工程地質資料檢索系統的設計和應用
2022-03-16 03:59:14朱泳標
計算機技術與發展 2022年2期
楊 科,朱泳標,李 娜
(中鐵二院工程集團有限責任公司,四川 成都 610031)
0 引 言
鐵路工程地質勘察階段中會產生大量資料,這些資料在施工建設期作為線路、路基、橋梁、隧道等專業設計依據之一,同時是鐵路工程項目的關鍵基礎資料。圍繞鐵路工程地質資料一體化、標準化建設已持續多年,隨著鐵路工程建設項目穩步增長,資料數量逐年增加,對資料的查閱暴露出響應速度慢、資料類型繁多、格式不統一等問題,傳統的歸檔查詢已經越來越難以滿足管理和使用要求,利用信息化前沿技術,對傳統的查詢系統進行智能化改造已經刻不容緩。分布式檢索平臺是大數據生態圈中重要的組成部分,依托分布式橫向擴展和倒排索引技術,不僅支持處理PB級海量數據檢索,還能提高檢索效率,將耗時控制在毫秒級。該文借助分布式檢索平臺,對工程地質資料查詢過程中的難點、痛點進行問題分析,并通過大數據優化設計,實現了一套工程地質資料檢索系統。
1 問題描述
1.1 檢索資料的廣度問題
工程地質專業主要為設計專業提供基礎數據,傳統上,地質人員通過模板整理資料,并提交給其他專業設計人員。設計人員在參考資料的時候,按照習慣和模板約束,在眾多資料里逐層手動搜索,找到想要的文檔或圖像。在數據量大的情況下,這種方式效率較為低下,對于設計人員而言,所有資料應該是一種“平面化”的數據,自己只需要輸入搜索關鍵字,就能從這些平面化數據中得到想要的結果。
例如想搜索某條線路里某段范圍內的“風化帶”資料,那么包括“風化帶”的所有資料應該以評分高低返回給用戶,評分越高的資料代表其更接近用戶的檢索意圖。但現實是,工程地質資料分為地質說明書、地質平面圖、縱橫斷面圖、試驗結果表等類型,包括了Office、AutoCAD、PDF、文本文件、圖像等多種格式,要在此多源異構、非結構化的數據背景下,完成海量數據檢索,且結果要高度貼合用戶意圖,就需要在“平面化”資料一側覆蓋所有文件格式,將其轉換、加載為文本。在檢索引擎一側支持服務的水平擴展,為海量數據的實時檢索提供基礎支撐。
1.2 檢索資料的深度問題
對地質資料的檢索和應用還存在更深層次的挖掘問題,即怎么從簡單的資料里獲取更多的信息,比如加入位置信息能夠方便用戶從地圖上直觀發現該資料,加入線路和工點信息則幫助用戶縮小檢索范圍,從而提高檢索的效率、精度。從信息論的角度來看,更多的信息,能使檢索的不確定性減少。增加信息量的方式,就是挖掘隱藏在已有資料之間的上下文信息。資料原作者在編寫過程中,存在沒有明確寫入事件發生的地點和時間的情況,究其原因可能是當時編寫環境就暗含了這些信息,也可能是資料存儲的路徑包含了這些信息,但是隨著文件上傳到中心平臺,被分布式系統分塊、冗余到各個服務器后,上下文信息在轉移過程丟失。檢索資料的深度問題,即如何利用技術手段和分析算法還原這些信息的問題。
1.3 檢索資料的存儲問題
工程地質資料通常存儲在磁盤陣列(RAID)上,依靠RAID的冗余能力實現資料的妥善存儲。但是在對數據進行挖掘和分析的情況下,磁盤陣列和分析系統位于不同的I/O會導致傳輸量大、延遲高等問題,海量數據則會將該問題更加放大。另一方面,需要基于RAID搭建文件服務,在用戶檢索到某份資料并想下載的時候,需要從業務服務切換到文件系統服務,進一步增加了延遲,影響用戶體驗。
2 設計實現
為了解決上述問題,該文設計和實現了基于分布式檢索引擎的工程地質資料檢索系統,重點解決了從海量異構資料中結構化文檔資料、挖掘隱藏信息,并將原始資料妥善存儲在檢索系統內部的問題,提供了一個用戶友好、性能強大的資料檢索解決方案。
2.1 搜索引擎選型
Elasticsearch是一個基于Apache Lucene的分布式搜索引擎,它在Lucene支持的功能之上,提供了在節點管理、節點發現、建索引、查詢的功能,并提供了對開發友好的 REST API,能夠較快實現多源異構數據的交換。Elasticsearch采用倒排索引技術,詞組全文檢索的準確度、效率都遠高于同類產品,并且作為分布式原生架構,其水平擴展的配置簡單,可以做到按需擴容,即使作為單點部署,在海量數據下仍然保持高響應速度和高吞吐率。
國內已有很多學者將Elasticsearch用于各個行業,解決了很多業務系統的檢索問題。結合工程地質資料特點,以及對廣度、深度和存儲問題的綜合分析,選擇以Elasticsearch作為基礎平臺開發搭建地質資料檢索系統。
2.2 元數據設計
元數據是描述數據的數據,是數據屬性的結構化信息,為數據的挖掘提供模板。從系統分析的角度來看,元數據約束了工程地質資料應具備的信息量,也為檢索系統定義了基本的數據結構。良好設計的元數據,能夠幫助檢索縮小范圍、提高命中率。
按照用戶對資料檢索的使用習慣,結合對工程地質資料的分析,該文將元數據分為兩大類,第一類是對資料分類的描述。資料分類是本系統最大的變量,不僅新工程的納入會增加分類數量,舊有的分類也會隨著系統使用而更新關鍵字,因此,分類元數據應該設計為一個全局的、可維護的基礎字典,最終形成如表1所示的結構。

表1 資料分類元數據設計
資料分類在系統上線前,通過梳理既有資料,統計得到資料分類的關鍵詞組,再組織地質人員和相關專家對關鍵詞組進行篩選后,將篩選結果存入Elasticsearch。
第二類是對資料數據的描述,是資料在系統內部的組織方式。用戶的檢索方式不局限于文字信息檢索,還包括地圖選點等方式以位置信息搜索資料。資料數據元數據設計為如表2所示的結構。

表2 資料數據結構元數據設計
資料數據在系統上線后,通過資料上傳頁面,由用戶批量導入資料。系統將對資料進行預處理、結構化、文本挖掘,得到元數據約束的信息,并存入Elasticsearch。
2.3 資料預處理
資料預處理是對工程地質原始資料進行數據清洗和轉換的過程,以確保入庫資料的有效性。通過對各類資料的分析,發現大部分資料具備元數據要求信息量,以Word格式的“地質說明書”為例,其中包括了線路、里程和地質信息,而dwg格式的“橫斷面圖”則包括了日期、線路、里程信息,但是不少文檔仍然需要一個或者多個信息才能補全元數據結構。同時還存在少數資料,特別是一些數據緩存文件,只是作為數據計算過程的中間結果,不具備檢索的意義,應通過數據清洗將這類資料過濾掉。清洗的方法包括后綴名過濾、對文件名進行正則表達式搜索淘汰。由于地質資料這類非結構化數據需要對文件內容進行文本抽取后才能結構化,因此很難在預處理階段應用數據合法性檢查、一致性檢查等結構化的清洗方法,對數據進行補全和糾正將放在對文本進行抽取、結構化之后。
數據轉換主要針對Office文件,特別是Office 2007之前的格式,這些文件不能被腳本語言直接抽取出文字,需要轉換為docx、xlsx等格式才能被后續流程處理。預處理流程如圖1所示。

圖1 數據預處理流程
2.4 文本抽取與結構化
文本抽取是整個系統的核心,設計的難點在于需要一套運行在Linux服務器上,自動化抽取多種資料格式的集成處理程序。考慮到系統將會使用到多種前沿技術,以及對Linux系統的支持,程序由Python語言實現能夠很好地“粘合”這些不同技術。
在數據預處理流程后,地質資料可以分為四種類型,第一類是Office文檔,包括Word、PowerPoint、Excel格式。第二類是PDF文檔,主要包括圖像和文字兩大類內容。第三類是CAD文件,通常為dwg格式,主要內容包括了平面圖和縱橫斷面圖。最后一類是圖像,包括巖芯和踏勘現場圖像,這類文件不僅數據量特別大,而且對工程地質人員的工作開展有極大的幫助,是重要的工程地質資料。另外需要考慮后續應用過程中,更多的資料類型加入檢索,在設計階段,遵循對修改封閉,對擴展開放的原則,采用工廠方法模式,根據輸入文檔的格式,設計不同的工廠類處理不同的地質資料。以目前的四類資料為主,每個工廠類生成如下產品:
(1)Office文件的抽取。
Python中有多個庫可以對Office 2007以后的版本進行全文提取,而圖像、樣式等信息將會被丟棄,只獲取所有文本內容、作者和編輯時間。
(2)PDF文件的抽取。
根據對地質PDF文件的研究,發現具有文本抽取價值的文件,大多數是文本型的,在Linux中有多個可執行程序,可以將其中的文本提取出來,使用Python的subprocess庫,啟動子進程來處理PDF文件,提取出的文字存入緩存文件,再由Python腳本獲取。
(3)CAD文件的抽取。
目前已經有多個商業或開源的庫可以處理CAD文件,在Linux上可以選擇的控件比較少,libdxfrw開源了對大多數版本CAD的解析,并支持Linux上GCC編譯。編寫獨立的Linux可執行程序,調用相關函數從dwg文件對象(AcDbObject)的文本區域提取出所有文字,存入緩存文件,再由Python腳本訪問緩存文件得到文本內容。
(4)圖像的抽取。
圖像目前是處理最為耗時的一類資料。主要思路是通過目標檢測算法找到圖像中的實體,并根據這些實體能夠得到語義上的聯系。該文通過卷積神經網絡和YOLO V3訓練了地質資料中常見的一些實體,例如巖芯中的泥土、巖石、鉆孔巖芯等,生成了一個可以識別這些實體的模型。在對圖像進行處理中,首先讀取該模型對圖像中的實體進行檢測,再對檢測到的所有實體進行去重,最后根據這些實體查詢實體關系字典,得到圖像的分類。例如,一張圖像通過實體檢測,得到了多個泥土、泥巖、鉆孔巖芯框實體,通過查詢實體關系字典,這張圖像很可能就是現場的鉆孔巖芯圖。
文本抽取的類設計如圖2所示,僅以Office文件和圖像抽取為例。

圖2 文本抽取工廠方法類圖
原始文件經過文本抽取后,得到原始文本、作者、編輯時間等元數據約束的信息。還需要對原始文本結構化處理,為后續的挖掘提供關鍵字、詞頻等重要信息。但文本結構化本身是一個復雜流程,應根據待獲取的信息,將該流程分解為多個較小的子流程,逐步降低復雜度,具體流程如下:
(1)去除停用詞,利用地勘語料庫進行中文分詞,統計前20個詞頻較高的詞組并緩存。
(2)調用中文文本摘要算法進行單文本摘要,對應元數據的“摘要”信息。
(3)對原始文本進行正則表達式搜索,得到線路里程信息。里程信息通常是以CK、DK、D1K、D2K冠號開始,加上1 000以內的數字組成,由起始里程和終止里程成對出現,如DK11+123~DK15+789。原始文本中可能包括多個里程信息對,通常出現頻率最高的才是真正里程信息,但是為了防止關鍵信息丟失,所有里程文字和出現頻率作為鍵值對一起緩存,便于后續挖掘處理。
(4)對于圖像這類特殊資料,不參與分詞或摘要流程,直接將圖像抽取后得到實體名稱作為詞組緩存。
經過文本抽取和結構化后,元數據要求的大多數信息已經具備,剩下較為隱蔽的信息等待挖掘。
2.5 隱藏信息挖掘
隱藏信息是指不明確寫入資料,或者需要對資料進行多次處理后才能得到的信息。結構化后的原始文本中可能包括了線路、工點、資料類型等關鍵信息,但是存在命名不一致、二義性等問題,另外圖像資料則可能不包含上述任何信息。因此,應在結構化后應用聚類、相似度算法盡量挖掘出線路、位置等關鍵信息。
(1)時間聚類,找到資料的時間軸。
在資料中包括了眾多時間,有踏勘時間、編寫時間、匯報時間,文檔本身還具備最近編輯時間,在這諸多時間中,哪一個時間更具備參考意義。當完成文本結構化后,不妨對單個文檔進行升維,將其映射到本次上傳的所有文本中的時間維度中,因為用戶的使用習慣往往同一批文件屬于同期所做工作的匯編。然后再對所有時間進行K-means聚類,最后將單個文檔里的所有時間,與聚類各個分簇中心計算歐氏距離,距離最短的時間往往更具備代表性,能夠體現該資料在時間軸上,與同批次文件編寫的強關聯性,選擇該時間作為本資料的編輯時間。圖3表示了只對時間信息中的日期進行聚類后的結果。圖4為時間信息挖掘流程。

圖3 同批次資料內含時間信息聚類示意圖

圖4 時間信息挖掘流程
(2)坐標反算結合非極大值抑制,分析資料的位置信息。
由于工程地質資料都采用投影坐標作為項目坐標,每個項目中央子午線和投影高是不同的,必須通過坐標轉換系統,對資料的項目坐標進行坐標反算,得到其GPS坐標,這個坐標是對資料最精確的位置描述,可以直接作為位置信息進行存儲。但是很多資料并不具備項目坐標,而是里程信息,并且一個資料內含多個里程信息,在前一步驟中,已經得到了多對和多個里程作為候選信息,消除重疊的找到最佳的里程即能完善該資料的位置信息。具體做法是利用坐標轉換系統將其轉換為GPS坐標,再沿線路方向建立笛卡爾坐標系,圍繞GPS坐標形成一個矩形,每個矩形具備一個分數值,即該里程對的詞頻,如圖6所示,沿線路方向,將里程信息對轉換為左右兩個GPS坐標點,默認500米作為矩形高度,單個里程則為500米的正方形。圖中深色的矩形為當前詞頻最高的里程信息,計算剩余的矩形和該矩形的重疊區域(IOU),當IOU大于預設值,則淘汰該里程信息。再在小于預設值的里程信息里選擇詞頻最高的,進行下一次循環,如圖中可以得到兩對里程信息,其對應的GPS坐標以空格分隔存儲到“位置信息”中。

圖5 位置信息挖掘流程

圖6 非極大值抑制算法獲取最佳里程示意圖
(3)相似度算法,挖掘資料的分類信息。
在結構化處理后,已經具備了單個資料詞組到詞頻的映射,查詢Elasticsearch中的文檔分類數據,將分類中的詞組詞頻映射取出,兩者計算余弦相似度,最相似的分類即為該資料分類,最后存儲到“類型信息”中。文檔分類數據也需要定時更新維護,通過同類文檔的關鍵字的聚合,在專家的建議確認下,逐步提高模型的準確性。由圖7可見,隨著同類文檔的數量增加,單個文檔與同類文檔的相似度越來越大,雖然數量達到一定量后,相似度有所下降,這是由于更多的關鍵字加入會降低相似度,但是整體保持了較高的相似度,保證了文檔分類的準確率。
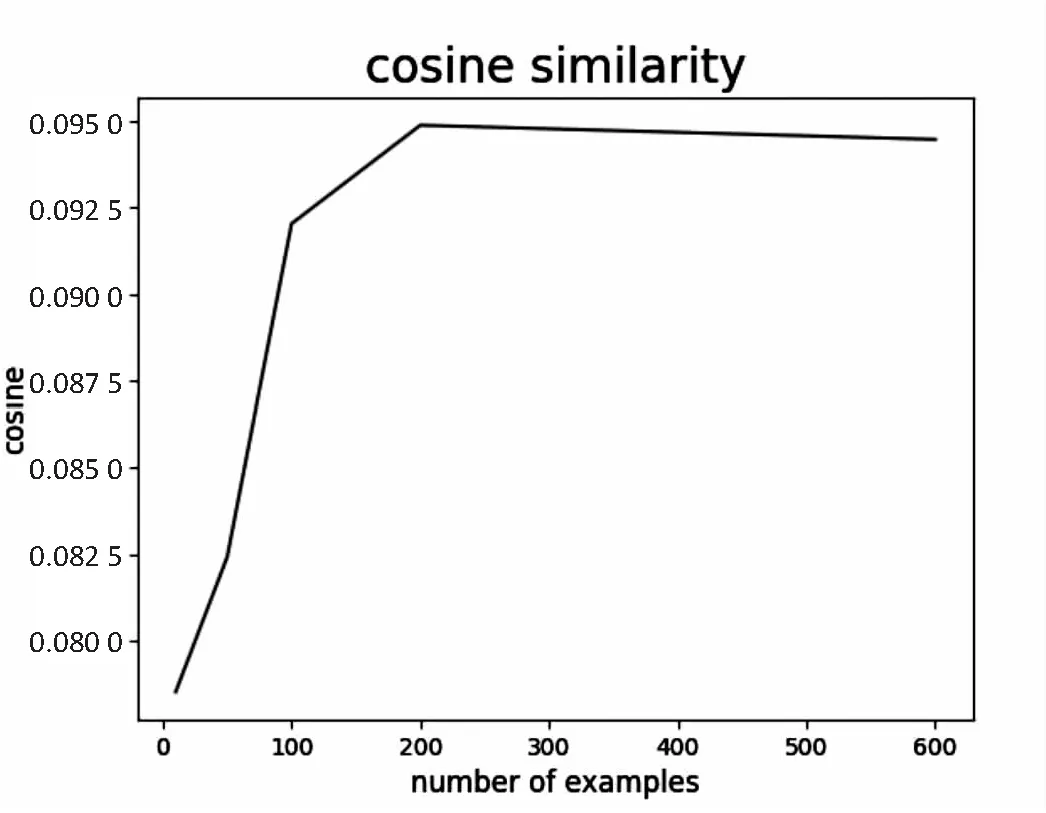
圖7 單個資料與相同分類資料的余弦相似度折線圖
在完成所有隱藏信息挖掘后,將原始文件通過BASE64編碼轉換成字符串,對應到元數據中的“原始文件”,便于用戶在檢索到該資料后,快速的解碼并下載。該方式也可以最大化利用分布式系統的性能,防止文件下載的單點故障。
3 結束語
該文引入分布式搜索引擎,結合軟件設計模式和數據挖掘方法,實現了工程地質資料檢索系統,該系統已經在中鐵二院地勘巖土工程設計研究院的多個項目組投入使用,并在兄弟設計單位中得到應用驗證。根據反饋,該系統支持資料格式多、檢索命中率高、檢索速度快、使用簡單的特點得到了用戶的肯定,從根本上改變了傳統資料檢索的使用方式,提高了地質、設計人員的工作效率。
隨著川藏線、成渝中線等重大鐵路工程項目的推進,該系統將為廣大地質人員、工程設計人員的工作、科研提供有力幫助。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
