一種深度強化學習制導控制一體化算法
2021-12-13 01:29:28何紹溟林德福
宇航學報 2021年10期
關鍵詞:智能
裴 培,何紹溟,王 江,林德福
(1.北京理工大學宇航學院,北京 100081;2. 北京理工大學無人飛行器自主控制研究所,北京 100081)
0 引 言
攔截導彈的制導和控制通常被當作兩個回路來分開設計,內回路是產生舵指令的自動駕駛儀控制回路,外回路是生成加速度指令的制導回路[1]。內回路跟蹤外回路的加速度指令產生舵偏角控制量,內外回路分開設計的主要問題是制導控制系統存在著時間滯后問題,無法攔截高速和高機動的目標。傳統的外回路采用比例導引制導律設計,比例導引算法的主要思想是產生加速度指令使零控脫靶量在有限時間收斂到零[2]。雖然理論上已經證明了導引增益為3的比例導引制導律對于常值速度的飛行器是能量最優的[1],對于終端速度最大的情況也是最優的[3];并且比例導引及其多種變化形式已經被廣泛的用來控制終端落角和飛行時間[4-6]。但是過去經典的制導算法的推導和理論證明都是基于忽略氣動力后的線性化運動方程得到的。當考慮制導控制一體化問題的時候,由于引入了彈體氣動模型,制導系統的模型就變得非線性和時變性,無法利用比例導引的形式求解。滑模控制[7]、反步法[8]和連續時間預測控制[9]等方法被用來求解制導控制一體化問題。查旭[10]針對打擊固定目標,采用終端滑模理論設計制導控制一體化算法。賴超[11-12]將其擴展成為在三維情況下打擊機動目標的制導控制一體化算法。雖然采用滑模控制可以實現目標攔截,但滑模控制會導致能耗增加,且容易出現控制飽和現象。這些形式的制導控制一體化算法控制律形式復雜,需要設置的參數多,針對不同的初始情況和彈體參數需要人工調整參數的取值來獲得良好的制導控制表現。簡化控制律的形式和自主進行參數調節是改進制導控制一體化算法的方向之一。
隨著嵌入式元器件計算能力的快速發展,計算制導算法的發展引起了學者的日益關注[13]。計算制導算法不同于傳統的制導律算法,它沒有一個解析形式的制導律,而是通過大量的在線計算來產生制導指令。計算制導可以分為基于模型和基于數據兩個類型。文獻[14]中提出了一種基于模型的三維終端落角約束計算制導算法,算法基于模型預測靜態規劃算法[15]。模型預測靜態規劃算法將動態規劃問題轉化為靜態規劃問題從而提高計算效率,因此許多制導問題利用模型預測靜態規劃的高效性來求解,例如終端落角控制制導律[16]和再入制導[17]。然而基于模型預測靜態規劃方法求解制導律需要一個很好的初始猜測值來保證算法收斂[18]。
基于模型的算法要求模型的信息是完全已知的,所以基于模型優化方法的表現與模型的精度有很大的關系。制導控制一體化問題中存在著很大的模型不確定性,例如目標機動、氣動不確定性等,因此不適合使用基于模型的優化方法求解。基于數據的優化算法不需要模型的精確信息,因此比較適合用來求解制導控制一體化問題。采用強化學習理論解決控制問題的研究大都應用在機器人上,很少用于解決航空航天中的制導問題。文獻[19]提出了一種基于強化學習的制導算法,首先將強化學習應用到了制導領域,然而文章只考慮了一種固定的情形,魯棒性差。深度強化學習技術還被應用于求解火星著陸制導問題[20]和再入制導問題[21]。文獻[22]利用強化學習技術來學習經典的終端落角約束制導律制導增益,并將算法應用到近直線軌道的相對運動制導問題中。文獻[23]利用Q學習方法根據傳統比例導引制導律,提出了基于強化學習的變系數比例導引制導律,然而其需要兩千次以上的迭代學習來保證結果收斂。
針對制導控制一體化問題存在的高度不確定性和控制律設計復雜的問題,本文基于無模型強化學習理論,研究了一種基于深度強化學習理論的制導控制一體化算法,算法可以通過學習自動生成制導控制智能體,無需人工進行參數調整。為了應用強化學習算法,將導彈的運動學和動力學過程建模為環境,舵偏角指令建模為智能體的行為,并且提出了權衡制導精度、能量損耗和飛行時間的獎勵函數。強化學習模型框架建立后,采用深度確定性策略梯度(Deep determinstic policy gradient, DDPG)算法學習出一個從導彈觀測量到舵偏角指令的行為策略。數值仿真表明提出的算法可以實現在各種不同的初始情況下的精準攔截,同傳統算法相比能耗更優,能夠避免控制飽和現象,并且算法對于彈體參數和氣動不確定性具備良好的魯棒性。
1 強化學習算法
強化學習的最優策略可以通過最大化值函數和最大化行為值函數得到。然而直接最大化值函數或者行為值函數都需要精確的模型信息,很難在模型不確定的情況下使用。而無模型的強化學習算法放松了對于精確模型信息的需求,因此,在存在高度模型不確定性的情況下可以使用無模型的強化學習算法。
無模型的強化學習算法可以分為值函數方法和策略梯度方法兩類。值函數方法只適用于離散行為空間的情況。著名的深度Q學習[24]就屬于此類。與之相比,策略梯度算法可以應用于連續控制系統的問題中。由谷歌Deepmind提出的深度確定性策略梯度算法是策略梯度算法的最新解決方案之一[25]。
1.1 深度確定性策略梯度算法
對于制導控制一體化問題,強化學習的主要目的是產生舵偏角指令控制導彈攔截機動目標。為了解決這個問題,本文使用了DDPG算法設計了一個制導控制一體化算法。DDPG是一個執行-評價算法,其基本概念框架如圖1所示。
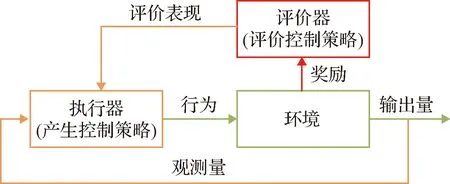
圖1 DDPG算法基本概念框架圖Fig.1 Basic concept of DDPG
1.2 訓練DDPG智能體
為了避免在探索狀態空間的過程中總回報函數陷入局部最優,DDPG在執行器網絡的行為上增加一個隨機噪聲vt:
a′t=at+vt
(1)
式中:at為執行器網絡輸出的行為。
并且在后面的系統中使用這個含噪聲的行為。隨機噪聲vt使用Ornstein-Uhlenbeck過程進行更新
(2)
式中:μv為噪聲的均值;N(0,∑t)為0均值∑t方差的高斯分布;βattract是平均吸引常數,代表噪聲被平均值吸引的速度;Ts是采樣時間。隨著訓練過程經驗的增加,方差∑t以速率ε指數級衰減:
Σt=Σt-1(1-ε)
(3)
DDPG的偽代碼如算法1所示。

算法1 深度確定性策略梯度算法1 使用隨機權重μ和w來初始化執行器和評價器網絡2 使用權重μ'=μ和w'=w來初始化目標執行器和評價器網絡3 初始化經驗緩沖區D4 for片段=1:最大片段個數do5 for t=1:最大步數do6 執行器依據當前狀態產生行為at=Aμ(st)7在行為中增加噪聲來探索a't=at+vt8執行行為a't得到新的狀態st+1和獎勵9將轉移經驗e(t)=(st,at,rt,st+1)存入經驗緩沖區D10從經驗緩沖區D中均勻抽取組隨機樣本ei11計算時序差分誤差δδt=Rt+ηQw'(st+1,Aμ'(st+1))-Qw(st,at)12計算損失函數L(w)L(w)=1N∑Ni=1δ2i

13 使用梯度下降法更新評價器網絡-12ΔwL(w)=1N∑Ni=1δiΔwQw(si,ai)wt+1=wt-αwΔwL(w)14使用策略梯度下降法更新執行器網絡ΔμJ(Aμ)=1N∑Ni=1ΔμAμ(si)ΔatQw(si,ai)μt+1=μt+αμΔμJ(Aμ)15更新目標網絡μ'=τμ+(1-τ)μ'w'=τw+(1-τ)w'16if任務結束then17終止當前片段18end if19 end for20 end for
式中:s,a,r分別為強化學習馬爾可夫過程中的狀態量,行為和獎勵,A和Q是分別由μ、μ′和w,w′參數化定義的執行器和評價器神經網絡,γ為定義的權重值,τ?1為很小的目標網絡更新速率,αμ,αw分別為執行器和評價器神經網絡的學習速率。
2 制導控制一體化強化學習模型建模
這個部分將制導控制問題轉化到強化學習的框架中。
2.1 相對運動學模型
考慮一個二維平面尋的階段,如圖2所示。慣性坐標系由(X,Y)所示。變量的下標M和T分別代表導彈和目標。λ和r分別表示視線角和導彈目標相對距離。γ為由慣性坐標系定義的彈道傾角。速度和側向加速度分別由V和a表示。則描述導彈和目標的相對運動關系方程可以表示為:
(4)
(5)
(6)
(7)
式中:aTraTsin(λ-γT),aTλaTcos(λ-γT)分別為目標沿著視線和垂直于視線方向的加速度;aMraMsin(λ-γM),aMλaMcos(λ-γM)分別為導彈沿著視線和垂直于視線方向的加速度。
彈道傾角和側向加速度之間存在以下關系:
(8)
2.2 動力學模型
導彈的加速度由氣動力提供,導彈的平面動力學模型可以被表示為[8,26]:
(9)
式中:α表示彈體攻角;m表示彈體質量;ωz表示彈體俯仰角速率;g是重力加速度;Jz是彈體的轉動慣量;θ是俯仰角。L和M分別表示升力和俯仰力矩,可以由下式計算得到[8,26]
(10)
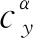
(11)
2.3 強化學習問題建模
為了使用DDPG算法求解制導控制一體化問題,需要將原問題轉化到強化學習的框架中,首先要建立一個馬爾可夫決策過程。式(4)~(11)的運動學和動力學方程構成了強化學習馬爾可夫決策過程中的環境,環境st由過程狀態可以表征為:
(12)
對于制導控制一體化問題,馬爾可夫決策過程中智能體的行為定義為舵偏角指令δz。假設導彈裝備有主動雷達探測器,可以測量與目標的相對距離r和視線角λ以及他們的導數。并且導彈裝備有慣導裝置,可以測量自身的俯仰角θ、俯仰角速率ωz和彈道傾角γM,經過組合導航算法后,可以得到攻角α,則馬爾可夫決策過程中智能體的觀測量ot可以定義為:
(13)
因此定義的馬爾可夫決策過程是全狀態可觀的。
相對運動學方程(4)~(10)、過程狀態(12)、智能體觀測量(13)、智能體行為和一個合適的獎勵函數構成了制導控制問題的馬爾可夫決策過程。制導控制一體化問題的強化學習框架的概念流程圖如圖3所示。
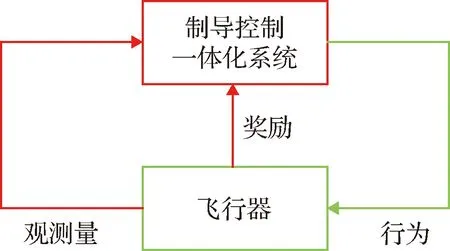
圖3 制導強化學習框架概念流程圖Fig.3 Conceptual flowchart of the proposed guidance RL framework
2.4 定義獎勵函數
采用DDPG算法求解制導控制問題最重要的部分是設計一個合適的獎勵函數使導彈穩定的攔截目標。最直接的獎勵函數是當導彈成功攔截目標時給智能體一個獎勵,否則給智能體一個負的懲罰獎勵。然而我們的實際測試表明這種簡單的獎勵是無效的,因為在隨機初始猜想條件下導彈成功攔截目標的概率非常低,智能體在有限數量的片段性學習中幾乎得不到正向激勵。
因為零化零控脫靶量可以實現零脫靶量攔截[1],所以本文使用零控脫靶量來建立獎勵函數。在任意時刻,零控脫靶量定義為從t時刻起,如果導彈和目標都不機動,導彈和目標最近的距離。將零控脫靶量定義為z,其形式為[26]:
(14)
舵偏角的大小直接量化了由誘導阻力導致的速度損失。考慮到這個情況,獎勵函數同樣需要考慮控制能耗。并且由于尋的階段通常非常短,需要導彈快速的攔截目標。因此,將獎勵函數定義如下:
Rt=Rδ+Rz+RVr+Rr
(15)
其中
(16)
(17)
(18)
(19)
式中:kδ,kz,kVr和kr是定義獎勵函數的四個常數。δzmax為受導彈物理結構限制的最大允許的舵偏角,z0代表零控脫靶量的初始值。
從式(15)中可以看出,獎勵函數的前兩項懲罰的是歸一化后的控制能耗和零控脫靶量。在獎勵函數中使用歸一化處理的原因是舵偏角大小和零控脫靶量具有不同的單位和尺度,很難在沒有歸一化的情況下直接比較。第三項rVr是激勵導彈持續減少相對距離來實現快速攔截。這一項同時也對任務失敗做出懲罰,因為如果在剩余飛行時間到0之后,導彈沒有命中目標,導彈和目標之間的相對距離就會增加。第四項rr是當相對距離小于一個正常數rd之后給予獎勵。這一項僅在導彈接近目標的時候產生作用,因此與經典優化控制問題中終端約束代價類似,用于約束終端狀態。簡而言之,本文提出的獎勵函數允許智能體在攔截精度、能量損耗和飛行時間之間進行權衡。由于強化學習的過程具有隨機性,目前針對獎勵函數參數的選擇沒有一個定量的解析形式,但是可以通過訓練結果定性的調整參數的取值。
kδ:通常選取比較小的數值,訓練的首要目的是命中目標,其次是降低能耗,當訓練結果保證命中目標后可以適當增大取值
kz:驅動零控脫靶量持續減少,參數取值過小零控脫靶量無法收斂到零,無法命中目標,參數取值過大訓練目標變為零控脫靶量減小最快而不是零控脫靶量收斂到零。
kVr:驅動相對距離持續較少,參數取值過小無法驅動相對距離持續減少,參數取值過大訓練過程無法適應相對距離先增大后減小的情況。
kr:類似終端獎勵,初始值可以給的較大,參數取值過小無法命中目標,參數取值過大不利于降低控制能耗。
rd:定義為導彈的毀傷半徑。
通過二分法調整參數取值,通過進行大量的數值仿真后,形成獎勵函數的超參數見表1。進行訓練采取的導彈速度為VM=1000 m/s,目標速度為VT=600 m/s,初始攻角為α0=0°,初始俯仰角速率為ωz0=0 (°)/s,初始俯仰角θ0等于導彈彈道傾角初始值γM0,其他初始條件參數見表2,彈體動力學參數如式(26)所示。

表1 獎勵函數的超參數取值Table 1 Hyper-parameters in shaping the reward function
3 訓練DDPG制導控制智能體
這個部分定義了DDPG制導控制智能體的訓練過程。智能體能夠直接學習控制指令δz,產生一個直接從觀測量到舵偏角指令的映射:
(20)
式中:fs是一個非線性函數。
訓練DDPG制導控制智能體包含三個主要步驟:1)提出訓練方案;2)創建執行器和評價器網絡;3)調整超參數。
3.1 提出訓練方案
在本文中,考慮一個導彈迎頭攻擊的情況。為了更好的使用已經學習到的經驗,首先采用幾個特定的初始狀態條件進行訓練。初始條件從狀態的最大值最小值中間選取,其數值見表2。首先基于這些初始條件序列的訓練DDPG制導控制智能體,當智能體采用一種特定的初始狀態進行訓練到收斂后切換到另一種初始狀態進行訓練。通過大量的經驗測試,我們發現提出的智能體在一種初始條件下200個片段以內就能收斂。在特定的初始條件訓練完成之后,片段進行隨機初始化訓練,初始狀態從這些狀態的最小值和最大值之間均勻隨機選取。這種啟發式的訓練方法比直接從隨機狀態開始訓練收斂快的多。

表2 訓練初始條件取值范圍Table 2 Initial conditions in training
3.2 創建網絡
根據原始的DDPG算法[25],使用四層全連接的神經網絡來表示執行器和評價器的網絡,這種四層網絡結構在深度強化學習中廣泛應用。這兩個網絡每一層的大小如表3所示。除了執行器的輸出層以外,其他層的每一個神經元都由一個整流線性單元(Relu)函數激活,該函數定義為:
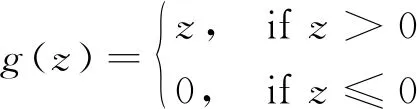
(21)
由于其線性特性,能夠比其他非線性激活函數提供更快的收斂速度。
并且受彈體結構限制,執行器輸出的行為舵偏角大小受限,因此執行器網絡的輸出層由雙曲正切函數激活:
(22)
執行器網絡使用雙曲正切激活函數的優點是限制執行器輸出為(-1, 1),避免控制輸入飽和問題。執行器的網絡輸出層由常數amax進行縮放。

表3 網絡層結構Table 3 Network layer size

(23)
式中:(·)0表示變量(·)的初始值,當初始值為0時,取值為1避免奇異現象。
為了解決穩定學習過程中的過度擬合問題,執行器和評價器網絡都使用帶L2正則化的Adam優化器來訓練。在使用L2正則化的情況下,執行器和評價器的更新方式變為:
(24)
(25)
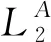
為了增加網絡訓練過程的穩定性,采用梯度截斷來限制執行器和評價器網絡的更新,也就是當梯度的范數超過了一個給定的上界ρ,梯度就被縮放到等于ρ。這種方式有助于防止訓練過程中出現數值溢出或者下溢現象。
3.3 調整超參數
當導彈和目標之間的相對距離小于rm=2 m或者時間步數超過了允許的最大步數,每一個片段訓練終止。本問題中DDPG算法訓練使用的超參數見表4。調整超參數對于DDPG算法的性能有很大影響,并且這種調整過程在不同的應用范圍內是不同的,不同問題有不同超參數集。在大量數值仿真經驗總結下,給出了表中的超參數取值。

表4 超參數設置Table 4 Hyper parameters setting
4 仿真結果
仿真訓練中與升力和俯仰力矩相關的參數為:
(26)
4.1 訓練結果
根據訓練方案,首先采取10個固定的初始條件來序列的訓練DDPG制導智能體。每一種初始條件采取200個片段進行DDPG制導控制智能體訓練。圖4給出了前四次固定初始條件下的學習曲線。曲線中的平均獎勵是最近30次片段獎勵的平均值。從圖中可以看出在前四次固定初始狀態訓練中,提出的DDPG制導控制智能體的訓練結果能夠在200個片段訓練內收斂。當使用這些固定的初始狀態訓練完成之后,訓練片段的初始化變為從狀態量的最小值和最大值之間隨機均勻取值。隨機初始條件訓練過程的學習曲線如圖5所示。從圖中可以看出即使是在隨機初始條件的情況下,經過10次固定的特定初始訓練條件訓練之后的DDPG制導控制智能體的平均獎勵仍然能在200個片段訓練內收斂到一個穩態值。訓練過程能夠收斂的原因是智能體已經在固定初始條件的訓練中得到了一些經驗。在我們的數值仿真測試中,我們發現使用啟發式的訓練過程比使用隨機初始條件開始訓練的收斂速度要快的多。

圖4 特定初始條件下的學習曲線Fig.4 Learning curves with some fixed characteristic initial conditions
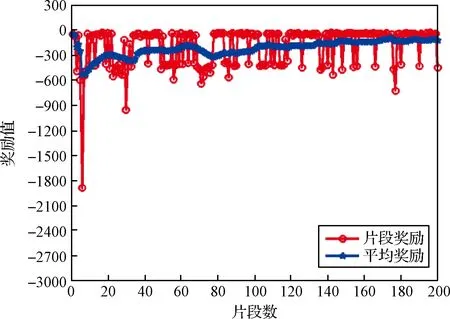
圖5 隨機初始條件下的學習曲線Fig.5 Learning curves with random initial condition
為了體現在訓練DDPG制導智能體的過程中對觀測量和行為進行歸一化處理的重要性,圖6給出了第一種固定初始條件下有無歸一化處理的200個片段訓練平均獎勵函數的對比結果。從圖中可以看出使用歸一化處理能夠使學習過程具有更快的收斂速度和更高的平均獎勵穩態值,不采取歸一化處理訓練曲線無法收斂。歸一化處理使得觀測量的每個元素的權重都相等,可以使訓練過程更有效、更高效。如果沒有歸一化處理,各個元素之間的尺度相差非常大,例如相對距離的量級就比視線角速度大得多,不利于執行器和評價器網絡的訓練。

圖6 有無歸一化處理過程學習曲線對比Fig.6 Learning process comparison with respect to normalization
4.2 結果測試
為了測試提出的DDPG制導智能體的攔截表現,將訓練得到的DDPG制導智能體應用到攔截機動目標的仿真測試中,仿真初始條件為相對距離初值r0=5000,初始彈目視線角λ0=0°,初始導彈彈道傾角為γM0=20°,初始目標彈道傾角為γT0=150°,目標常值加速度機動,加速度為20 m/s2。受彈體結構限制,舵偏角指令限制為|δz|≤δzmax。為了與傳統設計方法進行對比,文中采用了兩種方法進行對比,第一種是制導增益為3的比例導引制導律(Proportional navigation guidance,PNG)與自動駕駛儀組合來產生舵指令,自動駕駛儀采用極點配置法設計,第二種是采用反步法設計的制導控制一體化算法[23],仿真結果如圖7所示。其中三種算法的攔截精度見表6,可以看出由于采取了大量的數據進行訓練,提出的DDPG制導控制算法精度更高。從圖7(a)可以看出,三種制導算法都能夠成功攔截目標。攻角曲線如圖7(b)所示,舵偏角曲線如圖7(c)所示,提出的算法由于懲罰了舵偏角并且采用雙曲正切函數作為輸出層,抑制了舵偏角指令飽和現象。圖7(d)中的加速度曲線表明,當反步法制導控制一體化算法得到的最大加速度約200 m/s2時,攻角約為40°,DDPG制導控制算法得到的最大加速度約為-100 m/s2時,攻角約為-20°,驗證了式(11)中導彈的側向加速度由攻角和重力加速度共同作用產生,同時,舵偏角作用下,為了得到更大的攻角,彈體姿態的運動更大,因此攻角過大不利于導彈穩定飛行,提出的制導控制智能體產生的最大攻角比傳統反步法低,更利于工程實現。從圖7(e)中的舵偏角指令控制能耗曲線可以看出,提出的DDPG制導算法在三種算法中能耗最優。從圖中曲線可以看出提出的DDPG制導控制算法和反步法制導控制一體化算法曲線類似,但是由于懲罰了舵偏角指令,提出的制導算法得到的舵偏角比反步法制導控制一體化算法得到的舵偏角小,減小了控制能耗。

圖7 目標機動情況下仿真測試曲線Fig.7 Test results with random initial conditions for non-maneuvering target
為了驗證算法在工程應用的可行性,考慮到從組合導航算法中得到的數據存在噪聲,在仿真過程中引入噪聲,對算法進行仿真分析。定義加入的噪聲滿足高斯分布,其標準差的值見表5。從圖8(a)中的飛行軌跡曲線可以看出提出的算法在噪聲作用下仍然能攔截目標,但是由于存在噪聲,脫靶量增大為1.12 m,圖8(b)給出了舵偏角指令的曲線,可以看出控制量由于觀測量存在的高斯噪聲產生了高頻抖振。

表5 噪聲高斯分布標準差Table 5 Standard deviation of Gaussian distribution noise
為了測試算法對比其他兩種算法的魯棒性,對參數(26)負向拉偏40%后,采用3種算法分別進行仿真,仿真結果如圖9所示。仿真結果表明,在參數進行負向拉偏后,比例導引和反步法制導控制一體化算法控制量飽和部分增加,而提出的DDPG制導控制算法由于懲罰了舵偏角指令且采取了抑制飽和的輸出層,很好的抑制了飽和效應。三種算法的脫靶量見表6,可以看出參數負偏導致了制導律脫靶量增大,但是相比之下提出的算法精度仍然最高。
為了展現算法的魯棒性和泛化性,對訓練采用的參數(26)分別正向拉偏40%和負向拉偏40%后,
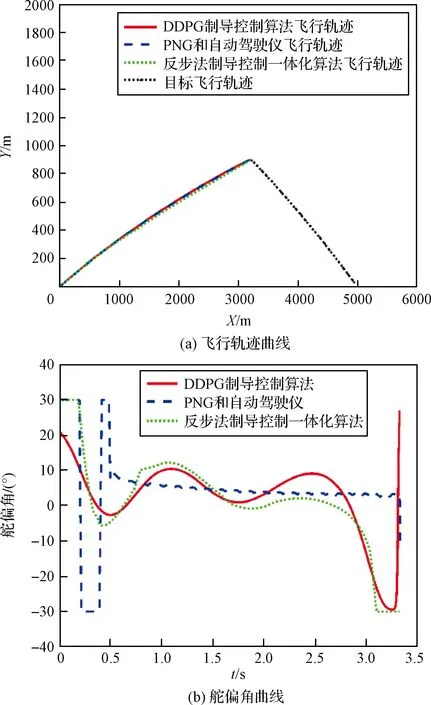
圖9 參數負向拉偏三種算法對比仿真Fig.9 Simulation results of three guidance algorithm with parameters negative deviation
采用訓練得到的制導控制智能體進行制導控制仿真,結果如圖10所示。仿真結果表明在參數存在不確定性的情況下,提出的制導控制智能體仍然能保證導彈命中機動目標,制導控制智能體對氣動參數和彈體參數的不確定性具有良好的魯棒性,系統不確定性對舵偏角指令產生影響。
最后,為了更進一步測試算法的魯棒性,初始條件在設定值的最大值最小值外浮動10%,參數(26)在標準參數的基礎上正負隨機偏差40%,采用不同隨機初始條件對三種算法同時進行蒙特卡洛數值仿真,仿真次數設置為100次。在每個測試周期中,目標的側向加速度為常值,均勻隨機從最小值-20 m/s2和最大值20 m/s2之間取值。三種算法的脫靶量結果如圖11所示,坐標信息為相對于目標位置的相對信息,同時仿真脫靶量的統計結果見表6,可以看出由于采取了大量的數據進行離線學習,提出的制導控制一體化算法在三者中精度最高。

圖10 參數不確定性測試結果Fig.10 Test results with parameters uncertainty

圖11 三種算法蒙特卡洛仿真結果Fig.11 Monte Carlo simulation results of three guidance algorithm
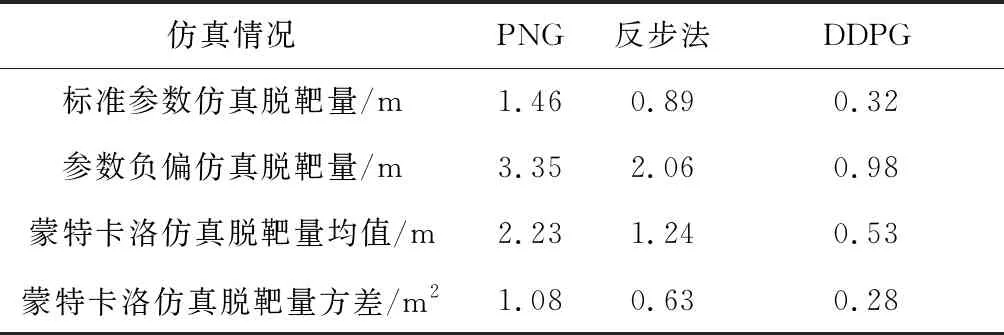
表6 不同仿真情況下三種制導算法脫靶量數值Table 6 Missdistance of three guidance algorithm for different simulation cases
5 結 論
本文基于深度強化學習理論提出了一個針對導彈目標攔截問題的制導控制一體化算法。將制導控制一體化問題轉化為一個強化學習優化問題,并且提出了一種啟發式的獎勵函數使導彈能低能耗且快速穩定的攔截目標。采用深度確定性策略梯度算法來訓練強化學習制導控制智能體,使總回報的期望最大化,生成從觀測量到行為映射的確定性策略,即生成了從觀測量到舵偏角指令的映射。大量的數值仿真驗證了提出算法的有效性和魯棒性,同傳統制導控制設計方法對比說明了提出的算法能耗更優。
猜你喜歡
開放教育研究(2021年3期)2021-05-25 02:41:06
小學科學(學生版)(2020年12期)2021-01-08 09:28:04
裝備制造技術(2020年4期)2020-12-25 05:26:24
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
能源(2018年4期)2018-05-19 01:53:44
