基于ARIMA和XGBoost的滾動軸承故障預測模型研究*
2022-04-07 09:58:24張天瑞周福強吳寶庫朱芷儀宋雨儒
制造技術與機床 2022年4期
張天瑞 周福強 吳寶庫 朱芷儀 宋雨儒
(①沈陽大學機械工程學院,遼寧 沈陽 116300;②沈陽大學機械工程學院國際學院,遼寧 沈陽 116300)
在實際生產中,滾動軸承是大多數機械設備中應用最為廣泛的一類零部件,起著不可替代的重要作用。由于滾動軸承長期處在惡劣的工作環境下,使得其成為現代工業中最易受損的元器件之一[1]。比如在滾動軸承的大型發電機的故障中,軸承的故障率達到40%[2]。一旦滾動軸承發生損壞,輕則導致機器等大型設備損壞、影響正常生產,重則造成嚴重的人員傷亡和財產的損失。為了及時發現滾動軸承故障類型并采取相應對策,要求提前獲取軸承振動信號及軸承的數據,一般通過傳感器等設備感知其狀態;故障診斷和預測就是要分析這些數據從而評估出軸承的工作狀態。滾動軸承提取信號的影響因素分為內部和外部兩類[3],兩類因素的綜合作用會對需要提取的振動信號造成影響。因此,針對軸承故障診斷相關方面的研究對于零件、設備和生產過程等各個方面都有重大而深遠的意義[4]。
隨著故障診斷方面技術的迅速發展,人們對其進行了大量的研究和改進,對于滾動軸承的故障診斷方面的研究逐漸由新興問題演變為復雜問題[5-6]。
傅里葉變換和小波變換、希爾伯特-黃變換、經驗模態分解(empirical mode decomposition,EMD)、補充集合經驗模態分解(complete ensemble empirical mode decomposition,CEEMD)和變分模態分解(variational mode decomposition,VMD)等信號處理的傳統方法一般從傳感器提取的原始信號中提取時域、頻域和多域等有效故障特征;傳統機器學習的方法在故障診斷方面也得到明顯的應用并發揮其優勢[7-9];上述方法僅僅在一定程度上、單方面地滿足軸承故障對其準確度等的要求。馬懷祥[10-11]等從模型分類方面,提出卷積神經網絡(CNN)和極端梯度提升(XGBoost)的滾動軸承故障診斷方法,用以提升模型預測準確度。Hu X 等[12-14]為了提高頻譜精度,提出了基于LMD和頻譜校正的滾動軸承故障診斷方法。而龔立雄[15-16]等從特征提取方面入手,提出基于核函數主元分析的軸承故障分類方法,非線性分類對準確度提升有很大幫助。本文結合了前人多篇關于滾動軸承故障診斷方面的文獻,在工業大數據和深度學習的背景下,提出一種基于局部均值分解(local mean decomposition,LMD)和固定點算法(fixed points algorithm,FPA)聯合降噪、核主成分分析(kernal pricipal component,KPCA)和極端提升決策樹算法(extreme gradient boosting,XGBoost)思想結合自回歸積分滑動平均(autoregressive integrated moving average model,ARIMA)時間序列模型的軸承故障診斷方法。基于滾動軸承故障診斷降噪-提取特征-分類(故障識別)所使用的不同方法,本文構建了滾動軸承的故障診斷模型,并使用美國凱斯西儲大學軸承數據集進行仿真驗證。
1 故障診斷過程
滾動軸承診斷和預測的事先準備過程為信號降噪和敏感特征提取:由于滾動軸承的工作環境復雜等影響條件下,提取的軸承信號具有大量背景噪聲,而其存在影響敏感特診提取,進而影響故障識別的準確度;用于軸承狀態檢測的特征指標有很多種,一般分為兩類,基于時域特征(是否存在故障)或基于頻域特征(故障內在原因)的選取。同傳統的軸承故障診斷的特征選取環節中不同的是,本文不采用單一的基于時域、頻域的輸入指標,而是通過多域提取出的特征(全面表現軸承的狀態變化過程)作為診斷模型的輸入,選取敏感多特征指標進行診斷分類,即為滾動軸承故障識別的過程。現多使用改進神經網絡、隱馬爾科夫模型和支持向量機等軸承故障診斷方法[17-18]。但由于面臨生產環境爆炸式增長的數據量的現狀,傳統的機器學習算法計算的準確度上相較于深度學習略顯不足。近年來,大數據方面應用較廣的 XGBoost算法能夠有效地應對上述問題;預測未來短時期滾動軸承信號趨勢的方法一般有支持向量機(support vector machine,SVM)、灰色理論和ARIMA 等;ARIMA 自回歸模型具有計算效率、準確度高[9]等特點,因此本文采用ARIMA進行故障預測。圖1 中闡述了故障識別和預測的一般過程:首先需要通過適合的傳感器采集到軸承的振動信號,振動信號經過濾波處理之后再經由敏感特征選取結合歷史數據使用ARIMA 自回歸模型預測未來的振動趨勢,再將預測的結果輸入到XGBoost數學模型中進行驗證,最后根據預測的結果做出相應的對策。

圖1 滾動軸承信號預測和故障診斷過程
2 理論和求解過程
2.1 LMD+FPA 聯合降噪
由于滾動軸承受到工作環境等影響,其通過傳感器獲取的滾動軸承的原始信號中包含大量無用噪聲干擾,降噪后的原始信號又需要進行提取特征的環節,而特征提取的參數又作為診斷模型的輸入;如果包含的噪聲不能有效去除,其提取的特征會與真實值發生明顯的差異,進而影響診斷模型的準確度。因此,對于原始信號的降噪處理顯得尤為重要。
LMD 是一種基于時域和頻域的自適應信號分析方法;其本質在于將原始信號分解為若干個分量值和殘余值。為了克服傳感器接收到的原始信號中具有不同信號源產生的多種信號的混合信號,又采用獨立分量分析(independent component analysis,ICA)[13]方法解決上述問題。ICA 方法又被稱為固定點算法FPA。固定點算法基于不同信號源頭之間統計的相互獨立性,它同傳統的濾波方法相比,對要求的原始信號的細節保留得更為徹底。綜上,本文采用LMD+FPA 聯合降噪的方法。下面是LMD 降噪方法在處理原始信號時的推導過程:
(1)選取包含大量噪聲的原始信號s(t),尋找其不間斷的極小值mk,c和極大值mk,c+1,順序計算兩兩鄰近的極值間的局部均值ni,k。極值點的相序數以c來代表;k代表求解極值過程的總次數;i代表有多少個分解完成的PF分量。再按照順序求解相鄰的極值差得到局部包絡值:局部包絡值和平均值的計算公式為:

(2)局部包絡函數ai,k(t)以 及局部均值函數ni,k(t)即為兩值之間構成的連續函數,通過移動平均(MA)法對上述兩個函數進行平滑處理。
(3)去除局部均值函數以后得到hi,k(t),再通過ai,k(t)進行解調得到調頻函數zi,k(t):

(4)局部包絡函數ai,k(t)越接近1,調頻函數zi,k(t)越 能滿足純調頻信號的條件。一般地,1-δ≤ai,k(t)≤1+δ的條件用來判斷局部包絡函數ai,k(t)能否滿足純調頻信號。δ是預先確定好的一個較小參數。當條件滿足時計算乘積函數;若條件不滿足,則令ai,k(t)乘ai,k-1(t)后返回第一步。當條件滿足時得到純調頻信號zi,k(t), 純調頻函數zi,k(t)在 [-1,1]范圍內的包絡信號ai,k(t)=1。當ai,k(t)與接近1時,將局部包絡函數ai,k(t)相乘,ai(t)為 包絡信號,q為最終的循環次數:

(5)將ai(t)與zi,q(t)相乘,可以得到乘積函數PFi(t),zi,q(t)為純調頻信號;用乘積函數PFi(t)減去原始信號s(t)得到剩余信號。剩余信號ui(t)則重復(1)~(5)的過程,一直到滿足條件之后剩余一個單調函數或極值點未知,停止計算。

經過上述幾個步驟之后,復雜原始信號s(t)在經過上述迭代過程以后被分解成n個乘積函數PF和一個剩余函數un(t):

LMD 過程中各個變量的含義:s(t)為原始信號;mk,c為局部極小值;mk,c+1為 局部極大值;ni,k為局部均值;c為極值點序數;k為求解極值次數;i為PF分量個數;ai,k(t)為局部包絡函數;ni,k(t)為 局 部 均值函數;zi,k(t)為 調頻函數;ai(t)為 包絡信號;q為循環次數;PFi(t)為乘積函數;zi,q(t)為純調頻信號;ui(t)為剩余信號。
由于FPA 只適用于觀測信號的數量大于等于源信號數量的情況,要求LMD 方法能夠來解決ICA方法下的欠定盲源分離問題。本文使用LMD 降噪方法將原始信號剔除剩余信號(噪聲值)后,又將重構虛擬的觀測信號和觀測信號構成一個新的二維矩陣,矩陣作為ICA的輸入。首先,LMD 方法將原始信號分解為若干個PF 分量。其次選取相關程度較大的分量信號之間重構形成虛擬觀測信號。最后重構得到的虛擬觀測信號和原始混合信號之間組成一個新的二維矩陣,使用ICA 方法予以分析分解,最終達到對原始信號中濾除無用信息的目的。兩種方法聯合降噪過程如圖2 所示。

圖2 LMD+FPA 聯合降噪過程
2.2 KPCA 特征提取過程
核主成分分析KPCA 又被命名為核主分量分析。和PCA 方法有所區別的是,KPCA 采用非線性方式進行樣本的空間變換,通過選取合適的非線性函數將原始的樣本數集映射到高維空間中,再在高維空間上對樣本的多向量進行主成分分析。因為其具有包含非線性分類方式的特點,非線性數據集的問題通過KPCA來解決是十分合適的[16]。
核主成分分析通過非線性方式把低維空間的數據向量轉換到另外一個高維空間F,再計算協方差矩陣C。協方差矩陣C的特征向量和特征值需要滿足以下條件:
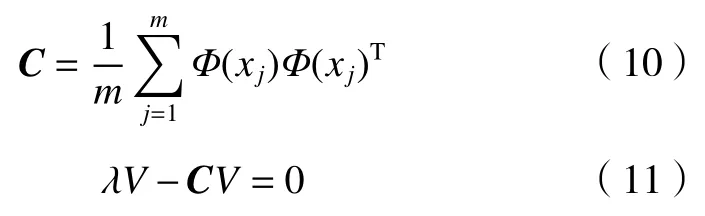
Φ(xj)為非線性函數,將其代入后得到:

特征向量可以用 Φ(xi)來線性描述,即:

引入核函數Kij=K(xi,xj)=Φ(xi)Φ(xj),簡化后可以得到:

綜上,隨機選取的樣本在特征空間F中主元成分 Φ(x)上的投影可以表示為:

KPCA 過程中各個變量的含義:F為高維特征空間;m為低維空間樣本數量;xi為低維空間樣本;Φ(xj)為 非線性函數; Φ(xi)為高維空間樣本點;K為核矩陣;C為協方差矩陣;V為C的特征向量;λ為C的特征值;α為K的特征向量。
2.3 Arima 預測振動信號
Arima 模型的基本原理是借助自身原始的數據集合經過差分處理之后再通過自身數據的特點進行未來一段時間內數據的預測[9]。相關圖用來判斷使用MA、AR 或者AR-MA 模型,若時間序列通過N階差處理后達到平穩狀態,則使用Arima 模型。下式為Arima 模型的計算公式:

式中:μ代表常數項;εt為隨機誤差值;γi為自相關系數;θi為 移動平均系數;p為自回歸項、q為移動平均項、d為時間序列平穩所需的次數。預測的數據集若為非平穩序列,一般先通過差分處理轉化為平穩序列,再使用AR-MA 模型進行擬合;若為平穩非白噪聲序列,需要求出自相關系數和偏相關系數結合相關圖分析得到p、q值。
2.4 XGBoost 過程
XGBoost 是華盛頓大學的陳天奇博士在2016 年基于梯度提升決策樹算法提出的一種基于梯度提升決策提升集成學習算法[12]。它經由GBDT 算法改進后得到,它的學習器可以是CART 決策樹(GBTree),也可以是線性分類器(GBLinear)。一般來說,XGBoost、GBDT 算法和隨機森林是一個遞進的關系。其中,GBDT 算法在隨機森林的基礎上融合了XGBoost 思想,使得森林的樹之間建立聯系而不是獨自存在,形成一種整體有序的決策測體系。同樣地,XGBoost算法以決策樹作為基礎,引入了二階泰勒展開和正則項,可以有效地控制模型的復雜程度(模型方差大幅度降低),訓練后的模型更簡單和穩定。XGBoost 能夠為運算過程中產生的缺失值設定分支的默認方向,此外XGBoost 還支持特征級別上的并行計算,加入的正則項防止過擬合和欠擬合現象的產生。XGBoost的關鍵是建立多個決策樹來有效地降低預測結果的誤差,并保證回歸樹組成的樹群有盡量大的泛化能力[19-20],最優泛化函數(Loss)的表達式如下:
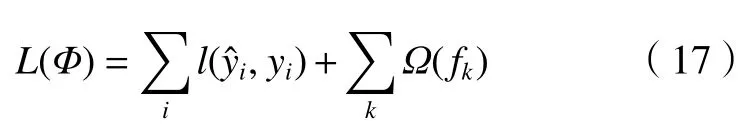
式中:求和函數分別為誤差函數和正則懲罰項。誤差函數中的參數y?i是整個模型的輸出;正則懲罰項表達式如下:
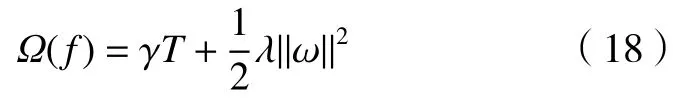
式中:T為決策樹葉子節點個數;ω為節點;XGBoost中要求對Loss 函數進行二階泰勒展開:

3 數值驗證和仿真過程
3.1 數值驗證
本文采用的軸承數據集來自美國凱斯西儲大學。使用的Python 版本為3.8.5、電腦CPU 為i7-9750h;使用的內存大小為16 GB。本次使用的滾動軸承數據集中包含7 個樣本:選取5 組作為訓練集,剩余2 組作為測試集。
3.2 數據分析
滾動軸承的整個運行周期是從完全健康狀態開始一直到發生不同類型的損壞以后結束的。傳感器為了全面監測軸承整個周期的狀態變化,從完好的狀態開始進行記錄,直到發生故障以后停止記錄。因此采集到的滾動軸承的信號包含有用的信息。本文選取前5 個樣本數據使用LMD+FPA 降噪完成預處理后進行特征提取。本文綜合考慮了時域特征和頻域特征,對經過降噪的原始信號進行KPCA 方法處理來得到多域特征,包括滾動體故障的特征和內圈故障等敏感特征,提取后的敏感特征作為診斷模型的輸入。
3.3 Arima 模型預測
Arima 模型用來預測未來一段時間內信號發生的變化,用以判斷數據是否穩定,并選取差分次數為1;時序圖圍繞其均值上下波動,自相關圖短期相關性較強。圖3和圖4 分別為原始信號和原始信號經過1-2 階差分處理之后得到的結果,圖5 為Arima 模型的振動信號預測結果。

圖3 1 階差分(ACF)

圖4 2 階差分(PACF)

圖5 Arima 預測振動信號圖
經過差分處理之后的數據用Arima 模型加以預測:選取11 000 個數據進行預測,預測完未來時期內的振動信號之后,還需要對其進行指標評估。常用評估指標如表1 所示[20]。

表1 幾種常見的模型評估標準
由于單一評估指標只能片面反映模型的性能,因此需要綜合地使用多個評估指標才能準確反映模型的預測結果。本文采用了準確率、精確率、召回率3 個方面作為模型的評估標準。評估結果如表2所示。

表2 ARIMA 預測振動信號性能
3.4 XGBoost 分類
XGBoost 將提取好的特征作為分類模型的輸入,為了方便區分,本文將軸承的幾種狀態用不同的數字加以表示:1 代表滾動體故障,2 代表外圈故障,3 代表內圈故障;0 為無異常狀態。0~3的作為分類模型的輸出。本次實驗使用前5 組作為訓練數據,經過降噪和提特征后輸入分類模型中進行訓練。XGBoost 模型的各個參數為:最大樹度為22;學習率選取為0.35;最小權重為0.1,而Score 得分為0.953。使用最后兩組數據用于測試,預測結果如圖6、7 所示。

圖6 第一組測試集的預測結果
圖6 中:10 000~40 000 雖然樣本數據期間發生波動,但波動程度較小,直到40 000~60 000 數據又趨向于平穩狀態。當接近60 000 組數據時,發生明顯波動,且60 000~70 000 值上升較快,代表軸承發生故障狀態的可能性增高,值圍繞在0.8 附近,根據之間分類的結果判定為滾動體故障,與實際結果相符合;圖7 中0~5 000 組波動較小,5 000~10 000樣本間基本上趨于平穩,13 000~20 000 組時波動情況較大,20 000 組以后值明顯升高,根據模型輸出結果判別為內圈故障,與實際結果一致。兩組測試結果均反映此模型可以較好地反映軸承故障的類型。

圖7 第二組測試集的預測結果
4 結語
本文針對滾動軸承故障診斷問題中的背景噪聲大,提取有效特征難和傳統機器學習算法準確度低的問題上,提出了基于Arima 自回歸和XGBoost 思想的模型用于軸承故障診斷和預測的方法。經由美國凱斯西儲大學軸承實驗數據進行實例驗證證明了本方法可以短時期內預測軸承狀態和故障類型,以便于為滾動軸承的后期維護、更換等做好準備。
(1)Arima 自回歸模型在處理非平穩振動信號采用N階差分的方式,可以短時間內預測軸承信號的走向和趨勢。
(2)XGBoost 算法在應對殘差值的處理方面優于GBDT 集成思想算法的改進,能夠有效地糾正診斷過程中發生的誤差,不斷進行修正,提升了模型分類和預測的準確度。
(3)基于Arima+XGBoost的滾動軸承故障識別和預測方法不僅在數值仿真過程中得到有效應用,也為滾動軸承應用于各種大型機械設備在實際生產中提供了一種參考方案。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
