
Python數據處理在“侵犯公民信息”案司法取證中的運用研究
2022-03-30 10:16:34金波
科學與信息化 2022年6期
金波
中浦鑒云(上海)信息技術有限公司司法鑒定所 上海 200080
1 “侵犯公民信息”案司法取證常規方法及使用Python數據處理的意義
近年來隨著手機及互聯網技術普及運用,海量信息唾手可得。為有效保護公民隱私、保障金融環境健康運行,銀行賬號、電子支付、網上交易等與居民息息相關的日常事務均采用了以手機號和身份證號等具有唯一性特征的公民信息進行實名認證[1]。同時,倒賣公民信息,用以實施詐騙、洗錢等違法犯罪活動也層出不窮。在“侵犯公民信息”類案件的司法訴訟過程中,需要對涉案檢材中的公民信息的數量進行統計排重,以檢測檢材中具有多少不重復的公民信息作為定罪量刑提供有效依據。
此類案件的數據處理通常是在各表格欄位格式一致的情況下對檢材中含有公民信息的數據表格進行合并,再對身份證號或手機號進行統計排重。傳統處理方法是以Excel為工具對表格進行手工處理,表格數量稍大則利用“方方格子”等插件進行半自動化處理。由于Excel效率低下、且不能超過百萬行的局限,遇到巨量數據時,則須將表格導入到關系型數據庫,再以結構化查詢語言進行統計[2]。
本文通過實例,闡述了在處理大量的欄位格式不一致的電子表格的情況下,克服手工處理的弊端,解決Excel和傳統關系型數據庫處理能力的瓶頸,運用Python數據處理模塊高效、精準地解決公民信息統計排重的難題。
2 使用Python數據處理所使用的材料與處理步驟
2.1 檢材
含有公民信息清單的Excel文件共12555個,總大小約為2.2GB。
2.2 檢測設備
2.2.1 硬件:PC 1臺:CPU Intel i9 8核心,內存 32G,硬盤500G SSD
2.2.2 軟件。
2.2.2.1 操作系統:Windows 10 專業版 20H1。
2.2.2.2 Python 3.8:含模塊os,datetime,xlrd,re,pandas。
2.3 處理步驟
2.3.1 利用os模塊遍歷檢材中含有Excel文件的目錄樹,并記錄其中每個文件名。
2.3.2 利用xlrd模塊讀取每個Excel文件中所有工作表的內容,對其中的每一行數據以字符串“::”作為分隔標識進行橫向合并,合并結果定義為源數據行的特征字符串字段,全部結果行合并寫入一個文本文件中。
2.3.3 利用Python中list和set兩種數據類型,對合并結果的文本文件中的特征字符串字段進行初步排重,先將所有特征字符串讀入list中,再對其以set進行處理,處理后每一行都是唯一的,重復的特征字符串只保留一行,以提高后續處理的效率[3]。
2.3.4 利用re模塊,編輯正則表達式對初步排重結果中的特征字符串進行判斷,按定義規則識別手機號和身份證號,并將其單獨提取為號碼字段,分別按身份證號和手機號保存為兩個含格式的文本文件。文件中每行的格式為:列1.號碼字段;列2.特征字符串。若在同一特征字符串中提取到多個手機號或身份證號,則對應分為多行,每行中只保存其中一個號碼。
2.3.5 在pandas模塊的dataframe類中,使用drop_duplicates方法對識別到的號碼進行統計排重,對重復號碼只取排在最先的一行。
3 異常情況的處理思路及核心代碼展示和處理結果
3.1 觀察到的異常情況
3.1.1 損壞且無法打開的Excel文件。檢驗過程中提取恢復到檢材中所有的xls和xlsx文件均被識別為Excel文件,但其中部分以“$”開頭的文件名為恢復到的因打開Excel文件而產生的臨時緩存文件,在非正常退出時未被及時清除,通常此類文件無法打開,因此記錄在日志文件中,以便進一步追溯核實[4]。
3.1.2 公民信息記錄特征-格式。
3.1.2.1 郵政、快遞的收發信息。格式:發貨人姓名、電話、地址、發貨時間、收貨人姓名、電話、地址。
3.1.2.2 客戶服務系統實名認證的通訊錄。格式:姓名,證件號,電話號1,電話號2,電話號3……(電話號數量不一)。
3.1.2.3 銀行系統的客戶實名信息。格式:姓名,電話號,證件號。
3.1.2.4 政府機構通訊錄。格式:省,市,區縣鎮,機構名稱,負責人及聯系電話(合并在同一單元格)。
3.1.2.5 金融系統的核銷記錄。格式:姓名、委托批次、手別、本月任務類型、賬戶類型、賬戶分包、來源、城市、單位電話號碼、性別、住宅電話、手機號碼……(多達150余列)。
3.1.3 公民信息記錄特征-異常情況。
3.1.3.1 在一個單元格中填塞入整個通訊錄名單。因此需將該單元格中的內容處理為多行數據,而非粗暴的合并為1行。
3.1.3.2 由于Excel會將18位身份證號當作數字處理,由于限制,前15位數字可正常顯示,后3位會被處理為000,因此有些單元格會在身份證號前加“‘”號,強制將單元格當作文本格式處理。有些手機號被當成浮點數處理,例如:19990909555.0,保留小數點后n位的數字形式。因此區分“‘”和“.”符號也需納入考慮。
3.1.3.3 容易混淆的身份證號為手機號的情況。例:身份證號31010219990909555X,其中19990909555易被誤識別為手機號。因此不能將該號碼既識別為身份證號,又識別為手機號。
3.2 公民信息的定義及作業思路
唯一性是定義的核心。身份證號人手一份且只有一份,與他人不重復,是最佳的界定唯一性的特征[5]。其次為手機號,手機號也不重復,注冊時需與身份證掛鉤,已被納入實名認證的特征之一,缺點是一人可以有多個號碼,可做參考。為避免同名同姓的發生概率高,以及同一住址可能會有多人居住的情況,因此姓名、地址不宜作為唯一性的特征用以區別。
因此,以身份證號(手機號為參考)區分唯一性。將所有數據的每一行合并為保留分隔形式的特征字符串,在特征字符串中識別提取符合身份證號(手機號)特征的號碼,最后對所有提取到的號碼進行排序去重。
3.3 特征識別的規則及正則表達式
3.3.1 身份證號。18位身份證號生成規則由國標GB 11643-1999《公民身份號碼》定義,由一系列特征碼組合而成,前17位數字為本體碼和最后1位則是校驗碼。本體碼依照先后次序為:6位地址碼,由各省市地方的標準代碼轉換而來;8位出生日期碼,分別為年份4位月份2位和日期2位;3位序列編碼,其含義為出生當日的出生順序及性別;1位校驗碼,由前17位通過一定算法計算而來的,校驗碼為0…9和X共11種。18位和15位的共同特征是:在特定位置有6位日期碼,分別為年年月月日日,其長度是固定的。
3.3.2 身份證號碼特征識別的正則表達式。正則表達式:(?
該表達式用來識別18身份證號,即:18位連續數字或17位連續數字后跟X,第7位起為2位世紀號18、19或20,后跟2位任意數字,第11位起為2位月份即01-12,第13位起為日期即01-31。以零寬斷言(?
3.3.3 手機號。手機號編碼相對較為簡單,其特征為11位連續數字,第一位為數字1,第二位為3-9的任一數字,不可為0、1、2。但手機號前有時會被加上86以區分國別,或加0作為長途撥號的便捷方式,因此需加以考慮和區分。
3.3.4 手機號碼特征識別的正則表達式。正則表達式:(?
該表達式用來識別11位手機號,即:開頭可以為86或0,后跟11位數字,其中第一位為1,第二位為3-9的任一數字,后跟9位任意數字。以零寬斷言(?
3.4 Python的運用
3.4.1 Python的優點。其次,Python開發語言的執行效率雖并不在最理想狀態,但可以看到因為通過lists和sets等數據變量處理數據,Python進程會占用到5-10G的內存,在硬件內存充足的情況下,統計排序去重等操作均在內存中完成。這避免了關系型數據庫為提高Cache Hit Rate減少磁盤讀寫而做的各種復雜的參數調整工作。
3.4.2 os模塊。os模塊用來遍歷檢材中含有Excel文件的目錄樹,并記錄其中每個文件名。代碼如下:

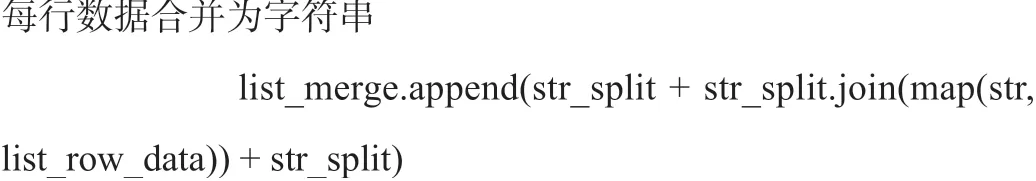
3.4.4 lists和sets數據類型。python中有lists(列表)和sets(集合)兩種數據類型,其表現形式均由元素組成的清單,list以[]形式表示,而sets以()表示,以“,”分隔的元素。但sets與lists不同的是,list的元素可以重復,而sets不可以。通過set()方法將List的內容去重,轉換為set。代碼如下:

3.4.5 re模塊。re模塊用來使用正則表達式在對象字符串中識別提取符合正則模式的內容。此處理步驟為檢驗檢測工作的核心。代碼如下:


3.4.6 pandas模塊。在pandas模塊的dataframe類中,通過使用drop_duplicates方法對“號碼,特征字符串”中的號碼字段進行排重,同時保留第一行特征字符串。代碼如下:

3.5 檢驗檢測結果
在檢驗設備硬件上,對檢材中含有公民信息清單的12,555個Excel文件應用上述代碼功能進行統計排重,檢驗檢測到可讀取的Excel文件11,202個,無法讀取的為1,353個。在可讀取的Excel文件中,檢測到10,121,012條記錄,經統計排重后獲得手機號2,230,034條,身份證號2,338,503條。檢驗檢測過程總時長為14分鐘。經抽樣核對,精確度達到99.99%。
相比之下,若按平均每個文件花5min的人工處理時間,由1人處理,需要56010min(近131個工作日),且無法保障結果的精確度。對比情況見下表:
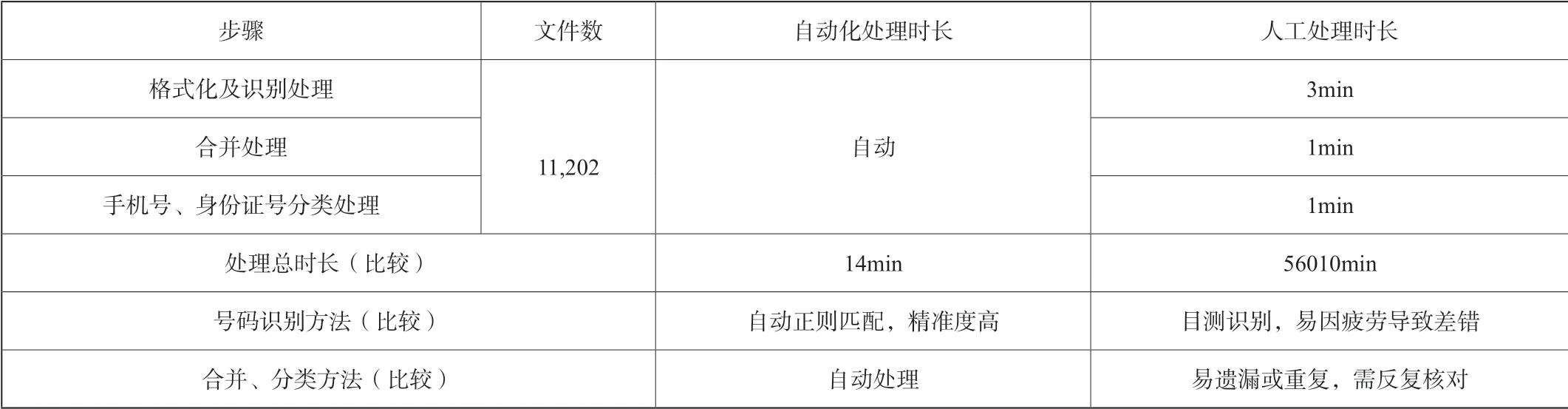
表1 python數據處理與人工處理的對比
4 結束語
綜上所述,本文通過研究Python編程語言中數據結構及模塊應用的特點,結合對巨量涉及公民信息的Excel工作簿文件中記錄特征的觀察,在對公民信息統計去重的司法鑒定工作實踐中,編寫代碼,建立了一套高效準確的合并、識別、統計、去重的方法,擺脫了對巨量Excel工作表進行人工處理的繁重勞動,為法庭科學提供了科學客觀且有效的證據,可為相關司法鑒定實踐提供參考。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
