一種無刷直流電機模糊自適應控制方法
2022-04-07 09:58:16宋麗君
制造技術與機床 2022年4期
宋麗君 王 燕
(洛陽理工學院電氣工程與自動化學院,河南 洛陽 471023)
無刷直流電機(brushless direct current motor,BLDCM)具有功率大、效率高、體積小和調速性能良好等特點,因而在航空、航天、兵器、工業和伺服系統等領域得到了廣泛應用。然而,BLDCM 是一個復雜系統,其內部變量眾多、非線性特性明顯,很難對其建立高精度的動態數學模型[1]。
模糊控制因模擬人類經驗、知識、判斷和推理過程,可用于難以建立數學模型的控制對象,故在BLDCM 控制中得到了廣泛應用[2-5]。然而,模糊邏輯控制器(fuzzy logic controller,FLC)的性能是由隸屬度函數和模糊規則決定,但隸屬度函數和模糊規則的建立、調試需要由該領域的專家根據經驗知識手動完成,主觀性較強;且控制對象不同,FLC的隸屬度函數和模糊規則也不相同。為此,研究如何自動生成FLC 便成為BLDCM 中的研究熱點。
自動設計FLC 主要分為3 種類型[6],第一類是FLC的隸屬度函數已知,對模糊規則進行自動生成和優化[7];第二類則是FLC的模糊規則已知,對隸屬度函數進行自動生成和優化[8];第三類是同時對FLC的隸屬度函數和模糊規則進行自動生成和優化。目前,隨著遺傳算法(genetic algorithms,GA)、粒子群算法等進化算法的快速發展,同時生成FLC的隸屬度函數和模糊規則已普遍應用[9-11]。
然而,在上述工作中,為自動生成FLC 多采用等腰三角形作為隸屬度函數,導致FLC 論域的覆蓋程度不足。FLC的隸屬度函數、模糊規則個數也多為固定值,不能更好地體現FLC的自適應性。且由于同時需要對隸屬度函數的模糊規則進行優化,導致染色體長度較長,造成運算的復雜性增加。
為解決上述問題,本研究提出一種基于GA 自動生成FLC的方法,可自主選擇隸屬度函數、模糊規則的數量,減少染色體長度,快速自動生成FLC。
1 BLDCM 工作原理
為了簡化分析,對無刷直流電機作以下假設:
(1)忽略磁路飽和,不計渦流和磁滯損耗。
(2)不考慮電驅反應,氣隙磁場分布為梯形波,平頂寬為120°。
(3)忽略齒槽形狀效應,三相繞組完全均勻分布。
(4)驅動器中逆變電路的開關功能器件均具有理想開關特性。
由此得到無刷直流電機的相電壓方程為式(1):

其中:U表 示該相電壓,V;R為 相電阻,Ω;L為相電感,H;M為與其他相的互感,M;e為該相的反電動勢;i為該相電流。
電機的電磁轉矩如式(2)所示:

其中:Te為電機電磁轉矩,ω為電機機械角速度。
電機的運動方程如式(3)所示。

其中:Tl為外部負載,J為電機轉動慣量,B為電機粘滯系數。
2 模糊自適應PID 控制器設計
2.1 模糊自適應PID 控制
PID 控制由于其原理簡單,算法易于實現,可靠性高、魯棒性好等優點,得到了廣泛應用。然而PID控制需要獲得被控對象的精確數學模型,對于非線性系統控制效果不好,PID 參數確定后無法更改。同時BLDCM 是一個非線性、強耦合系統,自身參數、負載及被控對象等時變性強、使得PID 控制在BLDCM 控制中的效果并不是十分理想。為此將FLC 引入BLDCM的PID 控制(稱為模糊自適應PID控制),利用FLC 來對PID的輸出進行實時在線調整,可有效提高對BLDCM的控制性能[12]。
模糊自適應PID 控制的基本思想是根據BLDCM的誤差E和誤差變化率Ec作為FLC的輸入量。在運行過程中,對E和Ec的變化進行實時檢測,依照模糊控制原理對PID 進行實時調整。此時PID的輸出kp、ki和kd應為:

其中:kp0、ki0和kd0為PID 控制器的原始數值;Δkp、Δki、Δkd為FLC的輸出調整數值。圖1 所示為模糊自適應PID 控制示意圖。

圖1 模糊自適應PID 控制示意圖
2.2 隸屬度函數的設計
隸屬度函數是模糊化過程中將精確量映射到各個模糊集合論域的重要環節。隸屬度函數的種類很多,其中三角型隸屬度函數表達式最為簡單,所需優化變量少而在自動生成FLC 中得到廣泛應用。但以往工作多將隸屬度函數數量固定為7 個,二輸入三輸出的FLC 中所有隸屬度函數的優化位數需要25 個。
隸屬度函數數量固定后,模糊規則的數量也隨之固定,不利于更好地體現FLC的優越性。且每個隸屬度函數需要優化位數較多,給優化造成一定困難。
為此,本研究采用文獻[13]的隸屬度函數優化方法。可大大減少需要優化變量個數。以一個輸入為例,僅需對2 個變量個數進行優化,分別用于確定隸屬度函數的個數和各隸屬度函數的分布情況。如此,對于二輸入三輸出的FLC,其隸屬度函數需要優化的個數僅需要5×2=10。
2.3 模糊規則的設計
模糊規則與隸屬度函數的數量息息相關,以往自動生成FLC 中對于模糊規則多采用字符串編碼,用不同數字代表不同的模糊規則,交由優化算法進行優化。如兩個輸入中隸屬度函數個數均為7,則模糊規則有49 條,需要147 位編碼。
同理選用文獻[13]的模糊規則優化方法,模糊規則中僅需對模糊規則的分布情況進行優化。則二輸入三輸出的FLC 中模糊規則的優化位數僅需5 位。
3 利用GA 自動生成FLC
3.1 基于GA 生成的模糊自適應PID 控制器
在利用GA 自動生成FLC 時,除前面所述的FLC 外,還需要對輸入的比例因子Gc、Gec和輸出的量化因子Gp、Gi和Gd進行優化,以確保精確數值能夠通過比例因子準確落在FLC的隸屬度函數工作范圍內。量化因子則是相反,需要將輸出的隸屬度函數轉化為精確數值,以實現對PID的自適應調整。圖2 所示為利用GA 自動生成的模糊自適應PID 控制器示意圖。

圖2 利用GA 自動生成的模糊自適應PID 控制示意圖
3.2 GA 編碼規則
依據前述可知,對于模糊自適應PID 控制器這個二輸入、三輸出的FLC,需要對輸入和輸出中隸屬度函數的數量、隸屬度函數的分布情況和模糊規則的構成情況,還有2 個比例因子和3 個量化因子進行優化。采用實數編碼的情況下,則對應FLC所需要的染色體的個數為5+5+5+5=20。
3.3 適應度函數
采用誤差絕對值時間積分性能指標作為GA 生成FLC 參數選擇的適應度函數。GA 算法中目標函數的選取非常重要,決定了算法能否達到預期控制目標,這里選取式(5)作為目標函數,在式(5)中加入u(t)的平方項,可以有效防止控制量過大。選用下式作為參數選取的最優指標函數。

式中:e(t)為 無刷直流電機被控量的誤差;u(t)為無刷直流電機的輸入量;tu為上升時間;w1、w2和w3為權值,分別取0.999、0.001和2.0。
無刷直流電機速度控制中一般不希望出現超調量,把超調量引入目標函數中,可以有效控制電機速度超調量,目標函數(5)就轉化為新的目標函數(6),如下式所示:
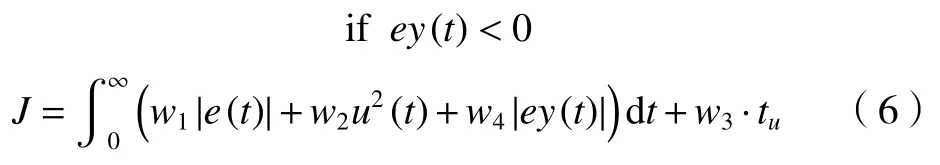
式中:ey(t)=y(t)-y(t-1),y(t)為 被控對象輸出。w4為權值,且w4?w1,w4取值為100。
3.4 選擇機制
為避免GA 進化時相同染色體過多導致早熟,采用無回放余數隨機選擇和最優保存策略相結合的選擇機制。可確保每一代種群中比平均適應度大的染色體能夠遺傳到下一代種群中,同時每一代適應度最高的染色體也可以遺傳到下一代種群中。
3.5 交叉和變異運算
交叉和變異運算是GA的重要環節,但由于以往交叉因子pc和變異因子pm多為固定值,不能自適應進行調整。為此,采用自適應交叉因子和變異因子(如式(7)、(8)所示),提高GA 運行效率。

式中:fmax、favg是當前種群的最大適應度和平均適應度值;f1為兩個交叉染色體中適應度較大數值;f2為 變異染色體的適應度數值;pc1和pc2為事先設定的交叉因子,分別取0.85和0.6;pm1和pm2為事先設定的變異因子,分別取0.1和0.001。
4 仿真與驗證
通過MATLAB 構建BLDCM 仿真模型,其參數為線電阻1.8 Ω,線電感為0.54 mH,額定工作電壓為24 V,額定轉速為800 r/min,電機反電動勢系數為0.066 V/(rad/s),轉矩系數為0.043 2 N·m/A,阻尼系數為0.05 N/(m/s)。
分別采用PID和模糊自適應PID 兩種控制方法對BLDCM的空載階躍進行控制,得到的結果如圖3所示。
由圖3 可知,模糊自適應PID 控制算法要比傳統的PID 控制算法更早達到穩定,前者約為0.003 s,后者則約為0.025 s,并且模糊自適應PID 控制算法沒有產生超調,而傳統PID 算法則產生了約1%的超調。

圖3 階躍控制圖
為測試模糊自適應PID 控制算法和傳統PID 控制算法對外部負載擾動的控制效果,在0.3 s 時對電機施加了0.2 N·m的外部負載,得到的仿真結果如圖4 所示。
由圖4 可知,模糊自適應PID 控制算法雖然在外部負載突變的情況下,產生了稍許的超調,但很快就達到穩定控制,耗時約為0.004 s。傳統PID 控制算法雖然未能產生超調,但達到穩定的時間較模糊自適應PID 算法大大增加,約耗時0.035 s。

圖4 外部負載擾動控制結果
5 結語
在傳統PID 控制算法的基礎上,通過遺傳算法自動尋優和設計模糊邏輯控制器,來對PID的控制參數進行微調,以便實現模糊自適應PID 控制。較人工設計模糊邏輯器的過程,具有速度快、精度高以及不依賴人的經驗等優點,并且模糊自適應PID控制的效果要比傳統的PID 控制效果更好。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
