機器生成語言的質量評價方法綜述*
2022-01-24 02:16:24秦穎
計算機工程與科學 2022年1期
秦 穎
(北京外國語大學人工智能與人類語言實驗室,北京 100089)
1 引言
生成可被理解的、流暢且符合語言環境和要求的自然語言是人工智能的重要體現。自然語言生成NLG(Natural Language Generation)廣義上包含了所有機器生成語言的任務,涵蓋機器翻譯、自動文摘、對話系統、故事和新聞寫作、圖像與視頻標題生成等。根據生成語言時是否有參照,本文將NLG任務分為參照型和開放型2大類,如圖1所示。

Figure 1 Main research directions of general natural language generation圖1 廣義自然語言生成任務的主要研究方向
參照型任務依據給定的文本或圖像等生成語言。常見的生成需求有:(1)形式轉換任務,例如機器翻譯、圖像/視頻標題生成等。機器翻譯將原文轉換為另一種語言的譯文;圖像/視頻標題生成任務為圖像/視頻生成相應的描述文字,即從圖像語義表達變為文字語義表達。(2)語義壓縮任務,主要包括自動文摘和句子簡化等文本到文本的生成任務,在保持給定原文核心內容不變的情況下,實現語義壓縮,生成更簡短的文本。
開放型生成任務往往沒有明確的生成參照,目的是實現基于自然語言的交流或創作,包括人機對話、機器寫作和文本擴展等典型任務。
不難看出,從機器翻譯、自動文摘、圖像標題生成到人機對話、機器寫作,生成任務的開放性逐漸增大。
近年來語言生成技術取得了令人矚目的進展,而生成語言的質量評價問題越來越突出。首先,代價高、周期長、重用性差的人工評價仍作為各個任務的黃金標準(Gold Standard),自動評價的性能較差,無法代替人工。其次,語言質量評價的研究發展緩慢,已經成為制約NLG發展的、亟待解決的難點和瓶頸問題[1 - 4]。下面以機器翻譯評測平臺WMT(Workshop of Machine Translation)近15年的人工與自動評價方法的變化為例。2006年人工評價標準是譯文流利度和充分性的5段打分,自動評價采用的是BLEU (BiLingual Evaluation Understudy)算法[5,6]。之后增加了人工排序和句法成分等更細粒度的評價,自動評價增加了METEOR、TER(Translation Error Rate)和GTM(Graph Theory Matching)等10種算法[7]。為保證人工評價的可信度,增加了多人評價的一致性衡量指標。2009年后不再對譯文打分,只對不同系統譯文進行排序,同時增加人工對機器譯文的編輯,采取HTER(Human-mediated Translation Edit Rate)指標反映譯文的質量[8]。為擴大人工評價的范圍,2010年開始采取眾包方式(Crowd-sourced)評估各個機器翻譯系統。自動評價方面,2012年增加了無參考譯文的質量估計[9]。之后又在人工排序評價前,加入了對系統譯文的聚類處理。質量估計的粒度從句子級擴展到詞匯級。2014年提出了新的排序模型,以更好地利用人工排序結果,質量評估的粒度也更多更細。2016年提出了單語直接評測法(Direct Assessment)[10],以避免參考譯文對人工評價的影響。
生成語言質量評價是研發過程的重要反饋,不但反映生成系統性能,很大程度還能指導生成技術的研究,并且在訓練時用于生成模型的參數調整[11]。
本文對近年來NLG任務的有關文獻梳理后發現,不同任務的評價方法差異較大,同時又有很強的關聯性,存在諸多可相互借鑒的思想和方法,有必要從整體上分析機器生成語言的質量評價問題,通過不同任務評價的對比,實現相互借鑒和融合,探索新的評價方法。
下文中,首先介紹人工評價的特點及關注的主要問題。然后是自動評價算法的介紹和優缺點分析,介紹開放的評價資源,并總結各算法之間的聯系和交叉應用情況;最后是對機器生成語言質量評價的總結和展望。
2 人工評價
人工評價機器生成語言的質量具有主觀性,盡管存在代價高、周期長、不一致和不確定等問題,人工評價目前仍是各個生成任務最準確、最認可的方式。人工評價主要有以下幾個關注的問題:
2.1 評價者與評價結果的選擇
常見的評價者有系統研發人員、語言專業人士和評價志愿者。評價者的選擇影響評價的結果,選擇不同的評價者時對評價質量的控制方法也不同。一般而言,系統研發人員和語言專業人士具有較好的背景知識,可信度相對較高。評價可由一人完成,也可多人評價。一人評價容易受個人主觀因素的影響而不穩定[12]。多人評價的結果也會存在波動性。為保證多人評價的可信度,需要檢查評價結果的一致性(Agreement)。衡量一致性的指標常用Kappa系數[13]。Kappa系數K的計算方法如式(1)所示:
(1)
其中,P(A)代表2個評價結果相同的概率,P(E)為基于隨機猜測時2個評價結果相同的概率。Kappa系數越大說明一致性越高。Kappa系數在0.2以下,說明幾乎沒有一致性;0.2~0.4表示一致性較低;0.4~0.6表示一致性中等程度;0.6~0.8表示一致性較高;0.8以上代表幾乎完全一致[14]。
基于眾包平臺如Mechanical Turk(MTurk)[15]和CrowdFlower(www. crowdflower.com)的志愿者評價是較為廉價的人工評價方式。眾包評價的關鍵是評價結果的質量控制,著名的有MACE(Multi-Annotator Competence Estimation)工具[16]。針對評價者的投機取巧等作弊行為,基于MTurk平臺也提出了多種控制質量的方法[17]。
2.2 內部評價與外部評價
內部評價(Intrinsic Evaluation)不涉及語言生成系統的設置和使用效果,是針對生成語言內在質量進行的評價,如語言的流利度、正確性和合理性等。而外部評價(Extrinsic Evaluation)考查的是生成系統達成目標的效度,是從系統的外部表現或系統作為其他應用的組成時對其他部分的影響角度進行的評價。顯然,效度與系統應用和設計目的密切相關[18]。例如評價京東客服機器人對話系統Alphasales時,使用了客服電話轉人工率、72小時內再次撥打的比例等與任務相關的外部評價指標。
2.3 評價方式
生成語言質量評價方式主要有分類(Classification)、評分(Scoring)和排序(Ranking)3種。一般認為,排序的評價難度低于分類和評分,且一致性也比評價分高,更適用于系統之間的比較[19]。此外,還有基于閱讀時間的測量法(Reading-Time Measure),是根據評價者做出判斷所需要的閱讀時間來區分不同的文本質量[20],一般來講,評閱時間越長,生成語言的質量越差,因此是一種間接的評價方式。
2.4 評價參考和事先培訓
人工評價結果作為黃金標準也不是完美的,經常會出現評價者曲解評價任務,或給出不合邏輯的、異常的評價。為了讓評價者更好地理解評價任務和評價標準,可通過事先培訓來提高評價的一致性。另一種提高人工評價一致性的方式是給出參考答案,比如評價機器翻譯時提供專家譯文作為評價的參考,但這樣的代價會更高,評價者的判斷也容易受參考答案的影響。
還有很多復雜的因素會影響人工評價的一致性,如評價文本的長度和復雜度、評價的數目等。
2.5 人工評價標準
內部評價常根據不同任務從不同的語言質量維度進行,主要指標有連貫性、內容性、結構性、正確性、風格和整體質量等。任務不同,維度也有所不同,比如機器翻譯一般不去評價譯文的語言風格和內容的豐富性,重點關注譯文的流利度和準確度。而評價幽默寫作的質量時,則會增加文檔的趣味性這一維度。評價基于多篇文檔的機器文摘時,會增加信息冗余度這一指標。以下是機器翻譯、自動文摘和人機對話任務常見的人工評價標準。
2.5.1 機器翻譯
1964年美國語言自動處理咨詢委員會ALPAC(Automatic Language Processing Advisory Committee)人工評價機器譯文包括2個角度:一是譯文的忠實度(Fidelity),二是譯文的可理解度(Intelligibility)。我國863機器翻譯評測中的人工評分標準包括充分性(Adequacy)和流利度(Fluency),評分共分6個等級。充分性衡量譯文多大程度體現了原文的語義,流利度反映譯文的可讀性。
從2009年開始,WMT開始采取眾包方式對參賽系統譯文進行質量排序,并且在亞馬遜網站上開發了著名的MTurk評價平臺。基于該平臺,可計算人工干預的翻譯編輯率HTER,即人工修訂機器譯文成為可接受的譯文需要進行的編輯量[15],值越小質量越高。
以上是內部評價機器譯文質量的標準。外部評價機器翻譯的質量,可讓評價者基于機器譯文進行閱讀理解測試[15]。
2.5.2 自動文摘
自動文摘任務有多種類型[21]:根據文摘的來源文檔數目可分為單文檔文摘(Single Document Summarization)和多文檔文摘(Multi-Document Summarization);根據文摘的策略可分為抽取式文摘(Extractive Summarization)和抽象式文摘(Abstractive Summarization)。而查詢文摘(Query-Focused)和通用文摘(Generic)的區別是前者圍繞查詢相關的內容組成文摘,后者是以核心內容構成的文摘。從輸出風格上又可分為標示型文摘(Indicative Summary)和信息型文摘(Informative Summary)。標示型文摘只需要給出文檔最核心的主題,而信息型文摘則要列出全部主題的內容。針對不同的文摘類型,質量評價指標也各不相同。通用型文摘強調摘要內容的重要性(查詢文摘重點是主題的相關性)、內容的覆蓋面、句子的連貫性和信息冗余度等。
內部評價文摘質量的標準主要包括:無冗余(Non-Redundancy)、結構和連貫(Structure and Coherence)、重點突出(Focus)和整體質量(Quality)狀況[22]。有的標準還包括文摘的語法性(Grammaticality)和參照清晰度(Referential Clarity)等指標[21]。
在文檔理解會議DUC(Document Understanding Conference)上,評價者以句子為單位評價機器文摘的內容和語言質量,其中語言質量指標又進一步分為語法性(Grammaticality)、內斂性(Cohesion)和連貫性(Coherence)3個方面[23]。后來在文本分析會議TAC(Text Analysis Confe- rence)上,人工評價機器文摘采用了金字塔(Pyramid)法和反應度(Responsiveness)2種標準[24]。金字塔法要求人工標注文摘的內容單元(Content Unit),基于文摘中包含內容單元的多少和權重計算得分。反應度是根據用戶信息需求對機器文摘進行的直觀印象評分。
外部評價將文摘置于特定的應用中來評價文摘對系統的影響,如將文摘置于類似游戲場景下,利用猜測下一個詞的游戲來評價文摘的信息含量[25];以及基于問答方式測試讀者對文摘的理解程度[21]等方法。
2.5.3 對話系統
對話系統的類型很多(如圖1所示),不同類型的對話系統功能和目的不同,評價標準差異較大[26]:(1)任務型對話系統強調對話的內容和策略,評價主要從任務實現(Task-Success)和對話效率(Dialogue Efficiency)2個方面進行,可分為用戶滿意(User Satisfaction Modeling)和用戶模擬(User Simulation)2種評價模型。(2)社會型對話屬于開放的、非結構化的交談,傳統的評價方式是圖靈測試(Turing Test)。粗粒度的評價標準包括對話應答的恰當性(Appropriateness)和類人性(Human Likeness)。細粒度的評價標準涉及具體的語言特征,如對話的連貫性和主題的維持(Maintaining)、主題的深度(Topic Depth)、對話的廣度(Conversational Breadth)等。(3)問答型對話的質量評價經常借鑒信息檢索的評價標準,如準確率和召回率等。
文獻[27]針對一個口語對話系統的生成話語設計了3項人工評價的內容:對話的信息度(Informativeness)、自然度(Naturalness)和總體質量(Quality)。可控聊天機器人的關鍵是對話的可控性,文獻[28]提出的評價生成話語可控制性的指標有:重復性(Repetition)、特異性(Specificity)、應答相關性(Response-Relatedness)和提問能力(Question-Asking)。最近谷歌公司開放域多輪對話系統Meena的人工評價標準是回復的合理性(Sensibleness)和內容的具體性(Specificity)2個指標的平均值,即SSA(Sensibleness and Specificity Average)評價指標[29]。實驗表明,SSA與人們對對話系統的喜好程度正相關。
人工評價聊天機器人的對話質量目前尚沒有確定統一的標準。評價時通常會設計很多問題進行問卷調查,比如“對話進行是否順暢?參與對話的程度如何?你認為對方是人還是機器人?是否愿意再聊一次?”等,這些問題主觀性強,答案與受訪者對系統的期望值有關。開放型對話系統的質量與多種因素有關,這些因素的權衡和比較在評價時十分重要。
為研究多輪對話中對整體對話質量有貢獻的重要因素,文獻[28]發現:(1)控制對話的重復率對所有人工判斷極其重要;(2)問更多的問題能提升對話系統的吸引力;(3)控制特異性即減少使用通用話語,能提高聊天的吸引力、興趣和感知;(4)評價者對非通用機器人的錯誤容忍度較低,當出現不流利或無意義的語句時評分通常較低。整體上,與用戶體驗關系密切的因素包括聊天內容的趣味性、對話的流利度、傾聽性和少問問題等。
3 自動評價
廉價、快速、一致和可重用是自動評價的優勢。自動評價算法通常與不同語言生成任務相適應。自動評價也分外部評價和內部評價。內部評價研究最多的是基于參考答案的評價,即將機器生成文本與人工參考答案進行相似度的比較,越相似的認為質量越高。
3.1 對自動評價算法的要求
根據NLG研究文獻,本文歸納了自動評價算法通常要滿足的要求:(1)算法有足夠的質量區分度,能夠區分不同質量的機器生成文本,或者能識別人工文本與機器生成文本。(2)可解釋性,也就是區分不同質量的文本的依據要合理。(3)對評價系統和數據的依賴度,一般要求評價算法獨立于系統和評價數據。(4)健壯性,即算法對評價數據變動的敏感程度[30],健壯的算法應能適應評價內容和領域的變化。(5)可重用性,算法應能重復使用,并保持多次評價結果不變。(6)可靠性,評價結果具有較高的可信度和準確度。
常用與人工評價的相關度來衡量自動評價算法的性能,如皮爾遜相關系數(Pearson Coefficient)、斯皮爾曼相關系數(Spearman Coefficient)和Kendall tau等指標,并用威廉姆斯測試(Williams’ test)[31]判斷相關的顯著程度。
3.2 不同任務的自動評價算法分析與資源
3.2.1 機器翻譯
機器翻譯中經典的、影響深遠的自動評價算法是BLEU。評價的思想是比較參考譯文和機器譯文在語言形式上的相似度,計算單位是共現的n-gram數目。BLEU得分的計算如式(2)所示:
(2)
其中,pn是不同n-gram的鉗位匹配率,wn是相應n-gram的權重,N一般取到4。BP是對長度小于參考譯文r的機器譯文c的懲罰因子。
BLEU算法的優點是與語言無關(Language Independent),簡單易行。盡管一直作為WMT平臺的官方評價標準(https://github.com/jhclark/multeval),BLEU評價還有很多問題,如當n較大時匹配的幾率很小,n-gram得分經常為0,因此目前采取的是Smoothed BLEU[32],處理了n-gram為0的情況。但是,Smoothed BLEU仍未能改變機械匹配和n-gram稀疏帶來的問題[33,34]。盡管算法可基于多個參考譯文進行評價,但正確的譯文往往是多樣的,機械匹配難以評價同義或近義的譯法。BLEU算法實際上是一種準確率評價指標。算法中譯文長度的懲罰因子設定也具有主觀性。針對上述問題,有不少改進研究,如EBLEU(Enhanced BLEU)算法[35]綜合了準確率和召回率、調和平均以及多種長度懲罰因子指標;AMBER(A Modified Bleu,Enhanced Ranking)評價[36]則是對比了10種懲罰因子、4種匹配策略和多種譯文輸入類型而提出的。這些工作一定程度上提升了BLEU算法的性能,但評價結果還是受到不少質疑[37],很多文獻指出BLEU得分并不足以反映譯文質量的細微差異。
與BLEU類似的、基于語言形式匹配的評價算法還有不少,如NIST(National Institute of Standards and Technology)[38]和METEOR[39]等,這類自動評價算法的困難都是無法深入到譯文的句法和語義層面進行相似度的比較,基于詞匯或n-gram的匹配只能在較淺的層面上檢查譯文的充分性和流利度。
無參考譯文時,自動評價算法一般要提取原文和機器譯文的語言特征并結合外部資源進行譯文質量的估計,判定詞匯級、句子級的翻譯質量等級或進行排序。WMT目前使用的機器翻譯質量估計平臺是QuEst[40]。QuEst+ +提取的語言特征已多達172種[41],但整體上質量估計的性能低于有參考譯文的評價性能,更多的應用是檢查機器譯文中的特異點,進行譯后編輯。
3.2.2 自動文摘
外部評價文摘質量時關注的是文摘對其他任務的影響。文獻[42]提出了關聯相關度(Relevance Correlation)評價方法,將生成文摘置于檢索任務中,根據摘要而不是原文進行檢索時,檢索性能相對下降的度量被定義為關聯相關度。
內部評價算法主要評價文摘的語言質量和信息度[21]。基于人工參考文摘的自動評價算法以內容的重疊程度為依據計算文摘的信息度[43]。常用的指標有句子共選(Sentence Co-selection)率、準確率、召回率、F1值和ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[44]。其中,ROUGE是DUC會議的官方評價標準。與BLEU類似,ROUGE也是一種求n-gram重疊率的算法。ROUGE有很多變體,包括ROUGE-N,ROUGE-L,ROUGE-W,ROUGE-S和ROUGE-SU等[45]。基本ROUGE-N的通用計算如式(3)所示,評價工具也是公開的(https://github.com/summanlp/evaluation/tree/master/ROUGE-RELEASE-1.5.5)。
(3)
其中,N表示n-gram的長度,{ReferenceSummaries}表示參考文摘構成的集合,S代表字符串,Countmatch(gramn)表示生成文摘與參考文摘共現的n-gram最大數目;Count(gramn)的含義是參考文摘中全部n-gram的數目。ROUGE給出每一個n-gram的得分,是一種召回率指標。因此,ROUGE評價主要反映的是文摘涵蓋信息的豐富程度。
ROUGE的優點是它是一種獨立于語言的評價方法,實現簡單。不同的變體體現了不同的評價側重點,比如ROUGE-N能夠反映詞序關系,但當N值較大時,ROUGE得分通常很低,影響了評價的區分度;ROUGE-S計算的是skip-gram,即不要求連續的n-gram匹配,因而能更好地關注句子的內容而不是其中詞匯的順序,但是不連續區間的大小又不容易確定。
ROUGE比較適用于抽取式文摘,而不太適合抽象式文摘的評價。抽象式文摘強調的是核心觀點和概念的抽取,可用不同于原文的句子使摘要內容更清晰[21],但ROUGE基于簡單匹配難以反映生成句子的準確率和流利度。實際上,文章中承載信息的形式很多,包括事實詞(Factoids)、相同意義單位和重述等,ROUGE只是從n-gram重疊率這個角度反映文摘的信息,算法同樣不能深入到語義層面分析摘要的意義。
自動文摘任務較開放,人工參考文摘的變化較多。研究者們開發了多種基于相似度比較的評價算法,著名的有QARLA評價框架[46]。如果沒有參考文摘做參照,評價算法往往通過比較機器文摘和原文檔的語義相似度、核心內容的相似度來判斷文摘的質量,例如求原文與文摘的主題相似度和詞匯意義相似度的潛在語義分析法LSA(Latent Semantic Analysis)[47],以及基于詞中心度的評價算法[48],中心詞代表的是向量空間文檔簇的中心。
3.2.3 圖像標題生成
圖像標題生成(Image Captioning)是計算機視覺領域的一個重要方向,屬于跨模態的語言生成任務,也稱圖像標注(Image Labeling)。
針對同一幅圖像,不同人給出的描述可能完全不同,但可能都是好的標題,因此圖像標題生成任務的開放性更大。研究者們也嘗試用BLEU、ROUGE等算法評價生成的標題,結果發現,基于人工標題和生成標題匹配的自動評價算法和人工評價結果很難有較高的一致性[49-51]。近年來出現了針對圖像標題生成特有的評價算法,如CIDEr(Consensus-based Image Description Evaluation)[49]、SPICE(Semantic Propositional Image Caption Evalution)和神經網絡判別模型等。CIDEr算法對n-gram利用TF-IDF(Term Frequency- Inversed Document Frequency)加權的方式計算生成標題與多個參考標題的一致性,力求得到不同參考標題共同關注的內容。
設第i幅圖像的參考標題句子集合為Si={si1,si2,…,sim},m是句子數目,n-gramwk在參考標題的句子sij以及在生成標題句子ci中出現的次數分別為hk(sij)和hk(ci),基于TF-IDF對n-gramwk的加權值gk(sij)如式(4)所示:
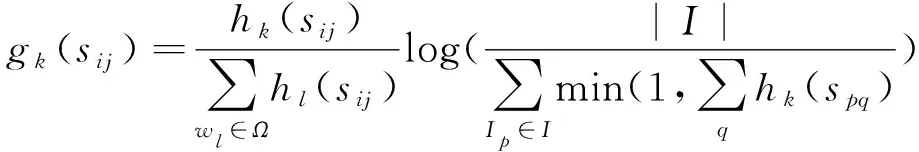
(4)
其中,Ω表示n-gram詞表,I是圖像集合。
長度為n的n-gram的CIDEr得分如式(5)所示:
(5)
其中,gn()為n-gram函數。
再結合n-gram的權重,最終CIDEr得分形式如式(6)所示:
(6)
CIDEr算法開源了評價工具包(https://github.com/tylin/coco-caption)和評價服務器[50]。算法與語言無關,評價思想也是比較n-gram的相似度,其特點是利用了加權方式反映出多樣化的人工標題中共同關注的圖像要素,其優缺點基本與BLEU和ROUGE的相同,不再贅述。
SPICE是從語義命題內容角度提出的評價圖像標題質量的方法[1]。將標題解析為場景圖(Scene Graphs),場景圖對對象、屬性和關系進行編碼。圖中的語義關系被視為邏輯命題的連接。基于圖中對象類別、關系和屬性構成的三元組判斷生成標題和參考標題的語義相似度,最終以F1值表示標題質量的高低。SPICE算法也有公開的工具(http://panderson.me/spice)。SPICE借助于場景圖解析標題所描述的對象、關系和屬性,更能從圖像內容層面實現評價,因此取得了較好的評價性能。SPICE算法適用于圖像標題類較簡短句子的評價,在機器翻譯等復雜評價任務上的嘗試還沒有開展。
圖像標題的質量評價還可以采用判別器模型[52]:輸入圖像、人工標題和生成標題,訓練一個模型,根據概率得分判別是人工標題還是機器生成的標題。計算如式(7)所示:
(7)

3.2.4 對話系統
與機器翻譯等有參照的生成任務相比,對話有以下的特點:首先生成語言的內容由系統決定,而不是參照文本或圖像;其次對話語言多呈現口語化,句子相對簡單,語言的復雜度比機器翻譯小。自動評價對話質量的主要困難來自任務的開放性內容。
如果有人工應答做參考,可借用機器翻譯、信息檢索等評價指標如BLEU、DISTINCT1/2、Hits@K和knowledgeprecision/recall/F1等評價應答的質量[53]。不同指標反映了生成應答在不同層面的質量:F1反映的是應答在字級別的性能,BLEU得分主要反映詞匯級的性能,而DISTINCT指標用于衡量應答的多樣性。針對知識型對話的應答質量,文獻[54]將生成的句子和系統知識在unigram層面計算準確率、召回率和F1值。也有基于多種距離函數來定義準確率、召回率和F1值的方法評價應答質量的研究[55]。
但是文獻[27]指出,F1、BLEU和DISTINCT等指標用于評價基于數據驅動的、端到端方式的對話系統生成的應答時,只能略微地反映出人工評價的思想。算法評價在系統級有較高的可信度,但在句子級的可信度很差。不同算法的性能還與特定的數據和系統有關。
神經網絡也被用于對對話質量進行評價,文獻[56]嘗試了對抗學習(Adversarial Learning)的評價方法:訓練一個生成對抗網絡,以判別器的性能反映對話的質量。但是,作者沒有評估判別器的評分能否作為評價對話質量的可行性。有研究者指出,利用對抗學習評價對話質量的可行性并不樂觀[57]。
針對開放性很強的生成任務,語言生成模型的困惑度PPL(PerPLexity)被用于評價人對于對話系統的喜歡程度。研究發現,PPL與人類喜歡程度負相關[29]。PPL其實是語言模型的評價指標,只能從統計意義上間接地體現生成應答的質量。PPL是一個指數值,模型的微小改變可能引起PPL的較大改變,PPL值的改變和人們對生成語言質量的感知并不成比例。
機器無法做到真正理解語言。對話系統所做的努力是讓機器產出的結果看起來像是理解了人類語言后才發出的響應,越是接近自然人的響應結果,越能體現智能性,對話應答的質量也越高。因此,對話的外部評價主要從應答的適宜程度和類人程度角度進行。
3.2.5 其他語言生成任務
句子簡化(Sentence Simplification)通過替換復雜單詞、簡化復雜的句法結構、刪去次要成分等方式重寫給定的句子,生成簡單短小的句子。句子簡化屬于文本到文本的生成任務之一[58]。為衡量簡短句的質量,文獻[58]采用了可讀性標準Flesch-Kincaid得分和SARI得分(可讀性得分的計算工具 https://github.com/mmautner/readability)。BLEU得分也被用于評價,但文獻[59]發現BLEU得分與人工流利度評分的相關度低,但正相關;與充分性評分的相關度更低,且負相關。
故事生成(Storytelling)屬于創意寫作。給定故事的開頭等提示信息,由機器自動生成后續的故事內容。故事生成也是開放域的生成任務,質量評價十分困難。文獻[60]用語言分析法評價故事生成的連續性。評價內容分為2項,第1項是獨立于故事的質量評價,語言特征包括句子長度、語法、詞匯多樣性、詞頻和句法復雜度等8項。第2項是與故事有關句子的質量評價,語言特征包括詞匯選擇、風格匹配度和實體共指等。文獻[61]基于一個常識故事結尾續寫的語料庫,提出了一個基于故事理解的自動評價框架——故事完型測試(Story Cloze Test):系統根據故事前面的句子完成最后一句的續寫,實際上是從正反2種故事結尾答案中做出選擇,類似完形填空,從而實現自動評價。文獻[62]提出的自動評價無需和人工故事進行比較,而是用故事生成模型的困惑度和提示排名精確度(Prompt Ranking Accuracy)來評估流利度和輸出對輸入的依賴程度。
機器新聞寫作的質量主要從讀者的接受程度考慮。由于機器新聞寫作同時有負面的應用,即假新聞(Fake News)的生成,因此,新聞寫作方面較多的研究是檢測新聞的真假[63],而不是評價生成新聞的質量。
文獻[64]指出,一個能很好地預測機器寫作與人工寫作相似性的評價方法并不一定能成為一個好的預測器,好的預測器能夠站在讀者角度預測寫作的有效性和有用性。
3.2.6 不同任務算法之間的聯系與應用
NLG各任務評價之間有較強的相關性,一些自動評價算法實現了跨任務應用。本文匯總了經典自動評價算法在多種不同生成任務上的應用情況,如表1所示。其中,MT表示機器翻譯,AS表示自動文摘,HD表示人機對話,IC表示圖像標題生成,ST表示故事生成。

Table 1 Application of automatic evaluation algorithms in different tasks
基于參考答案和生成文本相似度的評價算法如BLEU、ROUGE等獲得了最廣泛的應用,成為多數自動評價算法的基礎。盡管BLEU和ROUGE等在生成語言質量評價方面的結果并不理想,但仍然是官方認可的標準之一。圖像標題的CIDEr評價算法需要很多人工參考標題來獲得一致的評價內容,SPICE因為需要將句子解析為場景圖,在復雜句子上的應用有限。PPL是一種統計算法,主要反映模型的多樣性,并不能真正反映生成語言的質量,一般在缺少或不便提供參考答案時用困惑度來評價機器生成的語言的質量。
3.3 自動評價性能的影響因素與特點
自動評價的穩定性和可靠性影響因素與算法參數有關。與參考答案進行相似度比較的評價方法中,參考答案的數目是一個影響因素。研究表明[38],BLEU和NIST對參考譯文的數目并不敏感,多個參考答案對評價性能的提升并不明顯。同樣的結論也出現在自動文摘的評價ROUGE算法中[12];文獻[38]同時指出,評價樣本的數量其實對評價結果的穩定性和可靠性影響更大,要得到具有統計意義的結果,樣本要足夠多。
算法性能還與特定的數據和系統有關。自動評價區分一般質量與高質量的生成文本比較困難。對于質量較差的生成文本,自動評價似乎與人工評價的評價結果更趨一致,但對高質量的文本和中等質量的文本,自動評價與人工的評價相關度較差[27]。文獻[65]研究了多種評價算法的健壯性,更換場景、更換人物、共享場景和共享人物4種情況都對圖像標題的評價結果產生影響。
最后,自動評價往往高估(Overestimate)生成文本的質量,部分得分較高的系統實際生成語言的質量并不好[27,66]。
4 結束語
機器正在以各種方式大量生成自然語言,生成語言的質量評價不可或缺又異常復雜。人工對生成語言的質量評價相對準確可靠,具有可解釋性和診斷性等特點,但是代價高、周期長,且評價結果不可重用、不可擴展,從而嚴重制約了NLG的研發,迫切需要高性能的自動評價算法[67]。但是,現在還沒有任何自動評價算法可以充分捕捉到文本質量的全貌,即能夠代理人類的判斷。一個好的評價算法不但能評價生成文本的質量,還能夠兼顧答案的多樣性(Diversity),這對于帶有創造性、開放領域的生成任務而言尤其重要[67]。
語言質量評價應與文本生成任務分離,獨立于生成任務的質量預測是更好的選擇[4]。自動評價的研究遇到瓶頸,其主要困難從根本上看是評價模型的問題,如果自動評價采取模擬人工評價的思想和方法,模型的實現將十分復雜。因此,多數評價采取了與人工答案比較相似度的模型。利用相似度模型評價時,難點問題變成了相似度與語言質量的關系。一般性假設是,與人工答案越相似的質量越高,但這對于開放型評價任務并不總是成立。人工答案不是唯一的,數目也有限,質量評價時真正需要比較的應該是語義層面的相似度,語言形式的相似并不等于語義的相似,所以基于形式比較的自動評測都無法深入到參考答案的語義和語用層面。傳統的語言學特征是研究語言形式相似的主要手段。另一種觀點認為,文本質量是非構成式的,不是各個語言特征的疊加,而是文本的附屬屬性,是只能在特定上下文中對文本特征進行整體評估后才能獲得的一種屬性[68]。自動評價模型有待于提升。
第2個困難是評價機器生成語言的質量是一個動態的、源源不斷的需求,并且與任務相關。加上多文檔、多語種、多模態評價任務的出現,以及復雜評價因素如文本風格、個性化、情感傾向等的加入,無論是對自動評價還是人工評價而言,都面臨巨大的挑戰。各種評價算法一直是被動地去適應這些需求,領域適用性和穩定性不好,都未能從根本上解決語言質量評價的核心問題。
最近的自動評價研究體現出解決這些難題的一些思路。在相似度研究方面,除了利用傳統的語言特征,也開始嘗試新的語義表示方法,例如基于詞嵌入的相似度比較,相比機械匹配而言,詞嵌入能更多地捕捉語義,實現連續空間中的內容比較[65]。也有將文檔之間的距離視為旅行代價,基于詞匯移動距離WMD(Word Mover’s Distance)[69]求相似度的評價方法[22]。針對不同領域的評價,遷移學習的思想也受到關注,例如谷歌最近推出的評價機器翻譯的BLEURT(github.com/google-research/bleurt)算法,可提高BLEU在不同領域的適應性和穩定性。
本文認為,自動評價研究的大致趨勢可分為3個具體的方向:(1)新的評價模型的研究,最新的工作是利用深度學習的框架實現自動評價[70]。(2)不同評價方式的整合研究[18,24,46],由于不同的算法從不同角度捕捉了語言質量的不同方面,綜合的模型可更全面地反映生成語言的質量狀況。(3)定義更聚焦的評價算法以捕捉生成文本的特定方面,而不是進行籠統的質量評價,這樣可以幫助我們追蹤所關心的生成文本的某些重要的質量因素,比如流利度、多樣性和重復率等。
本質上,機器生成語言的質量評價屬于自然語言理解任務,全面準確地評價語言質量涉及的因素非常復雜,生成語言的質量評價比語言生成任務本身更有挑戰性。
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
文苑(2020年4期)2020-05-30 12:35:30
中國生殖健康(2019年2期)2019-08-23 08:12:08
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
汽車觀察(2016年3期)2016-02-28 13:16:26
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
