基于殘差密集網絡層次信息的圖像標題生成*
2022-01-24 02:16:20李軍輝
計算機工程與科學 2022年1期
王 習,張 凱,李軍輝,孔 芳
(蘇州大學計算機科學與技術學院,江蘇 蘇州 215006)
1 引言
自然語言處理NLP(Natural Language Processing)和計算機視覺CV(Computer Vision)是人工智能領域研究的2大熱點。當前,跨領域研究已經成為未來研究的一種趨勢,引起了研究者極大的興趣。圖像標題(Image Caption)正是結合計算機視覺和自然語言處理的一種跨領域研究,該技術最早由Farhadi等人[1]提出,給定二元組(I,S),其中,I表示圖像,S表示對該圖像的描述,模型要完成I→S的映射,基于深度學習網絡獲取圖像特征,然后輸出該圖像的標題內容。“看圖說話”對正常人來說非常簡單,但對于計算機來說是一項極具挑戰的任務,計算機不僅僅要識別圖像的內容,還要用人類的邏輯思維描述出人類可讀的句子。
當前生成圖像標題的主要方法是基于神經網絡的方法,特別地,基于自注意力機制的生成模型取得了較好的性能,其中Liu等人[2]提出的雙向注意力機制具有較好的性能。但是,在傳統的深層網絡中,層之間以線性方式進行堆疊,不同的層能夠捕獲不同的語義信息,導致低層語義信息無法在高層中體現,沒有得到充分利用。
因此,本文把Vaswani 等人[3]提出的Transformer(tf)模型作為基準模型,在此基礎上融入殘差密集網絡,以捕獲圖像標題的淺層語義信息。具體地,首先,為了能夠充分利用深層網絡的層次信息,以及提取深層網絡中的各個層的局部特征,本文提出LayerRDense(Layer Residual Dense)網絡,實現在層與層之間的殘差密集連接。其次,為了更好地融合圖像特征和圖像的描述信息,在解碼端每層網絡中的子層之間運用殘差密集網絡。在圖像標題任務MSCOCO 2014數據集上的實驗結果表明,本文提出的LayerRDense和SubRDense網絡均能進一步提高模型的性能。
2 相關工作
生成圖像標題的傳統做法是利用圖像處理的一些算子提取圖像的特征,經過支持向量機SVM(Support Vector Machine)等分類得到圖像中可能存在的目標對象[4]。然后根據提取到的對象及其屬性,利用條件隨機場CRF(Conditional Random Field)或者是一些指定的規則來生成對圖像的描述。不難看出,這種做法非常依賴于圖像特征的提取以及生成句子時所需要的規則,效果也并不理想。
受神經機器翻譯的啟發,將機器翻譯中編碼源文字的循環神經網絡RNN(Recurrent Neural Network)替換成卷積神經網絡CNN(Convolutional Neural Network)來編碼圖像,圖像標題生成問題便可轉化為機器翻譯問題。從翻譯的角度來看,此處的源文字就是圖像,目標文字就是生成的標題。因此,圖像標題生成采用的神經網絡模型通常由編碼器和解碼器2部分組成。編碼器使用CNN將圖像轉化為一個固定長度的向量,也稱圖像的隱層表示;解碼器使用RNN將編碼器輸出的固定長度的向量解析為目標語言句子。Vinyals等人[5]提出了神經圖像標題NIC(Neural Image Caption)模型,該模型將圖像和單詞投影到多模態空間,并使用長短時記憶網絡LSTM(Long Short-Term Memory)生成英文描述。Karpathy等人[6]利用片段圖像生成局部區域的標題。Mao等人[7]在基于傳統CNN編碼器-RNN解碼器的神經網絡模型的基礎上,提出使用多模態空間為圖像和文本建立聯系。Jia等人[8]提出了gLSTM模型,該模型使用語義信息指導長短時記憶網絡生成標題,解決了圖像僅在開始時傳入LSTM的問題。在此基礎上Wu等人[9]提出了att-LSTM模型,該模型通過圖像多標簽分類來提取圖像中可能存在的屬性,解決了總是使用全局特征作為圖像特征的問題。Xu等人[10]將注意力機制引入解碼過程,使得標題生成網絡能夠捕捉圖像的局部信息。然而,這種加入注意力的方法也存在一些缺點,即每個詞都會對應一個圖像區域,但是有些介詞、動詞等并不能對應實體,除此之外注意力機制是基于卷積層的加權,映射到圖像特征,會使得圖像變得模糊且不能準確定位圖中對應區域。為了解決這些問題,Lu等人[11]提出了一種自適應的注意力機制,使模型自主決定根據先驗知識(模板)還是根據圖像中的區域來生成單詞。
前面所有工作都是針對解碼器RNN進行研究,然而CNN也是不可忽略的一個重點,Chen等人[12]使用卷積層的不同通道做注意力計算,同時還利用空間注意力機制。Li等人[13]構建了首個中文圖像摘要數據集 Flickr8kCN,并提出中文摘要生成模型 CS-NIC(Crowd Sourced-Neural Image Caption),作者使用GoogleNet[14]對圖像進行編碼,并使用LSTM對圖像描述生成過程建模。Rennie等人[15]提出SCST(Self-Critical Sequence Training)模型,利用強化學習生成有區別度的標題。Anderson等人[16]提出了Bottom-Up and Top-Down模型,該模型結合Bottom-Up和Top-Down視覺注意力機制,Bottom-Up機制用來提取視覺特征,Top-Down機制用于關注詞向量特征。
上述模型均屬于使用CNN編碼器-RNN解碼器的框架,雖然RNN解碼器基于視覺特征并且使用注意力機制生成標題,但是這種方法只是考慮了圖像和標題多模態間的相互作用,沒有考慮圖像特征以及標題內部間的交互作用。本文使用的基準模型Transformer是一個深層的神經網絡模型,能夠在統一的注意力區域內同時捕獲模態內和模態間的相互作用的優點來彌補RNN的缺陷。本文參考Zhang等人[17]將殘差密集網絡運用到圖像處理問題中以解決像素分辨率問題,以及Shen等人[18]將密集運用到機器翻譯模型的Encoder端和Decoder端以獲取密集信息流,提出2種方法將Dense加入到基準模型中,探索層次信息之間的融合,以充分利用層次的特征信息。
3 基準模型:Transformer
3.1 模型架構
Transformer是基于自注意力機制的圖像標題生成模型,由編碼器和解碼器構成,如圖1 所示。編碼器由L個相同層堆疊組成(實際中設置L=6),每層都有2個子層,第1個是多頭自注意力MHA(Multi-Head self-Attention)機制子層,第2個是前饋網絡子層。2個子層的輸出采用殘差連接并進行歸一化,即LayerNorm(x+Sublayer(x)),其中x為上一個子層的輸出。
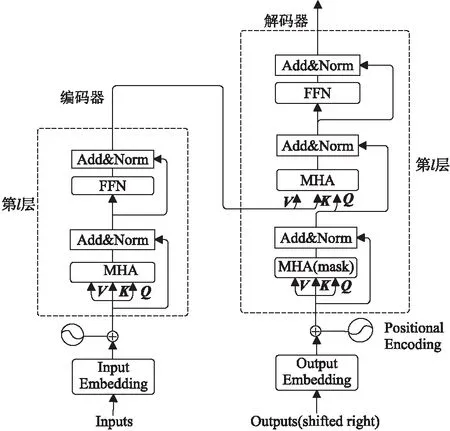
Figure 1 Structure of Transformer圖1 Transformer 模型結構
Transfomer模型的編碼器-解碼器由若干個多頭自注意力機制堆疊而成,單個“多頭注意力機制”又由多個點積注意力機制組成,如式(1)所示,最后將h頭的注意力計算結果進行拼接,再進行1次變換得到的值便是多頭自注意力機制提取的特征值,如式(2)所示。
(1)
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(2)
1≤i≤h
(3)

3.2 Transformer在圖像生成標題中的應用
為了將Transformer模型更好地應用在圖像處理中,類似于Transformer在機器翻譯任務中的應用,本文將二元組(I,S)中的I看作源端,S看作目標端。Transformer模型的結構高度契合目標任務,其注意力機制能夠同時捕捉圖像特征內部間的相互作用、圖像和標題間的相互作用以及標題序列內部的相互作用。
圖像標題生成的Transformer結構如圖2所示,整個網絡結構由圖像編碼器和標題序列解碼器組成。圖像編碼器將圖像作為輸入,使用CNN網絡提取視覺特征,然后將視覺特征經過線性層轉換之后輸入給編碼器,通過自注意學習獲得有意義的視覺特征。解碼器循環接收編碼段輸出的視覺特征和前一個單詞來預測下一個單詞,同時通過自注意力機制學習標題序列間的相互作用。為了使整個網絡結構看上去更簡潔,本文使用Encoder和Decoder分別表示圖1中的編碼器和解碼器。

Figure 2 Structure of Image caption generation model圖2 圖像標題生成模型結構
4 基于殘差密集網絡的圖像標題生成
本節分別描述在圖像標題生成模型中融合殘差密集網絡的2種方式。
4.1 LayerRDense網絡結構
第3節中提到,Transformer的Encoder和Decoder都由L個獨立層組成,為了更好地融入層次特征信息,本文提出殘差密集網絡Layer RDense,將每層的輸出融合起來,如圖3所示。其中,Hl表示第l層的輸出,1≤l≤L;X為位置編碼和詞向量相加的輸出;Layer(·)為每層包含的函數,包括Multihead(MHA)、Feed-Forward(FFN)和Layer Normerlization(Norm)等。
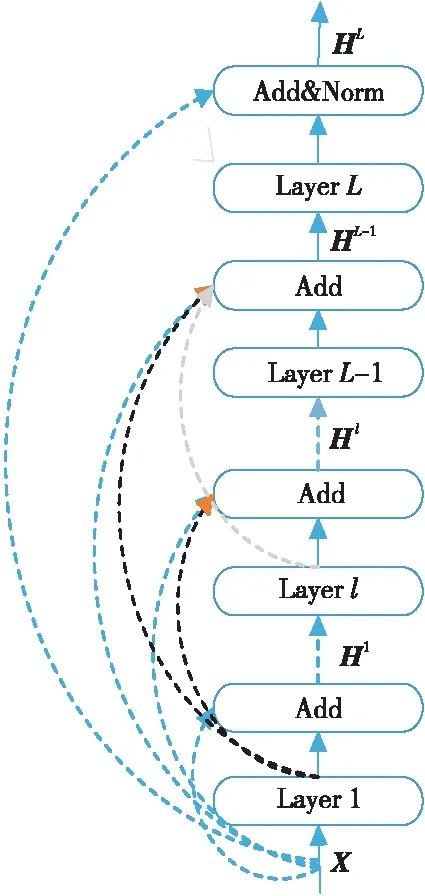
Figure 3 Structure of LayerRDense圖3 LayerRDense結構
盡管本文提出的Layer RDense會帶來與網絡的額外連接,每層的特性數量更少,但該結構鼓勵特征重用,并且模型每層特征可以更緊湊、更具有表現力,更容易進行特征融合以及殘差學習。特征融合是將所有層的輸出和原始輸入自適應地融合在一起。原始輸入可以直接和所有層的輸出加在一起,對于減少特征數是很重要的。融合公式如式(4)所示:
Hl=Layer(Hl-1)+Hl-2+…+H1+X
(4)
殘差學習在殘差密集網絡中更近一步地改善了信息流。原始輸入和每一層的輸出直接連接到后一層,既保留了原始輸入的性質,又提取了局部的密集特征。最終殘差密集部分的輸出如式(5)所示:
HL=LayerNorm(Layer(HL-1)+X)
(5)
其中LayerNorm(·)為層歸一化。
本文將殘差密集網絡融入到Transformer中,主要在Encoder與Decoder端的L=6個獨立層使用殘差密集網絡來充分利用層次特征。具體地,在第L層之前的所有層的輸出進行密集連接;而在第L層,將此層的輸出和原始輸入進行殘差連接,與以往不同的是,因在所有層進行密集連接會導致額外增加一些網絡連接操作,在每層的子層中只做殘差連接,即保持基準模型的其它操作不變。
4.2 SubRDense網絡結構
本文所做的圖像標題生成實驗,訓練的輸入包含視覺特征和圖像標題信息2個關鍵的輸入信息。為了將圖像標題的信息與圖像特征更好地融合起來,本文提出在Decoder端加入殘差密集網絡SubRDense,如圖4所示。

Figure 4 Structure of SubRDense圖4 SubRDense 結構
每個子層的輸出如式(6)~式(8)所示:
S1=LayerNorm(MultiHead(X,X,X)+X)
(6)
S2=LayerNorm(MultiHead(S1,E,Z)+S1+X)
(7)
S3=LayerNorm(FFN(S2)+S1+X)
(8)
其中,S1,S2分別表示各個子層的輸出;S3∈Rn*dmodel,n為句子長度,dmodel為模型輸出維度;FFN表示Feed-Forward;E和Z表示來自Encoder端的輸出。
從圖4中可以看出,Decoder端中第1個子層計算句子Self-Attention,第2個子層計算Context-Attention,在此層中,視覺特征所對應的句子標題信息第1次進行融合處理。第3個子層計算Feed-Forward。由此可以看出,在Decoder端,圖像的標題信息特征與圖像特征會進行融合處理,為進一步強化兩者的融合,在此基礎上,加入殘差密集網絡,將圖像特征與圖像所對應的標題信息更進一步融合。
5 實驗與結果分析
5.1 數據集
實驗使用的數據集為MSCOCO 2014[19],本文使用Karpathy等人[6]的方法將MSCOCO 2014數據集分成訓練集、驗證集和測試集,其中訓練集共有113 287幅圖像,驗證集和測試集各自有5 000幅圖像,每幅圖像都提供5句不同的英文標題。
本文使用BLEU-1~BLEU-4[20]、METEOR[21]、ROUGE_L[22]、CIDEr[23]和SPICE[24]共5種指標來衡量生成的圖像標題的質量。其中,BLEU一般用于評測機器翻譯的翻譯質量,反映了生成結果與參考答案之間的N元文法準確率。METEOR測量基于單精度加權調和平均數和單字召回率。ROUGE_L與BLEU類似,它是基于召回率的相似度衡量方法。CIDEr是基于共識的評價方法,該指標將每個句子都看成文檔,并將其表示為向量的形式,然后計算參考的標題與模型生成的標題的余弦相似度。SPICE是一種語義命題圖像標題評估方法,評測有些句子雖然根據N元文法規則重疊度很低,但是表達的意思相近的情況,盡可能多地考慮到每句話的語義命題。通過將候選標題和參考標題轉換為一種稱為場景圖的基于圖的語義表示來評估標題質量。場景圖顯式地對圖像標題中的對象、屬性和關系進行編碼,在此過程中抽象出自然語言的大部分詞匯和句法特性。
5.2 實驗設置
5.2.1 圖像特征提取網絡設置
視覺特征提取網絡CNN(I)完成I→V(I)的特征映射,其中I為輸入圖像,輸出為視覺特征。本文采用2種視覺特征。其中一種視覺特征使用ResNet-101結構[25]提取,此網絡在大規模單標簽分類任務ImageNet[26]上訓練獲得。實驗使用ResNet-101的最后一層卷積層的輸出經過平均池化層,將圖像特征映射為(50,14×14,2048)的矩陣,再經過隱藏單元數為512的全連接層,將視覺特征映射為(50,14×14,512)的矩陣作為最終的視覺特征輸入參數, 并且在整個訓練模型的過程中,ResNet-101的模型參數不更新。另外一種視覺特征使用Faster-RCNN[27]提取。Faster-RCNN結構是在目標區域檢測任務上進行訓練生成的。本文同樣使用Faster-RCNN最后一個卷積層的輸出作為提取到的視覺特征。對于Faster-RCNN模型,本文使用和Anderson等人[16]相同的特征輸入方式。
5.2.2 圖像標題生成模型設置
圖像標題生成使用Transformer模型,模型的隱藏狀態長度均為512,詞向量的長度為512,層數L=6,英文詞匯表的大小為9 487,未登錄詞用〈UNK〉表示,詞向量和模型參數的初始值在[-0.1,0.1]按均勻分布得到,優化器選用自適應估計(Adam)算法[28],學習率為5×10-4,批處理的大小為50,測試時批處理大小為10,測試時使用大小為4的柱狀搜索算法[29]。訓練過程中,每一層使用Dropout正則化來提高模型的泛化能力[30],訓練使用交叉熵損失函數,采用最大步長為20個epoch 的早停策略。
5.3 結果分析
本節分別展示與分析本文提出的LayerRDense和SubRDense的實驗結果。
5.3.1 LayerRDense的實驗結果
表1給出的視覺特征是使用Faster-RCNN提取的。表1中*_En指LayerRDense只在Encoder上使用,*_De指LayerRDense只在Decoder端使用;*_ED指在Encoder端和Decoder端都使用LayerRDense。表2給出的視覺特征是使用ResNet-101提取的。從表1和表2中可以發現,無論視覺特征的提取采用哪一種網絡,只要在Encoder端和Decoder端都使用殘差密集網絡,評測值相比于Base均有提升,說明層與層之間信息重用,能夠使信息更具有表現力,而且各層之間的信息傳遞能力有所增強。當視覺特征的提取使用Faster-RCNN網絡時,評測值的提高程度要比使用ResNet-101網絡時高,例如使用Faster-RCNN網絡提取時CIDEr值從114.2提高到115.5。而使用另一種網絡,CIDEr從107.1提高到107.7,說明視覺特征的提取使用不同的網絡也會導致效果的提升程度不同。
為了更進一步地探索層次信息,把在層之間融入殘差密集網絡的實驗分解開。第1個實驗僅僅在Encoder端使用殘差密集網絡,Decoder端不使用;第2個實驗只在Decoder端使用殘差密集網絡,Encoder端不使用。當使用Faster-RCNN網絡提取視覺特征時,從表1中可以發現,只在Decoder端使用殘差密集網絡,效果可以與在Encoder端和Decoder端都使用殘差密集網絡相當。當使用Resnet-101提取視覺特征時,只在Decoder端使用殘差密集網絡,從表2中可以發現,CIDEr值從107.1提高到107.8,BLEU值也均有一定的提升。從以上分析可以看出,在Decoder端進行低階特征和高階特征的融合,比在Encoder端和Decoder 端都使用殘差密集網絡的效果好,說明Decoder端圖像特征和標題特征的融合更容易提取到豐富的層次信息,而且除去了在Encoder端額外的網絡連接,訓練的時間也會縮短。

Table 1 Experimental results of LayerRDense extracting visual features using Faster-RCNN

Table 2 Experimental results of LayerRDense extracting visual features using ResNet-101
5.3.2 SubRDense的實驗結果
當使用Faster-RCNN網絡提取視覺特征時,從表3和表4中可以發現SubRDense的效果,CIDEr值相比Base從114.2提高到115.8,其它的評測值也均有提升。其次,在每層中的子層之間使用SubRDense,評測的效果可以達到只在Decoder 端使用LayerRDense的效果。

Table 3 Experimental results of SubRDense extracting visual features using Faster-RCNN

Table 4 Experimental results of SubRDense extracting visual features using ResNet-101
綜上,本文提出的2種網絡,從實驗的效果來看,2種網絡的效果相當。但是,從直觀的角度看,第2種網絡明顯比第1種的額外網絡連接操作數少,訓練時長也有所縮短。
5.4 圖像標題質量分析
圖 5 所示是標題模型的預測結果,從圖5中可以看出,基準系統預測出來的標題,丟失了圖像中所擁有的‘car’這個單詞的對象,并將其誤預測成‘meter’。而加入殘差密集網絡進行圖像特征與圖像標題的融合所得到的預測結果很顯然能夠把‘car’預測出來,且句子比較通順。

Figure 5 Image and prediction result by model proposed in this paper prediction result圖5 圖像和本文所提的模型預測結果
6 結束語
本文將殘差密集網絡融合到基準模型中,探索了層與層之間的信息融合。從圖像標題生成任務的角度,考慮將圖像的描述信息和圖像特征更好地融合起來,增強信息的傳遞能力。在LayerRDense中,當前的特征能夠自適應地從先前和當前層的輸出中學習到更有效的特征,并穩定地訓練網絡。本文從圖像特征和圖像標題信息更進一步地融合以及縮短加入LayerRDense的訓練時長的角度出發,提出在基準模型中加入SubRDense,實驗結果也表明,效果有一定的提升,訓練時長相比于LayerRDense只在Decoder 端使用的訓練時長也縮短了。
受注意力機制的啟發,在未來的工作中,可以去探索對每層的輸出信息的重視程度,比如給每層的輸出信息分配一個權重,這樣在訓練過程中,可以了解每層信息對整個訓練的影響程度,并進行增強或者削弱。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
