基于區塊鏈的數據完整性多方高效審計機制
2022-01-18 08:24:36周家順王娜杜學繪
網絡與信息安全學報 2021年6期
周家順,王娜,杜學繪
(信息工程大學,河南 鄭州 450001)
1 引言
大數據技術高速發展,并深入人們的生活。政務大數據[1]、司法大數據[2]、醫療大數據[3]等大數據技術正在逐漸為社會的進步提供有力的數據技術支撐。但是大數據具有與傳統數據不同的特點,需要使用適合大數據特點的技術進行處理。
大數據最顯著的特點就是數據量大,據Statista公司預測2025年的全球數據量將達到175 ZB。數據量的激增促使相應的存儲技術的發展,本地存儲、分布式存儲、云存儲等存儲技術為大數據存儲提供了技術支撐。為保證大數據存儲的安全,需要進行數據完整性驗證[4]判斷數據是否被篡改或者損壞。
數據完整性驗證技術一般通過挑戰應答機制實現數據完整性的判斷。數據擁有者將數據存儲于數據存儲系統中,在數據進行存儲之前利用BLS簽名等技術實現存儲數據的簽名,并生成證明元數據。數據擁有者從證明元數據中選取相應的數據生成挑戰,并將挑戰發送給數據存儲系統。數據存儲系統依據收到的挑戰,利用存儲的數據生成相應的數據完整性的證據。數據完整性審計機構對數據存儲系統生成的證據進行判斷,確定數據是否與原始數據一致。
對于大數據進行數據完整性審計需要充分考慮大數據的特點。
1) 大數據數據量大的特點要求數據完整性驗證技術能夠滿足審計的效率要求,實現數據完整性的高效判決。
2) 由于大數據的來源廣泛,大數據的數據類型變得多樣,數據可以分為結構化、半結構化和非結構化3種類型[5]。例如,政務大數據中的數據類型可以分為4類:業務數據、民意社情數據、環境數據和分散性公共數據[6]。大數據環境下的數據主要為非結構化數據,據IDC統計顯示,大數據中非結構化數據占比80%,非結構化數據完整性驗證成為大數據完整性驗證的關鍵。
3) 同時,信息化時代,數據成為越來越重要的資源。通過共享大數據來打破數據孤島,成為信息企業面臨的重要挑戰。數據共享不僅需要實現數據交換,也要保證數據的真實性。例如,對于政務大數據、司法大數據和醫療大數據這些較為敏感的數據,數據真實性的重要程度表現極為突出。
大數據的完整性驗證不僅需要向數據擁有者提供數據未被篡改或者未被破壞的證明,對于共享數據的使用者同樣需要進行證明。
中本聰發表文章Bitcoin: a peer to peer electronic cash system[7],標志著區塊鏈技術的誕生。從此之后,區塊鏈技術以其去中心化,不易篡改等良好特性吸引大批學者研究。數據的完整性驗證技術實際上是對于數據存儲者等多方信用的驗證,將區塊鏈技術與數據完整性驗證技術結合能夠發揮數據完整性驗證體系更大的價值。
基于此,本文提出基于區塊鏈的數據完整性多方高效審計機制(MBE-ADI),解決大數據環境下數據完整性的審計問題,主要貢獻如下。
1) 提出大數據環境中數據域的概念并構建基于數據域的混合Merkle DAG結構,實現對非結構化數據的管理,借助此結構實現證明元數據的生成,解決大數據環境下大量非結構化數據同時驗證的問題。
2) 設計基于BLS簽名多副本確定性驗證方法,實現數據完整性的多副本同時確定性驗證,滿足大數據環境下數據完整性高效驗證的需求。
3) 設計基于聯盟鏈的雙驗證審計架構,相應智能合約以及驗證過程元數據上傳方法,實現數據完整性去中心化自動審計以及審計歷史可信追溯,同時為數據擁有者和數據使用者提供數據完整性驗證服務,保證數據進行共享之前的歷史一致性,提高數據的可信度。
4) 基于阿里云服務器進行MBE-ADI系統部署并進行相關測試,驗證系統的可行性以及數據完整性審計的高效性。
2 研究現狀
Deswarte等[8]提出基于MAC碼的完整性驗證機制,該機制將MAC值作為認證元數據實現數據的完整性驗證,但存在通信開銷大且容易泄露隱私的問題。Ateniese等[9]提出數據持有性證明(PDP,provable data possession)機制,將數據分塊并使用RSA簽名機制進行抽樣檢測數據塊的完整性,提高了檢測效率,減少了通信開銷。Wang等[10]提出支持全同態操作的PDP機制,該機制使用Merkle樹驗證數據塊位置的正確性,采用BLS簽名對數據塊的完整性進行驗證。謝四江等[11]提出使用多分支路徑樹MBT進行完整性驗證的機制,該機制增加了節點的出度,相較于基于Merkle樹的完整性驗證機制能夠驗證更大規模的數據,且利用MBT的結構能夠較好地實現數據塊替換等動態操作。
多副本機制能夠提高數據的抗風險能力,即時使用多副本對損壞數據進行修復,對于重要的數據,多副本機制重要性更為突出。劉洪宇等[12]提出支持動態操作的多副本驗證機制,該機制對Merkle樹結構進行改造,提出基于等級的Merkle樹,實現對動態驗證的支持。該機制通過對多個副本進行關聯,實現多副本的同步更新。Curtmola等[13]通過隨機掩碼技術實現多副本數據的生成,為任意數量的副本使用恒定數量的元數據,可以動態創建新副本而無須再次預處理數據,且多副本完整性驗證的時間和單副本數據的驗證時間接近。但是多副本機制存在生成的隨機數等元數據過多、處理大數據量的文件時會出現元數據管理負擔過重的問題,不適合數據量大且包含大量非結構化數據的大數據環境。
以上的數據完整性驗證的審計主要使用可信第三方機構,但可信第三方機構尋找困難,容易發生第三方攻擊的問題。應用區塊鏈技術進行數據的完整性驗證成為新的選擇[14-21]。
Liu等[18]采用區塊鏈智能合約取代第三方審計機構,并認為在共享數據之前,數據使用者應該對數據的完整性進行驗證。為了實現公平的完整性審計,Zhao等[19]考慮使用區塊鏈技術進行數據完整性的驗證。數據擁有者將數據塊的簽名上傳到區塊鏈賬本,將加密后的數據上傳到云上,驗證的時候對數據進行下載,利用區塊鏈賬本記錄的數字簽名對數據的完整性進行驗證。Wei等[20]通過虛擬代理機制實現基于區塊鏈的數據完整性驗證,并結合基于角色的訪問控制技術對存儲的數據進行管控。魏艷等[21]提出基于以太坊[22]的數據完整性驗證機制,該機制在智能合約中存儲數據的哈希值以及數據簽名等信息,在進行數據完整性驗證的時候,將現有數據的哈希與智能合約中存儲的哈希進行對比實現驗證。目前基于區塊鏈的數據完整性驗證機制沒有考慮數據使用者獲取共享數據真實性的需求,僅對數據擁有者提供服務。
目前有學者注意到對于大數據進行完整性驗證的問題。Chang等[23]對外包大數據完整性驗證技術進行了總結,但與譚霜等[4]提出的技術基本一致,未體現大數據完整性驗證的特點。Chen等[24]實現數據塊的細粒度更新,采用平衡更新樹作為ADS(authenticated data structure)來減少動態更新后的更新驗證,從而減少計算和通信資源。Nasonov等[25]提出基于區塊鏈實現數據交易完整性的分布式大數據平臺,重點設計完整性管理器模塊,確保數據的真實性與一致性。Lebdaoui等[26]考慮到大數據來源廣泛以及大數據數據量大的特點,并提出數據輸入驗證模型實現對數據來源的驗證,提出連續完整性監測模型實現數據在使用過程中的完整性驗證,但僅提出了模型的框架。
綜上分析可得,目前仍需要對適合大數據環境的數據完整性驗證機制進行研究,對大數據環境下數據量大、包含大量非結構化數據和傾向共享等特點進行充分考慮。
3 基于數據域的混合Merkle DAG結構
由于大數據環境中的數據來源廣泛,且大多為結構不一的非結構化數據(例如,數據擁有者獲得的一組數據中可能同時包含圖像、視頻、文檔等),實現對這些非結構化數據的有效組織是進行高效驗證的前提。本節針對大數據環境數據中的特點,為實現對數據的有效管理,并在此基礎上生成數據完整性審計的證明元數據,提出基于數據域的混合Merkle DAG結構。在數據域層面,使用Merkle DAG結構構造非結構化數據間的組織關系;在數據塊層面,對單個數據的數據分塊構造多分支平衡Merkle樹。
本節提出數據域的概念,借助此概念實現對非結構化數據進行組織。這里的域是指對一類關聯的數據或者子數據域的包含。對于一批需要進行存儲的數據,數據擁有者根據數據的內在聯系,(如數據的來源、獲取日期、類別等)關系,對數據進行劃分,將一類數據歸置于一個域中。從而獲得一個包含所有數據和子數據域的最大域。
在該存儲結構中使用Merkle DAG。在Merkle樹的基礎上構建Merkle DAG,打破了Merkle樹的子節點個數的限制,無須進行數據的平衡操作,能夠根據實際的需要構建更為靈活的數據結構。Merkle DAG保留Merkle樹循環計算節點哈希獲得Merkle Root的特點,父節點的哈希值由子節點的哈希值決定,同時父節點包含指向子節點的信息。在IPFS[27]中將Merkle DAG作為數據的存儲結構,現實分布式文件存儲網絡。
構建基于數據域的混合Merkle DAG結構的過程如下:
1) 根據非結構化數據的包含與并列關系,構建包含所有數據的Merkle DAG文件結構;
2) 對域內的每條數據構建多分支平衡Merkle樹結構,獲取Merkle DAG節點信息中的nodeid。
3.1 構建基于數據域的Merkle DAG文件結構
針對非結構化數據構建數據域,相關聯的數據放在一個域內,數據域中包含子數據域,各級數據域表示數據不同的關聯程度,域中同時存放相關聯的多條數據,并規定域內至少包含兩個數據文件。如圖1所示,數據域為 {A,A1,A2}。A域包含 {A1,A2,d7,d8,d9}。A1域包含 {d1,d2}。A2域包含 {d3,d4,d5,d6}。
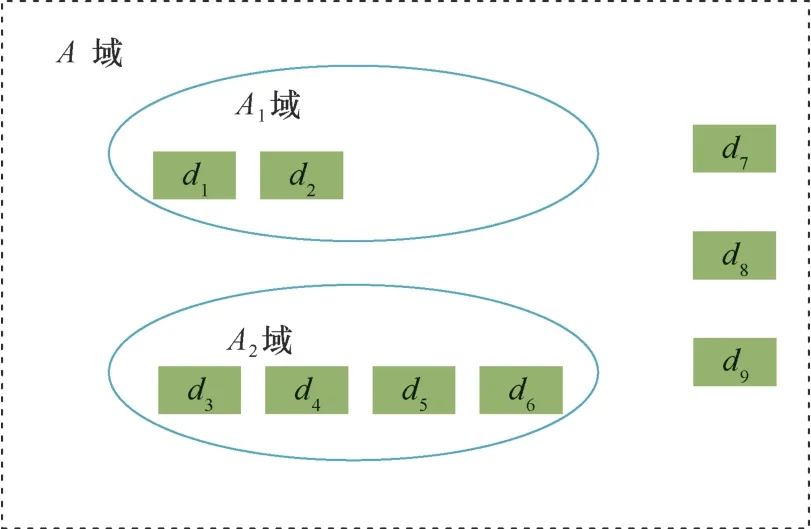
圖1 數據域結構Figure 1 Data field structure
基于數據域的混合Merkle DAG結構包含域節點和數據節點兩種節點。為每個域構建域節點標識該域,域節點如圖2所示, nodeid為該域節點的唯一標識信息,能夠使用 nodeid區分節點;Lr為右指針,指向同級域中的其他節點;{Id1, Id2,… ,Idi}為子指針,指向數據節點或者子數據域節點。
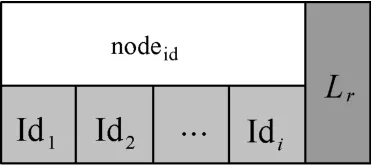
圖2 基于數據域的Merkle DAG結構域節點信息Figure 2 Domain-based Merkle DAG structure domain node information
在基于數據域的混合Merkle DAG結構中,每個非結構化數據由一個數據節點標識,數據節點如圖3所示, nodeid為該數據節點的唯一標識信息,能夠使用 nodeid區分數據節點;Lr為右指針,指向同級域中的數據節點。對圖1的數據域可以構建圖4所示的Merkle DAG文件結構。

圖3 基于數據域的Merkle DAG結構化數據節點信息Figure 3 Domain-based Merkle DAG structure data node information
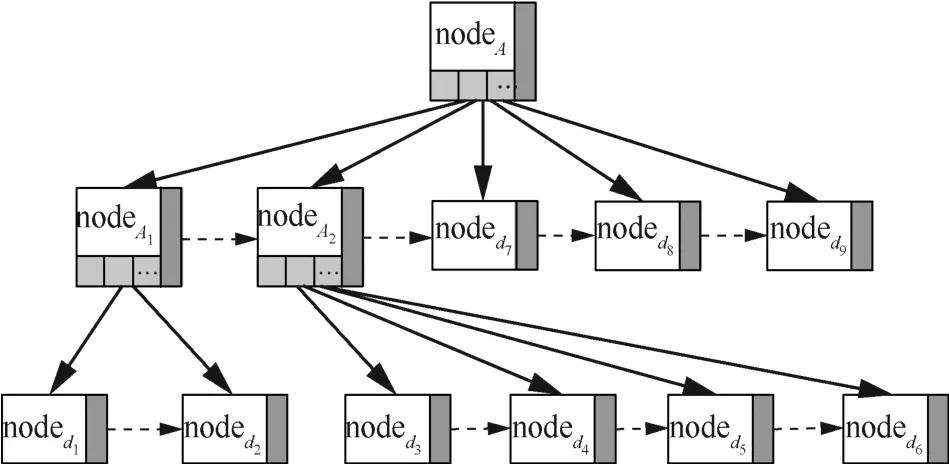
圖4 基于數據域的Merkle DAG文件結構Figure 4 Merkle DAG file structure based on data domain
3.2 獲取Merkle DAG節點 nodeid信息
構建基于數據域的Merkle DAG文件結構之后,需要獲取各個域節點或者數據節點中的nodeid。本文通過對非結構化數據構建多分支Merkle樹結構獲取標識不同節點的 nodeid。設非葉子節點最大的子節點的個數為Nmax;數據塊分割大小恒定為D。
構建多分支Merkle樹結構流程如下:
1) 數據分片。依據數據塊的分片大小對數據文件進行分片,分片之后剩余不足分片大小的數據充當最后一個數據塊。設將文件Df分成了n塊,則Df可以表示為Df= {m1,m2,… ,mn}。
2) 計算多分支平衡Merkle樹第一層節點哈希。對數據塊 {m1,m2,…,mn}分別計算哈希,獲得多分支平衡Merkle樹第一層(i為1)哈希{h(m1),h(m2),…,h(mn)}。
3) 對哈希節點分組。依據Nmax對平衡Merkle樹的第i層哈希層進行分組,每組的個數為Nmax。如果最后一組的個數不足Nmax,則將剩余的數據哈希歸為一組。
4) 計算i+1層哈希。對各組進行i+1層哈希節點的計算:hh=h(h1||h2||… ||hNmax),hh表示i+1層節點,{h1,h2,…,hNmax}表示i層某組節點,各組獲得的哈希節點組成平衡Merkle樹第i+1層哈希節點。
5) 循環計算獲得新的哈希層。對步驟3)和步驟4)進行循環,直到某層哈希節點的個數為1,將該哈希節點作為該條數據的Merkle Root,計為nodedi。
Nmax取3,數據d1可以構建如圖5所示的多分支平衡Merkle樹結構。該結構能夠滿足大數據量的表示。設非葉子節點的最大子節點的個數為Nmax,數據塊分割大小為D,設哈希層數為k,則該結構可以表示的數據量為Nmaxk-1?D。當Nmax取27,D取24 MB,k取4,則表示的數據量為461 GB。
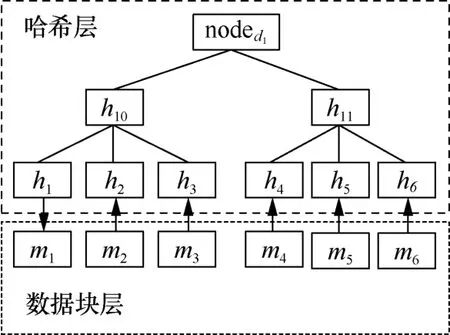
圖5 數據d1的多分支平衡Merkle樹結構Figure 5 Multi-branch balanced Merkle tree structure of data 1d
獲得數據nodedi之后,利用域中的各個數據節點的 nodeid計算數據域節點的 nodeid。例如,nodeA1表示為h(noded1||noded2)。獲得域節點和數據節點的 nodeid信息之后,便可獲得完整的基于數據域的混合Merkle DAG結構。完整的基于數據域的混合Merkle DAG結構如圖6所示。
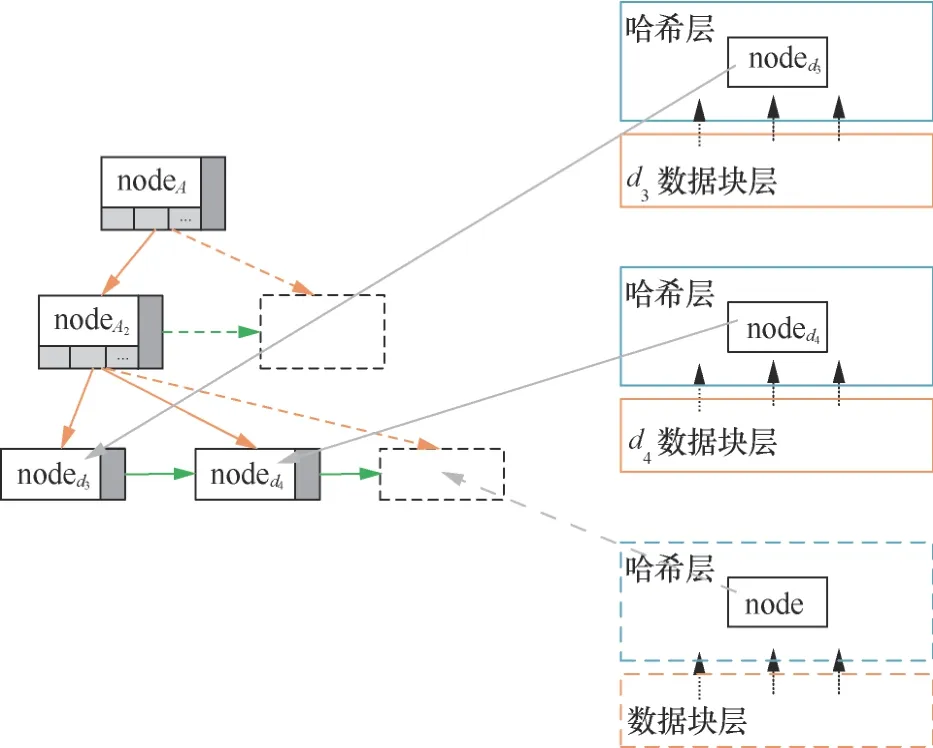
圖6 完整的基于數據域的混合Merkle DAG結構Figure 6 Integrate hybrid Merkle DAG structure based on data domain
當數據域中的非結構化數據的數據量小于構建多分支Merkle樹的分片大小時,非結構化數據不經過分片直接計算數據的哈希, nodeid=h(d)。圖7表示非結構化數據較小時,基于數據域的混合Merkle DAG結構,其構造簡單,能夠對數據個數多但數據量小的非結構化數據進行有效組織,并有利于在此基礎上生成完整性審計的證明元數據。
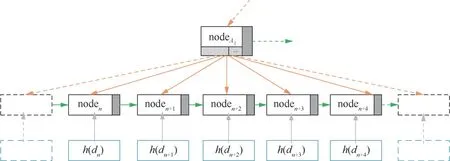
圖7 數據較小時,基于數據域的混合Merkle DAG結構Figure 7 Hybrid Merkle DAG structure based on data domain for small data
4 方案設計
4.1 MBE-ADI系統
本文考慮為某類數據相關的各方建立聯盟鏈系統。數據擁有者、數據使用者與數據存儲系統均會加入區塊鏈系統并且成為區塊鏈系統中的節點。基于聯盟鏈的雙驗證審計架構如圖8所示,DO表示數據擁有者,DU表示數據使用者,SP表示數據存儲系統。

圖8 基于聯盟鏈的雙驗證審計架構Figure 8 Dual verification audit architecture based on consortium blockchain
各個參與方在系統中包含鏈下基礎設施部分和鏈上區塊鏈節點部分。鏈下基礎設施包含存儲設施和計算設施,完成審計流程主要的存儲和計算任務。系統中通過區塊鏈網絡連接參與的各個節點,完整性審計的流程通過區塊鏈的元數據上傳合約、完整性判決合約和審計歷史索引合約實現,審計過程的關鍵數據通過區塊鏈賬本進行記錄。
在本文方案中,區塊鏈部分通過Hyperledger Fabric平臺實現。Hyperledger Fabric是由Linux基金會牽頭研發的面向企業應用的聯盟鏈平臺[28]。Hyperledger Fabric中的賬本分為世界狀態和區塊鏈兩部分。世界狀態以鍵值對的方式存儲賬本狀態的當前值,相較于遍歷整個交易日志能夠獲得更快的訪問速度。區塊鏈是交易日志,它記錄了區塊鏈賬本的完整數據,世界狀態的改變由這些交易日志決定。當鏈上數據的鍵唯一的時候,世界狀態的值就不會被改變,能夠穩定記錄數據的鍵值對。
對某個數據域的完整性審計的所有歷史記錄會在區塊鏈賬本上保存,通過檢索并審查審計歷史實現對數據域歷史可信度的增強。為保證對數據完整性審計歷史檢索的速度,本文對狀態數據庫進行檢索。為實現多類型索引查詢操作,狀態數據庫采用CouchDB數據庫。各個流程相關信息以JSON格式進行存儲,存儲的數據可以表示為:

ObjectType標識數據類型,分為data_up、challenge、prove、audit,分別代表上鏈數據、挑戰數據、證明數據、審計數據。時間戳Timestamp作為該條狀態數據的唯一標識,由區塊鏈智能合約自動生成。Node_block為需要進行數據完整性審計的數據域df節點標識,對于審計數據域,構建基于數據域的混合Merkle DAG結構,獲得Node_block= nodedf。data1和data2為其他信息,由不同的數據類型決定。
本文的完整性驗證方案通過BLS簽名實現。BLS[29]為數字簽名算法,其簽名長度較RSA和DSA簽名方案更短。
DH四元組定義:G為階為素數q的循環群,D=(g1,g2,u1,u2)?G4為四元組,其中g1、g2為G的生成元,。判斷α=β是否成立,如果成立,則稱D為DH四元組。
設G為間隙群,g為G的生成元,H:{0,1}*→G為全域哈希函數。隨機整數x為私鑰,y=gx為公鑰。M?{ 0,1}*為待簽名的消息,h=H(M),則σ=h x?G為消息M的簽名。如果四元組(g,h,y,σ)為DH四元組,則簽名判斷為True,否則簽名判斷為False。
4.2 基于BLS簽名多副本確定性驗證方法
4.2.1初始化階段
對于數據的加密,本文選用AES對稱加密。該階段生成數據加密所需的AES加密密鑰以及BLS簽名所需的公鑰和私鑰。該階段在每個數據擁有者鏈下計算設施中分別進行。
設需要產生μ個數據域副本,生成μ個AES加密密鑰 {K1,K2,… ,Kμ},密鑰長度為kbit。g為生成元,隨機選擇令x為數據擁有者DO的BLS簽名私鑰,數據擁有者DO的BLS簽名公鑰y滿足y=gx。啟動區塊鏈網絡,在區塊鏈各個節點部署智能合約。
4.2.2證明元數據生成階段
數據擁有者使用AES加密密鑰 {K1,K2,…,Kμ}分別對數據域df中每個數據進行加密,獲得μ個數據域副本 {df1,df2,… ,dfμ}。為實現對多個副本完整性的同時驗證,對多副本拼接獲得復合數據域DF,對DF進行數據完整性驗證實現對多副本的同時驗證。獲得數據域證明元數據流程如下。
1) 獲取復合數據域DF。獲取復合數據域需要對數據域中的數據進行逐個復合,以實現對多副本數據完整性的同時驗證。設原始數據域中的某個數據為d,數據域副本的個數為3,則數據d有3個數據副本 {d1,d2,d3},數據副本被劃分成n個數據 塊,表 示為j? (1,2,3)。數據擁有者確定生成證明元數據數量為k,并使用偽隨機數發生器生成k個隨機序列:L= {l1,l2,…,lk},并為每個隨機序列生成一個隨機序列拼接策略S= {s1,s2,… ,sk}。設隨機序列li對應的拼接策略是si:{md1||li||md2||md3},其中md1、md2、md3分別表示數據副本d1、d2、d3的數據塊,不同的拼接策略規定隨機序列插入的位置不同。則數據d的復合數據D可以表示為為復合數據D的各個數據塊的集合。逐個獲得數據域df中非結構化數據的復合數據。
2) 利用獲得的復合數據獲得df的復合數據域DF,并構建基于數據域的混合Merkle DAG結構,獲得復合數據域DF節點信息 nodeDF。圖9為獲取 nodeDF示意。

圖9 獲取證明元數據Figure 9 Obtain proof metadata
3) 計算h=H(nodeDF),使用私鑰x對h進行BLS簽名,σi=hx,則數據域df的證明元數據可以表示為 {nodedf,li,si,σi,y}。
4.2.3數據副本存儲階段
數據存儲系統通過安全通道接收數據擁有者需要存儲的數據域副本 {df1,df2,… ,dfμ},并通過簽名機制生成數據存儲憑證storage_credentials。
在該階段,數據擁有者上傳上鏈數據,docType取data_up,data1取數據名稱data_name,data2取數據存儲憑證storage_credentials。
4.2.4挑戰階段
在該階段,數據擁有者確定進行挑戰的數據域df,選取df對應的證明元數據為挑戰數據{nodedf,l i,si,σi,y},docType取challenge,data1取挑戰數據,data2取數據存儲憑證storage_credentials。
4.2.5證據生成階段
數據存儲系統作為區塊鏈節點,在線監聽數據擁有者對自己的挑戰,獲取挑戰元數據{nodedf,l i,si,σi,y},依據 nodedf,從存儲數據庫中獲取數據域的副本 {df1,df2,…, dfμ},依據隨機序列li和拼接策略si獲得復合數據域DF′,對復合數據域DF構建基于數據域的混合Merkle DAG結構獲得證據Ki=H(nodeDF')。
在該階段,存儲系統上傳證明數據,docType取prove,data1取證據Ki,data2取對應的挑戰時間戳challenge_timestamp。
4.2.6完整性判決階段
完整性判決合約獲得挑戰元數據{nodedf,li,si,σi,y}和證據Ki,并判斷(g,K i,y,σi)是否為DH四元組,如果是,則判斷數據完整,audit_results=True;如果不是,則判斷數據不完整,audit_results=False。
在該階段,數據完整性判決合約上傳審計數據,docType取audit,data1取審計結果audit_results,data2取對應的證據時間戳prove_ timestamp。
4.3 數據完整性審計歷史可信追溯
為實現對審計歷史的高效檢索,創建索引文件并與本文使用的智能合約一起安裝到區塊鏈系統節點。索引文件內容如下:


上述索引文件創建了兩個索引,索引1依據Node_block進行索引,能夠索引與某個數據域相關的所有信息,包括上鏈數據、挑戰數據、證明數據、審計數據;索引2依據docType和Node_block進行索引,能夠分別索引某個數據域的上鏈數據、挑戰數據、證明數據、審計數據信息。
5 方案分析
5.1 安全性分析
5.1.1驗證流程安全性
完整性驗證流程概括為數據副本生成、證明元數據生成、證據生成、證據審計4個階段。非結構化數據通過基于數據域的Merkle DAG文件結構進行組織,節點信息中的 nodedf保證節點的唯一性,節點信息中指針信息保證Merkle DAG文件結構確定,數據在數據存儲系統SP中以確定的方式進行存儲。副本生成機制保證數據損壞能夠即時修復。數據副本生成階段,通過設置μ個不同的AES密鑰 {K1,K2,… ,Kμ}對數據加密實現副本生成,防止存儲系統進行數據多副本偽存儲。該副本生成機制,能夠減少副本參數存儲,防止海量參數丟失與損壞。在證明元數據生成階段,使用隨機序列拼接方式組合獲得復合數據域nodeDF,對 nodeDF進行簽名獲得證明元數據{nodedf,l i,si,σi,y}。在證據生成階段,存儲系統同樣使用隨機序列拼接方式獲得復合數據域nodeDF',該方式能夠保證元數據生成必須使用完整副本數據塊,保證完整性審計的可行性。在證據驗證階段通過檢驗(g,K i,y,σi)是否為DH四元組,判斷數據是否遭到破壞,保證校驗結果的可信度。
5.1.2區塊鏈賬本記錄可信度
本文的完整性驗證流程通過智能合約實現,驗證的相關數據記錄在區塊鏈賬本上。智能合約取代可信第三方對證據的審計,這樣能夠解決防止第三方對驗證流程進行攻擊的問題。區塊鏈賬本能夠實現賬本數據的安全可信多方存儲,驗證流程數據記錄在區塊鏈賬本上,防止各方對驗證流程的篡改,保證數據完整性驗證歷史的真實性。在區塊鏈賬本上記錄數據在區塊鏈賬本上的唯一標識Node_block,唯一標識的確定能夠保證數據存儲與完整性驗證的一致性,實現對某一數據完整性驗證歷史的檢索。通過數據完整性驗證歷史的檢索,能夠保證數據在進行共享之前的歷史一致性,保證數據的可信度。
5.2 方案對比
表1 為本文方案與現有方案的對比。本文方案包含多個數據擁有者與數據使用者,以及多個數據存儲系統,能夠實現同領域數據或者聯盟成員間數據的多方審計。本文方案選用智能合約作為系統審計機構,能夠避免尋找可信第三方。與抽樣驗證相比,基于數據域的混合Merkle DAG結構能夠實現多副本數據的確定性驗證,提高數據完整性審計的效率與準確度。同時,本文方案設計數據完整性審計歷史高效檢索機制,實現數據完整性驗證歷史高效檢索以及多方驗證,保證數據歷史的一致性,增強數據的可信度。本文方案沒有實現數據的動態修改,降低了數據存儲的靈活性,但可以增加數據的歷史一致性,適合本文探討的傾向數據共享的場景。
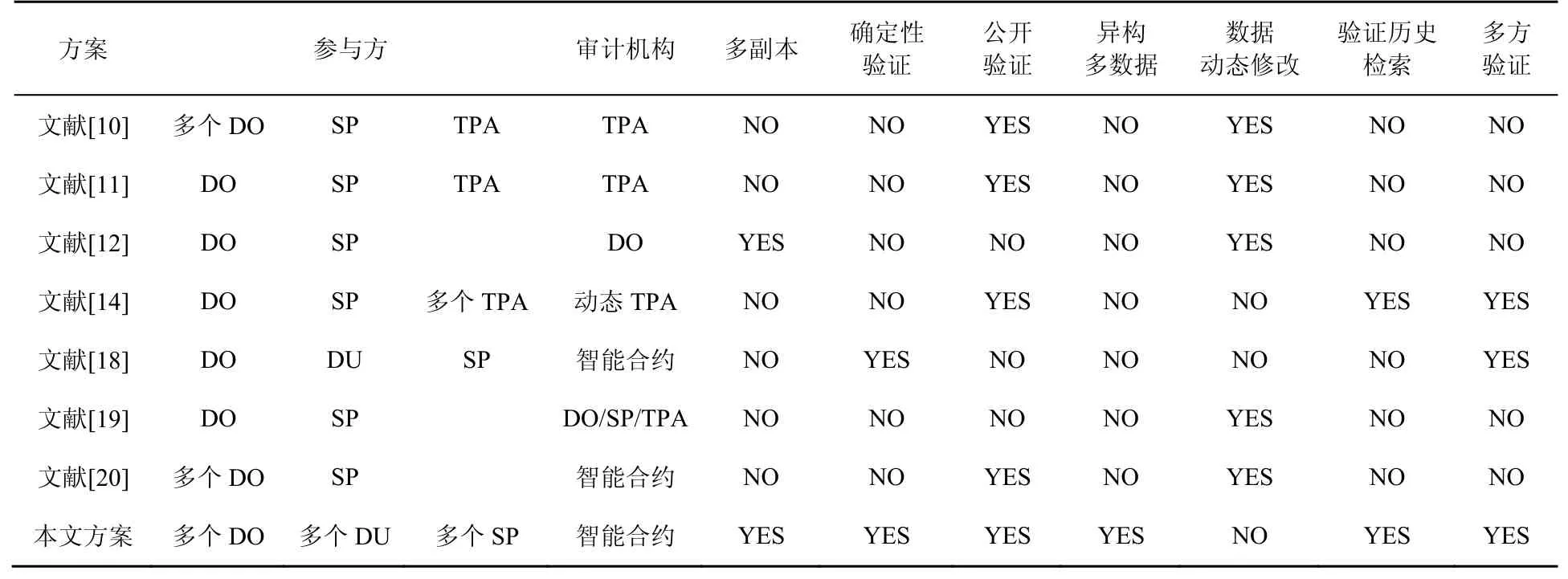
表1 方案對比Table 1 Scheme comparison
6 系統測試
本文實驗部署6臺阿里云服務器,其功能標識如表2所示。云服務器配置Intel Xeon Platinum 8269CY @2.5GHz處理器,256 GB內存,Ubuntu 16.04 64位操作系統。通過Java實現CBC模式128 bit密鑰AES加密。證明元數據生成階段使用go語言編程實現,并利用go語言的并發機制加快計算速度,使用SHA256算法進行數據摘要提取。BLS簽名驗證的部分通過Java的JPBC庫實現。區塊鏈部分基于Hyperledger Fabric 2.2實現。區塊鏈系統的背書策略為:將智能合約安裝在6臺服務器中的peer節點上,在進行區塊鏈交易時,6臺服務器中的peer節點均進行交易背書。

表2 云服務器功能Table 2 Cloud server function
證明元數據生成過程與證據生成過程相似,在本文的測試中,對證明元數據生成效率進行測試。為驗證系統對大數據環境中廣泛存在的小數據量數據進行完整性驗證的效率,測試了包含大量小數據的數據域生成證明元數據的速度。并進行證據校驗效率測試。
6.1 證明元數據生成效率測試
對數據量為1~10 GB的數據進行證明元數據生成效率的測試如圖10所示。在該測試中,數據副本的數量為3,多分支Merkle樹結構中參數Nmax取27,分別構建數據塊大小為16 MB、24 MB、32 MB的基于數據域的混合Merkle DAG結構。圖11所示的是對1 GB以內數據進行證明元數據生成效率的測試。數據副本的數量為3,多分支Merkle樹結構中參數Nmax取27,分別構建數據塊大小為1 MB、4 MB、8 MB的基于數據域的混合Merkle DAG結構。
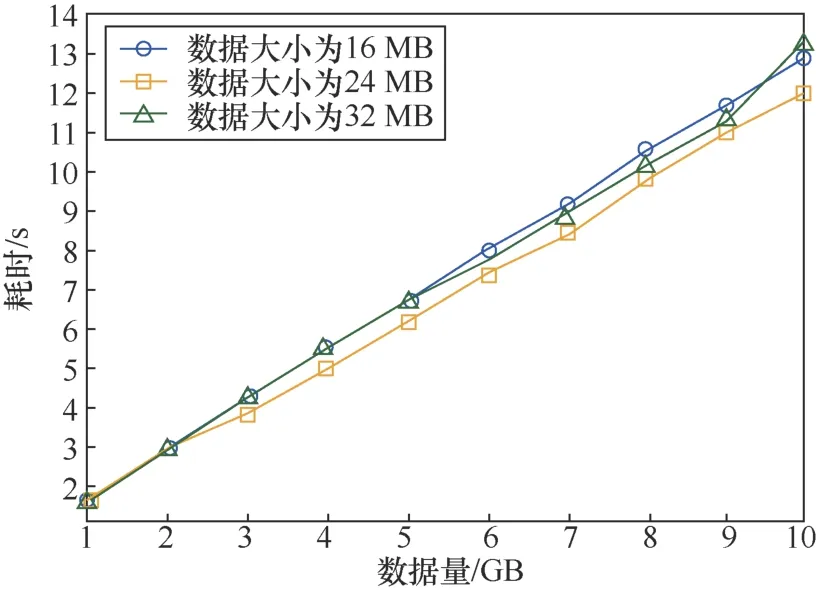
圖10 1~10 GB證明元數據的生成測試Figure 10 1~10 GB proof metadata generation test
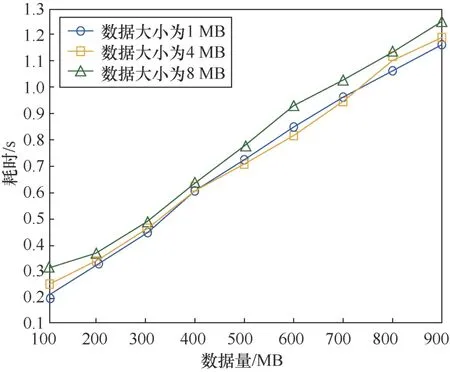
圖11 1 GB以內證明元數據的生成測試Figure 11 Data within 1 GB to prove metadata generation test
通過兩組曲線可以看出,相同的數據量使用不同大小的分塊進行處理,耗時基本相同。在實際的應用中,數據分塊大小可以根據數據量的大小以及實際的需求進行確定。證明元數據生成的時間與數據量成正比,耗時與數據量的比例關系約為1.25 s/GB,數據處理效率較高。
圖12 所示的是對1 000~10 000條非結構小數據進行證明元數據生成效率的測試。非結構化數據大小為1 MB左右,數據副本的數量為3,多分支Merkle樹結構中參數取27,構建數據塊大小為1 MB的基于數據域的Merkle DAG文件結構。從獲得的曲線可以看出證明元數據生成的速度與數據條數成正比,約為870 條/秒,數據處理效率較高。
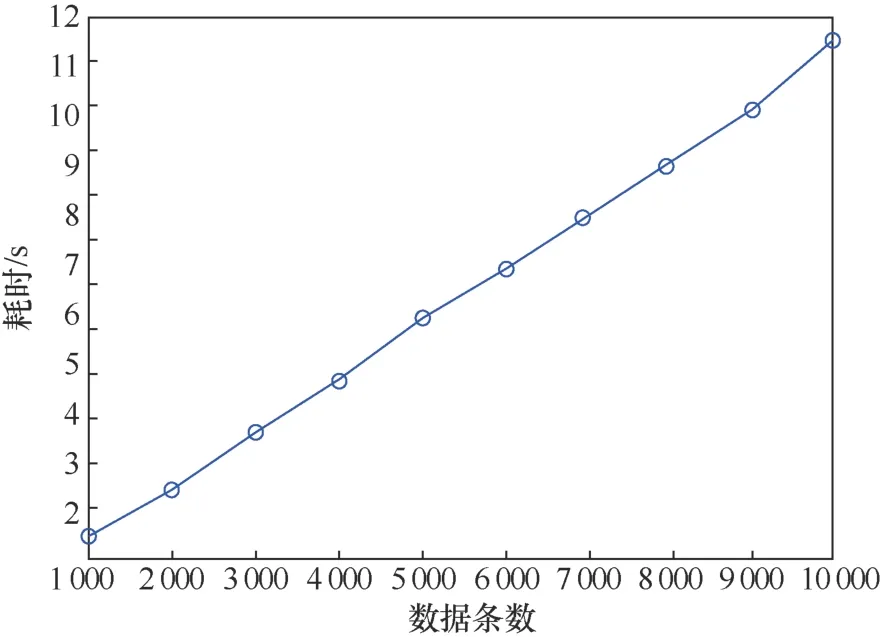
圖12 非結構化小數據證明元數據生成測試Figure 12 Unstructured small data proof metadata generation test
6.2 證據校驗效率測試
圖13 為對數據量1~10 GB的數據進行證據真實性校驗的效率測試。圖14為對數據量100~900 MB的數據進行證據真實性的效率測試。由結果可知,完整性證據的耗時與數據量的大小無關,證據真實性校驗的時間約為40 ms,能夠實現對證據真實性的快速校驗。
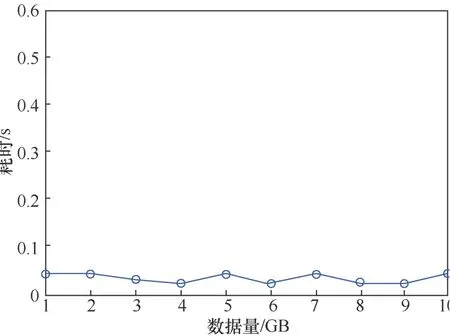
圖13 1~10 GB數據證據校驗測試Figure 13 1~10 GB data evidence verification test
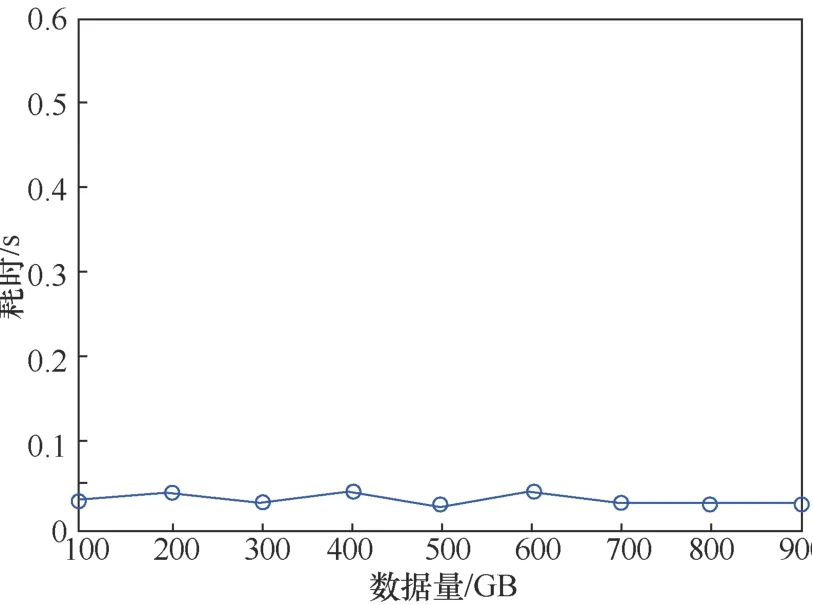
圖14 1 GB以內數據證據校驗測試Figure 14 Data proof verification test within 1 GB
6.3 性能分析
從實驗的結果可以看出數據完整性證明元數據生成以及完整性審計的速度都較高,能夠滿足數據異構以及數據量大的要求。需要說明的是,以上的測試均是在3個數據副本的基礎上進行的,測試消耗的時間是對3個數據副本同時進行數據完整性證明所用的時間。如果減少副本的數量,則將成比例減少時間消耗。在實際使用中,數據擁有者可以根據數據的重要程度選取合適的數據副本數或者不使用副本技術。
7 結束語
本文針對大數據環境下數據特點構建基于區塊鏈的數據完整性多方高效審計機制,實現非結構化小數據以及大體積數據的高效多副本審計。通過智能合約實現數據完整性審計過程,對審計歷史追溯實現對審計過程多方監督,保證數據共享之前的歷史一致性,增加數據可信度。但是本文方案證明元數據的生成需要在生成隨機序列的基礎上實現,下一步計劃研究更靈活的證明元數據生成方式。
