基于條件增強隨機蕨的果園蘋果檢測
2022-01-18 06:33:16白金華張宇航
湖南城市學院學報(自然科學版) 2022年1期
白金華,張 乾,范 玉,張宇航,何 興
(1. 貴州民族大學 數據科學與信息工程學院,貴陽 550025;2. 貴州民族大學 教務處,貴陽 550025;3. 貴州省模式識別與智能系統重點實驗室,貴陽 550025)
果實采摘是農業生產的一個重要環節.水果采摘機器人作為農業自動化采摘的重要工具,可以避免人工采摘的風險,及時有效地完成采摘周期的任務.針對機器視覺這一采摘機器人的重要技術組成部分,尋求一種簡單有效的目標檢測方法在自然環境下實現低耗、有效的樹上水果定位檢測,可以提高機器人在實際生產中的工作效率,有效促進農業自動化采摘技術的發展.
近年來,眾多學者對機器視覺技術用于果園水果檢測的研究取得了一定的進展.傳統的水果檢測算法主要通過背景建模及特征融合的方法來實現.Tabb 等[1]針對采摘機器人需要進行實時視頻圖像檢測的問題,利用RGB 背景顏色分布建模的思想,構建了一個全局混合高斯(global mixture of Gaussians, GMOG)模型用于紅色和黃色蘋果的檢測,提高了系統的動態重復檢測性能.詹文田等[2]認為使用單一特征進行檢測不能完整表達田間場景下的特征變化,將RGB、HSI 和L*a*b 3個顏色空間相結合,通過樣本訓練組合強分類器,使其適用于自然環境下的田間獼猴桃檢測.馮娟等[3]考慮樹上蘋果的識別會受到光照和環境的影響,使用激光視覺系統獲取果樹三維圖像,通過目標輪廓獲取邊緣信息并采用隨機圓環法實現了樹上蘋果識別,具有較好的識別率.麥春艷等[4]為避免果蔬定位三維重建的重復工作以及便于為機器人提供采摘基礎數據,通過隨機采樣獲取所有果實質心坐標和果實半徑,運用三維空間重構技術構建識別模型進行檢測,對在順、逆光環境下的果實識別都具有較好的穩定性.
自然環境下的果園水果傳統檢測方法主要針對特征選擇和融合方面進行改進,其在特定場景下的水果檢測效果較好,但特征提取方式較為繁瑣,同時對自然環境下多種水果檢測的泛化性不強.因此,人們迫切需要一種簡單的特征選擇和泛化性較強的檢測方法.隨機蕨算法是一種簡單的隨機二進制特征選擇算法,對于尺度變化、光照和遮擋等具有不變性,可以避免大量的特征計算,較適用于小樣本訓練模型且具有較好的泛化能力.隨機蕨算法是基于隨機森林的思想演化而來.2001 年,Statistics 等[5]提出了由相同分布的二值決策樹分類器組成的隨機森林算法,采用樸素貝葉斯理論作為算法決策輔助,將特征識別問題轉化為分類問題,保證了算法實時性.隨機蕨算法是Lepetit 等[6]于2004 年基于隨機森林理論提出的一種更加簡單的二值決策器,它將隨機樹決策器中各層節點的不同判斷準則改為相同準則,從而構造出一種簡單且有別于層次結構隨機森林的非層次結構隨機蕨.Villamizar 等[7-9]基于隨機蕨算法提出了面向方向梯度局部直方圖的不同方向目標的估計和分類,引入監督學習和梯度空間提高了算法的實時性和魯棒性.此后,人們在其基礎上通過適當地引導訓練步驟顯著提高了分類器性能,使之更適合于只有小樣本可用于訓練的情況.2018 年,有學者在以往的研究基礎上,通過共享特征降低計算成本、引入Real Adaboost增強算法和選擇更具判別性的分類器,組合出強分類器用于檢測定位,并利用對人臉、汽車、摩托車和馬等目標的驗證實驗,顯著提高了檢測率和計算效率[10].
針對果園水果的傳統檢測方法需要手工設計特征和多種場景檢測泛化性不強等問題,本文基于在目標檢測領域具有顯著效果的增強隨機蕨算法[9],對其進行改進并用于果園蘋果檢測.由于增強隨機蕨算法在梯度域上選擇特征時并未考慮特征之間的差異性問題,所以本文在面向梯度域選擇特征時加入了限制條件,以避免所選擇特征代表性不強而誤導檢測識別結果.
1 HOG 域的增強隨機蕨分類器
1.1 隨機蕨算法
隨機蕨算法利用半樸素貝葉斯分類器實現樣本特征到樣本類別的反饋,如圖1 所示.該算法使用蕨類植物的非層次結構代替決策樹中樹的層次結構,從而替換決策樹模型獲取更易訓練的方式,其訓練時間呈線性增長,分類速度更快.
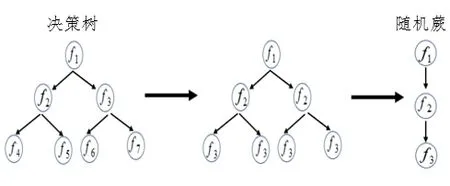
圖1 決策樹與隨機蕨
1.2 基于HOG 特征域的隨機蕨叢
方向梯度直方圖(HOG)是一種具有尺度和光照不變性的特征提取方法,能較好地捕捉目標的邊緣輪廓信息,近年來被廣泛應用于目標檢測領域并展示出顯著效果.HOG 結合了滑動窗口的優勢,使用大小為l×l的窗口I去掃描圖像窗口S,獲取I的局部方向梯度直方圖作為I的特征表達,其二值特征計算式為

通過選擇N組局部特征α來表示窗口I的特征,即一個蕨類植物被一個N維二值特征向量W表示:

1.3 增強隨機蕨分類器

通過每次迭代獲取到的參數計算判別能力最強的分類器,保留此時的概率分布P(W|)?和P(W|φ),并對參數uc*和?q*進行指標評價,將評價后的結果用于測試環節.最后,更新分類器與樣本間的關聯權重,即
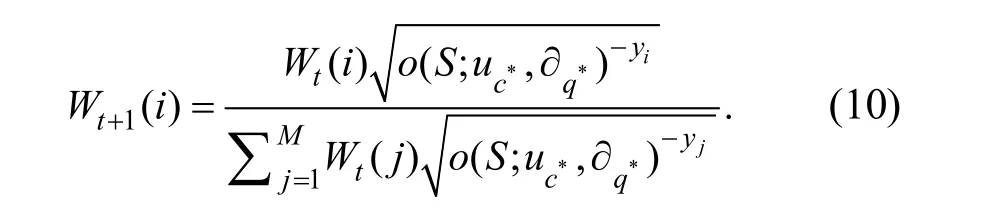
其中M代表訓練樣本集的個數.
2 條件增強隨機蕨
為了保持類內變化特征的穩定性,增強隨機蕨算法在HOG 特征域中采用了隨機蕨分類器隨機選取特征的理念[11].在滑動窗口中,隨機選取方向梯度直方圖上2 個箱子的值進行比較并轉化為二進制串,而該特征隨機選擇方式使得在梯度域平坦區域上選取的特征欠缺代表性,從而導致分類器特征誤分類的幾率增大.
為了避免選擇的特征代表性不強而導致誤分類情況的發生,本文參考文獻[12]中面向像素域使用整個圖像窗口的平均梯度值作為閾值控制二進制產生的方法,針對所提取的HOG 特征具有梯度方向差異的特點,控制隨機迭代選取的2 個點,使其處在不同的方向區間,并用遍歷窗口所在方向區域的梯度均值差作為閾值,對面向HOG特征域的增強隨機蕨分類器的二進制特征產生方式進行改進.使用以uc為中心的子窗口I遍歷圖像窗口S,提取子窗口所在位置的局部梯度直方圖特征.當窗口I所在的圖像區域很平坦且隨機選擇2 個箱子的值G(S;uc,a)和G(S;uc,a′) 很接近時,若直接比較其大小會增大誤分類的概率.因此,在窗口I的局部方向梯度直方圖上控制2 個箱子(a和a′)在不同的方向區間內隨機選擇,同時為了增強隨機選取箱子的代表性,對直接比較2 個箱子值大小的方式進行改進,即

其中,r=A/k,k表示區間方向數.通過計算出來的均值獲取局部區間均值差,即
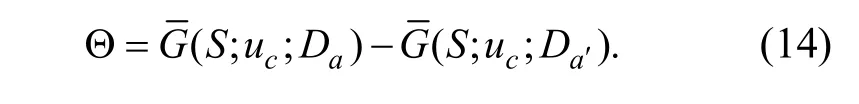
子窗口的局部區間均值差可以表達所選區域不同方向區間的梯度累積值的差異,這是由圖像區域的紋理變化情況決定的.
3 實驗及結果分析
3.1 實驗環境及數據集
本實驗在Windows 10 操作系統下進行,處理器為Intel(R) Core(TM) i5-9300H CPU@2.40 GHz,使用Matlab 語言編程.
針對果實重疊、光照不均和枝葉遮擋等復雜場景下蘋果種類多樣性的實驗需求,筆者通過網絡爬蟲技術下載了相關圖片并制作數據集.其中訓練集1 150 張,測試集108 張,部分圖像如圖2所示.

圖2 部分數據集示例
3.2 實驗參數及評價指標
根據特征選擇及數據集的特點,為了訓練過程更好地適應復雜環境下的果園蘋果檢測,在實驗中對條件隨機蕨算法構建的分類器進行參數設置,如表1 所示.
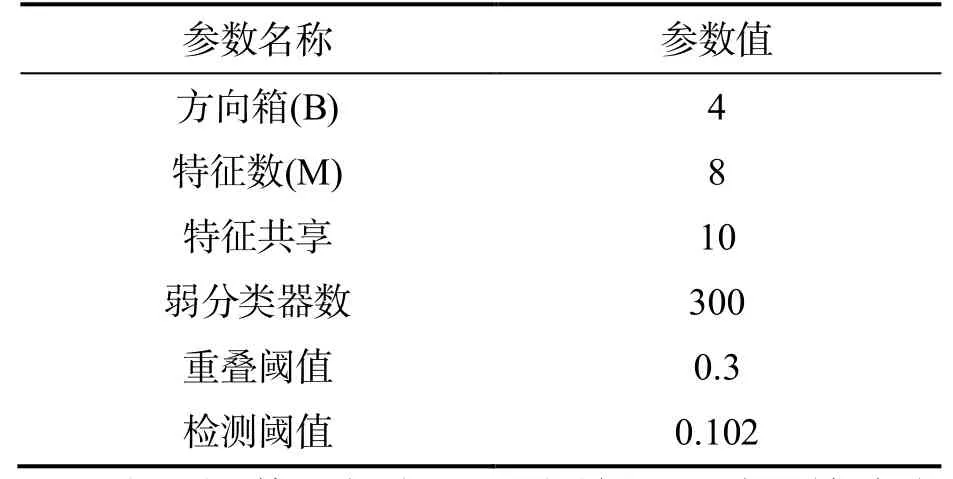
表1 實驗參數
為了評估所提方法的有效性,采用精確度(precision)、召回率(recall)和F1 值來衡量所提方法在復雜環境下對果園蘋果檢測的有效性.各評價指標計算公式分別為

其中,TP為正樣本被預測為正樣本的數量;FP為負樣本被預測為正樣本的數量;FN為正樣本被預測為負樣本的數量.
3.3 結果分析
選用相同的訓練集與測試集對改進前后的增強隨機蕨分類器模型進行對比實驗.在相同實驗條件及參數下,為驗證模型適應性,對不同環境下的多種水果進行了綜合測試,實驗結果如表2所示.
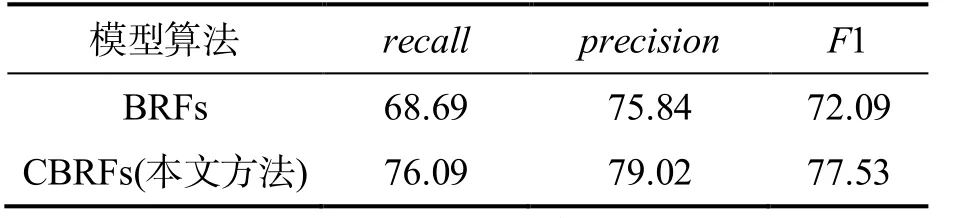
表2 2 種模型的檢測結果 %
由表2 可知,改進后的條件增強隨機蕨分類器相對于增強隨機蕨分類器來說,其檢測召回率提升了7.4%,精確度提升了3.18%.為了綜合評價模型的檢測效果,使用F1 值衡量模型改進前后的有效性.由表2 亦可知,改進后的模型相較于原模型其F1 值提升了5.44%,這說明改進后的模型在復雜環境下對果園多樣性蘋果的檢測效果相較于原模型有一定的提升.
圖3 為2 種算法檢測模型在相同實驗環境下的精確度回歸(PR)曲線對比.由圖3 可知,在果園蘋果檢測中,條件增強隨機蕨分類模型的檢測效果明顯優于增強隨機蕨分類模型.
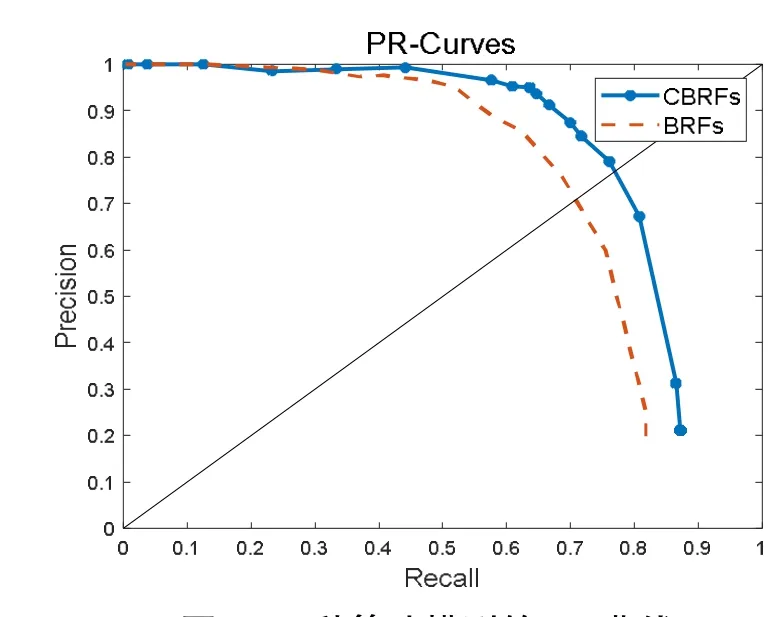
圖3 2 種算法模型的PR 曲線
圖4 表示在不同種類、多種角度和光照不均情況下的蘋果檢測效果圖.其中,藍色框代表標注的蘋果;綠色框代表檢測出的蘋果;紅色框表示誤檢的目標.由圖4 可知,在復雜環境下果園蘋果檢測任務中,本文提出的CBRFs 算法對于多類蘋果的檢測效果較為理想,能夠在不同角度和光照不均等情況下實現有效檢測,模型總體泛化能力較好.

圖4 總體檢測效果
4 結語
本文在增強隨機蕨分類器的基礎上,給出了基于條件增強隨機蕨分類器的果園蘋果檢測模型并予以效果檢驗.首先,面向梯度域提取目標圖像的方向梯度直方圖特征,形成圖像的特征空間;其次,在特征空間上采用條件隨機二值化方式選取特征,通過改進后的特征產生方式產生二進制特征,構建隨機蕨并組建弱分類器;最后,采用Real Adaboost 增強策略選擇最具判別性的弱分類器并構建強分類器.在自制數據集上的實驗結果表明:在復雜環境下的果園蘋果檢測中,條件增強隨機蕨分類器的F1 值達77.53%,比增強隨機蕨分類器提升了5.44%,有效地提高了果園蘋果檢測效果.然而,由于場景的復雜性和果實的多樣性,在實際檢測過程中仍存在部分漏檢和誤檢等問題,后續的研究重點將進一步考慮如何解決這些問題.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
