基于FTA和BP神經網絡的網絡系統故障診斷方法研究
2022-04-01 07:08:06李帥張軍
企業科技與發展 2022年11期
李帥,張軍
(哈爾濱師范大學 計算機科學與信息工程學院,黑龍江 哈爾濱 150025)
0 引言
在信息時代,隨著各種信息技術不斷創新與發展,計算機網絡給人們帶來了極大的方便與好處,但隨之而來的是一系列網絡安全[1]問題。網絡安全問題不僅關乎個人的財產安全,更關乎群體利益乃至國家的穩定發展,在這個新型的互聯平臺,守護平臺和諧穩定,共建美好網絡環境是每一個人的共同責任。為了保證網絡系統的安全性和穩定性,學者們對此進行了大量的研究。隨著網絡吞吐量和安全威脅的不斷增加,入侵檢測系統(IDS)[2]的研究受到了計算機科學領域的廣泛關注。當前反復無常的入侵類別不僅對入侵防御系統構成挑戰,而且對其龐大的計算能力構成挑戰。LIAO等[3]針對當前存在的入侵防御檢測系統的研究給出了一個詳盡的圖像進行全面的綜述,表達出每種技術都有其優越性和局限性,而且學習算法在安全和隱私方面有較高的成功率,也為之后的學者們將機器學習的技術融入網絡安全中提供了重要依據。
風險分析是軟件開發的一項重要活動,做得好可以確保關鍵資產以安全可靠的方式運行。故障樹分析法(Fault Tree Analysis,FTA)是其中最突出的技術,被各行業廣泛使用。FLAGE等[4]應用了一個綜合概率可能性計算框架,將認知的不確定性聯合傳播到故障樹的基本事件的概率值上,并使用可能性概率轉換在純概率和可能性設置中傳播認知不確定性。將不同方法的結果與頂部事件概率的不確定性表示進行比較,這個方法的提出有助于分析人員有效地應對新興技術帶來的安全挑戰。
反向傳播(Back Propagation,BP)神經網絡具有良好的自學習能力、自適應能力和泛化能力。QIU等[5]針對傳統BP神經網絡入侵檢測模型在檢測率和收斂速度方面的缺陷,結合粒子群優化算法(Particle Swarm Optimization,PSO)將改進的PSO-BP神經網絡應用于入侵檢測系統模型中,分析了梯度下降算法和附加動量算法,驗證了系統在假負率、假陽性率和收斂速度方面的改進效果,為網絡安全的未來發展提供建設性的建議,值得在實踐中進一步推廣。
1 網絡系統故障診斷分析模型
1.1 網絡系統故障FTA模型
網絡系統故障FTA模型本質是將網絡系統故障作為頂事件,逐層分析其可能引發頂事件的一系列原因,通過與門操作符和或門操作符將各事件之間的邏輯關系建立邏輯連接,最終生成一張倒立的樹狀邏輯因果關系圖。
1.2 BP神經網絡模型
BP神經網絡是一種梯度下降方法,通過網絡計算將輸入層的值分別傳輸到隱含層和輸出層,將最終輸出值與樣本值進行比較,計算誤差。BP算法是一種誤差函數按梯度遞減的學習方法[6],圖1顯示了這樣一個網絡。在這個網絡中,有一個輸入層、一個輸出層,以及它們之間的一個或多個隱含層。三層BP神經網絡結構如圖1所示。
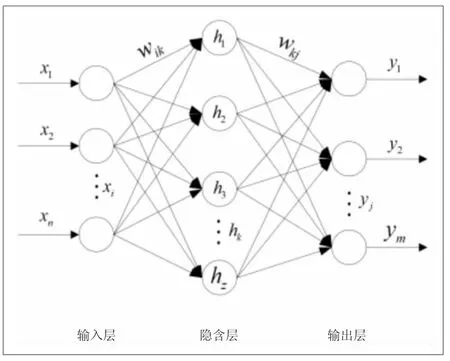
圖1 三層BP神經網絡結構圖
根據BP神經網絡的特性,只需具備單層隱含層和有限數量的神經單元,就能以任意精度擬合任意復雜度的函數。那么,若用表示輸入層的集合,其輸入層的集合表示如下:
其中,x表示輸入層,h表示隱含層,i表示輸入層的次序數,k表示隱含層的次序數,wik表示輸入層第i節點到隱含層第節點的權值,若用hk表示隱含層的輸出,其隱含層的輸出表示如下:
其中,f1表示輸入層到隱含層的傳遞函數,f2表示隱含層到輸出層的傳遞函數,θ是隱含層的閾值。
與傳統的BP神經網絡不同,在激活函數部分進行了改進,由于Sigmoid的收斂比較緩慢,并且Sigmoid函數是軟飽和,所以容易產生梯度消失的問題。根據不同的情況混合使用Sigmoid函數、Softsign函數和ReLU函數用來改善單一函數所存在的一些問題(圖2)。
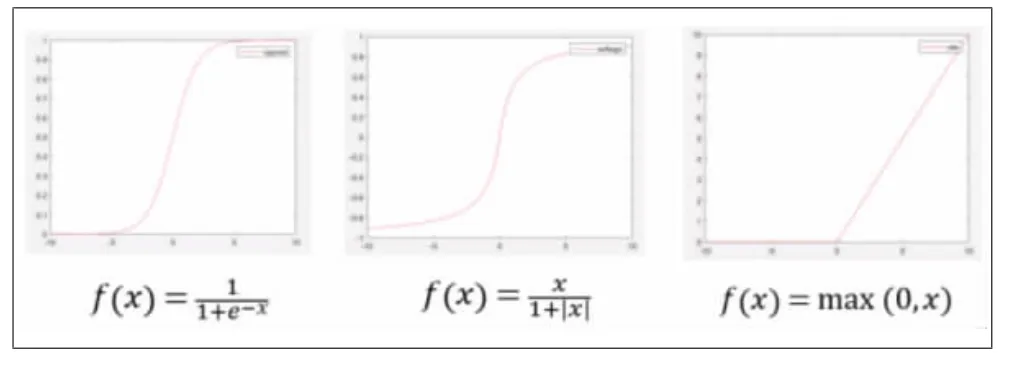
圖2 BP神經網絡傳遞函數圖像
從Sigmoid函數圖像上可以看出,當神經元輸出接近1時,曲線變得非常平緩,此時的導數也趨近于0,輸出層飽和,收斂速度開始變慢,容易產生梯度消失。而softsign函數圖像也是“S”形函數,不同的是Sigmoid函數的取值范圍是[0,1],而Softsign函數的取值范圍是[-1,1],從圖2可以看出,Softsign函數圖像相對于Sigmoid函數圖像而言過渡得更加平滑,而且解決了Sigmoid函數以非0為中心的問題,但是梯度消失的問題仍然沒有解決,因此引入ReLU函數,與Sigmoid函數和Softsign函數相比,ReLU函數不會在正數的區域產生飽和現象,有效解決了梯度爆炸和梯度消失的問題,并且ReLU函數的效率更高,收斂速度更快,而且ReLU函數的特點是會使其中一部分的神經元輸出為0,那么就會促使網絡變得稀疏,并且減少參數之間的相互依存關系,從而達到緩解過擬合的問題。在BP神經網絡中激活函數并不是唯一的,但根據情況選擇合適的激活函數是有必要的,對于圖2中的3種函數的優缺點進行自由混合,利用其優勢解決相應問題,這樣可以在設計學習模型時減少網絡的參數和隱含層的節點數量,簡化結構,有效提高泛化能力。
在學習模型的訓練過程中,關鍵是通過損失函數計算學習的誤差及確定模型的可靠性。假設Tj是輸出層y上第j節點的期望輸出,那么損失函數e表示如下:
2 實例研究
2.1 數據集采集
采用FTA-BP故障診斷模型對網絡系統故障中網絡入侵[7]分支進行分析實驗。本次實驗選用的數據集是第三屆國際知識發現和數據挖掘工具競賽使用的KDD CUP 99數據集,選取總計500條樣本用于本次實驗。其中,400條為正常流量,100條為異常流量。次序隨機打亂,隨機選擇400條作為訓練數據,100條作為測試數據進行實驗。
2.2 性能指標
在損失函數的基礎上將均方誤差(MSE)[8]作為FTA-BP模型的誤差輸出函數,用于測試該模型的性能。均方誤差不僅可以減少整個訓練集的全局誤差,而且可以降低每個特定樣本輸入時的局部誤差,并通過BP神經網絡不斷學習,不斷調整更新權值和閾值,從而不斷降低誤差,使實際輸出越來越接近期望輸出。均方誤差MSE表示如下:
其中,w表示權值,θ表示閾值,80%n表示輸入層全部樣本的80%為訓練樣本,20%為測試樣本。通過把得到的均方誤差不斷向前反饋,進行多次迭代采用,廣義的感知學習規則不斷更新權值和閾值[9],直至算法達到預期的效果為止。本研究基于梯度下降法,以目標的負梯度方向對參數進行更新,對均方誤差MSE(w,θ)給定學習率η,計算均方誤差對于權值部分的變化率進行調整,那么遵循反饋神經網絡誤差不斷減小的原則,權值的調整量△wik和△wkj分別表示如下:
同樣的,計算均方誤差對于閾值部分的變化率進行調整,那么遵循反饋神經網絡誤差不斷減小的原則,閾值的調整量△θik和△θkj分別表示如下:
2.3 數據預處理
該數據并不是統一的數字數據類型,還有其他的一些字符特征描述,如果隨意將字符數據丟棄,將會導致預測結果出現偏差。所以本研究通過Python Pandas中的Transform函數對文本信息進行字符特征向數字特征轉換,即對該數據集中的文本數據類型轉化為BP神經網絡訓練使用的數字數據類型。
2.4 實驗結果
通過FTA-BP模型對KDDCUP 99數據集進行了多次預測訓練,最佳FTA-BP實驗結果如圖3所示。
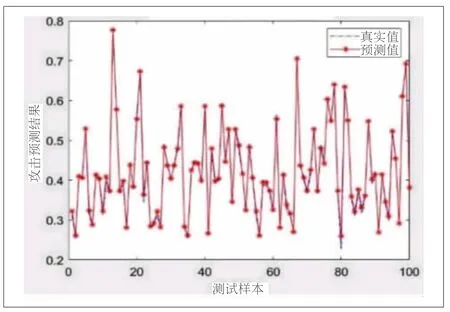
圖3 FTA-BP模型攻擊預測結果
實驗確定了最佳的隱含層節點個數為9,相應的均方誤差為2.7298×10-5,準確率為96.51%。訓練結果顯示驗證性能在第96輪時表現最佳。
3 結語
在傳統BP神經網絡的基礎上,結合故障樹分析法對傳統BP模型進行了改進,提出了一種FTA-BP網絡系統故障診斷模型。通過仿真實驗分析,提出的FTA-BP網絡系統故障診斷模型相比傳統的BP模型和ELM模型具有明顯的優勢,不僅提高了模型的精確率,而且預測效果較穩定。信息時代面臨尤為重要的網絡安全問題,網絡系統故障診斷方法是必不可少的。該模型還存在著一定的缺陷,雖然預測的準確率比傳統的BP模型要高,但是平均準確率還未達到最高標準。而且,實驗選用的數據集也存在著一定的局限性。下一步需要解決的問題是如何將FTA-BP模型的精確度進一步提升及如何將FTA-BP模型應用在網絡系統故障的其他部分。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
裝備制造技術(2020年3期)2020-12-25 05:22:30
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北京航空航天大學學報(2016年6期)2016-11-16 01:50:43
光學精密工程(2016年6期)2016-11-07 09:07:19
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
核科學與工程(2015年4期)2015-09-26 11:59:03
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
