基于Q學(xué)習(xí)算法的城軌列車智能控制策略
2022-01-22 08:57:48金則靈武曉春
鐵道標(biāo)準(zhǔn)設(shè)計 2022年1期
金則靈,武曉春
(蘭州交通大學(xué)自動化與電氣工程學(xué)院,蘭州 730070)
隨著城市的快速發(fā)展,城市人口數(shù)量大幅增加,交通問題日益突出,城市軌道交通以其運量大、速度快、占地少的特點,成為緩解城市交通的有效途徑。據(jù)統(tǒng)計,截止2020年底,我國城市軌道交通運營總長度7 545.5 km,大規(guī)模、高密度的行駛使得城市軌道交通的運行能耗急劇增長,其中,站間的牽引能耗占系統(tǒng)總能耗的50%。因此,減少牽引能耗,優(yōu)化控制策略成為近幾年研究的熱門。
列車的實際運行情況通常較為復(fù)雜,再加上機(jī)械磨損等不確定因素帶來控制參數(shù)的變化,以PID為代表的經(jīng)典控制器,很難精準(zhǔn)控制列車運行[1]。
近年來,智能控制和算法迅速發(fā)展,越來越多的學(xué)者將無模型的解決方法應(yīng)用于列車運行控制過程。成莉,俞花珍等[2-3]利用遺傳算法求解高鐵列車和重載列車的節(jié)能運行控制;黃友能,李誠等[4-5]利用粒子群算法分層優(yōu)化列車節(jié)能駕駛策略;徐凱等[6-8]將列車運行過程劃分為多階段的決策過程,采用動態(tài)規(guī)劃和時間差分進(jìn)行求解;張淼等[9]將司機(jī)駕駛經(jīng)驗與智能駕駛技術(shù)結(jié)合,設(shè)計了基于策略的強(qiáng)化學(xué)習(xí)方法;郭艷梅[10]通過深度強(qiáng)化學(xué)習(xí),根據(jù)列車的需求生成一套模糊控制方案。
強(qiáng)化學(xué)習(xí)(Reinforcement Learning,RL)是一種基于獎懲原則的學(xué)習(xí)策略,起源于行為心理學(xué)的發(fā)展和應(yīng)用[11]。與其他人工智能算法不同的是,強(qiáng)化學(xué)習(xí)無需先驗知識,具有較強(qiáng)的魯棒性。Q學(xué)習(xí)算法是強(qiáng)化學(xué)習(xí)中典型的無模型算法,由Watkins等在1992年提出的類似于動態(tài)規(guī)劃算法的一種激勵學(xué)習(xí)方法,目前已經(jīng)被廣泛應(yīng)用于各個領(lǐng)域[12-13]。
在大多數(shù)城市軌道交通的節(jié)能運行控制中,采用離線計算的方式優(yōu)化行車曲線,在列車運行過程中跟蹤優(yōu)化的曲線,且面對突發(fā)情況時,往往由ATO系統(tǒng)轉(zhuǎn)向人工駕駛模式,大大降低魯棒性。針對上述問題,以城市軌道列車為研究對象,建立列車的動力學(xué)模型,以杭州地鐵5號線三壩—萍水站線路為例,提出了一種基于Q學(xué)習(xí)算法的城軌列車控制策略,將列車連續(xù)狀態(tài)劃分為離散的狀態(tài)空間,建立列車時間和能耗獎懲函數(shù)作為算法學(xué)習(xí)的方向,對算法進(jìn)行迭代訓(xùn)練。在列車運行過程中,根據(jù)列車的行駛狀態(tài),在不使用離線速度曲線的情況下,實時計算最佳控制策略。在Q學(xué)習(xí)算法中,引入?yún)⒖紝<荫{駛經(jīng)驗的-greedy策略和按三角衰減的周期變化學(xué)習(xí)速率,有效提高了傳統(tǒng)Q學(xué)習(xí)算法的學(xué)習(xí)速率,解決了收斂慢的問題。
1 列車動力學(xué)方程
研究的對象為城軌列車,城軌車輛一般為6節(jié)編組,故將列車簡化成單質(zhì)點模型[14]進(jìn)行計算。對列車進(jìn)行受力分析,根據(jù)牛頓定律,給出單質(zhì)點運動方程為
(1)
式中,v(t)為列車當(dāng)前速度,m/s;M為列車總質(zhì)量,t;F(v)為列車施加的牽引力(或制動力);R(v)為列車的基本阻力;G(i)為線路坡道阻力。
列車的基本阻力在實際應(yīng)用中以戴維斯公式表示,計算公式為
R(v)=(av2+bv+c)·M·g
(2)
式中,g為重力加速度常數(shù),取9.8 m2/s;a,b,c為與機(jī)械阻力相關(guān)的系數(shù),一般通過擬合不同的車型得出曲線。
列車在坡道受到的阻力稱為坡道阻力,坡道阻力的計算公式為
G(i)=i·M·g
(3)
式中,i為坡道坡度千分?jǐn)?shù)。在城軌列車中,線路坡道對列車的牽引制動影響遠(yuǎn)大于其他阻力,因此將坡度因素從阻力中獨立出來[15]。列車在運行過程中還會受到曲線附加阻力、隧道空氣附加阻力的影響,這些影響較小,為簡化計算可忽略不計。
2 Q學(xué)習(xí)算法
Q學(xué)習(xí)算法通過函數(shù)迭代的方式,獲取相應(yīng)的獎懲值,不斷逼近最優(yōu)策略,Q學(xué)習(xí)算法是由一個四元組
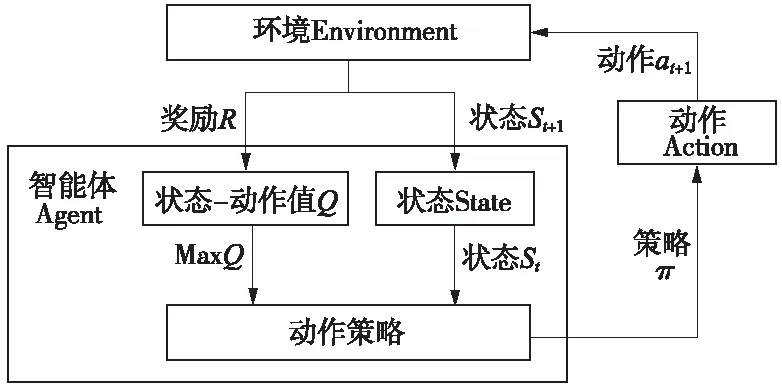
圖1 Q學(xué)習(xí)算法原理
狀態(tài)-動作值函數(shù)Q(s,a)為狀態(tài)s下執(zhí)行動作a對應(yīng)的期望回報,計算過程為
E[Rt+1+λRt+2+…+λn-1Rt+n|st,at]
(4)
式中,λ為折扣率,表示長期回報的權(quán)重。當(dāng)Agent完成了完整路徑后,才能獲取該狀態(tài)獎勵。根據(jù)貝爾曼原理將公式(4)轉(zhuǎn)化為多階段決策進(jìn)行計算
Qπ(st,at)=E[Rt+1+λRt+2+…+λn-1Rt+n|st,at]=
E[Rt+1+λ(Rt+2+…+λn-2Rt+n)|st,at]=
E[Rt+1+λQπ(st+1,at+1)|st,at]
(5)
Q學(xué)習(xí)根據(jù)時間差分思想(Temporal-Difference,TD)進(jìn)行值迭代[15],在每次迭代過程中優(yōu)化狀態(tài)-動作值函數(shù)Q,減少和目標(biāo)值之間的偏差
Q(st,at)=Q(st,at)+
α(Rt+λmaxatQ(st+1,at)-Q(st,at))
(6)
式中,Rt+λmaxatQ(st+1,at)為TD目標(biāo);Rt+λmaxatQ(st+1,at)-Q(st,at)為TD偏差;α為學(xué)習(xí)速率,決定了學(xué)習(xí)多少誤差。
Q學(xué)習(xí)算法的目標(biāo)是求解出最大狀態(tài)-動作函數(shù)對應(yīng)的策略,即
π*=arg maxatQπ(st,at)
(7)
3 基于Q學(xué)習(xí)的列車控制策略
列車的控制策略π(at|st)取決于t時刻的列車位置以及運行速度,具有馬爾可夫性,因此,以列車作為智能體,將列車的運行過程建立為MDP模型,如圖2所示,為基于Q學(xué)習(xí)的列車控制策略更新過程。以列車位置和速度作為狀態(tài)空間集S,列車對速度的控制作為動作空間集A,運行時間和牽引能耗作為獎勵函數(shù)R,初始化Q值為獎勵函數(shù),即Q(st,at)=R(st,at),給算法提供先驗知識。列車的下一個狀態(tài)根據(jù)動力學(xué)方程計算得出,按公式(6),更新得到最大狀態(tài)-動作函數(shù)對應(yīng)的列車控制策略。
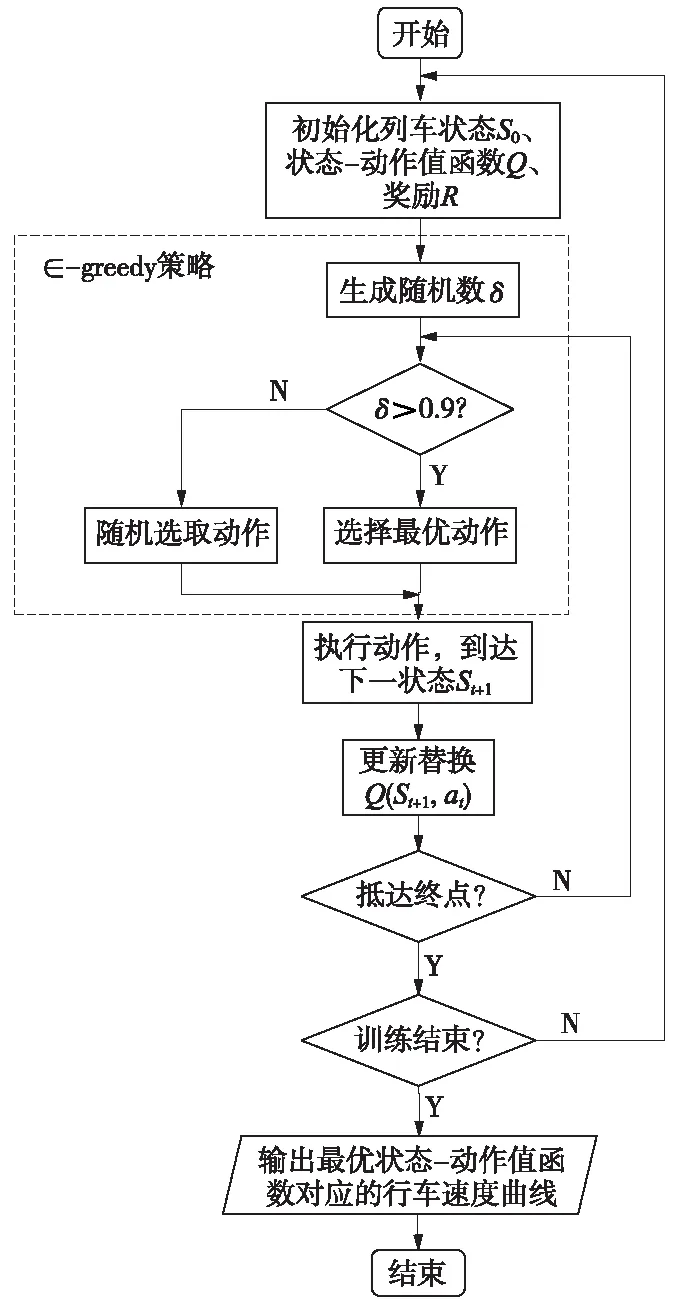
圖2 基于Q學(xué)習(xí)的列車控制策略
3.1 狀態(tài)和動作空間集定義
首先,定義Q(st,at)中的狀態(tài)s和動作a。如圖3所示,根據(jù)最大牽引加速度和制動減速度計算出列車最快速度曲線和列車最短運行時間Tmin,在實際運行中列車速度需始終低于該速度。將列車運行的過程離散化,把路程按ds劃分為k個,把最快速度按dv劃分為l個,組成列車所有的狀態(tài)集合S={s1,s2,s3,…,sk×l}。以不同速度作為控制列車的動作空間集,即A={a1,a2,a3,…,al}。ds和dv越小,描述列車狀態(tài)越精確,對應(yīng)計算量也越大。
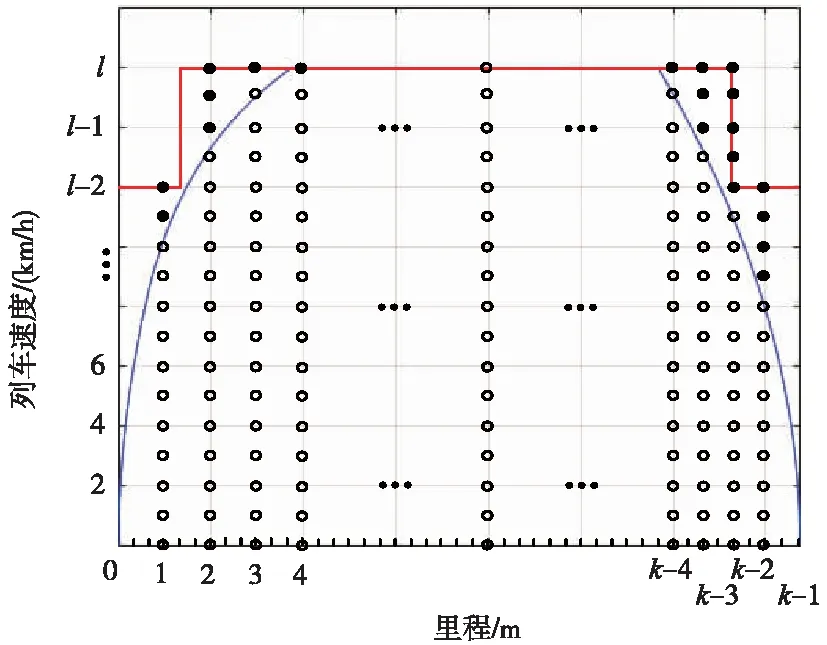
圖3 列車狀態(tài)空間集
在滿足限速條件下,列車的動作策略需滿足列車運行條件的動作,即
(8)
(9)
式中,afmax和abmax為列車的最大牽引加速度和最大制動加速度。列車根據(jù)選取出的動作,做勻加速運動至下一個狀態(tài),完成狀態(tài)轉(zhuǎn)移。
3.2 獎勵函數(shù)設(shè)計
獎勵函數(shù)關(guān)系到算法學(xué)習(xí)的方向,針對準(zhǔn)點運行和節(jié)能運行的目標(biāo),建立運行時間和牽引能耗對應(yīng)的獎勵函數(shù),即時間獎勵函數(shù)RT和能耗獎勵函數(shù)RE,設(shè)計綜合獎勵函數(shù)如下
R(st,at)=μRE(st,at)+RT(st,at)
(10)
式中,RE和RT為一一對應(yīng)的關(guān)系;μ將RE和RT平衡至同一數(shù)量級。根據(jù)pareto最優(yōu)解理論,μ取滿足列車運行時間的最大值。當(dāng)μ=0時,列車以最快駕駛速度策略行駛。對不符合列車運行條件和超速的動作,定義,避免算法學(xué)習(xí)到此類動作。
(1)時間獎勵函數(shù)
時間獎勵函數(shù)可表示為
(11)
式中,Tplan為列車運行計劃時間;T為列車兩狀態(tài)間運行時時間。用Tmax-T表示列車在兩個狀態(tài)間運行時間所用越少,獎勵越高;運行時間越久,獎勵越少。
(2)能耗獎勵函數(shù)
能耗獎勵函數(shù)可表示為
RE(st,at)=C-Ei=
(12)
式中,C為大于兩狀態(tài)間最大能耗的常數(shù);E為列車兩狀態(tài)間運行的能耗,同理能耗越大,獎勵越少。
3.3 最優(yōu)控制策略
為輸出合理的控制策略,需考慮列車運行過程中的舒適性、列車操縱規(guī)則等約束條件,對司機(jī)駕駛過程進(jìn)行數(shù)學(xué)分析,給出合理的控制策略。
實際列車不同工況之間的轉(zhuǎn)換不是任意的,必須滿足轉(zhuǎn)換規(guī)則[16],即
(13)
舒適性是控制城軌列車的重要標(biāo)準(zhǔn),根據(jù)文獻(xiàn)[17],列車加速度變化率<1 m/s3時,認(rèn)為乘客是舒適的。
(14)
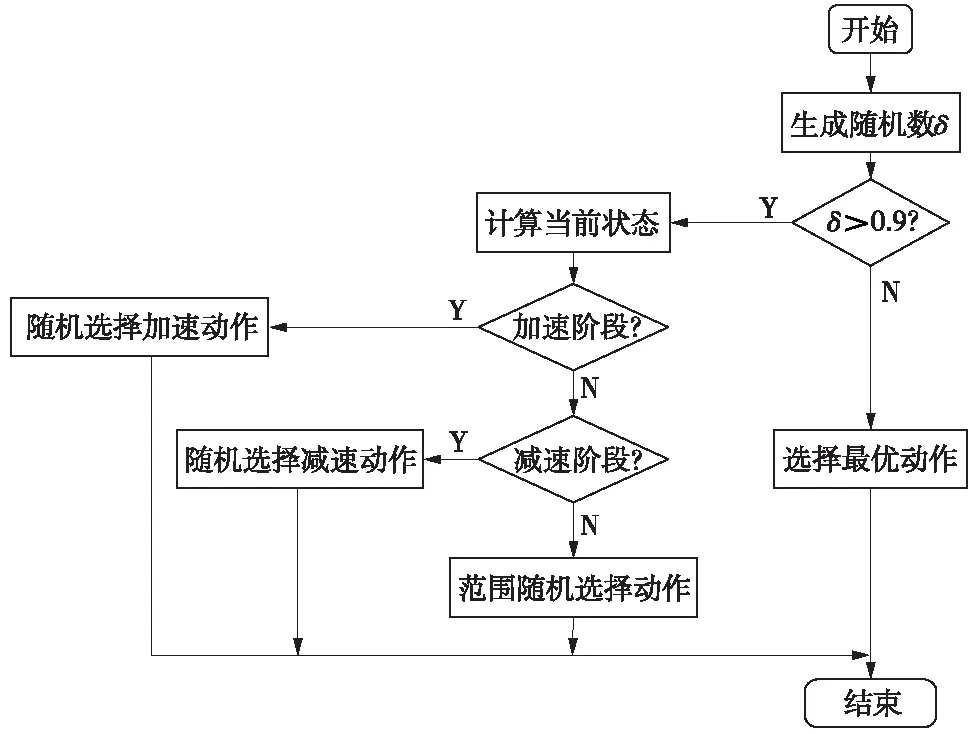
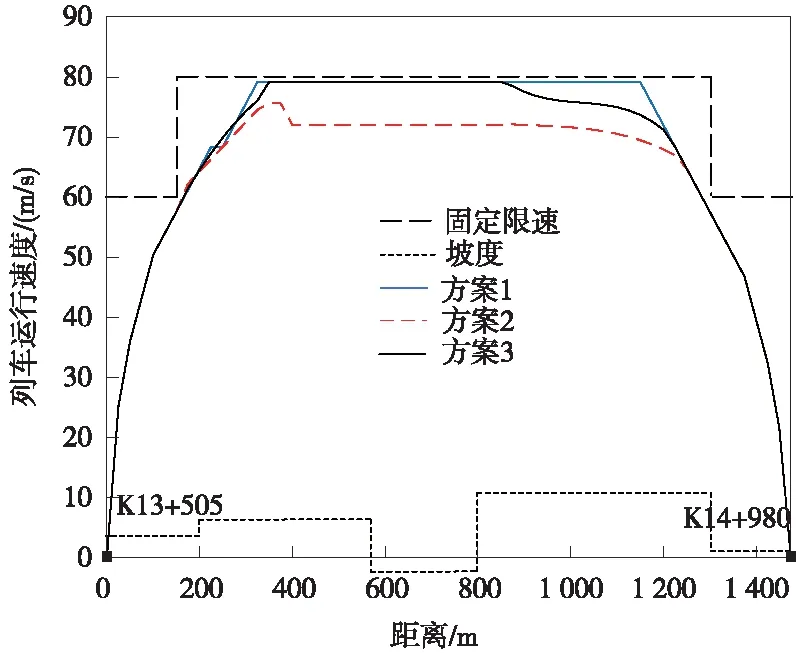
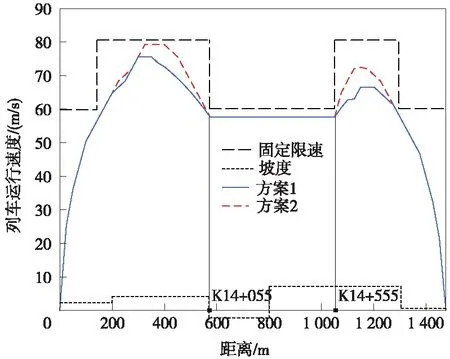
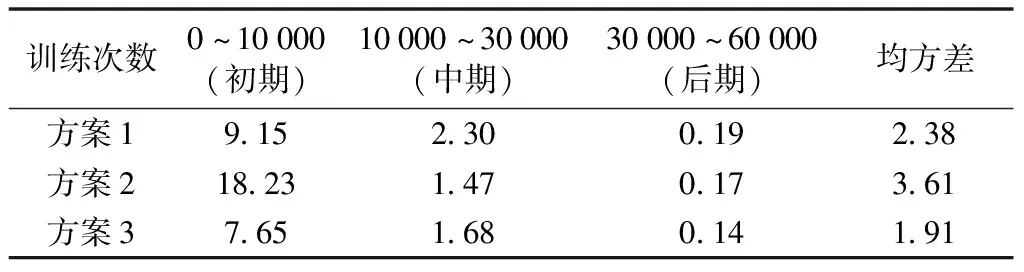
Q算法訓(xùn)練完成后,根據(jù)列車當(dāng)前狀態(tài)選擇滿足公式(13)、公式(14)約束條件動作,用公式(7)計算當(dāng)前狀態(tài)最優(yōu)控制策略,列車運行時間和牽引能耗用各個狀態(tài)間時間和能耗的總和計算,如公式(15)、公式(16)。若列車因故障自身晚點,且小于剩余最短運行時間5 s,即Tplan-T (15) (16) 為克服Q學(xué)習(xí)算法收斂速度慢的問題,在傳統(tǒng)Q學(xué)習(xí)算法的基礎(chǔ)上加入基于駕駛經(jīng)驗的-greedy策略,使算法根據(jù)列車的實際情況有目標(biāo)的進(jìn)行搜索,同時引入按三角衰減的周期變化學(xué)習(xí)速率,在保證收斂的情況下,減少算法的迭代次數(shù)。 強(qiáng)化學(xué)習(xí)算法的性能在很大程度上受算法控制策略中的兩個重要因素影響,即“探索”和“開發(fā)”[18]。隨機(jī)選擇動作為探索,保證了Agent盡可能多的嘗試所有動作,但收斂速度慢;選取最大回報的動作為開發(fā),則會讓Agent陷入局部最優(yōu)解。一種常見的方式是使用-greedy策略進(jìn)行探索和利用。在每一次迭代中以的概率選擇隨機(jī)動作,以1-的概率選擇最優(yōu)動作,同時兼顧探索和利用的平衡。為避免探索到無效的動作,提高Q算法學(xué)習(xí)效率,提出一種將司機(jī)駕駛經(jīng)驗加入到-greedy中的探索過程,實現(xiàn)過程如圖4所示。具體步驟為:當(dāng)Q學(xué)習(xí)選擇隨機(jī)動作時,計算列車當(dāng)前的位置st和速度vt,根據(jù)位置和速度判斷列車當(dāng)前所處的階段,并探索相應(yīng)的駕駛策略。 圖4 基于駕駛經(jīng)驗的-greedy策略流程圖 運用此基于駕駛經(jīng)驗的隨機(jī)選擇策略,降低了動作選擇的盲目性,減少了無效探索的次數(shù),有助于提升算法訓(xùn)練效率。 3.4.2 周期學(xué)習(xí)速率 學(xué)習(xí)速率(Learning rate,LR)是強(qiáng)化學(xué)習(xí)中的一個重要參數(shù),決定著能否收斂到最小值,何時收斂到最小值。根據(jù)公式(6)整理得到 Q(st,at)=(1-α)Q(st,at)+ α(Rt+λmaxatQ(st+1,at) (17) 式中,Q(st,at)為更新前的Q值,可以看出,學(xué)習(xí)速率越大,保留之前的訓(xùn)練效果越少,因此,選擇合適的學(xué)習(xí)率十分重要。在實際應(yīng)用中,一般采取固定的學(xué)習(xí)速率,或者離散下降學(xué)習(xí)率(discrete staircase Learning rate,DSLR),即經(jīng)過一段輪次的訓(xùn)練,學(xué)習(xí)速率減半。Smith L N等[19-20]提出一種三角周期學(xué)習(xí)率,讓學(xué)習(xí)率在邊界之間變化,避免陷入局部最優(yōu)解。文中引用一種按三角衰減的周期變化學(xué)習(xí)速率(Descent-Triangle Learning rate,DTLR),即學(xué)習(xí)速率的變化范圍隨訓(xùn)練次數(shù)的增加而減少,變化過程如圖5所示。 圖5 學(xué)習(xí)速率變化過程 圖5中Max_Lr和Min_Lr為學(xué)習(xí)速率的最大值和最小值,可通過實驗測試得出。在給定的迭代次數(shù)內(nèi)能保證收斂的最小的學(xué)習(xí)速率設(shè)定為Min_Lr,提高學(xué)習(xí)速率,當(dāng)訓(xùn)練結(jié)束,曲線依然震蕩,此學(xué)習(xí)率設(shè)為Max_Lr。在一個變化周期內(nèi),學(xué)習(xí)速率的計算公式為 (18) (19) β=T-1 (20) α=Min_Lr+(Max_Lr-Min_Lr)· (21) 其中,τ為一次周期的長度,根據(jù)循環(huán)次數(shù)及變化的周期次數(shù)給定;e為當(dāng)前的迭代次數(shù);β為所處的周期。每一輪周期結(jié)束后,Max_Lr-Min_Lr縮減一半,以提高狀態(tài)-動作函數(shù)的收斂速度。 為驗證算法的有效性,選取杭州地鐵5號線三壩站至萍水街站為例,線路參數(shù)如表1所示。 表1 線路參數(shù) 杭州地鐵5號線使用AH型地鐵列車,假設(shè)列車處于額定載荷(AW2),車輛具體參數(shù)如表2所示。當(dāng)列車處于AW2工況下牽引運行時,啟動加速度為1.09 m/s2,平均加速度為0.68 m/s2,牽引或者制動時,列車均采用無級控制。 表2 車輛具體參數(shù) 設(shè)置進(jìn)行60 000次的訓(xùn)練學(xué)習(xí),Q學(xué)習(xí)算法具體參數(shù)設(shè)置如表3所示。列車初始狀態(tài)為s1(x1=0,v1=0),列車的加速度由車輛的參數(shù)和Q-learning動作策略確定,一旦列車抵達(dá)終點,將列車最終狀態(tài)st(xt=1475,vt=0)重置為初始狀態(tài),完成一次訓(xùn)練。 表3 算法參數(shù)設(shè)置 為驗證算法的有效性,將本文算法與最快速度駕駛策略、文獻(xiàn)[21]傳統(tǒng)動態(tài)規(guī)劃算法進(jìn)行比較,方案1為最快速度駕駛,方案2為本文駕駛策略,方案3為傳統(tǒng)動態(tài)規(guī)劃算法。考慮到存在隨機(jī)性,對每個算法進(jìn)行20次仿真取均值,且在訓(xùn)練過程中,-greedy給定相同的隨機(jī)序列δ,仿真列車運行曲線如圖6所示。 圖6 列車運行仿真曲線 觀察圖6的列車運行仿真曲線,3個方案均滿足固定限速要求。在牽引階段,3個方案都以列車最大運行能力加速至最大運行速度,方案2的最大速度低于方案1和方案3;在惰行階段,方案2和方案3采用了惰行節(jié)省能耗,方案3在最后一段上坡道開始時采取惰行策略,而方案2為滿足準(zhǔn)點運行,在1 000 m左右開始惰行;在制動階段,方案1最先開始制動,其次是方案3,最后是方案2。仿真計算對比結(jié)果如表4所示。 表4 不同方案仿真計算結(jié)果 計算運行時差和節(jié)能率作為評價正點運行和節(jié)能運行目標(biāo),對比表4數(shù)據(jù)可得,3種方案均滿足準(zhǔn)點運行的要求,方案1站間運行時間最短,牽引能耗最大;方案2和方案3的控制策略能耗較于最快速度的駕駛策略均有不同程度的減少。傳統(tǒng)動態(tài)規(guī)劃法所得控制策略,列車運行能耗為29.16 kW·h,運行時間95.13 s,本文所采用的Q學(xué)習(xí)算法所得控制策略,列車運行能耗為27.94 kW·h,運行時間98.03 s,相較于最快速度駕駛節(jié)能效果為13.01%,相較于動態(tài)規(guī)劃算法節(jié)能效果進(jìn)一步提升3.79%。同時對比發(fā)現(xiàn),在相同的線路上,列車運行的時間越長,列車所能選擇控制策略越多,節(jié)能的效果越好。 為進(jìn)一步驗證算法的有效性,在原線路上增加一段500 m臨時限速區(qū)段,對方案1和方案2進(jìn)行重新仿真,仿真列車運行曲線如圖7所示,所得仿真計算結(jié)果如表5所示。 圖7 增加臨時限速列車運行曲線 表5 增加臨時限速后不同方案仿真計算結(jié)果 從圖7列車運行曲線看出,經(jīng)過限速區(qū)段后,Q學(xué)習(xí)算法列車為保證準(zhǔn)點運行,沒有直接選擇惰行策略,而是經(jīng)過一段時間加速后再選擇惰行和制動,運行時間99.57 s,滿足列車時刻表要求。增加臨時限速后不可避免的增加了牽引能耗7.5%,相較于最快速度駕駛策略節(jié)能12.66%,證明Q學(xué)習(xí)算法在滿足準(zhǔn)點運行下,仍具有節(jié)能效果。同時對比無限速情況發(fā)現(xiàn),增加臨時限速后,列車的操縱策略變得復(fù)雜,為滿足準(zhǔn)點運行,節(jié)能率會有所降低。 圖8 不同探索策略收斂結(jié)果 從圖8可以看出,相較于前2個方案,基于專家駕駛經(jīng)驗動作選擇策略。在前期訓(xùn)練中明顯減少了盲目的探索,更快的接近最優(yōu)解,進(jìn)一步計算3種方案不同階段的方差,結(jié)果如表6所示。 表6 不同探索方案仿真計算結(jié)果 從計算結(jié)果看出,在訓(xùn)練初期使用大探索率效果較好,中后期使用小探索率可以更精確的收斂,本文提出基于專家駕駛經(jīng)驗動作選擇策略,相較于其他探索策略,前期探索更接近最優(yōu)速度曲線,訓(xùn)練初期方差降低了16.4%和58%,總體方差降低了20%和47.2%。結(jié)果表明,加入了專家駕駛經(jīng)驗的探索策略,在訓(xùn)練初期引導(dǎo)算法朝著目標(biāo)策略進(jìn)行學(xué)習(xí),減少了無效學(xué)習(xí),加快收斂速度。 (1)針對城軌列車的節(jié)能運行,以準(zhǔn)點性、舒適度和節(jié)能運行為指標(biāo),提出一種無需使用離線速度曲線的Q學(xué)習(xí)算法列車智能控制策略,將-greedy策略與司機(jī)駕駛經(jīng)驗相結(jié)合,提高算法學(xué)習(xí)效率。 (2)仿真驗證表明,Q學(xué)習(xí)算法在保證準(zhǔn)點運行的情況下,可有效解決列車運行的節(jié)能問題。在增加臨時限速區(qū)段后,該算法可根據(jù)運行時間,調(diào)整列車控制策略。 (3)使用離散化的速度作為狀態(tài)空間,且未考慮列車運行過程中時刻表調(diào)整及列車牽引性能發(fā)生變化等情況,細(xì)化列車狀態(tài)空間,進(jìn)一步提高計算實效性及列車運行時刻表調(diào)整后如何在線計算是下一步的研究方向。3.4 優(yōu)化Q學(xué)習(xí)算法

4 仿真驗證及性能分析
4.1 參數(shù)設(shè)置


4.2 測試結(jié)果分析



5 結(jié)論
猜你喜歡
能源工程(2020年6期)2021-01-26 00:55:22
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
山東冶金(2019年3期)2019-07-10 00:54:04
消費導(dǎo)刊(2018年10期)2018-08-20 02:57:02
小學(xué)生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學(xué)低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
通信電源技術(shù)(2016年1期)2016-04-16 04:57:26
