基于信譽評估機制和區塊鏈的移動網絡聯邦學習方案
2022-01-18 08:22:24楊明胡學先張啟慧魏江宏劉文芬
網絡與信息安全學報 2021年6期
關鍵詞:模型
楊明,胡學先,張啟慧,魏江宏,劉文芬
(1. 信息工程大學,河南 鄭州 450001;2. 桂林電子科技大學,廣西 桂林 541004)
1 引言
隨著嵌入式系統和網絡技術的加速發展,具有計算、感知和無線通信能力的傳感器以及由其構成的移動網絡已經逐步進入人們的生活[1]。基于這些傳感器收集的數據,通過在移動設備終端部署機器學習模型,可以極大地提高移動服務的質量,如疾病預測[2]和自動駕駛路徑規劃[3]等。然而,傳統的端到端學習需要將訓練數據上傳到云服務器或者數據中心進行集中處理,這不僅會帶來過高的通信和存儲成本,而且會使移動用戶面臨隱私泄露的風險[4]。因此,如何在保證用戶隱私的前提下,充分發揮機器學習等人工智能方法的潛力是一項意義深遠而又亟待解決的問題。
聯邦學習[5-7]作為一種新興的分布式隱私保護機器學習訓練模型得到越來越多的重視,其系統結構如圖1所示。在每次迭代過程中,參數服務器將模型訓練任務部署到終端設備,后者不需要上傳原始數據,而是在本地根據自己的私有數據訓練機器學習模型,然后由前者聚合更新來自不同設備的模型參數。參數服務器和終端設備不斷重復上述過程,直到模型參數達到預定的精度[8]。目前,聯邦學習技術已經在一些移動網絡中有所應用。谷歌[9]將聯邦學習技術應用到Pixel和安卓等智能手機中,在保護用戶數據隱私的情況下提升自然語言處理模型的準確率。通過讓車輛在本地訓練預測模型,Uber推出的應用UberEats采用聯邦學習的方式利用實時交通信息估計送餐時間,以提高個性化服務的水平[10]。為協作訓練診斷模型以確定最佳治療方法,多家醫院可以通過醫學AI應用框架NVIDIA Clara將聯邦學習任務部署到各個醫療設備,而無須集中收集患者的敏感信息。
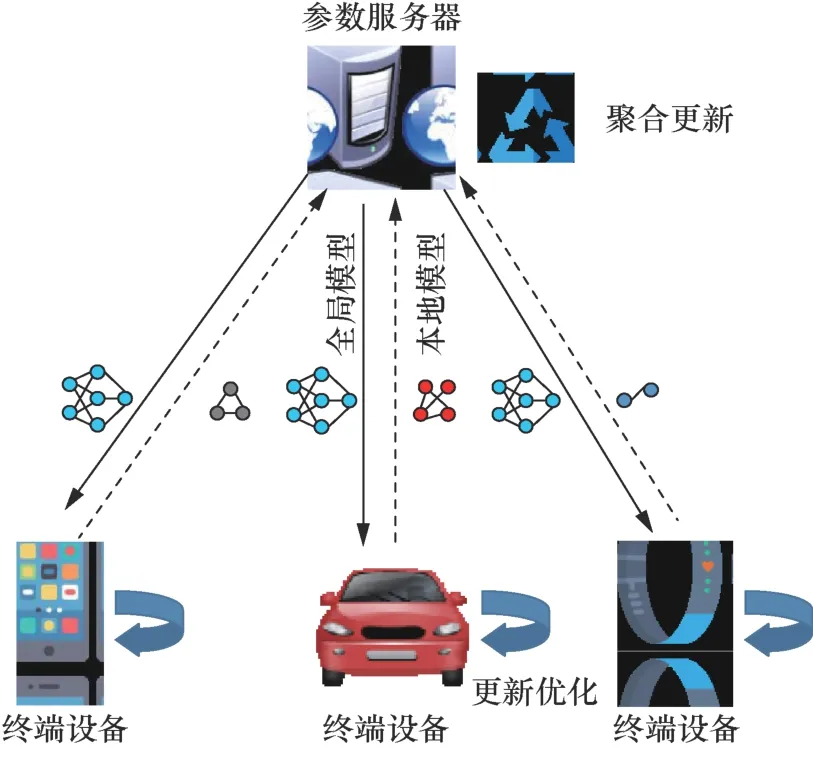
圖1 聯邦學習系統結構Figure 1 Architecture for a federated learning system
聯邦學習技術雖然在移動網絡中有廣闊的應用前景,但由于其本身處在發展的初級階段,仍然面臨嚴峻的挑戰。一方面是參與方的互信問題,即聯邦學習中的參與用戶來自不同的組織或個體,彼此之間缺少信任,如果沒有公開公正的可信平臺,參與用戶不愿意參加模型訓練[11-12]。另一方面是參與方提供的參數缺乏驗證,即一些參與用戶本地收集的數據質量與其他參與方相比差距過大,訓練的模型會直接影響整體模型的質量,此外,惡意的參與用戶甚至還會提供虛假的參數破壞學習過程[13],從而對其他參與方產生不利影響。因此,將聯邦學習應用到移動網絡的同時需要重點設計一種可靠的信譽評估管理機制,使移動用戶之間既能互相信任對方,又能獲得高質量的模型參數。
近年來,區塊鏈技術以其獨有的去中心化、不易篡改和可追溯等特性為解決上述問題提供了思路。一些研究人員開始將聯邦學習和區塊鏈技術相結合來實現移動網絡中的數據共享。文獻[14]設計了基于改進的DPoS共識的區塊鏈車聯網數據共享模型,引入主觀邏輯模型以實現安全高效的信譽管理。Rehman等[15]提出了基于區塊鏈的細粒度信譽感知的概念,確保移動邊緣計算的參與方能夠進行可信的聯合訓練。Fedcoin[16]從博弈論的角度出發,由共識網絡的礦工節點通過采用沙普利法精確計算各參與方所做的貢獻,使各參與方能夠公平分配聯邦學習獲得的利潤。
現有的移動網絡聯邦學習研究中缺乏對參與各方信譽的評估和管理,無法為用戶提供互信的協作訓練平臺。本文以此為出發點,利用主觀邏輯模型計算參與方的信譽值,然后將每次訓練后各個參與方的信譽值存儲到不可更改的區塊中,以供其他用戶使用。同時,為了對用戶上傳的信譽意見進行評價和管理,本文采用信譽評估機制和區塊鏈技術相結合的模式,將模糊層次分析(FAHP,fuzzy analytic hierarchy process)法集成到智能合約中,為用戶提供可調節的信譽意見訪問控制策略。只有信譽值超過一定閾值的用戶才可以訪問鏈上資源,從而有效降低了用戶的惡意行為,激勵更多用戶共享高質量的信譽意見。實驗表明,本文的方案可以顯著降低惡意數據擁有方參與聯邦學習的可能性,提高模型的準確率。
2 預備知識
2.1 區塊鏈的基本概念
區塊鏈是由區塊按時間順序串聯起來的鏈式結構,每個區塊包含區塊頭和區塊體兩部分[17-18],其存儲結構如圖2所示。以比特幣為例[19],區塊頭存儲了版本號、前一個區塊的哈希值(父哈希)、時間戳、Merkle根、難度值和一個隨機數,區塊體由交易信息構成,所有的交易以Merkle樹的結構存儲。其中,哈希指針能唯一標識區塊并將各個區塊相連接,使得區塊中的每條數據可以追溯到源頭,時間戳則保證了區塊的有序性。同時利用Merkle樹,可以單獨下載一個分支對部分數據校驗,實現高效的交易驗證。
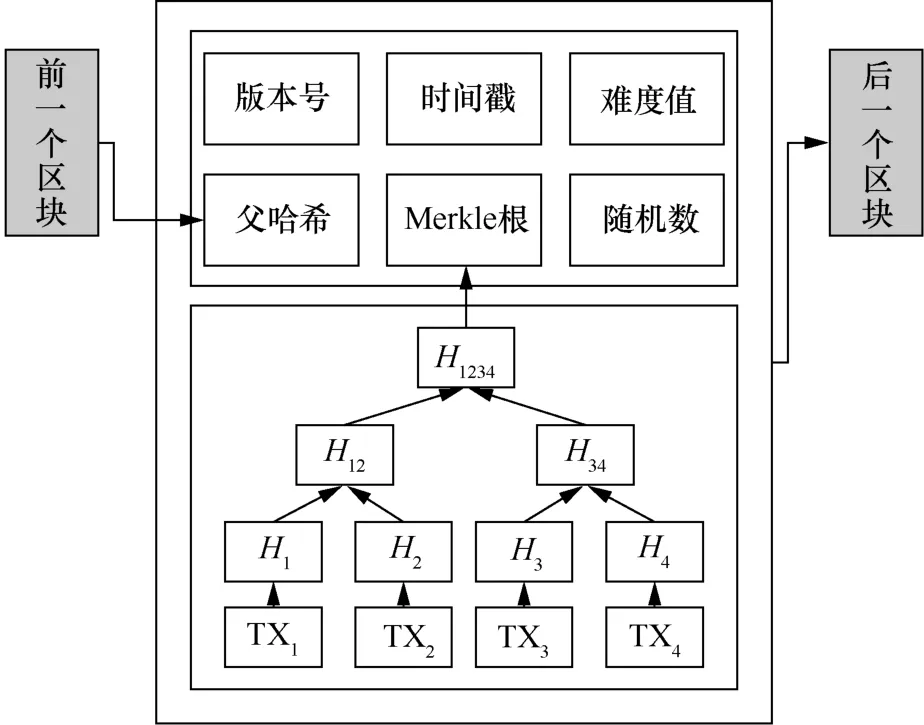
圖2 區塊結構Figure 2 The structure of blocks
依據賬本權限準入機制的不同,區塊鏈可以劃分為公有鏈、私有鏈和聯盟鏈[20],如表1所示。公有鏈沒有權限設定,任何人都可以隨時加入網絡,鏈上數據對全網公開,由全體網絡節點共同維護,被認為是完全去中心化的分布式賬本,如比特幣、以太坊等。私有鏈建立在一套身份認證與權限設置的機制上,對參與節點的狀態有更多的控制權,賬本記錄不對外開放,僅在組織內部使用,如企業的財務審計、供應鏈管理等。介于前兩者之間,聯盟鏈采用混合的組網機制,網絡中的節點只有部分控制權,信息對多個組織構成的聯盟成員開放,通常應用于企業合作,如銀行間的結算、企業間物流管理等。

表1 區塊鏈分類Table 1 Classification of blockchain
本文面向移動網絡提出的聯邦學習方案,具有以下3個特點:一是參與方的種類確定,由擁有各種終端設備的移動用戶組成;二是訓練得到的模型參數涉及用戶的隱私,不會隨便對外公開;三是需要較高的交易速度,要求節點之間能夠較快達成共識,對參與方的信譽實現高效管理。基于上述特點,本文采用聯盟鏈作為底層區塊鏈。
2.2 智能合約
智能合約是一套以數字形式定義的承諾,該承諾控制著數字資產流轉,并包含了合約參與者約定的權利和義務,合約是由計算機系統自動執行[21]。智能合約中的內容以數據化的形式寫入區塊鏈中,由區塊鏈技術的特性保障存儲、讀取、執行[22]。智能合約的自動化和可編程特性使封裝分布式區塊鏈系統中各節點的復雜行為得以實現,這促進了區塊鏈技術在各類分布式系統中的應用。
智能合約中的數據主要分為storage和memory兩種類型。前者也可稱為合約的狀態變量,會永久存儲在區塊鏈中,后者則是臨時變量,交易處理完成后會被清空。因此,在編寫合約時要為永久存儲的數據定義storage類型變量,而不僅僅是處理交易邏輯。
3 方案設計
本文提出一種基于信譽評估機制和區塊鏈的移動網絡聯邦學習方案。首先,介紹系統的架構和工作流程;然后,分別為任務發布方和數據擁有方設計了具體的信譽意見共享激勵機制和信譽評估機制。
3.1 系統架構
本節介紹的系統架構主要包括系統模型和敵手模型兩個部分。
3.1.1系統模型
基于聯盟鏈的移動網絡聯邦學習系統主要由移動設備、數據擁有方、任務發布方和區塊鏈服務平臺4個部分組成,如圖3所示。
1) 移動設備主要由各種移動網絡中的物聯網設備組成,包括智能手機、可穿戴設備、車輛傳感器和家用電器等。移動設備是執行聯邦學習任務的基礎設施,不僅可以從應用程序生成各種用戶數據,而且可以收集大量傳感數據。
2) 數據擁有方是收集、存儲和處理數據的實體。數據擁有方負責收集來自移動設備的數據,并存儲在本地的數據庫中。在模型訓練期間,首先,每個數據擁有方根據任務發布方的全局模型參數和訓練數據本地生成局部模型參數。然后,所有數據擁有方將各自的局部模型參數發送給任務發布方,以便更新下一輪的全局模型。接著,數據擁有方重復訓練過程,直到全局模型的精度達到預定的期望值。
3) 任務發布方主要由各種需要模型的物聯網設備和機構組成,如無人駕駛汽車、家政服務機器人、醫療機構和安全監管部門等。任務發布方負責公開聯邦學習任務的規范,如應用程序類型、設備類型、訓練數據的類型與格式、學習模型的類型和計算要求等,并根據實際情況選擇合適的數據擁有方。同時,任務發布方需要評估數據擁有方的局部模型質量,根據他們的評估結果生成信譽意見索引,然后制定相關的合約策略,并將信譽意見索引和合約策略一起上傳到區塊鏈服務平臺,以供其他任務發布方在聯邦學習中選擇信譽較好的數據擁有方。
4) 區塊鏈服務平臺是存儲信譽意見索引和合約策略的第三方平臺,由一組具有足夠計算和存儲資源的礦工維護。礦工通過共識算法進行驗證后,將接收到的信譽意見索引存儲到數據塊中。由于區塊鏈可追溯和防篡改的性質,當數據擁有方發送低質量的局部模型時,數據塊中相關信息可以作為持久且透明的證據。任務發布方將直接信譽意見與其他任務發布方的最新信譽意見進行集成,生成數據擁有方的綜合信譽值,將其作為在聯邦學習過程中選擇可靠數據擁有方的重要指標。此外,任務發布方通過區塊鏈中預先定義的訪問控制策略,確保信譽意見的安全共享,其他任務發布方對信譽意見的訪問都將保存在區塊鏈中。
3.1.2敵手模型
由于移動網絡體系結構的開放性和復雜性,參與用戶在合作訓練時存在著巨大的安全隱患。例如,數據擁有方通過不可靠的無線通信信道傳輸數據,導致遭受惡意攻擊,從而影響數據的可用性。針對面向移動網絡的聯邦學習可能產生的安全問題,本文著重考慮投毒攻擊和合謀攻擊。投毒攻擊是指在本地訓練過程中,惡意的數據提供方通過攻擊訓練數據集來操縱模型預測的結果。投毒攻擊主要有兩種方式:數據投毒(對訓練集中的樣本進行污染,如添加錯誤的標簽或有偏差的數據,降低數據的質量)和模型投毒(改變模型參數的變化方向,如發送錯誤的參數,減慢模型的收斂速度)。合謀攻擊是指任務發布方和某個數據擁有方進行主動合作,在對數據擁有方的模型質量進行評估時,生成不符合實際的信譽意見(如對低質量的模型按高質量的模型處理),故意誤導其他任務發布方選擇特定的數據擁有方。這兩種攻擊都會對全局模型的準確性產生負面影響,降低誠實參與方的積極性。
3.2 系統工作流程
基于聯盟鏈的移動網絡聯邦學習系統如圖3所示。系統可以借助區塊鏈服務平臺為任務發布方選擇信譽較高的數據擁有方進行模型訓練,具體描述如下。

圖3 基于聯盟鏈的移動網絡聯邦學習系統Figure 3 The system of federated learning for mobile network based on a consortium blockchain
步驟1任務發布階段。任務發布方將聯邦學習任務的規范廣播到全網,滿足要求的數據擁有方將數據集信息的摘要發送給任務發布方,該數據擁有方成為模型訓練的候選人。
步驟2數據擁有方選擇階段。為了獲得高質量的全局模型,在訓練模型前,任務發布方需要預先從區塊鏈服務平臺下載候選數據擁有方最近一段時間的信譽意見。基于區塊鏈和聯邦學習的移動網絡中含有兩種類型的信譽意見:直接信譽意見和間接信譽意見。任務發布方通過融合這兩種意見對每個數據擁有方做出綜合評價,選擇信譽值較高的數據擁有方參與聯邦學習的任務。
步驟3模型訓練評估階段。任務發布方向參與訓練的數據擁有方發送初始化后的全局模型參數。數據擁有方收到參數后,在本地依據所持有的數據,通過隨機梯度下降算法,尋找局部模型參數,使損失函數最小化,并將更新的模型參數上傳到任務發布方。為了識別進行投毒攻擊的數據擁有方,任務發布方需要執行一些投毒攻擊檢測方案。RONI(reject on negative influence)和FoolsGold分別是針對數據獨立同分布(IID)和非IID場景下的攻擊檢測方案。通過這兩種方案,任務發布方可以拒絕接受惡意數據擁有方的局部模型參數,并按照文獻[23]的方法計算其他局部模型參數的平均值。在每次迭代過程中,進行投毒攻擊的數據擁有方將會被記錄下來,任務發布方依此為其生成本地信譽意見。
步驟4信譽值更新階段。首先依據歷史記錄對數據擁有方生成直接信譽意見后,這些意見被當作交易由任務發布方簽名后上傳到區塊鏈服務平臺。然后,礦工驗證信譽意見的有效性,并執行實用拜占庭容錯(PBFT,practical Byzantine fault tolerance)共識算法將其上鏈。至此,信譽值的更新工作完成,所有的任務發布方都可以通過查詢區塊鏈上的信譽意見選擇表現良好的數據擁有方以完成聯邦學習任務。
3.3 信譽意見共享激勵機制
為了對任務發布方上傳信譽意見的行為進行監督,激勵更多任務發布方提供高質量的信譽意見,本文設計了一種信譽意見共享激勵機制。該激勵機制主要分為兩部分:基于智能合約的信譽意見管理和任務發布方信譽的評價。前者將信譽評估機制集成到智能合約中,為任務發布方提供可調節的共享策略;后者提出了計算信譽值的具體方法,為任務發布方調節共享策略提供依據。本節首先介紹基于智能合約的信譽意見管理,對任務發布方信譽的評價將在下一節進行介紹。
在本文的方案中,智能合約負責所有的交易邏輯處理,包括用戶節點注冊、信譽意見共享、信譽意見訪問和信譽意見更新4種交易。其中,節點注冊交易負責登記用戶身份,只有在區塊鏈中注冊的任務發布方才能進行信譽意見的共享、訪問和更新。智能合約狀態變量保留了永久性存儲在區塊鏈中的數據,為任務發布方的身份驗證、信譽意見的共享及任務發布方信譽值計算提供數據支撐。智能合約函數用于處理合約的內部邏輯,實現請求和更新等功能。智能合約狀態變量說明和智能合約函數說明分別如表2和表3所示。

表2 智能合約狀態變量說明Table 2 Description of smart contract variables

表3 智能合約函數說明Table 3 Description of smart contract functions
(1)用戶身份注冊
任務發布方將真實身份ID、身份證明Vid、注冊地址address和公鑰pk等信息發送給區塊鏈服務平臺上的審計節點,申請將信息登記到區塊鏈中。在該過程中,審計節點驗證任務發布方的身份信息,身份驗證成功后調用合約接口node_register()將任務發布方的信息寫入區塊鏈,同時將信息更新到審計節點變量audit_node。任務發布方注冊成功后就能夠上傳和下載有關數據擁有方的信譽意見。注冊過程如算法1所示。
算法1節點注冊算法

(2)信譽意見共享
聯邦學習任務結束后,任務發布方生成本地信譽意見reo,并且用隨機產生的對稱密鑰smk加密 [reo]smk。任務發布方將 [reo]smk上傳到云端,云端返回信譽意見的存儲索引url。任務發布方使用公鑰pkp加密smk獲得 [smk]pkp,然后調用接口函數contribute_reo()創建共享交易REO_TXID。合約內部執行函數verify_pk(),檢測任務發布方的身份注冊信息,驗證通過后將信譽意見相關信息存入變量reo_share[url_hash]中,該變量指向reo_sharing結構體。同時合約調用內部函數set_url_pk()將url與任務發布方公鑰pkp的對應關系記錄到變量url_pk[url_hash]中。之后合約為該信譽意見初始化白名單url_whitelist[url_hash],將任務發布方的信息及解密 [smk]pkp的私鑰存入白名單所指向的pk_whitelist中。隨后,任務發布方調用合約給白名單添加成員,允許其他信譽較高的任務發布方訪問信譽意見。本文方案基于移動網絡中只有少數任務發布方是惡意的這個假設,在共享過程中,單個任務發布方生成本地意見后進行修改對數據擁有方的信譽值幾乎沒有影響,因為所提方案會根據數據擁有方的歷史交互記錄和其他多個任務發布方的間接信譽意見,結合熵的理論定義自適應權重,對數據擁有方進行綜合的信譽評估,從而使信譽評估客觀準確。信譽意見共享如算法2所示。
算法2信譽意見共享算法

任務發布方在每次進行聯邦學習前,執行信譽意見訪問算法請求得到其他任務發布方的信息意見,以選擇可靠的數據擁有方。請求方輸入被訪問任務發布方的公鑰pkp及信譽意見索引路徑哈希url_hash、自己的公鑰pkr調用函數request_smk()后,合約驗證請求方的身份,如果驗證成功,合約會判斷請求方是否在被訪問任務發布方的白名單中,如果存在就會更新請求方的訪問時間,并返回加密密鑰 [smk]pkr,請求方用私鑰就可以解密得到對稱密鑰;否則視為請求方在被訪問任務發布方的本地信譽較低,任務發布方拒絕訪問,訪問失敗。此外,在訪問鏈上相應資源時,還需要由區塊鏈服務平臺上的審計節點進行身份認證。如果非白名單中的任務發布方通過與白名單中的任務方合謀得到對稱密鑰,不在白名單的任務發布方在認證時不會被通過,從而無法獲取信譽意見reo。信譽意見的訪問如算法3所示。
算法3信譽意見訪問算法

請求方會在本地對其他任務發布方的信譽意見進行評估,若某一任務發布方信譽較低的次數超過設定的閾值,請求方就會調用函數update_smk_remove(),將該任務發布方從自己的白名單中移除。信譽意見的更新如算法4所示。
算法4信譽意見的更新


3.4 信譽評估機制
本節給出計算任務發布方和數據擁有方信譽值的具體方法。
3.4.1對任務發布方的信譽評估
任務發布方會根據其他任務發布方的信譽意見在本地對其進行信譽評估,從而調用信譽意見共享算法調整信譽意見共享策略。被評價任務發布方提供的信譽意見越可靠,信譽值就越高,可訪問的信譽意見資源就越多。任務發布方的信譽并不能從單一特性進行評估,本文采用模糊層次分析法[24-25]對任務發布方的信譽進行評估。先將任務發布方的信譽分為n個特性,再把每個特性分為若干個特征類型,將任務發布方行為信譽評估問題轉化為簡單明確的信譽特征加權求和問題。FAHP計算任務發布方信譽值的過程分為以下4個步驟。
步驟1將信譽分為3層,如圖4所示。為了不給區塊鏈造成負擔,任務發布方會在本地分析其他任務發布方的信譽意見并依據區塊鏈網絡中交易情況,從而確定被評價任務發布方的行為特征。
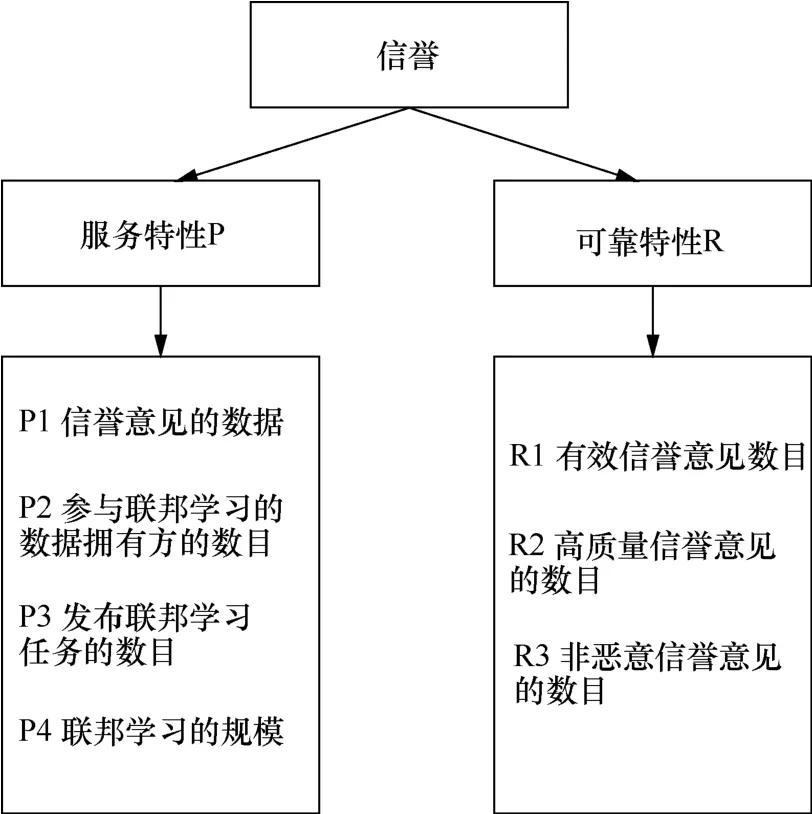
圖4 任務發布方行為特征分類Figure 4 Classification of task publisher behavior characteristics
步驟2建立行為特征矩陣為特性個數,m為特性中行為特征個數的最大值,不夠的項用零補充。為了便于計算和評估任務發布方行為,需要對矩陣C進行歸一化處理,將其規范為[0,1]的特征矩陣將同一特性下的特征按重要性做二元對比,獲得初始判斷矩陣EQ=[eqij]m×m。以服務特性為例,特征個數為4,特征矩陣Ep=[e1,e2,e3,e4],利用式(1)獲得初始判斷矩陣EQp。
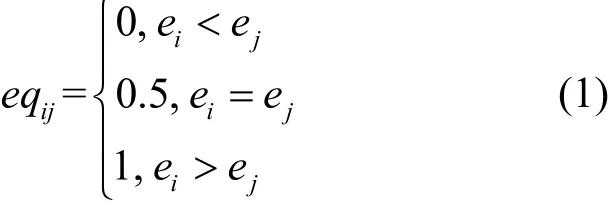
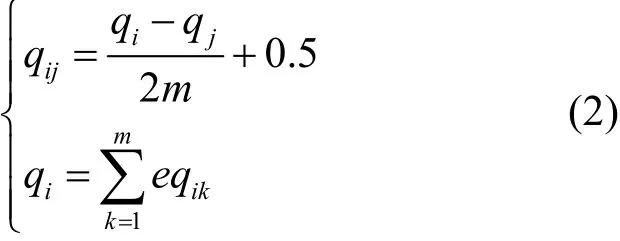
步驟3使用式(3)計算服務特性下個特征的
權重向量,從而得到wP=[wP1,wP2,wP3,wP4],對于可靠特性,同樣利用式(1)~式(3)得到可靠特性R的特征權重向量wR=[wR1,wR2,wR3]和特性權重向量Wf=[wP,wR]。
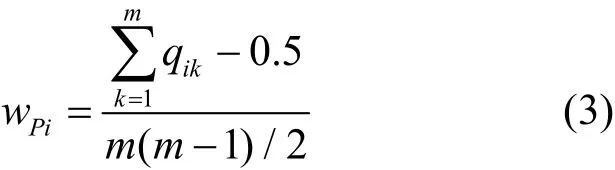
步驟4由特征矩陣E=[eij]n×m,權重矩陣W=(wij)n×m,根據E×WT得到的矩陣對角線上的值就是任務發布方的特性評估值矩陣F=(f1,f2,…fn),最后,任務發布方的信譽值表示為
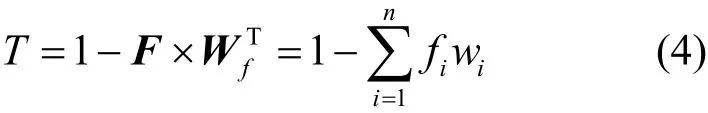
3.4.2對數據擁有方的信譽評估
在移動網絡中,有效和準確的信譽計算方法會激勵更多數據擁有方提供高質量的模型參數。本文在主觀邏輯的基礎上,采用貝葉斯理論消除訓練過程中的不確定交互,根據數據擁有方的歷史交互記錄和其他多個任務發布方的間接信譽意見,結合熵的理論定義自適應權重,制定了一個綜合的信譽評估方案。下面從信譽計算涉及的相關定義和評估方法進行詳細闡述。
定義1(交互)數據擁有方從任務發布方下載全局模型參數,并根據本地數據迭代訓練上傳一次參數的過程被稱為一次交互。其中,通過任務方投毒攻擊檢測方案的為正交互,否則為負交互。當數據擁有方未上傳任何參數時,即代表出現了不確定交互。
定義2(歷史交互)歷史交互是在Δt時間內任務發布方對數據擁有方交互記錄的集合t={s,f},其中,s和f分別為正交互的數目和負交互的數目。
本文在計算數據擁有方信譽值時采用了3種信譽評估的方法,分別為直接信譽評估、間接信譽評估和綜合信譽評估。
(1)直接信譽評估
根據主觀邏輯的概念,將任務發布方i在Δt時間內對數據擁有方j的信譽評價表示為一個三元組的形式 γi→j= {bi→j,di→j,ui→j}。bi→j是相信數據擁有方j服務質量的真實概率,di→j是認為數據擁有方服務是低質的概率,ui→j表示對數據擁有方j服務質量的不確定性。其中bi→j,di→j,ui→j?(0,1),并滿足以下要求
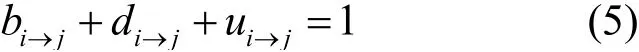
進一步,基于主觀邏輯的本地模型[14,26]和定義2,可以得到:

其中,qi→j是參數傳輸成功的概率,代表著通信質量。為了使信譽評價更精確,當數據擁有方j出現不確定交互時,本文使用貝葉斯公式預測數據擁有方出現正交互的概率,即
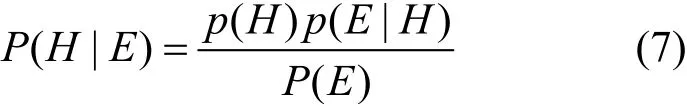
其中,將數據擁有方j的歷史交互ti→j作為前置條件E,出現正交互的行為作為事件H。假設事件E發生的條件下事件H發生的概率服從Beta分布,則數據擁有方j的不確定交互行為對信譽影響的相關系數ai→j可以用Beta分布[27]的數學期望表示為
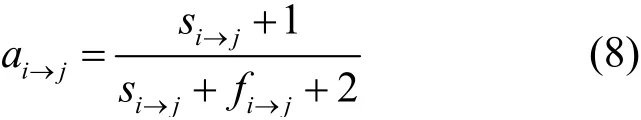
相關系數ai→j表示數據擁有方j不確定交互時表現為正交互的概率。結合式(6)、式(8),在一次聯邦學習任務中,任務發布方i對數據擁有方j直接信譽值Ti→j的計算公式為
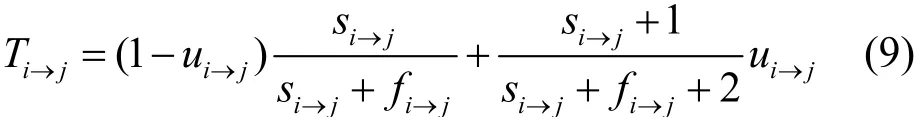
為了使評估具有更高的可靠性和可信度,本文考慮了活躍度和實效性兩個因素。
① 活躍度。模型的訓練過程需要考慮數據擁有方的計算成本和通信成本,其交互數目越多,付出的成本就越高。數據擁有方j的活躍度是任務發布方i在一定時間窗口與其交互的數目和與其他數據擁有方平均交互數目的比率,即

其中,ri→j=si→j+fi→j,表示任務發布方i與數據擁有方j在一定時間窗口內交互的總數目。本文假設在這個時間窗口與任務發布方交互的數據擁有方的集合為S。結合式(6)、式(9)和式(10),信譽值Ti→j的計算公式可以進一步調整為
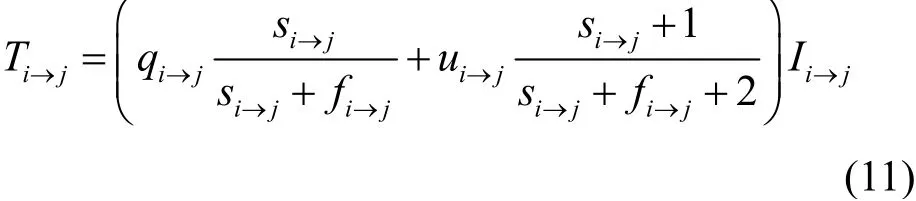
調整后的信譽值與活躍度相關,這不僅能反映當前數據擁有方自身的交互情況,也能反映它在所有交互情況下所占的比例。
② 時效性。歷史交互是任務發布方和數據擁有方在Δt時間內交互記錄的集合,因此對數據擁有方的信譽評價隨時間動態變化。一般來說,最新的歷史交互要比過去的歷史交互影響大,對信譽值計算有更多的參考價值。為了準確及時反映信譽評價的時效性,本文用ε表示最新歷史交互的權重,σ表示過去歷史交互的權重,ε+σ=1,ε>σ且ε,σ? (0,1)。具體ε的大小可以根據交互情況和歷史經驗獲得。據此,信譽值的更新公式表示為
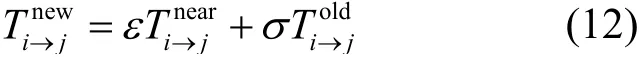
與社交網絡相似,移動網絡中的每個任務發布方在評估數據擁有方的信譽值時,會間接參考其他任務發布方對當前數據擁有方的信譽評估。間接信譽值是其他任務發布方k對數據擁有方j評估的直接信譽值,是任務發布方i通過查詢區塊鏈得到的。
考慮到其他任務發布方可能與一些數據擁有方串謀欺騙,因此間接信譽值并不都是可信的。本文引入信息熵的概念給不同的間接信譽值分配權重,可有效改善主觀分配權重帶來的問題,增強模型適應性。根據式(13),計算信譽值的熵。
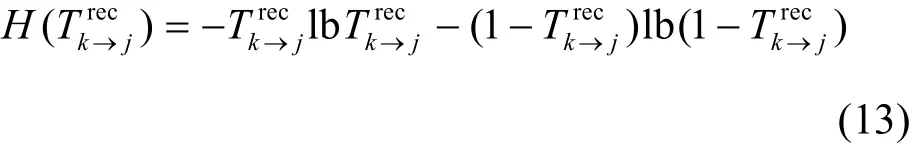
信息熵能夠反映間接信譽值之間的差異程度,即各間接信譽值偏離整體間接信譽值集合的程度。一些任務發布方可能為了利益對數據擁有方做出不切實際的信譽評價,造成信譽值的計算過高或者過低,信息熵將這種行為識別出來,使其信譽值在整體間接信譽評價中占有很小的比例,從而使間接評估客觀準確。通常,間接信譽值之間的差異化程度越小,對數據擁有方的間接評估就越客觀,因此,可以利用式(14)計算各間接信譽值的權重。
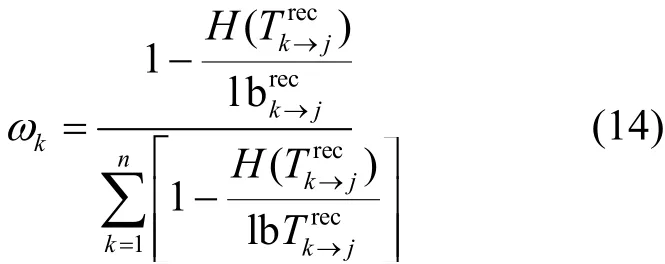
其中,n表示間接信譽值的個數。最后,全局的間接信譽評估值為
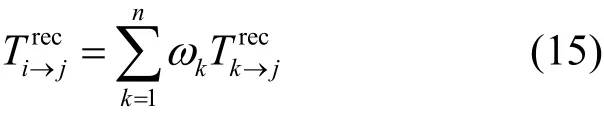
(3)綜合信譽評估
任務發布方i的綜合信譽評估方法是將直接信譽值Ti→j和全局間接信譽值進行合成,從而得到數據擁有方j的綜合信譽值,使評估過程全面準確。合成的方法是利用兩者所提供信息的效用值,即根據兩種評估方法之間的差異程度對信譽值的權重進行修正,因此,綜合信譽值由式(16)計算。
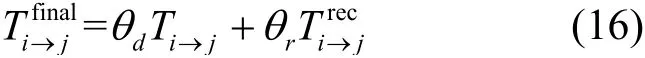
其中,dθ和rθ分別是直接信譽值Ti→j和間接信譽值的自適應權重,和分別是的信息熵。
4 系統評估與分析
4.1 安全性分析
本節證明所提出的方案可以有效防止投毒攻擊和合謀攻擊。
(1)防止投毒攻擊
本文通過檢測模型參數和信譽評估兩種方法可有效防止投毒攻擊。一方面,在模型訓練階段,惡意數據擁有方上傳的模型參數由本次的任務發布方進行檢測。只有檢測成功的模型參數才會用于模型的聚合,從而去除了可以對模型產生負面影響的參數。另一方面,在模型評估階段,未通過檢測的數據擁有方會被記錄下來,任務發布方根據記錄生成信譽意見并上傳到區塊鏈服務平臺。惡意數據擁有方投毒的次數越多,其信譽值越低。任務發布方能夠通過查看區塊鏈上的信譽記錄選擇信譽值較高的數據擁有方參與模型訓練,從而降低了惡意數據擁有方投毒的可能。
(2)防止合謀攻擊
為了防止一些任務發布方與數據擁有方進行合謀攻擊,必須確保在計算間接信譽評估值時,這些任務發布方的信譽評估占有很小的權重。信息熵可以反映數據擁有方信譽值的無序化程度,也就是各個信譽值偏離整個推薦信譽集合的程度。任務發布方做出的不切實際的信譽評估會被信息熵識別出來,從而保證數據擁有方能夠獲得客觀準確的評價。同時,與任務發布方合謀的數據擁有方作惡一次后,其信譽值會顯著下降。只有通過更多的正交互才能提高信譽值。作惡時間段越短,信譽值下降越快,被選中參與聯邦學習的可能性就越小。此外,任務發布方之間通過其行為特征互相評價,信譽較低的任務發布方將被大多數用戶從白名單中移除,從而無法訪問信譽意見資源。
4.2 性能分析
4.2.1實驗設置
為了評估所提出方案的性能,本文基于經典的Car Evaluation分類數據集進行了仿真實驗。該數據集包括1 728個測試實例,6個測試屬性和4類標簽。本文將數據集隨機分配給10個數據擁有方,其中包括3個惡意數據擁有方,它們會有意修改實例的標簽(修改后訓練實例數量占本地數據實例數量的百分比表示攻擊強度),操縱聯邦學習的結果。本文在Hyperledger Fabric v1.4.0上建立了信譽區塊鏈系統,共識算法采用實用高效的PBFT算法[14]。
3.4.2節介紹了任務發布方信譽值的計算方法,使用FAHP對任務發布方的行為特征進行劃分,其中,服務特性P的重要性劃分為P1>P2>P3=P4,可靠特性R的重要性劃分為R1=R2=R3,特性的重要性劃分為R>P。本文進行了20次聯邦學習的實驗,每次聯邦學習任務的最大迭代次數為50。新歷史交互的權重交互ε=0.6,過去歷史交互的權重σ=0.4。數據包傳輸失敗的概率為1%~40%,且數據擁有方的初始信譽為0.5。同時,將本文提出的結合貝葉斯的主觀邏輯模型與文獻[28]中的多權重主觀邏輯模型(multi-weight subjective logic model)進行比較,以分析在不確定交互情況下兩種方案對信譽值和聯邦學習準確性的影響。
4.2.2實驗結果
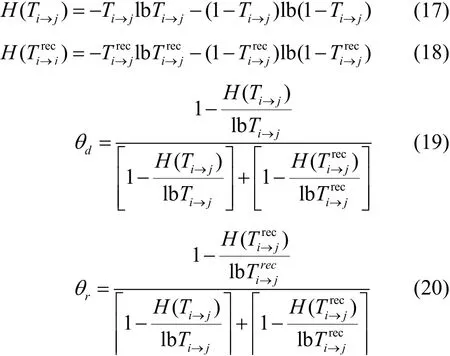
圖5 展示了惡意攻擊者在不同攻擊強度下對聯邦學習的影響。可以看出,攻擊強度的提高會導致聯邦學習準確率的降低。此外,當攻擊強度相同時,攻擊者越多,聯邦學習的準確率就會越低。當攻擊強度為0.9,且存在3個攻擊者時,聯邦學習的準確率僅為71%,攻擊強度為0.5且比有一個攻擊者的情況低26%。因此,攻擊強度和攻擊者數量的提高能夠對聯邦學習的準確性產生明顯的負面影響。
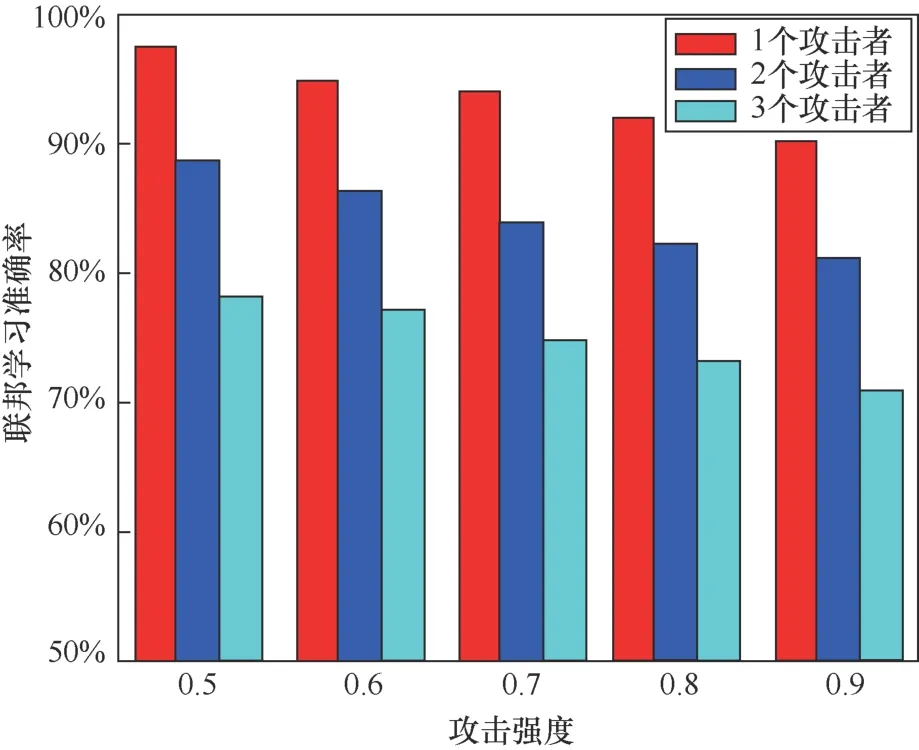
圖5 攻擊強度對聯邦學習準確率的影響Figure 5 The impact of attack strength on federated learning accuracy
為了測試惡意攻擊者在不同聯邦學習任務次數下的信譽變化,本文設定該攻擊者在前8次和最后4次聯邦學習任務中不進行攻擊,目的是獲得較高的信譽值。但在第9~16次實驗中,會向任務發布方上傳惡意的模型參數,實驗結果如圖6所示。在前8次實驗中,本文方案和文獻[28]中的方案對攻擊者的信譽值沒有很大差異,其信譽值總體是增加的,中間出現的波動主要是由于受到了通信質量的影響。當攻擊者采取攻擊行為時,其信譽值顯著下降,且本文的方案比文獻[28]方案信譽值下降更快。在整個攻擊期間,信譽值從0.87下降到0.66,下降了0.21。在之后的實驗中,本文方案攻擊者的信譽值已有所增加,但文獻[28]方案的信譽值仍在降低。圖7展示了信譽值閾值對聯邦學習準確率的影響。如果計算后的數據擁有方信譽值低于給定的信譽閾值,則該數據擁有方被視為不可靠的參與方。
圖6 一個攻擊者在不同聯邦學習任務次數下的信譽值變化Figure 6 The reputation value of an attacker under different number of federated learning task

圖7 信譽值閾值對聯邦學習準確率的影響Figure 7 The impact of reputation value thresholds on federated learning accuracy
從圖7中可以看出,隨著信譽值閾值的增加,聯邦學習的準確率也會增加。當信譽閾值范圍為0.35到0.5時,文獻[28]方案中的準確率比本文方案的準確率低,但當信譽值閾值不小于0.55時,文獻[28]方案的性能與本文相同。這是由于本文在計算信譽值時采用貝葉斯公式,計算了數據擁有方在傳輸失敗時的信譽值,更多地考慮了節點正交互的影響,而文獻[28]忽略了這種情況,這會導致部分表現良好的數據擁有方信譽值偏低,被選擇參與聯邦學習的概率降低,從而降低參與方的積極性。當信譽值閾值高于0.55時,任務發布方更容易檢測惡意的數據擁有方,兩種方案都會選擇信譽較高的數據擁有方,因此聯邦學習的準確率沒有差別。
綜上,本文的方案可以實現更準確和公平的信譽計算,從而能夠使任務發布方選擇更可靠的數據擁有方。
5 結束語
本文提出了一種基于信譽評估機制和區塊鏈的移動網絡聯邦學習方案。為了選擇可靠的數據擁有方參與模型訓練,引入了基于信譽的選擇方法,并采用主觀邏輯模型和貝葉斯模型,根據數據擁有方的交互歷史和間接信譽評估計算其信譽值。通過將信譽評估機制和訪問策略集成到智能合約中,任務發布方對數據擁有方做出的信譽意見被存儲到聯盟鏈中。實驗分析表明,本文的方案可以選擇更多的信譽較高的數據擁有方參與訓練,提高聯邦學習的準確率。此外,數據擁有方的數量和聯邦學習算法的選取與信譽值的計算密切相關,如何動態地調節信譽值閾值的大小,將惡意數據擁有方的負面影響降到最低,是本文下一步的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
