基于知識表示學習的實時語義數據流推理
2022-02-19 10:23:16顧進廣
計算機應用與軟件 2022年2期
高 峰 熊 輝 顧進廣
(武漢科技大學計算機科學與技術學院 湖北 武漢 430065)(湖北省智能信息處理與實時工業系統重點實驗室 湖北 武漢 430065)
0 引 言
隨著傳感器網絡、社交媒體和移動互聯網等應用的發展,網絡上產生了海量數據,數據的實時處理和分析具有重要意義。將實時數據流與知識圖譜技術結合,對數據流進行知識標注后可得語義數據流(Semantic Data Stream),語義數據流處理系統(RDF Stream Processing, RSP)能將靜態背景知識與動態信息結合,實現實時的、基于知識的查詢和推理。
針對實時推理,已經出現了不少實時語義數據流推理平臺,其中:集中式的系統包括C-SPARQL引擎[1],這是一種基于ESPER數據流處理引擎和Jena查詢的流推理系統;分布式的系統包括基于LARS[2]架構的BigSR[3]流推理平臺。它們都能在一定的程度上解決語義推理問題,但是傳統的實時語義流推理平臺在進行傳遞規則推理,特別是傳遞閉包規則推理時會產生大量中間結果,導致推理效率急劇下降[4-5]。
近年來,以深度學習為代表的知識表示學習技術發展較快[6]。知識表示學習是指在知識庫中,以實體和關系為基礎進行表示學習,實現對實體和關系之間語義信息的向量化表示。這種方式能夠將實體之間復雜的語義關系轉化為簡單的向量計算,對于提升推理效率效果明顯。因此,本文提出一種基于C-SPARQL平臺和KALE知識表示學習模型[7]的CSKR(Continuous Sparql with KALE Reasoning)實時流推理平臺。首先通過索引算法對ESPER引擎中實時數據流的謂語構建索引,再根據查詢語句以及推理規則生成預測的三元組集合,最后輸入給擴展的KALE模型并計算出推理結果。
1 相關工作
1.1 實時語義數據流推理
語義數據流中的信息是不斷變化與更新的,因此傳統的語義推理和查詢的方法無法適用于這種情況。現在已經有一些工作能夠處理動態RDF數據流。例如Streaming SPARQL[8]、C-SPARQL、CQELS[9]、EP-SPARQL[10]等。Streaming SPARQL 基于時代關系函數,用來擴展SPARQL語言,雖然支持RDF流處理,但是沒有考慮到連續計算過程中狀態共享的性能問題。C-SPARQL是一個基于ESPER數據流處理引擎和Jena組件的流推理平臺,通過添加新的運算符來擴展SPARQL語言,從而支持對RDF數據流的處理。CQELS同時支持靜態數據和動態數據并支持多源RDF流處理,可以提供優秀的查詢性能,但是沒有考慮并行的問題,對大數據集支持不好,大大降低了流處理性能。EP-SPARQL偏向于復雜事件處理和流推理,它可以轉化成一種基于Prolog復雜事務處理框架語言ETALIS[11],并實現實時語義數據流推理和查詢。LARS是一種基于邏輯的推理分析框架,在此基礎上BigSR結合了Spark和Flink推出了分布式實時語義數據流推理平臺,該平臺吞吐量較大并且延遲在毫秒以內。雖然此類方法能利用分布式處理有效降低推理延時,但對硬件資源要求較高,本文方法則無此限制。
1.2 知識表示學習模型
在Mikolov等[12]提出了word2vec詞表示學習模型之后,表示學習的方式在知識圖譜的領域受到了廣泛的關注。Bordes等[13]提出了TransE知識表示學習模型,這是一種既簡單又高效的模型,該模型將三元組中的關系看作平移向量,表示頭實體與尾實體之間的平移。因此,對于每一個事實三元組,都應當滿足以下條件:
ei+rk≈ej
(1)
式中:ei表示頭實體向量;rk表示關系向量;ej表示尾實體向量。
TransE模型的真值公式表示為:
(2)
式中:d表示向量空間的維度;I則表示每一個三元組經過計算之后得到的真值。
因為TransE模型的參數簡單、計算復雜度低,但是性能高效的特性,大量研究工作對其進行擴展和應用,并且出現了大量基于TransE模型改進和補充的知識表示學習模型。例如TransH[14]、TransR[15]、TransA[16]TransD[17]等模型。其中:TransH是一種針對TransE當中不能很好解決實體和關系之間一對多、多對一和多對多問題的改進模型;而TransR認為不同的關系擁有不同的語義空間,因此它將實體和關系嵌入到不同的空間中,在對應的關系空間中實現翻譯。
雖然以上模型都對TransE模型做了相應的改進,但是都沒有利用三元組之間的關系。KALE模型在TransE模型的基礎上根據Tim等[18]提出的關系抽取方式建立了三元組與推理規則的統一框架,改善了原有TransE模型訓練過程中只利用了實體內部的聯系而忽略了三元組之間推理規則的問題。因此本文以KALE模型為基礎,提出了相應的KR推理機制,并應用于實時流推理平臺。
2 CSKR平臺框架
傳統語義數據流推理中,主要包含ESPER流引擎、推理引擎和Sparql查詢引擎,CSKR將其中的推理引擎轉換為KALE模型并加入推理機制,將復雜的規則推理變成簡單的向量計算,從而大大降低了推理延遲,用來滿足大數據情況下的實時推理需求,CSKR推理主要包括以下幾個步驟:
(1) 加載RDF數據,通過Jena解析,將RDF數據轉化為ESPER數據流處理引擎可識別的數據格式。
(2) 讀取解析后的數據,并加上時間戳,放入RDF數據流中。
(3) 從ESPER流引擎中取出指定窗口內的數據,作為輸入數據輸入到聯合嵌入式模型當中。
(4) 聯合嵌入式模型獲取數據后,根據推理規則,預測可能存在的三元組集合,并將集合內的三元組進行向量計算后,依據目標函數的閾值進行分類,得出推理的三元組集合。
(5) 將推理結果放入Sparql引擎中進行查詢,并返回查詢結果。
CSKR平臺總體框架如圖1所示。

圖1 CSKR平臺總體框架
3 CSKR推理機制
本文在KALE的基礎上進行擴展,得到針對傳遞性規則的知識表示模型。基本的KALE模型只能應用于鏈接預測和分類的場景,無法直接替換傳統的推理引擎,因此本文提出一種基于三元組預測機制的CSKR推理平臺。
3.1 推理規則和模型框架
目前傳統實時語義流推理平臺主要采用的推理規則是RDFS/OWL規則集。它們在RDF的基礎上增加了對本體的描述和類型約束,并且添加了相關的推理規則。但是在推理過程中,因為傳遞規則尤其是傳遞閉包規則的復雜性,導致傳統推理方法性能很差,所以產生了大量重復數據,計算量呈指數級的上升。
在知識表示學習方向,KALE模型將三元組之間的規則嵌入到表示學習過程當中,建立了規則和三元組之間的統一框架。KALE模型基于Tim等[18]提出的關系抽取方法,以邏輯連接詞推理的方式對兩種類型的規則建立了統一得分函數。
第一種類型為假設(em,rs,en)?(em,rt,en),則根據關系抽取以及邏輯連接詞的推導,可以得到如式(3)所示的真值公式。
I(f)=I(em,,rs,en)·I(em,,rt,en)-
I(em,,rs,em)+1
(3)
式中:I表示三元組的真值。同樣的第二種類型為(em,rs,en) ∧(en,rk,el)?(em,rt,el),可以得到如式(4)所示的統一真值公式。
I(f)=I(el,,rs,em)·I(em,,rk,en)·I(el,,rt,en)-
I(em,,rs,en)·I(en,,rk,el)+1
(4)
KALE模型具體框架如圖2所示。

圖2 KALE模型框架
KALE模型利用卷積神經網絡分別學習三元組中實體和關系的描述,得到頭、尾實體和關系的向量表示em、en、rs。基于上述工作,KALE模型對知識圖譜中的三元組計算統一得分函數,對于正確的三元組,其得分越低越好;而對于一個負采樣產生的樣本,其得分越高越好,這樣通過訓練模型區分正負樣本。因此,在模型訓練過程中,采用合頁損失函數作為訓練目標,并使用隨機梯度下降算法進行優化,其損失函數定義如式(5)所示[7]。
(5)
式中:S+為正實例三元組的集合;S-為負實例三元組的集合;I為統一得分函數;γ是margin的超參數,表示正負樣本得分之間的間隔距離。
由于在實時推理中,傳遞性規則執行的效率較差,尤其是傳遞閉包產生大量中間結果導致性能下降,本文主要在KALE模型的基礎上實現傳遞性規則和傳遞閉包規則的實時流推理模型。
3.2 索引分類
數據流中的三元組中的主語和賓語變化較為頻繁,而其中的謂語則相對固定,例如存在兩個不同的三元組(e1,r,e2)和(e3,r,e4),他們的謂語都是r,但是主語和賓語分別為e1、e2和e3、e4,根據這種情況,本文對謂語建立了相應的索引以提高推理效率。
每當讀取一個新的三元組時,CSKR的數據流引擎抽取當前謂語,然后去索引節點中檢索,如果節點中不包括該謂語,則對該謂語建立相應的索引,并在這個索引上建立對應的主語集合和賓語集合,最后將這個三元組的主語和賓語分別放入對應的集合;如果節點中包括當前謂語,則直接將三元組的主語和賓語放入對應的集合。當讀取完所有的三元組數據之后,CSKR可以得到如圖3所示的索引結構。

圖3 KR算法索引結構
具體索引算法如算法1所示。
算法1索引算法
輸入:triples。
輸出:out。
begin
valout=outMap
for (tintriples) {
if (out.containsKey(t.p) {
out.get(t.p).get(subject).add(t.s)
out.get(t.p).get(object).add(t.o)
} else {
out.put(t.p,tripleMap)
out.get(t.p).put(subject,subjectSet)
out.get(t.p).put(object,objectSet)
out.get(t.p).get(subject).add(t.s)
out.get(t.p).get(object).add(t.o)
}
}
returnout
end
3.3 三元組預測和分類
為了將KALE應用于推理模型,CSKR首先需要生成預測三元組集合,再將預測三元組集合放入模型中計算得分函數。由于預測三元組集合的生成會根據數據特性生成不同數量的冗余數據,本文使用關系生成和實體生成兩種不同的策略來生成預測三元組,并使用如下方式自動選擇恰當的策略:在最開始的五次計算里,分別計算兩種生成算法生成的預測三元組集合數量,然后選取數量少的集合作為輸入參數進行接下來的計算,并對選取的策略標記加一,當五次采樣結束后,CSKR會選取標記多的策略作為接下來的生成算法。
關系生成算法首先根據規則集中的關系推理解析查詢語句,當查詢中包含需要推理的規則時,CSKR會從索引節點中獲取推理條件中謂語對應的主語集合與賓語集合,并與推理結果中的謂語組成新的預測三元組。例如存在如下傳遞推理規則:當三元組數據集中包含(e1,r1,e2)和(e2,r2,e3), 則一定可以推理出(e1,r3,e3)這樣的新三元組。根據關系生成算法,推理引擎將會先獲取r1的主語集合set1和r2中的賓語集合set2,并將set1中的實體作為主語,set2中的實體作為賓語,最后與r3組成新的預測三元組。其主要生成算法如算法2所示。
算法2關系生成策略
輸入:tripleMap,rules,gate。
輸出:out。
begin
valout=outSet
for (ruleinrules) {
valsubjectSet=tripleMap.get(rule.p1).get(subject)
valobjectSet=tripleMap.get(rule.p2).get(object)
for (sinsubject) {
for (oinobject) {
out.add(s,rule.p3,o)
}
}
}
returnout
end
實體生成算法則是根據實體所在的位置生成對應的預測三元組集合。如果一個實體既是某個三元組的賓語,也是另外一個三元組的主語,則生成算法認為該實體在這兩個三元組中對應的主語和謂語可能存在某種傳遞規則。其具體算法如算法3所示。
算法3實體生成策略
輸入:triples,rules。
輸出:out。
begin
valout=outSet
for (t1intriples) {
for (t2intriples) {
if (t1.o==t2.s) {
for (ruleinrules) {
out.add(t1.s,rule.p,t2.o)
}
}
}
}
returnout
end
在模型訓練中,系統會根據正實例的排名不斷調整得分函數的閾值,當三元組經過計算后,其得分大于閾值時,系統判定該三元組為正實例,否則為負實例。訓練完成后,推理引擎將新的預測三元組集合進行重新計算,并將得分大于閾值的三元組作為最后的推理結果。
4 實驗與結果分析
4.1 實驗設置
本文實驗所使用的軟件環境為操作系統Windows 10,采用Java 8作為編程環境,開發環境為IntelliJ IDEA。硬件環境為CPU i5 10210U@1.6 GHz, 內存大小為16 GB。
本文采用并擴展里海大學推出的LUBM(Lehigh University Benchmark)標準數據集[19]進行實驗,擴展數據集已在Github開源。實驗內容主要包括CSKR的推理準確性實驗和推理性能對比實驗。
4.2 推理實驗場景
LUBM數據集本身不存在傳遞閉包規則,因此,為了適應本實驗對傳遞規則以及傳遞閉包規則測試的情況,本實驗隨機對LUBM數據集部分GraduateStudent實體之間增加了schoolMate關系,并構造了傳遞規則Rule1和傳遞閉包規則Rule2,規則如表1所示。

表1 傳遞規則以及傳遞閉包規則
針對以上傳遞規則,本實驗構造了兩個查詢語句Query1和Query2如表2所示。

表2 實驗查詢語句
表2中Query1表示查詢University1的所有成員,在Rule1的條件,假設存在學生GraduateStudent1與學生GraduateStudent2之間擁有schoolMate的關系,且GraduateStudent2與University1之間擁有memberOf的關系,那么在查詢結果當中應當包含可以推理出來的三元組(GraduateStudent1, memberOf, University1)。Query2表示查詢GraduateStudent1的所有校友,在Rule2的條件,假設存在學生GraduateStudent1與學生GraduateStudent2之間擁有schoolMate的關系,且學生GraduateStudent2與學生GraduateStudent3之間擁有schoolMate的關系,那么在查詢結果當中應當包含可以推理出來的三元組(GraduateStudent1, schoolMate, GraduateStudent3),并且該推理結果仍然可以作為推理條件去推理新的結果,具有傳遞閉包性。
4.3 CSKR推理命中率
為了更好地評價本文模型在LUBM數據集上的效果,本文沿用了KALE模型中同樣的評價方式。對于每一個測試三元組(s,p,o),模型會打碎主語s,并將其替換為主語集合中的其他主語s′, 構成新的負實例三元組(s′,p,o),最后計算該負實例的真值。在所有主語遍歷完后,模型將會得到一個根據真值降序的列表以及正實例三元組中主語s在列表中的排名。同樣地,在替換完賓語之后,也可以得到一個正實例三元組中賓語o在列表中的排名。最終本文得到兩個指標: (1) MRR(Mean Reciprocal Rank)是一個常用的衡量算法的指標,目前被廣泛用在允許返回多個結果的問題當中。(2) HITS@N是指正例三元組排在真值降序列表中前n位置的比例。
本實驗將向量空間的維度d的分別設置為{30,40,50},為了驗證KALE模型對于TransE模型的改進有利于本實驗的數據集,加入了TransE模型在相同條件下的對比實驗。根據設置,實驗后可以得到如表3所示的實驗結果。

表3 KALE與TransE的推理命中率實驗結果
根據實驗結果可知,隨著d的逐漸增加,KALE模型在LUMB數據集上,評價指標越好,并且在相同維度的條件下,KALE模型的結果均好于TransE模型。
隨著向量矩陣的維度逐漸增加,雖然評價指標有所提升,但是模型計算得分函數的計算量也會依次增加,而且當維度從30增加到50的時候,HIT@10的結果提升不到3%, 計算消耗卻增加了70%左右。考慮到該模型將應用于大數據低延遲的場景,因此,本實驗選取d為30的KALE模型作為CSKR的推理引擎,然后與傳統C-SPARQL推理系統做對比。
4.4 CSKR查詢和推理時延
在傳統C-SPARQL推理引擎中,目前遇到的困難是,在碰到復雜的傳遞閉包規則時,推理會產生大量的重復三元組,急劇增加了推理延遲,降低推理效率,所以不能很好地處理實時數據。本實驗選取單位數量的三元組作為數據輸入,并以處理數據的延遲作為評價指標,分別設計了普通的傳遞規則和復雜的傳遞閉包規則查詢語句,并統計在復雜規則推理下,兩個系統的平均查詢延遲。
因為ESPER數據流處理引擎支持窗口操作,所以本實驗選取的窗口大小分別為{10,20,40},單位為s, 每秒窗口三元組的數量分別為{200,1 600},單位為個,窗口的步長為1 s。根據以上的輸入參數得到的實驗結果如圖4所示。
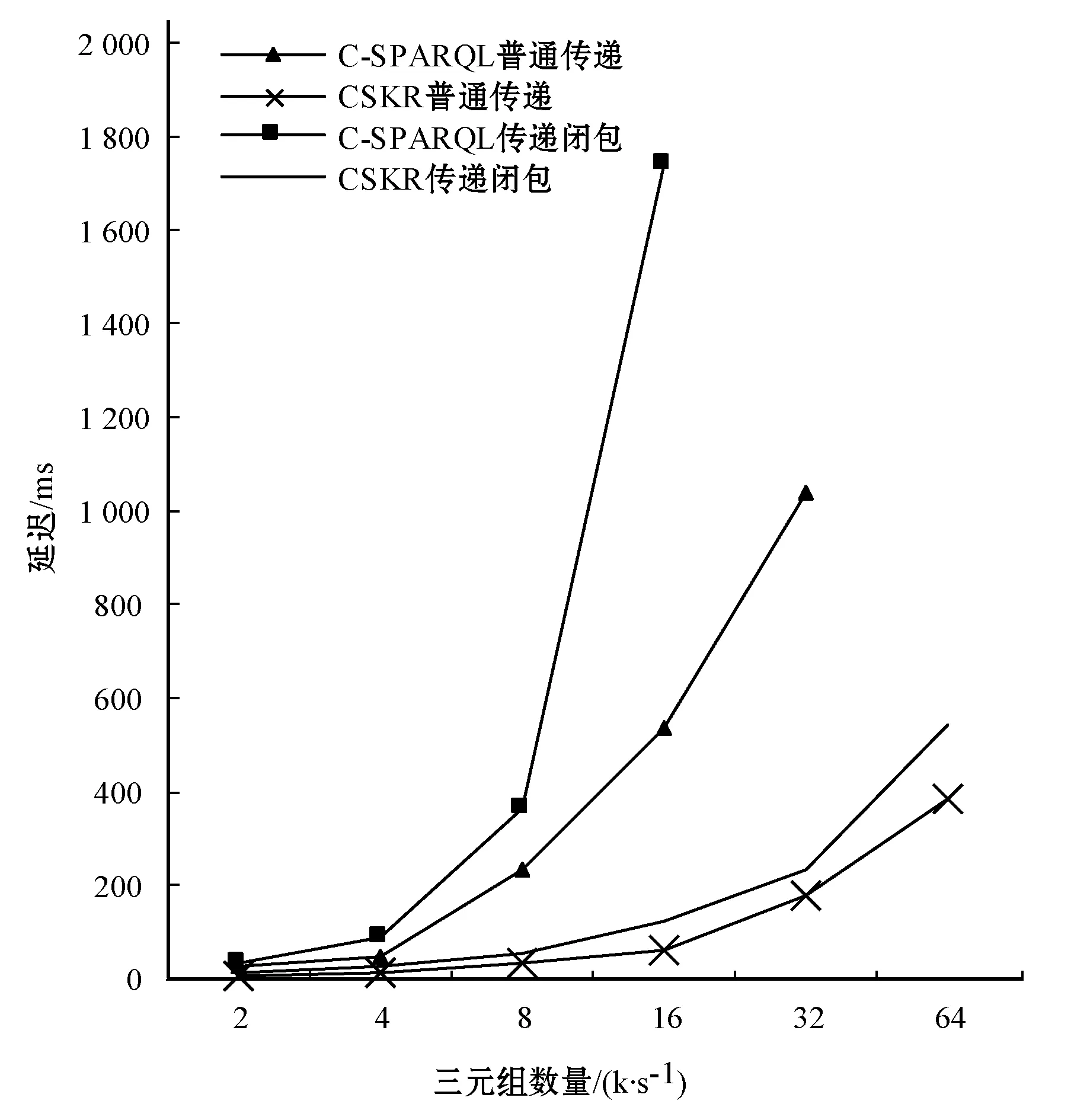
圖4 LUBM數據集的實驗結果
實驗結果表明,在相同條件下,CSKR平臺查詢所消耗的延遲明顯低于傳統的C-SPARQL平臺,在普通傳遞規則下最多能降低80%左右的延遲時間,而在傳遞閉包規則下最多能降低93%左右的延遲時間。在普通傳遞規則下,C-SPARQL數據量達到每秒32 000個三元組時計算量過大失去響應;在傳遞閉包規則下,C-SPARQL數據量達到每秒16 000個三元組時失去響應,而CSKR吞吐量均能達到每秒64 000個三元組以上,較C-SPARQL有明顯優勢。
5 結 語
本文在傳統的推理系統C-SPARQL上融入了基于知識表示學習的KALE模型,并加入索引和三元組預測機制。實驗結果表明,在普通傳遞規則和傳遞閉包規則下,CSKR較C-SPARQL性能提升十分明顯,前者CSKR時延降低最多能達到80%左右,吞吐量提升2倍以上,而后者時延降低最多能達到93%左右,吞吐量提升4倍以上,并且CSKR的結合方式也為傳統的實時數據流規則推理系統提供了新的研究方向。
雖然CSKR平臺在生成預測三元組的時候采用了根據數據特性自適應的策略,但是兩種生成算法仍然會產生大量冗余數據,造成性能浪費。因此,在未來工作中,如何進一步優化預測三元組生成算法依舊是研究重點。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
開放教育研究(2020年2期)2020-03-31 01:54:14
Coco薇(2017年11期)2018-01-03 20:59:57
商周刊(2017年22期)2017-11-09 05:08:31
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
現代語文(2016年21期)2016-05-25 13:13:44
河南電力(2015年5期)2015-06-08 06:01:46
皖西學院學報(2015年5期)2015-02-28 17:52:46
大連民族大學學報(2015年2期)2015-02-27 08:28:11
