改進的野草入侵算法在模塊劃分中的應用研究
2021-11-22 11:09:54趙躍,單泉,陳硯,孔芝
機械設計與制造 2021年11期
關鍵詞:設計
趙 躍,單 泉,陳 硯,孔 芝
(東北大學秦皇島分校控制工程學院,河北 秦皇島 066004)
1 引言
模塊化設計是指在對產品進行市場預測、功能分析的基礎上,綜合考慮產品對象,劃分并設計出一系列的功能模塊;然后根據用戶的要求,對模塊進行選擇和組合,迅速組合成不同功能、或功能相同但性能不同、規格不同產品的一種設計方法。
當前新一輪科技革命主導的新一輪工業革命正在到來,這也正是中國從制造大國走向制造強國的歷史性機遇。模塊化設計可以有效支持創新,符合創新驅動的發展戰略。通過使用模塊化設計,能夠有效降低產品開發設計復雜性、縮短產品開發周期、有效支持企業間的協同創新設計、支持客戶參與產品開發設計[1]。
模塊劃分是模塊化技術中的基石,模塊劃分方法根據形式可分為傳統模塊劃分方法和基于智能優化算法的模塊劃分方法。文獻[2-4]基于模糊聚類的方法對相應產品進行了模塊劃分工作,取得一定的成果。然而模糊聚類方法在閾值的確定上往往需要反復嘗試,工作量較大,且對于組件數量較多的模塊劃分問題,矩陣的變換分割也較為復雜。
因此,隨著計算機技術的發展,基于智能優化算法的模塊劃分方法也得到了長足的發展。遺傳算法被文獻[5-6]等廣泛應用于模塊劃分工作;文獻[7-8]等在此基礎上,將遺傳算法與模擬退火算法融合,使原算法性能加以提高;文獻[9-10]等將免疫算法進行改進用于模塊劃分;離散粒子群算法也被文獻[11]等引入該領域;文獻[12]采用貓群算法進行軟硬件的劃分,也取得了較好的效果。然而現階段基于智能優化算法的模塊劃分方法的發展對模擬退火算法、遺傳算法、免疫算法、粒子群算法等成熟算法的依賴性較大,且以上算法在迭代精度、速度上存在一定的瓶頸,一些新算法仍有待于引入模塊劃分工作中。將野草入侵算法加以改進引入模塊劃分中,為模塊劃分算法的設計與實現提供了一種全新的思路,對模塊化設計將起到一定的推動作用。
2 算法簡介
野草入侵算法是一種基于種群的無衍生優化算法,其靈感來自田間雜草的殖民化。該算法具有入侵性、穩健性以及適應環境變化等特性[13]。
野草入侵算法有四個主要步驟:初始化、繁殖、空間分布和競爭排斥。在初始化步驟中,在搜索域隨機生成一定量的個體,組成初始種群;繁殖個體,每個個體根據其適應度值產生種子數量。第三步,使用高斯分布在搜索空間上分布生成的種子,由于新生種子數量與個體的適應度有關,因此使用高斯函數完成空間分布能夠有效提高空間搜索的效率;由于繁殖過程,其種群大小在每次迭代時都會增加,因此算法的最后一步是競爭排斥,通過從群體中移除最差的個體來限制最大允許群體大小至規定值,從而控制群體大小。
與傳統遺傳算法相比,野草入侵算法不需要交叉變異等操作,因此其操作簡潔,計算效率高,運行時間短。但其新生個體的策略導致了算法由全局搜索逐步轉變為局部搜索,使其全局搜索能力不強,易于陷入局部最優。此外,該算法的隨機搜索特性對其收斂速度也存在著一定的影響。
3 改進的野草入侵算法在模塊劃分中的應用
野草入侵算法創立之初,是為了解決多元函數的最小值求解問題。與多元函數極值問題不同,組合問題中解空間的各個維度并不存在最優值,且存在著相互關聯,其最優解決定于分組情況。將該算法應用于模塊劃分中,需要對算法做出適當的修改,以滿足其約束條件以及使用要求。
首先,模塊的組成需要滿足以下兩個約束條件:任意模塊之間不能含有相同的元素;所有模塊的集合構成待劃分元素庫的整體。針對以上條件,對該算法中各個部分加以修改,修改后應用于模塊劃分的野草入侵算法流程,如圖1所示。
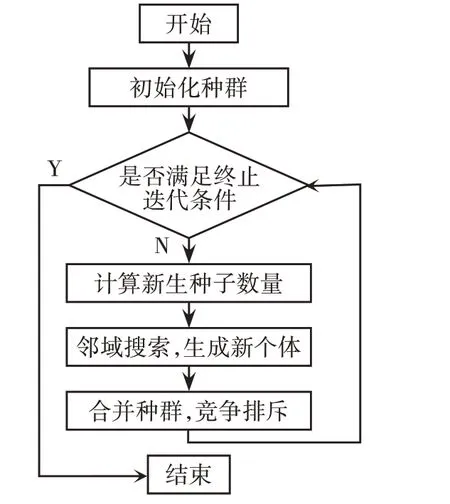
圖1 應用于模塊劃分的改進野草入侵算法流程Fig.1 Flow of Improved Weed Invasion Algorithm Applied to Module Partitioning
以求取適應度函數最大值時的分組方式為例,采用MATLAB進行程序編寫具體步驟如下:
(一)初始化種群,隨機生成N0個模塊劃分的形式,針對每個個體,其模塊劃分結果將是相互獨立的。由經驗公式,模塊劃分中默認模塊數目的最大整數)。根據確定的模塊數量求取方式,確定模塊數量,將n個代表元素代碼的數字隨機存入代表模塊的元胞(cell)中,并確保每個元胞中均存在元素。通過該方法完成模塊劃分,并分別求出每個個體對應的適應度函數值,完成種群初始化的工作。
(二)根據適應度函數值對種群從大到小進行排序,并記錄每次迭代的最大值與最小值。
(三)結合所記錄的最大值與最小值,計算每種分組方式對應的新種子個數。使用如下的式(1)用于新種子個數的求解。
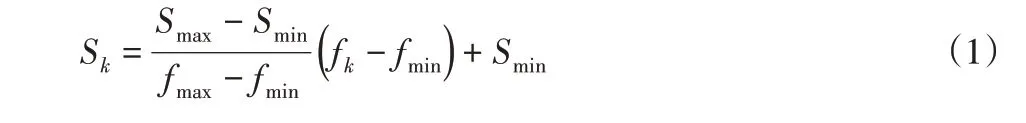
(四)對原算法進行改進,根據求得的新生種子數量,對選定的個體進行鄰域的搜索,以替代在一定范圍內隨機生成新種子的操作。即選取任意模塊中任意組件,將該組件放入任意其他模塊中,完成模塊的重新生成,并重新求解在該分組情況下的適應度函數值。需要指明一點,為了使重組后的模塊劃分不存在空模塊的情況,被選中遷出組件的模塊原組件數必須大于1。
(五)將原始種群與新生個體進行合并,組成新的種群,之后按照適應度函數值從大到小對新種群進行排序。由于新個體的加入,每次迭代種群中個體數量都會有所增加,因此通過從群體中移除最差的個體(即排名末位的個體)來將種群中個體數量減小至Nmax,從而達到競爭排斥的效果。
(六)當滿足迭代終止條件時,退出迭代,輸出最大的適應度函數值以及與之相對應的最佳模塊劃分方式。
保留原算法中新生種子個數的計算方式,使新生種子對原有種群優良性狀的繼承性得到增強,且提升算法對最優解的探索效率。同時,借鑒鄰域搜索操作,代替野草入侵算法中的以正態分布隨機生成種子的方法,增強算法的全局搜索能力,能夠彌補其在全局收斂上表現較差的情況,改善其容易陷入局部最優值的問題,增強該算法的穩健性,確保算法在每次優化過程中均能收斂到其全局最優的模塊劃分方案上。
同時選用野草入侵算法中的競爭排斥機制進行較差個體剔除的工作,減少算法迭代中的計算量,保持算法簡潔易于操作的特性,提高程序的運行速度,保證了算法迭代的高效性,并能夠有效解決陷入局部最優值的問題。與此同時,另一個重要改進在于在算法中進一步刪除種群變異、隨機生成新生種子等操作,進一步簡化算法,從而能夠保證算法收斂的速度與準確性。
4 實例驗證
為了驗證本方法的正確性且不失一般性,分別以文獻[15]中24個元件的直齒輪減速器以及文獻[16]中24個元件的錐齒輪三級減速器作為實例1與實例2進行驗證。適應度函數值由式(2)給出。實例1的最優適應度函數值是0.32749,其最優模塊劃分結果是{1,2,9,10,19}、{3,4,11,12,13,20,23}、{5,6,14,15,16,21,24}和{7,8,17,18,22};實例2最優適應度函數值是0.4399,其最優模塊劃分結果是{1,5,17,18,19}、{2,6,9,11,14,20,23}、{3,7,10,12,15,21,24}和{4,8,13,16,22}。
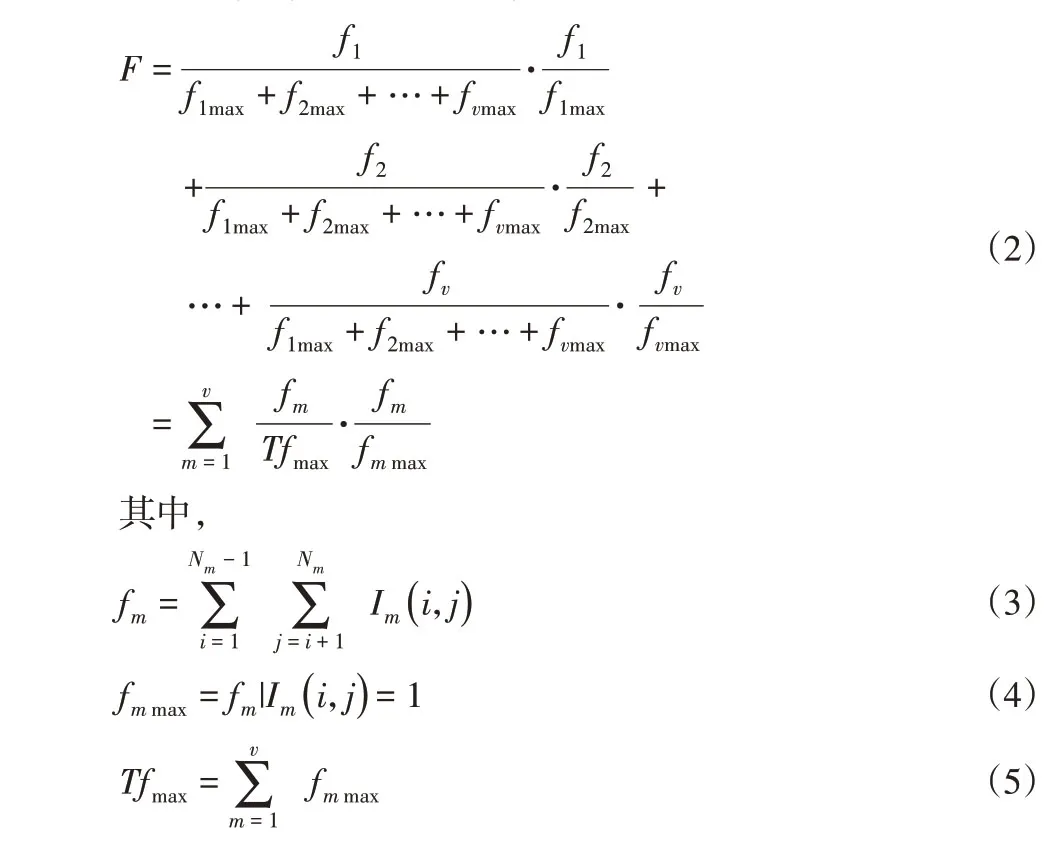
其中,Im(i,j)—第i個組件與第j個組件之間的相關度,即設計結構矩陣中第i行第j列元素的取值。
設定模塊數量為4,設定其初始種群數量為50,最大迭代次數500,最大種子最大值為4,最小值為0,實例1使用改進的野草入侵算法進行模塊劃分,當迭代到第37 次時,適應度函數值收斂,得到適應度函數的最優值0.32749,模塊劃分結果與文獻[15]相同;實例2使用改進的野草入侵算法進行模塊劃分,當迭代到第31次時,適應度函數值收斂,得到適應度函數的最優值0.4399,模塊劃分結果與文獻[16]相同。證明應用于模塊劃分的改進的野草入侵算法是一種有效的模塊劃分算法。
為了進行對比,加入標準野草入侵算法、粒子群算法、遺傳算法、免疫算法進行相同的分組。設置各個算法初始種群數量均為50,最大迭代次數500。野草入侵算法的最大種子最大值為4,最小值為0;粒子群算法的位置最大最小值為4和1(位置最大值代表模塊個數),速度最大值為2;遺傳算法的變異概率為0.2,交叉概率為0.6,選擇精英個數為10;免疫算法的克隆親本個數為10,克隆數量為5,突變概率為0.5。分別得到最優模塊劃分結果,優化曲線,如圖2所示。其中上半部分為實例1的優化曲線,下半部分為實例2的優化曲線。

圖2 五種算法的優化結果對比圖Fig.2 Comparison of Optimization Results of Five Algorithms
由圖可知,在兩個實例中,改進的野草入侵算法均達到最快的收斂。為了不失一般性,將以上各個算法重復運行50次,對運行時間、最快收斂代數、最慢收斂代數、平均收斂代數,收斂代數的標準差幾個參數進行考察,如表1所示。

表1 五種算法結果對比Tab.1 Comparison of the Results of the Five Algorithms
由以上兩個實例可知,改進的野草入侵算法與其他算法相比,性能提升較為明顯,且在運行速度和收斂速度上均大幅優于其他四種算法,且收斂代數的標準差最小,說明了該算法較強的魯棒性。由此可知應用于模塊劃分領域的改進的野草入侵算法是一種高效且準確可靠的算法。
5 模塊劃分軟件系統的編寫
基于以上結果,參考設計人員的工作習慣,并提高模塊劃分的效率,增加算法整體的可移植性,采用Python3.7開發人機交互的最優模塊劃分結果求取的軟件系統,其主界面,如圖3所示。

圖3 模塊劃分系統主界面圖Fig.3 Main Interface Diagram of the Module Partitioning System
其后臺迭代程序仍采用如圖1的算法流程進行編寫,在此基礎上對迭代過程中的適應度函數加以改進,采用如下公式進行迭代計算。
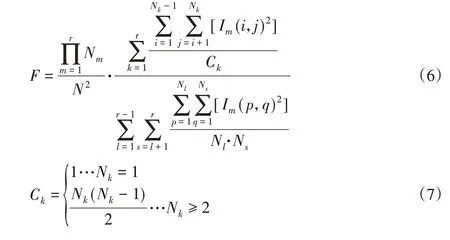
與式(2)類似,其中,N—組件數量之和;Nm—第m個模塊的組件數量;r—模塊數;Im(i,j)—整體結構設計矩陣中第i行j列元素;Ck—模塊內得組合數。
式(6)中第一項可作為各個模塊中組件數量相似性的度量,即可對模塊劃分結果中各個模塊中組件數量的平均程度加以保障;第二項中的分子與分母分別為內聚度和耦合度的表征。因此當模塊劃分結果呈現出“高內聚、低耦合”特性,且各模塊中組件數量近似相等時,適應度函數取得最大值。
應用本軟件系統,用戶可以完成的主要功能有:用戶輸入結構設計矩陣的保存、已存在結構設計矩陣的讀取、最優組合結果的輸出、迭代過程的顯示與儲存。仍采用文獻[15]中的實例對該軟件系統的使用過程進行說明,使用過程如下:
首先,用戶在組件數量對話框中輸入組件數量24,點擊右側“創建結構設計矩陣”按鈕,在界面中按照順序輸入各個組件之間的相關度,完成結構設計矩陣的建立,點擊“保存”,將結構設計矩陣保存為Excel表格文件,如圖4所示。
圖4 創建結構設計矩陣頂級窗口Fig.4 The Top-level Window for Creating the Design Structure Matrix
之后,點擊“請選擇結構設計矩陣”后的“點擊選擇”按鈕完成文件的讀取的工作,此時文件所對應的路徑便會顯示在右側的文本框中。之后,通過復選按鈕確定參與計算的結構設計矩陣,并對其設定相應的權重值。最后,通過右側三個單選按鈕對結果的顯示與保存方式進行選擇,即可完成最佳分組情況計算前的準備工作。準備工作結束后,點擊開始迭代按鈕,迭代過程與分組結果即顯示在文本框中,如圖5所示。此時根據輸出結果顯示,計算后的最佳分組是{1,2,9,10,19}、{3,4,11,12,13,20,23}、{5,6,14,15,16,21,24}和{7,8,17,18,22},與文獻[15]中結果相同,證明本軟件系統在模塊劃分中的真實可靠性。

圖5 迭代過程與模塊劃分結果的顯示Fig.5 Iterative Process and Display of Module Partitioning Results
本軟件基于模塊劃分的步驟,使設計人員通過創建、選取加載結構設計矩陣并設置相應的權重等過程,求得最佳分組結果及其所對應的適應度函數值,并可以根據用戶的需求顯示并保存所需結果。軟件整體使用流程符合設計人員的設計習慣,能夠有效提高設計人員的設計效率,減少重復性勞動,對模塊化設計起到較大的促進作用。
6 結束語
將野草入侵算法加以改進應用于模塊劃分中,改變原算法中新生個體的操作,并刪除種群變異、隨機生成新生種子等操作,使程序編碼簡潔,算法易于實現,且新算法兼顧收斂速度與準確性兩個重點,與原算法相比在性能上有較大的提升。并通過實例驗證,證明了該算法的可行性,為模塊劃分算法的設計提供了一種新的思路。并且將該算法與粒子群算法、遺傳算法、免疫算法進行比對,證明了該算法在模塊劃分中的高效性。并基于該算法,開發出模塊劃分軟件系統,以提高設計人員的設計效率,減少重復性勞動,促進模塊化設計的發展。
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
