深度交流學習模式
2022-02-07 09:20:18張仁斌周澤林左藝聰
智能計算機與應用 2022年12期
張仁斌,王 龍,周澤林,左藝聰,謝 昭
(1 合肥工業大學 計算機與信息學院,合肥 230601;2 合肥工業大學 大數據知識工程教育部重點實驗室,合肥 230601;3 合肥工業大學 工業安全與應急技術安徽省重點實驗室,合肥 230601)
0 引言
基于知識傳遞的知識蒸餾和參數遷移學習分別被廣泛使用于模型壓縮[1-2]和遷移學習[3]領域中,本文的目標是基于知識傳遞實現網絡間的交流學習,使網絡學習更加快速和充分。
盡管復雜龐大的網絡具有很高的性能,但是計算緩慢和網絡龐大不利于存儲的不足使其難以滿足在便攜設備上的應用需求。模型壓縮是解決這個問題的方法之一。Hinton 等 人[4]通過知識蒸餾(Knowledge Distillation,KD),首先利用大規模數據訓練一個大模型作為教師網絡,然后將小模型學生網絡向大模型學習,知識從教師網絡傳遞到學生網絡上,以此得到的小網絡也具有大網絡相當的泛化能力,實現模型壓縮。
在知識蒸餾的研究中,Zagoruyko 等人[5]提出將注意力作為知識從一個網絡轉移到另一個網絡中的學習方法,并且與將教師網絡的輸出作為學習對象的知識蒸餾方法進行結合。Chen 等人[6]提出交叉樣本的相似性作為網絡間可轉移的知識,并在多個圖像任務中進行驗證,轉移這種知識使行人識別任務相對基線取得明顯提升。Cho 等人[7]進一步探索知識蒸餾的有效性,得出了教師網絡的效果越好并非意味著學生網絡效果就會越好的結論,這與Mirzadeh 等人[8]的實驗結論相同。Heo 等人[9]將隱藏層特征作為知識進行蒸餾,并在圖形分類、檢測和分割三種任務上進行實驗,驗證了特征蒸餾的有效性。不同于分類任務,Saputra 等人[10]在回歸任務中成功應用了知識蒸餾。Phuong 等人[11]從多個角度解釋了為什么知識蒸餾能夠成功地將知識在網絡間進行轉移。近期,Facebook 團隊提出的Deit[12]方法,探索了使用多種其他類型的網絡來對圖像分類網絡ViT[13]進行注意力的教學,達到了非常理想的效果。Deit 方法中,在訓練時將基于Transformer[14]的ViT 作為學生網絡,將其他類型的網絡,如以CNN 為基礎的ResNet[15]、EfficientNet[16]作為教師網絡,借鑒知識蒸餾的方法,通過將學生網絡和教師網絡的輸出計算損失值并進行反向傳播,實現將知識從教師傳遞給學生,以此顯著提高作為學生的ViT 網絡的性能。實驗結果表明,相對于需要在大量數據集上進行預訓練的ViT,Deit 不需要額外的數據做預訓練,且用更少的計算資源生成更高性能的圖像分類模型。Deit 通過將不同網絡的知識進行傳遞,達到很好的學習效果。Lu 等人[17]分別在高分辨率和多分辨率模型中運用知識蒸餾提煉知識,通過交叉特征融合和多尺度訓練等方式獲得了更優的學生分辨率模型。Chen 等人[18]把神經網絡實例的特征和節點的關系作為編碼知識從教師網絡傳遞給學生網絡,在物體檢測的任務中取得了更好的模型效果。
把網絡的參數作為知識進行轉移也有著非常經典的應用。Pan 等人[3]將源領域中模型的參數遷移到目標領域的模型中的方法歸類為參數遷移(Parameter-transfer)學習。Fan 等人[19]將少樣本檢測任務上學習到的知識遷移到檢測模型的最后一層,檢測效果相對基線得到了穩定的提高。Jing 等人[20]通過知識參數遷移,把多個教師圖神經網絡的知識傳遞給同一個學生圖神經網絡,以此得到的學生網絡在多個任務上取得了與教師網絡相當的效果。在Mean Teachers[21]中,教師網絡通過將學生網絡的參數進行組合得到教師自身的網絡參數,以此實現知識從學生網絡向教師網絡的傳遞。
Mean Teachers 作為半監督的學習方法,同樣包括了教師網絡和學生網絡兩種結構。其中,學生網絡的參數是通過梯度下降進行更新,而教師網絡的參數則是僅僅通過組合學生網絡所學到的知識參數進行更新,而不進行梯度下降。在Mean Teachers中,知識通過網絡參數的形式從學生網絡流向教師網絡。進一步地,教師網絡的輸出結果作為學生網絡的學習目標,進行對學生網絡的教學。
深度互助學習[22](Deep Mutual Learning,DML)中,K個網絡中每一個網絡既有學生的身份,也有教師的身份。當對其中某個網絡傳遞知識時,其他所有K -1 個網絡都作為教師。在每一輪互助中,每個網絡都會接收到其他K -1 個網絡傳遞的知識。在知識蒸餾的方法中,小的學生模型通過將大的教師模型輸出作為學習的軟目標計算交叉熵進行梯度下降,進而完成知識從大模型向小模型的傳遞。DML 不以模型壓縮為目的,而是通過將學生網絡與其他K -1 個教師網絡的輸出結果的KL散度(Kullback-Leibler divergence,KL)取均值,并作為損失的一部分進行反向傳播,依托多個網絡輸出結果的互相借鑒,以此達到更高的魯棒性,實現共同進步。
利用知識蒸餾可以加快小模型的訓練速度和效果,但是具有一定的局限性。比如蒸餾的前提是擁有一個性能足夠好的教師網絡,且蒸餾的主要目的在于更好地訓練出一個小模型,并不能夠提升教師網絡自身的性能。DML 中每個網絡都會利用其他網絡的知識來提高自己,但是DML 中實現互助的方式是利用網絡之間的差異度作為損失值進行梯度下降,模型性能受梯度下降方法局限性的影響,如梯度消失和梯度爆炸等導致互助失敗。
針對以上問題,本文提出一種基于深度交流學習(Deep Communication Learning,DCL)的網絡訓練模式。在DCL 中,多個神經網絡在各自獨立學習的同時將網絡參數作為知識進行交流,單個神經網絡在訓練中將自身所學到的知識分享給其他網絡,同時從其他網絡上吸納一定比例的學習成果,獨自學習和在集體中的知識交流是交替進行的。
DCL 和Mean Teachers 都將網絡所學到的參數作為知識,并將這些知識進行傳遞。不同的是,Mean Teachers 中教師網絡的目的在于對無標簽數據進行標記,且最終學生網絡向教師網絡的學習方式同樣類似于知識蒸餾,是通過計算學生網絡和教師網絡輸出結果之間的差異度進行反向傳播實現的。Mean Teachers 中教師網絡和學生網絡的主體是固定的,而DCL 中每個網絡既會作為知識的傳授方,也會作為知識的接收方,這些網絡的身份是等同的,并且DCL 各個網絡間互相學習的策略與Deit 和DML 完全不同。Deit 和DML 借鑒知識蒸餾,以教師模型的輸出結果為目標,讓學生向教師模仿和學習,而DCL 則是將各個網絡所學到的網絡參數作為知識進行吸納和融合,交流的過程不使用梯度下降,而是對所學知識的直接交流。
本文利用經典、成熟的圖像分類神經網絡來驗證所提出的學習模式,使用Inception[23],ResNet,WRN[24],DenseNet[25],MobileNet[26],ResNeXt[27]和EfficientNet 等7 種經典網絡在Fashion-MNIST[28],CIFAR-10 和CIFAR-100[29]等多個數據集上進行實驗。結果表明,利用DCL,這些網絡獲得了學習效果最高3.44%的提升。
論文內容安排如下:本文第1 節提出了一種基于知識交流的深度神經網絡學習方式-DCL,并對該方法進行了詳細說明;第2 節通過使用多種網絡和數據集對DCL 進行了實驗,驗證了DCL 學習模式的有效性;第3 節對全文進行總結并展望未來工作。本文將代碼和模型進行了開源[30]。
1 深度交流學習
深度交流學習模式如圖1 所示。深度交流學習是對人類社會學習進步的一個仿照。正如人類在個體單獨學習后進入集體進行知識的交流,并經獨自的學習把從集體獲得的知識進行消化和吸收,利用集體的知識提高自己,同時在獨自學習中探索和獲取新的知識,再于此后的交流中對其進行分享。
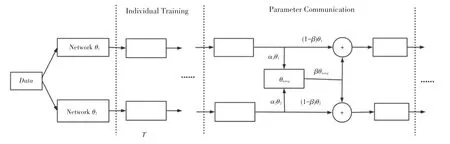
圖1 深度交流學習模式Fig. 1 The process of Deep Communication Learning
網絡學習到的知識存在于網絡的參數之中,讓深度神經網絡在學習的同時進行知識的交流是深度交流學習的核心。DCL 的具體策略是,網絡在獨自學習一定的迭代輪次T后,各個網絡把自己學習到的知識貢獻到集體中,并以一定的比例βi收納來自集體的知識。隨后各個網絡再獨自學習一段時間T,以適應和吸收集體的知識經驗,再獨自探索新知識用于下次和其他網絡的交流。DCL 用這樣的方式讓所有網絡不斷地在互相交流中進行學習和進步。
即使是同一類型的網絡,不同的初始化參數也會使網絡變得互不相同。雖然數據集和網絡結構都一樣,但是額外的知識存在于不同的初始化參數之中。針對于Independent 學習中網絡知識量有限的問題,DCL 模式中采用知識交流的方法,支持每個網絡擁有額外的知識量。
1.1 網絡交流方式
設DCL 中的網絡初始化數量為K,此K個網絡表示為:θ1,θ2,……,θK。設具有N個樣本且分為M類的數據集為:
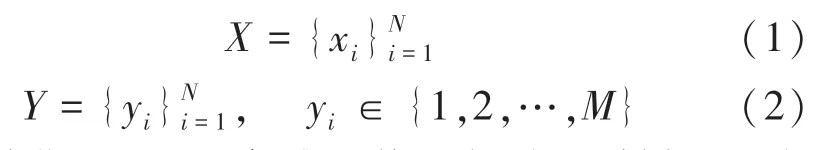
初始化DCL 后,每個網絡進行隨機采樣和反向傳播學習。在經過T次獨自學習的迭代后,所有網絡進行一次知識交流。交流中,每個網絡首先將自己所學的參數知識以αi的比例貢獻到集體中,并存儲于θwavg中。對此過程可用式(3)進行描述:
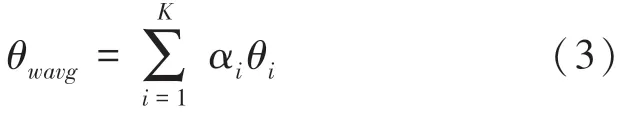
其中,對于每個網絡所貢獻的比例,具有以下約束:

然后,每個網絡從集體的知識中吸納比例為β的知識量,實現總體網絡的知識向每個網絡的傳遞:
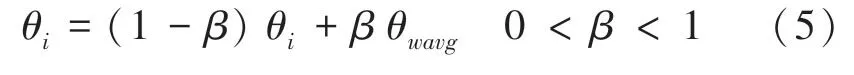
對于個體向集體貢獻的知識量比例αi數值的確定,本文借鑒正則化(regularization)的思想,即如果網絡參數的絕對值|θi |越小,則讓其對集體貢獻更大比例的知識,從而讓這些網絡在表現效果相當的情況下,更多地向參數小的網絡學習,以此增加自身的魯棒性。本文采用的策略是令貢獻的比例與自身參數的絕對值大小成反比,即:

根據式(3)~(5),可以得出每次交流中單個網絡的參數對總體的貢獻比例為:
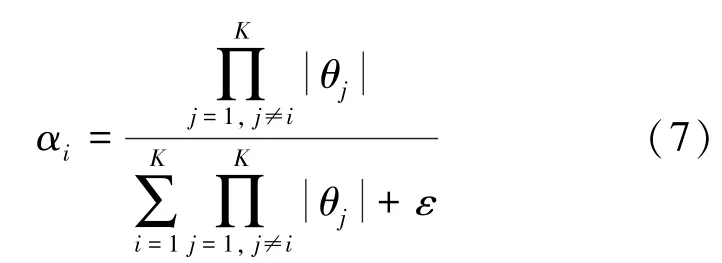
其中,ε為一個極小數,用來避免當網絡某層的參數全為0 時出現分母非法的情況,在實際使用中,本文對ε的取值為1×10-18。
1.2 深度交流學習流程
算法1 描述了DCL 的具體流程。
算法1Deep Communication Learning

代碼中,E為訓練的總迭代次數,E和學習率衰減策略的具體設置見本文的2.3 節。
在本算法中,T的設置是關鍵之一,因為來自于其他網絡的知識參數,未必會在吸納后立即就能很好地適應自身的網絡參數。因此,如果讓網絡一直交流而不給予足夠的獨自學習和適應時間,很容易會出現這些網絡由于無法適應其他網絡的知識參數,而一直處于欠擬合狀態。
單個網絡每次從集體中吸納的知識比例β是一個超參數。如果β的取值過小,會使網絡向集體學習的知識量很少,這種情況下一方面會相對保持網絡的獨特性,即網絡之間不會非常相像,另一方面會降低交流學習給網絡所帶來的收益。在β取極值為0 時,網絡之間停止交流,個體不再向集體學習。同樣,如果β的取值過大,則會使網絡之間隨著交流次數增多而變得更加相像,在一定程度上喪失自身的獨特性。因此將β取一個適當大小的值是非常重要的,本文第2 節實驗中將0.1 作為β的取值。
2 實驗
本文使用多種網絡在多個數據集上進行實驗,所有源代碼、模型和實驗結果均已開源[30]。
2.1 數據集
本文使用3 個數據集進行實驗。CIFAR-10 和CIFAR-100 數據集由大小為32×32 的RGB 圖像組成,分別包含10 個和100 個類別的物體。兩者都被劃分為50 000 張圖像作為訓練集和10 000 張圖像作為測試集。Fashion-MNIST 是一個包含10 種服飾類別的圖像數據集,圖像大小為28×28,并且以60 000張圖片作為訓練集,10 000 張圖片作為測試集。本文將圖像分類的正確率作為這3 個數據集的評價指標。
2.2 網絡
本文使用7 種具有不同原理和參數量大小的經典神經網絡進行實驗。包括經典卷積網絡Inception-V1 以及深度殘差網絡ResNet-18,以及以殘差為基礎進一步發展而來的WRN-16-4、DenseNet-121 和MobileNet-V2。作為ResNet 和Inception 的結合,ResNeXt-50 也被用在本文的實驗中。兼顧速度與精度的EfficientNet-B3 在圖像分類領域有著優秀的表現,本文也采用這個網絡作為實驗對象之一。
2.3 實驗設置
本文使用PyTorch 實現了所有網絡,并且以NVIDIA Tesla V100 GPU 作為加速進行實驗。實驗采用Nesterov 動量設置為0.9 的SGD 作為模型優化器,batch size設置為128,并且設置了0.000 1的L2正則損失。在訓練時,對于在ImageNet 進行過預訓練的模型,學習率被初始化為0.001,而沒有預訓練過的模型,學習率被初始化為0.1。學習率每迭代60 個epoch會衰減為原來的0.1,并且200 個epoch被作為訓練的總迭代次數。實驗中,數據增強方法包括對圖像的隨機翻轉和每邊填充4 個像素后進行的隨機裁剪,裁剪后缺失的像素被填充為0。
2.4 實驗結果與分析
表1~表3 分別比較在3 個數據集上多種網絡在K =2 時,通過Independent 學習和DCL 學習達到的Top-1 正確率。結果分析表明:
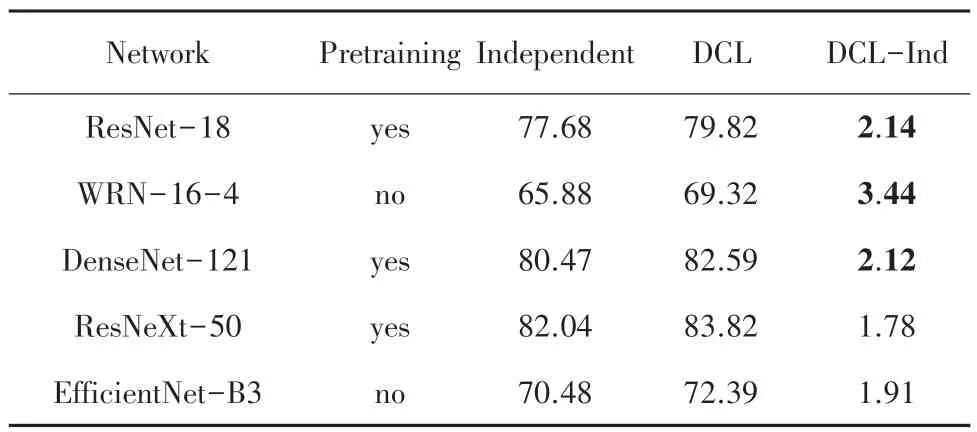
表1 CIFAR-100 數據集K=2 的Top-1 正確率Tab.1 Top-1 accuracy for CIFAR-100 dataset when K=2 %
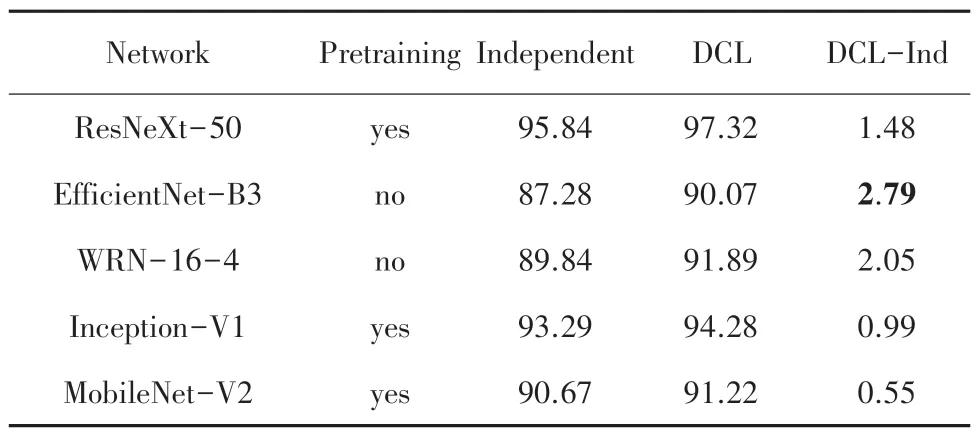
表2 CIFAR-10 數據集K=2 的Top-1 正確率Tab.2 Top-1 accuracy for CIFAR-10 dataset when K=2 %
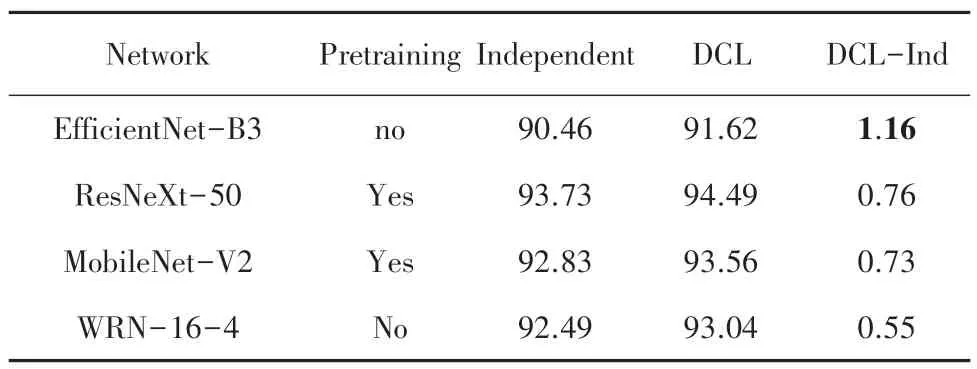
表3 Fashion-MNIST 數據集K=2 的Top-1 正確率Tab.3 Top-1 accuracy for Fashion -MNIST dataset when K=2%
(1)相對于Independent 學習,所有這些網絡都可以通過DCL 來提高自己的學習效果,這些提高體現在DCL-Ind 一列中的數據都是正數。
(2)沒有經過預訓練的網絡結構,通過DCL 則更顯著地提升了學習效果。3 個數據集上最大的提升都來自于WRN-16-4 和EfficientNet-B3 這2 個未進行預訓練的網絡,分別是3.44%,2.79%和1.16%。
(3)相對于單通道且圖片尺寸更小的Fashion-MNIST,DCL 的學習方式在三通道且圖片尺寸更大的CIFAR 數據上對學習效果的提升更加明顯。
在DML 中,本文通過使用KL散度作為損失的一部分,讓不同網絡的輸出更集中(不離群),而讓網絡各自都取得更好的學習效果。DML 能夠生效的原因是這種方式使輸出結果更加集中,提高網絡的魯棒性。在蒸餾學習中,通過讓小網絡把大網絡的輸出做軟目標進行學習,實現大網絡向小網絡的知識傳遞。在Deit 中,通過讓ViT 網絡在某些層的輸出向和卷積網絡或者混合學習,實現把知識向ViT 的傳遞,因而讓ViT 在圖像分類中取得了更加優秀的表現。
本文DCL 模式中,不同網絡通過分享一部分權重來進行知識的溝通,在一定程度上使得這些網絡的最終輸出更加集中、即不離群,也有利于網絡獲得更高的魯棒性。
圖2 和圖3 比較EfficientNet-B3 和ResNet-18使用不同數量的網絡進行DCL 學習的結果。學習效果對比表明:
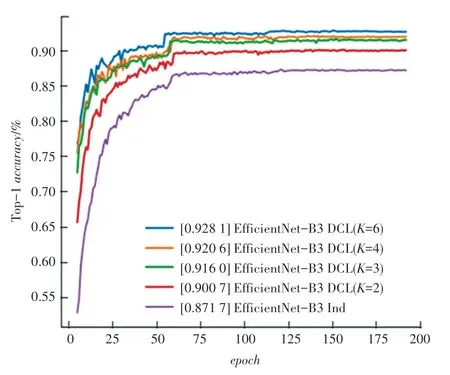
圖2 CIFAR-10 上EfficientNet-B3 使用不同數量網絡進行DCL學習的Top-1 正確率結果Fig. 2 Top-1 accuracy of DCL learning using different number of networks for EfficientNet-B3 on CIFAR-10
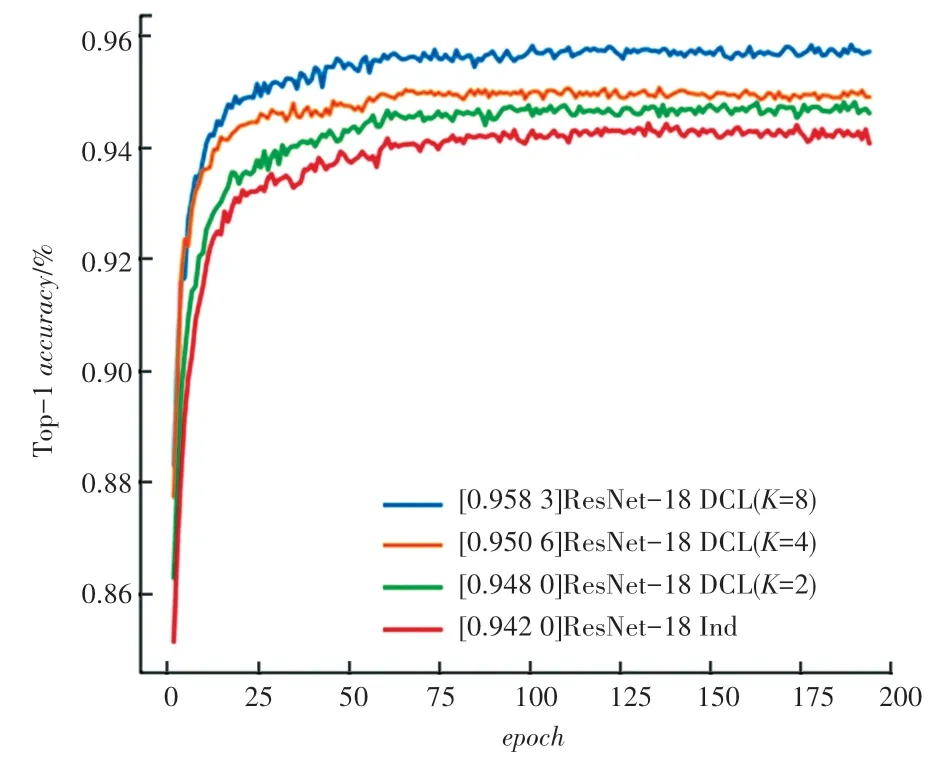
圖3 CIFAR-10 上ResNet-18 不同數量網絡進行DCL 學習的Top-1 正確率結果Fig. 3 Top-1 accuracy of DCL learning using different number of networks for ResNet-18 on CIFAR-10
(1)DCL 的正確率曲線總是高于Independent的正確率曲線,表明在相同的迭代學習次數下,DCL比Independent 學習得更加充分,并且在訓練結束后,DCL 達到了Independent 所沒有達到的學習效果。
(2)K的值越大,圖中的正確率曲線就處在更高的位置,表明增加進行交流和溝通的網絡個數K,將提高整體的學習效果。在DCL 中,進行交流的學習者越多,集體會傾向于取得更加優秀的學習表現。
3 結束語
本文提出了一種讓深度神經網絡在學習中進行互相交流的訓練模式,利用經典、成熟的圖像分類神經網絡對所提出的學習模式的驗證結果表明,該模式使多種深度神經網絡的學習效果獲得了明顯提高。利用DCL,深度神經網絡學習的效果更好。實驗結果證明了DCL 模式對多類神經網絡都有效,且增加交流的網絡個數,能進一步提高學習效果。未來的工作將對分布式訓練的交流方式進行探索,以提高多個網絡進行交流訓練的時間效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科教新報(2022年12期)2022-05-23 06:34:16
快樂語文(2021年27期)2021-11-24 01:29:04
今日農業(2021年14期)2021-10-14 08:35:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海峽姐妹(2020年8期)2020-08-25 09:30:18
數學物理學報(2020年2期)2020-06-02 11:29:24
甘肅教育(2020年22期)2020-04-13 08:11:16
福建基礎教育研究(2019年3期)2019-05-28 23:14:43
光學精密工程(2016年6期)2016-11-07 09:07:19
