基于GRU和K-means算法的入侵檢測模型與方法研究
2022-04-01 07:08:06李昊,郝寬,姜偉
企業科技與發展 2022年11期
李 昊,郝 寬,姜 偉
(哈爾濱師范大學 計算機科學與信息工程學院,黑龍江 哈爾濱 150025)
0 引言
隨著互聯網及網絡應用的飛速發展,人們的生產生活已經深度依賴網絡,人們從互聯網中獲取信息也變得極為便利,這就難以避免海量的數據信息通過網絡進行傳播。互聯網提高了人們的生活生產效率與質量,但同時,一系列網絡安全問題也相應產生,比如網絡入侵,不論是個人、企業,還是政府、軍隊的信息,一旦被不法分子竊取、篡改,極有可能造成無法彌補的損失。
傳統的基于防火墻等的靜態安全防范技術已然無法滿足當前網絡安全的需求,為了更好地應對當前的網絡安全問題,現在更多應用主動防御的網絡入侵檢測系統。但是隨著網絡攻擊智能化,網絡入侵檢測系統也面臨著巨大的挑戰,需要對入侵檢測技術進行不斷研究。
在網絡流量中,惡意的網絡攻擊往往隱藏在大量的正常行為中。它在網絡流量中表現出高度的隱身性和模糊性,使得網絡入侵檢測系統難以保證檢測的準確性和及時性。研究機器學習和深度學習在入侵檢測問題上的應用,提出了一種結合GRU網絡和K-means的算法模型進行入侵行為檢測。首先,利用GRU網絡對網絡行為進行信息特征提取,實現全面有效的特征學習。其次,使用K-means算法對前置輸入進行聚類,對于那些暫時無法進行屬性判斷的流量行為,再次進行特征提取后使用K-means算法進行分類,有效減少傳統二分類入侵檢測對于暫時無法判斷的流量行為的誤判動作。
1 相關知識
1.1 GRU網絡
CHO等[1]提出了門控循環單元(gated recurrentunit,GRU)。相比于長短期記憶網絡(LSTM,Long Short-Term Memory),GRU網絡具有更為簡潔的模型,GRU中去除了細胞狀態,有重置門和更新門兩個門限結構,重置門確定如何將前一時刻的記憶與新的輸入信息相結合,表示前一時刻信息的忽略程度,值越大代表忽略的信息程度越小。更新門代表前一時刻信息對當前狀態的傾向程度,用于控制前一時刻的狀態信息被帶入到當前狀態中的程度,值越大代表影響越大[2]。GRU結構在多種場景下被證實有效,具有計算方便、訓練速度更快的特點,同時可以很好地將長距離的信息進行依賴保存,有效解決梯度問題。循環神經網絡(Recurrent Neural Network,RNN)用于分析或預測順序數據[3],這使得它成為入侵檢測的一個可行的候選對象,因為網絡流量數據本質上是順序的[3]:
上式中,zt代表更新門,rt代表重置門,tanh為雙曲正切函數,σ為Sigmoid函數,w為t時刻的權值矩陣。
基于這些特點,本研究采用GRU網絡結構如圖1所示。
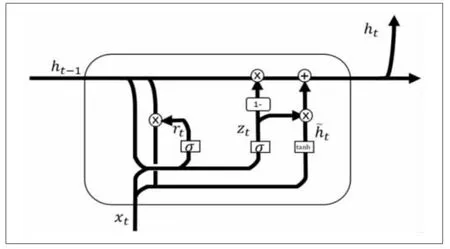
圖1 GRU網絡結構圖
1.2 K-means算法
聚類算法一般分為劃分聚類和層次聚類,K-means算法是Macqueen在1967年提出的一種劃分聚類算法[4]。K-means算法是一種基于劃分的無監督的聚類算法,利用數據對象間的距離作為相似性的評價指標[5]。傳統的K-means算法如下:對給定包含n個對象的數據集x:x={x1,x2,x3,…,xn},其中每個對象都具有m個維度的屬性,依據對象間的相似性,最終將n個對象聚集到指定的k個類簇中,每個對象屬于且僅屬于一個聚簇類,這個對象到這個類簇中心距離為最小。
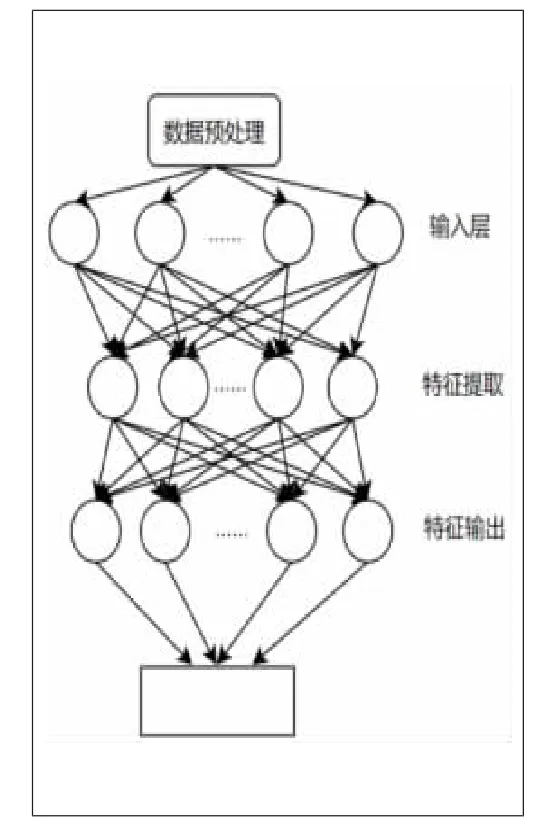
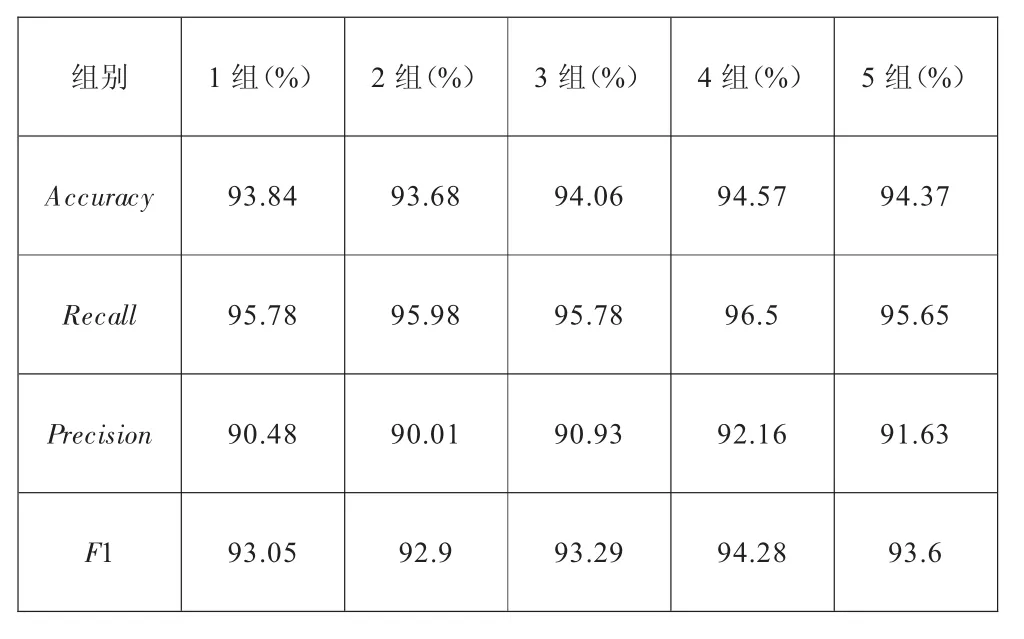
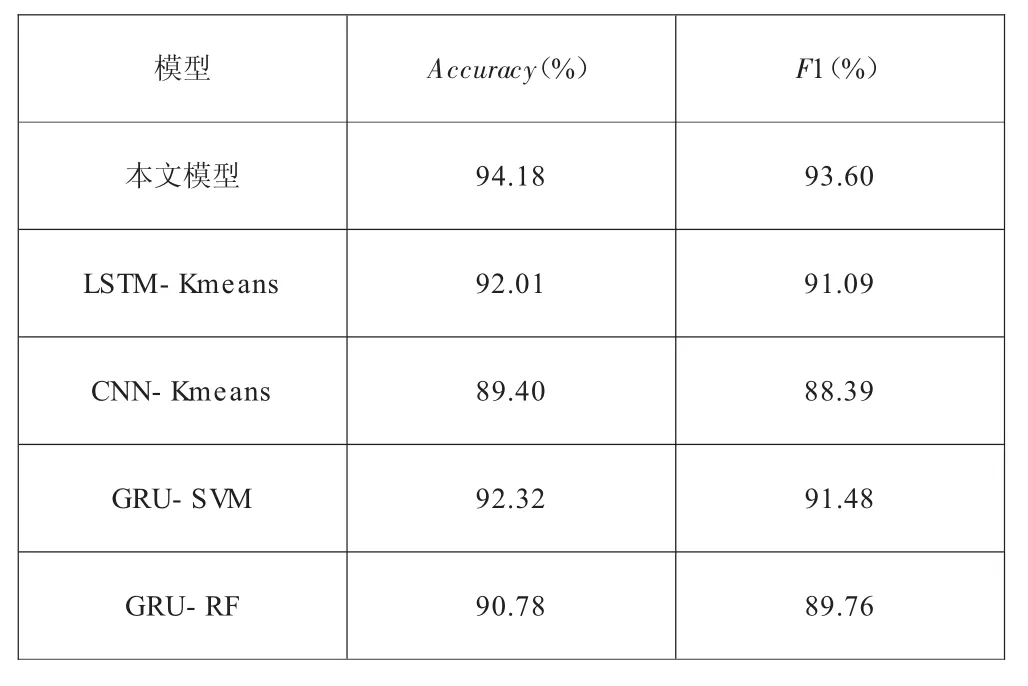
K-means算法的實現步驟。①初始化k個聚類中心:{C1,C2,C3,…,Ck},1 圖2 K-means算法流程圖 構建的基于GRU網絡和K-means算法的入侵檢測方法,其整體流程主要包括兩大部分:一部分為預處理數據,使用GRU網絡對數據特征進行提取;另一部分為使用K-means算法對上步驟輸入的數據進行聚類劃分。 在進行特征提取之前,需要先對所選數據進行預處理,在這個階段,主要工作是將數據集中的字符型特征使用One-hot進行數值化轉換,再劃分訓練集、測試集。采用Train_Test_Split()函數劃分數據集來盡量平均劃分數據樣本,減少人為主觀原因帶來的誤差。Train_Test_Split()是交叉驗證中常用的函數,對目標數據集的劃分具有隨機的、按比例的功能,將目標數據集劃分為訓練數據集(Train Data) 和測試數據集(Testdata)。 待檢測的網絡輸入數據復雜度一般較高,導致RNN網絡的結構較為復雜,容易出現梯度消失等問題。在GRU的單元結構中,無須考慮循環神經網絡中的隱藏層的細胞狀態,LSTM網絡中的輸入門和遺忘門被替代,減少了相應網絡的參數數量,提高了模型收斂性能,降低了時間復雜度。同時,網絡流量數據是具有時序特征的序列數據,例如DDos攻擊,就是使用短時間內對某服務大量訪問的手段達到使被攻擊服務不可用的目的,而GRU能對具有時序特征的數據進行很好的處理。融合GRU網絡的部分主要對數據進行特征提取及數據降維處理。主要步驟如下:①將上一層的輸入進行整合;②對數據進行長距離依賴特征提取;③將特征張量化后輸出;④對下一層邊界域中數據進行處理(如圖3所示)。 圖3 GRU網絡特征提取示意圖 在真實的網絡環境中,每時每刻產生的數據流量都是巨大的,并且具有分布不均的特點。仿真實驗使用的數據9數據集中冗余和重復的樣本,樣本分布較KDDCup 99更合理。KDD99產出于1999年第三屆國集為NSLKDD,NSL-KDD是KDDCup 99的改進版本[6],主要是消除了KDDCup 9際知識發現和數據挖掘工具大賽。此數據集共有大約500萬條數據,共收集了9個星期。 本實驗使用的機器配置如下。處理器:11th Gen Intel(R)Core(TM)i5-11320H@3.20 GHz;內存:16.0 GB(單通道);硬盤:512GB(SSD)。 軟件環境及版本如下。操作系統:Windows 10家庭中文版21H2;集成開發環境:PyCharm 2021.1;編程語言:Python 3.6。 實驗評價指標是入侵檢測中常用的評價指標,分別為:準確率(Accuracy)、召回率(Recal)l、精確率(Precision)、F1 (F1-score)。 準確率(Accuracy)表示模型對給定樣本判別能力: 召回率(Recall)表示真實攻擊樣本在所有攻擊樣本中的比例: 精確率(Precision)表示真實攻擊樣本在被預測為攻擊樣本中的比例: F1(F1-score)表示整體指標及Recall與Precision兩項指標: 以上指標中,TP為預測為非入侵的正樣本;TN為預測為入侵的負樣;FN為預測為入侵的正樣本;FP為預測為非入侵的負樣本。 對同一數據集,用隨機函數選出訓練數據集,進行5次共得到5組隨機訓練集,在每組數據集上進行3輪訓練,取平均值,各指標見表1。 表1 不同訓練集模型檢測效果 除了已提出的模型,作為對照實驗,使用同一數據集在不同模型進行相關的實驗,結果對比見表2。 表2 不同模型檢測效果 通過橫向和縱向對比,可以得出算法模型具有一定的優勢。但是在實驗過程中也發現,對于流量相對較小的攻擊,無法充分學習其特征,從而導致檢測結果并不理想。在實際的環境中,攻擊行為越來越隱蔽且方式新奇,對于如何更好地及時檢測出這種攻擊行為,提高模型泛化能力仍是未來研究的重點。 機器學習與深度學習逐漸和入侵檢測領域交叉結合,取得了較好的效果。對入侵檢測進行了深入研究與設計,在神經網絡方面選取了結構更為簡潔的GRU網絡,提出了一種結合GRU網絡及K-means算法的混合入侵檢測方法,在兼顧檢測效率、精度及可靠性的同時,盡量控制成本。實驗結果表明,提出的方法為入侵檢測方法模型拓展了思路,具有一定的可行性,值得繼續深入研究。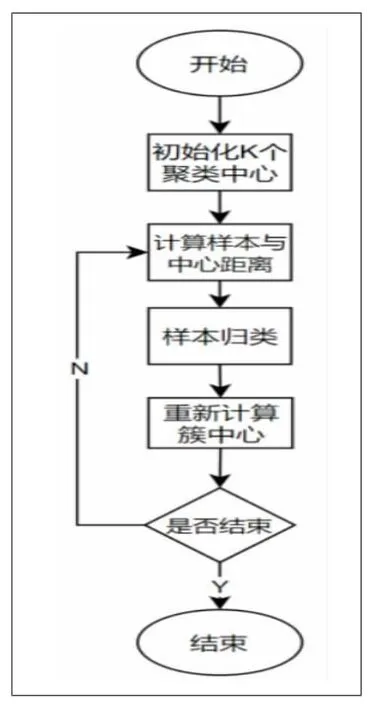
2 基于K-means算法的入侵檢測模型與方法
2.1 入侵檢測算法整體流程
2.2 基于GRU網絡的特征提取
3 實驗與結果分析
3.1 數據集
3.2 實驗環境
3.3 評價指標
3.4 實驗分析與結果
4 結語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2019年15期)2019-08-27 01:12:00
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
海峽科技與產業(2016年3期)2016-05-17 04:32:12
