基于CUDA架構下的直方圖均衡并行算法
2021-12-06 03:24:16肖詩洋孫陸鵬郭寶云
桂林理工大學學報 2021年3期
肖 漢, 肖詩洋, 孫陸鵬, 郭寶云
(1.鄭州師范學院 信息科學與技術學院, 鄭州 450044; 2.東北林業大學 土木工程學院, 哈爾濱 150040;3.山東理工大學 建筑工程學院, 山東 淄博 255000)
0 引 言
在圖像的采集、傳輸和處理等過程中, 經常受到外部噪聲和光照不均勻等各種環境影響, 圖像質量會嚴重降低, 有必要對圖像進行增強處理[1]。圖像直方圖是圖像處理中一種十分重要的圖像增強工具, 在軍事、航空、商業等領域有廣泛的應用。該算法的理論基礎是概率統計, 通過對圖像中像素點值的計算對圖像直方圖進行變換, 從而達到圖像增強的目的[2]。圖像增強往往要求做到實時、快速,而面對海量圖像數據、算法復雜度不斷增加, 圖像增強的高效快速處理面臨著新的挑戰[3]。
對于提高圖像對比度和直方圖均衡算法的性能, 引發了很多學者的關注和研究。為了提高水下圖像對比度, Wong等[4]提出了一種采用并行結構的的差分灰度直方圖均衡算法。為了在平均亮度保持和對比度增強之間取得折衷, Khan等[5]采用自適應直方圖均衡增強血管和背景之間的差異性;陳松等[6]提出了基于數字信號處理器(digital signal processor, DSP)的圖像直方圖均衡算法的優化方法, 執行效率提升了6.02倍;齊建玲等[7]利用FPGA的并行處理能力, 對直方圖均衡算法進行優化設計, 將處理速度提升1倍;占正峰等[8]提出了基于GPU的直方圖均衡化并行算法,充分利用GPU的并行處理能力, 獲得了24.96倍加速比;Mahmud等[9]利用OpenCL并行計算方式實現了直方圖均衡并行算法, 大大減少了系統消耗的時間。
近年來, 隨著制程工藝和集成技術的發展, 圖形處理器(graphic processing unit, GPU)的計算能力越來越強大。CPU+GPU的計算模式是由CPU負責執行復雜的邏輯處理和事務處理等不適合數據并行的任務, 由GPU負責進行密集型大規模數據并行計算[10-11]。統一計算設備架構(compute unified device architecture, CUDA)是NVIDIA公司于2007年提出,用于GPU計算的新的軟硬件架構, GPU在架構中被視為一個數據并行計算設備, 對要處理的計算任務進行分配和管理[12]。
本文利用CUDA來解決在異構計算設備上進行大規模圖像的直方圖均衡處理問題, 提出了一種基于CUDA架構的高效直方圖均衡并行算法, 在保持其串行算法精度的同時, 取得了61.58倍的加速效果。
1 算法的軟件模型
1.1 CUDA異構編程模型
CUDA是一種新的基礎異構架構, 該架構可以使用GPU來解決工業、商業以及科技方面的復雜計算問題。它是一種完整的圖形處理器通用計算(general-purpose computing on GPU, GPGPU)的解決方案, 提供了硬件的直接訪問API, 而不必像傳統方式一樣須依賴圖形用戶接口來實現GPU的訪問。在架構上采用了一種新的計算體系結構來利用GPU提供的硬件資源, 從而給大規模的科學計算應用提供了一種比CPU更為強大的計算能力。CUDA采用C語言作為編程語言以提供大量的高性能計算指令, 使開發者能夠以GPU的強大計算能力為基礎, 建立起一種更高效率的密集數據計算解決方案。由于科學計算應用具有較高的計算密度, 因而, GPU可通過計算隱藏存儲器訪問延遲, 而不必使用較大的緩存器。用大規模并行處理器和CUDA C擴展語言進行通用計算的工作, 這種新的GPU編程模式就是“GPU計算”。
1.2 算法原型
直方圖均衡化是以概率累積函數變換法作為基礎, 將已知圖像的概率分布轉變為均勻概率分布, 從而獲得一幅視覺增強后質量較好的圖像。經過直方圖均衡化處理, 可使原圖像的灰度分布轉換為一種均勻分布方式, 使圖像的細節更容易辨識。設pr(r)表示待處理圖像的概率密度函數,ps(s)表示經過直方圖均衡化后的圖像概率密度函數, 圖像總灰度級數為L, 由概率理論可得
ps(s)=pr(r)|dr/ds|,
(1)
由式(1)得到ps(s)中變量s的表達式為
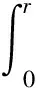
(2)
由萊布尼茨準則可知,

=(L-1)pr(r),
(3)
把式(3)代入式(1), 得到
(4)
在圖像處理中, 當圖像像幅大小為M×N時, 其直方圖可表示為
(5)
且pr(rk)滿足
(6)
其中:pr(rk)表示圖像中灰度級為rk的分布概率;nk表示灰度級為rk的像素個數,即對灰度級為rk的投票;MN表示像素總數。
直方圖均衡化處理就是通過某種函數映射, 將原圖像的灰度級分布從集中轉變為均勻。設T為映射算子, 則有
s=T(r),
(7)
式(7)滿足s在0≤r≤1內單調遞增, 且0≤s≤1。直方圖均衡化后的概率密度函數ps(sk)是一種均勻概率密度函數。所以, 圖像經過映射算子的作用, 進行直方圖均衡化操作后, 直方圖信息將顯示出均勻性。累計分布函數的表達為
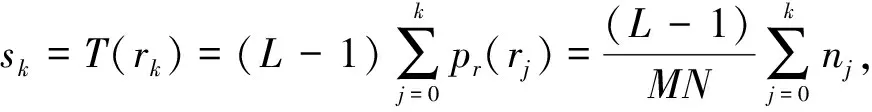
k∈[0,L-1],
(8)
取整擴展
sk=int(sk+0.5)。
(9)
1.3 程序性能瓶頸剖析
根據測試方法, 為保證測試時間更加準確, 實驗的測試結果取100次運行結果的平均值并記錄。為了確保測試數據真實可靠, 實驗時保證本輪測試具有獨占性。在取得算法各步驟的運行時間及整個算法的執行時間之后, 計算得到直方圖均衡算法中各主要步驟耗時在整個算法中所占比例, 具體數據如表1所示。
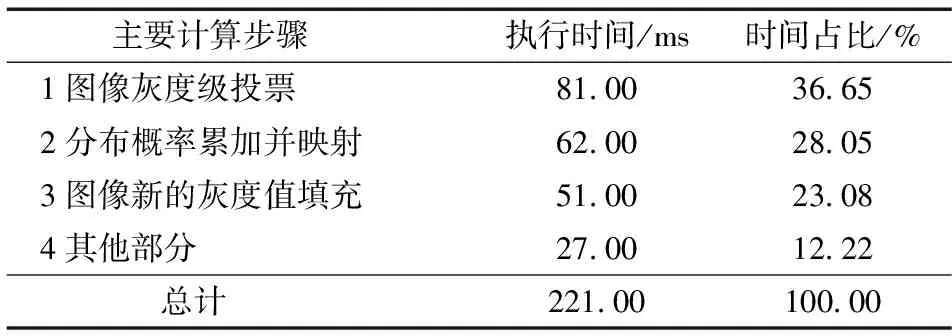
表1 算法各步驟運行時間占比
可見, 直方圖均衡算法耗時主要集中在步驟1, 其次是步驟2和3。以3 268×3 689圖像像幅大小為例, 這3個步驟的運行時間在串行算法總執行時間中所占比例為87.78%, 其他步驟處理時間只占算法總運行時間的12.22%, 說明步驟1~3是串行算法的性能瓶頸所在。如果采取一定并行措施能夠大幅降低直方圖均衡算法的處理時間, 就可以獲得良好的加速效果。
1.4 并行化可行性分析
直方圖均衡算法的熱點主要包含3部分: 統計圖像中每個灰度級上的像素數量、計算圖像中每個灰度級的分布概率并進行累加映射, 以及像素點灰度值映射結果的填充。通過分析發現: ① 每個灰度級上的像素數量的統計計算可相互獨立進行, 存在一定的并行性, 但由于圖像灰度級L?M×N, 可采用原子操作方法和同步機制解決當多線程同時將統計結果寫至直方圖數組時導致的訪存沖突問題。這是直方圖均衡算法中計算量最大的部分, 如果對其進行并行化, 會極大地提高算法的運算速度。② 在L個灰度級上進行的操作具有較強的并行性: 分配一個線程進行某個灰度級分布概率的計算, 根據灰度級所在的等級進行前綴和式的概率值求和, 并依據映射規則完成灰度值的映射。③ 遍歷圖像像素點用新的灰度映射值填充相應像素點: 可以設計合適的數據結構, 通過CUDA并行設計方法對其進行并行化。經分析可知, 圖像灰度值數量統計、分布概率累加并映射和圖像新的灰度值填充3部分都可以并行化。
2 直方圖均衡算法的CUDA實現
2.1 并行算法描述
根據CUDA計算架構的特點, 設在單指令多線程(single instruction multiple thread, SIMT)模型中啟動M×N個線程, 每一個線程只負責處理一個像素的轉換, 然后把結果存儲到對應的位置。整體的并行化思路如下。

算法 SIMT模型上的直方圖均衡并行算法輸入: 圖像像素矩陣srcImageData輸出: 均衡化后圖像像素矩陣desImageDataBegin In CPU: Input image array srcImageData In GPU:forj=0 to (M×N-1) par-do t ← srcImageData(tid) Add grayscale value t to the corresponding grayscale level counter end for for i=0 to(L-1) par-do Calculate probability density function of gray level Calculate the prefix sum of the probability density function of gray level Calculate grayscale mapping end for for j=0 to (M×N-1) par-do t ← srcImageData(tid) Update the mapped grayscale value corresponding to the grayscale value t to the corresponding pixel end for In CPU: Output equalized image array desImageDataEnd
假設圖像像幅為M×N, 如果用CPU實現直方圖均衡串行算法, 則是通過遍歷整個圖像像素數據進行計算, 因此, 算法時間復雜度是Ο(M×N)。采用GPU的多線程對直方圖均衡算法進行并行計算, 一個線程負責處理一個像素點。因此, 運算時間將減少到Ο(1), 這是一個恒定的等級。核函數中處理所有的像素點如果沒有并行執行, 則每個線程執行直方圖均衡內核函數最少(M×N)/ST次, 其中ST是線程的數量。此時, 時間復雜度將為Ο((M×N)/ST)。然而, GPU中可以保持的活動線程量很大, 即ST總是一個很大的量值。所以, 存在直方圖均衡并行算法時間復雜度Ο((M×N)/ST)?Ο(M×N)。
2.2 方法設計
圖1具體說明了基于CUDA架構的直方圖均衡化算法的過程。主機端首先獲取輸入圖像的參數, 同時對GPU設備進行初始化, 包括設備的選擇和設置。隨后, 主機申請圖像數據、圖像均衡數據、圖像各灰度級概率統計和圖像各灰度級映射需要的信息存儲空間, 將圖像數據由主機端內存拷貝到設備端的全局存儲器。在GPU中完成數據的網格處理任務。在設備端通過獲取CUDA二維線程索引, 并根據灰度級投票、灰度級概率密度函數和灰度級映射的運算任務, 計算出當前線程對應的數據地址。讓每個線程塊執行一個子圖像塊, 進行一個子直方圖均衡化轉換, 接著合并每個線程塊的子直方圖均衡轉換結果, 得出總的直方圖均衡化結果。將設備端完成運算任務后的圖像均衡化結果傳輸到主機端內存, 主機完成最終的圖像均衡結果的顯示。

圖1 直方圖均衡并行算法流程圖
2.3 并行計算方法
2.3.1 核函數并行維度的設計 根據按行連續排列存儲圖像數據的特點和CUDA網格模型的特點, 對內核計算的圖像處理任務進行粗粒度和細粒度的劃分。以子圖像塊作為劃分依據, 將圖像劃分為互不重疊的格網區域, 實行粗粒度的并行,再在各子圖像塊中按照像素為單位再行劃分, 實行細粒度的并行。
內核計算任務并行劃分見圖2。一個Kernel對應一個線程塊網格, CUDA中的Kernel是以線程塊網格(Grid)的形式組織。Grid包含若干個線程塊(Block), Block又包含若干個線程(Thread)。直方圖均衡內核任務劃分映射到上述線程模型: 整幅圖像映射到Grid上, 一個子圖像塊映射到一個Block, 子圖像塊中的像素點映射到Block中的Thread。
一是土壤結構改變問題。果農在栽培管理過程中化肥施用過量,有機肥施用量少,沒有重視微量元素微肥,造成土壤肥力下降,土壤中各種元素失衡;二是大面積無限制的使用化學農藥防治病蟲害和過量使用生長調節劑,殘留物對環境造成了污染;三是廢棄物處理問題。不易降解的農用地膜、套袋薄膜、農藥化肥包裝袋及其它田間廢棄物不經任何處理就隨意丟棄在道路旁、江河里,臭氣熏天、蚊蠅滋生,造成大面積環境污染[2]。
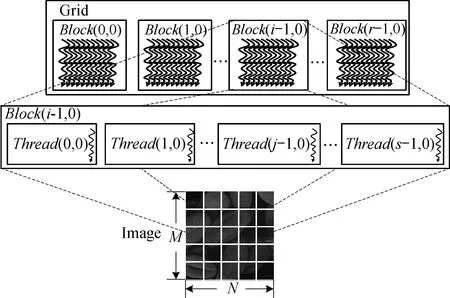
圖2 直方圖均衡內核任務并行劃分示意圖
線程和線程塊的劃分對并行算法的效率影響很大。CUDA中主要通過分配線程塊和線程來實現直方圖均衡并行計算, 具體用粗粒度并行和細粒度并行劃分線程和線程塊。
① 粗粒度并行。在圖像直方圖均衡并行處理時, 將一幅圖像分成一系列子圖像塊, GPU線程網格由二維線程塊網格組成。每一個線程塊可以獨立處理相應的子圖像塊。具體分配線程時采用二維線程塊網格進行線程劃分。假設M、N分別是圖像的高和寬, 每個線程塊能夠分配nTX×nTY個線程, 則需要分配BX×BY個線程塊, 其中BX=(M+nTX-1)/nTX,BY=(N+nTY-1)/nTY, 在GPU內核函數配置時, 進行線程塊和線程分配, 即
Dim3Threads(nTX,nTY)
Dim3Blocks(BX,BY)
② 細粒度并行。圖像中每個像素點數據的計算都是獨立的, 只要在并行運算平臺CUDA中為每個像素點分配一個線程, 每個線程并行地根據式(1)和式(4)即可計算完數據項。實現并行計算數據項需要進行線程與像素點映射, 即
tidx=threadIdx.x+blockIdx.x×blockDim.x
tidy=threadIdx.y+blockIdx.y×blockDim.y
其中,threadIdx.x和threadIdx.y為某個線程塊中的線程分別在X和Y方向的索引,blockIdx.x和blockIdx.y為某個線程塊在網格中的X和Y方向的索引,blockDim.x=BX,blockDim.y=BY。這樣, 每一個線程均對應一個像素點, 同時計算每個像素點的數據項。
2.3.2 灰度級投票的并行設計 通過對各像素投票值累加可獲得每個灰度級的最終投票值。而配屬線程內部的寄存器在網格內的線程間不可見, 無法通過計數器完成投票的累加操作。此時就需要一種操作, 既可以保證各線程之間的計算互相獨立, 又可確保將最后的統計結果進行累加。鑒于GPU中每個線程訪問同一個全局存儲器地址時, 在計算能力為1.2以上的設備中, half-warp塊所請求的具有4 B數據字的同一地址的模式都會實現合并訪問。因此, 可以采用全局存儲器來進行投票累加數據的存取, 用來完成每個灰度級的累加, 且可以保證線程之間計算的獨立性,如圖3所示。
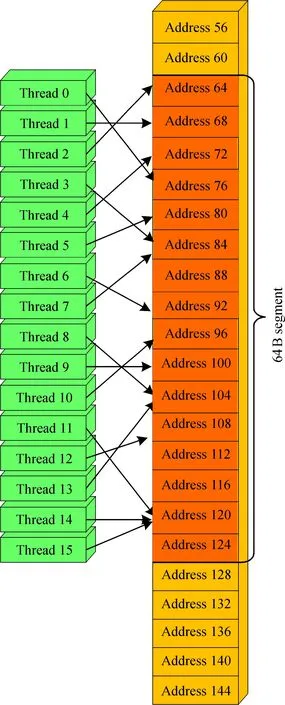
圖3 在一個64 B的分區內的隨機float存儲器訪問, 得到一個存儲器事務
但是全局存儲器的使用會帶來未合并訪問的問題。如果在half-warp中有部分線程對存儲器地址的訪問出現了交錯或起始地址未對齊, 就會造成未合并訪問。投票過程中一旦出現未合并訪問情況, 會致使全局存儲器訪問效率降低, 算法運行的速度將遭受嚴重影響。為了克服這個問題, 采用原子加機制來執行投票累加的過程。在CUDA中開辟L個全局存儲器存儲空間, 每個存儲空間負責一個灰度級的統計。線程網格內開啟BX×BY×nTX×nTY個線程, 每個線程根據自己對應像素點位置上灰度值進行投票。采用CUDA內部的原子加操作統計, 在類別數組上取數據并執行加法操作。同步線程塊內線程, 得到最終投票數組。原子加操作可保證在某個線程對某個灰度級進行累加的操作過程中, 不會被線程調度機制打斷。也就是說,當多個線程同時訪問灰度級數據的同一位置時, 保證每個線程能夠實現對共享可寫全局存儲器數據的互斥操作。在整個投票累加器工作期間都不會切換到另外的線程, 意味著投票過程是串行執行。在一個線程執行對某個存儲器地址的累加運算后, 其他的線程才能再執行對該存儲器地址的累加操作,于是便解決了未合并訪問的問題。
2.4 性能優化
不同線程塊的布局對于存儲器訪問的性能不相同, 每個線程塊的線程數量應為warp大小的整數倍。為了避免因warp塊填充不足而造成的計算資源浪費, 系統中應保持足夠多的線程塊數量。根據全局存儲器合并訪問和分區沖突的要求, 建議每個線程塊使用128~256個線程, 這樣可以提高訪問全局存儲器的效率。盡可能同時執行更多的線程, 就越容易隱藏存儲器延時。線程塊應盡量使得X和Y方向的維度是warp大小的倍數。表2中顯示了圖像像幅大小為5 234×5 648時, 在線程塊中設置不同數量線程時的系統運算時間。可以看出, 線程塊中的線程數量不同, 其對應的運算時間有差異。對于本例,當線程數為16×16時, 系統性能最優。運算中,為每個線程塊分配更多線程可實現有效的時間分割, 從而提高運算速度; 但線程數量過多, 每個線程可用的寄存器就越少, 實際能夠被調度到流多處理器上運行的線程塊也越少, 甚至造成Kernel由于寄存器不足而無法啟動。

表2 線程塊大小對運算速度的影響
3 實驗測試和結果分析
3.1 實驗運算平臺
本研究的硬件實驗平臺CPU為Intel Core i7-7700(四核心), 主頻3.6 GHz, 系統內存為16 GB。GPU主要配置參數如表3所示。操作系統為微軟Windows 8.1 64 bits; MATLAB R2018b; Microsoft Visual Studio 2017集成開發環境; OpenMP 3.0的多核處理器支持環境; CUDA Toolkit 8的編譯支持環境。

表3 NVIDIA GTX 1060配置參數
3.2 實驗數據
為了進行多組數據的對比實驗, 需要對原始圖像數據進行預處理, 通過裁剪獲得圖像大小分別為356×687、1 256×1 587、2 868×2 745、3 268×3 689、4 253×4 725、5 234×5 648和7 646×7 862共7組實驗數據。圖4、5、6分別是對像幅大小為500×500的暗圖像、亮圖像、低對比度圖像進行直方圖均衡處理的結果和相應的直方圖。
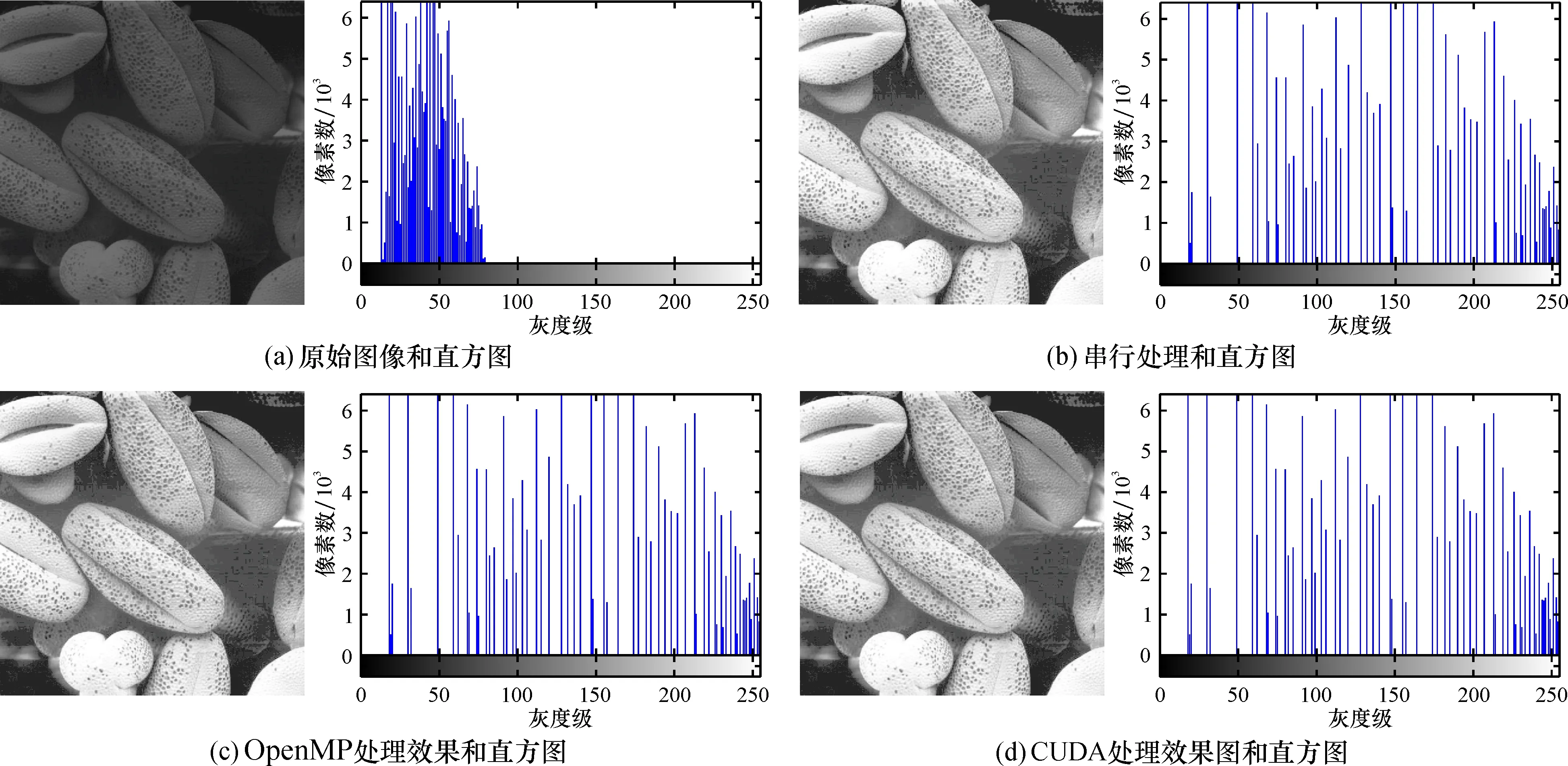
圖4 暗圖像處理效果
本文共設計3種實驗以驗證圖像直方圖均衡算法: 第一種實驗運行基于CPU平臺的串行圖像直方圖均衡算法;第二種實驗運行基于多核CPU平臺的OpenMP并行圖像直方圖均衡算法;第三種實驗運行在GPU平臺的并行圖像直方圖均衡算法。針對3組測試圖像, 多次運行3種直方圖均衡系統, 計算出各組實驗的直方圖均衡平均耗時, 數值結果保留小數點后兩位, 串行算法執行時間與并行算法執行時間對比如表4所示。
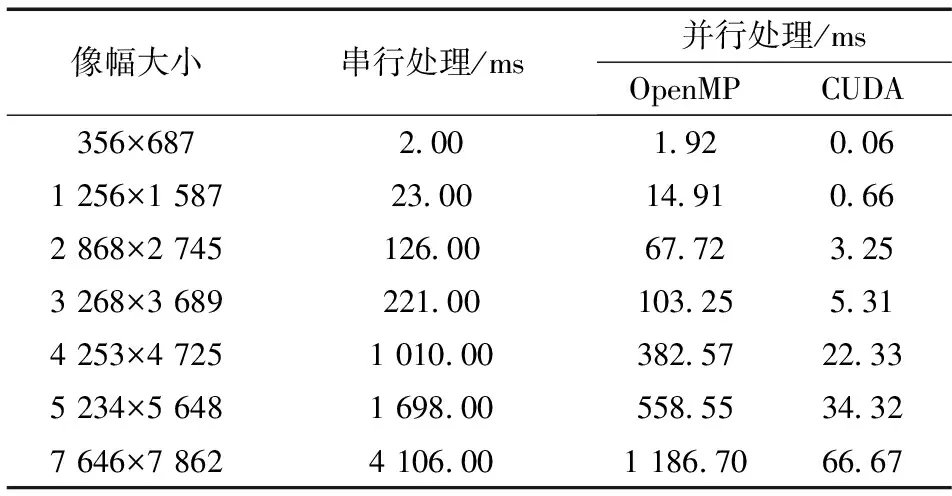
表4 不同計算平臺下直方圖均衡算法執行時間
定義加速比
s=Ts/Tp,
(10)
其中, 串行算法的執行時間為Ts, 并行算法的執行時間為Tp。將串行算法執行時間和并行算法執行時間相比即為加速比。加速比反映了在相應并行計算架構下的并行算法相比CPU串行算法系統執行效率的改善情況, 能夠對實際系統的速度進行客觀評價, 如表5所示。
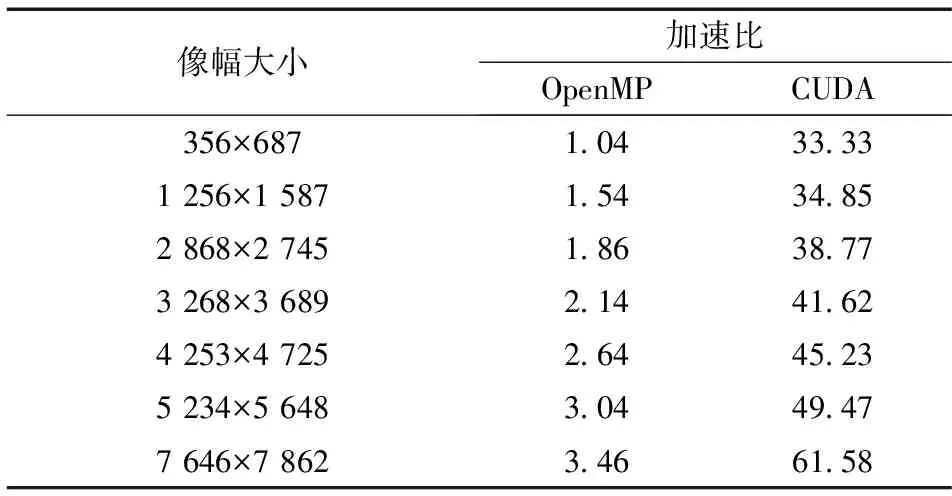
表5 不同計算平臺下直方圖均衡并行算法性能對比
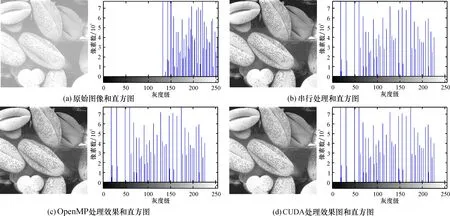
圖5 亮圖像處理效果
3.3 有效性驗證
本文以在CPU串行計算中實現的圖像直方圖均衡算法作為進行GPU移植和優化的基準CPU程序, CUDA算法系統的各方面參數與該基準程序保持一致。因此, 有效性驗證只和該CPU串行算法的運行結果進行比較。
3.3.1 宏觀層面結果一致性 由圖6的實驗結果可知, 在3組實驗中原始圖像對比度都較低且圖像暗淡, 而經過直方圖均衡算法串行和并行處理后圖像都比原始圖像要清晰明亮, 具有較高的對比度。圖像直方圖均衡串行系統和并行系統的運行結果相同, 無肉眼可辨的差異。

圖6 低對比度圖像處理效果
3.3.2 微觀層面結果一致性 由圖4~圖6的實驗結果可見, 在每一組實驗中的直方圖均衡串行處理和并行處理的直方圖對應的數據相同, 即相同灰度級的像素數一樣。在3組實驗中, 原始圖像的直方圖分布并不均勻, 經過直方圖均衡算法串/并行處理后的圖像直方圖分布均勻, 保持了處理結果的一致性。
3.4 實驗數據分析
3.4.1 系統性能瓶頸分析 在直方圖均衡算法處理過程中,需要對原始圖像數據進行M×N次存儲器讀取, 對直方圖均衡圖像增強數據進行M×N次存儲器寫入操作。由于M×N=3 268×3 689, 每個像素值分配存儲空間大小是2 B, 所以, 存儲器存取數據總量約為0.048 GB。除以Kernel實際執行的時間0.000 312 s, 得到的帶寬數值是約154 GB/s, 這已經接近GeForce GTX 1060顯示存儲器的192 GB/s帶寬了。可見, 基于CUDA架構的直方圖均衡并行算法的效率受限于全局存儲器帶寬。
3.4.2 不同架構下直方圖均衡算法運算時間分析 在3種計算平臺上對不同像幅大小的實驗圖像進行直方圖均衡處理, 將CPU串行運行時間和在兩種不同并行計算架構下的運行時間進行對比, 如圖7所示。當圖像像幅大小相同時, 在不同并行計算平臺上執行時間相對CPU串行執行時間都有不同程度的縮減, 即均獲得了加速效果。對于像幅大小為7 646×7 862的直方圖均衡串行運算時間為4 106.00 ms, 在OpenMP計算平臺下運算時間縮短為1 186.70 ms, 而在CUDA架構下的并行計算平臺上運算時間則大幅縮減為66.67 ms。
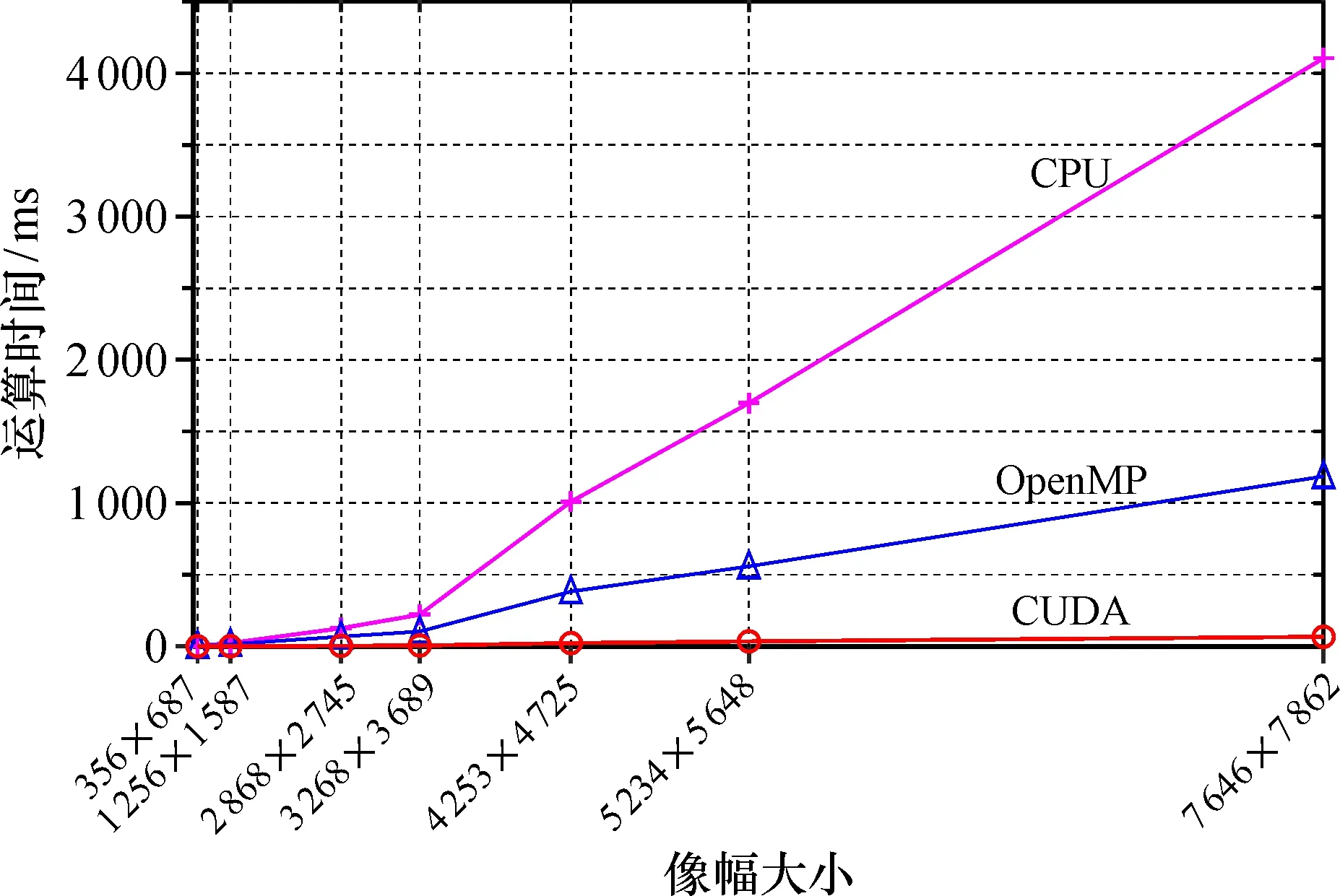
圖7 不同計算平臺下直方圖均衡算法運算時間對比
在相同像幅大小下, 利用OpenMP并行處理后的直方圖均衡算法的運算時間相比單線程的串行算法運算時間有明顯的減少,并且在相同的線程數下隨著圖像規模的增大, 運行時間也越來越長, 基本符合線性增長的趨勢。
當圖像像幅較小時, 在基于CUDA的直方圖均衡并行算法中, 由于啟動的線程計算量不滿載, 大部分時間消耗在系統調度方面。GPU高性能計算的優勢沒有展現, 運算時間與CPU運算時間差別不明顯; 隨著圖像像幅的增大, 每個線程的計算量漸漸滿載, 在系統調度方面消耗的時間比例降低, GPU并行度提高, 加速比上升。
3.4.3 并行計算架構下直方圖均衡算法加速效果對比分析 由圖8可知, 基于多核CPU的直方圖均衡算法取得了一定的加速效果。相較于串行算法, 隨著像幅大小的增大, 總體保持著近2~4倍左右的加速。由于受到CPU核數的制約, OpenMP并行算法很難達到比較高的加速比。而GPU并行算法的加速效果則十分明顯, 并行算法在處理7 646×7 862大小的圖像時, 實現了比串行算法快61.58倍的加速比, 極大程度節約了運算時間。同時, 隨著圖像規模的增大, 并行算法所得到的加速比也在不斷增大, 可以很好地滿足實時性要求。但是, 并行處理性能的提升是一種非線性增長, 且隨著像幅規模的進一步增加, 緩慢上升的趨勢十分明顯。出現此現象是由于主機與設備間的數據傳輸帶寬遠低于設備之間的數據傳輸顯存帶寬,主機內存和GPU存儲器間的交互數據過程造成了一定的時間開銷。當圖像像幅規模不大時,這部分開銷對系統的計算時間有較大影響;只有當圖像規模較大時, 數據交互時間所占比例較小, GPU并行計算時間足以抵過系統傳輸延遲開銷, GPU加速的效果才凸顯出來。
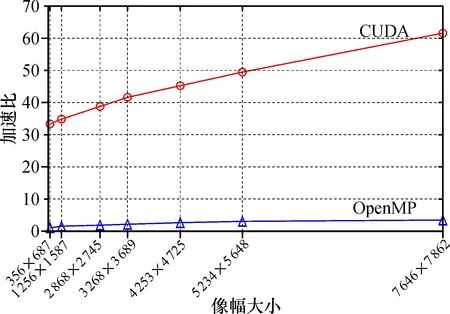
圖8 直方圖均衡并行算法加速比趨勢圖
將本文算法的整體加速效果與文獻[6-9]進行對比。文獻[6]中基于DSP的直方圖均衡并行算法的性能提升6.02倍, 文獻[7]中基于FPGA的直方圖均衡并行算法的性能提升1倍, 文獻[8]中基于GPU的直方圖均衡并行算法最大獲得了24.96倍的加速比, 文獻[9]在處理圖像大小為100×100時獲得了最大加速比是12.32。而根據表5的測試結果可以看到, 本文基于CUDA加速的直方圖均衡并行算法獲得了61.58倍加速比。因此, 相比文獻[6-9]中的算法, 本文并行算法取得了更好的加速性能。
4 結束語
本文對基于CUDA的圖像直方圖均衡算法進行了深入研究。首先對直方圖均衡處理技術的時域算法進行了分析, 以尋找算法的熱點; 然后充分分析直方圖均衡算法性能瓶頸步驟的可并行性; 最后, 針對CUDA編程模型與直方圖均衡算法特點, 提出了基于CUDA的直方圖均衡并行算法的優化方案。該方案利用直方圖均衡算法各個計算步驟的不同特征, 與CUDA存儲器訪問機制相結合, 提高數據計算速度。針對方案中數據和任務的并行度, 闡述了按照圖像格網區域進行粗粒度并行和子圖像塊中像素點進行細粒度并行的兩級并行處理技術, 最大限度地利用了GPU并行計算資源。根據GPU硬件特點, 采用原子加操作完成了并行投票累加的過程, 并充分利用了全局存儲器合并訪問的特性, 提高了運算速度。實驗表明, 使用本文并行設計方案, 與傳統CPU實現方式相比最大獲得了61.58倍加速比, 擁有了更高的圖像處理效率。
為了更好地增強圖像的局部細節, 今后將采用基于子塊重疊的局部直方圖均衡算法來得到最優的增強效果。同時, 利用微分方程模型和最優化模型描述直方圖均衡算法也是一個重要的研究方向[13-16]。下一步需要通過對算法的深入剖析, 盡可能優化數據的存儲, 研究多GPU協同計算機制, 利用更強計算能力的GPU計算設備或GPU集群提升算法的性能。
