一種基于EFT的數(shù)據(jù)中心運維無閾值告警方法
2021-12-14 01:28:28張開芳高曉鋒段誼海
計算機應(yīng)用與軟件 2021年12期
張開芳 張 東 高曉鋒 郭 鋒 段誼海
1(鄭州大學(xué)信息工程學(xué)院 河南 鄭州 450001)2(浪潮電子信息產(chǎn)業(yè)股份有限公司 山東 濟(jì)南 250101)3(鄭州云海信息技術(shù)有限公司 河南 鄭州 450019)
0 引 言
數(shù)據(jù)中心是收集、存儲、共享和處理數(shù)據(jù)的平臺。IDC調(diào)查顯示[1],2010年我國數(shù)據(jù)中心和機房的總數(shù)量已經(jīng)達(dá)到504 155個。預(yù)計到2020年,我國數(shù)據(jù)中心保有量將超過8萬個,總面積將超過3 000萬平方米[2]。數(shù)據(jù)中心在日常生產(chǎn)生活中發(fā)揮重要作用,若是宕機,會帶來巨大的財產(chǎn)損失。Ponemon研究所調(diào)查表明單次數(shù)據(jù)中心宕機的平均成本約73萬美元[3]。在2016年8月,Delta航空公司數(shù)據(jù)中心宕機,導(dǎo)致公司損失了1.5億美元[4]。因此保障數(shù)據(jù)中心安全平穩(wěn)運行有著重要意義。數(shù)據(jù)中心運維方式由數(shù)據(jù)中心監(jiān)控平臺向運維人員發(fā)送告警通知,運維人員通過告警通知提前發(fā)現(xiàn)問題,檢查相關(guān)部件,及時做出反應(yīng),維護(hù)設(shè)備安全。
1 相關(guān)工作
工程應(yīng)用上,目前數(shù)據(jù)中心監(jiān)控平臺有兩種,一種是商用類型,如IBM的Tivoli[5]和HP公司的OpenView[6]監(jiān)控產(chǎn)品;另一種是開源類型,如Zabbix[7]、Nagios[8]等。由于商用類型的監(jiān)控平臺價格昂貴,目前企業(yè)級監(jiān)控一般采用開源監(jiān)控平臺。其對監(jiān)控項的告警方式一般由運維人員依據(jù)經(jīng)驗設(shè)定固定閾值,通過腳本編程實現(xiàn)。但該方法無法體現(xiàn)監(jiān)控項數(shù)據(jù)的波動變化,因此可能引起較大誤差,造成缺失告警或錯誤告警,無法滿足實時復(fù)雜情況下的告警需求。
在理論和方法研究上,文獻(xiàn)[9]實現(xiàn)了對數(shù)據(jù)中心各機房電源、空調(diào)和煙感等環(huán)境監(jiān)控量監(jiān)控,主要解決機房不同品牌設(shè)備之間因接口不兼容導(dǎo)致通信失敗的問題,但對環(huán)境監(jiān)控量的告警通知由人為制造(如人為釋放煙霧看是否產(chǎn)生告警),并且未提及相關(guān)監(jiān)控量的閾值問題。文獻(xiàn)[10]側(cè)重于設(shè)計實現(xiàn)數(shù)據(jù)中心實際工作需求的監(jiān)控軟件,在軟件的告警子系統(tǒng)中對基本事件流的告警方式基于閾值。文獻(xiàn)[11]重點在降低監(jiān)控任務(wù)負(fù)載與監(jiān)控可擴(kuò)展的研究上,其告警模塊基于Nagios[8]監(jiān)控軟件采集監(jiān)控項數(shù)據(jù),人工編寫腳本實現(xiàn)告警功能。文獻(xiàn)[12]實現(xiàn)了基于動態(tài)閾值的網(wǎng)絡(luò)性能管理系統(tǒng),實現(xiàn)動態(tài)閾值的方法是采用前四周同一時刻的數(shù)據(jù),通過線性回歸分析預(yù)測當(dāng)前時刻的閾值,但該方法基于性能監(jiān)控的周期性前提實現(xiàn),無法較好地反映數(shù)據(jù)波動且研究對象為網(wǎng)絡(luò)性能管理。文獻(xiàn)[3]通過自定義CPU、內(nèi)存和磁盤的過載閾值,經(jīng)由模型訓(xùn)練預(yù)測未來三天內(nèi)上述監(jiān)控指標(biāo)的負(fù)載,文獻(xiàn)數(shù)據(jù)來自百度股份有限公司。文獻(xiàn)[13]設(shè)計了Hdoctor通用框架實現(xiàn)磁盤的故障預(yù)測。文獻(xiàn)[14]提出了基于神經(jīng)網(wǎng)絡(luò)的框架,側(cè)重CPU、內(nèi)存、磁盤與網(wǎng)絡(luò)的資源利用率等監(jiān)控指標(biāo)的負(fù)載預(yù)測。文獻(xiàn)[15]提出兩個基于約束編程和神經(jīng)網(wǎng)絡(luò)的負(fù)載預(yù)測模型,完成對云數(shù)據(jù)中心物理服務(wù)器CPU利用率的預(yù)測。
上述研究大都集中于數(shù)據(jù)中心監(jiān)控系統(tǒng)的設(shè)計與實現(xiàn),在監(jiān)控指標(biāo)研究上更關(guān)注的是如CPU、內(nèi)存和磁盤等的利用率或故障預(yù)測方面,很少有文獻(xiàn)涉及到監(jiān)控項閾值問題告警層面的研究分析。對此,本文提出了一種基于EFT特征提取的無閾值告警模型,通過分析監(jiān)控項數(shù)據(jù)特點,提出從監(jiān)控項的能量、波動與時間三個方面提取特征,最終輸入到隨機森林模型訓(xùn)練,經(jīng)投票得出實時監(jiān)控數(shù)據(jù)告警結(jié)果,完成監(jiān)控項無閾值告警研究。
2 基于EFT的無閾值告警模型
2.1 模型流程圖
首先對監(jiān)控項數(shù)據(jù)預(yù)處理,經(jīng)由人工經(jīng)驗知識判斷實時監(jiān)控數(shù)據(jù)是否告警,接著基于EFT方法提取特征,輸入到訓(xùn)練好的隨機森林模型中得到最終判決結(jié)果。基于EFT的無閾值告警模型流程示意圖如圖1所示。
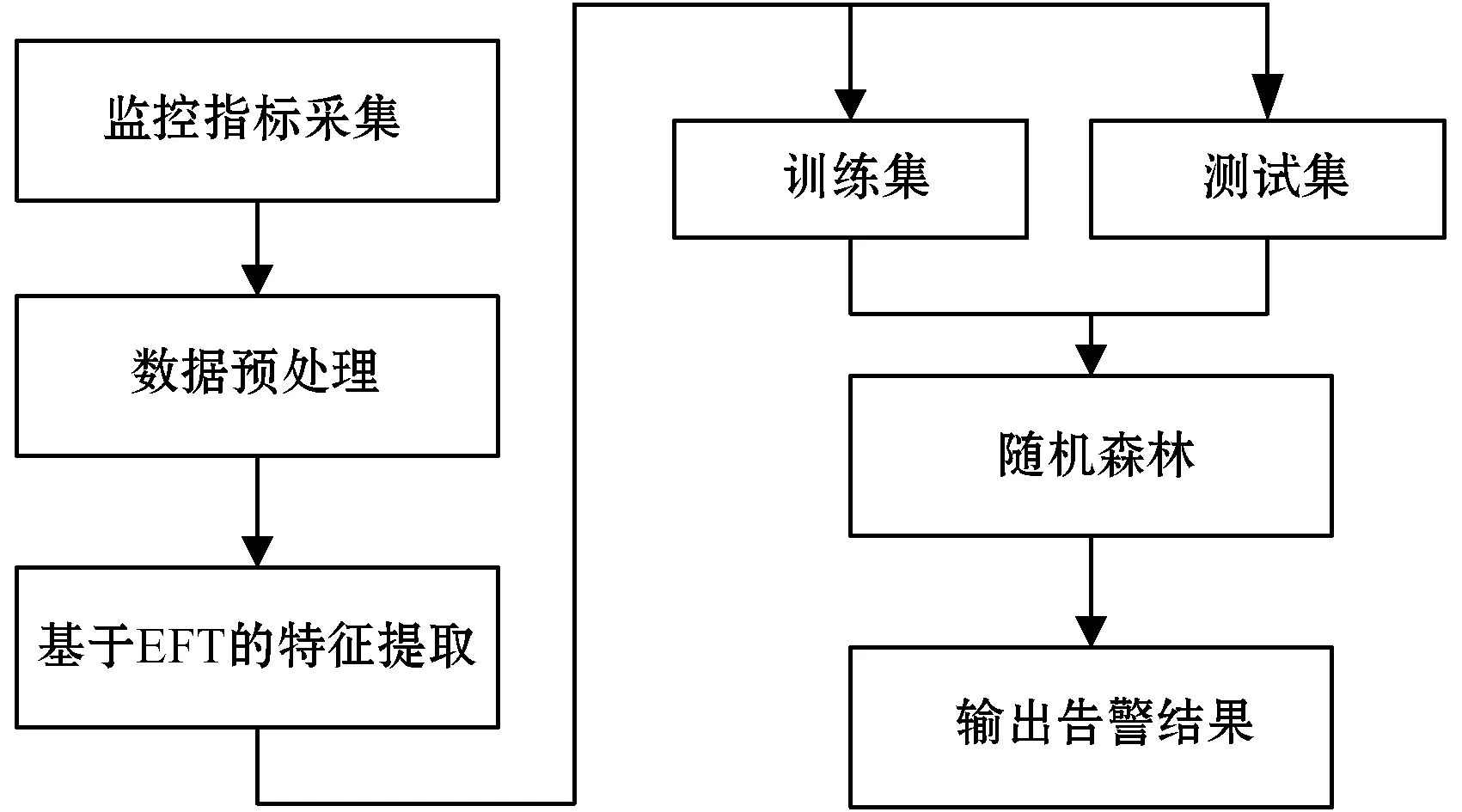
圖1 基于EFT的無閾值告警模型流程示意圖
2.2 數(shù)據(jù)預(yù)處理
為保證獲得高質(zhì)量的數(shù)據(jù),對于數(shù)據(jù)采集中由設(shè)備故障等原因造成的數(shù)據(jù)缺失,本文采用數(shù)據(jù)填充法處理,即用前后數(shù)據(jù)點的平均值來填充中間的缺失數(shù)據(jù)。
經(jīng)數(shù)據(jù)預(yù)處理后,通過滑窗構(gòu)造數(shù)據(jù)集中的樣本。窗口大小代表每個窗口中包含監(jiān)控值的個數(shù)。窗口數(shù)即為樣本數(shù)。在監(jiān)控平臺中,業(yè)務(wù)需求等因素會影響各監(jiān)控項數(shù)據(jù)變化,若窗口取值過大,太靠前的數(shù)據(jù)與當(dāng)前時刻數(shù)據(jù)關(guān)聯(lián)不大;若窗口取值過小,則提取的特征無法完整地體現(xiàn)局部數(shù)據(jù)變化。本文取窗口大小為5,監(jiān)控項每5分鐘獲取一次監(jiān)控值,即每個窗口的時間段為20分鐘。滑窗法構(gòu)造數(shù)據(jù)集示例如圖2所示。設(shè)監(jiān)控項經(jīng)由數(shù)據(jù)填充之后得到N個監(jiān)控值,則得到樣本N-5+1個。

圖2 滑窗構(gòu)造數(shù)據(jù)集示例
2.3 EFT特征提取
本文通過分析數(shù)據(jù)中心監(jiān)控項數(shù)據(jù)特點,提出一種基于EFT特征提取方法,即從監(jiān)控項數(shù)據(jù)的能量、波動和時間特性三個方面提取特征值。其中,能量反映監(jiān)控值的大小,波動反映監(jiān)控項數(shù)據(jù)的變化,時間聯(lián)合當(dāng)前監(jiān)控值分析。在能量方面,提取當(dāng)前窗口的監(jiān)控值、平均值和能量值。在波動方面,提取當(dāng)前窗口的斜率、標(biāo)準(zhǔn)差和相鄰波動及高于均值的個數(shù)(當(dāng)前窗口中所提取的標(biāo)準(zhǔn)差與高于均值個數(shù)中的平均值為監(jiān)控項所有數(shù)據(jù)的平均值)。在時間方面,以一周為周期,將時間細(xì)化到分鐘,進(jìn)一步挖掘監(jiān)控數(shù)據(jù)與時間的關(guān)聯(lián)。為了更進(jìn)一步體現(xiàn)以往窗口對當(dāng)前窗口監(jiān)控結(jié)果的影響,本文采取組合特征的方式,即將當(dāng)前窗口t與前兩個的窗口t-1、t-2所提取出來的特征組合在一起,作為最終特征集。每個窗口提取特征Pt的表達(dá)式如式(1)所示;最終組合特征集Fi如式(2)所示。表1為基于EFT方法提取的特征及計算方法,其中t代表窗口大小。
Pt=[f1,f2,…,f9]
(1)
Fi=[Pt-2,Pt-1,Pt]t=1,2,…,t-3+1
(2)
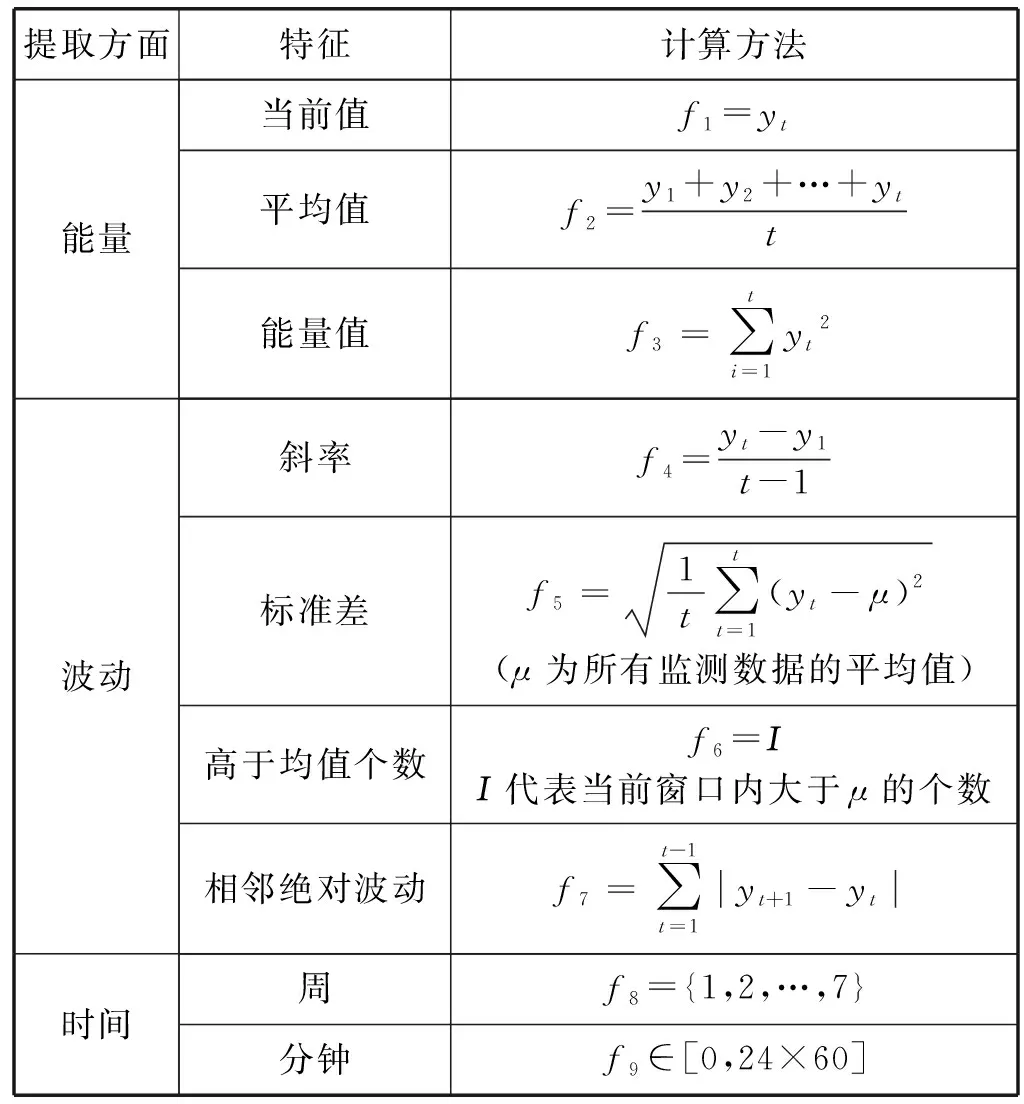
表1 基于EFT提取特征及計算方法
2.4 隨機森林
隨機森林[16]是包含一系列樹結(jié)構(gòu)分類器的集合{h(x,Θk,k=1,2,…)}。Θk是具有獨立均勻分布的隨機向量,在輸入x時,每棵樹具有相同權(quán)重,投票最多的類別即輸入x的所屬分類。建立多顆決策樹的概念第一次由Williams[17]提出。Ho[18]提出了集成過程中對每棵樹構(gòu)造使用特征子空間的方法。Dietterich[19]對構(gòu)造樹提出隨機分裂策略。隨后,Breiman[16]在2001年提出了隨機森林算法。
基于隨機森林的分類過程可分為三步:① 子訓(xùn)練集生成。從原始的數(shù)據(jù)集(大小為N)中采用Bootstrap方法有放回地采樣N次,構(gòu)成各子訓(xùn)練集,重復(fù)上述過程,共構(gòu)造M個子訓(xùn)練集,對應(yīng)隨機森林中樹的顆數(shù)M。② 特征選擇。對于森林中樹的各節(jié)點,從所有特征中隨機選擇一定數(shù)目的特征,采用基尼指數(shù)選取最優(yōu)的特征劃分節(jié)點,構(gòu)造決策樹。③ 所有決策樹最大深度生長不剪枝,最終形成由M顆樹組成的森林。森林中每棵樹具有相同的權(quán)重,對于測試樣本,通過森林投票選出的最多的類別即是該測試樣本的最終分類結(jié)果。算法流程如圖3所示。
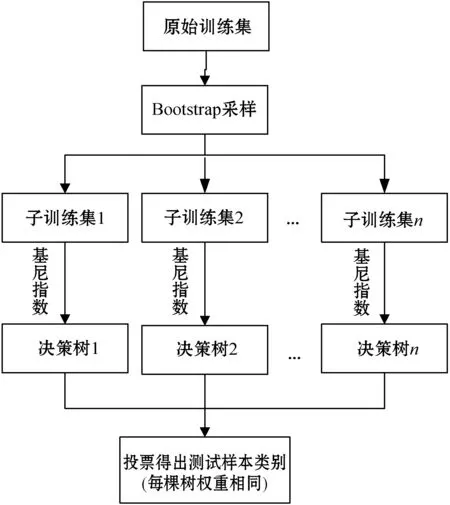
圖3 隨機森林算法流程
基尼指數(shù)是隨機森林特征選擇準(zhǔn)則,代表數(shù)據(jù)不純度,其值越低,純度越高,即數(shù)據(jù)的一致性越好,其計算方法如下。
對于給定的樣本D,假設(shè)它有K個類別,第k個類別的數(shù)量為Ck,則樣本D的基尼指數(shù)計算式為:
特別地,對于樣本D,如果根據(jù)特征A的某個值a,把D分為D1和D2兩個部分,則在特征A條件下,D的基尼指數(shù)計算式為:
隨機森林訓(xùn)練速度快、抗噪聲能力強、準(zhǔn)確率高,不容易出現(xiàn)過擬合,能夠?qū)Χ喾N數(shù)據(jù)有效分類,可處理高維數(shù)據(jù)等優(yōu)點,本文將隨機森林引入無閾值告警模型。
3 實 驗
3.1 實驗配置
本文的實驗設(shè)備為PC,配置處理器為Intel(R) Core(TM)i5-3210M CPU @ 2.50 GHz,RAM 4 GB,Windows 7操作系統(tǒng),開發(fā)環(huán)境是Python 3.7.3。本文實驗監(jiān)控項數(shù)據(jù)來源于企業(yè)級監(jiān)控平臺采集。采集2019年4月19日到5月19日共1個月內(nèi)500臺服務(wù)器的監(jiān)控項數(shù)據(jù),表2為部分監(jiān)控指標(biāo)及采集頻率。經(jīng)由數(shù)據(jù)預(yù)處理與滑窗構(gòu)造數(shù)據(jù)集。
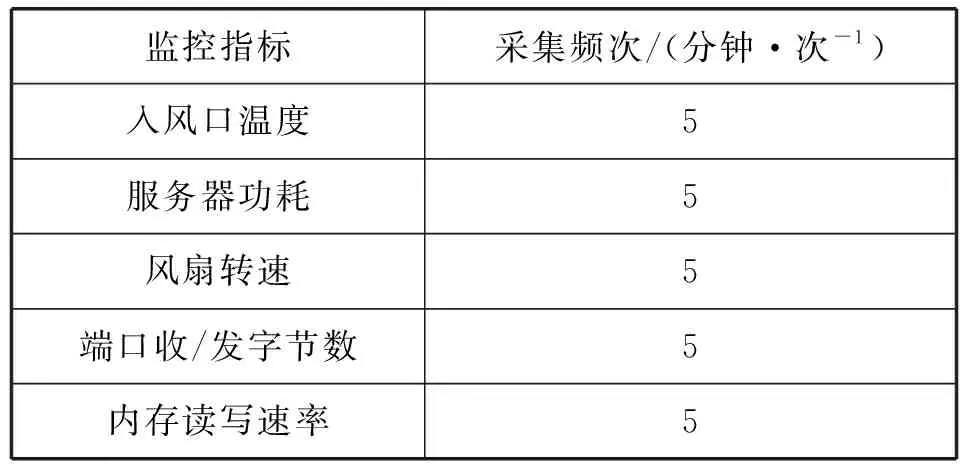
表2 部分監(jiān)控指標(biāo)及采集頻率
3.2 評價指標(biāo)
分類算法的評價指標(biāo)較多。其中準(zhǔn)確率代表分類的樣本個數(shù)與總體樣本的比值,數(shù)值越高,代表測試樣本中分類正確的數(shù)目越多。但它無法對類別不均衡的樣本做出準(zhǔn)確評價,只采用這一指標(biāo)太單一,且無法準(zhǔn)確多角度評價本文提出的無閾值告警模型。精確率代表分類結(jié)果是告警的樣本數(shù)中真實樣本為告警的樣本比例,其值越高,誤報數(shù)越少。召回率代表正確預(yù)測為告警的樣本數(shù)與屬于告警樣本總數(shù)之間的比值,其值越高,漏報數(shù)越少。所以加入精確率和召回率用以模型評價。上述評價指標(biāo)可由混淆矩陣計算得到,本文中混淆矩陣由表3所示。
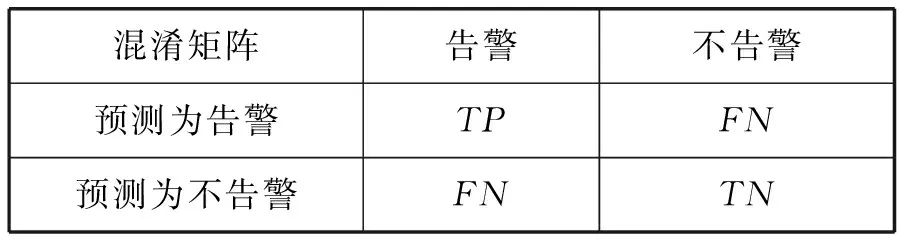
表3 混淆矩陣
準(zhǔn)確率acc、精確率pre和召回率re計算式分別為:
3.3 EFT特征提取實驗結(jié)果
圖4、圖5為本文提出特征提取方法的示例圖,其中畫有圓圈的部分即為告警數(shù)據(jù)。示例圖中的入風(fēng)口溫度與服務(wù)器功耗的數(shù)據(jù)分別為某臺服務(wù)器含告警數(shù)據(jù)一周內(nèi)的數(shù)據(jù)(60×24×715=2 016),通過滑窗得到樣本(2 016-5+1=2 012),從樣本中提取特征,鑒于篇幅有限,畫出的特征示例分別為能量中的當(dāng)前窗口能量值、波動中當(dāng)前窗口的斜率與標(biāo)準(zhǔn)差、時間時分。由圖4、圖5可見,本文提出的基于EFT的特征提取方法能夠較好地體現(xiàn)實時告警數(shù)據(jù)的變化,證實提取特征的有效性。
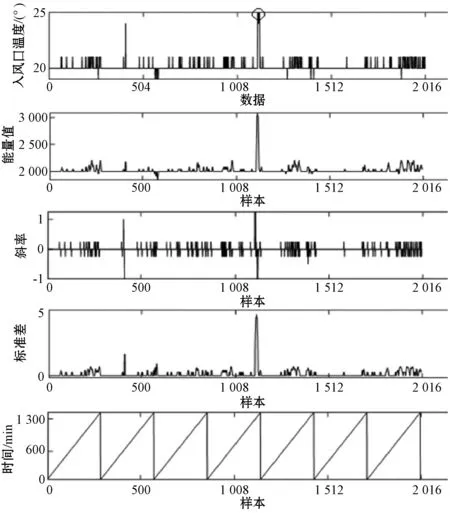
圖4 入風(fēng)口溫度提取特征

圖5 服務(wù)器功耗提取特征
3.4 分類結(jié)果

圖6-圖8分別所示為十次實驗中入風(fēng)口溫度和服務(wù)器功耗準(zhǔn)確率和精確率與召回率的數(shù)值,可以看出,兩種監(jiān)控項的準(zhǔn)確率均高達(dá)95%以上,且十次實驗結(jié)果比較穩(wěn)定。精確率與召回率相較于準(zhǔn)確率波動大,并且精確率波動相較于召回率更大,說明模型相較于誤報下更不易于漏報,并且誤報差錯率值也在10%以下。這證實了模型的有效性,可滿足實時條件下監(jiān)控項的告警需求。
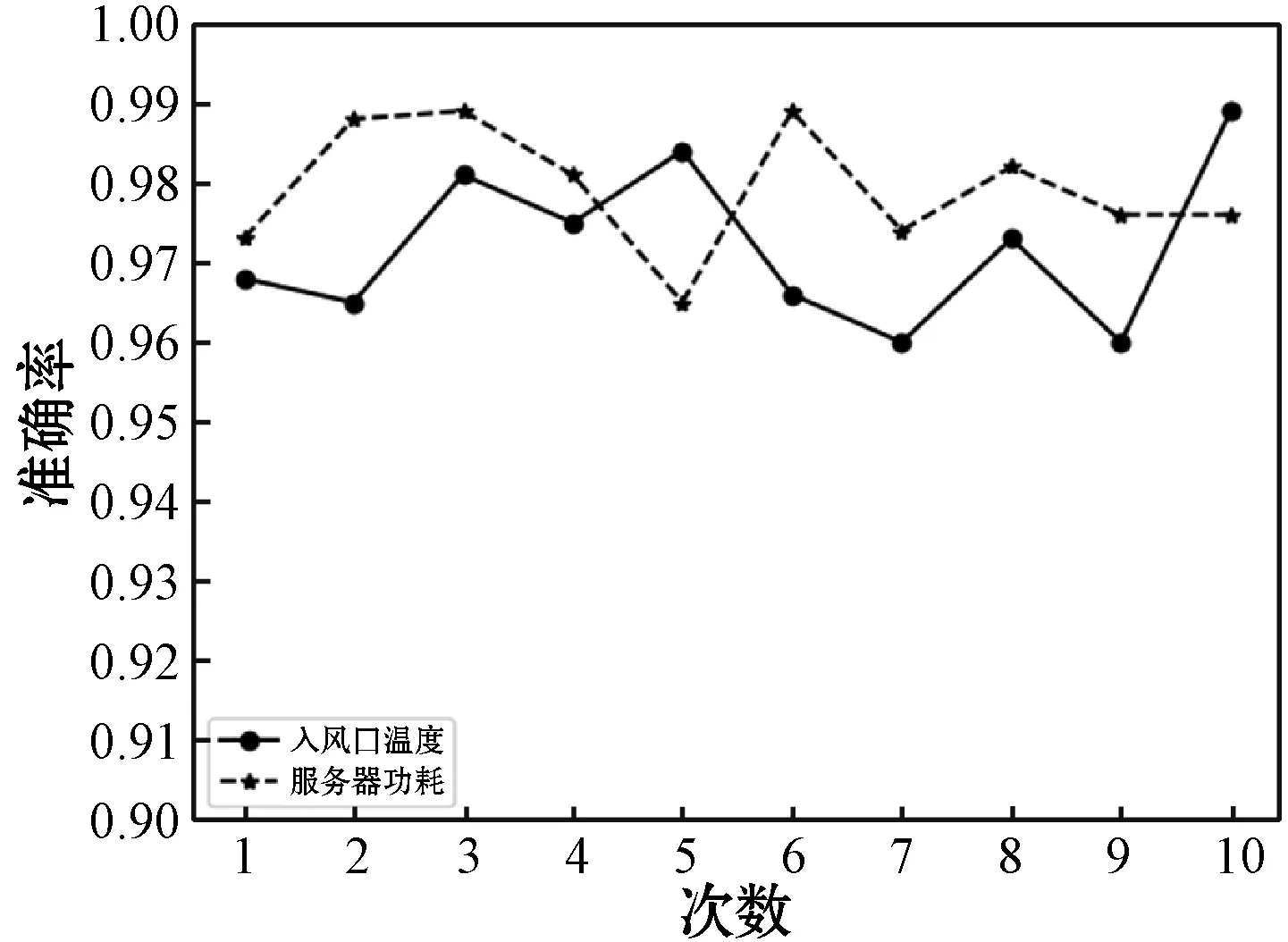
圖6 準(zhǔn)確率
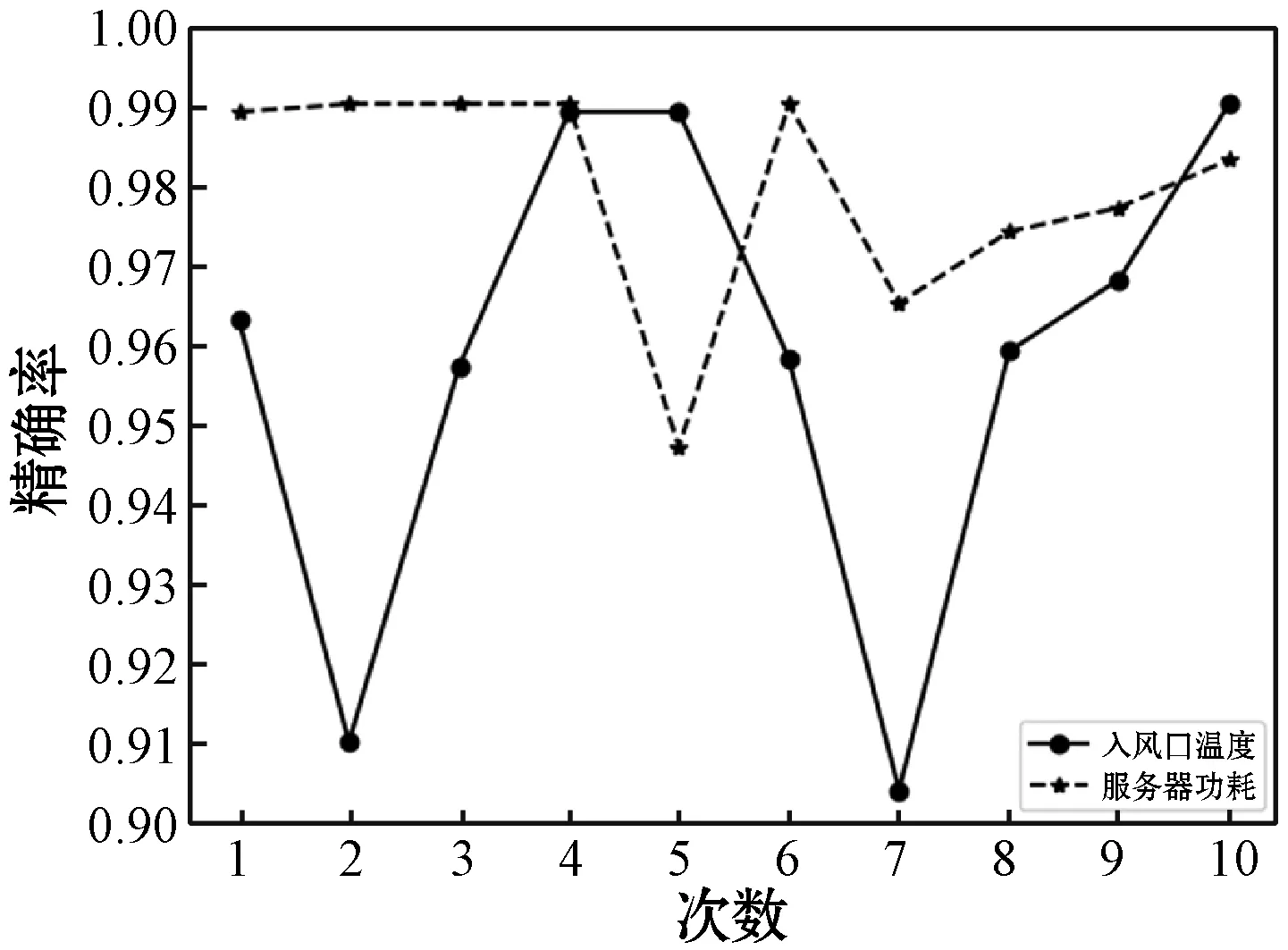
圖7 精確率
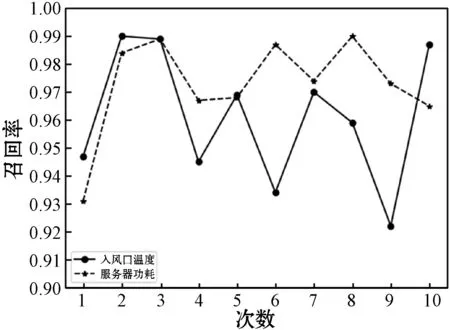
圖8 召回率
4 結(jié) 語
本文主要研究了數(shù)據(jù)中心監(jiān)控平臺監(jiān)控項的閾值告警問題,通過結(jié)合監(jiān)控項的數(shù)據(jù)特點,提出了一種基于EFT特征提取方法,最終建立了隨機森林?jǐn)?shù)據(jù)中心監(jiān)控項無閾值告警模型。實驗表明本文模型表現(xiàn)良好,準(zhǔn)確率、精確率與召回率均達(dá)到90%以上,證實了其有效性,可反映實時條件下監(jiān)控項的波動,滿足實時告警需求,并具有一定實用性,有助于運維人員分析處理數(shù)據(jù)中心告警情況。未來工作將研究內(nèi)容轉(zhuǎn)向多指標(biāo)融合告警的根因分析,因為單個監(jiān)控項的告警不利于運維人員排查根本原因,多指標(biāo)融合告警的根因分析可幫助運維人員分析告警源頭,提高工作效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
