣泄漏等特大事故,從而給社會、人員和環境帶巨大的傷害.所以,確保化工過程安全、可靠,故障檢測的準確性具有十分重要的意義.故障檢測的研究也成為大量海內外專家學習和研究的熱點[1-4].
故障檢測技術包含4大類:(1)基于專家系統的診斷方法;(2)基于多元統計分析的診斷方法;(3)基于機器學習的診斷方法;(4)基于深度學習的診斷方法.其中專家系統包括淺知識專家系統和深知識專家系統,具有知識獲取方便、形式統一、維護簡單等優點,但存在知識集不完善、過分依賴專家經驗和推理速度相對較慢的缺點.常用的多元統計分析方法包括主元分析(principal component analysis,PCA)[5]、基于k近鄰的方法(k-nearest neighbor,kNN)[6]、偏最小二乘法(partial least squares,PLS)[7],以及獨立主元分析(independent component analysis,ICA)[8],具有方法簡單、數學解釋性強的優點,但是針對化工過程數據的多模態、非線性問題并不能妥善處理.機器學習包含了人工神經網絡(artificial neural network,ANN)[9]、支持向量機(support vector machine,SVM)[10]、高斯混合模型(Gaussian mixture model,GMM)[11]等,具有特征學習能力強的優點,同時也存在著故障檢測率低的不足.深度學習包含了深度信念網絡(deep belief network,DBN)[12]、卷積神經網絡(convolutional neural networks,CNN)[13]等,具有可通過捕捉輸入樣本的模式特征、通過網絡連接的方式提取出最高層的特征、再將其分類的優點.
目前已有一些專家學者將深度學習中的卷積神經網絡用于故障檢測與診斷中,并且獲得了一定的成果.李輝[14]等將二維卷積神經網絡用于變壓器的故障檢測,提出一種將一維樣本數據轉為二進制二維數據的檢測方法和流程,并且取得相對較好的成果.趙東明[15]等將一維卷積神經網絡用于柴油發電機的健康評估,提出一種基于卷積神經網絡的健康評估方法,并與常用的BP神經網絡對比,在準確率和識別速度上都有了明顯的提升.吳春志[16]等將卷積神經網絡用于齒輪箱的故障診斷,利用一維卷積神經網絡模型對齒輪箱故障進行檢測,該模型對單一和復合故障檢測準確率均高于傳統檢測方法.Wen[17]等提出一種基于卷積神經網絡的智能故障檢測方法,在凱斯西儲大學電機軸承數據集上進行了實驗,獲得了預測精度高達99.51 %的成果.Zhang[18]等提出一種基于擴展深度信念網絡,利用DBN子網絡提取故障數據的時空特征,利用全局反向傳播網絡進行故障分類,并且獲得平均故障檢測率高達82.1 %的成果.盡管以上算法用于工業故障檢測可以獲得較好的成果,但是針對化工過程中的非線性、高噪聲、非高斯分布問題,尚存在識別速度慢、識別準確率低、誤報率高等問題[19].
針對以上提出的問題,本文以傳統的田納西-伊斯曼(TE)化工過程數據作為研究背景,應用二維卷積神經網絡(2D-CNN)方法對TE過程構建故障分類模型,將此模型用于TE過程11個操縱變量的處理.使用卷積神經網絡中的卷積層進行特征提取和池化層進行特征降維學習原樣本數據中高層的抽象特征,再將抽象特征輸入全連接神經網絡分類器,訓練該神經網絡識別不同的故障.經過訓練的模型用在TE化工過程數據中,獲得了以下良好的優勢:(1)因輸入層樣本由多個采樣樣本組成,可以快速采集樣本并將該段時間內采集的樣本批次處理,所以,能夠應用于對實時性要求高的故障檢測領域,實現快速診斷的效果;(2)對訓練的樣本組合式預處理,使得卷積神經網絡模型訓練的時間大幅減少,同時檢測率和誤報率也相應地提升和降低.
1 卷積神經網絡基本原理
1.1 卷積層與池化層前向傳播
卷積神經網絡主要是通過卷積核對局部范圍內的特征進行提取,卷積層中每個神經元連接數據窗的權重是固定的(參數共享),每個神經元只關注一個特征.其中卷積核的滑動使得對全局的局部特征進行整合,以此來獲取整個樣本的信息.卷積核每滑動到一個位置,將對應位置的數據與卷積核對應位置的值相乘并求和,得到一個特征圖矩陣的元素.一般,卷積層為
(1)
其中:l代表層數;K為卷積核;Mj代表輸入層的感受野.每個輸出特征圖都有一個偏置b,卷積核的操作流程如圖1所示.
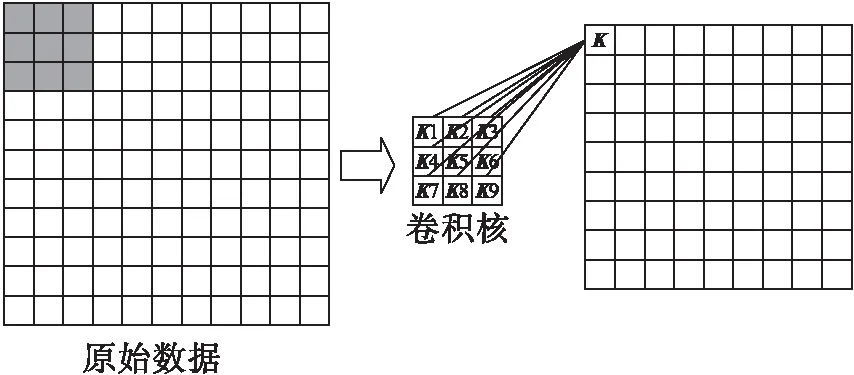
圖1 卷積核操作示意圖
卷積層對原數據進行多個卷積運算產生一組線性激活響應,而非線性激活層是對之前的結果進行了一個非線性的激活響應.卷積神經網絡使用的激活函數一般為修正線性單元(rectified linear unit,RELU),特點是收斂速度快,能夠有效地防止梯度消失的問題.RELU函數的形式如圖2所示,函數
f(x)=max(0,x) .
(2)
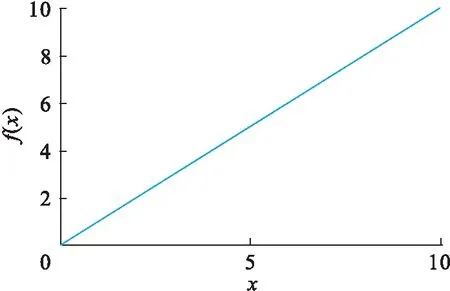
圖2 RELU函數
經過RELU修正后的數據進入池化層,使用步長為n×n的最大池化(max-pooling)選出n×n范圍內的最大特征值作為該池化的輸出.池化層的主要作用就是減少特征圖的尺寸,降低特征維數,同時一定程度上增加網絡模型對特征縮放、扭曲的魯棒性.池化操作的形式為
(3)
其中:MaxPolling(·)為池化函數;?為權重系數.
1.2 全連接層的前向與反向傳播
常用的全連接層神經網絡大多為誤差逆傳播算法訓練的多層前饋神經網絡(back propagation,BP),具有較強的非線性映射能力.常用的全連接層神經網絡結構如圖3所示.

圖3 全連接層神經網絡基本結構
其中全連接層輸入參數為經過卷積神經網絡中池化層降維處理并且拉伸為一維向量的樣本數據.網絡的輸出參數y1,y2,…,ym為網絡分類輸出的概率值;d1,d2,…,dm為樣本中原始數據的標簽值,通過誤差計算層計算出輸出誤差,再反向更新網絡中隱含層與輸出層的權重系數.
全連接層中隱藏層的激活為
(4)
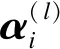
經過不斷重復上式的計算,最終求得網絡的輸出y1,y2,…,ym,利用網絡期望輸出和實際輸出的差值,得出網絡輸出的誤差.常用的誤差函數為均方誤差函數,公式為
(5)
其中:dk為理想輸出;yk為實際輸出;K表示輸出神經元的個數.
全連接網絡的迭代終止于Ek達到預設精度或大于設定的迭代次數,最后通過對誤差函數與全連接神經網絡中的權重關系,使用梯度下降法來獲取最優權值為
(6)
(7)
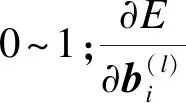
模型完成一整個反向傳播更新權值參數后,將網絡輸出的結果經過sigmoid函數進行二分類.sigmoid函數多用于二分類問題中,它可以將整個實數區間映射到(0,1)區間內,sigmoid函數為
(8)
其中x為上一層神經元輸出的結果.
1.3 卷積層的反向傳播
在一個卷積層中,上一層的特征圖被一個可學習的卷積核進行卷積運算,然后通過激活函數,就得到了輸出特征圖,這個輸出特征圖可能是包含了多個輸入特征圖的卷積輸出,對于卷積層的每一種輸出的特征圖xj有[20-25]
(9)
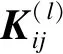
因其第l+1層為池化層,同樣也相當于是做卷積操作.為了求取單個樣本的誤差代價函數對參數的偏導,定義節點靈敏度δ為誤差對輸出的變化率[25-26],即
(10)
式中若采樣的因子是n,只需要簡單地將每個像素水平和垂直向上拷貝n次,就可以恢復原來大小.
因為連接的權值是共享的,因此給定一個權值,需要對所有與該權值有聯系的連接對該點求梯度,然后對這些梯度進行求和,使用(u,v)代表靈敏度矩陣中的元素位置,求得誤差函數對偏置b的偏導與誤差函數對卷積核K的偏導為
(11)
(12)
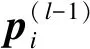
2 基于卷積神經網絡學習模型的故障檢測
卷積神經網絡(convolutional neural network,CNN)是一種常見的深度學習網絡框架,通常是含有卷積層、池化層、全連接層的神經網絡,能夠對高維數據特征進行提取和分類,進而實現數據本質特征的發掘.此前該方法廣泛應用于圖像識別、圖像檢測、語音識別等領域,并取得了很好的效果.
2.1 基于卷積神經網絡高層數據特征的故障檢測步驟
給定原始數據X.
(2) 通過專家經驗對原始數據進行標簽的標注處理;
(3) 提取訓練和測試數據中的標簽樣本;
(4) 將不含標簽的樣本經卷積層操作產生一個特征映射來表明某些特征在輸入樣本中出現的位置;
(5) 將步驟(3)中輸出的特征映射矩陣經過池化層的降維處理,輸出一組低維度的特征矩陣;
(6) 再對步驟(4)輸出的數據經過一組卷積層和池化層的特征提取、降維操作,接著將重構的特征壓縮為一維數據,將其做為全連接層神經網絡的輸入,并通過全連接神經網絡輸出預測結果,最后將預測結果與標簽對比得出誤差,并通過反向傳播算法更新全連接神經網絡和卷積層的權重和偏置;
(7) 使用含標簽的測試樣本對模型進行評估,若訓練誤差與測試誤差均符合設定的要求則保存模型,否則,繼續執行(4)、(5)、(6)步驟,直到滿足要求.
其流程如圖4所示.
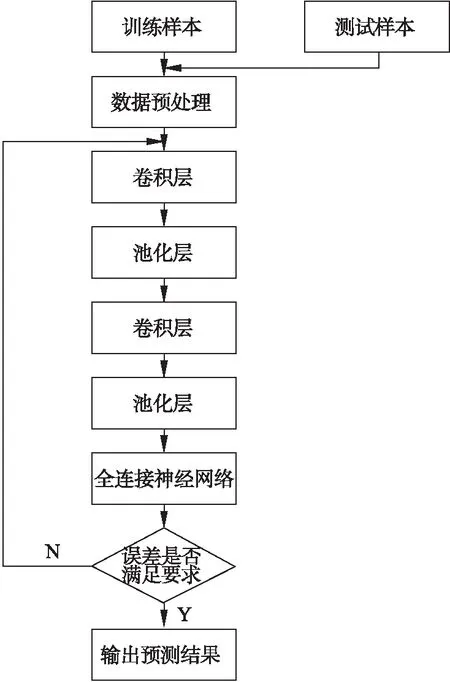
圖4 卷積神經網絡故障檢測流程圖
2.2 卷積神經網絡模型的基本結構
卷積神經網絡模型如圖5所示.根據輸入樣本的大小為11×11的二維數據,考慮其卷積核大小、卷積核移動步數(步長)、卷積核個數、卷積層數與其結果準確率的關系,網絡參數如下:
第一層為卷積層,使用16個4×4大小的卷積核,橫向縱向步長均設置為1時,可得到特征為8×8的特征圖,再經過2×2最大池化,橫向縱向步長設置為1后,輸出的為16個4×4的特征圖.
第二層卷積層使用了16個1×1大小的卷積核,橫縱向步長設置為1,得到16個4×4的特征圖,再經由2×2最大池化,橫縱向步長設置為1后,輸出的為16個2×2的特征圖.
在進入全連接層之前,將16個2×2的數據展開為一維向量,目的是將高維數據降到低維,為全連接層提供特征數據.
最后使用sigmoid函數對神經網絡的輸入進行分類.
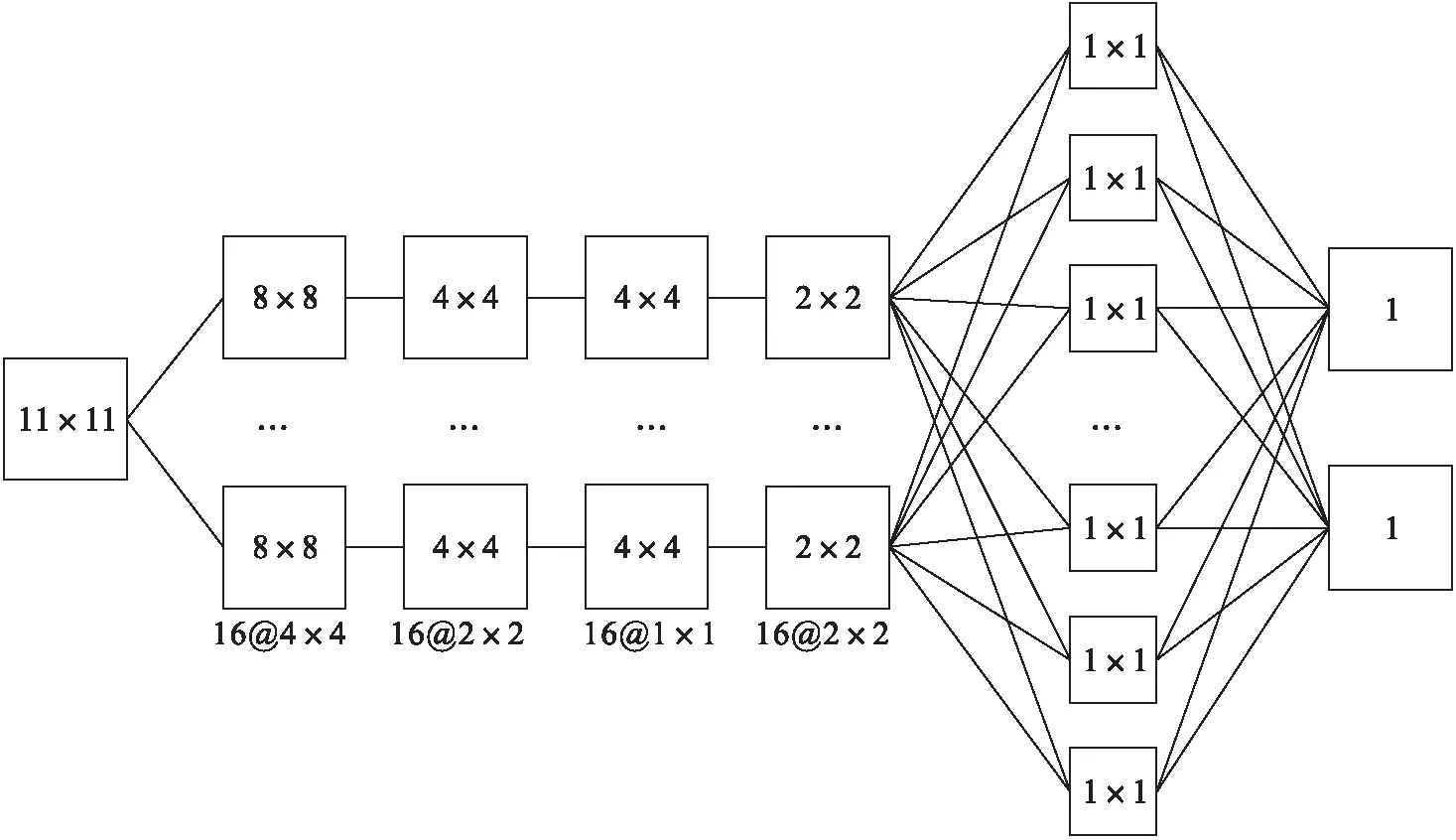
圖5 卷積神經網絡基本結構
3 TE生產過程的仿真研究
3.1 數據采集
數據來自田納西-伊斯曼化學公司某實際化工生產過程提出的一個仿真系統.該流程作為通用測試平臺得到了廣泛的應用.TE工藝有12個操縱變量和41個被測變量,分別位于混合器、反應器、冷凝器、分離器、壓縮機、汽提器等6個主要操作單元中.對TE過程的模擬包括1種正常狀態和21種故障狀態,分別發生在測試數據集的第161個樣本點.
TE過程數據由訓練集和測試集構成.訓練集又分為正常狀態訓練集和故障狀態訓練集.其中正常狀態訓練集由500個樣本點、52個變量組成,構成500×52維度的正常樣本;故障狀態訓練集由各種類型故障的500個樣本點、52個變量組成,構成共計21組500×52維度的故障樣本,每組樣本對應其中一種故障.測試集分為21組包含故障狀態的測試樣本,其中每種故障僅存在于一組測試樣本中.樣本由960個樣本點、52個變量組成,其中測試集前160個樣本點均為正常狀態,故障在第161個樣本點時刻引入,960個樣本點時刻截至,構成960×52包含正常和故障的樣本集.本文只使用了TE過程中最主要的11個操縱變量,這些變量與生產過程的狀態密切相關.
本文中訓練模型使用的數據同樣也由訓練集和測試集構成.訓練集由495×11的正常狀態樣本與495×11的故障狀態樣本組成,構成21組,每組僅包含一種故障的訓練樣本,樣本均從TE過程數據的訓練集中不放回地隨機抽取,再對訓練樣本中的正常和故障樣本標注標簽后構成一個維度為990×12的帶標簽訓練集.測試集由550×11的正常狀態樣本與550×11的故障狀態樣本組成,其中正常狀態樣本由21組故障測試集的前160個正常樣本組成3360×11的正常樣本,再隨機不放回挑去550個樣本點做為測試集中的正常狀態樣本;故障狀態樣本由故障測試集中第161個樣本到960個樣本中隨機不放回抽取的550個樣本所組成;最后對正常狀態樣本和故障狀態樣本標注標簽后構成一個維度為1100×12的帶標簽測試集.
3.2 仿真實驗結果
利用已經搭建好的分類模型對TE過程進行故障評估,再與BP神經網絡的分類準確率、誤報率進行對比.為了保證模型對比的一致,其中BP神經網絡的激活函數、隱藏層數、神經節點數與二維卷積神經網絡參數一致.因二維卷積神經網絡的輸入為二維數據,所以在同一訓練集和測試集情況下,二維卷積神經網絡的訓練和測試樣本數分別為90個和100個,而BP神經網絡是對單樣本進行處理的,所以測試和訓練樣本個數各為990個和1100個.
使用TensorFlow架構來實現化工過程故障檢測模型,因此,可以使用TensorFlow自帶的神經網絡工具箱函數來搭建該模型.為獲得更好的效果,現對2D-CNN神經網絡參數進行優化,表1所示為2D-CNN準確率與學習率和附加動量之間的關系.由表1可知:當學習率為0.01、附加動量為0.9時,模型的準確率高達100 %,且訓練誤差最低.由圖6可以看出:相校于BP神經網絡,2D-CNN具有較小的訓練誤差.

表1 2D-CNN準確率與學習率及附加動量的變化關系

圖6 兩種算法的訓練誤差與迭代次數之間的關系
選取TE過程的故障1、5、8、11、13、14、17來驗證算法的有效性.實驗結果如表2所示.
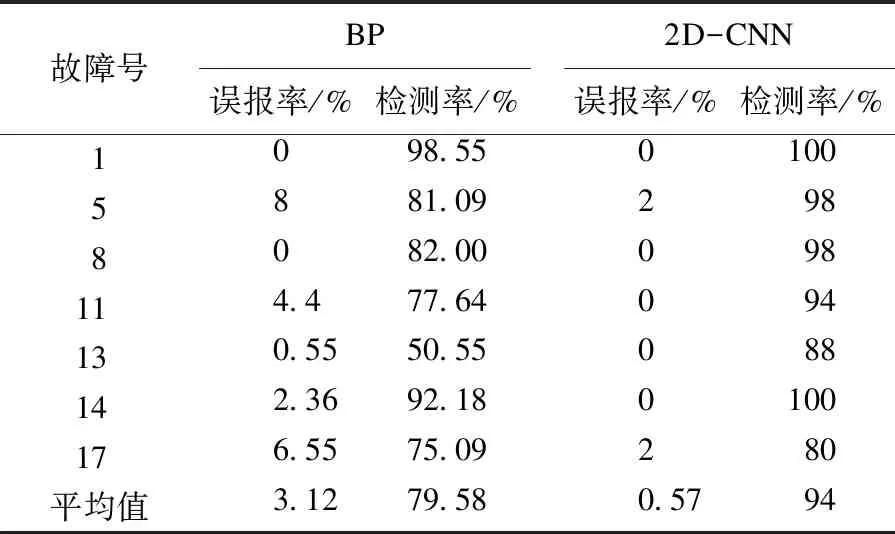
表2 兩種算法的誤報率和檢測率
對于同樣的訓練數據,BP神經網絡和2D-CNN的誤報率和檢測率如表2所示.BP神經網絡采用傳統神經網絡的預處理模式,通過對樣本的不斷迭代學習,輸出分類結果.BP神經網絡對TE過程的7種故障都能較為準確地識別出,而且其誤報率相對較低,但是TE過程為化工連續過程,BP神經網絡只考慮單個樣本中變量之間的關系,而沒有考慮到前一時刻和現在時刻數據之間的特征關系.對比2D-CNN,經過多個樣本之間的特征學習,提取出化工過程連續樣本之間的高層關系,使得檢測率有了明顯增加,特別針對故障11和故障13,2D-CNN的分類準確率分別增加了16.36 %和37.45 %,誤報率降低了4.4 %和0.55 %.對于故障5、8、14、17,2D-CNN的檢測率都明顯優于BP神經網絡,且能夠保證誤報率相對較低.對于故障1,因其故障尺度較大,BP神經網絡和2D-CNN均能較好地分類識別.
選取卷積神經網絡檢測率較高的3種故障(故障5,11,14)進行結果分析,圖7給出了這3種故障的分類結果圖.神經網絡分類結果輸出的為概率結果,設定類別概率值大于0.5就分為對應類別,其中正常樣本標簽為1,故障樣本標簽為2.
對于所選的3個故障,在檢測出故障后,此后的故障都能被良好地識別出來,達到了較高的檢測率.針對故障5和11,由圖b和d可知:BP神經網絡的故障分類從第557個樣本開始才正確檢測出來,而后的過程中仍有大量故障沒有檢測出來,而錯誤的將其分為正常類.由圖a和c可知:2D-CNN的故障分類從故障一開始的第一時刻就已經正確識別出來,此后的所有故障都被正確地檢測出來,僅故障11的故障樣本有兩處分類錯誤.而針對故障14,由圖e和f可知:BP神經網絡在故障發生后第555個樣本才開始檢測出故障,且正常樣本中存在大量誤報樣本,故障樣本中也同時存在分類錯誤的樣本;而2D-CNN在故障發生的第一時刻就檢測出來,同時正常樣本中和故障樣本中均無錯誤分類的樣本存在.

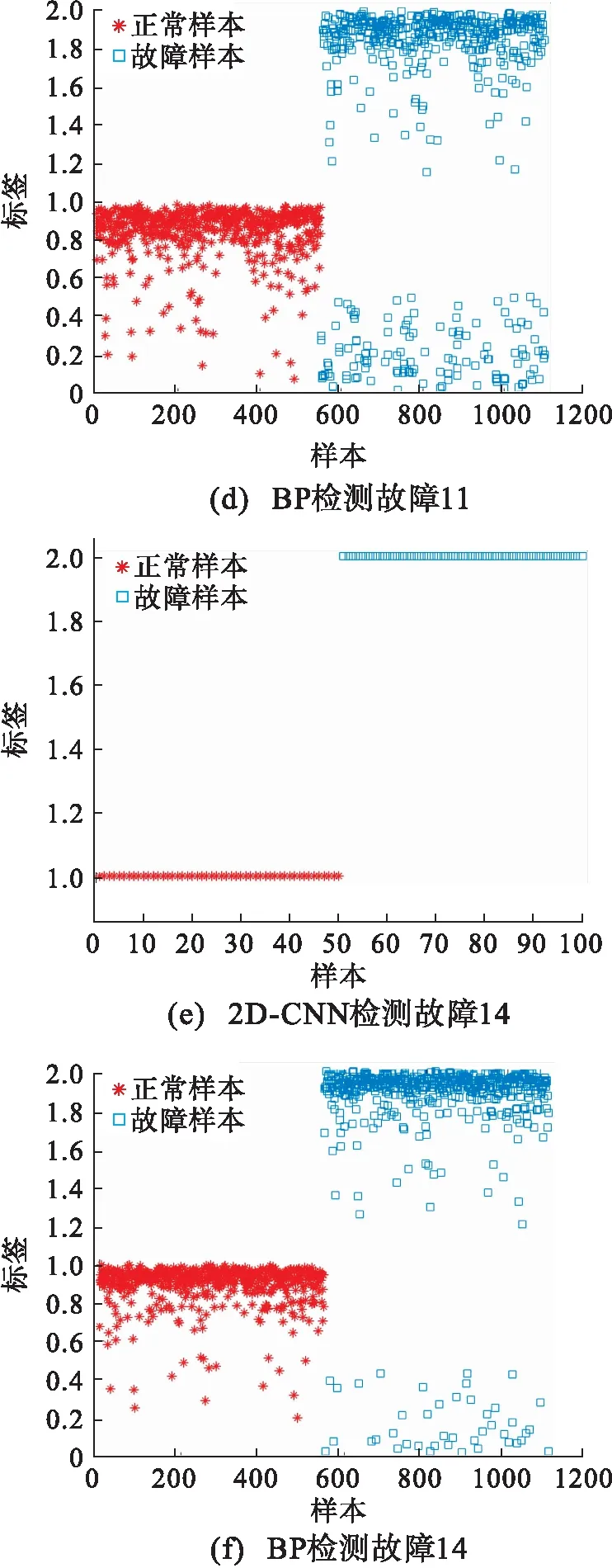
圖7 2D-CNN與BP神經網絡的分類分析結果
4 結 論
提出使用二維卷積神經網絡(2D-CNN)找到TE化工過程數據故障各自對應的高層特征,通過卷積、池化、反向傳播等操作實現數據的特征學習、特征重構,并且使用不同的神經網絡方法進行對比,得到以下結論:卷積層的輸入需要大量樣本,使用卷積神經網絡能夠實現實時的樣本采樣和檢測,使得該神經網絡模型可以很好地使用在實時的故障檢測系統中;卷積核在樣本數據中的滑動能夠很好地尋找到不同時刻樣本與樣本之間、變量與變量之間的潛在特征關系,得到最能反映原始數據中特征的隱藏變量.TE應用結果表明,二維卷積神經網絡相較于BP神經網絡,其檢測率得到提高,同時誤報率相對較低,很好地驗證了該算法的有效性.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年6期)2015-04-17 03:31:50
