基于奇異譜分析與梯度優化算法優化的RVM、SVM月徑流預測研究
2022-02-18 02:31:36梁曉鑫崔東文
人民珠江 2022年1期
關鍵詞:模型
梁曉鑫,崔東文
(1.云南省水文水資源局文山分局 云南 文山 661100;2.云南省文山州水務局 云南 文山 663000)
徑流時間序列是指月徑流數據按照時間先后順序排列而成的數列,開展徑流時間序列分析預測對水文預測預報、水資源開發利用等具有重大意義。水文時間序列影響因素眾多、變化復雜,表現出較強的非線性、非平穩性和多尺度等特征,傳統自回歸類模型、集對分析模型、灰色模型等傳統擬線性預測方法存在著局限性,難以獲得理想的預測效果[1]。當前,基于“分解—預測—重構”模式的時間序列預測方法被廣泛應用于水文時間序列徑流預測,并取得較好的預測效果。常見的時間序列分解方法有小波變換(WT)、經驗模態分解(EMD)、集合經驗模態分解(EEMD)、變分模態分解(VMD)、奇異譜分析(SSA)等方法;預測模型主要有BP神經網絡[2-3]、廣義回歸神經網絡(GRNN)[4]、支持向量機(SVM)[5]、相關向量機(RVM)[6]、極限學習機(RELM)[7]等。
為進一步提高水文時間序列預測精度,克服單一模型的不足,本文基于“序列分解—參數優化—分項預測—結果疊加”思想和“奇異譜分析(Singular Spectrum Analysis,SSA)、梯度優化(gradient-based optimizer,GBO)算法、相關向量機(relevance vector machine,RVM)與支持向量機(Support Vector Machines,SVM)”方法,提出SSA-GBO-RVM、SSA-GBO-SVM月徑流時間序列融合預測模型。通過SSA對月徑流數據進行處理,提取多個獨立子序列,達到降低徑流數據復雜性的目的;針對RVM核寬度因子和超參數、SVM懲罰因子和核函數參數對RVM、SVM預測性能影響較大以及參數難以選取等問題,采用GBO算法優選RVM、SVM關鍵參數,達到提升RVM、SVM預測性能的效果;利用云南省龍潭站65年共780個月月徑流數據對SSA-GBO-RVM、SSA-GBO-SVM模型預測性能進行檢驗,旨在驗證SSA-GBO-RVM、SSA-GBO-SVM模型用于月徑流時間序列預測的可行性和可靠性。
1 SSA-GBO-RVM、SSA-GBO-SVM集成模型
1.1 奇異譜分析(SSA)
SSA依據所觀測到的時間序列構造出軌跡矩陣,并對軌跡矩陣進行分解、重構,從而提取出代表原時間序列不同成分子序列[8-10]。SSA包含分解與重構2個階段。
a)分解。選取窗口長度L構造軌跡矩陣X如下:
(1)
式中M——時間序列長度;L——窗口長度,即嵌入維數,一般為不超過序列長度1/3的整數。
對矩陣X進行SVD(singular value decomposition,SVD)分解:
(2)
式中λi——第i個特征值;Ui——與第i個特征值對應的特征向量;Vi——第i個主成分;d=rank(X)=max{i:λi>0}。

(3)
式中 向量數量K=M-L+1;L*=min(L,K);K*=max(L,K)。
1.2 梯度優化(GBO)算法
1.2.1GBO算法簡述
梯度優化(GBO)算法是Ahmadianfar I 等人受牛頓-梯度下降法啟發而提出的一種新型元啟發式優化算法。與傳統元啟發式優化算法相比,GBO算法不但實現簡單,設置參數少(僅需設置種群規模和最大迭代次數),而且具有較好的探索、開發、收斂能力和有效避免局部極值的能力。參考文獻[12],GBO算法數學描述簡述如下。
a)初始化。GBO算法中,種群個體被稱為“向量”,該“向量”在D維搜索空間中可表示為Xn,d=[Xn,d,Xn,d,…,Xn,d],n=1,2,…,N;d=1,2,…,D,在D維搜索空間中隨機生成初始向量Xn表示為:
Xn=Xmin+rand(0,1)×(Xmax-Xmin)
(4)
式中Xmax、Xmin——搜索空間上下限值;rand——[0,1]范圍內隨機數。
b)梯度搜索規則(GSR)。GSR規則可以幫助GBO算法在優化過程中解決隨機行為,從而促進探索并避免局部最優;運動方向(DM)用于創建合適的局部搜索趨勢,以提高GBO算法的收斂速度。梯度搜索規則(GSR)與運動方向(DM)數學描述如下:
(5)
(6)
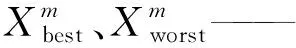
GBO算法第m+1次迭代向量位置更新描述如下:
(7)
其中,
(8)
(9)
(10)


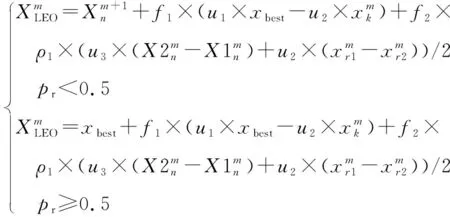
(11)
(12)
式中f1——[-1,1]范圍內隨機數;f2——平均值為0、標準差為1的正態分布隨機數;pr——概率;u1、u2、u3——3個隨機數;其他參數意義同上。
1.2.2GBO算法仿真驗證
選取6個典型測試函數在不同維度條件下20次尋優平均值對GBO算法尋優性能進行評估,并與文獻[11]海洋捕食者算法(MPA)、粒子群優化(PSO)算法的仿真結果進行比較,結果見表1。實驗參數設置如下:GBO、MPA、PSO算法群體規模N=100,最大迭代次數M=500,其他采用算法默認值。

表1 函數優化對比結果
a)對于單峰函數,GBO算法在不同維度條件下尋優精度分別較MPA和PSO算法提高113、88、61和134、102、 68個數量級以上,具有較好的尋優精度。
b)對于多峰函數Griewank、Rastrigin、Ackley,GBO算法在不同維度條件下20次尋優均獲得了相對理論最優值0和8.88e-16,尋優精度略優于MPA,遠優于PSO算法,具有較好的全局搜索能力。
可見,GBO算法對上述6個測試函數均具有較好的尋優精度和全局搜索能力。
1.3 相關向量機(RVM)
RVM是一種基于貝葉斯推理的稀疏概率機器學習模型,其基本算法簡述如下[13-16]。

(13)


(14)
式中t=(t1,t2,…,tN)T;Φ——N×(N+1)的核函數矩陣。
為避免ω和σ2過擬合,常使用零均值高斯先驗概率分布約束參數:
(15)
式中α——一個N+1超參數向量。
基于貝葉斯公式,后驗分布的權重描述為:
(16)
式中μ=σ-2∑ΦTt;∑=(σ-2ΦTΦ+A)-1;A=diag(α0,α1,…,αN)。
為建立統一的超參數,p(t|α,σ2)定義如下:
(17)
本文利用高斯徑向基核函數(RBF)作為核函數,即:
(18)
式中d——核函數寬度因子。
1.4 支持向量機(SVM)
設含有l個訓練樣本的集合為{(xi,yi),i=1,2,…,l},xi(xi∈Rd)為第i個訓練樣本輸入列向量,yi∈R為對應輸出值[17-18]。則SVM在高維特征空間中建立的線性回歸函數為:
f(x)=wΦ(x)+b
(19)
式中Φ(x)——非線性映射函數;w——超平面的法向量;b——超平面的偏移量。
(20)
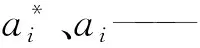
選擇徑向基核函數作為SVM核函數,徑向基核函數表達式為:
(21)
式中g>0。
1.5 SSA-GBO-RVM、SSA-GBO-SVM建模流程
SSA-GBO-RVM、SSA-GBO-SVM建模預測實現流程見圖1,實現步驟如下。

圖1 實例月徑流預測流程
步驟一采用SSA方法將原徑流序列分解為多個獨立的子序列;通過自相關函數法(Autocorrelation Function Method,AFM)確定各子序列輸入向量,合理劃分訓練樣本和預測樣本。
步驟二構建適應度函數:
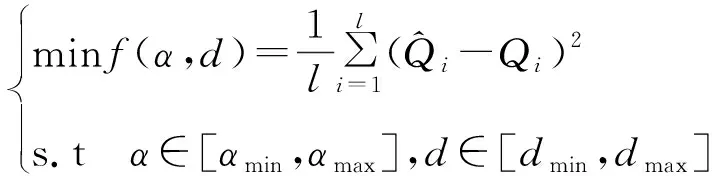
(22)
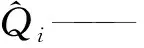

圖2 奇異譜分析分解圖與原始月徑流量

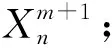


步驟八分別利用GBO-RVM、GBO-SVM模型對各子序列進行預測,預測結果疊加即得到實例月徑流預測的最終結果。
步驟九分別采用平均絕對百分比誤差(mean absolute percentage error,MAPE)、平均絕對誤差(mean absolute error,MAE)和納什系數(Nash-Sutcliffe efficiency coefficient,NSE)對各預測模型有效性進行評估,見式(23)。
(23)
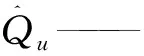
2 實例應用
2.1 數據來源
龍潭站系紅河流域瀘江水系盤龍河干流控制站,控制徑流面積3 128 km2,為國家重要水文站和中央報汛站。盤龍河發源于紅河州蒙自縣鳴鷲鄉,流經西疇、馬關、麻栗坡于天保船頭附近注入越南,河長252.6 km,平均坡降8.73‰,中越國界以上流域面積6 497 km2,多年平均徑流量為26.93億m3。本文數據來源于龍潭站1952年1月至2016年12月實測月徑流序列,月徑流量變化過程見圖2。
2.2 SSA分解
SSSA分解確定子序列數量至關重要,若子序列數量過少,則不足以將原始序列中蘊含的不同成分提取出來;若子序列數量過多,則增加了模型復雜程度和建模工作量[8]。由于水文氣象是以年為周期,因此本文設置窗口長度L=12,即利用SSA方法將原月徑流時間序列數據分解為12個獨立的子序列,利用SSA-GBO-RVM、SSA-GBO-SVM模型分別對12個子序列進行預測,將預測結果疊加后得到最終預測結果。SSA分解與月徑流隨時間變化趨勢見圖2。從圖2可以看出,子序列1振幅最大、頻率最高、波長最短,大致反映了原月徑流時間序列的變化趨勢;子序列2—12振幅逐漸減小、頻率逐漸降低、波長逐漸變長,反映了原徑流時間序列的波動情況。
2.3 確定輸入向量
本文采用AFM法確定各子序列的輸入向量,通過計算各子序列逐月徑流數據序列的自相關系數,將自相關系數最大時所對應的滯后數Y作為各子序列的最優嵌入維數,即將預測月的前Y個徑流量數據作為輸入向量,預測月作為輸出向量,見表2。本文利用實例后120個月作為預測樣本。
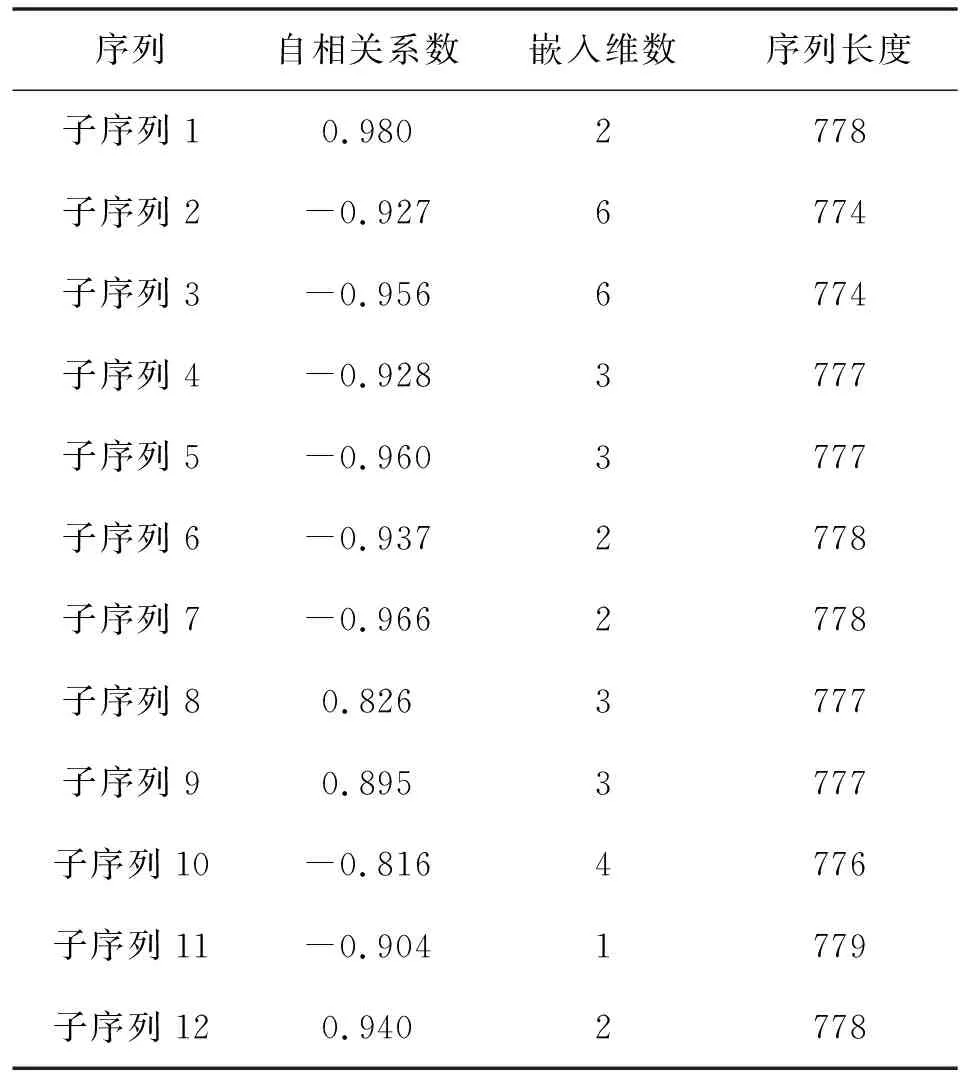
表2 各子序列自相關系數、嵌入維數及序列長度
2.4 參數設置及預測分析
2.4.1參數設置
SSA-GBO-RVM、SSA-GBO-SVM模型參數設置為:GBO算法種群規模N=50,最大迭代次數M=100;核函數選擇徑向基核函數RBF。其中,RVM超參數和核函數寬度因子搜索范圍均設置為[-10,10];SVM懲罰因子、核函數參數搜索范圍均設置為[0.01,100],交叉驗證折數設置為3,不敏感損失系數設置為0.01,原始數據采用[-1,1]進行歸一化處理。
2.4.2月徑流預測及比較
利用SSA-GBO-RVM、SSA-GBO-SVM模型對實例子序列1—12進行訓練及預測,將結果進行疊加即得到實例月徑流訓練及預測的最終結果。采用平均絕對百分比誤差MAPE、平均絕對誤差MAE和納什系數NSE對各模型性能進行評估,結果見表3;訓練及預測效果見圖3—6。

表3 實例136個月月徑流預測結果對比表

圖3 SSA-GBO-RVM模型訓練效果

圖4 SSA-GBO-RVM模型預測效果

圖5 SSA-GBO-SVM模型訓練效果

圖6 SSA-GBO-SVM模型預測效果
依據表3及圖3—6可以得出以下結論。
a)SSA-GBO-RVM、SSA-GBO-SVM模型對實例月徑流時間序列擬合的MAPE分別為5.74%、5.69%,MAE分別為1.10、1.14 m3/s;預測的MAPE分別為6.20%、7.82%,MAE分別為0.88、1.00 m3/s,均具有較好的擬合、預測效果。表明SSA方法能有效將原徑流時間序列數據分解成多個更具規律的子序列,GBO算法能有效優化RVM核寬度因子和超參數、SVM懲罰因子和核函數參數,基于序列分解—參數優化—分項預測—結果疊加思想構建的SSA-GBO-RVM、SSA-GBO-SVM模型均具有較高的預測精度,將其用于水文時間序列預測是可行的。其中,SSA-GBO-RVM模型預測效果要優于SSA-GBO-SVM模型。
b)SSA-GBO-RVM、SSA-GBO-SVM模型對實例訓練樣本、預測樣本擬合、預測達到水文預報甲等精度等級的比例(相對誤差絕對值小于等于20%)分別均為96.9%、99.2%,滿足水文預報精度要求,均具有較好的預報效果。
c)SSA-GBO-RVM、SSA-GBO-SVM模型對實例訓練樣本、預測樣本擬合、預測的納什系數NSE分別高達0.994 8、0.993 9和0.992 6、0.991 3,表明SSA-GBO-RVM、SSA-GBO-SVM模型用于月徑流時間序列預測可信度較高。其中,SSA-GBO-RVM模型可信度最高。
d)從圖3—6來看,SSA-GBO-RVM、SSA-GBO-SVM模型對實例月徑流時間序列擬合、預測的效果均較好,除少數樣本的相對誤差、絕對誤差較大外,絕大多數樣本的擬合、預測結果較接近實測值,滿足預測精度要求。其中,SSA-GBO-RVM模型預測結果更接近實測值,相對誤差更小、預測效果更佳。
3 結論
本文基于序列分解—參數優化—分項預測—結果疊加思想構建SSA-GBO-RVM、SSA-GBO-SVM時間序列集成模型,通過云南省龍潭站月徑流時間序列預測實例對SSA-GBO-RVM、SSA-GBO-SVM模型進行檢驗,得到以下結論。
a)通過6個單峰、多峰函數在不同維度條件下對GBO算法進行仿真驗證,并與MPA、PSO算法比較。驗證了GBO算法具有較好的尋優精度和全局搜索能力。將GBO算法用于RVM核寬度因子和超參數、SVM懲罰因子和核函數參數尋優是可靠的。
b)SSA-GBO-RVM、SSA-GBO-SVM模型對實例月徑流時間序列均具有較好的擬合、預測效果,模型具有較高的可信度,將其用于水文時間序列預測是可行的。其中,SSA-GBO-RVM模型優于SSA-GBO-SVM模型。
c)實例驗證表明,SSA方法能有效將原徑流時間序列數據分解成多個更具規律的子序列,抽取出徑流序列的整體趨勢和不同周期上的波動情況;GBO算法能有效優化RVM核寬度因子和超參數、SVM懲罰因子和核函數參數;基于序列分解—參數優化—分項預測—結果疊加思想構建的SSA-GBO-RVM、SSA-GBO-SVM模型在水文時間序列徑流預測中均具有較高的預測精度和可信度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
