基于RetinaNet的場景文字檢測算法
2022-02-19 10:24:00金靈張軼
計算機應用與軟件 2022年2期
金 靈 張 軼
(四川大學計算機學院 四川 成都 610065)
0 引 言
場景文字檢測是計算機視覺領域一個非常重要的研究課題,其研究成果可以被應用于車輛輔助駕駛系統、社會場景識別、圖片文本分析、機器人導航、圖片檢索等實際場景。
場景文字的表現形式復雜,不僅具有較大的長寬比、任意方向性、字體和大小多種多樣等特點,而且因環境限制,存在圖片曝光不均、目標區域模糊等問題。場景文字檢測的主要手段是提取圖片特征,以區分圖片中背景和文字區域。傳統方法大多基于手工構造特征,其檢測過程繁瑣,應對復雜的自然場景時魯棒性不足。得益于日益增大的數據量和不斷提升的硬件計算性能,深度神經網絡算法在計算機視覺研究的各個研究方向取得了突破,受其影響,越來越多的神經網絡自然場景文字檢測算法被提出。
1 相關工作
1.1 研究現狀
神經網絡模型的自然場景文字檢測算法可分為基于錨框的方法和基于像素分割的方法。受目標檢測算法啟發,Liao等[1]設計了一組具有不同長寬比的錨框,通過在不同層次的特征圖上設置不同大小的錨框,檢測不同尺寸大小的文字區域,但是該方法只能檢測到水平方向的文字區域。Ma等[2]通過為錨框增加旋轉角度參數,模型能夠檢測任意方向的文字區域,但是錨框更為復雜,增大了模型學習的難度。錨框能夠保證較好的召回率,但是如何設計錨框需要人的先驗經驗作為指導,并且難以應對復雜多變的場景文字情況,模型中存在的錨框會產生不可忽視的計算資源開銷。因為模型學習的目標是錨框與真實區域之間的偏移量,所以基于錨框的方法又被稱為間接回歸方法。
基于像素分割的方法中,He等[3]首先提出通過對每個像素點進行分類和預測邊界距離,從而定位像素所在的文字區域。因為回歸的目標是一個文字像素點與其所在文字區域邊界的距離,所以其又被稱為直接回歸方法。Zhou等[4]提出了RBOX標簽生成機制,通過生成像素點分類標簽,回歸距離標簽和回歸角度標簽,實現以像素點為單位標記文字區域的目的,但同文提出的EAST算法在單個特征圖上學習目標文字區域,未考慮文字區域大小不一,長寬比變化較大等問題。Deng等[5]對像素分類和相鄰像素鏈接分類,然后使用Union-Find算法得到像素連通域,實現文字區域實例分割,最后使用最小外接矩形方法得到文字區域。該方法訓練過程快,處理小區域文字效果較好,但是在處理文字密集區域時較為繁瑣的后處理過程耗時較長。
場景文字檢測的樣本圖片中往往只有少量文字區域,文字像素點和背景像素點的比例極不均衡。針對該問題,現有方法往往在訓練過程中使用在線困難樣本挖掘算法[6],該算法啟發式地選取正負樣本,將其比例控制在一個相對較小的范圍以內,以緩解樣本比例懸殊問題,但其在模型訓練過程中會產生不可忽視的計算資源消耗,且樣本選取具有隨機性,并不能充分利用現有的訓練數據。
針對上述問題,本文提出在多尺度特征圖上學習不同大小的文字區域,解決因尺度變化大而引起的模型學習困難問題。設計了一個共享卷積核的檢測模塊,采用直接回歸方法定位文字區域;使用Focal Loss[7]作為分類損失函數解決正負樣例不均衡問題。
1.2 RetinaNet簡介
RetinaNet[7]是一種基于錨框的通用目標檢測算法,該網絡模型使用特征金字塔網絡提取多層次的具有上下文語義的特征圖,并且在多個特征圖之間共享同一個檢測模塊,具有檢測效果好且速度快的特點。如圖1所示,RetinaNet檢測模塊使用class subnet和box subnet分別處理目標類別分類任務和目標定位任務,其中K表示檢測目標的類別個數,A表示預設錨框的個數。
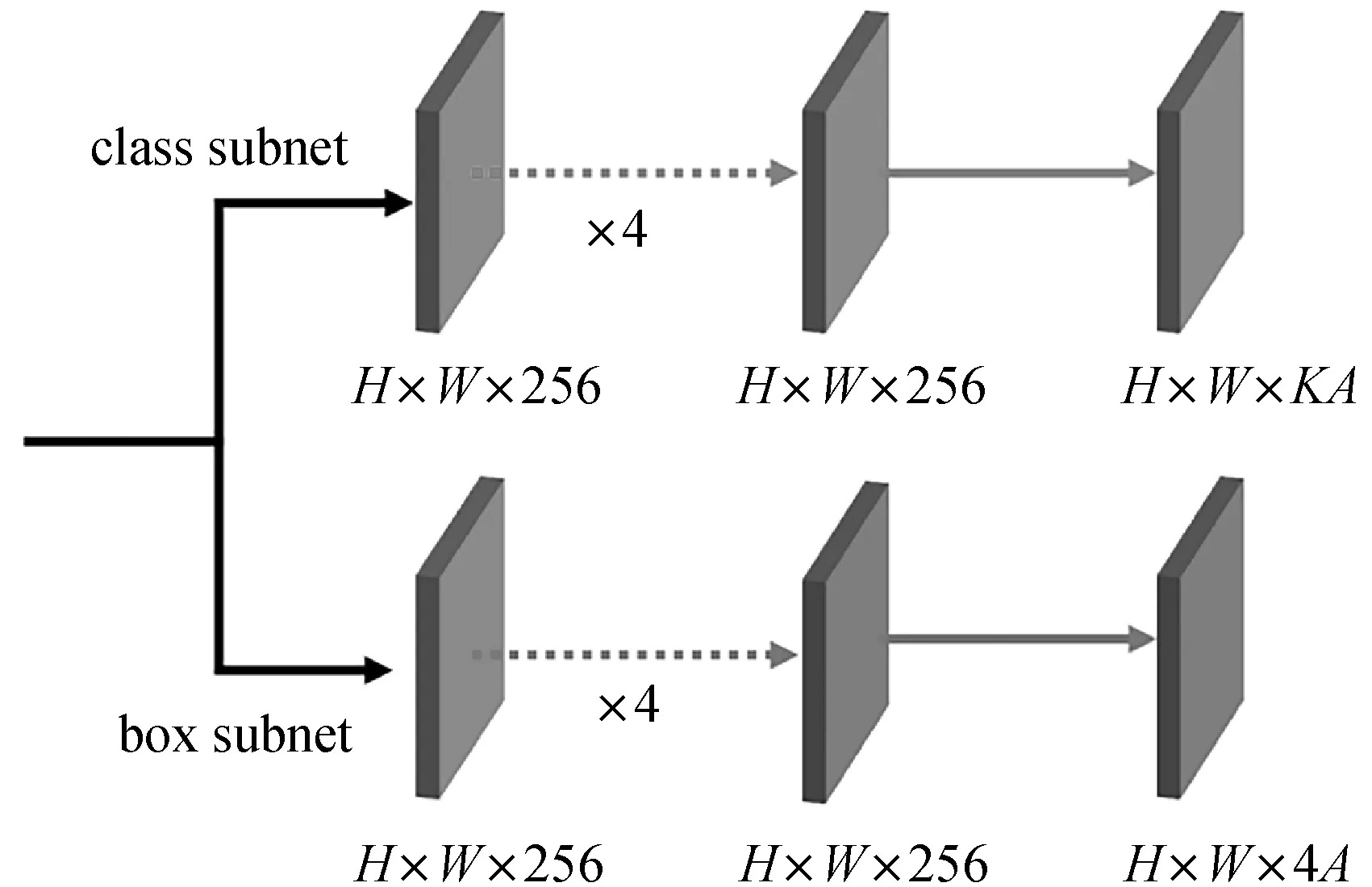
圖1 RetinaNet檢測模塊
2 模型設計
本文提出的場景文字模型受RetinaNet啟發,其整體架構如圖2所示,分別由特征提取網絡、特征金字塔網絡、文字區域檢測模塊三部分組成。圖2左側的特征提取網絡和特征金字塔網絡共同用于構建融合特征圖。首先,使用特征提取網絡提取輸入圖片的特征信息;然后,基于多尺度特征融合的思想,使用特征網絡金字塔構建出尺寸不一且具有不同特征語義的融合特征圖。
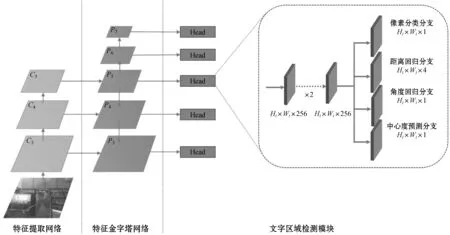
圖2 模型整體結構
針對場景文字檢測任務的特點,本文設計了一個輕量級的文字區域檢測模塊,其架構如圖2右側部分所示。目標檢測任務的目標類別數量K往往很大,如COCO數據集[8]含有80個類別,此外RetinaNet是基于錨框的目標檢測方法,每一層有9個預設錨框,因此圖1中的class subnet輸出通道數為720,box subnet輸出通道數為36。因為本文方法無需預先設置錨框,僅需使用像素分類分支對輸入圖片中的像素進行二分類,所以其輸出通道數設為1。在此基礎上,為了定位文字像素所在的預測文字區域,添加了距離回歸分支和角度回歸分支,分別用于預測像素到其所在文字區域邊界的距離,及文字區域方向角度,其輸出通道數分別為4和1。針對場景文字區域長寬比較大的特點,本文提出了中心度預測分支,該分支輸出結果可用于重新調整像素分類置信度,其輸出通道數為1。所以本文提出的文字區域檢測模塊整體輸出通道數為7,相比于RetinaNet的檢測模塊,計算資源使用量下降了99%。為了進一步節省計算資源開銷,在多個分支間共享卷積層。
綜上可知,本文提出的文字區域檢測模塊更為輕量,這有利于模型在計算資源有限的硬件環境下運行。
2.1 特征提取網絡和特征金字塔網絡
本文模型采用ResNet-50[9]作為主干特征提取網絡。該網絡由多個殘差模塊組成,共生成多個原始特征圖,分別可記作C1、C2、C3、C4、C5,每個原始特征圖的步長對應為2、4、8、16、32。因為卷積神經網絡生成的不同尺寸的特征圖具有不同特征信息,網絡淺層特征圖尺寸較大,保留了較多圖像原始位置信息,網絡深層特征圖尺寸較小,具有更抽象的特征語義信息,因此使用特征金字塔網絡[10]將相鄰特征圖進行融合,得到同時具有豐富位置信息和抽象語義信息的融合特征圖。
特征融合的具體實現直接采用了文獻[7]所述方法。選取C3、C4、C5作為基礎特征圖,步長分別為8、16、32。首先對C5施加卷積核尺寸為3、步長S為1、Padding為1的卷積運算,即可得到同尺寸大小的P5。以P5為輸入,進行一次卷積核尺寸為3,步長S為2的卷積運算,即可得到P6,P7由P6反復此計算過程并施加ReLU作為激活函數得到,二者步長分別為64和128。將P3和P4統一記作Pi,具體地,首先對Pi+1進行上采樣運算,令其尺寸等于Ci,并且將二者疊加,最后通過卷積運算進一步融合特征。數學公式如下所示:
Pi=Conv(Ci⊕Upsample(Pi+1))
(1)
式中:Conv(·)表示卷積核大小為3×3的卷積運算;Upsample(·)表示上采樣運算。至此即可得到融合特征圖P3、P4、P5、P6、P7,尺寸分別為輸入圖像的1/8、1/16、1/32、1/64、1/128,并且通道數統一設置為256。這些具有豐富語義信息的融合特征圖將被用作檢測模塊的輸入,用于檢測候選文字區域。
2.2 像素預測分支
場景文字圖片中的像素可以被分為兩類。處于文字區域中的像素被視作文字像素,其余為背景像素。像素分類分支用于對輸入圖片中的像素點進行二分類,以文字像素為正例,背景像素為反例。
因為本文所設計的檢測模塊在多個不同層次的特征圖之間被共享,而且每個特征圖具有不同的尺寸大小,相對于原始輸入圖片的步長不同,所以需要將不同特征圖上的每一個位置映射回原始輸入圖片。具體地,融合特征圖可以被統一地表示為Pi∈RHi×Wi×C,另外記Hi和Wi分別為其長和寬,C為通道數量,此處設置為256,并記其步長為Si。對于Pi上的任意給定位置(x,y),其所對應的原始輸入像素點坐標為(x′,y′),二者之間的映射方式如下:
(2)
針對場景文字圖片中不同類別像素比例極為不均衡的問題,采用Focal Loss[7]作為分類損失函數,具體計算公式如下所示:
(3)
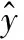
2.3 距離回歸分支和角度回歸分支
為了定位文字像素所在的文字區域,使用距離回歸分支預測像素點與其所在文字區域邊界的距離,角度回歸分支預測該文字區域的傾斜角度。此處采用RBOX標簽生成方法[4],如圖3所示。對于任意文字區域,計算其最小外接矩形框區域。對于文字區域內的任意像素,其同樣位于對應矩形框區域內。計算文字區域內每個像素點到矩形框上下左右四邊界的距離,記作(t,r,b,l),作為距離回歸分支的學習目標。通過三角函數計算,可以得到矩形框的旋轉角度θ,作為角度回歸分支的學習目標。場景文字圖片中的文字區域可能會有重疊,對于處在重疊區域的像素點,設定其回歸目標為具有相對較小尺寸的文字區域。

圖3 RBOX標簽生成方法
距離回歸分支采用IoU Loss作為損失函數,具體形式如下:
(4)
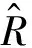
(5)
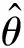
Lreg=Ldist+λθLθ
(6)
式中:λθ用于控制二者比例,實驗將其設置為10。
2.4 中心度預測分支
場景文字具有較大的長寬比,對于任意給定的文字區域,其中心位置的像素點感受野分布相比其他位置更為均勻,邊界距離回歸目標更為平衡。受FCOS[11]啟發,本文提出中心度預測分支,用于度量像素點相對其所在文字區域中心位置的偏離程度,其標簽生成公式如下:
(7)
式中:t、b、l、r分別為像素點距上下左右四邊界的距離。式(7)可知,越靠近文字區域中心的像素點,由于其到上、下邊界的距離相近,到左、右邊界的距離相近,則對應的中心度得分越高,反之則越低。中心度回歸分支使用Binary Cross Entropy作為損失函數,其具體形式如下:
(8)
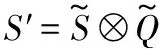
(9)
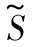
2.5 模型優化目標函數
模型采用多任務學習策略進行訓練,整體優化目標函數計算公式如下:
L=Lfl+λ(Lreg+Lcent)
(10)
式中:λ是比例因子,用于控制二者在整體損失中的比重。在實驗過程中,λ設置為1。
2.6 分層學習策略
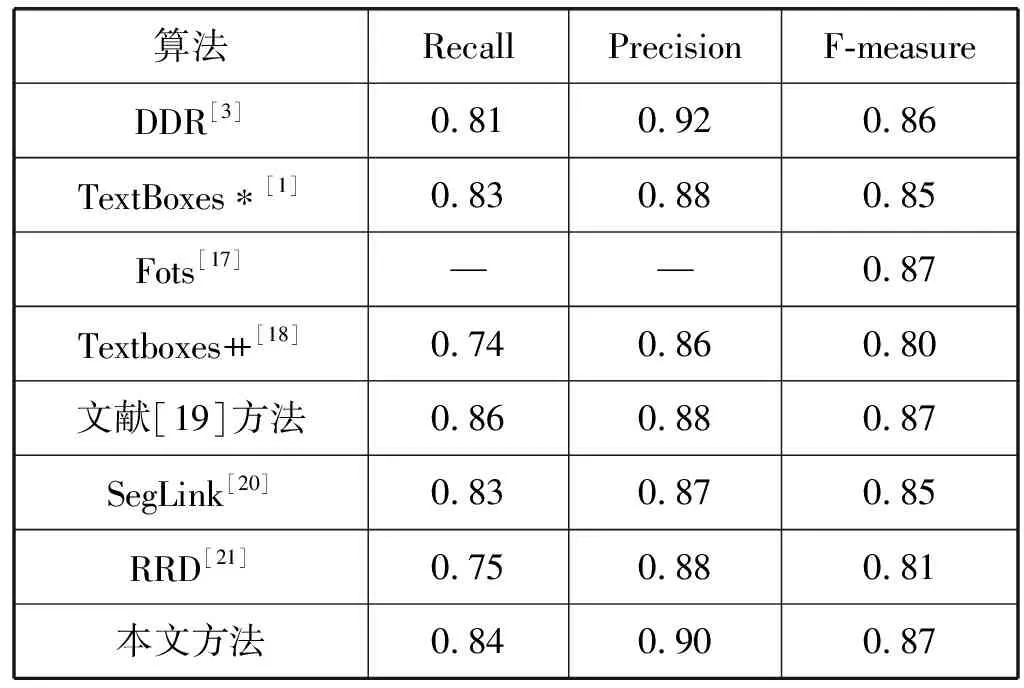
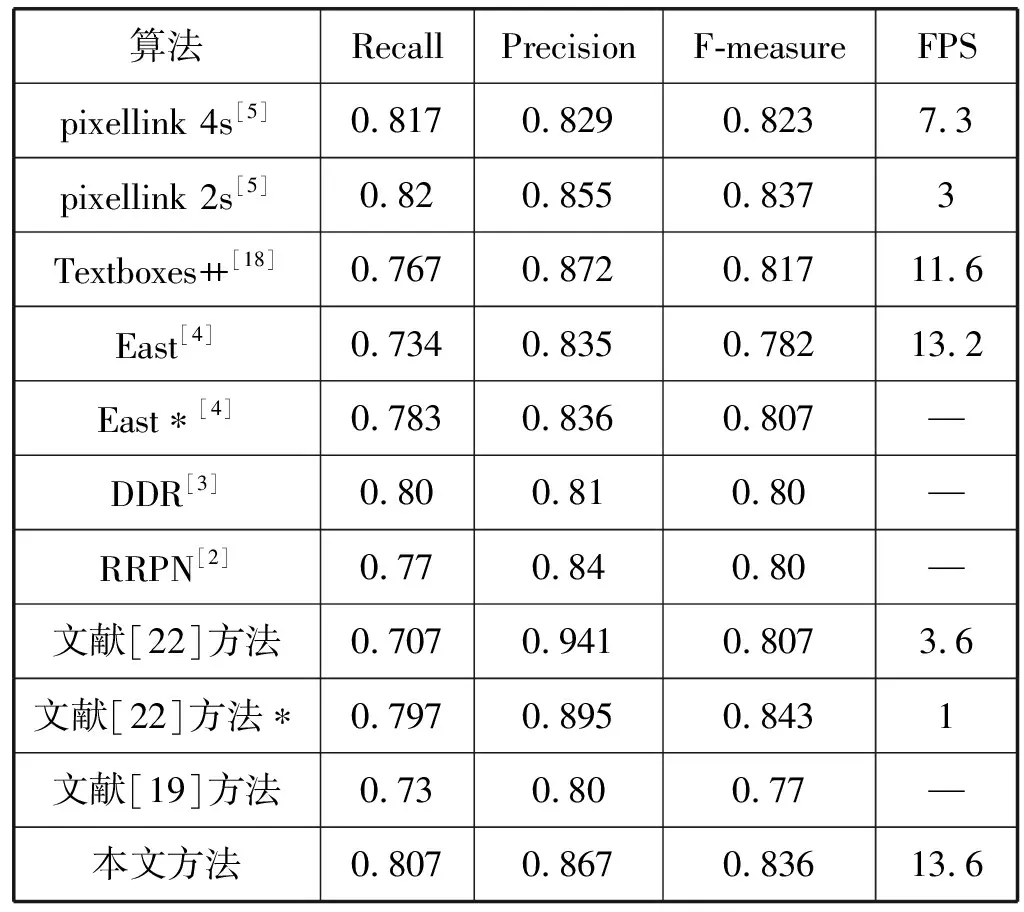
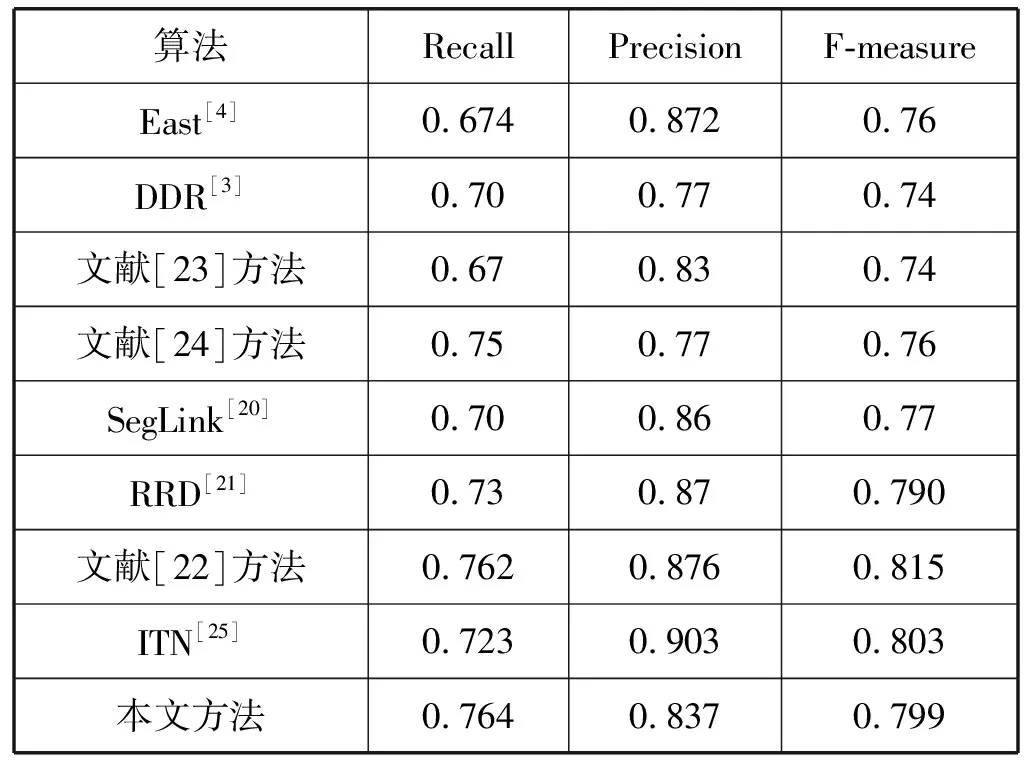
針對場景文字區域大小不一、尺度變化較大的問題,提出按文字區域大小為依據的分層學習策略。神經網絡模型淺層特征圖的感受野較小,有利于學習小目標區域,深層特征圖具有更大的感受野,常被用于學習大目標區域。具體地,記每個像素點對應的最大邊界回歸目標k=max(t,r,b,l),設融合特征圖Pi最大可接受回歸距離為mi,若有mi-1≤k 為了驗證本文方法的有效性,實驗分別在ICDAR-2013[12]、ICDAR-2015[13]和MSRA-TD500[14]數據集上進行了性能驗證。 ICDAR-2013數據集由227幅訓練圖片和233幅測試圖片構成,其中文字區域多為水平方向,文字內容以英文為主,圖片內容清晰,常用于驗證模型的基本性能。ICDAR-2015數據集共包含1 500幅圖片,其中1 000幅用于訓練,其余500幅構成了測試集。該數據集由Google Glass拍攝,包含大量聚焦模糊的圖片,文字內容包含中英雙語,其中的文字區域尺度變化大,具有明顯的方向性,可以用于驗證本文模型能夠處理多方向及不同大小文字區域的能力。MSRA-TD500數據集的訓練集包含300幅圖片,測試集有200幅圖片。該數據集的主要特點是其以行作為標注單位,包含中英雙語文字內容,且文字區域長寬比大,適用于驗證本文所述模型處理大長寬比文字區域的能力。 本文模型在上文所述各數據集上測試效果如圖4所示。可以看出,該模型在應對各種尺度大小、任意方向的文字區域時,具有令人滿意的檢測效果。針對較為密集的文字區域,或存在重疊的文字區域時,也能夠正確進行處理。 (a) ICDAR-2013文字檢測結果 (b) ICDAR-2015文字檢測結果 (c) MSRA-TD500文字檢測結果圖4 文字檢測效果圖展示 本文所述模型使用maskrcnn-benchmark[15]框架進行開發工作,開發語言為Python,使用一塊Nvidia 1060 6 GB顯卡對模型進行訓練。在實驗過程中,因硬件條件限制,調整圖片尺寸大小令最大邊長不超過800,并將batch size設為4,以最大程度利用顯卡計算資源,并且對輸入圖片進行隨機的翻轉、旋轉、拉伸等操作,以達到數據增廣的目的,將變換后的圖片用作模型輸入。訓練過程中,使用隨機梯度下降算法(SGD)對模型進行優化,為了讓模型優化過程能夠穩定地進行,將初始學習率設為0.001,weight decay設置為0.000 5。除此之外,以實驗結果指標為依據,調整融合特征圖Pi能夠接受的最大歸回距離mi,具體地,m2、m3、m4、m5、m6、m7分別設置為0、48、96、192、384和∞。 Zhan等[16]提出了一個人工合成數據集,該數據集由10 000幅添加有隨機文字區域的圖片構成,該類數據集常被用于對模型進行預訓練,以加速模型收斂。在模型訓練階段,首先使用該數據集訓練模型100個周期。在此基礎上,使用上文中所述三個不同的數據集分別在其上進行微調,直到損失函數無明顯的變化時停止訓練過程。 本文方法在上述三個數據集上取得的測試效果如表1、表2和表3所示,表內*表示多尺度檢測。 表1 ICDAR-2013數據集結果對比 表2 ICDAR-2015數據集結果對比 表3 MSRA-TD500數據集結果對比 在ICDAR-2013數據集上,準確率、回歸率、F1分數分別取得了0.90、0.84、0.87,檢測結果性能與現有方法具有可比性,證明該方法具備處理基本自然場景文字區域的能力。 在ICDAR-2015數據集上不僅測試了模型的檢測效果,還測試了模型的運算速度。實驗結果表明,該方法能夠在一秒內處理大約13.6幅輸入圖片,說明了模型設計過程中所提出的一系列節省計算資源開銷的方法的有效性,能夠有效地提高模型整體運算速度。準確率、回歸率、F1分數分別為0.867、0.807、0.836,表明該方法能夠處理環境復雜的文字區域。具體地,該方法計算資源使用小,運行速度快,且具有優秀的檢測效果,說明該方法具有更好的實用性,能夠滿足某些對運行速度要求的應用場景。 最后,在MSRA-TD500數據集上,該方法分別取得了0.837、0.764、0.790的準確率、回歸率和F1分數,表明該方法具有處理具有顯著長寬比的文字區域的能力。 另外還在該數據集上驗證了本文所提中心度分支的有效性。在測試階段,去除式(9),直接使用分類分支預測的輸出作為預測文字區域的置信度。準確率、回歸率和F1分數分別為0.824、0.748、0.784,與啟用中心度分支的測試結果相比有微幅下降,表明本文所引入的中心度分支能夠提高模型檢測結果的質量。 本文所提多尺度檢測方法,將EAST算法[4]作為基線參考模型。從上述三個實驗結果對比可知,本文所提方法在檢測效果上均取得了更好的評價指標。 為了驗證Focal Loss的有效性,修改本文模型設計,采用EAST方法中的設置,使用OHEM方法平衡正負樣例個數,正負比例設置為1 ∶3,并且使用Balanced Cross Entropy作為像素分類損失函數,其具體形式如下: (11) 模型性能的提升從評價指標和運行速度兩方面進行分析。通過采用分層學習策略,將不同文字區域劃分到具有不同語義的融合特征圖上進行學習,減緩了文字區域尺度大小顯著的問題;采用Focal Loss作為分類損失函數,減緩了樣例類別不平衡對模型學習的影響程度,并且令模型在學習過程中更多地關注困難樣例;引入的中心度分支能夠對候選文字區域置信度進行二次調整,有效地抑制了邊緣檢測不完整的區域。因此實驗中本文模型具有很好的評價指標性能。該方法設計的文字區域檢測模塊設計輕量,并且在多個融合特征圖之間共享使用,降低了計算資源使用的增加量;使用Focal Loss替代在線困難樣本挖掘方法,避免了中間處理過程,減少了內存使用;模型在整體計算過程中無需錨框,不僅消除了錨框匹配過程,也消除了因錨框而產生的內存消耗。模型整體結構簡潔,后處理過程僅使用標準的非極大值抑制算法。因此,該方法相比于現有方法更快。 針對自然場景中文字區域尺度變化顯著的問題,提出了依據文字區域大小進行學習分配的分層學習策略,針對文字區域長寬比較大的問題,提出了中心度分支,針對文字區域圖片中像素樣例類別嚴重不均衡問題,提出了使用Focal Loss作為分類損失函數。在多個數據集上對模型的有效性進行了驗證,實驗結果表明,本文方法相比于先前方法有所提高,且本文方法整體過程簡潔,無中間處理過程,后處理過程簡單,整體計算資源開銷小,運行速度更快,因此具有更好的可用性。本文方法改進空間如下:(1) 針對小字體區域和復雜字體區域的檢測效果尚顯不足;(2) 分層學習策略采用了啟發式方法,該方法不一定將文字區域分配到最佳融合特征圖上,后續工作可依據上述兩點展開。3 實 驗
3.1 數據集



3.2 實驗細節
3.3 實驗結果展示
3.4 模型性能分析
4 結 語
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
