現代數據庫法律保護研究
2022-01-09 09:59:38生明君
傳播與版權 2022年1期
關鍵詞:數據庫

[摘要]數據時代的到來使得大量互聯網企業依托海量數據得以生存,因而數據庫的權益也越來越受到人們的重視,不同的國家分別從不同的角度對數據庫進行了保護。我國目前大多通過《中華人民共和國著作權法》來保護數據庫因其獨創性的選擇與編排方式而產生的知識產權。為了結合本國的特點維護數據庫安全,本文分析了不同國家保護數據庫的方式,并結合多種法律手段,為當前我國數據庫安全保護體系建設提供思路。
[關鍵詞]數據庫;法律保護;知識產權;《歐盟數據庫保護指令》
一、數據庫概述及其著作權保護
數據庫是存儲和管理數據的系統,其中的數據可以指代任何類型的信息。數據庫引擎可以對數據庫中的信息進行排序、更改或提供服務。信息本身可通過許多不同的方式存儲,計算機出現之前,數據通常存儲在紙質載體中,而現在大多數數據都保存在電腦中。電子數據庫具有巨大的實用價值和經濟價值,這使得它們能夠直接服務于個人的生活或生產經營活動。但是隨著社會的不斷發展,數據庫的權益糾紛逐漸增多,阻礙了用戶與企業、企業與企業之間的信息獲取和交流活動[1]。
眾多企業經營者、政策制定者和學者都在呼吁對數據庫進行產權保護。他們目前關注的是聯網汽車、工業機器、人工智能和物聯網上的其他設備產生的大量數據。這些數據庫的數據對與連接設備相關聯的許多方來說都具有私密性,數字市場的利益相關者經常將其視為所有權的一種,并據此維護自身的權益。
傳統的數據庫編輯工作主要是為了娛樂或是閱讀。因此,在此觀點下,電子數據庫被視為一種與傳統數據庫擁有不同定義的獨立作品。但是從法律角度看,電子數據庫與傳統數據庫的基礎編輯工作相似,產出的內容結構相仿,不應當將其視作獨立作品。從構成數據庫材料的法律屬性來判斷,數據庫可以分為由作品或作品集合構成的數據庫和由非作品的其他材料構成的數據庫。前者是受著作權法保護的獨立作品的集合,而后者是不受著作權法保護的事實和信息的集合。
著作權法只保護信息和數據的創造性表達,而不是信息和數據,乃至數據庫本身。因此,著作權法可以保障包含信息的原創作品的財產權[2],其中就包括數據的創造性匯編,但是不能保障基礎數據本身的財產權。著作權所有人擁有排除他人復制、改編、分發、表演或展示創造性內容的專有權,但是不包括其中所包含的潛在事實信息。例如,會計類書籍的作者可以根據著作權法主張他的權利,禁止他人對書中文字進行直接復制,但是不能禁止他人以不同措辭對書中的會計方法進行描述。
在中國,數據庫實際上是以匯編作品的形式受到《中華人民共和國著作權法》的保護,并按照只保護表達而不保護思想的原則對數據庫進行了著作權保護[3]。只要匯編數據具有創造性,著作權法就能賦予其知識產權。換言之,作者可以創造性地選擇或安排匯編作品中的事實,如選擇哪些事實,以什么順序放置它們,以及如何安排收集的數據等。
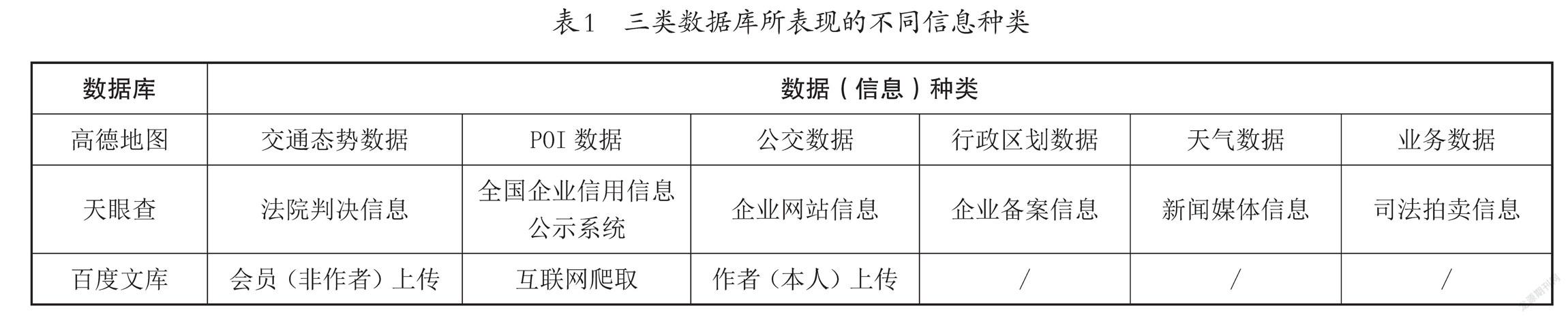
法律的保護原則并不局限于數據的選擇和編排,當涉及數據庫本身的內容時,如果內容本身構成作品的話,就可以直接納入著作權的保護范圍。但是如果數據庫的內容沒有展示作為作品的特質,那么著作權法最多只能保護其具有獨創性的選擇與編排方式。然而,我國并沒有明確的法律法規界定選擇與編排方式的“獨創性”,盡管這種獨創性可能體現在數據庫的檢索方式中,也可能體現在數據庫的表達順序、表現內容的優先度中,但是具體什么方式是獨創性的,表現到哪種程度才算擁有獨創性,并沒有合適的法律或者司法解釋來界定它[4]。在表1三類數據庫中,筆者列舉了三種不同的數據庫及其部分數據來源。可以看到,高德地圖和天眼查的數據大多來自自己系統爬取的政府公開信息,并且高德地圖還涉及符合《互聯網地圖服務專業標準》下的測繪數據。這些數據來源作為數據庫內容一般會被認為不受著作權法保護,但是以百度文庫為主的作品匯編類數據庫,其內容卻受到著作權法保護。表2是對表1所展示數據進行獨創性的選擇和編排后制作而成。筆者認為,高德地圖和天眼查的數據庫,雖然其內容來源不受著作權法保護,但是應當認為其對大量公共數據進行了選擇和編排。
二、對數據庫的特殊保護—以《歐盟數據庫保護指令》為例
《歐盟數據庫保護指令》(以下簡稱《歐盟指令》)在著作權法體系之外還建立了數據庫特別保護體系。根據該指令,如果某個數據庫的內容本身是由享有著作權的作品構成,或者該數據庫雖然由事實資料組成,但是在選擇和編排上具有獨創性,它們就可以受到著作權法的直接保護。對由事實資料組成,但在選擇和編排上沒有獨創性的數據庫,如果判斷其具有實質性投入,也可以進行特殊保護[5]。該指令給予了著作權所有人足夠的專有權,著作權所有人可以限制他人面向公眾臨時或永久復制、改編、發行、傳播、展示或表演的行為。合法用戶無須獲得授權,即可采取為訪問數據庫內容和正常使用數據庫內容所必需的任何限制性行為。同時,任何企業之間、企業與個人之間、個人與個人之間與之相反的合同條款都是無效的。
在該指令發布之前,成員國數據庫的著作權保護可以分為兩大類。在英國、愛爾蘭和荷蘭,其著作權保護的門檻相當低。特別是之前英國和愛爾蘭普通法中納入了一種“額頭出汗”原則,這種原則是從早期英國的案例中發展而來[6]。該原則指的是只要數據庫搭建者在建設數據庫的過程中付出了辛勤勞動,就可以得到保護。然而,在其他歐洲國家,數據庫的內容想要得到著作權法的保護,需要相當高的原創門檻。
但是,《歐盟指令》也不是完美無瑕的,它過分強調對數據庫開發者實質性投入的保護,造成后來的數據庫開發者為盡量避免使用受著作權保護的素材,而不得不重新進行資料的收集,從而造成時間的極大浪費和資源的重復建設。
許多政策制定者和法學家認為,制定特殊的數據庫保護政策會是一種糟糕的公共政策,其導致經濟成本很可能超過其收益[7]。例如,著作權法允許數據庫擁有者對收集到的數據進行壟斷,雖然這會使數據庫擁有者鎖定對基礎科學研究至關重要的信息,但是這種保護可能會導致一種反競爭環境的形成,使增值產品和服務難以進入市場。這種環境反過來又會使信息產品更加昂貴,從而損害消費者和整個社會的利益。
《歐盟指令》保護數據庫建設者的知識產權,可能會在其他國際監管體系中帶來關于隱私、貿易和投資的問題。這些問題相當復雜,對決策者探索如何建立健全數據管理制度,具有重要意義。
(一)權利保護限制較少
《歐盟指令》的權利保護限制和權利保護例外較少,只在極少數特殊情況下允許第三方使用人可以在未經數據庫創建者的同意下,使用數據庫的一些實質內容。這些特殊情況包括私人使用、教學指導或以學術研究為目的的合理使用,但其仍需要表明數據來源,并且應當是非營利目的[8]。此外,以公共安全或行政、司法為目提取數據庫內容也可以被認為是合理使用。與我國的著作權法相比,《歐盟指令》未能保護少數民族和殘疾人的利益,也未能明確表明圖書館和檔案館是否可以免費使用,因而其在公益性的保護上存在一定漏洞。
(二)獨創性定義不明
就像存在于著作權法中如何判斷選擇與編排的“獨創性”問題一樣,《歐盟指令》也并沒有準確定義實質性投入的標準。如此模糊的法條容易導致相關工作者在工作中過于謹慎,最終在具體案例中還是需要法官來判斷實質性投入的程度。
(三)保護期限過長
《歐盟指令》對數據庫的保護期限也有修改的必要。根據其規定,數據庫原則具有15年的保護期限,但是可根據數據庫不停地更新而不斷重新計算數據庫的保護期限。該保護期限條例促使數據處理者及其合作者有機會分析生成的數據,并且這種保護不需要持續這么長時間。因為有了最新的技術,數據分析可以相當快地完成。而這種所謂的15年保護期,經過數據庫所有者的無限更新,很容易變成無期限的保護,這與著作權法分享知識、促進共同進步的理念是相違背的。知識產權法也需要有適當的限制條件。專有權的目的是產生更大效益而進行的投資,比如推動科學技術進步等,但是專有權的保護范圍太寬泛或保護時間太長,實際上可能達不到預期。同時,這也是為了在著作權所有者的利益和廣大公眾的利益之間實現平衡。數據通常是從知識產權法的可保護主題定義中分離出來的,任何國家都沒有已知的“數據產權法”。因此,著作權法更不應該讓數據庫的保護期限能無限期延長,并且如果有些數據庫自建設完成后15年內未提供給公眾使用,也許可以考慮不再給予保護。
三、《歐盟指令》對我國的啟示
傳統著作權法的保護范圍涵蓋不了所有類型的數據庫,因而其在保護數據庫建設者的權益時也會有一些局限性。《歐盟指令》增加了特殊權利保護的內容,但這種保護偏重投資者利益,而沒有充分考慮數據庫建設者的權益與公眾權益之間的平衡。這實際上是擴大了數據庫建設者的權利空間,縮小了社會公眾合理使用數據庫的空間[9]。
(一)中國數據庫種類繁多
我國不能盲目借鑒《歐盟指令》的條款。因為《歐盟指令》距今已有20年歷史,當今數據庫服務器可以儲存并且處理的數據量也遠遠不是《歐盟指令》時期可以比擬的。當前,數據庫管理者之間、數據庫管理者和注冊用戶之間的矛盾糾紛可能比之前要復雜得多。我國如果要通過法律維護數據庫管理者的權利,應當充分考慮目前市場的數據庫種類和創建,運營不同數據庫所付出的智力勞動和實質性投入等因素。不同數據量的數據庫所要求的實質性投入是否一樣,該從何種角度定性所謂的投入,都是值得相關人員思考的。以百度文庫為代表的數據庫幾乎不需要自己定義檢索標準,更不需要自己設置標簽、引申內容。事實上,百度文庫的內容主要來自用戶上傳,此類數據庫付出的智力勞動極小,那么他們的實質性投入能否使得他們的數據庫受到保護呢?相對而言,天眼查等企業信用查詢系統,其內容來自海量的公共網站以及企業官網,他們在獲取數據時要面對不同網站的檢索機制、驗證機制,可能還有等級機制,在選擇、管理數據時還要充分考慮消費者的需求,并對大數據和算法設置的大量信用評級機制和企業關系網等數據進行多步加工。那么,天眼查該證明多少“實質性投入”來保護自己的數據庫數據不被其他人無償使用、復制、再傳播。這些都是我國在引入數據庫特殊保護時需要思考的問題。
不同的數據庫所有權人可以在以下幾個方面主張不同的權利:一是信息(數據)內容。例如,某企業某年度營業利潤為多少,百度文庫取得了該信息原作者授權的作品表達形式,其以文字、符號、圖畫或其他作品形式表達信息,或以創造性或功能性地組織、匯編而成的數據庫;二是信息的物理表現。比如,照片、書籍的封面或墻上的畫,企查查等公司經過計算、統計出的企業信息等;三是信息所涉及的項目。比如,故障的自動駕駛車輛本體,互聯網科技公司使用的深度學習技術、大數據分析技術。當前,在主張數據庫產權保護時,數據庫的原創性成了諸多學者爭論的焦點。
(二)中國的數據庫保護法可借鑒現有法律
數據庫保護可以與現有法律規定相配合。《中華人民共和國數據安全法》第二十一條第一款規定了國家根據數據在經濟社會發展中的重要程度,以及一旦遭到篡改、破壞、泄露或者非法獲取、非法利用,對國家安全、公共利益或者公民、組織合法權益造成的危害程度,對數據實行分級分類保護。這條法規的主要目的是以不同類型數據的重要程度為判斷標準進行分級,從而給予不同程度的保護。這一法規的理念是很適合保護并且規制數據庫的。如果從保護角度進行分級的話,以百度文庫為代表的匯編作品類數據庫在數據流通方面是互聯網服務提供商,適合引用“避風港原則”和“紅旗原則”,因為它并沒有進行過多的實質性投入,那么給予的特殊保護程度也應較低。而企查查在爬取大量數據后,還要經過大量計算,這可以認為其進行了較多的實質性投入,那么給予的特殊保護程度也應較高。
但是在結合其他法律時,數據庫保護的相關法規需要考慮其權利保護范圍的問題。因為明確的范圍將有助于防止或解決“權利重疊”的問題,即防止存在覆蓋同一主體的多重且相互競爭的權利層次。比如,如果使用數碼相機拍攝的電影不僅可以作為受著作權法保護的作品,還可以作為受“數據生產者權利”保護的機器生成數據。同樣,金融數據庫中的股票市場總體數據也受到數據庫特殊權利的保護,因為這些數據是由股票交易所的計算機自動記錄的。當在既有法律已能保護這些數據的利益時,新的法律不應當再將其囊括在內。
從目前的情況來看,我國著作權法中關于數據庫保護的規定并不能適應信息技術的發展。因此,相關部門可以根據“數據庫知識產權公約”的規定和中國的國情,對著作權法進行必要的修改,并在著作權法中明確體現《與貿易有關的知識產權協定》和“數據庫知識產權公約”的精神。其根本目的是建立一個合理的數據庫特殊保護制度,實現個人利益和公共利益的平衡,既保護數據庫建設者的利益,也維護消費者和用戶的利益。這將是未來數據庫特殊保護的重點。
[參考文獻]
[1]徐艷麗.歐盟數據庫版權保護模式的構成及啟示:以《歐盟指令》為例[J].山西檔案,2017(03):94-96.
[2]馬海生.數據庫法律保護若干爭議評價[J].知識產權,2001(04):40-44.
[3]劉梅.國內外數據庫權益保護模式比較研究[J].圖書館學研究,2009(08):94-97.
[4]李揚.數據庫特殊權利保護制度的缺陷及立法完善[J].法商研究,2003(04):26-35.
[5]彭霞.數據庫的法律保護[J].重慶工商大學學報(社會科學版),2011(01):73-78.
[6]陳軍.國內外數據庫保護比較研究[J].科技進步與對策,2004(06):152-153.
[7]薛虹.數據庫的法律保護與反壟斷[J].知識產權,1998(03):20-24,9.
[8]馬海群,張濤.從《數據安全法(草案)》解讀我國數據安全保護體系建設[J].數字圖書館論壇,2020(10):44-51.
[9]董舞藝,湯荷月.美、德兩國數據庫版權保護的法律模式及對圖書館的影響[J].圖書與情報,2014(03):10-14.
[作者簡介]生明君(1998-),女,山東濟南人,北京郵電大學人文學院碩士研究生。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
