基于LDA和卷積神經網絡的半監督圖像標注方法*
2022-01-24 02:16:22王保成劉利軍黃青松
計算機工程與科學 2022年1期
王保成,劉利軍,黃青松,2
(1.昆明理工大學信息工程與自動化學院,云南 昆明 650500; 2.云南省計算機技術應用重點實驗室,云南 昆明 650500)
1 引言
隨著科技的快速發展,人們已經不再滿足于文字形式的情感分享,更多地選擇使用圖像來表達自己的情感,這使得網絡中圖像的數量與日俱增,同時也出現了一個問題:虛擬現實中出現了大量缺少標簽的數據,特別是大量的以圖像形式存在的數據沒有標簽,使得這些圖像不能被很好地使用。如何更好地利用這些無標簽但含有大量信息的圖像成為當今一個重要的問題,同時又因為我們身處于一個信息大爆炸的時代,所以每幅圖像中都含有大量且豐富的信息。因此,每幅圖像中往往需要標注多個標簽,相對而言,雖然標注多個標簽的方法更復雜,但圖像中的信息能被更好地挖掘和使用。
目前生成模型、判別模型和最近鄰居模型常被用來完成圖像的多個標簽的標注。生成模型通過同時學習圖像和文本的分布來進行標注。其中,主題模型[1]經常被使用,例如,采用最大期望EM (Expectation Maximization)算法的概率潛在語義分析PLSA (Probabilisticlatent Semantic Analysis)模型[2]、使用貝葉斯框架的隱含狄利克雷分布LDA (Latent Dirichlet Allocation)模型[3]、融合PLSA和高斯混合模型GMM(Gaussian Mixture Model)的標注方法[4]和改進的融入類別信息的一致性LDA corr-LDA(correspondence LDA)方法[5]等。判別模型[6]首先為每個待標注標簽單獨訓練一個分類器,再用其進行標注。最近鄰居模型借助檢索最近鄰居的標簽來標注圖像,如根據特征計算距離的共同平等貢獻JEC(Joint Equal Contribution)模型[7]和權重與鄰居標簽的存在狀態有關的 標簽傳遞TagProp (Tag Propagation)模型[8]。
因為深度網絡的不斷發展,學者們著手研究是否能把深度網絡應用在圖像上。例如,使用線性回歸的卷積神經網絡回歸器CNN-R (CNN Regressor)模型[9]、對損失函數進行優化的均方誤差卷積神經網絡CNN-MSE(CNN Mean Square Error)模型[10]、利用網絡中間層特征的標注方法[11]、引入關聯規則的CNN-LDA模型[12]和引入鄰域排序損失函數的LNR+2PKNN(List-wise Neural Ranking+Two Pass KNN)方法[13]。然而,這些方法仍然存在樣本不足和標注詞分布不均勻等問題。
因此,本文使用LDA來對文字數據降維,并且減少人工標注的成本,同時把注意力機制加入到卷積神經網絡中,以更好地獲得2種模態間的聯系,并修改其損失函數解決標注詞分布不均勻的問題,最后采用半監督學習的方法來處理樣本可能不足的問題,從而得到了較好的結果。
2 相關介紹
2.1 主題模型
LDA模型生成主題和標注詞的流程如圖1所示。

Figure 1 LDA model圖1 主題模型
圖1中,θ表示主題參數,z表示主題,w表示標注詞,α和β表示模型參數,M表示訓練集大小,N表示輸入詞的數量。
模型生成主題和標注詞的LDA步驟如下所示:
(1)先對文檔切詞;
(2)隨機抽取主題;
(3)為所有在文檔中的詞選擇任意主題;
(4)確定第i個文檔的第j個詞所屬主題,重復操作(從所有詞中最終篩選得到的詞才稱為標注詞);
(5)得到文章-主題分布和標注詞-主題分布。
從圖1可知LDA的聯合概率為:
P(θ,z,w|α,β)=P(θ|α)C
(1)
(2)
其中,zn為抽取的主題,wn為生成的標注詞。
用LDA來標注圖像時,首先計算得到屬于測試集圖像的所有主題分布,再根據該分布確定圖像所屬的主題,最后由選中的主題得到圖像對應的標注詞的概率。
2.2 卷積神經網絡
卷積神經網絡逐層獲得圖像的高級視覺特征[14],越接近網絡的輸出層,圖像特征表示形式就越抽象,就越能獲得更豐富的高級視覺特征,對圖像的識別能力越強。
本文使用的是AlexNet網絡,它有以下優點:
(1)激活函數是修正線性單元ReLU(Rectified Linear Unit),解決了在較深網絡中Sigmoid可能會帶來的問題,表明ReLU在較深網絡中優于Sigmoid。
(2)在訓練時用Dropout隨機忽略一些神經元來解決過擬合問題,但是在預測時不使用Dropout。
(3)網絡結構中的競爭機制使泛化能力得到了增強。
(4)借助GPU的計算能力加快了網絡的訓練。
2.3 注意力機制
目前該機制被廣泛應用于文本生成[15]和圖像分類[16,17]等之中。例如,由Huang等[18]搭建的選擇性多模態長短期記憶網絡,借助可以對圖像的任意部分特別注意的功能,來調節標簽與特征之間的對應關系。由Zhang等[19]搭建的對抗哈希網絡,具有能捕獲部分多個模態信息的功能,能提高對內容相似性的度量性能。因注意力機制能模擬人類的視覺進行物體選擇,在輸出某個實體時會關注圖像的相應區域,本文同樣把注意力機制引入網絡中以獲得2個模態間的聯系。計算注意力的公式如下所示:
B=XW
(3)
(4)
E(Z)=aX
(5)

Figure 2 Modified convolutional neural network圖2 改進后的卷積神經網絡
其中,X=(x1,…,xn1)為n1維的輸入特征向量,W由隨機正態分布初始化得到且隨著網絡的訓練而改變,a=(a1,…,an1),Z為輸出。式(4)可以看成是對特征進行選擇,ai為第i個特征在所有特征中的權重,表示該特征的重要程度;式(5)對特征進行加權以選擇特征,調整注意力關注區域,因為該過程可導,即可訓練W。B表示不同特征的得分,借助式(4)進行正則化后與輸入結合,以得到每個特征的注意力大小。
2.4 標簽相關性
標簽往往不是單獨出現的,而是存在著某種看不見的聯系,如“房間”和“床”,分析并利用這種聯系能更精確地進行標注。并且,借助標簽相似性可以解決以往進行標簽標注時出現的一個標簽訓練一個分類器,所有分類器無法相互配合,導致實驗結果不是很理想的問題。
3 改進的卷積神經網絡
3.1 使用注意力機制與遷移學習的卷積神經網絡
本文使用的AlexNet模型[20]的結構共 11 層,因為其層次較多,需要大量圖像數據進行訓練才能得到較好的模型,因此對ImageNet[21]的訓練參數進行遷移學習[22]。首先把ImageNet中的全部圖像進行訓練后得到參數;然后訓練訓練集中的圖像來改變模型最末層的參數,同時對損失函數和網絡結構進行改進:把一個注意力層添加到該模型的最后的全連接層前,以標注多個標簽和獲得2個模態間的聯系,以及對類似圖像間的不同進行關注;最后使用改進的網絡進行訓練來對圖像進行標注。該網絡的初始化參數為:動量 0.5,衰減量 0.000 2,學習率0.001。改進的卷積神經網絡的結構如圖2所示。
3.2 損失函數的改進
研究人員通常把Softmax函數作為單標簽的損失函數來完成單標簽的標注,其定義如式(6)和式(7)所示:
(6)
(7)
為了計算樣本的全部損失以標注多個標簽,本文定義新的損失函數如式(8)所示:
(8)
其中,N1 表示圖像文本標簽的種類;ali表示圖像訓練樣本x對應的高層特征向量第i維的特征值;pi代表卷積神經網絡預測訓練樣本x屬于第i類標簽的概率;L表示交叉損失函數;yi表示訓練樣本x對應一個標簽時的標簽值(0或1);K表示訓練樣本x對應多個標簽類時標簽類個數;yji表示第i個訓練樣本對應多個標簽類時第j個標簽類的標簽值。
由于訓練集的標簽分布不均勻會導致模型對高頻標簽類預測的準確率大大超過低頻標簽類的準確率,所以需要平滑處理[23]高頻標簽類,即在高頻標簽類中加入噪聲,以提高低頻標簽類的預測準確率。先計算各個類的頻率系數并添加到損失函數中,如式(9)所示:
(9)
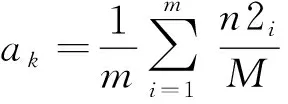
(10)
4 標簽相關性方法
首先把所有的已知標簽L1,L2,…,LD和所有訓練圖像M1,M2,…,MM組成一個矩陣K,Kij表示標簽Li是否在圖像Mj中出現,0和1分別表示未出現和出現的情況。K如表1所示,則2個標簽Li和Lj的相關性計算方法為:cij=ri·rj,其中cij表示2個標簽Li和Lj的相關性,ri和rj分別表示矩陣K的第i行和第j行,·表示向量點積。
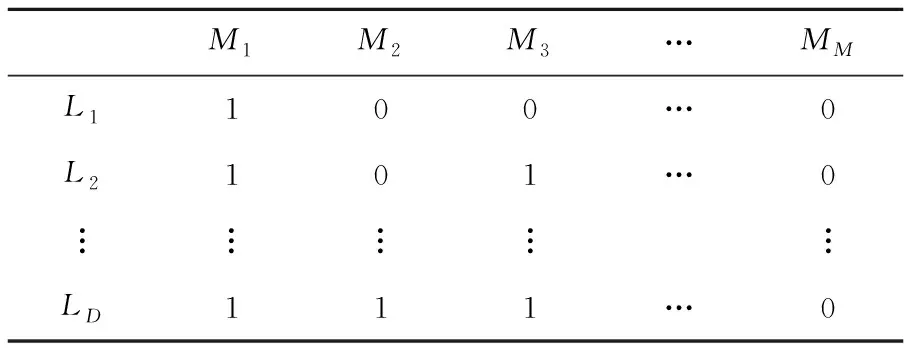
Table 1 Correlation matrix K
5 基于主題模型和半監督的圖像標注方法
首先利用LDA主題模型對圖像訓練集的文本進行建模,生成圖像訓練集標注詞分布,該過程充分利用主題模型的優勢,在降低圖像文本數據維度的同時避免了人工標注,不僅降低了圖像標注的人工成本,也節省了時間。但是,LDA模型生成的標注詞存在不夠精確且數量較多的問題,本文使用標注詞篩選和降維來解決這個問題。標注詞篩選和降維步驟如下所示:
(1)篩選:通過限制主題中詞的概率來進行標注詞篩選,規定只有主題中詞的概率大于某個閾值y時,該詞才能作為標注詞。
(2)降維:類似于特征降維,標注詞降維主要是解決標簽空間存在冗余信息的問題,即標注詞之間普遍存在的相關性,本文即利用標注詞的相關性進行降維,步驟如下所示:
①分別計算每2個標注詞在同一幅圖像中同時出現的次數,即可以得到相似性矩陣A。
②構建無向圖,每個節點對應一個標注詞,2個節點之間連線的權重為節點對應的標注詞在同一幅圖像中同時出現的次數,即相似性,如果沒有同時出現過,則無連線。
③從A中找到一個非零的最小值,同時在無向圖中把這個值對應的2個標注詞之間的連線斷開并且把該值歸零。
④從無向圖中尋找極大連通子圖,一個極大連通子圖包含的標注詞歸為一類,如果極大連通子圖的總數量少于需要的數量,重復③和④,直到極大連通子圖的總數量大于或等于需要的數量,停止操作,完成降維。
考慮到深度學習在圖像標注方面的優勢,本文采用卷積神經網絡提取圖像的高層視覺特征,又因為深度卷積網絡提取的有用特征易受背景等因素影響,而與無用特征混合在一起對圖像識別造成干擾,并且為了解決圖像間的微小差異會隨著層數的加深漸漸消失的問題,本文在卷積神經網絡的最后2個全連接層之間增加一個新的注意力層。同時改進損失函數,以完成多標簽標注,最后利用半監督學習將網絡的標注結果和標注詞的相似性結合起來完成圖像標注。本文的標注方法如圖3所示。
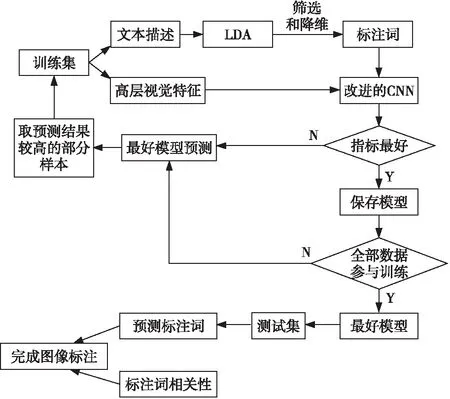
Figure 3 Semi supervised image annotation framework based on LDA and deep network圖3 基于LDA和深度網絡的半監督圖像標注框架
由圖3可知,本文的標注方法過程如下所示:
(1)借助LDA完成訓練集的文本降維,降維后仍然會存在標注詞精確性不高、數量較多問題,本文通過進一步篩選和降維來獲得待標注的標注詞。
(2)利用改進后的卷積神經網絡提取圖像的高層視覺特征,由于該卷積神經網絡使用了遷移學習和注意力機制,提取到的高層視覺特征比傳統手工特征更加全面,利用圖像的高層語義特征及其對應的標注詞來訓練模型。
(3)把數據集分成訓練集和測試集,考慮到樣本可能不足的問題,使用半監督學習的方法首先對訓練集的圖像的高層視覺特征和對應的標注詞進行訓練,記錄下模型的評價指標。然后利用該模型對測試集進行預測,選擇準確率較高的一部分測試集樣本放入訓練集中再次進行訓練,如果此次評價指標優于當前的最好指標,則保存該模型并且繼續用該模型對測試集進行預測,選擇準確率較高的一部分測試集樣本放入訓練集中再次進行訓練;否則減少從測試集放入訓練集的樣本數量的同時用已保存的評價指標最好的模型開始重新訓練,當訓練集的大小等于數據集的大小時停止訓練。
(4)計算所有圖像標注詞個數的平均值h,選擇評價指標最大的模型為最終模型并對測試集進行預測,選擇概率最大的前h個標注詞構成預測的標簽集合。
(5)把集合中的每個預測標簽和其他標簽的相關性與所有兩兩標簽之間的相關性的平均值比較,當相關性大于平均值時把未預測的標簽加入預測標簽的集合中,當相關性小于平均值但標簽存在于集合時,把對應標簽去除。把預測結果與標注詞的相關性結合后可以得到一個標簽集合,該集合即為最終的標注結果。
6 實驗與結果分析
6.1 實驗設置

6.2 實驗參數設置
首先對閾值y和標注詞種類Q進行討論。本文對Q以步長為10進行取值,對y以步長為0.01進行取值,同時以F1的值作為實驗的對比指標。由圖4可知,當Q為80時,F1值達到最大;由圖5可知,當Q為80時,F1值達到最大。所以,本文將Q設為80,將y設為0.02。

Figure 4 F1 values corresponding to different topic numbers圖4 不同主題數對應的F1值

Figure 5 F1 values corresponding to different thresholds y圖5 不同閾值y對應的F1值
6.3 實驗結果
首先將本文方法的模型與采用較傳統方法的JEC模型[7]相比較;然后與TagProp-ML[24]和2PKNN模型[25]相比較;同時與ANNOR-G(Automatic image aNNOtation Retriever-Global features)模型[26]、特征融合與語義相似度FFSS (Feature Fusion and Semantic Similarity)模型[27]比較;最后與使用了深度卷積神經網絡的CNN-R模型[9]和CNN-MSE[10]模型、CNN-LDA[12]模型、CNN-MLSU(CNN using Multi-Label Smoothing Unit)模型[28]和LNR+2PKNN[13]模型進行實驗對比。實驗結果如表2所示。
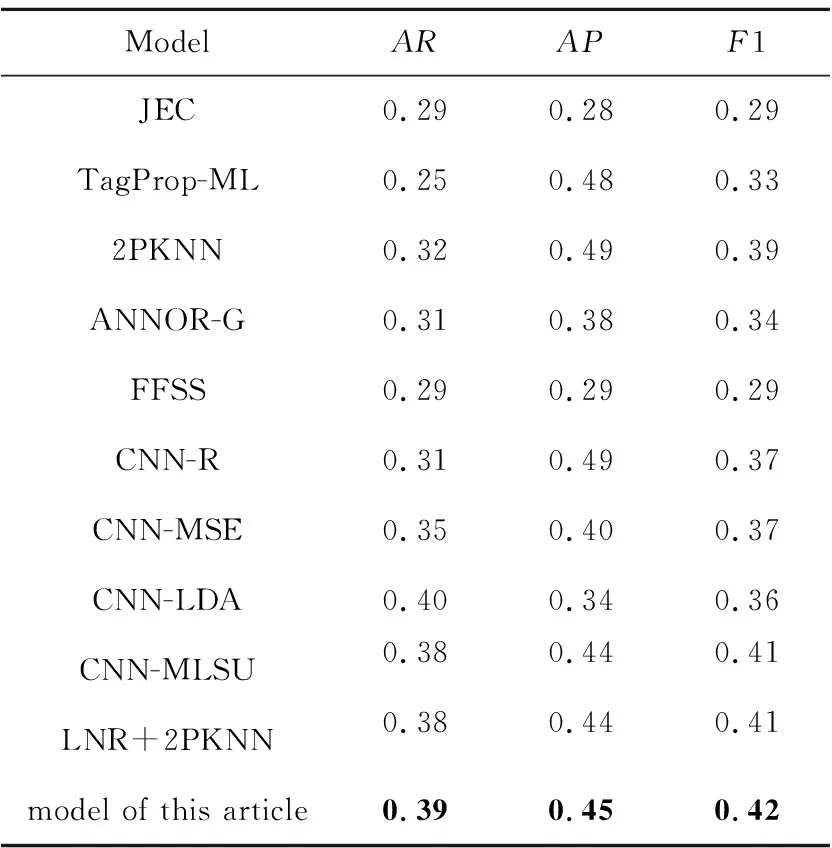
Table 2 Comparison between our models and other annotation models
通過表2可以看出,在同一圖像集上,本文模型的結果相對于傳統的標注模型有較大提高。在同一圖像數據集上,平均召回率相對于JEC 提高了10%,相對于 TagPro-ML 提高了14%,相對于2PKNN 提高了7%。平均準確率相對于JEC的提高了17%,但低于TagProp-ML 和2PKNN 的。對比較為先進的ANNOR-G 模型和 FFSS 模型,本文模型的各項指標都有提高。
通過與使用了卷積神經網絡的模型進行比較,可知本文模型的平均召回率只低于最高的CNN-LDA模型1%,但其平均準確率遠高出它。平均準確率小于CNN-R的,但其F1高出5%。本文模型的F1不低于所比較的任何模型,通過本文模型和其他模型在同一數據集上的比較結果可知,本文模型在平均召回率上表現良好,但在平均準確率上不是很好,總的來看本文模型相對于大部分模型都有所提高。提高的原因有以下幾點:首先,因注意力機制對特征進行選擇,使網絡其模擬視覺且不再只關注全局,更易獲得2種模態間的聯系;其次,利用改進的損失函數能夠提高低頻詞的準確率;最后,使用半監督方法進行訓練能夠充分利用樣本。
此外,為檢驗加入噪聲對低頻標簽類的標注影響,把加入噪聲前后低頻標簽類的平均準確率AP、平均召回率AR進行對比,該數據集有55個低頻標簽類,實驗結果如表3所示。
由表3可知,加入噪聲能防止模型過擬合,在幾乎不影響高頻標簽類的標注下,極大提高了低頻標簽類的標注準確率。
7 結束語
本文利用主題模型在文本處理方面的優點來完成對文字數據的降維,同時更改AlexNet模型的網絡結構和損失函數來更好地進行多個標簽的訓練和預測,并把模型的預測和標簽間的相似性進行結合來提高準確率。由對比實驗可知,本文方法的標注更精確。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
