融合多策略的中文科技文獻機構名稱規范化研究與實踐*
2022-02-13 11:09:06孫月萍
醫學信息學雜志 2022年12期
關鍵詞:規范化
劉 燕 孫月萍 侯 麗
(中國醫學科學院/北京協和醫學院醫學信息研究所 北京100020)
1 引言
面對日益激增的海量數字化文獻資源,如何利用規范化的機構體系對文獻資源進行整合、挖掘、分析等一直是學界關注的重點[1]。近年來,學界加強了對機構規范文檔[2-3]、機構知識庫[4]等的構建與應用研究,從機構名稱統一標識[5]、機構類別特征化[6]、機構名稱相似度計算[7]等角度,推進規范化機構在各種服務場景中的應用。機構作為科技文獻的重要組成元素之一,是開展科研評價、信息檢索、學術資源組織與關聯的基礎。但現實中文獻機構名稱著錄混亂、層級結構模糊、更名、重組、合并、拆分等現象頻繁,加之名稱存在縮寫、簡稱、書寫不規范等問題,導致機構名稱識別度降低,各類數據庫和搜索引擎很難準確統計機構對應的資源數量[8],從而影響統計分析和評價結果的可靠性[9]。因此為有效整合并利用機構實體不同名稱下的信息資源[10],進行機構名稱規范化的研究與實踐至關重要。
機構名稱規范一般是指通過收集機構實體的所有表現形式,實現多個機構名稱到一個機構實體的映射[11]。對于科技文獻中的機構名稱規范研究而言,其核心問題是提取“作者單位”著錄項中的機構名稱,并進行機構名稱的消歧,使同一機構實體的不同名稱表現形式都指向一處。學者們據此開展諸多研究,取得較好效果,然而還無法有效解決表達形式差異較大的機構名稱規范問題,如“北京安貞醫院”與“首都醫科大學第六臨床醫學院”。對此,有學者通過發文著者共現情況來判斷機構名稱的相似度[12-13],取得了一定效果,但未考慮不同類型機構的差異。鑒于此,本文嘗試從“機構-作者”共現和機構類型特征詞的角度,進行機構名稱的規范化研究,分析不同類型機構名稱的命名特點,并結合機構共現作者和相似度計算方法進行中文機構名稱的消歧,最后以醫學領域機構為例進行實踐。
2 常見機構名稱規范化方法
機構名稱的規范化建設經歷了規范控制、訪問控制、唯一標識符等階段。其中,規范控制是為各機構設置一個規范名稱并將其他名稱都指向它,缺點是檢索其他名稱時只能獲取包含該名稱的資源;訪問控制則不設置規范名稱,而是將所有名稱都加入一個可訪問的白名單中,檢索任意名稱都能獲取全部資源,但多次檢索會加重系統負擔[14];國際標準名稱識別碼[15](International Standard Name Identifier, ISNI)、Ringgold標識數據庫[16]等希望通過唯一標識符來實現機構的唯一識別,但由于目前并未形成統一的全球化方案,在文獻數據中的應用程度還較低,因此利用唯一標識符解決機構實體的歧義問題更多是愿景和輔助手段[14]。常見機構名稱規范化方法主要有基于字符串相似度的方法、基于規則的方法、基于統計關聯的方法和混合策略的方法。
2.1 基于字符串相似度的方法
基本思路是利用字符串相似度計算的方法判定機構名稱相似性程度。常用方法包括Levenshtein編輯距離[17]、Cosine相似度、Jaccard相似度等。有學者[18-19]基于字符串編輯距離的方法構建機構名稱規范文檔。Ferosh J[20]利用Levenshtein編輯距離方法對求職簡歷中求職者機構名稱進行規范。Jiang Y等[21]基于歸一化的壓縮聚類方法實現對同一機構不同名稱的聚類。
2.2 基于規則的方法
主要思想是基于建立的規則庫對錯誤匹配對進行過濾。有學者[22-23]根據機構名稱的特點,提出基于規則的機構名稱消歧方法,并在Web of Science不同學科數據集中進行有效性測試。沈嘉懿等[24]針對網絡文本數據提出基于規則識別中文組織機構名稱的方法,借助機構后綴詞庫、規則匹配和貝葉斯模型識別機構邊界。
2.3 基于統計關聯的方法
基本思路是利用Web大規模語料,通過計算不同機構名稱字符串搜索結果中統一資源定位符(Universal Resource Locator,URL)的共現情況來判定機構名稱相似度[25]。Aumueller D等[26]基于谷歌和雅虎搜索返回的前k個URL共現重疊情況來計算兩個機構名稱匹配程度。
2.4 混合策略的方法
主要思想是通過整合兩種或兩種以上的方法,來實現更高的機構名稱識別精準度。楊瑞仙等[27]提出一種基于規則和向量空間模型的科研機構名稱識別方法。孫海霞等[9]提出一種基于規則和編輯距離的機構名稱匹配策略,并以中文生物醫學文獻數據庫為例進行實踐。張建勇等[14]基于規則和相似度計算的方法對國家科技圖書文獻中心內的科研機構實體進行消歧,以便構建科研合作網絡等。
3 中文科技文獻機構名稱規范化處理流程
本研究以中文科技文獻中的機構為例開展名稱規范化研究。設計中文科技文獻機構名稱規范實現流程,包括數據采集、機構名稱提取和機構實體消歧3個步驟,見圖1。
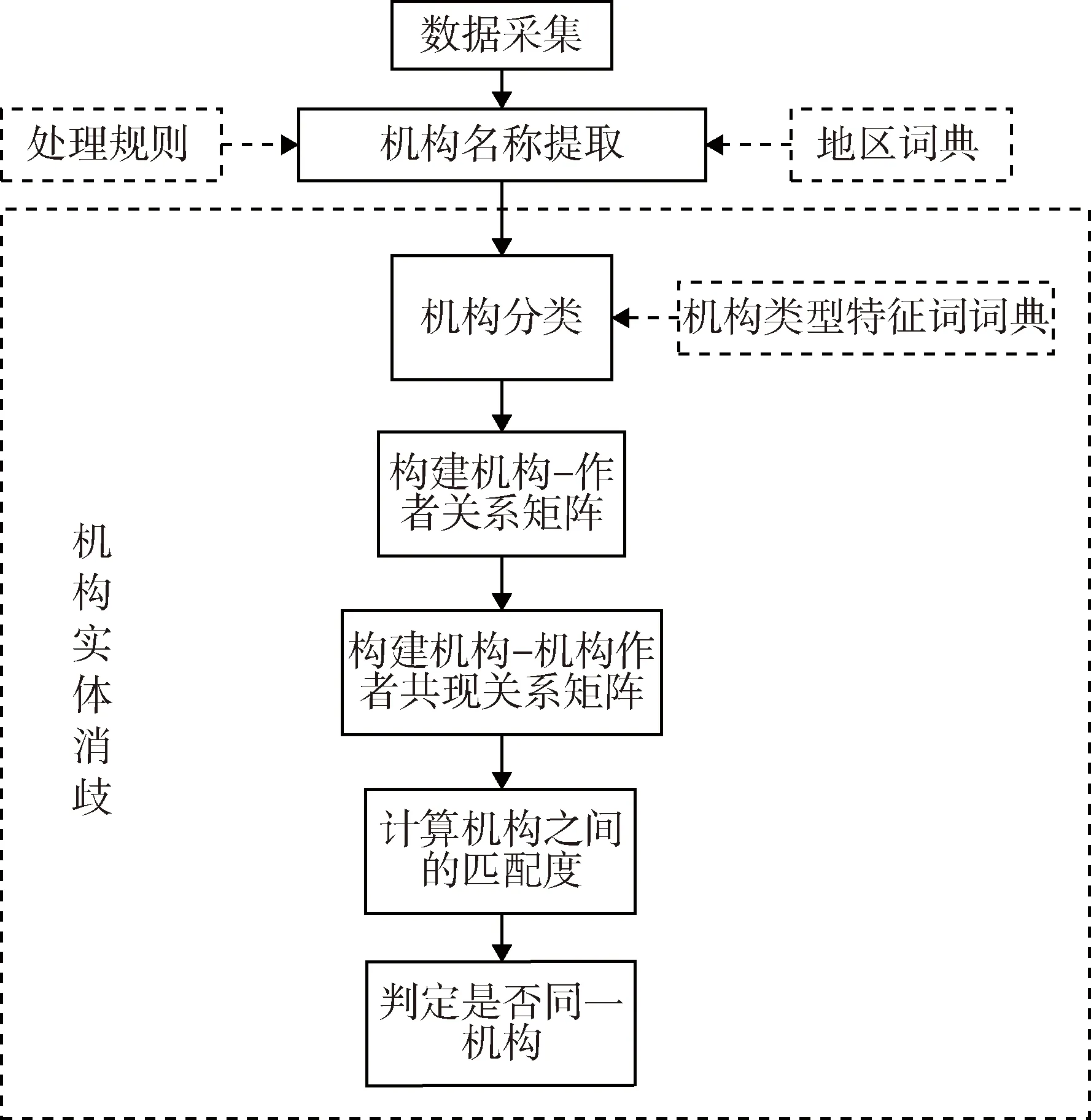
圖1 中文科技文獻機構名稱規范化處理流程
3.1 數據采集
科技文獻來源包括數據庫商、出版商、服務商等,不同來源的數據描述粒度不同,數據質量也有所差異。本研究制定數據采集方案如下:根據數據質量、權威性等采集要求,確定采集來源、時間范圍、期刊等;確定需要采集的字段項,如題目、作者、機構著錄項等;利用爬蟲軟件進行數據采集,完成格式轉換與存儲;制定規則對不完整數據和重復數據進行處理,將缺少文獻題目、作者、機構等關鍵字段的數據直接剔除,刪除重復數據中字段項較少的,判定重復數據的條件為兩篇文獻DOI是否一致或題目、作者和期刊3項信息是否完全相同。
3.2 機構名稱提取
3.2.1 概述 機構名稱在科技文獻中的表述形式多樣,存在問題主要包括兩點:機構合作客觀存在,且1位作者可能會隸屬于多個機構,故1篇文獻可能會存在多個機構的現象(簡稱多機構);機構著錄項標注形式不統一,且不同期刊對機構著錄項要求不同,如郵編位置、是否標注機構所在國家、機構是否為獨立法人等。鑒于此,本研究將利用字符串匹配、詞典和規則過濾的方法進行規范化機構名稱提取。
3.2.2 多機構拆分 將包含多個機構的數據拆分為多條數據,確保1條數據只包含1個機構及其對應的作者,便于統計機構發表的文獻及隸屬于機構的作者。拆分方法是先利用字符串方法找到機構著錄項之間的分隔符,并以分隔符為邊界完成機構拆分。
3.2.3 機構著錄項拆分與過濾 對單機構的機構著錄項進行拆分并過濾郵編、行政區劃地址等信息,以獲取作者原始著錄的機構名稱信息。(1)機構著錄項拆分。以逗號或空格為分隔符對機構著錄項包含的字段進行拆分,考慮到機構名稱長度至少為4,可直接過濾掉長度小于4的字段。(2)郵編和行政區劃地址過濾。判斷剩余的字段是否為郵編和行政區劃地址,若是則直接刪除。其中,郵編可使用字符串編輯的方法處理,若該字段由6位連續的數字組成,則判定為郵編;行政區劃地址可通過構建國內各省市地區字典來處理。
3.2.4 機構名稱規范化提取方案 本研究的規范化機構名稱是指法人級別的機構,因此要對部門、科室等二級機構名稱進行識別并刪除。通常,中文機構名稱以“A+B”的形式表達,A部分一般由方位詞、序數詞、動詞等構成,B部分一般為“大學”“研究所”“醫院”等用來表示機構特征的中心語,故可以通過B部分來判定機構名稱是否已規范至法人級別。本研究設計面向中文科技文獻機構名稱規范化提取方案包括:(1)機構名稱分詞。構建機構名稱詞庫,利用中文分詞工具Jieba對機構名稱進行分詞,得到A和B 兩部分。(2)構建機構特征詞表。結合國家機構類型分類標準《組織機構類型(GB/T 20091—2006)》,將機構分為科研機構、高等教育機構、醫療機構、事業單位、行政機構、公司企業、社會團體、其他8類,進而利用中文機構名稱的命名特點,構建機構類型特征詞表。(3)識別機構名稱著錄深度。依次比較機構名稱的B部分與機構類型特征詞表有無匹配項,若有匹配項則不作處理,若無匹配項則表明該字段包含二級機構名,應從右至左依次遍歷分詞列表,直到匹配到正確的機構中心語,并將中心語右側的二級機構名刪除,得到規范的一級機構名稱,見圖2。
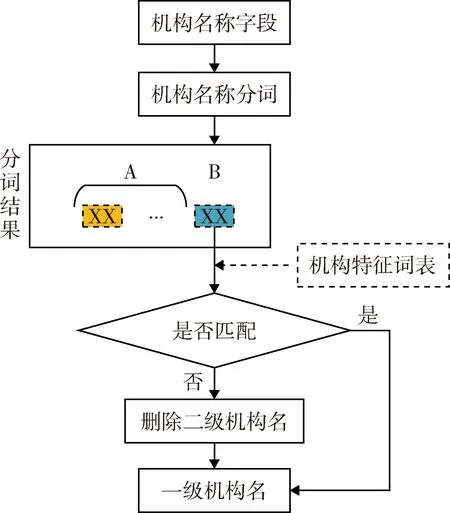
圖2 中文科技文獻中的機構名稱規范化提取方案
3.3 機構實體消歧
3.3.1概述 可用于機構實體匹配的文獻特征有機構名稱、行政區劃地址、郵編等,但很多機構著錄項中的行政區劃地址和郵編信息并不完整。因此本研究考慮從機構名稱出發,構建“機構-作者”關系表,并基于機構類型特征詞典對機構進行分類,進而面向不同機構類別分別構建“機構-機構”作者共現矩陣、計算作者共現率,以實現機構實體消歧。假設不同類別中的機構名不可能指向同一機構實體,即無需匹配不同類別之間的機構名,這樣一方面可以減少機構之間兩兩匹配的次數,提高計算效率;另一方面能夠降低錯誤匹配的幾率,提升匹配準確率。
3.3.2 構建“機構-作者”關系表 通常,機構發表的文獻都不止1篇,故本研究先以機構為中心對文獻進行聚類,聚類個數即為待消歧機構名稱的數量,從而得到各機構發表的文獻集合,整合對應集合中的作者,完成“機構-作者”關系表構建。作者消歧是實體消歧的另一關鍵問題,非本研究重點,故暫不考慮作者同名的情況。
3.3.3 機構分類 利用分詞工具對上述規范至法人級別的機構名稱進行分詞處理,選取能夠代表機構類型的中心語,即分詞列表中的最后一個詞,依次與機構類型特征詞表中的特征詞進行比較,據此得到各機構名稱的分類。以“中國人民大學”為例,首先分詞得到“中國/ns 人民/n 大學/n”,然后選擇分詞列表中的最后一個詞“大學”與機構特征詞表進行匹配,發現該機構名稱屬于“高等教育機構”。
3.3.4 機構消歧 本研究假設,在一段時期內機構成員會保持相對穩定[28],因此可通過機構之間的作者共現率來推斷不同機構名是否指向同一實體。此外,考慮到本研究涉及的機構類型多樣,如公司企業、社會團體等機構發文量難以保證,無法避免由于發文量低而導致的重名風險,即若某機構發文量極低(如小于5),則可能因個別作者重名而導致作者共現率超過閾值[29],影響消歧準確率。因此綜合考慮機構對之間的作者共現率和作者絕對共現量指標,即針對不同類別機構的數據,循環遍歷“機構-作者”關系表中的n個機構,依次比較機構m(1≤m≤n)和剩下的n-1個機構,統計兩機構各自的作者數、機構間的共同作者數和全部作者數,構建“機構-機構”共現矩陣,計算機構對之間的作者共現率,此處共現率是指機構的共同作者占全部作者的比值,見公式(1),進而確定共現率閾值(如0.3),并據此篩選出具有同一關系的候選機構對;利用作者絕對共現量(機構間的共同作者數)指標控制重名風險:若作者絕對共現量大于等于2,判定兩個機構名稱指向同一機構實體,否則即使機構對的作者共現率大于等于閾值,仍將其判定為非同一實體。
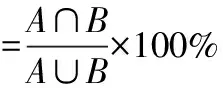
(1)
其中,A和B分別為兩個機構對應的作者集合,A∩B為兩個機構的共同作者數,A∪B為兩個機構的全部作者數。
3.4 評價指標
主要采用準確率P來評價本文提出的中文科技文獻機構名稱規范化方案有效性,見公式(2)。
(2)
其中,n為人工審核的正確機構對數量,N為識別出的機構共現對數量。
4 機構名稱規范化實踐
醫藥衛生知識服務系統(https://med. ckcest.cn)整合大量醫學領域的科技文獻、專家、機構、專利等學術資源,但科研成果中的機構名稱存在著錄混亂、層級結構模糊、更名頻繁等問題,導致機構名稱識別困難,難以開展文獻、專家、機構等科研實體之間的進一步關聯分析與深入挖掘。為進一步提高機構名稱識別效率,打通不同類型學術資源之間的壁壘,提高用戶信息檢索效率,需要對機構名稱進行規范化處理。本研究以醫藥衛生領域的中文科技文獻為例,開展機構名稱規范化實踐,驗證提出的機構名稱規范化處理方案是否可行。
4.1 數據采集
選取醫藥衛生知識服務系統作為數據來源,篩選醫藥衛生領域相關的期刊進行采集,采集內容包括文獻題目、作者、機構著錄項等,共采集1999—2020年發表的文獻數據10萬條,完成數據格式轉換與存儲,并對不完整數據和重復數據進行預處理,剔除文獻題目、作者、機構等關鍵字段不完整的數據,得到相對規范、完整的數據,見表1。

表1 部分采集樣例數據
4.2 機構名稱提取
4.2.1 多機構拆分 從采集的中文科技文獻數據可知,其機構著錄項之間都是通過分號進行分割。因此以分號為分隔符,利用字符串方法對機構進行拆分,拆分后共得到包含單機構記錄的數據350 587條。
4.2.2 機構著錄項拆分與過濾 對于拆分后的單機構記錄,其機構名稱、行政區劃地址和郵編之間均以空格或逗號作為分隔符,據此可先對機構著錄項進行初步拆分,并直接剔除長度小于4的字段。然后,基于字符串編輯方法過濾掉剩余字段中的郵編。最后,基于構建的國內各省市地區字典識別并刪除行政區劃地址,只保留作者原始著錄的機構名稱。
4.2.3 機構名稱規范化處理 系統分析并構建醫藥衛生領域機構類型特征詞表,該詞表共覆蓋8種類型機構,包含特征詞103個,其中醫療機構最多(41個),其次為事業單位(22個),見表2。
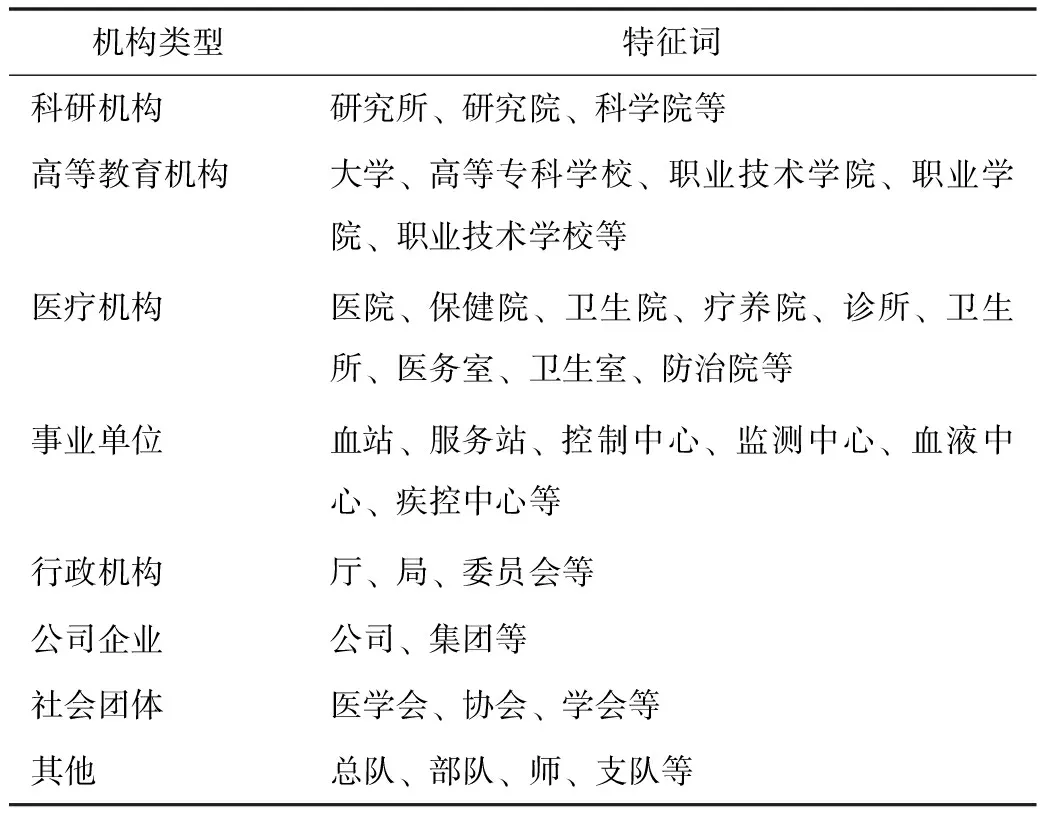
表2 醫藥衛生領域機構類型特征詞
對作者原始著錄的機構名稱數據進行分詞、識別機構著錄深度并刪除相應的二級機構名稱,完成機構名稱規范化處理,見表3。

表3 規范化機構名稱部分示例
4.3 機構實體消歧
4.3.1 構建“機構-作者”關系表 以機構為中心對文獻進行聚類,共得到15 088個聚類集合,分別整合各集合中的作者,構建“機構-作者”對應關系表。
4.3.2 機構分類 基于醫藥衛生領域機構類型特征詞表,對上述機構名稱進行分類,其中,醫療機構占比最高,其次為事業單位,社會團體最低,見表4。
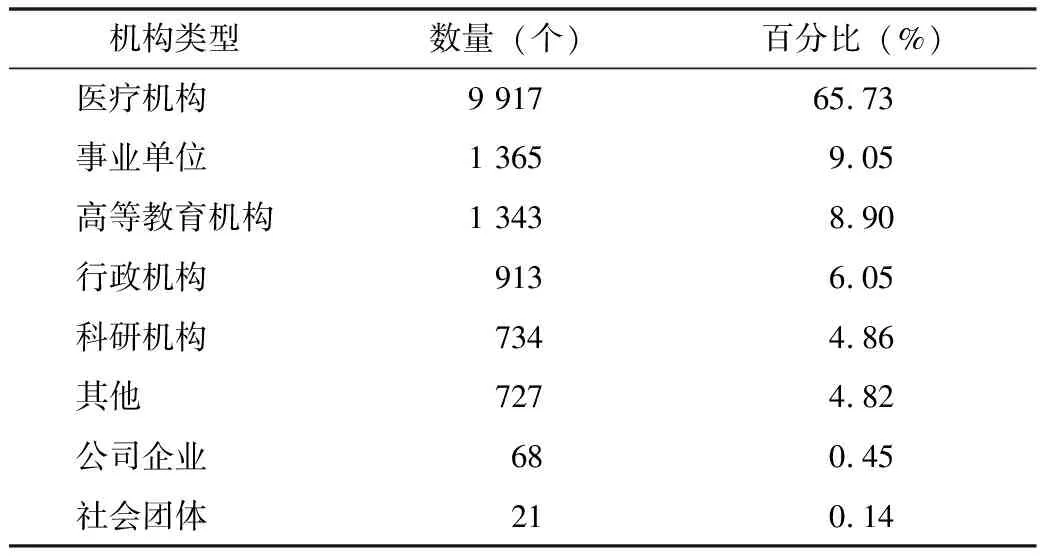
表4 醫藥衛生領域機構名稱分類情況
4.3.3 構建“機構-機構”共現矩陣 按照分類,依次計算各類別中機構對之間的作者共現率。經統計共14 592個機構對間存在作者共現情況,考慮到共現率小于0.1時誤判率過高,分析意義不大,本研究只針對共現率大于等于0.1的2 088個機構對進行比較分析,并將根據不同類型機構在數據集中所占的比例,按照同等比例從中隨機遴選300個機構共現對,進行準確率的分析。需要說明的是由于“其他”類型中共現率大于等于0.1的機構對共2個、“社會團體”共0個,故實際遴選出來的相較按比例的數量少(若按比例應遴選“其他”14個、“社會團體”1個),因此最終子集共包含機構共現對287個。由專業人員進行結果準確性測評,經分析,將共現率閾值設置為0.1時準確率可達89.2%,具有較高的機構實體消歧能力,盡管隨著閾值的提升,準確率也呈上升趨勢,但提升幅度較小,同時也會過濾掉很多雖然共現率低但實際為同一實體的機構對,故本研究暫將共現率閾值設置為0.1。
4.4 結果
通過統計,隨機遴選的閾值大于等于0.1的287個機構共現對中,人工認為其中256個機構對是同一機構,整體準確率為89.2%,具有較好的可參考性。此外,為進一步比較該方法對于不同類型機構的消歧效果,針對各類機構分別進行了誤判率統計。其中,“其他”類型誤判率最高,究其原因是該類型數據太少,少量誤判就會造成大的結果偏差;“高等教育機構”和“行政機構”類型誤判率也顯著高于其他類別,其原因可能是這兩類機構存在更為頻繁的更名、重組、拆分等現象,依據較低的共現率難以實現機構實體的有效識別。后續可通過進一步擴大數據集或提升共現率閾值來提高其準確率。
5 結語
規范化的機構名稱是開展面向機構的科技評價、異構學術資源整合、學術圖譜構建等工作的基礎與關鍵。本研究從“機構-作者”共現和機構類型特征詞的角度,開展面向中文科技文獻數據的機構名稱規范化研究,通過分析科技文獻中不同類型機構名稱的著錄特點,并結合作者共現情況進行機構名稱的消歧,最后在醫學領域進行驗證。經測試評估,該策略能夠有效匹配同一機構的不同表現形式。后續將進一步優化消歧策略,擴大實驗數據集并盡快推進其在醫藥衛生知識服務系統中的應用。通過機構間的作者共現率可以有效規范機構名稱,實現機構實體不同名稱形式的全面聚類與挖掘。但從長遠發展來看,建議積極落實對機構唯一識別碼的使用,特別是發表論文、專利等成果時,準確標識不同機構實體,從而更好地開展機構評價、構建機構知識庫、構建學術知識圖譜、規范存儲機構知識資源等工作。
猜你喜歡
家庭影院技術(2018年4期)2018-05-09 07:07:29
商周刊(2017年23期)2017-11-24 03:24:09
蘭臺內外(2017年5期)2017-06-06 02:24:19
中外醫療(2016年15期)2016-12-01 04:25:46
時代農機(2016年6期)2016-12-01 04:07:29
中國老區建設(2016年9期)2016-02-28 09:34:05
行政事業資產與財務(2015年23期)2015-10-26 03:13:30
中國衛生產業(2015年10期)2015-03-11 18:58:41
中國當代醫藥(2015年9期)2015-03-01 02:02:15
中國衛生(2014年3期)2014-11-12 13:18:18
