一種改進的Kubernetes 彈性伸縮策略*
2022-03-17 10:17:12李洪赭李賽飛
計算機與數字工程 2022年2期
沐 磊 李洪赭 李賽飛
(西南交通大學信息科學與技術學院 成都 611756)
1 引言
隨著虛擬化技術和云計算技術的快速發展,基于Hypervisor 傳統虛擬化的云計算技術因為其較低的資源利用率等一系列問題,已經逐漸被以Docker[1]為代表的基于容器虛擬化的容器技術所代替[2]。相比于傳統虛擬化技術,Docker 容器技術通過復用本地操作系統來提高啟動速度,減少開銷。同時因為Docker容器技術簡化了應用的部署工作,受到廣大開發者的歡迎[3]。然而在面對大規模集群的容器組時,對這些容器進行管理會顯得非常困難。Kubernetes[4]是Google 的Borg[5]開源版本,Docker 容器集群編排調度系統,使用Master-Slave模型[6]為容器化應用提供資源調度、自動化部署、服務發現、彈性伸縮、資源監控等服務[7]。其中彈性伸縮是通過監測用戶指定的評價指標,使用閾值的方式對應用進行水平擴容和縮容,以保障應用的服務質量和最大化地節省資源。
針對Kubernetes 的彈性伸縮技術的研究大致可以分為兩類,第一類采用方法或者預測模型對未來資源的利用率進行估計或預測。文獻[8]針對擴容和縮容時的不同特點,分別提出了快速擴容算法和逐步收縮算法,通過在工作負載增加時快速創建多個pod 和在工作負載降低時逐步縮容的方式保障應用的服務質量。文獻[9]使用了基于動態參數的指數平滑法對資源利用率進行預測,通過預測式擴容和響應式擴容相結合的辦法解決Kubernetes擴容時的響應延遲問題。這些處理方法雖然簡單,但是在提高資源利用率和預測精度上仍有不足。第二類是針對Kubernetes 內置的彈性伸縮策略進行改進和優化。文獻[10]提出了一種基于負載特征的彈性伸縮策略,該策略根據負載特征對應用進行分類,求出應用的整體負載并使用ARIMA 模型對負載進行預測,使用預測值和負載值共同作為判斷伸縮的條件,以減少擴縮容時的伸縮抖動現象。該策略提出的根據負載特征衡量復合型應用負載的方法未考慮各種資源的重要性差異和資源極度不均衡情況下的服務質量問題。
綜上所述,雖然目前針對Kubernetes 彈性伸縮策略中存在的問題的研究已經比較全面,但是仍有改善的空間。本文通過對Kubernetes 內置的伸縮策略進行分析,針對單一衡量指標和預測問題提出了一種改進的彈性伸縮策略。該策略給出綜合負載率CLR(Comprehensive Load Rate)的計算方法,使用CLR 作為彈性伸縮的指標。同時使用ARIMA-Kalman 預測模型對資源進行預測,提高預測精度。
2 Kubernetes默認伸縮算法及分析
Pod 是Kubernetes 資源控制的基本單位。Kubernetes 通過HPA(Horizontal Pod Autoscaler)實現Pod的自動伸縮[11]。HPA 控制Kubernetes伸縮原理圖如圖1所示。
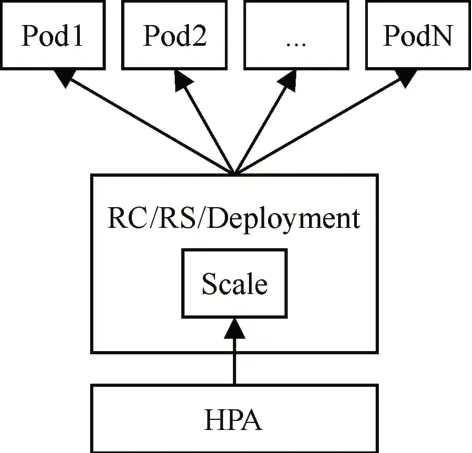
圖1 Kubernetes擴縮容原理圖
在部署應用時會設置某項資源監測指標和該資源的目標平均使用率閾值TAU。則該指標的伸縮閾值計算公式為
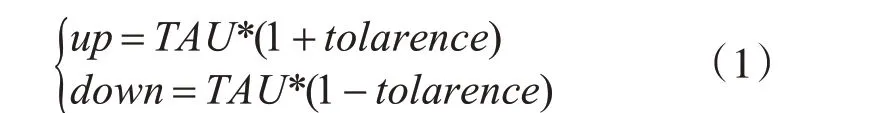
其中tolarence系統默認值為0.1,設置該參數是為了防止應用出現頻繁地擴容和縮容。up和down分別是伸縮的上下限閾值。假設當前共有k個該應用的pod,HPA 通過輪詢的方式獲取當前該pod集合中所有的該資源使用量Ui,求得當前資源利用率和CAU為

其中request代表該pod 中資源的分配量。如果k*down≤CAU≤k*up,則不需要擴縮容,否則需要進行擴縮容操作,計算公式為

以上是Kubernetes 實現伸縮功能的流程概述。從上面的分析可以看出。雖然Kubernetes 內置的水平伸縮的算法比較簡單,但是存在兩個比較明顯的問題:單一衡量指標和響應延時。在面對復雜應用系統時,應用涉及多種資源類型的消耗可能會隨著時間和業務的變化而發生變化,單一衡量指標無法準確地衡量應用整體負載的情況。當應用面對突發的負載變化時,在pod 擴展之前的應用服務質量無法保障,甚至可能會發生應用因為負載太高而崩潰的現象。
3 本文伸縮策略優化
針對上文所說的單一衡量指標和響應延時問題,本文提出了一種改進的彈性伸縮策略。該策略通過監測記錄pod 各個指標,計算出當前pod 的綜合負載率CLR(Comprehensive load rate),將CLR 作為pod伸縮的衡量指標。同時使用ARIMA-Kalman模型對CLR進行預測,提前進行伸縮以保障服務質量。
3.1 衡量指標確定
影響應用服務質量的因素有許多,包括CPU、內存、網絡、磁盤I/O 等多個基礎指標。假設當前pod 節點涉及的資源種類為n,Ci表示節點上第i種資源的使用率Ci為

其中Ri表示節點上資源i的分配量,Ui表示pod 對資源i 使用量。記Cmax為各種資源利用率的最大值,為了減少計算的復雜度,當某項資源利用率低于下限閾值時,認為該資源的利用率對應用負載幾乎沒有影響,則該資源的利用率將不作為計算綜合負載CLR 的參數。如果Cmax低于下限閾值,則令CLR=Cmax。如果Cmax高于上限閾值,則資源可以被認為是應用的性能瓶頸,為了保證服務質量,防止出現只有一種資源消耗非常高,其他資源利用率相對較低導致綜合負載率沒有達到擴容閾值的情況,同樣令CLR=Cmax。由經驗,設定下限閾值dl=0.4,上限閾值ul=0.95。
假設當前應用涉及的n種資源利用率中有k(k>0)個資源利用率滿足dl<Ci<ul且Cmax<ul,則CLR為

根據以上公式,最終計算出當前pod 的CLR,該CLR 指標在簡化計算復雜度和保證應用服務質量的前提下,全面反映出當前pod 節點整體負載水平。
3.2 ARIMA-Kalman負載預測模型
3.2.1 ARIMA預測模型
差分自回歸平穩滑動平均模型(ARIMA)是時間序列預測方法,是博克斯和詹金斯提出的一種基于時間序列預測方法。該模型將非平穩時間序列轉化為平穩時間序列,讓因變量對其滯后值及隨機誤差項的現值和滯后值進行回歸[12]。ARIMA(p,d,q)模型的數學表達式如下:
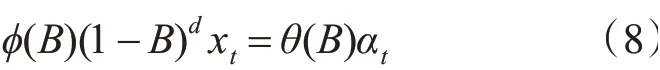
其中p為自回歸階數,d為差分次數,q為移動平均階數。B為后移差分算子,xt為原序列,αt為均值為0,方差為δ2的正態白噪聲序列。?(B)和θ(B)計算方法如下:
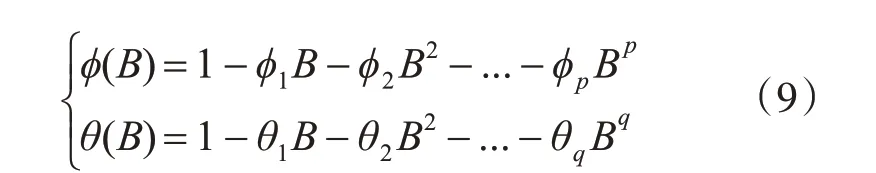
?(B)為p階AR 多項式,?i(i=1,2,…,p)為該多項式的待估系數;θ(B)為q階MA 多項式。θj(j=1,2,…,q)為該多項式的待估系數。
ARIMA 模型的優點在于只需要有限的樣本序列,就可以建立精度較高的預測模型。但是該模型存在低階模型預測精度低,高階模型參數估計難度大的缺點[13]。
3.2.2 Kalman濾波算法
Kalman 濾波是一種獲取變量的最佳估計,將過去的測量估計誤差合并到新的測量誤差中來估計將來的誤差,來對系統狀態進行最優估計的算法[14]。其線性離散的Kalman濾波方程如下:

其中x?k|k-1為從tk-1時刻對tk時刻的預測值;Kk為tk時刻的卡爾曼增益矩陣;Pk是tk時刻xk的狀態估計協方差矩陣。
卡爾曼濾波算法采用遞歸的形式,不需要全部的數據,只需要根據tk時刻的測量值修正tk-1時刻的估計值,具有動態加權修正的特性[16],具有較好的預測精確度。但是Kalman 濾波算法需要狀態方程和測量方程才能保證有很好的預測精度。
3.3 ARIMA-Kalman預測模型
針對以上對ARIMA 預測模型和Kalman 濾波模型的描述,可以看出這兩種預測模型都存在不足。本文通過使用ARIMA-Kalman算法,將兩種預測模型結合。利用ARIMA 模型建立低階預測模型,將該低階模型處理后計算Kalman 濾波模型的狀態方程和測量方程,使用Kalman 迭代方程進行預測。
對于CLR 序列集合X(t) ,令x1(t)=x(t) ,x2(t)=x(t-1) ,… ,xp(t)=x(t-p+1);α1(t)=α(t) ,α2(t)=α1(t-1) ,…,αq(t)=αq-1(t-1) 。則ARIMA預測模型如下:

該組合算法的具體步驟如下所示。
1)數據采集
利用工具對各個指標進行采集并處理,按照上文中綜合指標CLR計算方法對數據進行計算,得出時間序列X(t)。
2)平穩化處理
為了保證數據的平穩化,對采集到的數據信息利用平穩性檢驗方法ADF 檢驗進行判斷。如果是非平穩數據,通過差分進行平穩化處理至ADF 檢驗滿足要求。
3)ARIMA模型參數確定
ARIMA(p,d,q)預測模型中,d代表在數據平穩化的處理過程中差分的次數。p和q確定的方法有多種,本文中使用固定步長,遍歷求出最小AIC 信息準則時p和q的值,從而確定ARIMA 模型的參數。
4)Kalman濾波模型預測
根據ARIMA 建模求得AR 模型和MA 模型的待估系數,確定Kalman 系統的狀態方程和測量方程。利用式(12)~(16)遞推求出系統最新估計值。
4 實驗
4.1 實驗環境
為了驗證本文提出的改進的彈性伸縮策略,搭建了兩個相同的Kubernetes 集群環境,Kubernetes的版本都是1.16.2,每個集群包含一個Master 節點和兩個Slave節點。其中一個集群使用內置的彈性伸縮方法,另一個集群使用本文提出的彈性伸縮策略。集群的詳細配置如表1所示。

表1 實驗環境配置
4.2 實驗數據
本文的實驗數據使用2018 年阿里巴巴公開的生產環境采集的部分容器資源使用率信息。該數據包括CPU 利用率、內存使用率,網絡以及磁盤IO等多個維度的資源使用情況。由于該數據集數據量龐大,本文選取出同時使用兩種及兩種以上維度的資源維度的容器數據作為算法計算的基礎數據。由于該公開的數據采樣的時間間隔不相等,去除時間間隔較近的點并對個別時間間隔較長的數據中間使用均值補差進行補充,使時間間隔大致相等。
4.3 實驗步驟及結果分析
本文提出的改進的Kubernetes 的伸縮策略需要從功能性和準確性兩個方面進行實驗驗證。所以實驗應該包含兩個部分:1)使用JMeter 工具對Kubernetes 的pod 進行壓力測試,分別記錄兩個集群的pod 的數量變化情況并進行對比。驗證本文的伸縮策略在應對負載變化時的預測伸縮效果。2)使用公開容器負載信息,計算出CLR序列。分別使用指數平滑法,ARIMA 預測模型和ARIMA-Kalman 預測模型進行預測并對這三種預測模型的預測精度進行評估。
首先在兩個實驗環境中分別部署一個相同的Web 應用,伸縮閾值設置為60%,容忍度設置為默認的0.1。利用JMeter 工具進行模擬并發訪問請求,每隔1min增加并發請求數量并檢查當前pod的數量。其中使用本文伸縮策略的實驗環境使用Prometheus獲取pod的資源信息并計算CLR進行預測。具體數量變化情況如圖2所示。
從圖2 中可以看出,相比內置的伸縮策略方法,本文使用的方法可以提前針對負載的變化趨勢進行預測式的彈性伸縮,從而解決Kubernetes 內置的伸縮策略的響應延遲問題,保障了服務的質量。
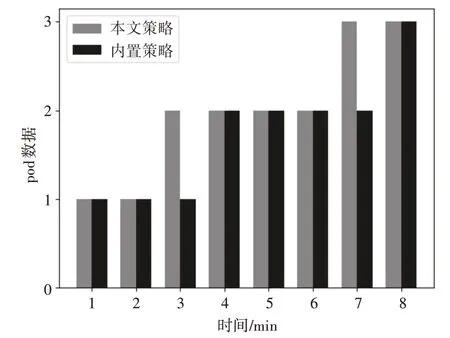
圖2 pod數量變化圖
為了比較本文使用的ARIMA-Kalman 預測模型和其他模型的精度,使用阿里巴巴的生產環境容器公開數據集的負載信息數據作為基礎數據。簡單處理后計算出CLR,將CLR 作為模型預測的輸入。分別使用絕對誤差(MAE)、平均絕對誤差(MSE)、平均絕對均方誤差(MSRE)這三種最常見的衡量指標對文獻[5]中使用的指數平滑法以及文獻[6]使用的ARIMA 預測模型和本文使用的ARIMA-Kalman預測模型進行評估。
每個容器的處理后的采樣數據約為650~800個,統一選取前550 個信息節點作為訓練數據,后100 個數據作為預測。指數平滑法,ARIMA 預測模型和ARIMA-Kalman 的預測誤差圖已經分別如圖3所示。
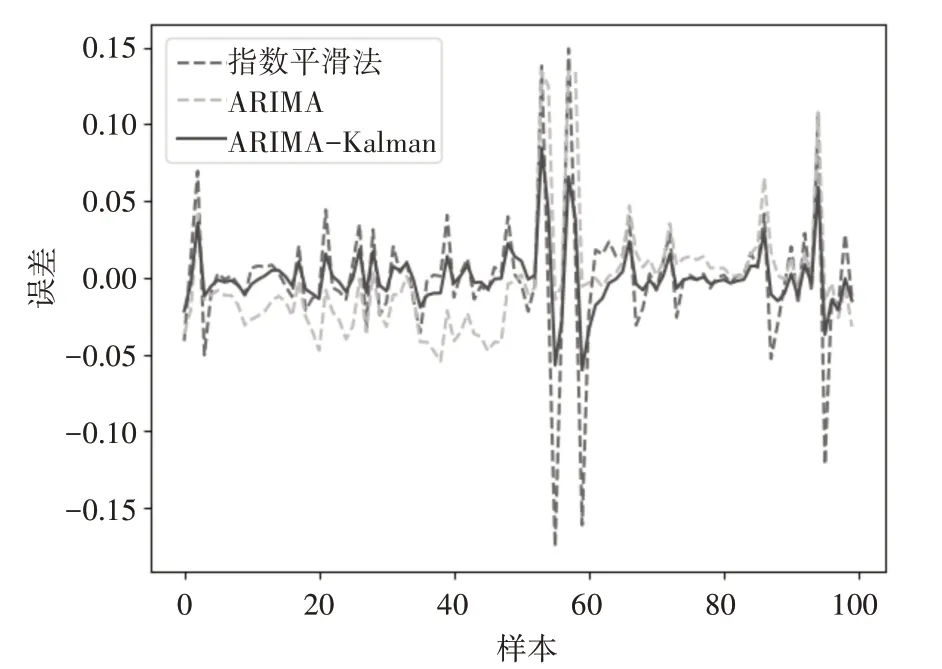
圖3 模型預測誤差比較圖
由圖3 可以直觀看出,ARIMA-Kalman 的誤差相對其他兩種方法更小。由于ARIMA 模型的參數確定過程計算量較大,不適合對數據模型進行動態更新,只適合做短期預測,本文一次性預測100 個數據點,所以整體誤差較大。指數平滑法由于使用了所有歷史節點的信息,在使用中會消耗更多的內存資源,而且沒有考慮到數據變化的規律性。ARIMA-Kalman模型通過建立低階的ARIMA模型確定狀態轉移方程,使用Kalman 模型進行更新迭代預估,其精確度相比ARIMA 和指數平滑法較大的提升。表2是對這三種模型的評估。
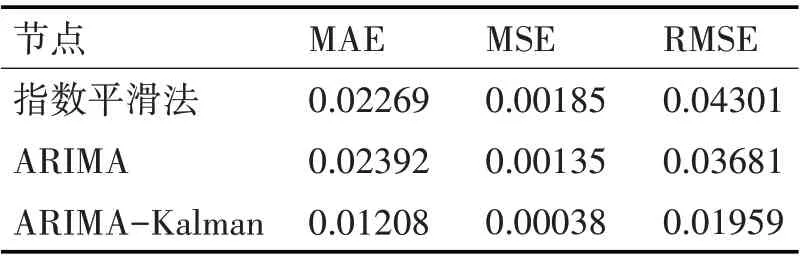
表2 各模型評價指標對比
可以看出,相比于指數平滑法、ARIMA 模型,本文所使用的ARIMA-Kalman 預測模型的預測精度更優。在面對負載變化的情況,能夠準確地進行預測。
5 結語
本文針對Kubernetes 內置的彈性伸縮機制的單一衡量指標和響應延遲的問題,提出了一種改進的彈性伸縮策略。該策略通過定義統一負載評價指標CLR,有效衡量出復雜應用的整體負載水平。同時通過上下限閾值的設置,簡化了計算的復雜度并且保證了服務的質量。使用ARIMA-Kalman 預測模型對應用當前CLR進行預測,提前伸縮以保證服務質量。實驗證明,該預測模型相比于指數平滑法和ARIMA預測模型具有更高的精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
數學大世界(2018年1期)2018-04-12 05:39:14
資源再生(2017年3期)2017-06-01 12:20:59
