基于一維卷積神經網絡的惡意代碼家族多分類方法研究
2021-12-14 01:28:44玄佳興韓雨桐廖會敏魏博垚
計算機應用與軟件 2021年12期
王 棟 楊 珂* 玄佳興 韓雨桐 廖會敏 魏博垚
1(國網電子商務有限公司(國網雄安金融科技集團有限公司) 北京 100053)2(國家電網有限公司電力金融與電子商務實驗室 北京 100053)3(中國科學院信息工程研究所 北京 100093)4(首都師范大學信息工程學院 北京 100048)
0 引 言
惡意代碼家族分類研究可理解為不同的惡意代碼是否源自同一套惡意代碼或是否由同一個作者、團隊編寫,是否具有內在關聯性、相似性。而以深度學習為代表的人工智能技術則被認為能夠在惡意代碼分析方面發揮重要作用。
Yuan等[1]利用受限玻爾茲曼機(Restricted Boltzmann Machine,RBM)對多層感知機預訓練,對安卓惡意軟件的檢測準確率從79.5%提升至96.5%。李盟等[2]使用n-gram頻次信息以及各API間的依賴關系,提出一種提取惡意代碼語義動態特征的方法。Jung等[3]結合了多層感知機與循環神經網絡(Recurrent Neural Network,RNN)對惡意flash進行檢測,以文件頭(Headers)、標簽(Tags)、指令操作碼(Opcodes)、API調用序列為特征,達到98.33%的檢測準確率。Pascanu等[4]將系統事件序列視為文本序列,使用循環神經網絡和回聲網絡(Erasmus Student Network,ESN)進行降維,使用最大池化配合邏輯回歸分類的方法,檢測準確率比3-gram方法更好,提高到98.3%。Saxe等[5]在40萬惡意樣本數據集上訓練一個四層感知機二分類模型,達到95%分類檢出率、0.1%誤報率。David等[6]以樣本沙箱分析報告為特征,分解報告到單詞級別后,將20 000維的輸入向量降維嵌入至30維,使用k-近鄰(k-Nearest Neighbor,kNN)分類,準確率從95.3%提升至98.6%。喬延臣等[7]對惡意樣本匯編代碼進行文本詞向量分析,并將分析特征結果轉化為圖像送入CNN進行分類,實現了98.56%的分類準確率。Yakura等[8]在卷積神經網絡分類惡意樣本的基礎上引入了注意力機制。
以上工作通過對惡意代碼的靜態特征進行提取,或者通過沙箱運行進行動態特征提取,建立惡意代碼的特征模型,有一定的主觀選擇性和時間空間開銷,相比惡意樣本的圖像信息獲取成本要高,序列信息也會丟失惡意代碼本身的某些空間特征。惡意代碼圖像特征的概念,最早是由Nataraj等[9]于2011年提出的,將惡意代碼的二進制文件轉換成灰度圖像,再結合GIST特征來進行聚類。Cui等[10]基于惡意樣本字節碼的灰度圖像對惡意樣本變種進行分類,但準確率不夠高。惡意樣本圖像是一種可以高效處理的惡意樣本特征形式,但是既有方法會造成信息丟失;卷積神經網絡對圖像有良好的分類效果,但惡意樣本圖像處理不當會引入額外的局部相關性。這兩點都會影響惡意代碼分類效果。
本文的主要貢獻包括以下幾個方面:
1) 研究惡意代碼圖像特征映射和優化,提出改進的惡意樣本圖像縮放算法(Improved Malaware Image Rescaling,IMIR),實驗證明,IMIR會提高惡意代碼多分類能力。
2) 基于一維特征圖像的卷積神經網絡(One-Dimensional Convolutional Neural Network,1D-CNN),構建高效的惡意代碼分類模型1D-CNN-IMIR。
3) 通過在公開的惡意代碼數據集上進行大量對比實驗得出1D-CNN-IMIR準確率達到98%。
1 惡意樣本圖像特征提取和優化
1.1 惡意樣本圖像特征提取
惡意樣本預處理的方式多種多樣,其中惡意樣本灰度圖像[9]預處理容易、耗時短。如圖1所示,在不依賴反匯編的情況下,將惡意樣本的8位二進制數據轉化為目標圖像的一個像素,或者說一個一維灰度圖像。
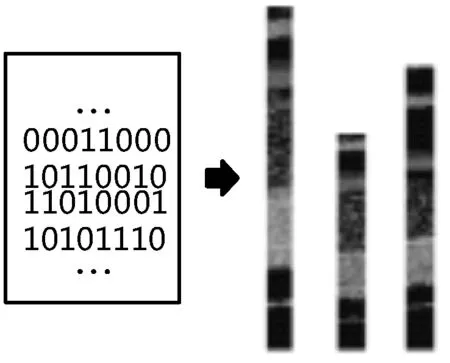
圖1 惡意代碼特征圖像映射
惡意樣本是一維的,而卷積神經網絡解決的問題大多是關于二維圖像的,從一維樣本轉換成二維圖像必然會導致關于惡意樣本特有的空間局部相關性的錯誤。如果人為地將其轉為寬度為w的二維圖像,如圖2所示,箭頭指向了在兩種維度情形下的相同數據,在原圖像中距離為w的若干點就會被重排到一列上,距離被拉近,在后續的模型中被識別為局部相關點群,而這些點之間卻可能并不存在所期望的空間局部相關性。
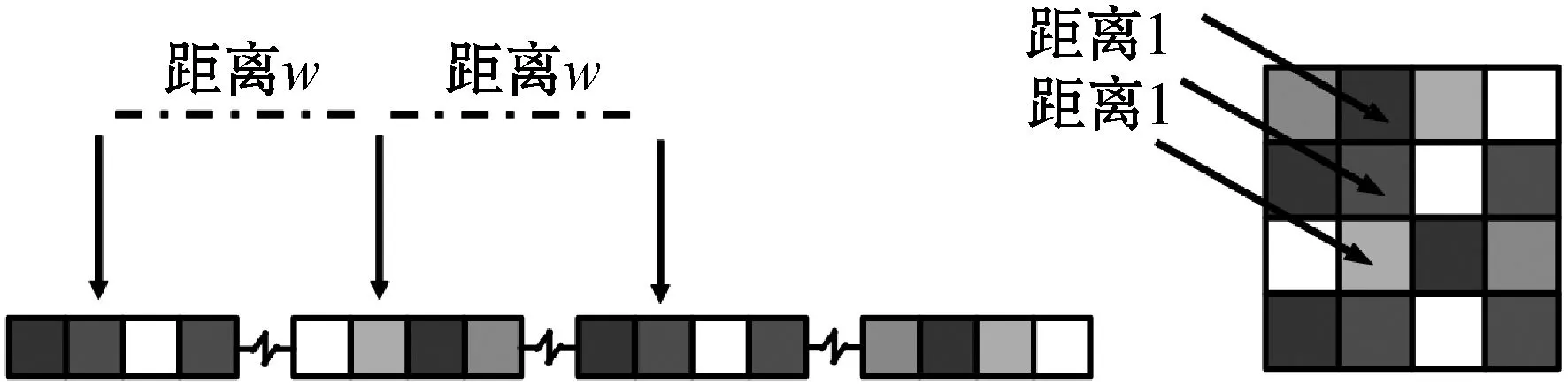
圖2 局部相關性變化示意
距離相近的點具有空間局部相關性是卷積神經網絡的主要特征之一。距離的定義決定了卷積方式,錯誤的距離定義將誤導分類網絡,使其從惡意樣本圖像上不相關的點中捕獲額外的錯誤空間局部相關性,最后導致過擬合,降低分類性能。為了緩解過擬合,去除了寬度設置,不進行圖像維度變換。
1.2 改進的惡意樣本圖像縮放算法
深度學習模型處理圖像信息前需要對多尺度的圖像進行規范化。Cui等[10]使用類似雙線性插值算法的三線性插值算法。雙線性插值算法被廣泛用作默認的圖像縮放算法。文獻[10]也使用雙線性插值對惡意樣本圖像進行了規范化處理。但是雙線性插值縮放在規范化圖像時有大量的信息損失,會影響后續分類效果。因此,提出改進的惡意樣本圖像縮放算法(IMIR)。
IMIR算法將采樣點的范圍從最近的若干個點提升至整個滑動窗口內的點,再調整了滑動方式使其更適合惡意樣本圖像,且沒有增加額外耗時,1萬個樣本耗時約1 min。在數據集中最小的樣本大小是32 KB,惡意圖像大小標準取4 096 KB。
IMIR算法基于局部均值算法,不同于真實圖像,每一個惡意軟件映像的像素同樣重要,所以應該盡可能完整地捕獲每個字節的信息,避免信息丟失。將范圍擴展到采樣窗口的邊界,調整步幅計算方法和添加填充步驟以適應本地均值惡意軟件圖片。IMIR算法偽代碼如算法1所示。
算法1IMIR算法
輸入:任意代碼原始圖像,目標圖像大小targetSize。
輸出:具有targetSize大小的惡意代碼圖像rescaledImg。
sourceSize=size(sample)
stepWidth=(sourceSize-1)/targetSize+1
fullNum=(sourceSize-1)/stepWidth
blankNum=targetSize-1-fullNum
halfLen=(sourceSize-1) modstepWidth+1
fullPart=?
foreachi∈[0,1,…,fulNum-1]do
fullPart=fullPart+[mean(sample[stepWidth*i,stepWidth*i+1,…,stepWidth*(i+1)-1])]
endfor
halfPart1=sample[stepWidth*fullNum,stepWidth*fullNum+1,…,stepWidth*fullNum+halfLen-1]
halfPart2=repeat(0,stepWidth-halfLen)
halfPart=[mean(halfPart1+halfPart2)]
blankPart=repeat(0,blankNum)
returnfullPart+halfPart+blankPart
//兩個數組之間的“+”表示連接符
2 一維卷積神經網絡構建
1D-CNN使用VGG模型[11]設計惡意代碼分類器。如圖3所示,該分類器包含五組伴隨最大池化層的卷積層、三個使用dropout的全連接層、一個不使用dropout的全連接層和作為輸出的Softmax層。
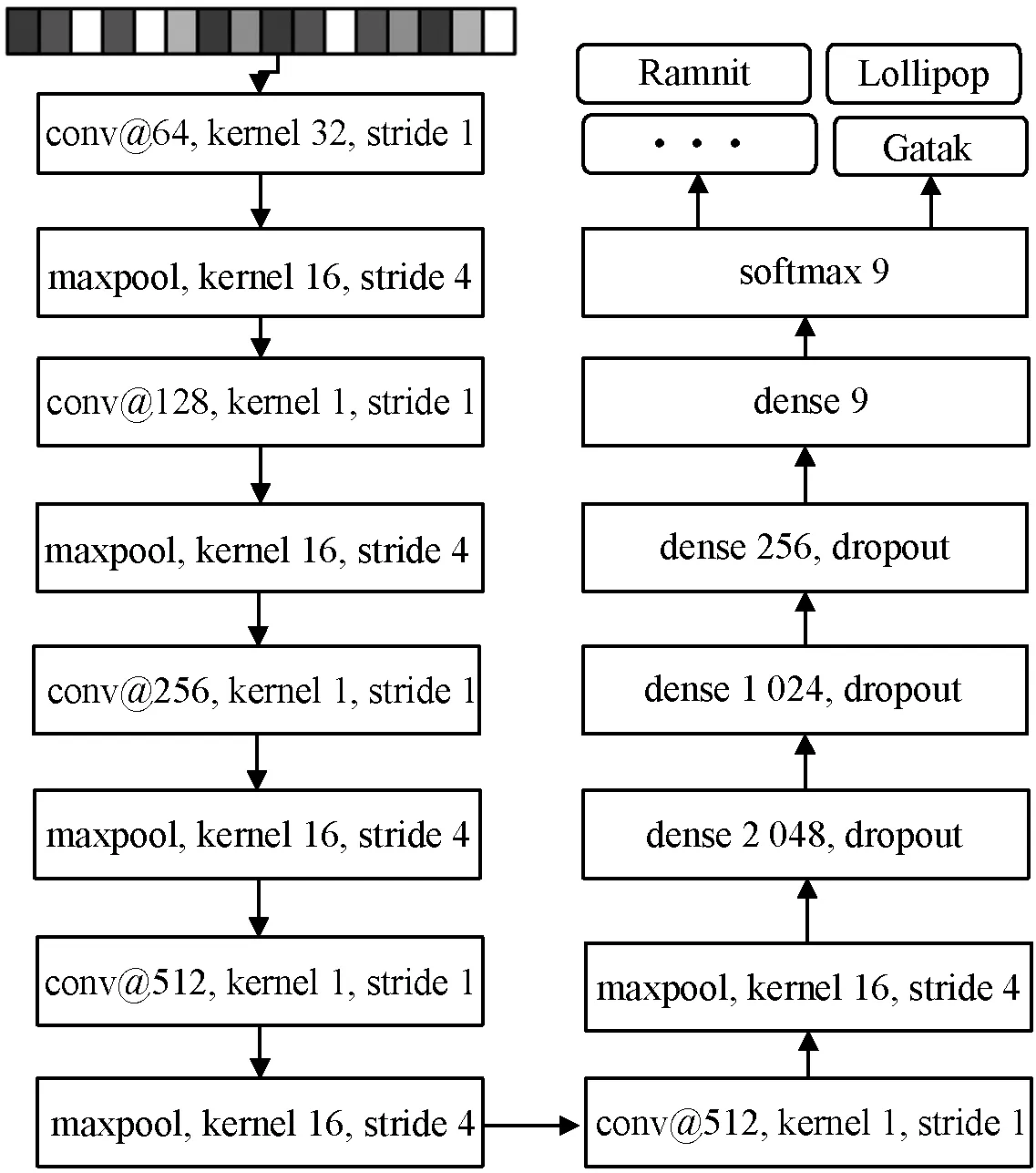
圖3 惡意樣本分類1D-CNN結構
使用IMIR算法縮放至4 096像素的惡意樣本一維圖像作為輸入,圖3中stride 1使用ReLU函數作為激活函數以緩解梯度消失[12],并提升訓練速度。輸出9個惡意代碼家族標簽的概率向量。在此以交叉熵作為損耗函數,如式(1)所示,并使用Adam優化器將其最小化到訓練數據上。
L=-Ex,y~datalnP(y|x)
(1)
式中:P(y|x)表示將惡意樣本x分類至家族標簽y的概率向量。
3 1D-CNN-IMIR模型設計和實驗環境配置
模型首先對惡意樣本進行圖形化處理,利用改進的圖像縮放方法進行預處理,然后利用一維卷積神經網絡進行識別,輸出惡意代碼家族分類如圖4所示。

圖4 1D-CNN-IMIR模型結構
3.1 實驗數據集
實驗數據集采用的是微軟2015年公開在數據競賽平臺Kaggle上的惡意樣本數據集Microsoft Malware Classification Challenge[13],該數據集廣泛用于惡意樣本研究中,便于同其他研究對比算法效果。數據集共有10 868個樣本,分為9個家族,包含了蠕蟲、木馬、后門程序等多種惡意樣本,表1詳細展示了各個樣本集的數量與種類。其中每個樣本提供了兩種文件,一種是asm文件,另一種是bytes文件,如圖5所示。
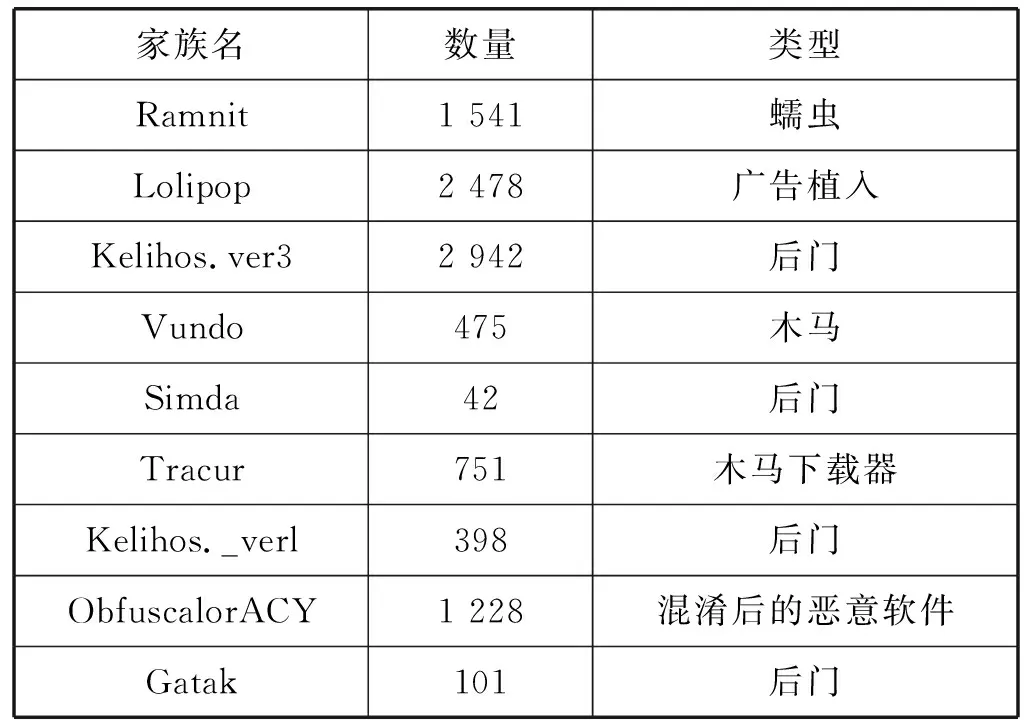
表1 Microsoft Malware Classification數據集

圖5 數據集中兩種文件內容示例
3.2 實驗評價指標
實驗評價選用了準確率(Accuracy)、精確率(Precision)、召回率(Recall)和錯誤率(Error)這四個指標。具體來說,假設在被檢測方法判斷為家族a中,實際不屬于家族a的數量為FP,實際屬于家族a的數量為TP;在被檢測方法判斷不屬于家族a的樣本中,實際為不屬于家族a的數量為TN,實際為家族a的數量為FN。準確率、精確率、召回率、錯誤率的定義分別如下:
(2)
(3)
(4)
E=1-A
(5)
此外K折交叉驗證(K-Fold Cross-Validation)是能較好地衡量泛化性能效果的一種數據集劃分方法,在實驗中,統一設置K=5。
4 實 驗
使用Adam優化器訓練卷積網絡,Adam能更快地到達全局近似最優解,節約訓練時間,更有利于調整模型參數,具體參數如表2所示。
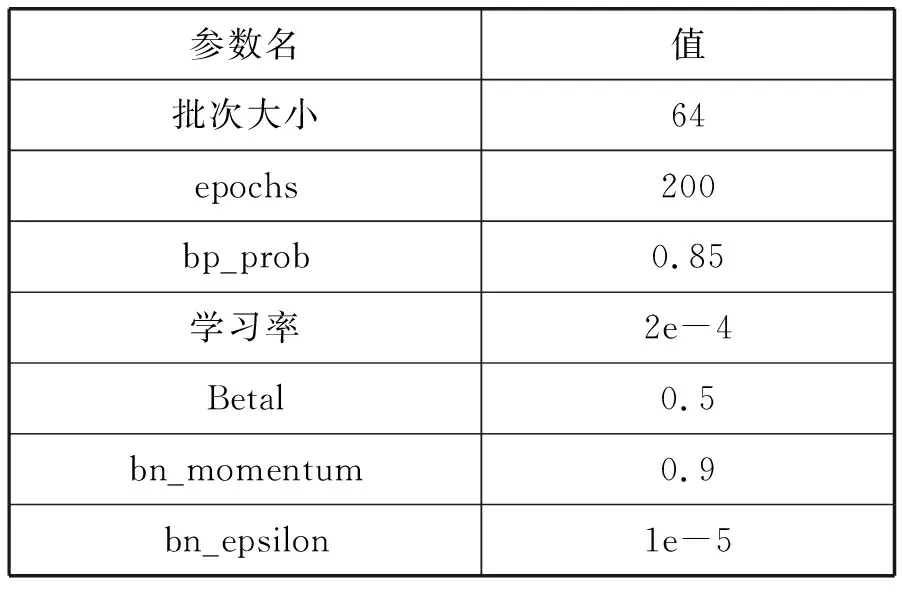
表2 模型訓練參數
4.1 IMIR算法有效性對比實驗
使用IMIR算法對惡意樣本圖像特征進行規范化處理。使用雙線性插值做對比實驗,選擇k近鄰算法(k Nearest Neighbor,kNN)、支撐向量機(Support Vector Machine,SVM)、基于二維圖像的卷積神經網絡(2D-CNN)、1D-CNN-IMIR,對比驗證IMIR算法對惡意代碼特征處理的有效性和1D-CNN-IMIR分類準確性。
由表3的數據顯示,對于kNN分類器,IMIR相對雙線性插值極大地降低了分類錯誤率;對于SVM分類器,IMIR相對雙線性插值的錯誤率提高了1.29百分點,這是因為相比kNN,SVM對特征要求較低一些,因此特征工程算法改進影響會變小;對于兩種CNN分類器,因為分類器本身有良好性能,所以錯誤率都不高,這種情況下進一步降低錯誤率已經較為困難,然而相比雙線性插值算法,不論是使用1D-CNN或2D-CNN,IMIR仍然將錯誤率降低近三分之一,說明IMIR對CNN分類器有效。
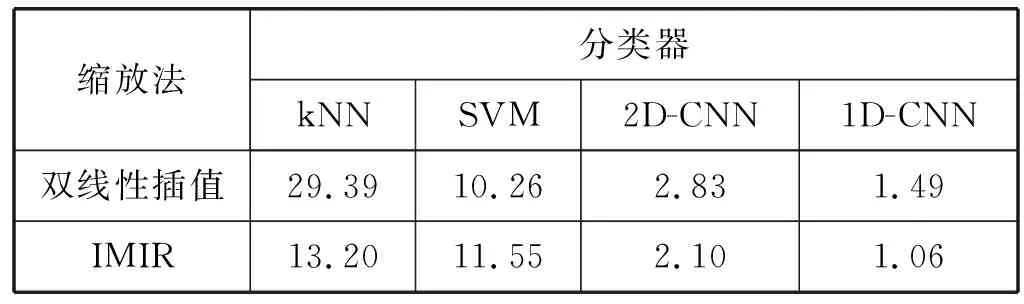
表3 不同分類器(5折交叉驗證)錯誤率(Error)對比(%)
在同時使用IMIR算法情況下,1D-CNN相對2D-CNN的錯誤率進一步降低一半,說明一維卷積神經網絡確實更加適合惡意樣本圖像特征的分析;而1D-CNN與IMIR的算法組合相對2D-CNN-雙線性插值的算法組合錯誤率降低了62.5%,說明1D-CNN-IMIR算法是有效的。
4.2 1D-CNN-IMIR模型對惡意代碼檢測實驗
統計最優方法組合1D-CNN-IMIR對各個惡意代碼家族分類效果如表4所示。平均準確率和召回率分別高達97.50%、98.65%,普遍高于97%,最差也達到了90%,說明了分類模型基本未對某些特定家族偏斜,整體較為有效可靠。

表4 基于1D-CNN-IMIR的圖像分類實驗(%)

續表4
4.3 1D-CNN-IMIR與其他深度學習算法的對比實驗
為了確保結果的客觀性,將1D-CNN-IMIR算法與其他深度學習分類算法對比研究,均在相同數據集上使用5折交叉驗證。AE-SVM[14]、tDCGAN[15]、Strand[16]是惡意樣本字節碼或灰度圖像特征維度上實驗效果最好的方法,而MCSC[17]是基于反匯編的效果最好的研究之一。
從表5可以看出,1D-CNN-IMIR相比其他四個工作,不需要反匯編或沙箱監控過程,但卻顯著地提高了分類準確率,達到98.94%;即使與需要反匯編的MCSC相比,1D-CNN-IMIR準確率仍然略占優勢。這說明了1D-CNN-IMIR對海量惡意樣本的快速分類有明顯的實際意義。
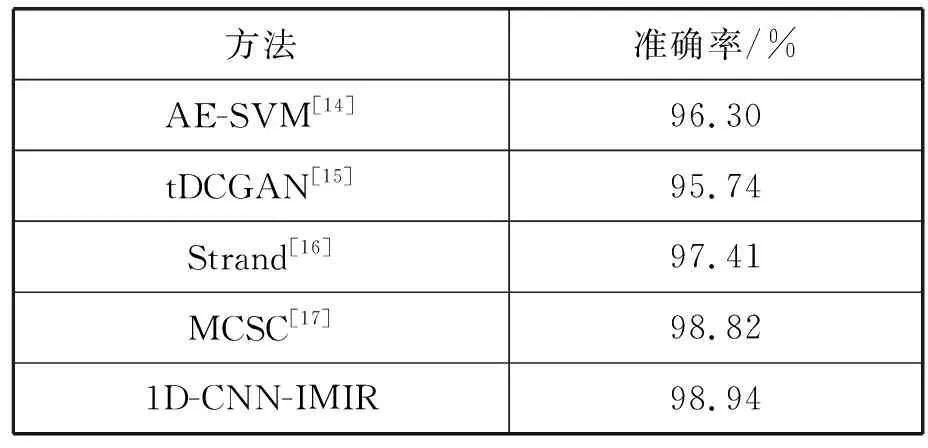
表5 相關研究準確率對比
5 結 語
本文從樣本特征提取、分類網絡結構、數據利用三方面對現有基于深度學習的惡意代碼分類研究進行了改進,提出了惡意樣本專用的圖像縮放算法IMIR,設計了基于一維卷積神經網絡的惡意樣本分類器模型。經過實驗驗證,三者協同工作,可以減少模型構建與使用的時間代價,提高更新效率,增強時效性。下一步的工作是引入生成對抗網絡,實現小樣本標簽情況下的半監督對抗生成網絡,補償樣本標簽缺乏導致的分類準確率下降。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
