基于體感識別技術的運動訓練輔助系統(tǒng)設計
2022-01-06 12:33:08鄭永權張飛云周帥
電子設計工程 2021年24期
鄭永權,張飛云,周帥
(西安交通大學城市學院,陜西西安 710018)
隨著經濟水平的提高,人們更加注重身心健康,積極參與運動鍛煉[1-2]。隨著無線通信和圖像處理技術的迅速發(fā)展,新型運動裝備以智能化的互動方式正改變著人們的運動習慣[3-5]。傳統(tǒng)的運動裝備只是簡單地記錄運動者的運動時間、距離等物理信息,并根據(jù)簡單的統(tǒng)計學計算得出相關運動建議[6]。而以Kinect、VR 為代表的新型運動裝備具有捕捉人的運動姿態(tài)、豐富運動場景等功能,增強了運動的趣味性。
體感識別是指通過某些裝置識別人的肢體動作,從而實現(xiàn)某些功能,其被應用于多種場景,常見的有運動類游戲、手勢拍照、人臉支付等[7-9]。迄今為止,業(yè)界學者對于體感技術的分類主要基于其實現(xiàn)原理來進行劃分,通常分為慣性感測、光學感測、慣性與光學聯(lián)合感測以及其他方式感測。其中,應用最廣泛的體感設備是由日本索尼公司開發(fā)的EYE TOY[10-16]。
該文將體感識別技術應用于常規(guī)運動訓練中,以Kinect V2 為運動數(shù)據(jù)采集設備,利用分隔策略降低數(shù)據(jù)量,同時精簡骨骼關節(jié)個數(shù)從而降低動作識別的復雜度,并通過尋找標準化模量的方法來降低絕對數(shù)據(jù)引發(fā)的偏差。采用堆疊模型和VGG 卷積神經網絡將二維關節(jié)數(shù)據(jù)轉換成人體姿態(tài)圖,并將其作為模型的訓練樣本,完成訓練和參數(shù)優(yōu)化后,最終得到運動動作識別模型。
1 基于體感識別技術的運動訓練輔助系統(tǒng)框架
文中利用Kinect V2 配備的攝像頭傳感器、計算機、顯示設備、云服務器來進行運動訓練輔助系統(tǒng)的硬件設計,具體硬件連接如圖1 所示。首先,計算機作為整個系統(tǒng)程序的執(zhí)行中心,負責接收用戶的身份認證信息和Kinect V2 攝像頭傳感器采集的數(shù)據(jù),然后將相應數(shù)據(jù)傳送至顯示設備和云服務器;Kinect V2 攝像頭傳感器負責采集用戶的肢體動作,并將數(shù)據(jù)傳輸至計算機;顯示設備負責顯示運動訓練輔助系統(tǒng)的用戶登入界面、訓練實時動作識別結果、訓練日記等信息;云服務器負責接收用戶上傳的運動訓練數(shù)據(jù)和系統(tǒng)更新數(shù)據(jù)包等。
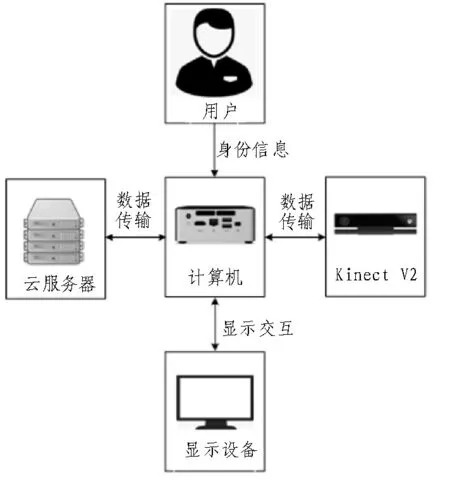
圖1 硬件連接示意圖
文中所述運動訓練輔助系統(tǒng)采用C/S 框架,考慮到用戶較多,因此采用多個客戶端與一個服務端進行設計。其中,客戶端在功能上涉及對用戶實時運動動作的識別、動作分析、用戶信息采集、數(shù)據(jù)儲存與服務端的通信等;而服務端主要位于云服務器,涉及客戶端的系統(tǒng)更新、歷史運動訓練數(shù)據(jù)儲存等。系統(tǒng)框架如圖2 所示。該系統(tǒng)軟硬件之間通過USB 3.0 進行數(shù)據(jù)的傳輸;客戶端與服務端之間的通信采用TCP/IP 通信協(xié)議。

圖2 系統(tǒng)框架示意圖
2 運動識別算法與實現(xiàn)
2.1 人體動作數(shù)據(jù)采集
當人在運動時,通過Kinect V2 攝像頭傳感器采集到的視頻數(shù)據(jù)通常具有較大的容量,不適合直接進行動作分析;另外,由于人物所處環(huán)境較為復雜,濾除背景可提高人物動作的識別精度,因此需要進行數(shù)據(jù)預處理。
Kinect V2 采用紅外發(fā)射器投射經過調制后的近紅外光,通過解析近紅外光經物體反射回來的時間差來得到物體與Kinect V2 攝像頭傳感器的距離,使用近紅外光線可有效降低光線變化對成像質量的影響。另外,在識別人體動作時采用分隔策略將人物從背景中分離出來,并在后續(xù)識別過程中只保留人物的圖像,以降低人物動作識別計算量。
由此得到的人物深度圖中通過機械學習算法可以識別人物的骨骼點,骨骼點的移動表示人物身體各個部分的移動。如圖3 所示,將人體簡化為18 個關節(jié)部位,通過觀察這18 個點的位置移動來判斷人體的動作。任何運動動作的識別均基于人體肢體的基礎動作,這些基礎動作包含肢體彎曲、關節(jié)扭轉等。由于人體身體構造的限制,肢體轉動的角度均不超過180°,因此可以選擇余弦函數(shù)作為肢體轉動角度函數(shù)。
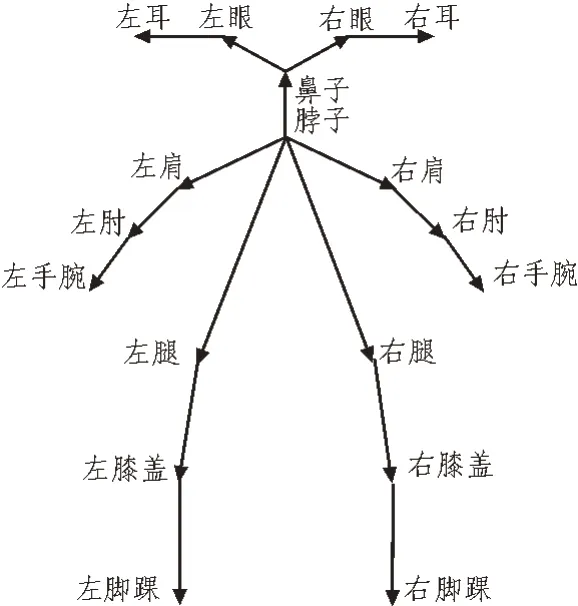
圖3 人體關節(jié)示意圖
2.2 多目標動作追蹤
通過攝像頭傳感器采集人體6 個基礎動作的18個關節(jié)點的位置信息,這些位置信息將作為基礎動作要素。每一個關節(jié)點的位置信息均由二維坐標組成,將一段時間的關節(jié)點位置信息組成數(shù)據(jù)集,即可得到諸如跳躍、站立等基礎動作的數(shù)據(jù)模板。當人在做復雜動作時,則需要使用多目標跟蹤來捕捉關節(jié)點位置數(shù)據(jù)。其具體流程如圖4 所示。
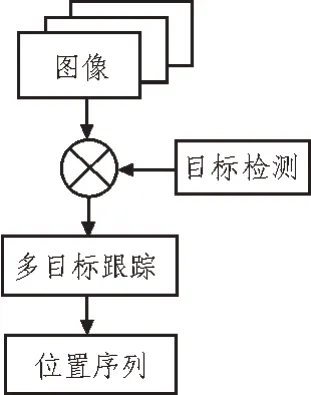
圖4 多目標跟蹤算法流程圖
文中使用Deep Sort 多目標算法進行關節(jié)點位置信息的獲取。該算法對攝像頭采集到的每一幀畫面進行目標檢測,并將檢測結果經有權值的匹配算法處理后與之前運動軌跡相比較,形成關節(jié)的運動軌跡。其中,權值的確定需要通過點和運動軌跡的馬氏距離來計算,而馬氏距離則通過Kalman 濾波函數(shù)計算。當前軌跡與之前軌跡是否匹配,需要設定一個閾值來進行比較,該閾值被定義為相鄰時刻畫面的軌跡匹配成功所用的時間差。當該時間差大于閾值時,表明相鄰時刻畫面的軌跡長時間匹配不成功,則認為該動作已停止。在匹配過程中可根據(jù)不同特征的最大響應數(shù)值來分配權重值,具體計算公式為:
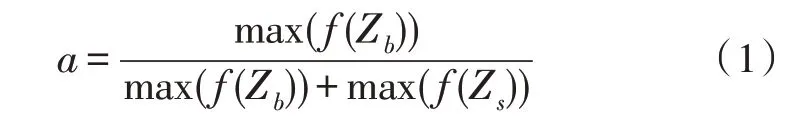
式中,f(Zb)、f(Zs)表示圖像邊緣特征的梯度角度以及色度飽和度的響應輸出向量。
上文提取到的關節(jié)骨骼位置數(shù)據(jù)中包含著大量的噪聲數(shù)據(jù)和無用數(shù)據(jù),在進行動作識別前需要進行數(shù)據(jù)預處理來提高有用數(shù)據(jù)的比例。文中使用尋找標準化模量的方法,來降低絕對數(shù)據(jù)引發(fā)的偏差。人體固有肢體結構數(shù)據(jù)所提取的向量因受人體動作變化影響較小,故可作為標準向量。通過調用Open Skeleton Frame()函數(shù),可實現(xiàn)骨骼數(shù)據(jù)的獲取。
2.3 運動訓練實時動作識別模型
利用上文獲取的多目標骨骼數(shù)據(jù),文中以自下而上的順序對關鍵關節(jié)進行檢測,并依據(jù)關鍵關節(jié)的分布位置來確定人的姿態(tài)。為了實現(xiàn)更精準的人體姿態(tài)識別結果,文中將VGG 和卷積神經網絡相結合進行關鍵關節(jié)的檢測。其具體結構如圖5 所示。首先將Kinect V2 攝像頭采集到的畫面輸入至VGG中進行特征向量F的提取;再將特征向量F作為卷積神經網絡第一階段的輸入,通過多個階段的回歸得到該圖片的關鍵關節(jié),并在第二階段利用貪心推理識別各個關鍵關節(jié)的相對位置,形成人體骨骼的姿態(tài)。
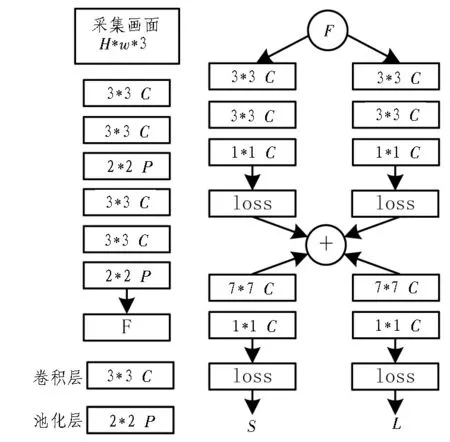
圖5 人體姿態(tài)估計算法結構圖
為了實現(xiàn)實時連續(xù)動作的識別,需要對每一個畫面的人體姿態(tài)進行綜合分析。該文利用上文得到人體姿態(tài)圖,通過搭建堆疊模型來實現(xiàn)實時運動動作的識別。具體過程如下:
1)將每一幀的人體姿態(tài)圖進行預處理,得到數(shù)字圖像特征,并用one-hot encoding 進行編碼;
2)將線性堆疊模型和VGG 卷積神經網絡聯(lián)合訓練,使用Relu 作為激活函數(shù),Soft max 作為分類函數(shù);
3)使用Compile 對模型參數(shù)進行設置,并在樣本數(shù)據(jù)訓練時進行參數(shù)調優(yōu);
4)使用測試數(shù)據(jù),驗證模型對訓練動作識別的準確度。
在上述堆疊模型中融入Batch Nor maization,該函數(shù)可將數(shù)據(jù)歸一化,使得每個數(shù)字圖像特征的分布均值為0、方差為1。由于實時采集的圖像數(shù)據(jù)較多,為了增強實時識別效率,利用數(shù)據(jù)的規(guī)范化和線性變換來實現(xiàn)VGG 卷積神經網絡中不同層之間的解耦,最終實現(xiàn)整個人體運動動作識別模型的學習速度。
堆疊模型在規(guī)范化數(shù)據(jù)時,具體表達式為:
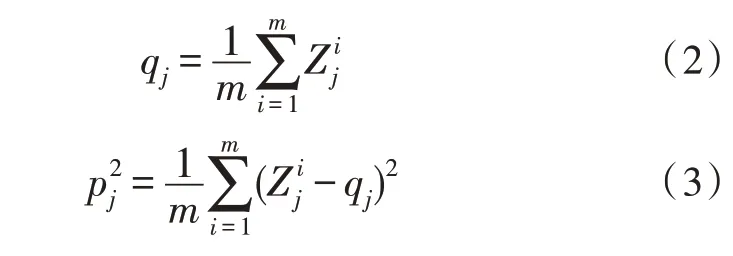
對于動作識別的精度,分類器的選擇尤為重要。文中將Softmax 作為動作識別分類器,該函數(shù)的表達式為:

該函數(shù)將VGG 卷積神經網絡的神經元輸出映射為(0,1)之間的實數(shù),且總和為1。式(4)中Vi表示Softmax 分類器前級神經元的輸出,i表示動作的類別,C為動作類別的總數(shù),Si表示當前動作分類的概率值與所有動作分類概率和的比值。
3 測試與驗證
為了驗證該文所述方案的有效性和可行性,文中使用揮手、踢腿、彎腰和蹲4 個動作進行驗證。測試過程中使用Intel(R)Core(TM)i7-3470 CPU@3.2 GHz,16 GB 的計算機;代碼編輯器使用Sublime Text。首先選擇5 名男生、5 名女生作為志愿者,為了保證較高的模型識別精準度,該10 名志愿者應具有不同的身高、體重等外形。分別讓這10 名志愿者做100 組上述4 種動作,并按照8∶2 的比例劃分為樣本訓練數(shù)據(jù)和驗證數(shù)據(jù)。由于動作識別數(shù)據(jù)多分類問題,需要對上述動作進行編碼,即將揮手、踢腿、彎腰和蹲分別使用0、1、2、3 表示。圖6 給出了訓練數(shù)據(jù)和驗證數(shù)據(jù)的訓練精度結果對比。從圖中可以看出,通過增加訓練次數(shù),訓練數(shù)據(jù)和驗證數(shù)據(jù)的精度曲線逐漸重合并趨向于0.86,這表明該文所述方案具有較好的穩(wěn)定性和魯棒性。
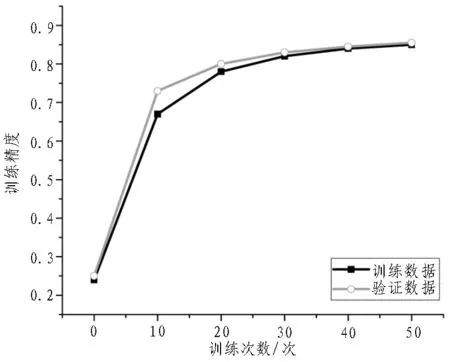
圖6 訓練數(shù)據(jù)與驗證數(shù)據(jù)的訓練精度對比結果
另外,為了驗證該文所述方案的實用性,使用LSTM 動作識別算法作為對照組進行對比試驗,對照組與實驗組使用相同的軟件、硬件設備和訓練數(shù)據(jù)。表1 給出了實驗組和對比組的4 種動作識別準確率結果。由表可知,文中所述方案比LSTM 動作識別算法具有更高的識別準確率,這表明該文所述方案具有一定的可行性和實用性。值得注意的是,兩種動作識別算法對彎腰和蹲的識別準確率均較低。這主要是由于做這兩種動作時,關節(jié)存在重疊現(xiàn)象,僅靠一個攝像頭采集的數(shù)據(jù)難以有較高的區(qū)分度。
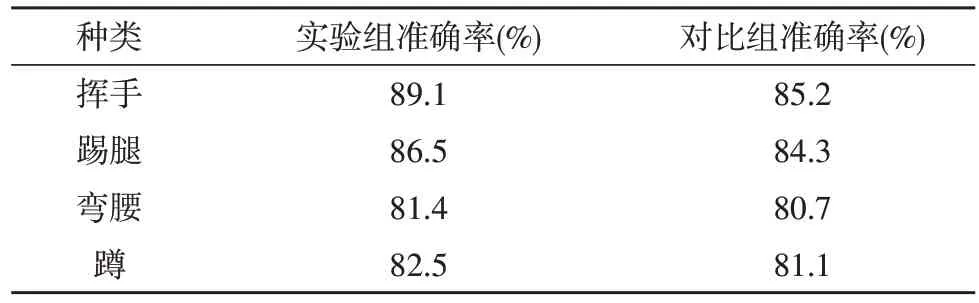
表1 實驗組和對比組的4種動作識別準確率結果
4 結束語
該文將體感識別技術與機器學習中的VGG 卷積神經網絡應用于運動訓練輔助系統(tǒng)的設計中,以提高對人體實時動作的識別準確率。該運動訓練輔助系統(tǒng)將采集到的實時畫面進行人物與背景分離,并采用18 個關鍵關節(jié)的數(shù)據(jù)使用VGG 卷積神經網絡來構建人體姿態(tài)圖,并利用堆疊模型實現(xiàn)實時連續(xù)動作的識別。通過驗證實驗,證明了文中所述方案具有一定的魯棒性和可行性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
