基于CSAGA-LSSVM算法的坦克駕駛模擬訓練數據分類挖掘
2022-02-16 11:12:04鄧青,薛青,翟凱
山東科技大學學報(自然科學版) 2022年1期
鄧 青,薛 青,翟 凱
(1. 陸軍裝甲兵學院 演訓中心,北京 100072; 2. 68303部隊,青海 格爾木 816099)
坦克駕駛模擬訓練是裝甲兵掌握駕駛技能的重要途徑,對提高裝甲分隊戰場快速機動能力具有重要意義[1-2]。坦克駕駛模擬訓練數據包括訓練操作數據、受訓人員數據等,這些數據之間蘊含著復雜的關系。傳統的坦克駕駛模擬訓練結果由人工進行統計分析[3],易受分析人員專業知識、個人偏好的主觀影響,對訓練的影響因素考慮不全,無法精確指導受訓人員,也難以從這些復雜的數據中發現有價值的訓練規律。為解決這一問題,提出將分類挖掘引入坦克駕駛模擬訓練數據分析中,以期從中獲取訓練指導規律。
Robinson等[4]運用主成分分析方法對通信指揮模擬訓練數據進行分析,為實施作戰指揮提供支持,但需要事先提取指揮員的能力特征表示,不同場景下的概念描述比較繁雜。Cady[5]選擇裝甲裝備模擬訓練系統中的地形條件、任務樣式、敵人屬性等作為輸入數據,運用定制的聚類算法和最小二乘法進行分析,得出殺傷力、戰損率等結果與輸入數據之間的關系,但算法細節沒有描述。Wang等[6]采用聚類方法分析裝甲兵模擬訓練數據,通過發現數據分布的簇特征,去除離群值,計算車輛位置的平均值,得出中心點移動速度與各車速度之間的關系,為機動力評估提供依據,但均值計算存在有偏估計問題。鄧桂龍等[7]運用關聯規則方法分析某型空地作戰系統模擬訓練數據,提取雷達連續照射時間、打擊導彈陣地種類與作戰效果之間的強關聯規則,輔助作戰分析人員獲取更多有用的知識,但生成規則的數量龐大,需要人工篩選。唐志武等[8]采集了裝甲兵模擬訓練系統在特殊想定條件下的交戰數據,運用多變量決策樹進行分析,得到機動、防護等作戰能力指標的影響因素,但決策樹的分叉比較繁瑣。貝葉斯網絡運用有向圖模型來描述和計算變量之間的概率依賴關系,利用先驗知識更新后驗概率,但往往需要專家確定初始值[9],而坦克駕駛模擬訓練數據在很多情況下無法提前確定先驗概率。決策樹分類具有原理簡單、抗噪音強等優點[10],主要適用于小樣本數據集的分類,在面對海量高維度數據時易產生無效節點。深度學習在圖像識別、自然語言理解領域有著廣泛運用[11],適合從高維度數據中提取特征,但由于內部的“黑盒”,對提取特征可解釋性較差。最小二乘支持向量機(least squares support vector machine,LSSVM)利用核函數、特征空間等處理高維數據,實現從樣本空間到特征空間的映射,具有良好的分類能力[12-13]。
坦克駕駛模擬訓練數據具有時序性的特點,不能直接輸入LSSVM進行分類,而要提取相應的特征后進行分類,同時LSSVM存在的超參選擇難問題也需要解決。本研究在LSSVM中引入Shapelets并進行組合以提取原始數據特征,設計自適應遺傳算法(adaptive genetic algorithm,AGA)實現超參數的最優選擇,最終得到一個組合Shapelets的自適應遺傳最小二乘支持向量機算法(combination shapelets adaptive genetic algorithm-least squares support vector machine, CSAGA-LSSVM),將其應用于坦克駕駛模擬訓練操作數據分析,通過分類得到標準的駕駛操作動作集合,更好地對受訓人員進行指導。
1 坦克駕駛模擬訓練數據分類挖掘問題描述
坦克駕駛模擬訓練數據中的知識和信息是分析決策的有效依據。對這些數據進行分類挖掘,除了具有傳統意義上的分類挖掘含義外,更重要的目標是從中發現有意義的模式。
從模擬器的數據采集分系統中抽取數據集B=(B1,B2,…,Bn),將B劃分為若干個不重復的記錄,其中每個元組都對應相同數量的條件屬性和類別屬性,假設條件屬性值的集合為C={C1,C2,…,Cn},類別屬性值的集合為D={D1,D2,…,Dn},則分類挖掘問題為發現從C到D的映射f:C→D[14]。在此基礎上,將坦克駕駛模擬訓練數據分類挖掘描述如下:
假設P={P(k)|k=1,2,…,N}為坦克駕駛模擬訓練數據的N維特征空間U?RN中所包含的非空模式集,其中任一子集族記為S={S(l)|l=1,2,…,c,1≤c≤N},若約束條件

(1)
成立,則稱S是對N維特征空間劃分所形成的一個子類,即S為P中的一個分類。
2 CSAGA-LSSVM分類挖掘算法
TS={vt1,vt2,…,vti,…,vtn}是一個實值時間序列,其中vti為時間序列點,n為時間序列長度;記為|TS|。通常相鄰時間序列點之間是等間隔的,時間序列簡記為TS={v1,v2,…,vi,…,vn}。時間序列的子序列TSj,l={vtj,vtj+1,…,vtj+l-1}是一個從TS取出起始位置為j、長度為l的連續序列。m個時間序列TS組成的集合稱作時間序列數據集,記為DTS={TS1,TS2,…,TSi,…,TSm},其中時間序列數據集的實例數|DTS|=m。
Shapelets是時間序列TS中能夠最大程度確定該序列所屬類標簽的特征表示,也是最具有辨識性和可解釋性的局部時序模式。一個長度為k的Shapelets={s1,s2,…,sk}是時間序列TS={v1,v2,…,vi,…,vn}的一個子序列。在時間序列分類問題中,從時間序列數據DTS集中每次學習獲得的時間序列Shapelets長度并不相同。
2.1 基于關鍵點的Shapelets快速獲取
Shapelets獲取是整個分類算法的第一步,通過定義關鍵點篩選子序列,減少產生的候選Shapelets個數,從而快速獲取Shapelets[15]。
關鍵點是從時間序列點內部產生的,并能夠表達時間序列的主要特征和變化趨勢。本研究的關鍵點包括時間序列的起始點、結束點、階躍點和極值點。
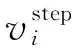
(2)
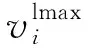
(3)
其中k是極值點附近鄰域的大小。
確定關鍵點后,按以下步驟產生Shapelets:
1)Key為存儲關鍵點的數組,Dsup為存儲Shapelets的字典,初始化均為空。設定初始鄰域k、閾值ρ。TS={v1,v2,…,vn}為一時間序列,n為時間序列長度,i=1;
2) 判斷點vi是否為時間序列的起始點,若是則將點vi存入數組Key中,轉步驟6);
3) 判斷點vi是否滿足vi-k≤vi且vi+k≤vi或vi≤vi-k且vi≤vi+k,若是則將點vi存入數組Key中,轉步驟6);
4) 判斷點vi是否滿足(vi+1-vi)/(vi-vi-1)≥ρ,若是則將點vi存入數組Key中,轉步驟6);
5) 判斷點vi是否為時間序列的結束點,若是則將點vi存入數組Key中,轉步驟7);
6) 結束對點vi的處理,i=i+1,轉步驟2);
7) 對關鍵點數組Key進行遍歷,按順序依次從Key中取出兩個元素構成Shapelets的兩個端點,并將該Shapelets及其所在的序號存入Dsup。
2.2 組合Shapelets特征生成
通過坦克駕駛模擬器可以進行各種駕駛操作練習,對油門、離合等部件的操作有明確的先后次序和時間間隔要求,因此受訓人員的駕駛動作識別屬于多維時間序列分類問題。而之前獲取的Shapelets由于忽略不同序列之間的操作時間、邏輯組合等關系,難以達到準確的辨識效果。因此將多個Shapelets進行組合,并加入時間間隔,以增強組合Shapelets的分類能力,并通過信息增益評價最優Shapelets組合,以提高分類的準確性。
對于長度均為n的TS1和TS2,采用歐氏距離
(4)
作為兩個時間序列之間的距離,來度量兩者間的差異。
對于Shapelets子序列s與TSi的距離shpdis(s,TSi),采用滑動窗口方式在TSi上生成(n-s+1)個與s等長的序列TSi,|s|,按式(4)計算距離,由動態彎曲距離比對原則取最小值作為s與TS1之間的距離度量,即:
shpdis(s,TSi)=min(dis(s,TSi,|s|)) 。
(5)
對于時間序列數據集DTS={TS1,TS2,…,TSi,…,TSm},類標簽的個數為C,設某一類ci在時間序列數據集DTS中有ni個時間序列,則時間序列數據集DTS的熵表示為:
(6)
隨機選擇s1、s2兩個Shapelets進行合取操作,按式(5)分別計算s1、s2與DTS={TS1,TS2,…,TSi,…,TSm}中每一個時間序列之間的距離。合取后的s1∧s2同時含有s1、s2的特征,則s1∧s2與TSi的距離comshpdis(s1∧s2,TSi)應取兩者中較大的值進行度量:
comshpdis(s1∧s2,TSi)=max(shpdis(s1,TSi),shpdis(s2,TSi)) 。
(7)
對s1∧s2與DTS={TS1,TS2,…,TSi,…,TSm}中時間序列的距離按遞增順序存入一維數組Discshp。設定閾值δ,遍歷數組Discshp元素并與δ比較,將時間序列數據集DTS分成DTSleft、DTSright兩部分:
DTSleft={TSi|TSi∈DTS,Discshp[i]≤δ},
(8)
DTSright={TSi|TSi∈DTS,Discshp[i]>δ}。
(9)
通過式(6)計算DTSleft、DTSright數據集的熵,得到s1∧s2的信息增益
(10)
以對s1∧s2進行評估,并將對應的子序列加入候選組合Shapelets,記作Canshp。
為增強組合Shapelets的分類能力,參照決策樹的構建思想,將Shapelets之間的時間間隔作為分類的輔助特征,減少單純使用距離度量分為兩個數據集DTSleft、DTSright所產生的分類誤差。在式(5)中,通過求取s與TSi的距離最小值,找到最佳匹配初始位置記作Bpos(s,TSi),TSi(Bpos(s,TSi),Bpos(s,TSi)+s-1)表示時間序列TSi從初始位置Bpos(s,TSi)開始,長度為|s|的子序列,則有:
shpdis(s,TSi)=dis(s,TSi(Bpos(s,TSi),Bpos(s,TSi)+s-1)) 。
(11)
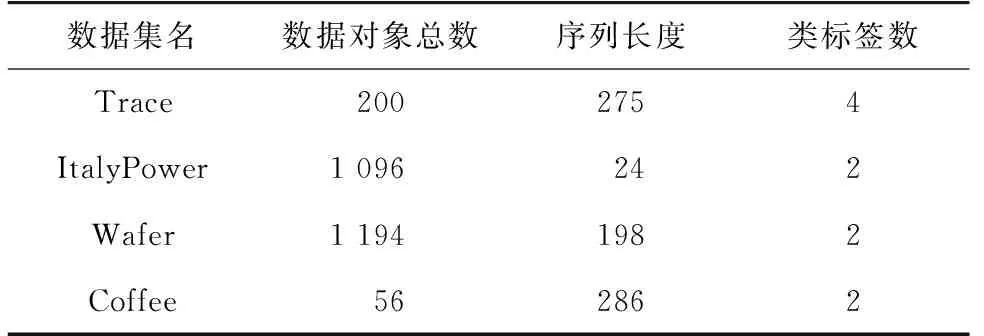
設Bpos(s1,TSi)、Bpos(s2,TSi)分別表示s1、s2與TSi的最佳匹配初始位置,并且Bpos(s1,TSi) Itime(s1∧s2)=Bpos(s2,TSi)-Bpos(s1,TSi) 。 (12) 對Canshp中的所有組合Shapelets按式(12)計算相應子序列的時間間隔,得到時間間隔集合 SItime={Itime(si∧sj)|Itime(si∧sj)=Bpos(sj,TS)-Bpos(si,TS),si,sj∈Canshp} 。 (13) (14) (15) 通過式(6)、(10)計算得到信息增益 (16) 選擇信息增益最大的子序列作為組合Shapelets。 考慮到用LSSVM分類時,核參數σ和懲罰因子C的取值對分類算法的性能有重要影響,而且遺傳算法具有良好的魯棒性,故本節采用遺傳算法進行參數尋優。但傳統的遺傳算法存在早熟收斂等問題,故采用自適應遺傳算法改進交叉、變異操作,避免陷入局部最優。具體步驟如下。 1) 交叉操作 采用單點交叉算子,隨機選擇兩個父代個體,并設置每一對個體的基因位置用于交叉操作。隨著進化代數的增加,按式(17)自動調整交叉概率pc,然后在交叉點進行染色體互換,生成兩個新的子個體。這種自適應變化克服了因采用固定交叉概率而導致的后期不易保留優秀個體的問題,有利于維護種群的多樣性。 (17) 式中:τ為進化代數,psize為種群數量,len為染色體長度。 2) 變異操作 變異操作促使產生新個體,可以提高算法的局部搜索能力,變異概率設定過高容易破壞適應度最優的個體,導致收斂變慢;過低不利于產生新個體,容易陷入早熟。根據個體的適應度變化動態調整變異概率pm,對于適應度較小的個體賦予較大的變異概率,促進個體向更優解進化,反之賦予較小概率,即: (18) 式中:fitmax為種群中的最大適應度值,fitmin為種群中的最小適應度值,fiti為種群中個體i的適應度值,λ為調整系數,pm0為初始概率常數。 在獲得組合Shapelets的基礎上,利用Shapelets轉換概念[16-17]計算原始時間序列與Shapelets之間的距離,將原始序列映射到新的特征空間,通過AGA-LSSVM算法進行分類。 假設xk∈Rn為經轉換后的輸入,yk∈R為類標簽,則LSSVM將分類轉化為如下優化問題: (19) 式中:ω為權重矩陣,b為偏倚變量,ek為訓練誤差,C為懲罰因子。 對式(19)的優化問題采用拉格朗日泛函得到下式: (20) (21) 結合卡庫塔條件(Karush-Kuhn-Tucker,KKT),將式(21)轉換為矩陣形式所表示的線性方程組: (22) 令A=Ω+C-1I,最終求得α和b分別為: α=A-1(Y-bH), (23) (24) 根據α和b的值,對任意輸入樣本x的分類函數為: (25) 對于多維時間序列數據集DTS={TS1,TS2,…,TSi,…,TSm}的任一維TSi,其輸入樣本子集可采用AGA-LSSVM方法學習訓練出分類器,根據符號函數sgn()計算輸出類標簽,為: (26) 通過以上對CSAGA-LSSVM分類挖掘算法四個階段的描述,得到CSAGA-LSSVM算法具體流程如圖1所示。 圖1 CSAGA-LSSVM分類挖掘算法流程圖Fig. 1 Flow chart of CSAGA-LSSVM classification mining algorithm 為了驗證CSAGA-LSSVM分類挖掘算法性能,設計多維時間序列數據的分類實驗,分析該算法的分類精度和執行效率。 實驗用計算機配置:處理器Intel(R) Core(TM) i7-4510@2.60 GHz,硬盤1 TB+128 GB SSD,顯卡NVIDIA GetForce 840 M,內存8 GB DDR3,操作系統Windows 7 64位,編程環境為Python 3.7。選擇公開數據集Trace、ItalyPower、Wafer和Coffee進行對比實驗,數據集的簡要說明如表1所示。 表1 實驗數據集Tab. 1 Experiment data set 實驗中分別利用基于采樣Shapelets[18](S-Shapelets)、邏輯Shapelets[19](L-Shapelets)和本研究的組合Shapelets(C-Shapelets)對原始數據進行特征提取,其中S-Shapelets通過劃分子類得到中心序列,選擇與中心序列距離之和最小的序列作為采樣數據,從而減少候選Shapelets的產生;L-Shapelets采用加速技術與剪枝方法過濾具有相似形狀的Shapelets,從而增加更多有辨別能力的Shapelets用于數據轉換,大大提高了分類的準確度。分別采用LSSVM、GA-LSSVM和AGA-LSSVM建立分類模型,共形成9種不同的分類方法。選取分類準確率和運行時間兩個指標,對9種分類方法的性能進行實驗測試對比。實驗中采用8折交叉驗證法將數據集劃分為訓練集和測試集,通過訓練集對每個分類算法進行迭代訓練,然后在測試集上進行檢驗,取平均值作為兩個評價指標的最終結果。 1) 分類準確率 分類準確率是測試集上正確識別的樣本數與數據對象總數的比值。9個分類方法在不同數據集上的準確率對比見表2。 表2 9個分類方法在不同數據集上的分類準確率對比Tab. 2 Comparison of classification accuracy of 9 classification methods on different data sets % 從表2可見,CSAGA-LSSVM分類方法的準確率要優于其他分類方法,且采用C-Shapelets的同一分類模型具有最高的準確率,說明C-Shapelets通過引入不同Shapelets之間的時間間隔對子序列進行組合,并根據信息增益選擇最優的子序列,可以有效增強Shapelets的辨識能力,提高分類精度。同時基于C-Shapelets的AGA-LSSVM通過自適應遺傳操作,比LSSVM、GA-LSSVM能搜索到更優的超參數解,對原始時間序列數據有更完整的特征表示,表現出更好的分類能力。另外,利用S-Shapelets的LSSVM在Trace數據集上的分類準確率較低,說明直接采用單個Shapelets對較長的時間序列進行分類,容易忽略不同子序列之間的關聯,導致分類效果下降。而L-Shapelets采用剪枝策略對相似的Shapelets進行過濾,增加其他特征的Shapelets,具有較高的分類精度。 2) 運行時間 通過調用Python中time模塊的時鐘函數返回當前時間,用來計算算法運行的時間。表3為9個分類方法在不同數據集上的運行時間對比。 表3 9個分類方法在不同數據集上的運行時間對比Tab. 3 Comparison of running time of 9 classification methods on different data sets s 從表3可知,直接采用S-Shapelets的LSSVM分類方法所需時間最少,原因在于S-Shapelets沒有進行不同Shapelets之間的組合運算,而是通過子類劃分產生候選Shapelets,計算過程比L-Shapelets、C-Shapelets簡單,并且LSSVM不進行參數尋優,因此整個算法的運行時間最少。基于C-Shapelets的時間序列表示充分利用具有顯著特征的關鍵點,能夠快速產生候選Shapelets,減少了相應子序列的搜索時間,從而算法的運行效率高。L-Shapelets在所有可能的子序列空間搜索候選Shapelets,空間復雜度較大,在產生Shapelets后還要進行迭代剪枝操作,故大多數情況下基于L-Shapelets的AGA-LSSVM所花費時間較多。另外AGA-LSSVM和GA-LSSVM采用遺傳操作對LSSVM超參進行尋優,需要反復迭代直至全局收斂或達到規定的代數,因此運行時間相比傳統的LSSVM要長,但準確率有所提高。 綜上,CSAGA-LSSVM分類方法在準確率方面具有明顯優勢,適用于不同規模和密度的數據集,說明所提出的組合Shapelets能對原始時間序列進行更完整的特征表示。在運行時間上,基于C-Shapelets的AGA-LSSVM分類方法比S-Shapelets的LSSVM長,但比采用L-Shapelets的GA-LSSVM、AGA-LSSVM運行時間要少。綜合考慮分類準確率的影響及分類模型訓練的時間要求,CSAGA-LSSVM分類方法是可行的。 通過安裝在某型坦克駕駛模擬器上的位移傳感器、光電傳感器實時記錄受訓人員的操作數據,模擬器系統幀頻為25 fps,每運行1幀采集數據1次,即每秒采集25組數據。采集的操作數據主要包括起動開關、變速裝置擋位、加油踏板、離合器踏板等。 為便于分析,對坦克駕駛操作分為基本操作和組合操作。基本操作是指駕駛過程只有一個操縱部件的狀態發生變化,是駕駛操作的“元動作”。組合操作是由若干個基本操作按不同的順序組成的動作序列,與動作次序、完備程度、完成時間等密切相關。換擋操作是適應不同路面環境下的機動要求,是坦克駕駛操作的一項重要內容。下面以“一擋換二擋”為例,運用CSAGA-LSSVM算法進行模擬訓練結果分析。 在坦克駕駛模擬訓練實驗中,選擇1 200名受訓人員(二級坦克駕駛員、三級坦克駕駛員、初級坦克駕駛員和無等級人員各300名)在某型坦克駕駛模擬教室進行“一擋換二擋”操作訓練,每名受訓人員進行6次換擋操作,通過傳感器和模擬訓練系統采集到的駕駛員部分操作過程數據如表4所示。 表4 坦克駕駛模擬器“一擋換二擋”操作數據Tab. 4 Data of the tank driving simulator in “shifting from the first to the second gear” operation 從表4可以看出,油門踏板位移、離合器踏板位移和制動器踏板位移屬于一元時間序列數據,變量取值隨時間連續變化形成多變量時間序列。本次實驗共產生7 200個樣本,選擇油門踏板位移、離合器踏板位移、制動器踏板位移、擋位值為特征變量,對操作成績離散化處理為類標簽y,形成決策表,如表5所示。 表5 坦克駕駛模擬器操作數據分析決策表Tab. 5 Data analysis decision of the tank driving simulator operations 從表5中隨機選取80%的數據作為訓練集進行分類器訓練,余下的20%作為測試集。首先通過Shapelets特征提取方法對換擋操作的多維時間序列進行表示,求解組合Shapelets,再依次計算油門踏板位移、離合器踏板位移等時序數據與組合Shapelets之間的距離,實現換擋操作數據變換,用于后續分類輸入;然后運用AGA求得最優超參數C=65.8,σ=0.25。基于調優后的分類模型對時序數據進行分類,最終得出分類結果如表6所示。 表6 結果數據Tab. 6 Statistics of Results 以表6為依據,結合坦克駕駛換擋操作的理論與實踐,對得到的最終解分析如下: 1) “一擋換二擋”操作成績合格所對應的Shapelets:油門踏板時序數據Shapeletsacr[1]∧Shapeletsacr[2]={00,01,00}∧{00,01},離合器踏板位移時序數據Shapeletsclu[1]∧Shapeletsclu[2]={000,010,011,110,111}∧{111,100,011,010,000},擋位時序數據Shapeletsgear={1,2},表示換擋前應平穩踩下油門踏板至適當位置,然后松開油門踏板同時將離合器踏板由初始位置踩到最大位置,迅速將變速桿由1擋推向2擋位置,掛擋后松回離合器踏板應做到前快后穩,同時均勻踩下油門踏板。 2) “一擋換二擋”操作成績不合格所對應的Shapelets:制動器踏板位移時序數據Shapeletsbrk={00,01,11},油門踏板時序數據Shapeletsacr={00},擋位時序數據Shapeletsgear={1},表示“一擋換二擋”過程中踩下了制動器踏板,而未踩油門踏板進行沖車,車輛擋位值沒有發生變化;油門踏板時序數據Shapeletsacr[1]∧Shapeletsacr[2]={00,01,00}∧{00,01},離合器踏板位移時序數據Shapeletsclu={000},擋位時序數據Shapeletsgear={1},表示“一擋換二擋”過程中未踩下離合器踏板,換擋操作不合格。 將“一擋換二擋”操作成績為合格所對應的Shapelets組合可建立相應的標準操作動作模式,作為“一擋換二擋”操作技能水平的評價等級,對受訓人員的駕駛動作進行精確分析。比如,隨機選取一名受訓人員的訓練樣本數據進行預處理生成相應的Shapelets,其中離合器踏板位移時序數據Shapeletsclu[1]={000,011,100,110},擋位時序數據Shapeletsgear={1}。通過計算與標準操作動作模式之間的距離,可以發現該名受訓人員在換擋過程中沒有將離合器踏板踩到底,導致擋位狀態仍為1擋,掛擋不成功,表明該受訓人員掌握動作要領較差,需要在今后的訓練中加強理論學習,熟記換擋的關鍵動作和操作流程,同時注重模擬器基本駕駛動作訓練,反復體會換擋要領。 本研究為挖掘坦克駕駛模擬訓練數據,提出一種CSAGA-LSSVM分類挖掘算法。先根據起始點、結束點、階躍點、極值點快速獲取候選Shapelets,減少產生的候選Shapelets數量;再通過選擇距離和時間間隔對Shapelets進行組合操作,并計算信息增益評價最優組合,增強特征的辨識能力,提升分類的準確性;然后設計了自適應遺傳算法,通過動態調整交叉和變異概率來加速搜索LSSVM超參數的全局最優解,減少分類挖掘時間;最后,利用CSAGA-LSSVM算法分析某型坦克駕駛模擬器換擋操作數據,提取不同訓練水平人員的操作特征,從而更好地發現訓練問題,促進個性化訓練的開展。
2.3 基于自適應遺傳算法的LSSVM超參數尋優
2.4 基于組合Shapelets的AGA-LSSVM分類




3 實驗與對比分析

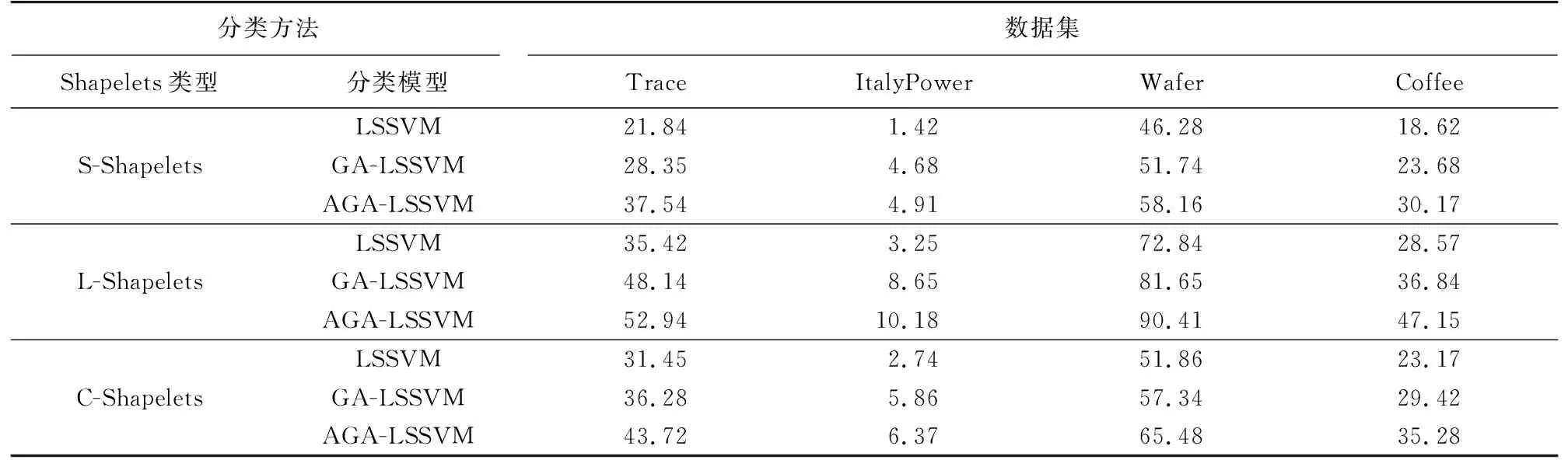
4 基于CSAGA-LSSVM的坦克駕駛模擬訓練操作數據分析
4.1 數據來源

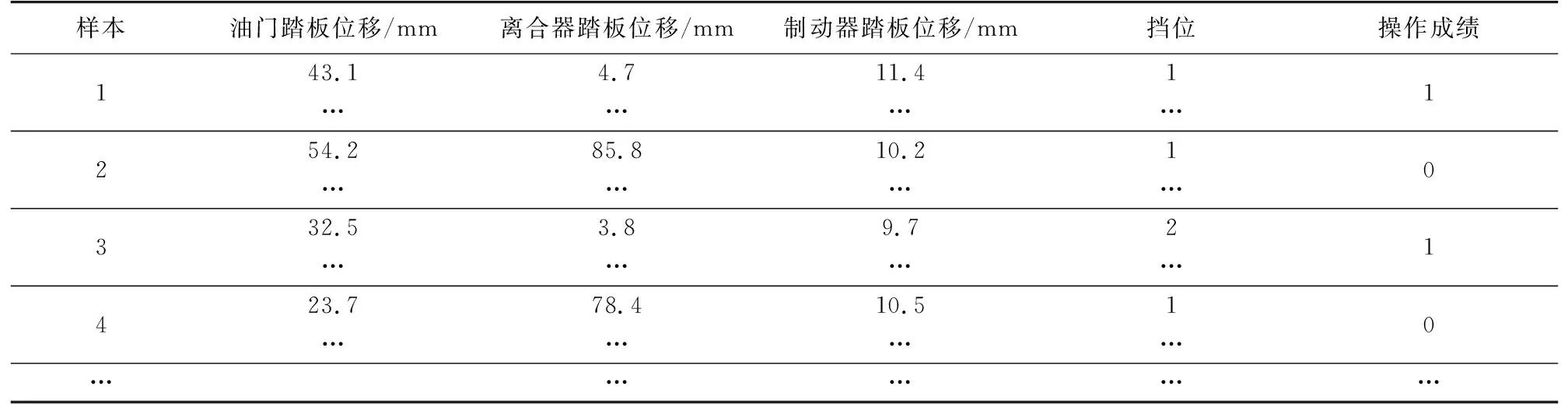
4.2 最優分類解獲取
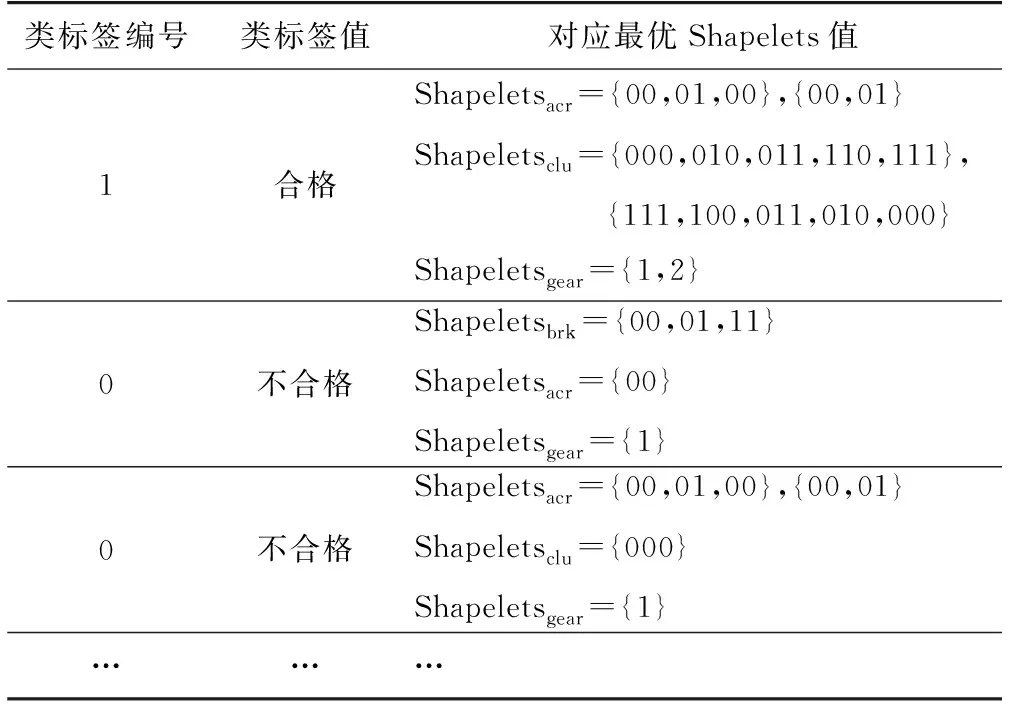
4.3 結果分析
5 結論
猜你喜歡
車主之友(2022年6期)2023-01-30 07:58:16
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
黃河之聲(2019年23期)2019-12-17 19:08:43
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
汽車實用技術(2019年17期)2019-09-21 03:46:32
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
