
基于自然語言處理的監管文本知識圖譜構建
2021-12-31 03:24:26高赫
中國科技縱橫 2021年21期
高赫
(北京金融安全產業園,北京 100005)
近年來,互聯網與金融不斷融合,大數據和云計算等信息技術使傳統金融業務得以重塑,推動類金融機構和新金融業態快速發展,但也衍生出一定風險,對金融監管提出新的挑戰。通過調整監管方式、明確監管職能,一系列監管法規陸續出臺,力求維護金融體系健康有序發展。
就網絡借貸行業而言,目前已形成“3+1”架構的監管體系(“1”即《網絡借貸信息中介機構業務活動管理暫行辦法》;“3”即《網絡借貸信息中介備案登記管理指引》《網絡借貸資金存管業務指引》和《網絡借貸信息中介機構信息披露指引》)。為便利上述監管體系落地,作者所在機構與北京市相關監管部門合作,基于相關監管文本,采用NLP技術構建知識圖譜,實現文本內容的邏輯化,為相關金融業務的合規檢查提供支撐。
1.工作目標設定及技術方案選擇
監管文本邏輯化的核心技術方案為條件隨機場(Conditional Random Fields,CRF)以及深度學習方法的結合。
1.1 監管文本實體抽取
實體抽取主要涉及從文本中抽取出特定實體信息。目前較成熟的方法主要包括基于規則、基于統計及基于深度學習3種。
1.1.1 基于規則的方法
基于相關領域專家提供專業知識,人工構造抽取規則,再將之與文本字符匹配,以識別實體。其優點在于算法實現簡單;缺點在于隨數據集增大,人工成本增加,且規則可移植性差,不同領域的應用效果懸殊。
1.1.2 基于統計模型的方法
基于經人工標注語料訓練模型,常見模型包括隱馬爾可夫(Hidden Markov Model,HMM)、最大熵(Maximum Entropy,ME)和條件隨機場(CRF)。將實體抽取轉化為序列標注,預測標簽序列以達到抽取目的,性能明顯優于基于規則的方法。
1.1.3 基于深度學習的方法
以詞向量作為輸入,借助神經網絡完成端到端實體抽取。常見模型包括:卷積神經網絡(Convolutional Neural Network,CNN)、循環神經網絡(Recurrent Neural Network,RNN)及包含注意力機制(Attention Mechanism)的神經網絡。
單向長短期記憶神經網絡(Long Short-term Memory Networks,LSTM)模型[1]基于RNN優化,結合詞向量特征進行實體抽取。雙向LSTM(Bi-directional Long Shortterm Memory,BiLSTM)模型[2],則通過順逆序計算增強語義信息理解力,并結合CRF模型抽取實體,進一步提升準確率。
綜合上述方法優勢,本研究選擇基于已有的標注數據集和規則模板,并采用BiLSTM-CRF模型實現。
1.2 監管文本實體關系抽取
實體關系抽取本質是對抽取出的實體及各實體間關系的可能分類進行預測。與實體抽取類似,主流方法同樣是基于規則、基于統計機器學習及基于深度學習3種。
1.2.1 基于規則的方法
深入分析數據后,由專家人工設定規則,盡可能覆蓋全部領域。該方法同樣有明顯局限性,只適用特定領域,移植困難。
1.2.2 基于統計機器學習的方法
此類方法主要有2種:即基于特征向量和基于核函數。前者缺點在于可移植性差,而特征選擇也對模型效果影響顯著;后者的劣勢則在于計算復雜度高、模型訓練耗時長,效果也取決于所選特征。
1.2.3 基于深度學習的方法
該方法優勢在于可自主發現隱含語義特征,且抽取精度高。基于RNN 的實體關系抽取[3],輸入變量為向量和矩陣,以掌握詞義及其相互關系;缺點在于需學習的參數較多。基于CNN的實體關系抽取[4],預先將詞轉為輸入向量進行關系分類。Nian Yang等人于2019年提出SDP-BGRU模型[5],從非結構化數據中抽取企業(實體)關系,轉化為分類問題處理。模型使用兩實體之間最短依賴路徑(SDP),通過雙向門控循環單元網絡(BiGRU)獲取特征向量,采用支持向量機作為分類器。實驗表明,模型在測試數據集上效果良好。
鑒于監管文本部分抽象關系無法直接提取,決定采用基于BERT的雙向門控循環神經網絡模型結合注意力機制(BERT-Att-BiGRU)來訓練關系抽取模型,輸出形如“實體I~關系~實體 II ”的關系組合。
1.3 監管文本知識圖譜構建
語義網絡(Semantic Network)本質是一種有向圖:頂點代表概念,而邊表示概念間語義關系,并由此發展出多種優秀語義知識圖譜。
常見構建方法包括:基于專家知識、基于眾包數據及基于機器學習。
1.3.1 基于專家知識
Cyc和Wordnet等通過語言學家人工構建語義關系,具有結果準確度高的優點,但構建速度也因此受制約,只能適用小規模數據集。
1.3.2 基于眾包數據
ConceptNet、Yago、Wikidata、DBpedia等英文知識圖譜為此類代表。由大量志愿者共同合作構建,成本低,速度快;但個體認知差異決定了圖譜質量無法保證。
1.3.3 基于機器學習
構建方法主要基于從海量數據中獲得RDF三元組,適用于處理主、客觀世界中數量龐大的概念和實體,以及實體和概念間的復雜關系[6]。
在完成實體和實體關系抽取后,本研究將獲得的結果在圖數據庫中保存,并支持查詢操作及內容展示。
2.監管文本實體抽取
本項工作的主要任務是提取文本中行為主體名、金融產品名等要素。首先利用規則模板抽取出文本首尾的半結構化信息,對正文的復雜邏輯則采用BiLSTM-CRF模型,結構如圖1所示。
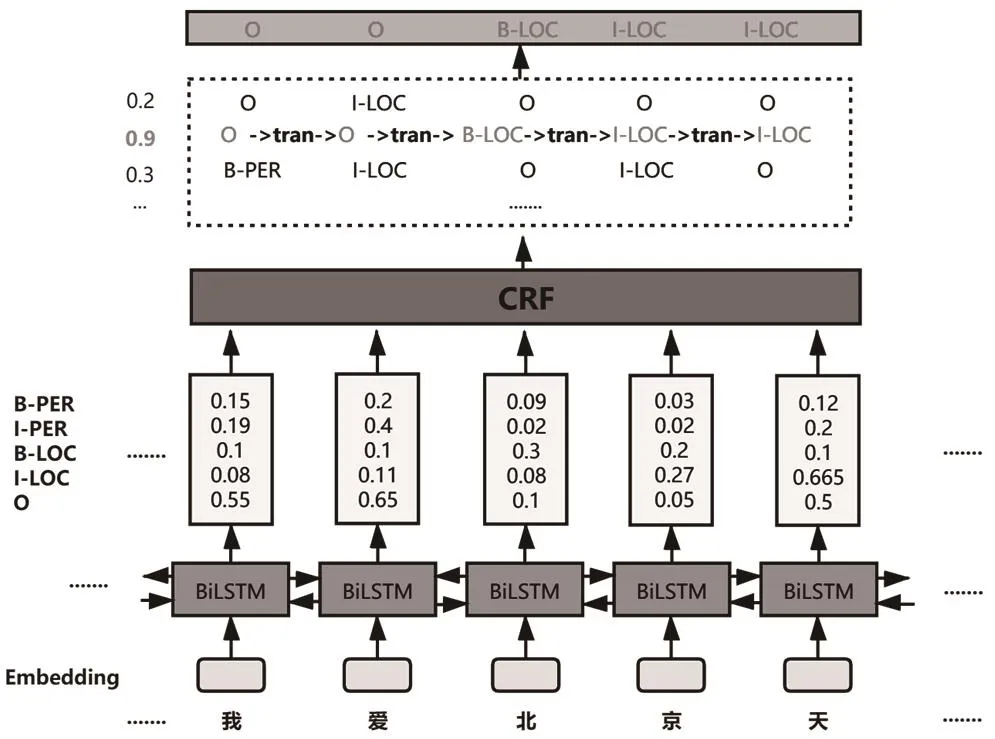
圖1 BiLSTM-CRF模型
基于1998年人民日報標注數據、MSRA微軟亞洲研究院、玻森等數據集,采用Pytorch的BiLSTM_CRF模型訓練,結果如表1所示。
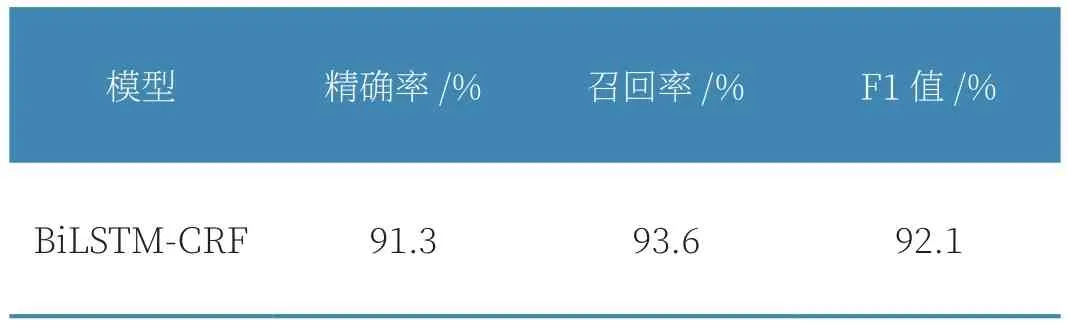
表1 BiLSTM-CRF模型測試結果
該模型既可減少工作量,又較好地完成實體抽取任務,為后續實體關系抽取任務打下良好基礎。
3.監管文本實體關系抽取
本項工作的主要任務是對抽取出的各實體間的關系進行預測,本節針對法律文書中正文的實體關系抽取任務,使用 BERT-Att-BiGRU模型,以一段文本及2個實體作為輸入,輸出實體間關系。模型結構如圖2所示。
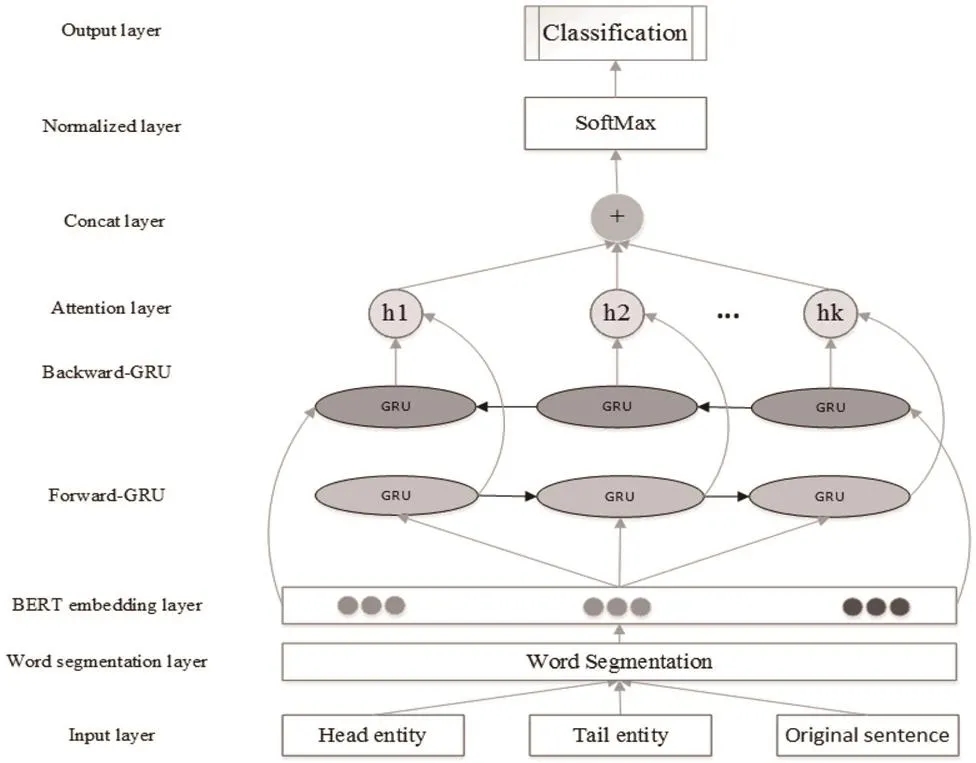
圖2 BERT-Att-BiGRU模型
模型融合BERT、雙向門控循環單元以及注意力機制,對經人工標注的2000條監管規定進行訓練,結果如表2所示。
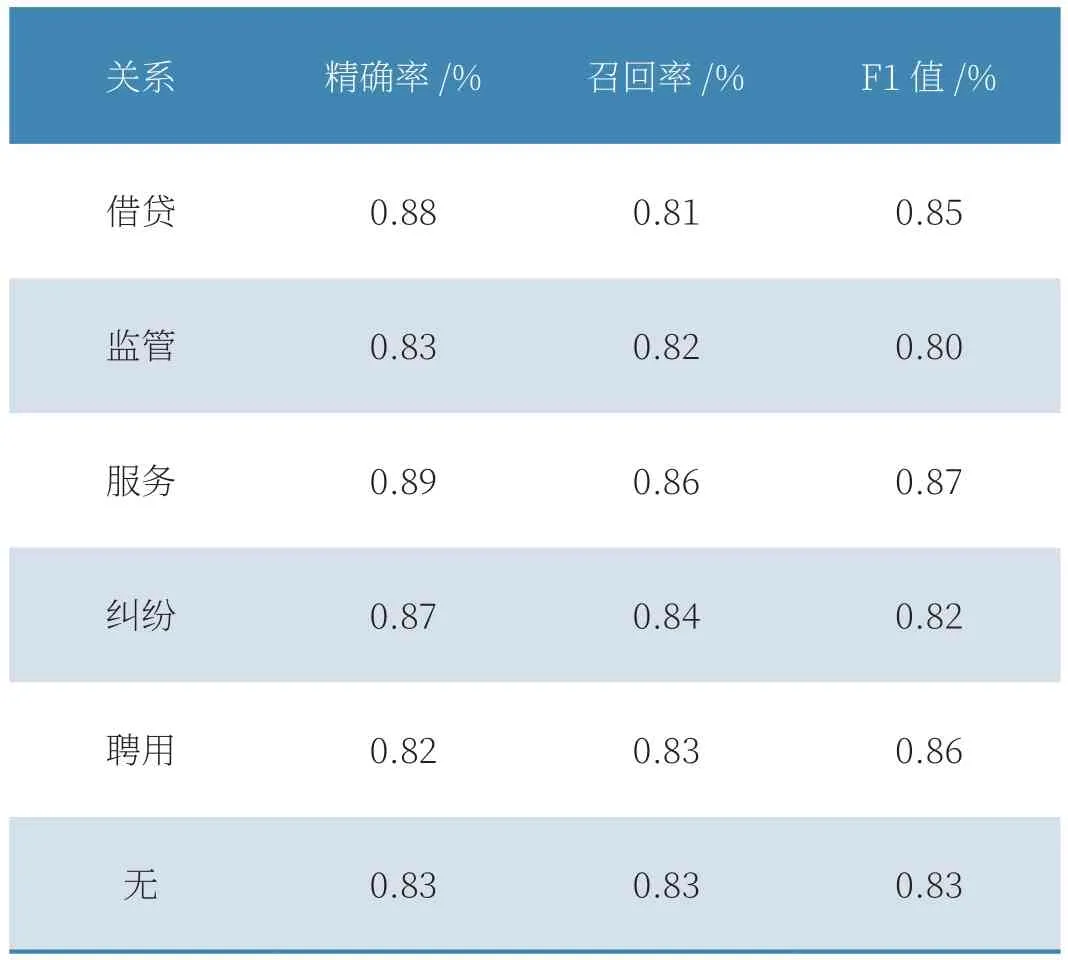
表2 BERT-Att-BiGRU模型測試結果
實驗結果證明該模型準確率可達80%以上,能夠有效提取關系三元組,為構建復雜知識圖譜系統提供了便利。
4.監管文本知識圖譜構建
將前兩步從監管文本中提取出的實體及實體關系三元組存儲至Neo4j圖數據庫(如圖3所示),共抽取43項合規風險指標、21項管理風險指標(如表3所示),實現對網貸業務的合規監測。
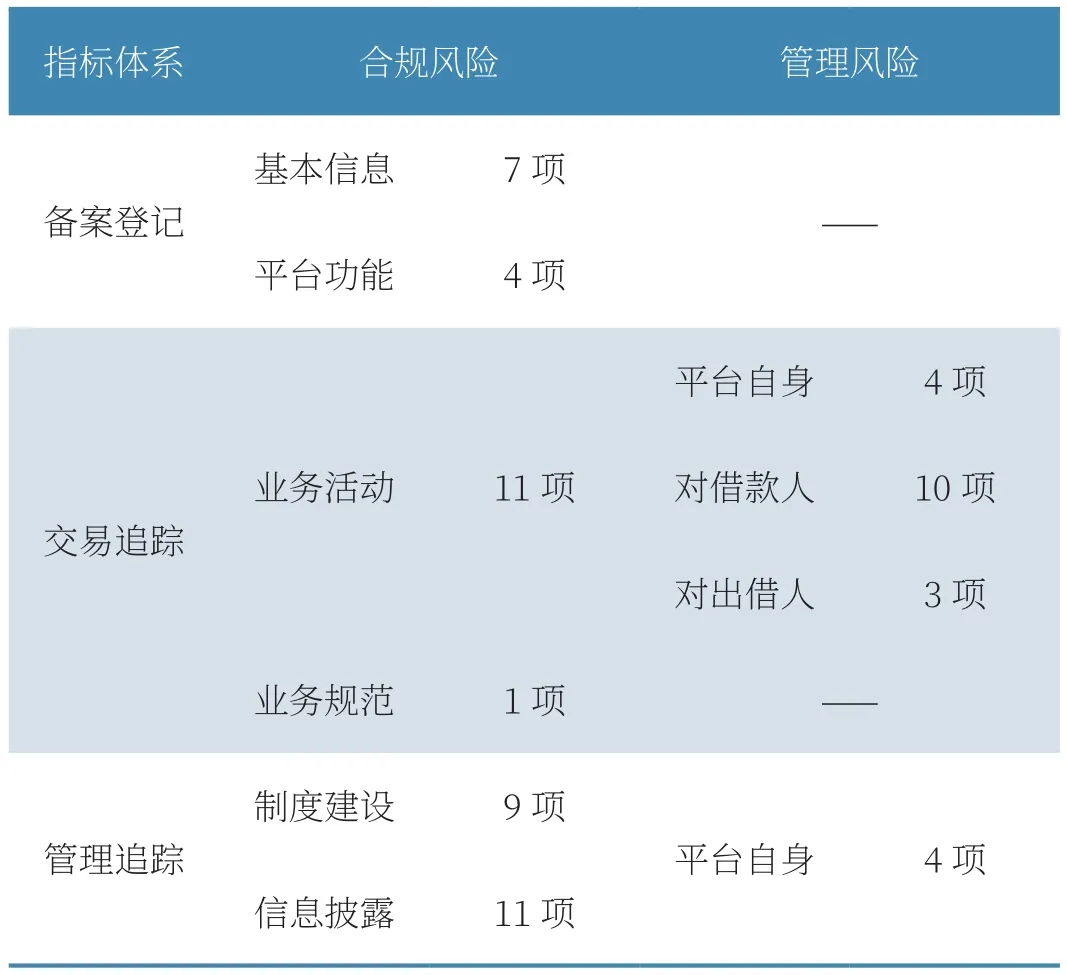
表3 風險監測指標抽取結果
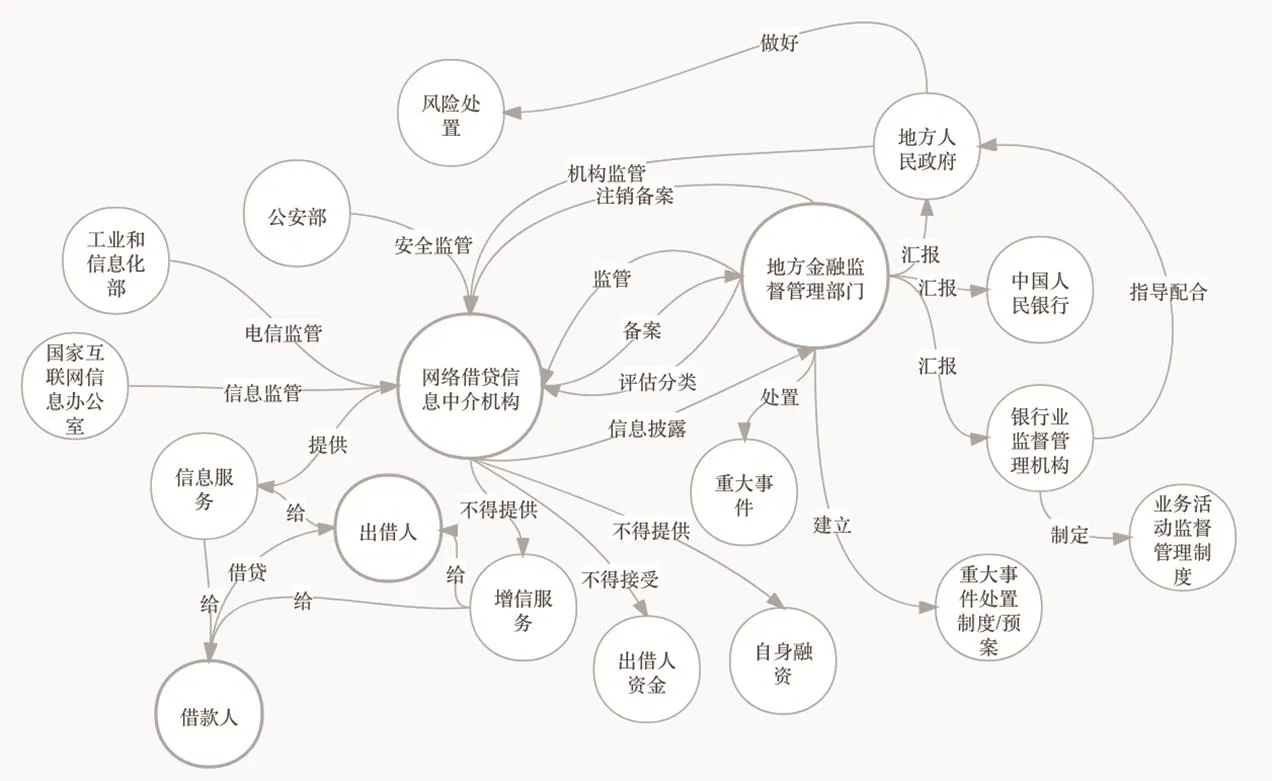
圖3 Neo4j圖數據庫(局部)
5.結語
本次研究圍繞監管文本知識圖譜構建,探索了具體構建方法并實際測試。實驗結果表明,所采用的方法能有效抽取監管文本中的實體及實體關系,并構建知識圖譜,便利相關金融風險的監測和預警。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
