屬性語義與圖譜語義融合增強的零次學習圖像識別
2022-01-22 03:02:42汪玉金余蓓蓓向鴻鑫
圖學學報 2021年6期
汪玉金,謝 誠,余蓓蓓,向鴻鑫,柳 青
屬性語義與圖譜語義融合增強的零次學習圖像識別
汪玉金,謝 誠,余蓓蓓,向鴻鑫,柳 青
(云南大學軟件學院,云南 昆明 650500)
零次學習(ZSL)是遷移學習在圖像識別領域一個重要的分支。其主要的學習方法是在不使用未見類的情況下,通過訓練可見類語義屬性和視覺屬性映射關系來對未見類樣本進行識別,是當前圖像識別領域的熱點。現有的ZSL模型存在語義屬性和視覺屬性的信息不對稱,語義信息不能很好地描述視覺信息,從而出現了領域漂移問題。未見類語義屬性到視覺屬性合成過程中部分視覺特征信息未被合成,影響了識別準確率。為了解決未見類語義特征缺失和未見類視覺特征匹配合成問題,本文設計了屬性語義與圖譜語義融合增強的ZSL模型實現ZSL效果的提升。該模型學習過程中使用知識圖譜關聯視覺特征,同時考慮樣本之間的屬性聯系,對可見類樣本和未見類樣本語義信息進行了增強,采用對抗式的學習過程加強視覺特征的合成。該方法在4個典型的數據集上實驗表現出了較好的實驗效果,模型也可以合成較為細致的視覺特征,優于目前已有的ZSL方法。
零次學習;知識圖譜;生成對抗網絡;圖卷積神經網絡;圖像識別
零次學習(zero-shot learning,ZSL)是遷移學習在圖像識別領域中的一個重要分支。ZSL可在完全沒有視覺訓練樣本的情況下,對從未訓練過的視覺目標類別進行一定程度的識別。這種學習模型能夠顯著提升傳統視覺計算模型的適應性和泛用性,在視覺計算領域有著極其重要的研究意義。其相關研究也在快速增長,成為了當前的一個重要研究熱點。
ZSL的本質是跨模態學習,具體來說是語義(屬性)-視覺”的跨模態學習。即視覺特征是可以被語義特征所描述的,只要準確地找到視覺特征與語義特征的跨模態對應關系,便可以在不進行相應視覺樣本訓練的條件下,預測未見視覺目標的所屬分類。一個經典事例是:一個從未見過斑馬的人,通過對斑馬的語義表述(如像一匹馬,身體白色,但有黑色斑紋),便能夠在腦海中想象出斑馬樣貌,從而識別出斑馬。基于該思路,ZSL不斷迭代發展,已經衍生出一系列經典方法。
2009年,ZSL首次由PALATUCCI等[1]明確提出。同年,LAMPERT等[2]正式發表了第1個ZSL模型-直接屬性預測(direct attribute prediction,DAP),其原理是對視覺樣本進行屬性標記(如是否有尾巴、毛發顏色等),進而學習視覺目標的語義屬性特征,最后由一個判斷器評判視覺目標所滿足的屬性組合分類。隨著語義嵌入技術的發展,ZSL的第2個階段性標志是2013年由AKATA等[3]提出的屬性標簽嵌入(attribute label embedding,ALE)模型,其將屬性的語義編碼作為向量,并將圖像編碼作為特征向量,而后學習一個函數,計算屬性語義編碼和圖像視覺編碼之間的相似度,從而預測圖像的分類。
隨著深度學習技術在圖像識別領域的發展,ZSL的第3個階段性標志是2017年由KODIROV等[4]提出的激活酶(SUMO-activating enzyme,SAE)模型,采用自動編碼技術,其能夠對圖像更細粒度的屬性特征進行編碼,并與語義屬性特征進行解碼映射,較好地做到了“視覺-語義”的跨模態學習,整體性能較ALE有明顯提升。憑借著對抗生成網絡[5]在視覺計算中的顯著效果,ZSL迎來了第4個階段性標志。2018年ZHU等[6]發表了對抗生成的零次學習(generative adversarial approach for zero-shot learning,GAZSL)模型,其采用對抗生成網絡,將語義特征合成為視覺特征,進而能夠通過語義信息合成偽視覺信息,開創性地實現了“語義-視覺”的跨模態學習,其H-score (未見類得分和可見類得分的調和分數)在多個ZSL標準集中超過25%,較之前最優模型提升近2倍。基于該對抗生成的思路,ZSL出現了井噴式的發展。到2020年底,相關研究[7-10]已經將GAZSL模型進行了深度優化,H-score在ZSL多個標準集中也達到了60%以上。然而,對比一般的圖像分類模型普遍90%以上準確率,ZSL還有很大的提升空間,但目前已觸到了瓶頸。
這個瓶頸便是ZSL中經典的“領域漂移問題”。從2009年ZSL首次提出,到2020年底的最新研究,領域漂移問題不斷被消解,但從未被消除。領域漂移問題普遍存在于“語義-視覺”跨模態學習中,由于語義信息較視覺信息更為單一,在語義信息轉化為視覺信息時,會丟失視覺的細節信息,從而造成誤判。典型的例子是同樣描述一個視覺目標是否“有黑色的尾巴”,但是真實視覺可能是“羅威納犬的尾巴”或“杜賓犬的尾巴”,雖然都是黑色的尾巴,但是其視覺細節有著巨大的差異,語義信息并不能完備地對其描述。這主要是由于相較于視覺信息,語義信息不夠豐富而不能對等匹配,在“語義-視覺”跨模態轉化時,產生嚴重的領域漂移問題。
針對該問題,本文提出了一種屬性語義與知識圖譜關聯語義融合增強的方法,用于增強語義信息,緩解目前語義信息與視覺信息不對稱情況,進一步消解ZSL的領域漂移問題。首先,基于對抗生成的思路,模型采用圖卷積網絡設計了一個知識圖譜視覺特征生成網絡,能夠將知識圖譜語義信息轉化為相應的關聯視覺特征。而后,將關聯視覺特征與通過屬性語義信息轉化而來的屬性視覺特征共同輸入特征融合網絡合成融合視覺特征。最后,將融合視覺特征輸入一個特征空間映射網絡并與真實視覺特征進行合理性判別和類別判別。整個模型在ZSL標準集SUN,AWA,CUB和aPY中進行了評估,結果證明其能夠顯著地增強語義特征,合成更為細致的視覺特征,其表現優于目前已有的ZSL方法。
1 相關工作
1.1 知識圖譜關聯零次學習
知識圖譜是一種特殊的圖結構,也可以看作是一種大規模的語義網絡[11]。知識圖譜抽象地描述了現實世界。現實中的事物被描述成圖譜中一個點,事物之間的聯系描述成了一條邊。錯綜復雜的事物關系便構成了一張網。結構化的表現形式和豐富的語義信息讓知識圖譜可以服務人工智能領域的下游任務。
知識圖譜用于ZSL的現階段工作較少。2018年KIPF和WELLING[12]引入了圖卷積網絡(graph convolution networks,GCN),在做零次圖像識別時使用了語義屬性的嵌入和類別的關系的類別預測分類器[13],并將每個數據集類別作為一個知識圖譜的節點,樣本類別之間的關系作為圖譜的邊。GCN模型訓練的輸入為節點的語義嵌入特征。該模型使用6層的圖卷積作為預測類別分類器。測試中,使用訓練完成的可見分類器給未見類別進行分類。該方法在某些指標上得到2%~3%的提升。是最早將知識圖譜應用于ZSL的方法。
2019年KAMPFFMEYER等[14]針對文獻[13]工作做了改進,提出了GCNZ[13]的一些不足并做了改進,同時指出6個層次的圖卷積層會導致過度的拉普拉斯平滑,讓每一個節點趨于相似,降低了模型的性能。另一個矛盾是,較淺的圖卷積網絡層不會學習到較遠距離的節點特征。于是本文針對該問題做了2個改進:①減少了GCN圖卷積網絡的層數,設置為2;②改進了知識圖譜的結構,在原有的知識圖譜上將祖先節點和孫子節點進行了相連從而得到了更為稠密的知識圖譜。同時在知識圖譜的邊上設置權重值,即稠密圖傳播(dense graph propagation,DGP)方式。其他處理形式同文獻[13]。
1.2 生成式的零次學習
生成對抗網絡(generative adversarial networks,GAN)是文獻[13]提出的機器學習架構。監督學習的數據集通常是由大量的帶有標簽的訓練集和測試集組成。非監督方式學習[15]可以根據學習,從而降低出錯的概率。監督方式的學習準確率領先于非監督式的學習方式,但前者需要大量優質的帶有標簽的數據集,且十分費時費力。GAN的出現是非監督式學習提升一個關鍵因素。其十分擅長無監督的學習,特別是在生成數據方面。GAN具有強大的表征能力,在潛在的向量空間執行算數運算,并可以很好地轉換為對應特征空間的特征表示。
圖1是生成對抗網絡的基本學習框架。隨機噪聲輸入到生成器中生成偽視覺特征。訓練樣本的視覺特征和生成器生成的視覺特征一同輸入到判別器中進行判別。若判別器識別正確,說明生成器效果還有提升,此時會優化生成器;若判斷錯誤,說明判別器有優化空間,對其進行優化,以避免錯誤再次發生。經過不斷的迭代優化,生成器可以生成接近真實圖片分布的偽視覺特征,判別器可以鑒別出真和偽視覺特征,兩者達到一個均衡和諧的狀態。
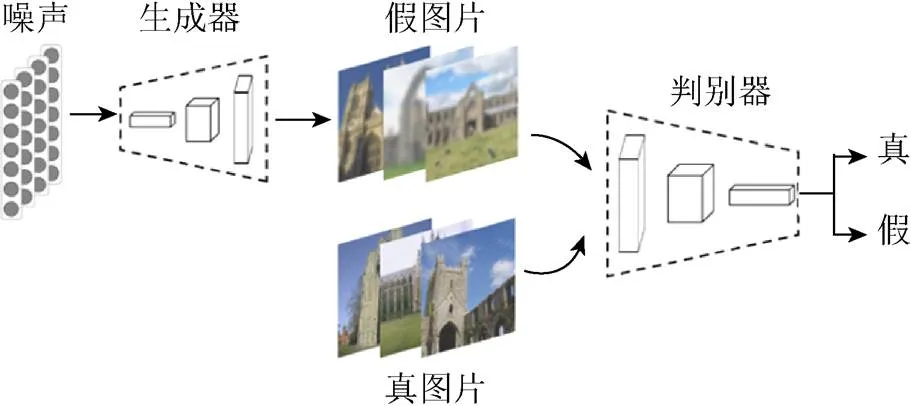
圖1 生成對抗網絡的基本框架
原始GAN[5]生成圖片的效果并不理想,與變分編碼器(variational autoencoder,VAE)[16]效果不相上下,遠遠未達到研究者的目標。因此研究者們對GAN做了較多的改進,解決其訓練中存在的不穩定、梯度消失和模式崩潰等問題。例如WGAN模型(wasserstein generative adversarial networks)[17]通過理論分析發現,若2個分布之間存在不相交的部分,則JS散度不適用于衡量這兩者之間的距離。因此使用Wasserstein代替JS散度來測算2個條件分布之間距離,解決模式崩潰的難題。基于文獻[17],條件生成對抗網絡(conditional GAN,CGAN)[18]通過為生成器以及辨別器引入輔助信息,例如類別標簽、文本甚至圖像,提高生成圖像的質量。輔助分類生成對抗網絡(auxiliary classifier GAN,ACGAN)[19]則通過添加額外的類別識別分支,進一步穩定了辨別器的訓練過程。與ACGAN[19]不同,為ZSL設計的生成對抗網絡(generative adversarial approach for zero-shot learning,ZSL-GAN)[20]中添加了視覺軸正則化(visual pivot regularization,VPG)使生成樣本的數據分布中心盡可能逼近真實樣本數據分布聚類中心。
目前,已有較多研究基于GAZSL開展。文獻[13]為了解決GAN中存在的多樣性和可靠性低的問題,提出了條件式瓦瑟斯坦距離的(conditional Wasserstein GAN,CWGAN)。語義描述和噪聲作為CWGAN的輸入來產生具有多樣性的生成樣本。同時,該方法定義了靈魂樣本,通過使生成器生成的樣本靠近對應的靈魂樣本來保證生成器的可靠性。為了解決GAN在語義到視覺轉化過程中出現的領域漂移現象,HUANG等[21]提出了雙向的生成對抗網絡(generative dual adversarial network,GDAN),該網絡分別使用生成器和回歸器完成語義到視覺和視覺到語義的雙向映射來保證更加泛化的生成器。然而,目前該方向的研究仍然基于常規的對抗生成網絡,在ZSL跨模態生成過程中存在原理上的局限。
2 屬性語義與圖譜語義融合增強的零次學習模型
2.1 知識語義圖譜構建
知識圖譜(knowledge graph)[11]的概念由谷歌2012年正式提出,旨在實現更智能的搜索引擎,并于2013年后開始在學術界和工業界普及。其在智能問答、情報分析、反欺詐等應用中發揮著重要的作用。
知識圖譜構建采用2種方式:①基于數據集原始屬性語義空間距離構建知識圖譜;②基于自然知識構建知識圖譜。
基于屬性語義空間構建知識圖譜具體流程如圖2所示。由原始屬性語義的空間分布來獲取類別之間的聯系。類別聯系建立的依據是否超過2個類別屬性語義空間分布距離D。D值根據類別可視化距離分布情況而設定。
圖2 基于語義空間距離的圖譜構建
基于自然知識構建知識圖譜方法具體流程如圖3所示。實驗中AWA[22]和SUN[23]使用自然知識構建了圖譜。因為AWA和SUN中類別屬性語義空間分布比較雜亂,構建質量較好的數據集圖譜較為困難。AWA知識圖譜構建是根據門綱目科屬種中的“屬”關系來進行構建。SUN知識圖譜構建是根據其官網展示中的場景相似鏈接。以此場景相似關系作為SUN知識圖譜構建的依據。AWA,SUN,CUB和aPY構建的圖譜規模見表1。
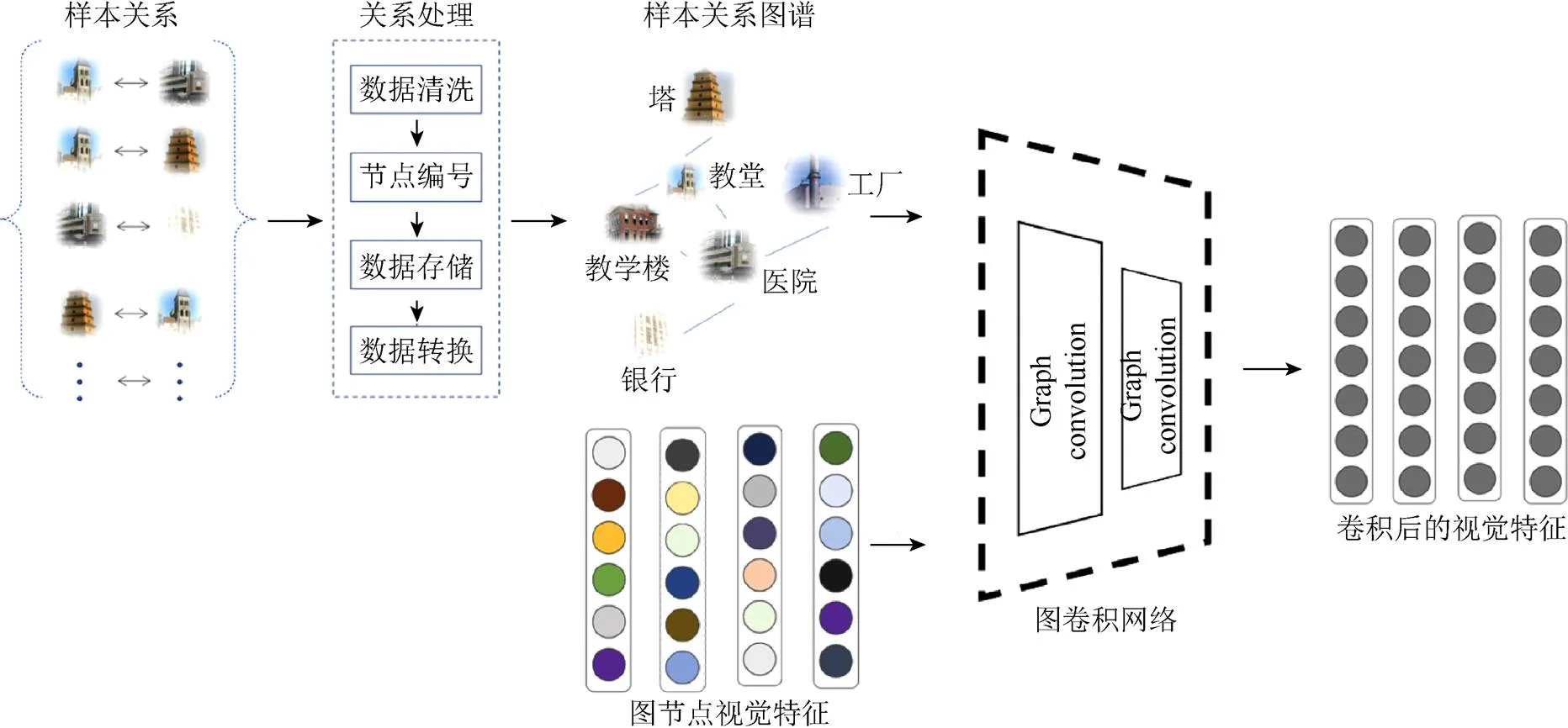
圖3 基于自然知識的圖譜構建
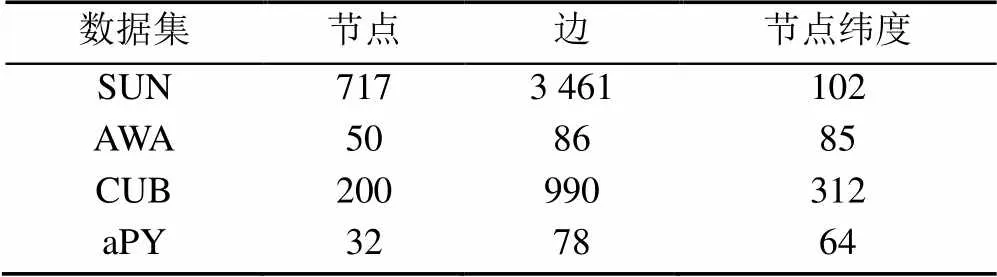
表1 SUN,AWA,CUB和aPY圖譜大小
2.2 知識圖譜嵌入學習
圖嵌入(graph embedding)是表示學習的范疇,也可以叫做圖表示學習。其目的是將圖譜中的節點表示成向量的形式。嵌入后的向量在特定的向量空間中可以得到合理的表示,具體的可以用于學習的下游任務,比如節點的分類等。
圖嵌入的方式有3種:①矩陣分解;②DeepWalk;③圖神經網絡(graph neural network,GNN)。實驗中知識圖譜嵌入方法使用圖卷積神經網絡(graph convolutional network,GCN)的方式。GCN是GNN的一種,即采用卷積方式的一種網絡,具體為
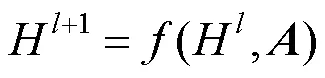
其中,為第層的輸入,當=0時,對應的H是原始圖譜的輸入;為鄰接矩陣,不同的GCN的差異體現在了函數上。
式(1)是以圖譜語義網絡作為輸入。通過不斷的迭代實現節點圖卷積學習的效果。以節點為特征的圖卷積式為
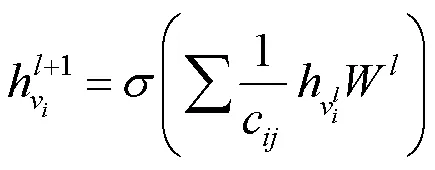
權重矩陣參數。
2.3 圖譜語義與屬性語義融合學習
模型可以劃分為3部分:①圖譜語義學習;②屬性語義學習;③空間映射學習。本文將以SUN數據集為輸入來說明屬性語義與圖譜語義融合增強ZSL模型學習過程。
2.3.1 圖譜語義學習
與傳統的GCN不同,本文方法在GCN卷積融合的同時讓其做泛化的生成。GCN模塊的使用會彌補GAN中缺失合理泛化和語義信息缺失的問題。GCN的對抗學習網絡設置了判別器DGcn (discriminator for Gcn),其對抗優化的目標式為
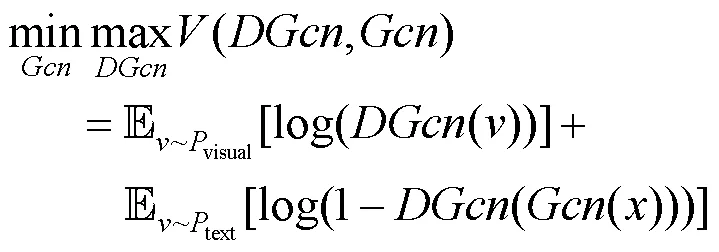
圖卷積部分實現圖譜語義到視覺空間的嵌入。本文使用SUN官網場景相似關系提取了該數據集中的樣本關系。SUN知識圖譜包含717個類節點,3 641條屬性邊。按照DGL庫中標準輸入,本文將樣本分為起始節點和結束節點的集合。類別節點的特征表示使用原始語義屬性。圖譜語義特征到視覺特征之間的映射方法使用GCN[12]{Kipf, 2016 #11}來實現。GCN輸入是圖關系中的起始節點的序號集合和結束節點序號集合。研究方法使用了DGL庫中2個圖卷積函數來組成圖卷積模塊。GCN輸出的偽視覺特征和真實視覺特征使用余弦相似度比較產生損失進行圖卷機模塊GCN的學習。圖譜語義學習框架如圖4中圖譜語義部分。
圖4 屬性語義與圖譜語義融合增強模型架構。生成器實現語義到視覺特征的映射;圖卷積網絡實現圖譜語義到視覺映射
Fig.4 The framework of attribute and graph semantic reinforcement. The generator realizes the mapping from semantic attributes to visual features, and the graph convolution network realizes the mapping from graph semantic attributes to visual features
2.3.2 屬性語義學習
生成器(generator,G)在模型中是用來將語義信息合成偽視覺特征。合成的偽視覺特征將用于視覺特征的融合。生成器部分實現了屬性語義到視覺空間的映射。
場景類別的102維度的語義特征拼接102維的噪聲后輸入到生成器。噪聲的加入保證了生成器可以生成豐富多樣的特征,如圖4中屬性語義部分。
訓練過程中生成器和判別器對抗優化的目標式為
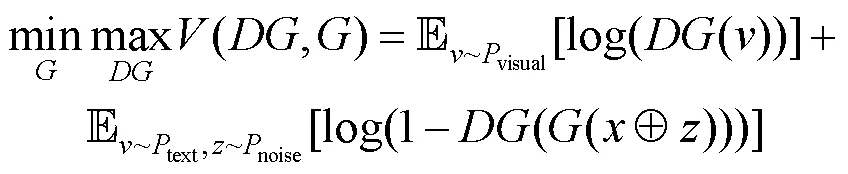
2.3.3 空間映射對抗學習
空間映射模塊的作用是將融合后的視覺特征映射到新的空間中,合成的視覺特征在此空間更加的泛化。空間映射(space encoder,SE)模塊,對應的對抗判別器(discriminator for space encoder,DSE)。其將GCN和G的融合視覺特征映射到新的特征空間。其對抗優化式為
模型中的圖卷積模塊和生成器產生的偽視覺特征通過融合模塊進行了特征融合,產生了新的視覺特征,如圖4框架圖后半部分。為使融合的視覺特征在測試階段具有類級別的判別性,模型使用空間映射模塊SE (space encoder)讓偽視覺特征在新的特征空間進一步接近真實視覺特征。訓練空間映射模塊時真實特征的輸入為ResNet[24]提取的2 048維度的視覺特征。空間映射模塊接受融合后的偽視覺特征和真實圖片的視覺特征輸入,將合成的視覺特征和真實的視覺特征映射為1 024維度。SE判別器在圖片的真實性和類別標簽正確性兩方面進行判別。該判別器在保證SE映射后的視覺特征真實性的前提下,又讓樣本之間產生一定的判別性。空間映射模塊的判別器中使用了標簽損失以此來達到更好地分類效果。這種判別性具體體現在類別視覺特征經過SE現映射后在映射空間會存在合理的距離。模型測試階段的分類方法使用KNN算法[25]來實現樣本的分類。
3 實驗及性能評估
實驗通過SUN,AWA,CUB和aPY 4個數據集來評估屬性語義與圖譜語義融合模型。本文將依次介紹本次實驗數據集、評估方法、實驗細節和可視化對比展示。
3.1 數據集
在ZSL中常用的數據集有CUB[26],AWA1,AWA2,SUN和aPY[27]等。其中CUB和SUN數據集是細粒度的數據集。AWA1,AWA2和aPY是粗粒度的數據集。為了更好地評測該方法的有效性,本文選擇了SUN,AWA1,CUB和aPY 4個標準數據集進行實驗。
場景理解(scene understanding,SUN)數據集,是中規模細粒度混合場景(包括人物、風景、風箏等類別)的數據集。其包括717個場景類別的14 340張圖片,每類含有20張圖片。并且數據集中為每個類別提供了102維的場景屬性向量。這些屬性特征描述了場景的材質和表面屬性,以及照明條件、功能、供給和一般圖像布局等屬性。
動物與屬性(animals with attributes,AWA)數據集涵蓋50個動物分類,30 475張圖像,每類至少包括92個樣本。每張圖像由6個預提取的特征表示,并且為每個類別標注了85維語義屬性。標注的屬性使得已見類到未見類的知識遷移成為可能。通常在ZSL的實驗中,將數據集中的40類劃分為訓練集,10類劃分為測試集。
加州鳥類(Caltech-UCSD Birds-200-2011,CUB)數據集是目前細粒度分類識別研究的基準圖像數據集,共有11 788張鳥類圖像,包含200類子類,提供了圖像類標記信息、圖像中鳥的屬性信息、位置邊框信息等。
帕斯卡和雅虎(attribute Pascal and Yahoo,aPY)數據集是中規模粗粒度的數據集。該數據集類別語義為64維,共有15 339張圖片,包含32個目標類。4個ZSL數據集詳細規模信息見表2。
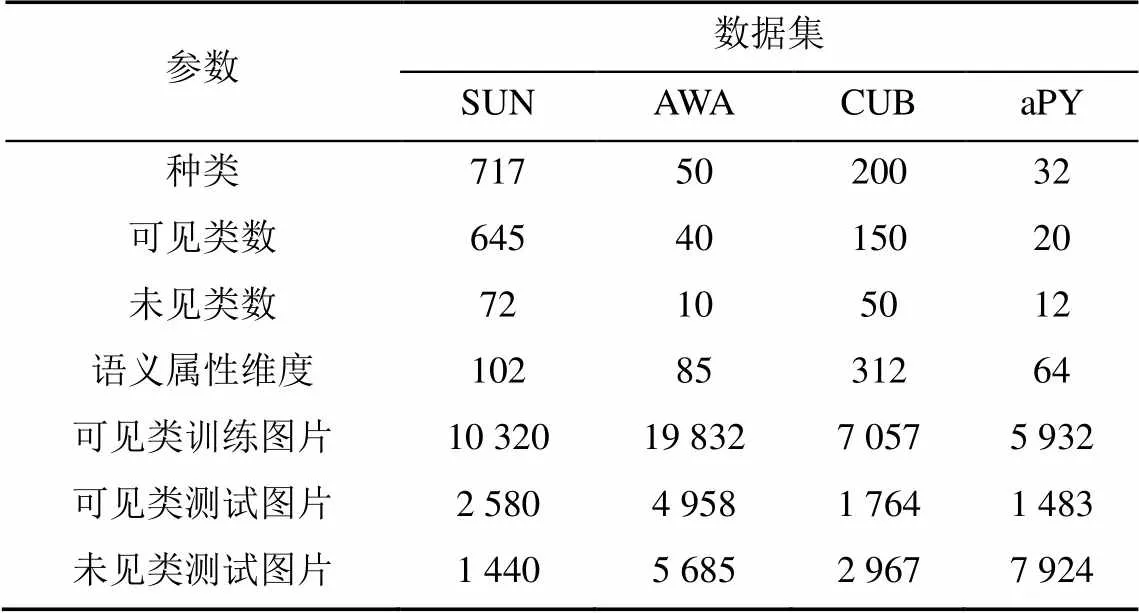
表2 SUN,AWA,CUB和aPY數據集規模
3.2 評估指標
目前對于小規模數據集評價指標分為2類,即平均分類準確率(accuracy,Acc)和平均精確率(mean average precision,mAP)。由于部分數據集可能出現樣本分布不均的情況,在這種情況使用mAP將導致評價結果失去意義。
模型性能的評估是通過每個類別的Top-1準確率來進行評估的。在廣義的ZSL中,可見類和未見類的圖片作為ZSL的測試集。然而傳統的ZSL測試集僅僅是未見類中的圖片。在此,評估模型的Top-1準確率在可見類中,記做。同樣的,未見類的Top-1準確率記做。然后定義調和平均值=(2××)/(+)來整體評測ZSL模型的性能。
3.3 實驗參數設置
實驗中,模型的搭建選擇了神經網絡框架Pytorch。生成器構建了含有4 096個隱藏單元的隱藏層,激活函數采用LeakyReLU[28]激活方式。
GCN的知識圖譜的構建以及圖譜的卷積操作,模型使用DGL庫函數以及自定義的模塊化的GCN網絡來完成知識圖譜語義知識到偽視覺向量的映射。
在DGcn和DG中的相似度判別方式使用了余弦相似度的方式來計算GCN和G生成偽視覺特征的損失值。余弦相似度不同于歐氏距離,其從特定的向量空間中計算出空間向量的夾角,可以從整體的角度去衡量合成視覺特征的真實性。
在特征融合階段,GCN的輸出特征和G的輸出特征通過融合模塊融合。現階段的視覺特征融合方法使用視覺特征拼接的方式。
在優化器的選擇上,選擇了Pytorch中的Adam優化器[29],同時將批處理大小設置為512。學習率設置為0.000 1。實驗中為了使生成器生成偽視覺特征更真實穩定,模型的學習過程采用Wasser-steinGAN[17]和一些其他的改進優化策略。
3.4 結果可視化分析
本文與其他方法進行比較,以驗證屬性語義與圖譜語義融合增強方法的有效性。實驗針對測試階段合成視覺特征的數量,對模型的性能進行了相應的測試。合成視覺特征的數量對實驗結果有很大的性能影響是因為測試預測階段使用最近鄰算法(K-nearest neighbor,KNN)[25]的方式去進行評估,如圖5所示。
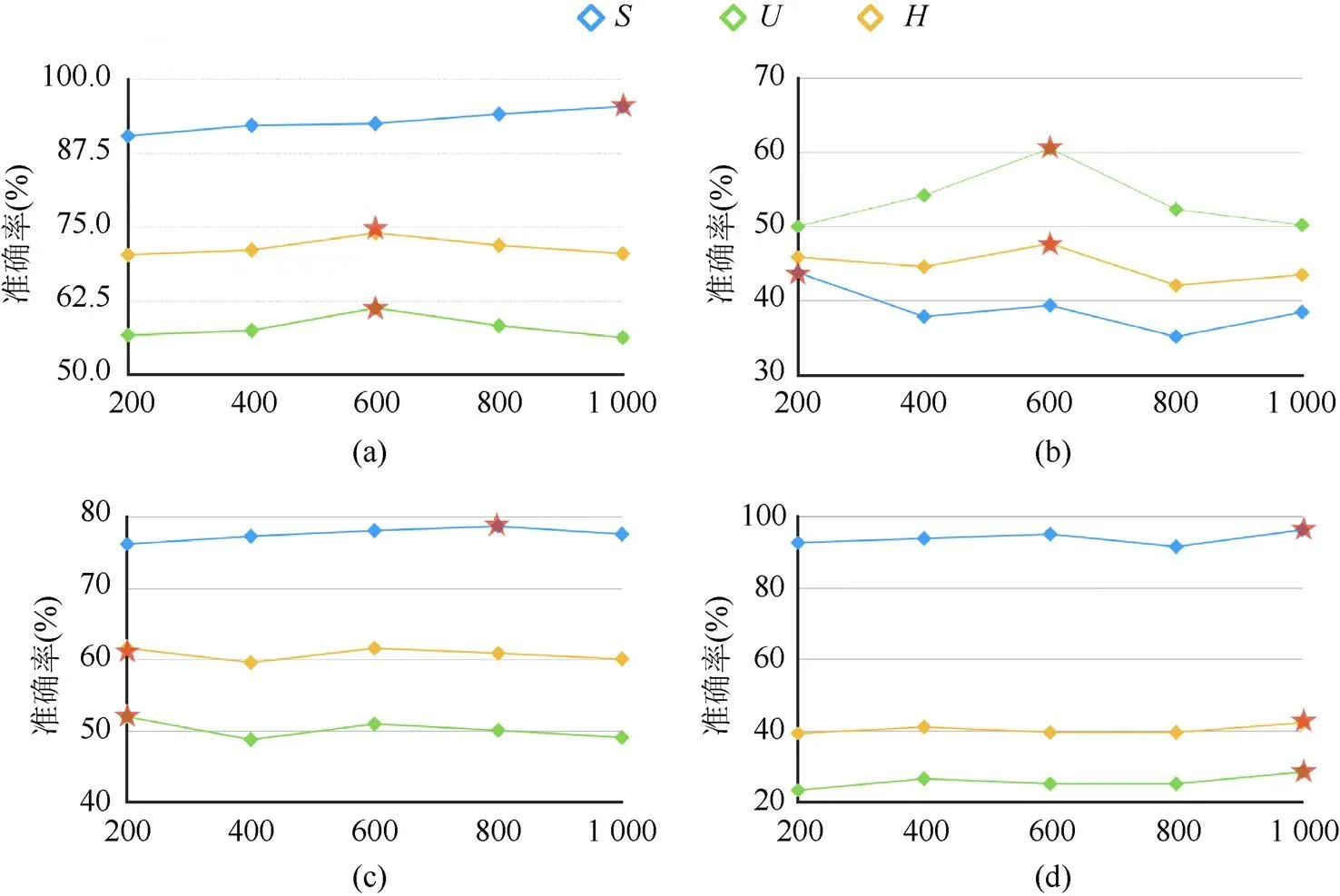
圖5 生成器合成視覺特征數量對實驗結果的影響((a)AWA數據集下,不同數量的合成視覺特征對的影響。當數量為600時H取得最好的結果;(b)SUN數據集下,不同數量的合成視覺特征對的影響。當數量為600時H取得最好的結果;(c) CUB數據集下,不同數量的合成視覺特征對的影響。當數量為200時H取得最好的結果;(d)APY數據集下,不同數量的合成視覺特征對的影響。當數量為1000時H取得最好的結果)
KNN考慮的是特征空間中最近的個特征,合成的偽視覺的數量會直接影響評估算法的匹配。合成未見類特征數量越多,匹配到未見類別視覺特征的幾率越大。通過在SUN,AWA,CUB和aPY 4個標準數據集實驗發現:
(1) SUN數據集上合成的視覺特征數量在600時,,和都取得了最高的值。SUN數據集中訓練種類多且數據集中每個場景類別圖片數量有明顯差距。屬性語義與圖譜語義融合增強的ZSL模型泛化能力,讓類別數量較少的未見類識別精度高于可見類識別精度。
(2) aPY數據集上,和3個值最高均在合成數量為1 000時。aPY數據集上和值差距較大是由于測試圖片數量高于訓練圖片的數量。
SUN數據集在ZSL中是有挑戰的數據集。諸多ZSL模型在AWA,CUB和aPY數據集上表現較好,但是在SUN數據集上效果欠佳。圖6展示了SUN數據集未見類真實的視覺特征通過t-SNE[30]算法降維后的數據特征分布。SUN數據中未見類的真實視覺特征區分度不大,聚合度不夠,場景類別視覺中心不夠明顯。
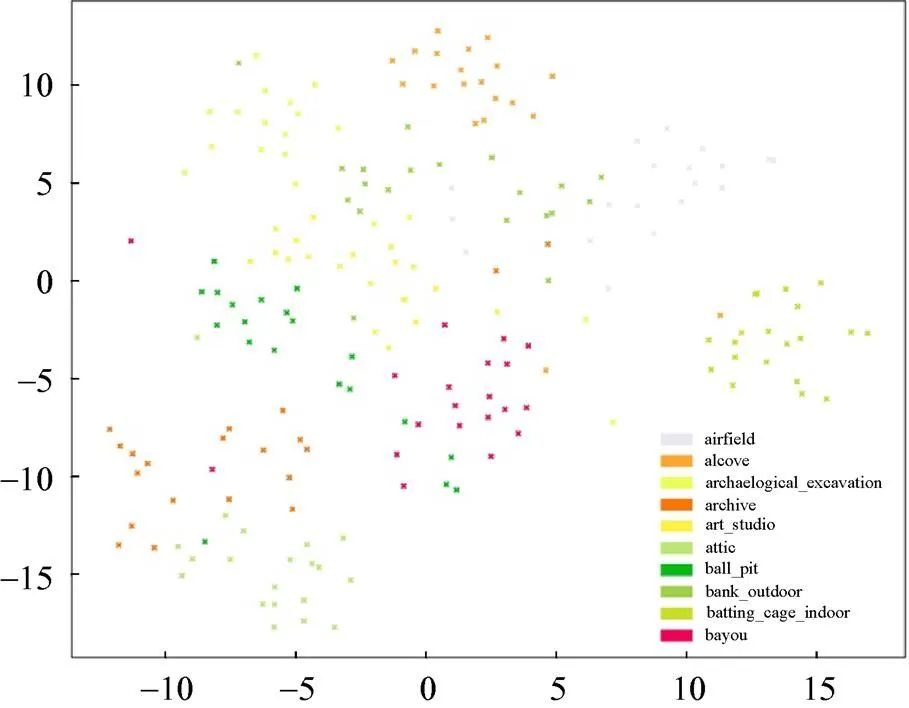
圖6 SUN未見類中真實視覺特征分布
為使數據的類視覺中心明確。本文方法首先通過屬性語義與圖譜語義融合增強,進而輸入到SE模塊映射到新空間中進行分類預測。在新的特征空間中合成的未見類視覺特征可以合理的分布在真實視覺特征中心的周圍,如圖7所示。
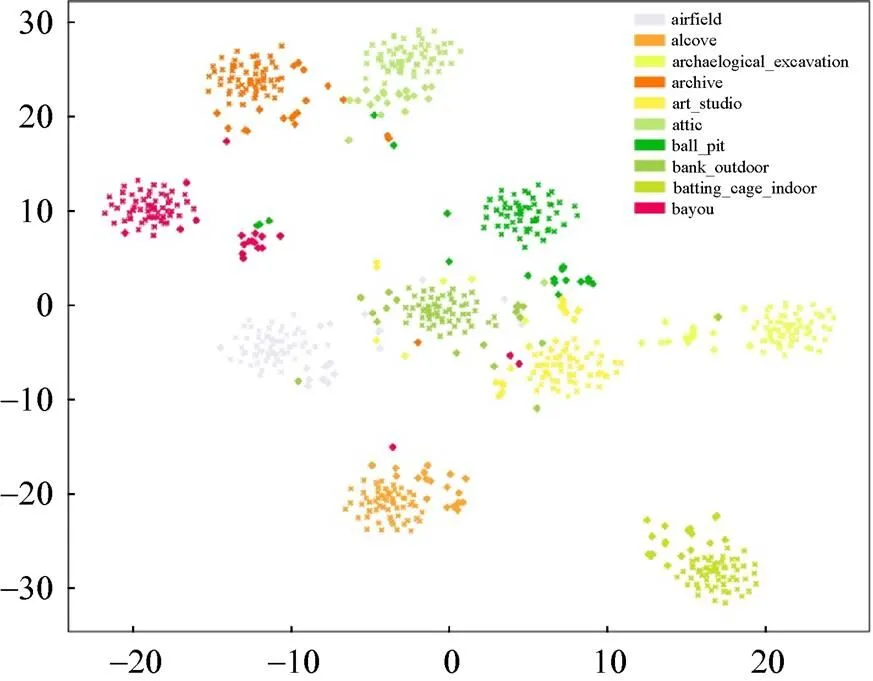
圖7 SUN未見類中真實特征和合成特征的分布
表3為廣義的ZSL的結果。本文選擇近三年來廣義ZSL的相關方法與屬性語義與圖譜語義融合增強的方法進行對比。通過對比,本文方法模型在4個標準數據集上都取得了相對較好的實驗結果。
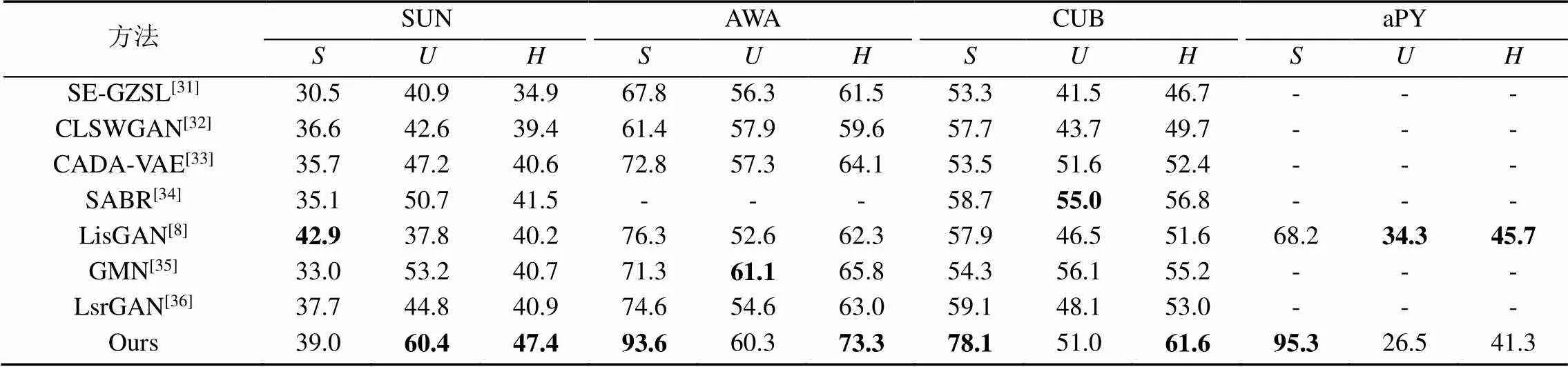
表3 屬性語義與圖譜語義融合增強的零次學習方法與現階段工作的對比
4 總結與展望
本文設計了一種屬性語義與圖譜語義融合增強的ZSL模型,并在SUN,AWA,CUB和aPY數據集上進行了實驗,表現出較好的效果。該方法結合知識圖譜和GAN在ZSL中的優點,一定程度上解決了領域漂移問題中語義信息缺失問題,可以將類別語義特征合成更為細致泛化的視覺特征,有著較強的泛用性和可解釋性。
后續將針對ZSL中領域漂移的未見類語義缺失問題,通過使用知識圖譜關聯目標級別的視覺特征嘗試進行解決。這也是ZSL向強人工智能邁進的重要一步。
[1] PALATUCCI M, POMERLEAU D, HINTON G E, et al. Zero-shot learning with semantic output codes[C]//The 22nd International Conference on Neural Information Processing Systems. New York: ACM Press, 2009: 1410-1418.
[2] LAMPERT C H, NICKISCH H, HARMELING S. Learning to detect unseen object classes by between-class attribute transfer[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 951-958.
[3] AKATA Z, PERRONNIN F, HARCHAOUI Z, et al. Label-embedding for attribute-based classification[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2013: 819-826.
[4] KODIROV E, XIANG T, GONG S G. Semantic autoencoder for zero-shot learning[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 4447-4456.
[5] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-144.
[6] ZHU Y Z, ELHOSEINY M, LIU B C, et al. A generative adversarial approach for zero-shot learning from noisy texts[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 1004-1013.
[7] JI Z, CHEN K X, WANG J Y, et al. Multi-modal generative adversarial network for zero-shot learning[J]. Knowledge- Based Systems, 2020, 197: 105847.
[8] LI J J, JING M M, LU K, et al. Leveraging the invariant side of generative zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 7394-7403.
[9] HUANG H, WANG C H, YU P S, et al. Generative dual adversarial network for generalized zero-shot learning[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 801-810.
[10] SARIYILDIZ M B, CINBIS R G. Gradient matching generative networks for zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 2163-2173.
[11] PUJARA J, MIAO H, GETOOR L, et al. Knowledge graph identification[C]//The 12th International Semantic Web Conference. Heidelberg: Springer, 2013: 542-557.
[12] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. [2021-02-21]. https:// arxiv.org/abs/1609.02907.
[13] WANG X L, YE Y F, GUPTA A. Zero-shot recognition via semantic embeddings and knowledge graphs[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 6857-6866.
[14] KAMPFFMEYER M, CHEN Y B, LIANG X D, et al. Rethinking knowledge graph propagation for zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 11479-11488.
[15] BARLOW H B. Unsupervised learning[J]. Neural Computation, 1989, 1(3): 295-311.
[16] KINGMA D P, WELLING M.Auto-encoding variational bayes[EB/OL]. [2021-01-30]. https://arxiv.org/pdf/1312.6114. pdf?source=post_page.
[17] ARJOVSKY M, CHINTALA S, BOTTOU L.Wasserstein generative adversarial networks[C]//The 34th International Conference on Machine Learning. New York: ACM Press, 2017: 214-223.
[18] MIRZA M, OSINDERO S.Conditional generative adversarial nets[EB/OL]. [2021-02-05]. https://arxiv.org/pdf/1411.1784. pdf.
[19] ODENA A, OLAH C, SHLENS J. Conditional image synthesis with auxiliary classifier GANs[EB/OL]. [2021-02-29]. http:// proceedings.mlr.press/v70/odena17a/odena17a.pdf.
[20] ZHU Y Z, ELHOSEINY M, LIU B C, et al. A generative adversarial approach for zero-shot learning from noisy texts[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 1004-1013.
[21] HUANG H, WANG C H, YU P S, et al. Generative dual adversarial network for generalized zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 801-810.
[22] PATTERSON G, XU C, SU H, et al. The SUN attribute database: beyond categories for deeper scene understanding[J]. International Journal of Computer Vision, 2014, 108(1-2): 59-81.
[23] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 770-778.
[24] HASTIE T, TIBSHIRANI R. Discriminant adaptive nearest neighbor classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1996, 18(6): 607-616.
[25] WELINDER P, BRANSON S, MITA T, et al. Caltech-UCSD birds 200 [EB/OL]. [2021-01-30]. https://www.researchgate. net/publication/46572499_Caltech-UCSD_Birds_200.
[26] FARHADI A, ENDRES I, HOIEM D, et al. Describing objects by their attributes[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2009: 1778.
[27] LAMPERT C H, NICKISCH H, HARMELING S. Learning to detect unseen object classes by between-class attribute transfer[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 951-958.
[28] ZHANG X H, ZOU Y X, SHI W. Dilated convolution neural network with LeakyReLU for environmental sound classification[C]//2017 22nd International Conference on Digital Signal Processing (DSP). New York: IEEE Press, 2017: 1-5.
[29] DA K. A method for stochastic optimization[EB/OL]. [2021- 01-13]. https://arxiv.org/pdf/1412.6980.pdf.
[30] VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2625.
[31] VERMA V K, ARORA G, MISHRA A, et al. Generalized zero-shot learning via synthesized examples[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 4281-4289.
[32] XIAN Y Q, LORENZ T, SCHIELE B, et al. Feature generating networks for zero-shot learning[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 5542-5551.
[33] SCH?NFELD E, EBRAHIMI S, SINHA S, et al. Generalized zero- and few-shot learning via aligned variational autoencoders[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 8239-8247.
[34] PAUL A, KRISHNAN N C, MUNJAL P. Semantically aligned bias reducing zero shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 7049-7058.
[35] SARIYILDIZ M B, CINBIS R G. Gradient matching generative networks for zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 2168-2178.
[36] VYAS M R, VENKATESWARA H, PANCHANATHAN S. Leveraging seen and unseen semantic relationships for generative zero-shot learning[C]//The 16th European Conference on Computer Vision - ECCV 2020. Heidelberg: Springer, 2020: 70-86.
Attribute and graph semantic reinforcement based zero-shot learning for image recognition
WANG Yu-jin, XIE Cheng, YU Bei-bei, XIANG Hong-xin, LIU Qing
(School of Software, Yunnan University, Kunming Yunnan 650500, China)
Zero-shot learning (ZSL) is an important branch of transfer learning in the field of image recognition. The main learning method is to train the mapping relationship between the semantic attributes of the visible category and the visual attributes without using the unseen category, and use this mapping relationship to identify the unseen category samples, which is a hot spot in the current image recognition field. For the existing ZSL model, there remains the information asymmetry between the semantic attributes and the visual attributes, and the semantic information cannot well describe visual information, leading to the problem of domain shift. In the process of synthesizing unseen semantic attributes into visual attributes, part of the visual feature information was not synthesized, which affected the recognition accuracy. In order to solve the problem of the lack of unseen semantic features and synthesis of unseen visual features, this paper designed a ZSL model that combined attribute and graph semantic to improve the zero-shot learning’s accuracy. In the learning process of the model, the knowledge graph was employed to associate visual features, while considering the attribute connection among samples, the semantic information of the seen and unseen samples was enhanced, and the adversarial learning process was utilized to strengthen the synthesis of visual features. The method shows good experimental results through experiments on four typical data sets, and the model can synthesize more detailed visual features, and its performance is superior to the existing ZSL methods.
zero-shot learning; knowledge graph; generative adversarial networks; graph convolution; image recognition
TP 391
10.11996/JG.j.2095-302X.2021060899
A
2095-302X(2021)06-0899-09
2021-03-24;
2021-05-10
中國科協“青年人才托舉工程”項目(W8193209);云南省科技廳項目(202001BB050035)
汪玉金(1995-),男,山東泰安人,碩士研究生。主要研究方向為知識圖譜、零次學習和圖像生成。E-mail:wyj1934966789@gmail.com
謝 誠(1987-),男,云南普洱人,副教授,博士。主要研究方向為知識圖譜與零次學習。E-mail:xiecheng@ynu.edu.cn
24 March,2021;
10May,2021
China Association for Science and Technology “Youths Talents Support Project” (W8193209); Technology Department Program of Yunnan Province (202001BB050035)
WANG Yu-jin (1995–), male, master student. His main research interests cover knowledge graph, zero-shot learning and image generation. E-mail:wyj1934966789@gmail.com
XIE Cheng (1987–), male, associate professor, Ph.D. His main research interests cover knowledge graph, zero-shot learning. E-mail:xiecheng@ynu.edu.cn
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
