基于多尺度復合金字塔模型的緩存策略研究
2022-03-16 03:36:44王志寶陳良富
計算機技術與發展 2022年2期
王 賀,王志寶,陳良富,趙 亮
(1.東北石油大學 計算機與信息技術學院,黑龍江 大慶 163318;2.中國科學院空天信息創新研究院遙感科學國家重點實驗室,北京 100000)
0 引 言
網絡地理信息系統(WebGIS)是網絡和地理信息系統的結合,以互聯網協議和終端為基礎形成的客戶端地理信息應用系統,與人們的日常生活密不可分。傳統的WebGIS系統通過客戶端向服務器發送地理信息相關的請求,服務器收到后將相應的數據返回給客戶端。該方法受網絡速度和服務器配置的影響,存在響應時間長、渲染效率低的缺點。為了提高客戶端顯示效率,構建金字塔模型是重要的解決方案,在不影響畫面視覺效果的同時,構建不同分辨率的多級數據來提高繪制速度,節省繪制所需時間。構建金字塔模型的關鍵環節是對空間數據進行組織,經過組織后的瓦片數據可以提升檢索效率。
在大數據時代,由于瓦片數據的海量特性和用戶規模的不斷增長,仍然存在網絡擁塞、服務器過載等問題。通過研究瓦片緩存策略,以讀取緩存數據的方式來減少對服務器的請求數量,可以在數據組織的基礎上減輕服務器和網絡傳輸的壓力。因此,改進現有的瓦片緩存策略對網絡地理信息系統具有重要意義。
在瓦片金字塔的基礎上,該文提出了一種多尺度復合金字塔模型。與傳統的瓦片金字塔模型相比,它可以統一組織和管理多種類型數據。并在此基礎上提出了一種基于多尺度復合金字塔模型的緩存置換策略(multi-scale compound pyramid cache replacement),相較于現有的瓦片緩存算法,進行了如下優化:(1)支持加載多種類型數據;(2)考慮瓦片數據的空間特性,根據用戶操作習慣,動態計算當前命中瓦片相鄰及相鄰層級瓦片數據的請求頻次;(3)引入瓦片保護機制。在瓦片進入到緩存空間后,一段時間內無法被置換。這種方式可以有效解決當緩存空間已滿時,新進入到緩存空間的瓦片數據由于價值最低而被置換的問題。
1 構建多尺度復合金字塔模型
對多種類型數據進行組織,傳統的做法是將多種類型數據單獨建立索引,建立不同的金字塔模型以分開管理。采用這種方式金字塔的構建效率低、管理難度大。所以該文提出了一種能夠統一管理各類數據的多尺度復合金字塔模型,如圖1所示。
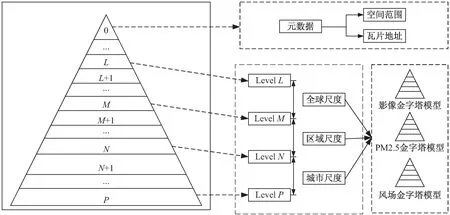
圖1 多尺度復合金字塔模型
多尺度復合金字塔模型從金字塔的底層到頂層,分辨率逐漸降低,包含了全球、區域、城市三個尺度數據,在不同尺度下又由多種類型數據共同組成,且多種類型數據在相同層級下表示的地理范圍一致。
在多尺度復合金字塔模型中,在每種尺度下分別定義1個層級作為實際物理儲存層級,負責儲存該尺度范圍內的所有信息。如圖2所示,地理空間共分為P
個等級,其中L
級至M
-1級為全球尺度;M
級至N
-1級為區域尺度;N
級至P
-1級為城市尺度。將多種類型數據根據三個尺度進行重新組織,并分別選擇L
級、M
級、N
級存儲該尺度下的元數據信息。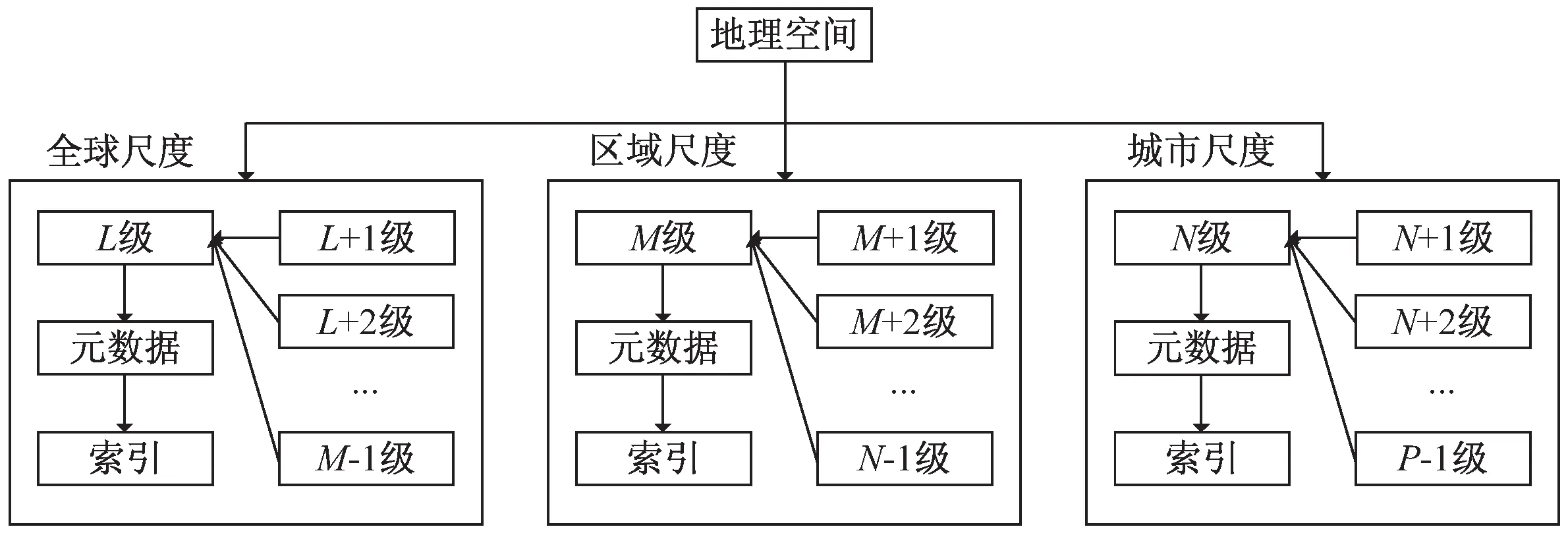
圖2 多尺度組織模型示意圖
多尺度復合金字塔模型本質上是利用地理空間劃分將同一尺度下不同類型元數據存儲到統一的存儲單元或單元組中,根據索引實現以空間區域為基礎的文件組織管理體系。采用這種數據組織與管理技術可以將用戶訪問數據的空間區域位置與數據文件本身表達的空間區域位置建立直接關聯,提高了海量數據的尋址檢索。
2 瓦片緩存機制
傳統的緩存置換算法主要有:先進先出置換算法(FIFO)、最近最少使用瓦片置換算法(LRU)、最不經常使用置換算法(LFU)。國內外學者針對瓦片數據緩存算法做了較多研究,Kang等對瓦片預取和替換方式進行了研究,根據計算結果留下概率高的瓦片;在此基礎上,張婷婷提出了基于時空熱度的瓦片緩存置換策略,可以快速傳輸影像數據;Hsiao等將多核gpu共享緩存中的瓦片進行分組,提出了一種基于多核位置感知的緩存置換算法(MLCR);史孝國通過考慮瓦片的訪問頻率及瓦片數據大小計算瓦片的保留價值,對置換算法進行了改進;涂振發等提出了一種最小空間數據價值緩存置換算法(GDLVF),基于時間、頻率及空間位置計算瓦片價值,將價值最低的瓦片置換;劉佳星等提出了基于地理單元熱度的瓦片緩存置換算法(GUH),通過考慮空間特性,結合貪婪算法置換出熱度值最低的瓦片;陸曄等研究了基于主題時空價值的瓦片緩存算法(GDTST),綜合考慮了時間局部性、空間局部性以及用戶主題傾向性,置換出主題時空價值最低的瓦片。傳統的緩存置換算法沒有考慮到瓦片數據的空間位置特性,瓦片命中率效果較差;傳統的緩存置換算法只考慮了瓦片進入緩存時間及命中次數,瓦片命中率較差。在上述研究中,依然存在如下三個問題:(1)緩存置換策略都是基于同一類型數據進行研究,不適用于多種類型數據進行加載;(2)部分研究人員雖然考慮了空間位置特性以及請求瓦片對下一時刻其鄰近位置瓦片被訪問造成的影響,但是在進行研究時沒有考慮用戶的操作習慣,請求瓦片對臨近位置瓦片影響相同;(3)未設置保護機制,新進入緩存的瓦片由于價值低可能會很快被置換出去。
因此,該文提出了一種基于多尺度復合金字塔模型的緩存置換策略MCPCR。MCPCR滿足多種類型數據在客戶端進行緩存,并充分考慮瓦片數據的空間特性,根據用戶操作習慣,動態計算當前命中瓦片相鄰及相鄰層級瓦片數據的請求頻次,當瓦片數據進入緩存時,計算當前瓦片數據價值,當緩存空間已滿或達到閾值時,緩存空間中價值最低的瓦片將被替換。同時引入瓦片保護機制,在瓦片進入到緩存空間后,一段時間內無法被置換,避免當緩存空間已滿時,進行置換操作時將新進入到緩存空間的瓦片數據剔除。
2.1 瓦片緩存索引設計
當用戶在客戶端請求數據時,首先要在緩存中查找是否存在相關數據,因此,為了實現緩存中數據的快速檢索,需要對緩存索引進行設計,從而提高數據檢索速度,本次研究基于多尺度復合金字塔模型設計了索引機制。
服務器端為已經組織好的多分辨率層級的復合瓦片金字塔模型。當客戶端請求相應數據時,當縮放層級為Z時,獲取到當前顯示區域中心點的地理坐標Center(X
,Y
);根據屏幕寬度W
,屏幕高度H
,以及瀏覽器顯示的單位像素表示的實際地理距離D
,以屏幕左下角為原點,計算屏幕左下角(X
,Y
)及屏幕右上角(X
,Y
)地理坐標:
根據請求數據類型以及在該層級下地理范圍對該類型瓦片數據行列號進行轉換,并向復合金字塔模型中請求相應數據,將查詢到的數據向客戶端進行傳遞。
瓦片金字塔模型中瓦片的生成都是先將柵格數據或矢量數據進行切片,生成瓦片矩陣后再通過分級分塊的方式構建多尺度瓦片矩陣集,每張瓦片通過層級與行列號唯一確定。本次研究是對多尺度復合金字塔模型進行研究,具有多種類型瓦片數據,因此做出如下定義:
定義1:多尺度復合金字塔模型包含多種類型數據瓦片金字塔模型,每一張瓦片都可以通過數據類型、層級及行列號唯一確定。TileID代表多尺度復合金字塔模型的瓦片索引值,可以表示為:
TileID=(Type,Layer,Row,Column)
其中,Type表示瓦片數據類型,Layer表示該類型瓦片數據所在層級號,Row表示瓦片在該級下的行號,Column表示瓦片在該級下的列號。為了加快數據定位速度,索引項TileID采用哈希存儲。基于多尺度復合金字塔的瓦片索引結構為:
Index=(TileID,Value,Size,Frequency,
LastTime,TimeInterval)
其中,Value表示當前瓦片的價值,Size表示瓦片所占空間的大小,Frequency表示該瓦片的請求頻次,LastTime表示瓦片上一次被請求時間,TimeInterval表示瓦片最近兩次被請求的時間間隔。
2.2 MCPCR策略
MCPCR策略,當緩存空間已滿或達到閾值時,置換出過了保護期限且價值最低的瓦片數據。其中瓦片價值為:
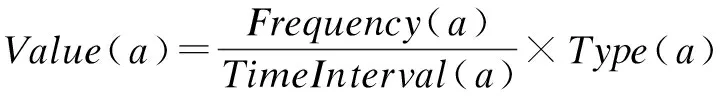
其中,Frequency(a)表示基于用戶操作習慣的空間訪問頻次,TimeInterval(a)表示當前瓦片的歷史平均訪問間隔,Type(a)表示數據類型權重。
用戶在客戶端最常用的操作是平移操作和縮放操作。圖3所示為瓦片相鄰范圍示意圖。
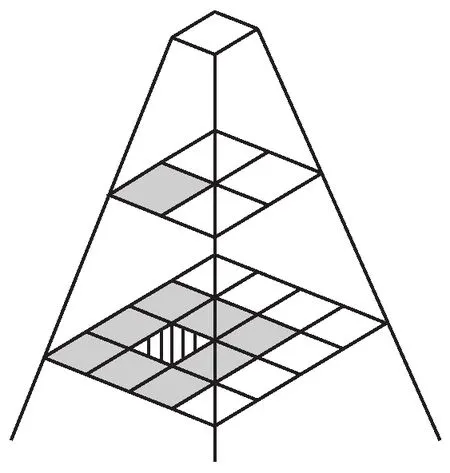
圖3 瓦片相鄰范圍示意圖
當用戶操作為平移操作時,可以從上、下、左、右、左上、左下、右上、右下八個方向請求瓦片數據;當用戶進行縮放操作時,有放大操作和縮小操作兩種情況。放大操作是指向服務器請求當前位置高層級數據;縮小操作是指向服務器請求當前位置低層級數據。也就是說,在某個時間用戶訪問了瓦片數據,附近的瓦片和相鄰級別的瓦片數據在下一次再次被訪問的概率更高。故定義瓦片的請求頻次Frequency為:
定義2:設Frequency為瓦片請求頻次。根據用戶操作歷史庫,分別記錄用戶操作up、down、left、right、upperLeft、lowerLeft、upperRight、lowerRight、upLayer、nextLayer及操作總次數T
。當瓦片被命中時,此瓦片Frequency = Frequency+1,緩存中相鄰瓦片數據及相鄰層級瓦片數據Frequency = Frequency +t
,其中t
為用戶分別在10個方向上的操作占總操作次數T
的比例。Frequency本質上是瓦片的累計訪問頻率及其相鄰范圍影響權值的總和。當瓦片被請求時,其相鄰瓦片及相鄰層級瓦片下一次被請求的概率增加,并根據用戶操作習慣將不同方向上的瓦片賦予不同的權重。
通過計算瓦片歷史平均間隔實現對瓦片數據命中在時間維度上產生的影響,同時考慮當前訪問時間間隔以及歷史訪問時間間隔。故定義歷史平均訪問間隔TimeInterval:
定義3:設TimeInterval為歷史平均訪問間隔,CurrentTime表示當前瓦片訪問時間,LastTime表示瓦片上一次訪問時間,TimeInterval表示瓦片最近兩次被獲取的時間間隔,H
為歷史訪問權重,C
為當前訪問權重。TimeInterval公式為:TimeInterval=[TimeInterval×H
+(CurrentTime-LastTime)×C
]其中,H
與C
的和為1,當H
的越大時,認為歷史訪問間隔對瓦片請求的影響越大。由于數據類型多樣,針對緩存置換策略的制定需要考慮到數據類型權重,同時考慮到瓦片單個數據大小,對數據類型權重進行定義:
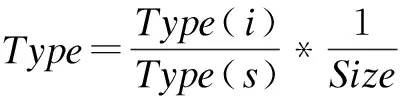
其中,Type(i)表示訪問的某一類型數據總和,Type(s)表示訪問瓦片全部類型的總數量,并考慮瓦片大小對于緩存置換的影響,單個瓦片數據量越大,影響度越低,當緩存空間已滿時,優先置換出數據較大的瓦片。
為了避免在緩存空間已滿,新進入的瓦片由于價值最低,下一次置換操作時被移除,引入瓦片保護機制,也就是說,瓦片數據在剛剛進入緩存空間的一段時間內不能被替換。故定義瓦片保護時間ProtectTime:
定義4:設瓦片保護時間為ProtectTime,瓦片數據進入到緩存空間后初始化ProtectTime,進入保護期,并隨著時間的增加不斷減小,當ProtectTime為0時,保護期結束,瓦片保護時間為ProtectTime=ProtextTime -Time。
其中,Time為當前時間與瓦片進入到緩存空間的時間差。
2.3 MCPCR算法流程
(1)新的瓦片數據進入緩存空間時,需要初始化瓦片信息,包括瓦片類型Type,層級Layer,行列號Row、Column,價值Value以及保護時間ProtectTime;
(2)判斷緩存空間能否容納新瓦片,當緩存空間充足時,將瓦片存儲在緩存空間中并執行步驟(3);當緩存空間不足時,則執行步驟(5);
(3)將瓦片數據發送至客戶端,同時得到該瓦片相鄰瓦片數據信息及相鄰層級瓦片數據信息,將已經在緩存空間中的瓦片數據執行步驟(4),否則一次性從服務器中獲取所有瓦片;
(4)更新緩存中瓦片價值Value;
(5)判斷ProtectTime是否為0,若已經為0,說明已經過期,同時不再更新;若不為0,則繼續更新;
(6)計算緩存空間中保護機制過期且價值最低的瓦片,按順序進行移除直至緩存空間充足;
(7)MCP算法結束。
3 實驗與分析
3.1 實驗環境
實驗通過Fiddler采集客戶端獲取瓦片日志數據,根據獲取到的瓦片數據計算用戶操作,模擬用戶瓦片數據操作記錄,共計1 267 154條記錄。其中最大的瓦片大小為48.4 KB,最小的瓦片大小為232 B。實驗環境為Intel(R) Core i5-8300H @ 2.30 GHz,4核CPU,12 GB內存。根據用戶請求記錄,獲得瓦片的類型、層級、行列號、大小及時間等數據,模擬用戶在客戶端的行為。
在MCPCR算法中,需要設置歷史訪問權重H
以及當前訪問權重C
,通過實驗測試,當歷史訪問權重設置為0.7,當前訪問權重設置為0.3時,實驗效果較好。實驗共由兩個部分組成,首先分別選取三種數據類型單獨進行實驗,第二部分同時選取三種類型數據進行實驗,統計緩存空間中的字節命中率及瓦片命中率,并與傳統緩存策略FIFO、LRU、LFU進行對比。3.2 實驗結果與分析
將用戶請求的日志結果分別設為數據集a、b、c、d,其中數據集a、b、c僅包含單一類型數據,數據集d包含a、b、c數據中三種類型數據。在設置客戶端緩存大小為20 M、40 M、60 M、80 M、100 M時,利用FIFO、LRU、LFU、MCPCR四種緩存置換策略進行模擬調度。比較相應的字節命中率及瓦片命中率,圖4中(a)、(b)、(c)、(d)分別代表數據集a、b、c、d字節命中率點線圖,圖5中(a)、(b)、(c)、(d)分別代表數據集a、b、c、d瓦片命中率點線圖。
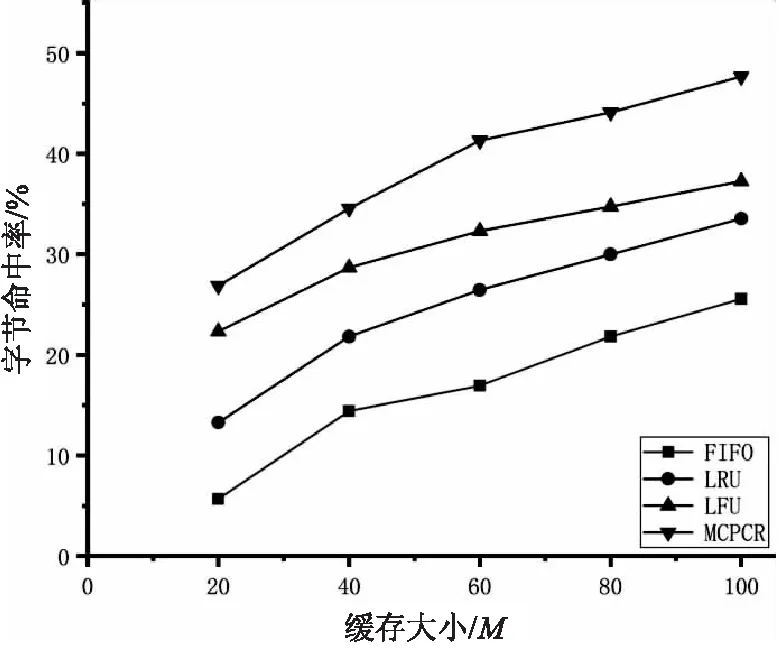
(a)數據集a字節命中率
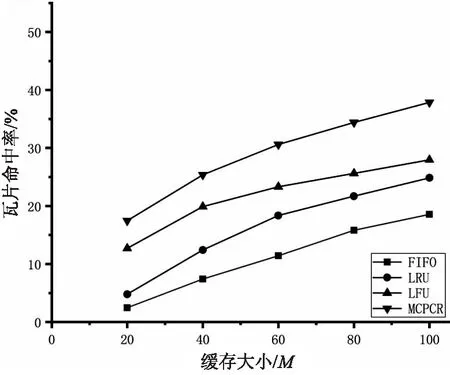
(a)數據集a瓦片命中率
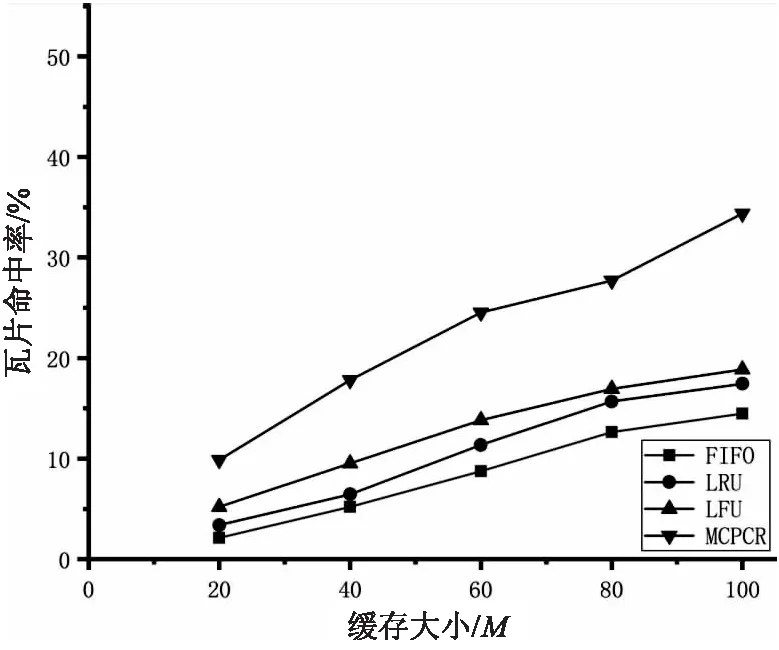
(d)數據集d瓦片命中率
通過實驗可知,在三種不同的數據集下,四種緩存置換策略的命中率都會隨著緩存空間大小的增加而逐漸增加,曲線最終趨近于平緩。由四種緩存置換策略進行對比可知,在對單一類型數據加載時,FIFO緩存置換策略命中率最低,LRU緩存策略淘汰最后被訪問時間最久的數據,要優于FIFO,LFU緩存置換策略能夠避免LRU周期性或者偶發性的操作導致緩存命中率下降的問題,整體優于LRU,MCPCR由于在考慮時間和空間因素的基礎上,引入用戶操作習慣因素及保護機制,在不同緩存空間大小下的命中率要優于其他三個緩存置換策略。在對不同類型數據進行加載時,傳統緩存置換策略命中率下降明顯,MCPCR依舊能夠保持良好的緩存命中率,通過實驗證明,MCPCR策略能夠有效支持多種類型數據同時進行緩存,并能夠有效提升緩存命中效率。
4 結束語
該文提出了一種多尺度復合金字塔數據組織模型,能夠有效地組織和管理不同類型的瓦片數據。基于該模型,設計了瓦片緩存索引。考慮到用戶的操作習慣、歷史訪問對瓦片價值的影響并引入瓦片保護機制,提出了一種基于多尺度復合金字塔模型的緩存替換策略MCPCR。實驗結果表明,對同一種瓦片數據類型進行加載時,MCPCR在不同大小的緩存空間中命中率均優于其他幾種算法,在對多種類型瓦片數據進行加載時,MCPCR仍然能夠保持良好的命中率。可以有效支持不同類型瓦片數據加載,從而提高用戶的響應速度。
猜你喜歡
遼河(2025年7期)2025-07-25 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
揚子江(2019年1期)2019-03-08 02:52:34
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
