卷積神經網絡在表情識別上的研究綜述
2022-04-12 01:52:51趙宣棟陳曦
計算機時代 2022年4期
趙宣棟 陳曦

摘? 要: 近年來機器學習和深度學習在機器視覺方面已取得了很大進展,表情識別已然成為其中的熱門領域。表情識別的應用使得計算機可以更好的理解人類情緒,具有較高的研究價值和應用前景。本文歸納了表情識別領域常用公開數據集;介紹了表情識別的基本流程與常見方法,以及不同卷積神經網絡在表情識別方面的方法研究與分析;針對表情識別領域現存問題和未來發展進行了分析總結。
關鍵詞: 表情識別; 卷積神經網絡; 機器學習; 深度學習
中圖分類號:TP391.41? ? ? ? ? 文獻標識碼:A? ? ? ?文章編號:1006-8228(2022)04-01-04
Research of convolutional neural network in expression recognition
Zhao Xuandong Chen Xi
(1. School of Computer Science and Information Engineering, University of Harbin Normal University, Harbin, Heilongjiang 150000, China;
2. Zhengzhou University of light industry, College of computer and communication engineering)
Abstract: In recent years, machine learning and deep learning have made great progress in machine vision, and expression recognition has become a hot field. The application of expression recognition makes computer better understand human emotion, which has high research value and application prospect. In this paper, the common public data sets in the field of expression recognition are summarized; the basic process and common methods of expression recognition, as well as the research and analysis of facial expression recognition based on different convolutional neural networks are introduced; the existing problems and future development in the field of expression recognition are analyzed and summarized.
Key words: facial expression recognition; convolutional neural network; machine learning; deep learning
0 引言
19世紀,達爾文[1]第一次提出對表情進行研究,直到現在對表情的研究仍在繼續。1969年,Ekman等[2]人通過深刻的研究將人的表情詳細劃分,建立了面部動作編碼系統,這一系統對之后的研究影響深遠。在Ekman的面部動作編碼系統基礎上,很多學者通過將人臉劃分為多個動作單元,再組合一個或多個動作單元,來描述人的面部動作,進而對人臉面部細微表情進行檢測。目前,表情識別不僅廣泛地使用在司法、臨床、治安等領域,也引起了社會媒體和科學界[3]的廣泛關注。
1 基于卷積神經網絡的表情識別研究與進展
1.1 表情數據集
人的表情并非單一的,所以收集數據集時很難保證每個表情都具有單一性,加之收集時受外界條件影響較大,而非專業人員又難以準確鑒別,因此專業性的表情數據集數量較少[4],詳細數據集情況如表1所示。
1.2 基于LeNet-5模型的表情識別
20世紀末,LeCun研究團隊開發了第一個卷積神經網絡模型--LeNet-5模型[5]。該模型適合用于字符識別,如果想要使用LeNet-5模型對表情來識別,需要對嘴巴、眼睛以及其他面部皺紋的細微變化分別進行識別,因此需要大量的特征圖像。同時,由于其網絡結構過于復雜,且對硬件配置要求過高,導致訓練時間過長,所以其實用性,性價比較低。因此,在實驗中一般使用改進后的LeNet-5模型,增加C1和S1層的特征圖數量,降低C3和S4層的特征圖數量,僅保留一個全連接層。
改進的LeNet-5的優點是可用于實際自然場景下和非證明的表情識別,其正確率和有效率遠遠高于LeNet-5模型,并且隨著訓練次數的不斷增加,每批樣本的損失函數會逐漸下降,最終逐漸趨于平緩。當訓練達到38000次左右時,損失函數的變化就會小于0.001。但是,由于需要更多特征圖來檢測面部表情的細微變化,因此,需要更長時間來計算卷積,所以改進后的LeNet-5訓練時間會相對較長。
1.3 基于AlexNet模型的表情識別
相比于LeNet-5網絡,AlexNet網絡有很大的改進,主要體現在GPU訓練,通過將網絡擴展在兩個GPU上進行訓練,加速網絡訓練速度和加深網絡的層數,且將原LeNet-5網絡的7層擴展到11層。加深網絡的深度可以增進訓練速度,但是同樣也暴露出Sigmoid激活函數存在的問題。據研究數據顯示,當網絡深度隨著需求增加時,Sigmoid激活函數出現明顯的梯度彌散。為解決這一問題,AlexNet網絡選擇放棄Sigmoid激活函數,改用Relu激活函數。除此之外,AlexNet網絡新加了LRN層[6],從而促進了大的響應神經元,抑制了反饋小的神經元,同時提高了模型的泛化能力。此外,該模型也利用大量的ImageNet和Dropout機制來減少過擬合情況。7342C20B-B95E-461D-9C3C-9DD9AA43235D
1.4 基于VGGNet模型的表情識別
VGGNet[7]是由Google Deep Mind團隊和牛津大學合作完成的,可以說是 AlexNet的高配加深版。與AlexNet模型相比,VGGNet通過不斷增加網絡層數,發現了神經網絡的網絡深度對模型性能產生的直接影響。VGGNet的卷積核采用小而多的形式,使用了三個3×3的卷積核,而不是一個大的卷積核。這樣做的好處是既增大了網絡的深度,也沒有加大運算量。在相同的感受野下,可得到更為精密高效的計算結果。此外,VGGNet具有較強的場景遷移性,在任何場景與環境上都具有較強的泛化能力。
VGGNet與同時推出的GoogleNet都是在AlexNet網絡結構的基礎上改進而得到,它們共同的特點就是“深度”[8]。GoogleNet模型的突出點在于模型結構,而VGGNet更注重網絡深度。與GoogleNet相比,VGGNet使用三個3×3的卷積核,使原始圖像的感受野達到一個7×7的卷積核的效果,但是與一個7×7的卷積核相比,圖像經過3次激活函數的非線性變換具有更好的表達性,也能夠相對減少參數量,這也是VGGNet遠超其他網絡泛化能力的根本原因。在實驗中,將進行VGG-16網絡在Softmax損失+中心性損失+人臉驗證損失和三元組損失兩種不同訓練下的性能統計。在兩種損失信號都能達到99.2%的情況下,用VGG-16進行表情識別時,同樣以RAF-DB和CK+作為數據集,其正確率可以分別達到67.06%和91.10%。
1.5 基于GoogleNet模型的表情識別
GoogLeNet相對于其他卷積神經網絡來說,是較為新的卷積神經網絡算法。首次提出是在ILSVRC14比賽上,GoogLeNet是一個深達22層的深層網絡[9]。GoogLeNet的研究核心是如何優化卷積神經網絡的局部稀疏結構,使其盡可能的接近實際密集內容。
在GoogLeNet中,每個模塊的輸入都是在上一個分支在獲得一個特征映射后,將這些相同比例的特征映射拼接在一起,再傳遞給該模塊。為避免模塊的對齊問題,Inception結構采用了不同尺度的嵌套低維濾波器,可以保留多個感受野的局部相關信息。在這種情況下研究發現,使用5*5的卷積核仍然會給程序帶來巨大的計算量。為解決這個問題,GoogLeNet選擇了與VGGNet完全不同的方法,通過在每個分支上加一個1×1的卷積核,來有效的減少參數數量。
與AlexNet和VGG不同的是,Inception V1用全局平均池化層代替全連接層,這一改進將參數的數量減少到前所未有的少量,但研究人員可以添加全連接層來微調和再訓練,以便在其他模式識別場景中使用;其次,為了解決網絡深度過深造成的梯度消失現象,Inception V1額外增加了兩個分類器層,反向傳播使用多個損失信號進行參數梯度計算;最后Inception V3基于NIN思想的精髓,設計了一個精細的Inception模塊,以提高網絡參數的利用率。
在實驗時我們使用CK+數據集進行擴充,進行預處理后進行訓練,結果顯示,GoogleNet無論是從頭訓練還是微調的情況下都能夠取得比AlexNet更好的識別效果。
1.6 基于ResNet模型的表情識別
2015年,ResNet [10]在ILSVRC 2015比賽中奪冠,進而進入大家的視野當中。ResNet引入了殘差單元,利用殘差的思想成功訓練了深度高達152層的神經網絡,從此一鳴驚人。為避免深度網絡中的性能下降,ResNet[10]采用了對網絡中模塊學習目標函數進行變換的方法。打個比方,如果輸入n網絡模塊,那么其他神經網絡學習目標函數為H(n),但如果n是直接連接到輸出,那么學習目標則為H(n)-n,所以只需要學習最初學習目標和網絡模塊輸入數量的差值即可,這也是“殘差”的由來,這樣做的最大優勢是簡化了學習的目標數量和難度,也為超深層網絡的訓練提供了方向。
在兩層殘差學習單元模型中,k層直接輸入x1到k+2層輸出,然后將k+2層輸出作為k+3的輸出。而只有維度相同的向量才可以相加,所以在殘差過程中不能進行池化操作,并且卷積核數和輸出數必須相等,否則就必須使用一個1×1卷積進行線性變換。而在第三層殘差學習單元模型中,使用了兩個1×1的卷積核,可以通過卷積核的個數實現特征圖的降維和升維操作。
2016年,KaimingHe等人提出ResNetV2。該模型易于訓練,具有較強的泛化能力。與ResNet相比,ResNetV2將ReLU激活函數改為同等映射函數,且在每一層中添加了批量歸一化技術。
在表情識別中,ResNet網絡在表情識別數據集進行訓練時,其正確率高達67.50%和92.21%,比VGGNet和AlexNet都要高出很多,同時其參數量又遠小于其他經典網絡。
2 存在的問題及發展趨勢
2.1 存在的問題
⑴ 缺乏對現實人類的研究。表情識別研究所用數據集絕大部分為基本表情數據集,雖然在這一方面取得了不小進展,但是由于人的表情是多變和復雜的,所以絕大部分研究成品都無法應用到現實中。
⑵ 面部表情數據嚴重不足。現在已有的表情數據庫中每個表情的數據都比較少,而且都非常刻意,表情流露不自然,與自然境況下的表情存有一定的差異,難以成為十分精確有效的數據,并且其中的動態序列圖像更是嚴重缺乏。
⑶ 研究場所多為實驗室,缺少真實情況下的訓練。表情識別的研究絕大部分是在理想適合的條件下進行的。但是由于自然環境下會出現遮擋物體、遮擋人臉,不同時間亮度不同,以及周圍環境等其他的情況,都會對面部表情識別結果產生較大的影響,最終導致實際結果與實驗結果有所不同。
⑷ 當前表情識別多數僅能在單一表情情況下識別。人類表情是豐富多彩的,每種表情之間的界限與區別都是模糊的,就像一個人的圖片是睜大眼睛的,這有可能代表害怕,也有可能代表驚喜或驚奇。7342C20B-B95E-461D-9C3C-9DD9AA43235D
⑸ 不同人的臉部存在差異。在同種人的情況下,由于每個人的民族、年齡、生長條件等因素都會影響到識別的正確性。且不同種族下人的習慣又存在差異,導致人臉很難使用統一的模型來歸類,增加了識別難度。
2.2 發展趨勢
⑴ 研究新的更加高效,更加精準的識別算法。一個新的高效算法可以有效增加識別效率和降低識別時間,可以更大范圍的應用到各個場景當中。
⑵ 加強三維立體面部表情識別的研究。與二維圖像相比,三維立體圖像更接近于真實環境,其能包含更多、更準確的人臉特征,結合三維信息可以更好地解決光照亮度等問題。
⑶ 在現實生活的應用。一個人的表情往往可以直接反應出其內心的心理變化。如果可以把表情識別與心理學、神經科學、犯罪學等學科結合,那么對于社會發展與治安將會產生巨大效益。
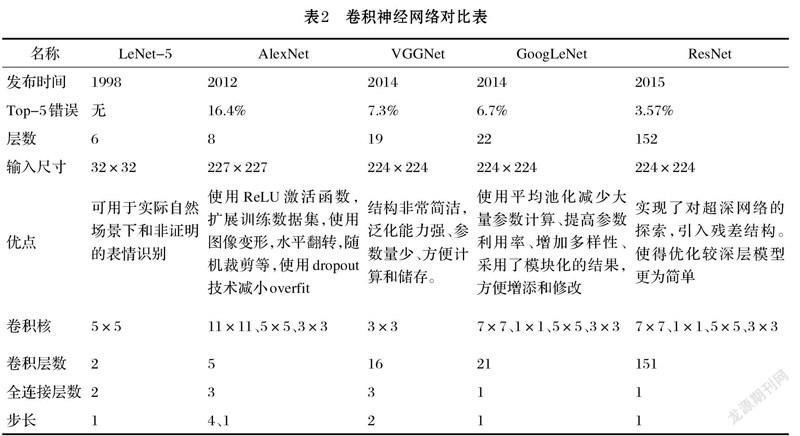
卷積神經網絡的適用范圍越來越廣,可處理的數據越來越多,其模型層數也從幾層變為上百層。本文對比和總結了熱門模型情況。如表2所示。
3 結束語
算法在不斷改進,而卷積神經網絡依然是計算機視覺乃至深度學習和機器學習領域的主流模型,但是由于人類表情具有多樣性、模糊性等特點,導致真實情況與研究情況產生誤差。因此,與其他識別相比,表情識別發展相對較慢,在現實中的應用也較少。但表情識別在臨床醫學、人機交互以及心理分析等方面具有不可代替的地位,具有廣闊的應用前景。除此之外,表情識別技術在理論上已相當成熟,但在真實情況下的識別率和準確度還有待提高,例如在室外的識別需加大研究力度。總的來說,卷積神經網絡強大的特征提取能力極大地促進了表情識別領域的發展,基于卷積神經網絡的表情識別具有巨大的發展潛力和應用前景。
參考文獻(References):
[1] DARWIN C. The expression of the emotions in man and
animals[M]. University of Chicago Press,1965
[2] EKMAN P, Friesen W V. The repertoire of nonverbal
behavior: categories, origins, usage, and coding [J]. Semiotica,1969,1(1):49-98
[3] SCHUBERT S. A look tells all [J]. Scientific American
Mind, 2006,17(5):26-31
[4] DAILEY M N, JOYCE C, LYONS M J, et al. Evidence and
a computational explanation of cultural differences in facial expression recognition [J]. Emotion,2010,10(6):874-893
[5] YANN L C, BOTTOU L, BENGIO Y, et al. Gradient-
based learning applied to document recognition[J]. Proceedings of the IEEE,1998,86(11):2278-2324
[6] DHALL A, GOECKE R, Lucey S, et al. Collecting Large,
Richly Annotated Facial-Expression Databases from Movies[J].IEEE Multimedia,2012,19(3):34-41
[7] SIMONYAN K, ZISSERMAN A. Very Deep Convolutional
Networks for Large-Scale Image Recognition[J]. Computer Science,2014,1409(15):1-9
[8] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking
the Inception Architecture for Computer Vision[C],Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:2818-2826
[9] HE K, ZHANG X, REN S, et al. Deep Residual Learning
for Image Recognition[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:770-778
[10] HUANG G, LIU Z, et al. Densely Connected
Convolutional Networks[C],Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:4700-47087342C20B-B95E-461D-9C3C-9DD9AA43235D
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
科學與財富(2016年28期)2016-10-14 21:19:17
