基于YOLOv5的毫米波圖像目標檢測方法研究
2022-01-18 09:44:58張格菲李春宇劉金坤屈音璇
宇航計測技術 2021年5期
張格菲 李春宇 劉金坤 屈音璇
(中國人民公安大學偵查學院,北京 100038)
1 引 言
近年來,隨著暴力恐怖事件的增多,安全問題越來越引起人們的關注。爆炸案是最嚴重的暴力犯罪,社會危害大,關注度高。爆炸帶給人們的不僅僅是經濟損失、生命威脅,同時也危及到國家和社會的穩定性[2]。為防范恐怖爆炸犯罪,需要對機場、港口、海關、車站等重點場所進行全天候安全檢查和監控,嚴防爆炸物、易燃物品帶入車輛或混入重點場所。傳統上,違禁物品主要包括槍支、金屬刀具和爆炸物。但是,隨著科學技術的發展,陶瓷刀具、塑料炸藥、化學制劑等新型違禁物品不斷涌現,給違禁物品的檢測帶來新挑戰。
檢測待測目標的傳統方法[3-7]是采用特征分類器來完成圖像中的目標檢測。但是,這種傳統的物品檢測方式存在一定的缺陷,即泛化能力較差。目標檢測算法的性能往往受圖像背景的復雜程度影響。圖像背景越簡單,目標檢測的效率也就越高,檢測性能越好。相反,一旦圖像背景變得復雜,目標檢測的效率以及性能都會隨之下降。為了解決上述缺陷,有學者在深度學習技術的基礎上研發出了卷積神經網絡CNN(Convolutional Neural Network)[8]。卷積神經網絡不但能夠完成特征提取,并且具有較好的魯棒性以及較強的表達特征性能,不管是簡單環境還是復雜環境,都能精準定位到檢測目標。隨著檢測技術的不斷發展[9],R-CNN(Region-CNN)算法成功將深度學習應用到目標檢測領域中,并帶動了卷積神經網絡的發展[10],卷積神經網絡通過不斷的深化和研發,相繼發展出Fast R-CNN[11]技術,以及其優化算法Faster R-CNN[12]技術。Faster R-CNN設計出RPN(Region Proposal Networks)區域生成網絡,替代了R-CNN中的選擇性搜索方法用于實現端到端的模型訓練。借鑒Faster R-CNN的技術思想,進一步推導出YOLO(You Only Look Once)[13]、SSD(Single Shot MultiBox Detector)[14]、R-FCN(Region-based Fully Convolutional Networks)[15]等一系列目標檢測方法[16]。YOLO創造性的提出了one-stage,也就是將物體分類和物體定位在一個步驟中完成,完全能夠滿足實時性要求。SSD提取不同尺度的特征圖來做檢測,采用不同尺度和長寬比的先驗框,在準確度和速度上都有極大的的提升。相比傳統金屬安檢門,毫米波人體安檢系統在使用中不會對人體造成傷害,且毫米波成像不受衣物影響,能夠獲取人體形狀特征以及藏匿于服飾下的危險物品,因而毫米波人體安檢系統逐漸得到廣泛運用。有鑒于此,基于深度學習和YOLO系列的研究成果,本文要解決的關鍵問題是如何保證攜帶不同刀具的毫米波圖像能夠正確識別和檢測,降低復雜環境下的誤檢和漏檢率,提高檢測和識別的準確性。本文采用YOLOv5目標檢測算法對可攜帶刀具的毫米波圖像進行檢測,并改進了YOLOv5算法,以提高YOLOv5的檢測精度。
2 毫米波成像與算法簡介
2.1 毫米波成像原理
毫米波收發機在掃描平面上上下掃描,掃描的頻率范圍從28GHz到33GHz,覆蓋介于兩者之間的64個頻率點。將收發器在某一時刻的位置記錄為(a,b,Z),此時的頻率為ω,光速常數為c,波數為k=ω/c,目標物體在位置(x,y,Z)處的反射系數記為f(x,y,Z),通過將整個目標視場的像素點積分,獲得電磁場數據為
(1)
推導反射系數f(x,y,Z),以重建物體的圖像
(2)
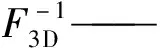
傳統的目標檢測算法主要是針對光學圖像數據庫,應用基于圖像特征的圖像分割方法,這種方法誤檢率高,易受到人體姿態的干擾。而毫米波成像技術在新興的安檢應用中,雖然在標準數據庫的建立與目標檢測算法的應用尚處在起步階段,但在安全性、隱蔽性和實時性等方面表現突出,尤其在人體安全檢查領域有著良好的應用前景。因此研究符合此應用場景的目標檢測算法并提升相應的檢測速度與檢測準確率具有重要的應用意義和很高的應用價值。
2.2 YOLOv5網絡模型
YOLOv5網絡模型具有深度、寬度兩個結構參數,參數值不同構造出不同的網絡結構。YOLOv5包括四種不同的網絡結構:YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x。這四種網絡結構的深度參數值、寬度參數值,見表1。

表1 YOLOv5深度和寬度參數對比
與深度最淺的YOLOv5s結構相比,YOLOv5x結構的Neck數量最多,是YOLOv5s結構的4倍。YOLOv5s結構的寬度最窄,YOLOv5x結構的卷積核數量最多,通道層數是YOLOv5s結構的2.5倍。在相同數據集的情況下,YOLOv5s結構的訓練和推理性能最好,體積最小,而YOLOv5x結構的平均準確率最好[18]。
YOLO主要網絡結構性能對比見表2。本文使用的YOLOv5x網絡結構模型如圖1所示。
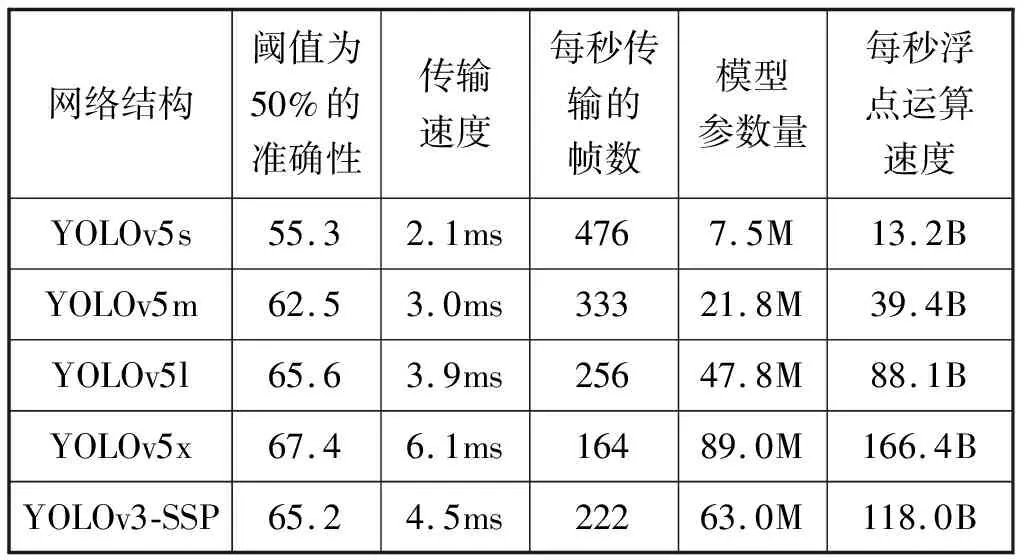
表2 YOLO主要網絡結構對比
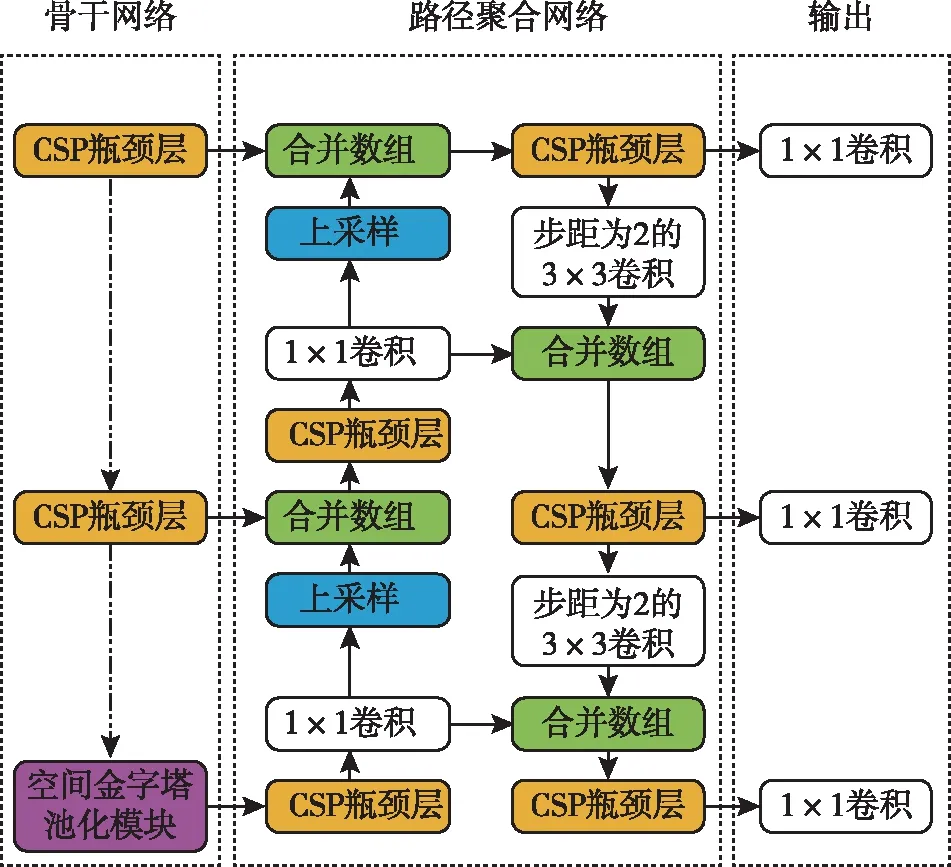
圖1 YOLOv5x網絡結構模型框圖
BackBone結構是YOLOv5技術的網絡核心,其目的是在圖像輸入的過程中提取信息以進行利用和處理。在網絡結構模型當中,梯度信息往往存在許多重復性的問題,可以結合CSPNet技術來解決,使得梯度變化和特征圖融入在一起,將模型的參數量和模型FLOPS值都控制在較低的范圍之內,從而提高推理的精確度和效率,也可以達到縮小模型體積的目的。
PANet是在Mask R-CNN網絡框架和FPN網絡框架基礎上發展而來的,對信息的傳播功能進行了優化和改善。該網絡在提取特征的過程中增強了自底向上的路徑,提高了底層特征的傳播。對于第三個網絡路徑,上一個網絡階段的數據信息特征映射就是這一個階段的輸入端,按照3×3卷積的方式來操作,每一個階段輸出的特征映射值會直接和同一個階段的路徑信息進行連接,有效增強了高層與低層信息的聯合利用。區域和特征之間那些受到損傷的信息路徑,在自適應特征池的作用下,也能夠得到迅速的恢復[19],并在各特征層對各候選區域進行聚合,避免隨機分配。
在深度學習網絡中有一個非常重要的環節就是選擇正確的激活函數。在YOLOv5中,中間/隱藏層使用Leaky ReLU[20]激活函數,最后一個檢測層使用sigmoid型激活函數。本文使用GIOU_Loss損失函數進行bounding box結構的損失計算,表達式為
(3)
GIOU_Loss損失函數與IOU一樣,具有非負性、尺度不變性等特性,相比IOU_Loss,GIOU_Loss在任意情況下都可以進行訓練。GIOU_Loss損失函數有效的處理了IOU_Loss中bounding box不重疊情況,具有更快的收斂速度,穩定性更強,極大地提升了衡量尺度相交的能力,并利用基于二叉交叉熵和logits函數的損失函數計算目標分數的類概率和損失[21]。
3 實驗數據集的準備
由于刀具具有易獲取、便攜性等特點,是危害人員密集場所安全的主要因素,本實驗以可攜帶刀具作為檢測對象,采用航天科工集團203所研制的毫米波人體三維圖像集作為實驗數據集,包含1081幅攜帶陶瓷刀和金屬刀的人體毫米波圖像,目標種類和位置信息都屬于數據集中的標注信息。為了確保訓練數據和測試集盡可能多的通用性,按照1∶10的比例劃分了測試集和訓練集。
3.1 數據預處理
對于收集得到的圖像數據,采用數據增強的方法來保證不同圖像可以被充分訓練。本研究主要使用Mosaic數據增強、自適應錨定幀計算、自適應圖像縮放等方法。
Mosaic數據增強的實現思路是:一次讀取4張圖片,對4張圖片進行翻轉、色域變換以及縮放等操作,并依次擺放在左上、左下、右上、右下4個方向,然后按照4個方向的位置拼接在一起,且圖片中保留標注框,至此完成圖片和標注框架的組合。Mosaic數據增強豐富了檢測數據集,增強了算法的魯棒性,提高了檢測小目標的能力[18]。
在YOLO算法中,為不同數據集設置初始長度和錨寬復選框。在網絡訓練中,網絡基于初始錨定幀輸出預測幀后與實際幀的groundtruth進行比較,在計算兩者之間的差距后對網絡參數進行反向更新迭代。在常見的目標檢測算法中,不同圖片具有不同的長度和寬度。因此,常見的方法是將原始圖像統一縮放到標準大小,并將其發送到檢測網絡,即自適應圖像縮放法。
本研究通過減小圖像兩端的黑色邊緣高度優化原始圖像處理方法,減少了推理中的計算量,提高了目標檢測的速度。通過這個簡單的改進,推理速度提高了37%,效果非常顯著。
3.2 數據的標注
在標記數據時,使用labelimg工具進行選擇框并標記,分為陶瓷刀和金屬刀兩種工具,標注的示例如圖2所示。
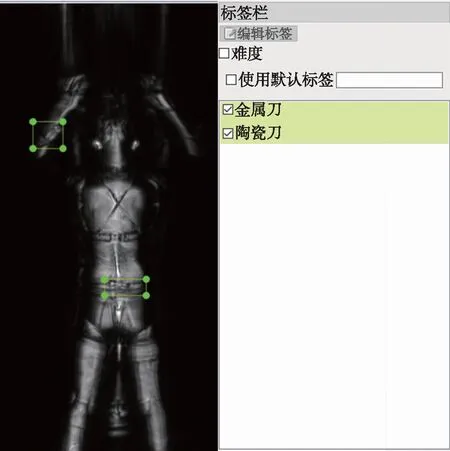
圖2 可攜帶刀具標注圖
4 實驗與結果分析
4.1 實驗設定
毫米波圖像目標識別任務模型訓練的實驗環境為:RTX4000顯卡,CUDA10.1 GPU驅動,Pytorch深度學習框架。訓練時設置參數:輪數(batch-size)16,初始學習率0.01,動量0.937,訓練總迭代次數500次。
4.2 改進方向分析
為了讓數據集中包垂直方向的目標數據,Mosaic數據增強部分增加了垂直旋轉90°的增強。該增強效果明顯,可以有效豐富訓練數據的分布,使擬合更加科學合理,同時優化了檢測模型的泛化功能。另外,通過適當添加圖像數據噪聲,使模型的魯棒性和整體性能更優。
4.3 實驗結果分析
從實驗結果可以看出,采用YOLOv5算法模型進行訓練,訓練效果較好,如圖3所示。YOLOv5在目標檢測上的準確率較高,可以準確地檢測和識別相關刀具,但仍需進一步訓練以提高準確率。
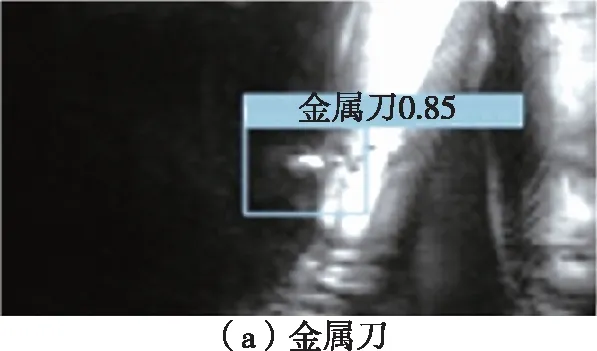
圖3 金屬刀和陶瓷刀檢測結果圖
5 結束語
本文重點介紹如何使用YOLOv5網絡模型實現不同刀具的毫米波圖像檢測,介紹YOLOv5算法、數據集處理和網絡參數優化,并提出了相應的分析改進思路。通過實驗結果證明,YOLOv5能夠保證對相應目標的檢測,檢測速度較快,檢測準確率較高。結果表明,該模型的檢測精度很高,但仍有一些不完善之處。在訓練過程中,要注意迭代次數,否則結果會過擬合,圖片無法正常識別。后續將進一步優化補充毫米波圖像集,增加環境與檢測物品的多樣性,并研究提升檢測性能的策略。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
