基于CNN的惡意軟件分類方法
2021-12-28 23:23:05張豪
計算機時代 2021年12期
關鍵詞:深度學習
張豪


摘? 要: 傳統的基于機器學習的惡意軟件分類方法需要從惡意軟件文件中提取許多特征,這給分類帶來了很高的復雜性。針對這一問題,提出了一種基于卷積神經網絡(CNN)的惡意軟件分類方法。現有的惡意軟件樣本由大量字節組成,該方法首先計算惡意樣本大小并對樣本中字節數進行統計。然后將惡意樣本大小特征和字節統計特征融合并歸一化。最后對基于CNN構建的模型訓練并對測試樣本進行分類。實驗結果表明,對比基線實驗中最優的XGBoost算法,該方法不僅訓練耗時短而且準確率更高。
關鍵詞: 惡意軟件分類; 深度學習; 卷積神經網絡
中圖分類號:TP391? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2021)12-48-04
Abstract: Traditional malware classification methods based on machine learning need to extract many features from malware files. This brings high complexity to classification. To solve this problem, a malware classification method based on convolutional neural network (CNN) is proposed. The existing malware samples consist of a large number of bytes. This method first calculates the size of the malware samples and counts the number of bytes in the samples; Then fuses the malicious sample size feature and byte statistics feature and makes the normalization; Finally, the model based on CNN is trained to classify the test samples. The experimental results show that compared with the optimal XGBoost algorithm in the base line experiment, this method not only takes less time to train, but also has higher accuracy.
Key words: malware classification; deep learning; convolutional neural network
0 引言
惡意軟件是指,其目的是對計算機造成損害的軟件,惡意軟件會竊取信息、竊取處理器功率和導致系統故障[1]。目前有幾種惡意軟件檢測技術。基于簽名的檢測是基于在一組已知的惡意簽名字節碼上匹配字節碼[2]。簽名方法速度很快,但純粹是反動的,無法識別新的惡意軟件。行為分析在受控環境中執行程序,并觀察惡意行為,這是緩慢且有風險的[3]。啟發式分析使用文件的特征來確定它是否是惡意軟件[4]。啟發式分析受到其分類模型有效性的限制。深度學習可以用來創建分類模型,所以使用深度學習來擴展啟發式分析,有可能大大提高啟發式分析的性能。
深度學習在計算機視覺、自然語言處理等應用領域已經取得了巨大的成功。因此,深度學習技術被用來解決復雜的網絡安全問題。Popov等人[5]提出了一種基于Word2Vec和機器學習的惡意軟件檢測方法。他們把匯編指令序列看成一個文檔中的一個句子,把一個單獨的匯編指令看成一個詞,然后用Word2Vec計算樣本集上不同指令的詞向量。接下來,他們獲取每個樣本的前n個指令,將每個指令構建成一個矩陣,最后使用CNN構建一個分類模型。測試結果表明,該方法準確率達到96%。Trung等人[6]提出了一種基于自然語言處理(NLP)和API的惡意軟件分類方法。他們首先使用動態分析技術獲取惡意軟件的API調用序列,然后使用n-gram、Doc2Vec、TFIDF等自然語言處理方法將API調用序列轉換成向量。接下來,利用SVM、KNN算法等構建一個分類模型。測試結果準確率在90%-96%之間。Bugra等人[7]提出了一種基于深度學習的惡意軟件分類方法,樣本矩陣化的過程類似于Popov等人[5]的過程,然后使用GBM(梯度增強機)[8]構建分類模型,達到96%的準確率。
為了解決現有惡意軟件分類特征提取和模型訓練過于復雜等問題,本文提出了一種基于卷積神經網絡(CNN)的惡意軟件分類方法。惡意軟件樣本由大量字節組成,其值范圍從0x00到0xFF。因此,每個惡意軟件樣本都可以被視為由字節寫入的文檔。本文首先計算每個樣本的大小并對每個樣本的字節進行統計。其次,將字節統計特征和惡意樣本大小特征融合并歸一化。接下來,基于CNN構建模型在訓練樣本上訓練。最后,使用訓練好的模型對測試樣本進行分類。該方法在特征提取階段不使用專家經驗和數據依賴。該方法在降低特征維數的同時避免了過擬合。該方法在微軟惡意軟件分類挑戰數據集(BIG2015)的公共樣本集上進行了測試[9]。結果表明,該方法訓練耗時短的同時還具有較高的準確率。
1 基于CNN的分類方法
在這一部分中,將說明所提出基于CNN的惡意軟件分類的流程,如數據集選取、數據特征提取、分類模型構建。
1.1 數據集選取
微軟舉辦了一場惡意軟件分類競賽,發布了微軟惡意軟件分類挑戰(BIG2015) ,BIG 2015數據集中的每個樣本由兩個文件組成,一個是去掉PE頭的字節文件,另一個是樣本匯編代碼文件。本文僅使用字節文件,該字節文件由大量的十六進制字節組成。
1.2 數據特征提取
本文對惡意軟件字節文件的靜態特征提取包括以下兩個方面:①字節文件大小;②字節文件中0x00到0xFF的數量統計。
通過對BIG2015數據集的觀察,每個惡意軟件字節文件的大小均不相同,所以本文先計算每個字節文件的大小(以MB為單位),將其作為靜態特征之一,對采用箱線圖對其進行可視化。
從圖1中可以看到,每個惡意家族的大小均不相同且有較大差異,所以可以將字節文件大小作為惡意軟件特征之一。每個字節文件都是由0x00、0x01…0xFF組成,所以我們對其進行數量統計,然后我們將兩個特征進行融合,可以得到字節文件特征。為了降低計算復雜度,最后對每個特征進行歸一化處理,字節文件部分靜態特征如圖2所示。
1.3 分類模型
本文基于CNN設計了惡意軟件分類模型,該方法在降低特征維數的同時避免了過擬合。
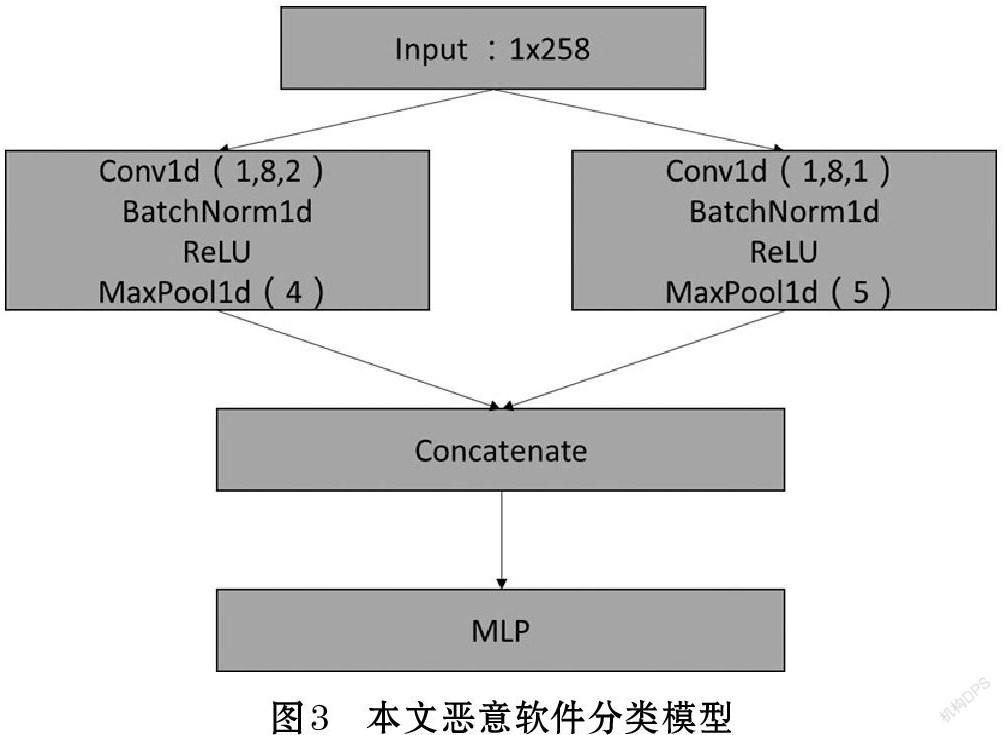
本文惡意軟件識別模型如圖3所示,每一層的功能描述如下。
輸入層:對每個惡意軟件的字節文件進行特征提取,轉換成[1×258]維的矩陣;
卷積層:采用了兩個并行的卷積結構,每個卷積結構都由1維卷積、BN層、ReLU激活函數和一維最大池化組成。通過不同卷積池化的參數,提取多種信息特征。卷積層的輸入是[1×258]維,每個卷積結構輸出維度是[8×85]。
連接層:將卷積層的輸出進行拼接,作為MLP層的輸入。連接層的輸出維度為[1×1360]。
預測輸出層:采用多層感知器(MLP)作為本文模型的預測輸出。該MLP由三層結構組成,每層結構如下:全連接層(FC)、激活函數、Dropout層。最后一層的激活函數為softmax激活函數。第一FC層的輸出維度是[1×400],第二FC層的輸出維度是[1×200],最后FC層的輸出維度是[1×9]。
2 實驗
2.1 實驗數據劃分
微軟惡意軟件分類挑戰發布的BIG 2015數據集,其中包含訓練和測試集。但是測試集沒有給出準確的分類結果,因此無法在測試集上驗證。但是訓練集有九個惡意軟件家族的10868個樣本,每個樣本信息均唯一,所以本文的實驗僅使用BIG 2015標注的訓練集。本文執行BIG2015訓練集隨機抽樣來為本文實驗生成新的訓練集、驗證集和測試集。首先,將樣本集平均隨機分為十個部分,其中一個作為測試集。剩余九個中的一個用作驗證集,剩余八個用作訓練集。最終訓練集、驗證集和測試集的比例為8:1:1。經過訓練后,使用測試集對分類模型進行測試。
2.2 實驗環境
實驗硬件環境為:Intel(R) Core(TM) i5-3210M CPU@2.50GHz,RAM 8G,Windows10系統。主要軟件和開發工具包為:Python 3.7、PyTorch v1.4.0、scikit-learn 0.22.2。
2.3 基線實驗和訓練過程
在學術領域,已經有一些將惡意軟件轉換成灰度圖像的研究工作。然后采用深度學習方法對灰度圖像進行分類。這些方法取得了良好的效果。Kim等人[10]提出了一種方法,通過深度學習分析圖像檢測惡意軟件。他們在微軟惡意軟件分類挑戰的訓練集上進行了實驗,最高準確率為91.76%。Rahul等人[11]也將惡意軟件字節文件轉換為灰度圖像,同樣在BIG 2015數據集上進行了測試,平均準確率達到94.91%。
本文將字節統計特征和惡意樣本大小特征融合并歸一化。歸一化后的特征用于訓練模型。所提出的模型與其他機器學習算法(如KNN和XGBoost等)在本文提取的特征下訓練,再進行比較。此外,本文算法還與現有取得良好效果的算法進行了對比。
我們為本文模型訓練選擇的優化方法是Adam自適應學習率算法。損失函數使用交叉熵損失函數。訓練初始學習率設置為0.0001,訓練輪數為50次。每輪單批次大小設置為128。對于所有的實驗,我們選擇在驗證集上工作最好的模型,然后在測試集上對其進行評估。
2.4 實驗結果與分析
2.4.1 實驗結果
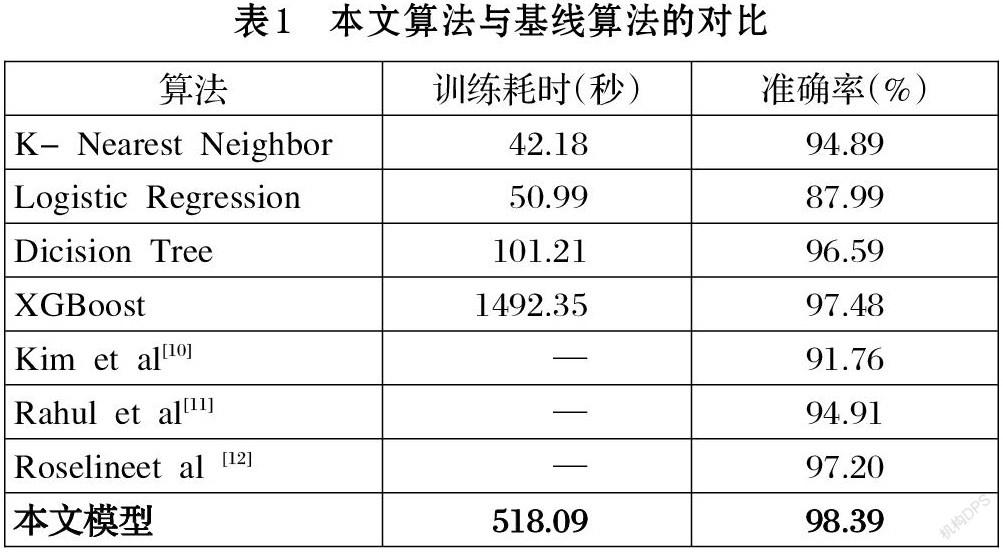
本文實驗使用的性能指標為訓練耗時以及測試集上的準確率(%)。實驗結果如表1所列。
2.4.2 實驗結果分析
從表1的結果數據可以明顯的看出:
⑴ 與所有的機器學習算法中最優的XGBoost算法相比,本文模型的訓練耗時僅為其1/3,但是本文模型的準確率達到了98.39%,相比XGBoost算法提高了0.91%,由此可得出,與XGBoost算法相比本文模型不僅訓練耗時短而且準確率更高。
⑵ 本文算法與現有的其他深度學習三種算法相比,本文的算法準確率最高。該實驗結果表明,傳統的惡意軟件灰度圖可視化方法由于填充、截斷等操作,不能完全表示所有特征,容易造成誤報,而本文通過對字節文件的特征提取方法不僅復雜度低且具有較高準確率。
3 結論
隨著當前惡意軟件分類方法中使用的特征類型的不斷增加,特征提取的難度也在增加。因此,分類的復雜性變得越來越高。本文提出了一種基于字節文件靜態特征和CNN的惡意軟件分類方法。本文首先計算每個惡意樣本的大小并對每個樣本中的字節進行統計。其次,我們將字節統計特征和惡意樣本大小特征融合并歸一化。最后我們使用基于CNN構建的模型訓練并對測試樣本進行分類。實驗結果表明,基于字節特征和CNN的分類方法不僅訓練耗時短且準確率達到了98.39%。基于該方法,可以對新的惡意軟件樣本進行分類。這將大大提高惡意軟件分析的效率。
參考文獻(References):
[1] Snow E, Alam M, Glandon A, et al. End-to-end Multimodel Deep Learning for Malware Classification[C]//2020 International Joint Conference on Neural Networks (IJCNN). IEEE,2020:1-7
[2] Santos I, Penya Y K, Devesa J, et al. N-grams-based File Signatures for Malware Detection[J].ICEIS (2),2009.9:317-320
[3] Firdausi I, Erwin A, Nugroho A S. Analysis of machine learning techniques used in behavior-based malware detection[C]//2010 second international conference on advances in computing,control, and telecommunication technologies. IEEE,2010:201-203
[4] Bazrafshan Z, Hashemi H, Fard S M H, et al. A survey on heuristic malware detection techniques[C]//The 5th Conference on Information and Knowledge Technology. IEEE,2013:113-120
[5] Popov I. Malware detection using machine learning based on word2vec embeddings of machine code instructions[C]//2017 Siberian symposium on data science and engineering (SSDSE). IEEE,2017:1-4
[6] Tran T K, Sato H. NLP-based approaches for malware classification from API sequences[C]//2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES). IEEE,2017:101-105
[7] Cakir B, Dogdu E. Malware classification using deep learning methods[C]//Proceedings of the ACMSE 2018 Conference,2018:1-5
[8] Friedman J H. Greedy function approximation: a gradient boosting machine[J].Annals of statistics,2001:1189-1232
[9] Ronen R, Radu M, Feuerstein C, et al. Microsoft malware classification challenge[J].arXiv preprint arXiv:1802.10135,2018.
[10] Kim H J. Image-based malware classification using convolutional neural network[M] //Advances in computer science and ubiquitous computing. Springer, Singapore,2017:1352-1357
[11] Rahul R K, Anjali T, Menon V K, et al. Deep learning for network flow analysis and malware classification[C]//International Symposium on Security in Computing and Communication. Springer, Singapore,2017:226-235
[12] Roseline S A, Geetha S, Kadry S, et al. Intelligent Vision-Based Malware Detection and Classification Using Deep Random Forest Paradigm[J].IEEE Access,2020.8:206303-206324
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
