基于花粉算法的廣域無線傳感器網絡最優數據聚合設計
2022-01-07 08:54:20蘭婷婷秦丹陽孫冠宇
黑龍江大學自然科學學報 2021年5期
蘭婷婷, 秦丹陽, 孫冠宇
(黑龍江大學 電子工程學院, 哈爾濱 150080)
0 引 言
無線傳感器的廣泛使用以及將其組織到網絡中時會存在許多部署問題,能量的高效利用是最主要問題之一。因此,需要有效地使用傳感器中有限的能量來維持網絡性能,使服務質量(Qualit of seyrvice, QoS)不會受到影響[1]。為此,研究者開發了許多節能技術,如媒體接入控制(Media access control, MAC)協議、路由協議和數據聚合技術等,其中數據聚合是最常用的技術,能夠有效降低網絡能耗,減少網絡擁塞[2]。除了提高系統效率之外,數據聚合還有助于培養可擴展的網絡[3],能夠輕松擴展到大型系統。
目前,無線傳感器網絡(Wireless sensor network,WSN)中的聚類協議已被廣泛研究,典型的聚類協議LEACH是一種基于數據聚合的層次型路由協議,通過隨機方式進行簇頭(Cluster head, CH)的選擇,來避免簇首能量消耗過度,同時將數據進行聚合處理能夠有效地減少網絡中的通信量[4],但是LEACH不能使用任何目標函數提供CH的最佳選擇,且僅在小覆蓋區域上進行有效工作,所以不能用于大規模的WSN中。HEED是一種分簇聚類協議[5],其分簇速度更快,能產生分布更加均勻的簇頭、更合理的網絡拓撲[6]。HEED算法中簇頭會直接和基站進行通信,由于沒有考慮它們之間的距離,會造成節點能量快速消耗[7]。在解決廣域的無線傳感器網絡聚類問題時,采用扇形聚類協議(Fan-shaped clustering, FSC)進行簇頭的選擇既簡單又很有效,有利于降低網絡中通信成本,但是FSC算法在執行的時候不強調所需的QoS[8]。也可以在網絡中使用其他聚類方法,包括K均值和模糊C均值[9],這兩種方法都是采用隨機選擇k個中心點,剩余節點與最近的中心點分組,但是如果沒有謹慎地選擇起始點,則這兩種聚類方法都可能產生較大的分歧或收斂到局部最優。文獻[10]提出了一種適用于大規模傳感器網絡的聚類算法,該算法在實現過程中考慮了聚合網絡規模,信息表達能力和能量消耗情況,能夠提供更好的網絡性能。在廣域的無線傳感器網絡中研究聚類算法和路由協議時,由于接收器附近的節點經歷更多的數據量,會出現能耗不平衡問題[11-12]。因此,文獻[13]提出了一種基于能量感知的聚類路由協議,該協議能夠對網絡進行聚類并選擇最優的簇頭,并通過改進的布谷鳥搜索算法進行了優化。
本文基于WSN數據聚合技術,設計一種最優廣域無線傳感器網絡數據聚合模型(Optimal data aggregation model, ODAM)。研究和分析了標準花粉算法的搜索性能,利用花粉算法在基站(Base station, BS)進行集中式聚類,通過目標函數能夠獲得性能最佳的聚合簇。利用相關數據進行仿真實驗,驗證算法的有效性及可行性。
1 模型的設計與描述
1.1 花粉算法
自然界中植物的授粉過程包括自花授粉和異花授粉兩種方式,花粉算法是根據植物花朵授粉行為機理進行模擬而設計的一種新型啟發式優化算法,算法的局部搜索和全局搜索過程分別模擬自花授粉和異花授粉行為[14]。將花粉算法建立以下規則:
規則 1:植物的異花授粉過程被模擬為全局搜索過程,其中花粉個體服從Levy飛行機制;
規則 2:植物的自花授粉被模擬為局部搜索過程;
規則 3:花的恒常性與授粉過程中兩朵花的繁殖概率或相似度成比例。
規則 4:局部搜索和全局搜索由轉換概率p∈[0,1]控制,當Rand>p時,進行全局搜索,反之進行局部搜索。
對于全局搜索過程,花粉粒子由昆蟲和鳥類等傳粉者攜帶,能夠傳播較遠距離,因為昆蟲,鳥類等生物媒介可以飛行或移動較長距離。將上述規則用數學表達式進行表示,規則(R1)和(R4)表示為:
(1)

(2)
而對于局部搜索,可以把上述規則(R2)和(R3)定義為:
(3)

1.2 最優數據聚合模型
假設給定的網絡區域中存在N個節點或網絡設備,將傳感器網絡區域劃分為N個同心圓,也可以稱為層,基站位于圓心處,如圖1所示。在聚合網絡中,簇節點間的通信開銷比較大,會減少網絡的生命周期。在最優數據聚合模型(ODAM)中,通過在基站中使用花粉算法可以對網絡區域中每一層的節點進行聚類,能夠使得節點和BS之間進行有效的通信。對于每一層中的聚合簇,簇節點將收集到的數據信息發送給簇頭節點,簇頭將對收到數據信息進行聚合,并且還可以作為中繼節點將聚合后的數據包中繼給下一層的簇頭節點,最終會形成簇頭覆蓋的網絡。

圖1 最優廣域傳感器網絡數據聚合模型Fig.1 Aggregation model of optimal wide-area sensor network data
與其他類似網絡不同的是,ODAM將聚類、簇頭選擇、簇頭重選、信令以及重新聚類[15-16]等過程限制在基站中進行,目的是為了減少節點間的計算開銷,有助于延長傳感器節點的壽命。具體實現過程如下:
Step 1 簇的形成BS根據收到的節點位置和節點剩余能量等信息,執行聚類過程并把給定簇中的簇頭ID發送給節點,節點在此基礎上形成簇。節點和BS之間的所有通信都通過簇頭進行,由于每個節點的ID、位置信息和剩余能量都會保存在BS中,因此可以根據節點的狀態進行實時的更新,如圖2所示。當現有簇中沒有節點能滿足設定的閾值時,則觸發重新聚類,在此期間,新的閾值會重新被設定。在BS中進行簇節點間距離和能量的計算,能夠降低節點間的能量消耗。
Step 2 數據聚合在成簇階段完成后,第N層的節點將數據發送給簇頭,簇頭將收集到的數據進行聚合并將聚合后的數據發送給鄰近的簇頭,作為來自第(N-1)個環的中繼節點,直到數據被中繼到BS為止。數據聚合的模型如圖3所示。

圖3 數據聚合Fig.3 Data aggregation
Step 3 簇頭重選隨著節點工作時間的增加,節點自身的能量不斷減少,當CH的能量逐漸接近所設定閾值時,將通過廣播的方式來提示所有節點啟動簇頭重選過程。此時節點將自身剩余能量的信息發送給CH,CH將其和這一輪的相關數據一起中繼到BS。當基站接收到數據后,則更新傳感器節點的相關信息,并利用FPA對簇頭進行重選。簇頭重選如圖4所示。
Step 4 逐層重新聚類在傳感器網絡中,如果給定簇中沒有節點具有足夠的能量來充當簇頭,則節點與網絡中的其他簇進行重新分組。當網絡中每一層的聚合簇接近飽和時,BS通過設置簇頭滿足的閾值,對整個層執行重新聚類。
1.3 最優聚合目標函數
假設在不影響數據包傳輸的情況下,成員節點可以直接向簇頭傳遞數據。在廣域的無線傳感器網絡中,為了形成具有高能效的簇,把在單位時間內消耗單位能量所傳輸的總比特數,即效率E設定為ODAM模型所需的目標函數為:
(4)
式中:P為網絡中消耗的總功率;DR1和DR2分別代表簇頭和節點的數據傳輸速率。
式(4)中的簇頭和簇節點的數據傳輸速率滿足:
(5)
(6)
式中:N和Nc分別為傳感器節點和聚合簇的數量;Ze和Za分別代表簇頭和節點上的陰影;β1為簇頭發送包的數量;PTx為簇頭的傳輸功率;D1和D2分別為節點與基站和簇頭之間的距離;w1為簇頭的帶寬;w2為簇中每個節點的帶寬;Pla為簇頭經歷的路徑損耗,Ple為節點經歷的路徑損耗,如式(7)和式(8)所示。
Ple=128.1+37.6·log2(D1/1 000)
(7)
Pla=38.5+20·log2D2
(8)
簇通過最小化節點、簇頭和基站之間的陰影效應被更換,因此,形成的簇具有較高的能效,且在不影響QoS的情況下有助于延長網絡生命周期。立足于所構建的ODAM模型,結合花粉算法設計的最優聚合算法,如算法1所示。

算法1 最優聚合算法Algorithm 1 Optimal aggregation algorithm
2 仿真結果與性能分析
在仿真實驗中,無線傳感器節點被均勻地分布在100 m×100 m的區域上,其中BS位于網絡區域中心,仿真參數如表1所示。本文在評估ODAM性能時考慮了以下指標:
(1) 數據包收集率: 在基站處每輪傳輸后所收集的數據包數量與所傳輸總的數據包數量的比值,在無線傳感器網絡中常采用輪數表示網絡工作時長;
(2) 網絡節點平均剩余能量: 每輪傳輸結束后網絡中所有節點的剩余能量與節點數量的比值;
(3) 生存節點數量: 在每輪傳輸后網絡中運行的節點總數。
2.1 數據包收集率
數據包收集率與輪數之間的關系如圖5所示。可以看出,ODAM在接收器處可以提供更穩定且連續的數據包收集率。當數據包收集率降至0.9時,HEED和FSC分別出現在網絡生命周期的35%和75%左右,而在網絡生命周期的86%之后,ODAM中數據包收集率才降至0.9,可以看出ODAM的網絡壽命明顯優于HEED和FSC。雖然曲線適用于較短的網絡工作時間,但在數據包收集率方面可以看出所提出的ODAM模型要比其他兩種算法更加穩定。
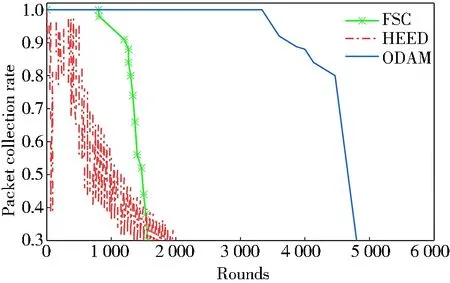
圖5 數據包收集率的比較
2.2 網絡節點平均剩余能量
節點平均剩余能量(Residual energy of nodes, REN)隨著輪數的變化情況如圖6所示。對比三條曲線,在節點經歷3 000輪左右傳輸時,HEED和FSC的節點的平均剩余能量值均降為0,網絡開始失效,而ODAM系統中的平均剩余能量還有900 mJ左右,因此,網絡工作時間要比其他兩種聚合算法更長。在初始階段,FSC中節點的平均剩余能量下降的較為緩慢,但在1 400輪后開始迅速下降,而ODAM中節點的能量減少速度要相比于HEED和FSC要更加地穩定。在ODAM模型中,網絡區域采用分層結構的設計,使得簇頭傳輸數據時所跨越的距離進一步減少,節省了傳感器節點的能量。

圖6 節點平均剩余能量的比較Fig.6 Comparison of average REN
2.3 網絡生存節點數量
三種算法隨著輪數的增加,網絡中運行節點數量的比較圖如7所示。可以看出,相比于HEED和FSC來說,ODAM在初始階段節點數量的減少更為緩慢。由于ODAM試圖將聚合簇中大多數計算限制在基站中進行,因此,可以減少節點間因計算產生的能量消耗,有助于增加節點的壽命。圖中當FSC和HEED進行4 000輪時,幾乎已無節點存活,此時,ODAM依然有將近2 000個節點存活,說明ODAM的網絡生命周期要遠優于HEED和FSC。
3 花粉算法的特征分析
為了驗證采用花粉算法是否為聚類網絡中節點的最佳選擇,本節將通過研究不同簇數的能效和節點數量的關系來證明FPA的選擇。其中聚合簇Cluster的簇數n分別取值2、4和6,如圖8所示。可以看出,聚合簇Cluster中節點數較少時,n=4時具有能效最高,如當聚合簇Cluster中有20個節點時,三種簇數(n=6、4、2)的能效分別近似為12.5、13.5和12.2Mbits·J-1。但是隨著聚合簇Cluster中的節點數量不斷增加,這種變化趨勢將發生改變。比如當節點增加到200個時,三種簇數(n=6、4、2)的能效分別近似1.55、1.5和1.45Mbits·J-1。三種簇數的能效值隨著節點的增加會大大收斂,在聚類網絡中,應用FPA算法能夠獲得更高的能效,而且不受聚合簇數量的影響。因此,網絡可以根據其他特征需求選擇簇的數量,同時不會影響聚類網絡中的能效。

圖8 花粉算法的特征分析Fig.8 Characteristic analysis of flower pollination algorithm
4 聚合簇數量的分析
在ODAM中,聚合簇的數量對無線傳感器網絡的性能也產生一定的影響。為了獲得最佳數量的聚合簇,通過對不同數量的簇在平均數傳輸速率和計算時間上進行比較能夠有效地進行聚合簇的選擇。
三種不同簇數的平均數據傳輸速率的比較如圖9所示,可以看出,三種簇數的平均數據傳輸速率隨著節點數量的增加均呈逐漸遞減的趨勢,而且簇數越大,平均數據傳輸速率越大,即6個簇中的的平均數據傳輸速率最高,當聚合簇中有50個節點時,三種簇數(n=6、4、2)的平均數據傳輸速率分別為125、75和25 kbps。雖然這種趨勢隨著節點數量的增加而繼續保持著,但是速率值變化的差異卻減小了。
三種簇數隨著節點數量的增加,形成聚合簇所需計算時間的比較情況如圖10所示。三種簇數的計算時間均隨著節點數量的增加而增加,同時,聚合簇的簇數越大所需的計算時間也越多,即聚合簇數量為6時,發現所計算時間最多。當聚合簇中有200個節點時,三種簇數(n=6、4、2)所需的計算時間分別為0.9、0.75和0.6 s。

圖10 計算時間的比較Fig.10 Comparison of computational time
為了達到這個平衡的要求,需要去平衡網絡支持的平均數據傳輸速率與其運行過程中所涉及的計算時間,在分析聚合模型時選擇簇數為4的聚合簇。所提出的ODAM模型使用有效的FPA算法進行聚類,使得單位能耗下能夠獲得最大的數據速率,實現在不影響QoS的情況下獲得較高的能效。
5 結 論
設計了一種最優廣域無線傳感器網絡數據聚合模型,該模型通過采用FPA算法與目標函數結合進行簇頭的最佳選擇,從而獲得最優的簇集合,并能夠在簇間和簇內的通信成本上取得平衡。進一步將聚類和簇頭重選等類似活動限制在BS,使得節點不受開銷的影響,同時,將數據進行分層傳輸,有助于提高數據傳輸的準確性和節省網絡中的能量。在考慮節點的傳輸功率和帶寬的情況下,實驗結果表明,ODAM較其他聚類算法能夠有效地延長網絡壽命,由于使用了優化功能,在接收端能夠接收到連續的數據包,在不影響QoS的情況下,使得傳感器網絡中能量能夠被高效地利用。但是由于對花粉算法的提出時間較短,花粉算法的理論還需進一步的完善,在后續的研究中,可以考慮借鑒智能優化算法的改進來提高花粉算法的性能。
