
基于機器學習的乳腺癌預測研究
2022-04-29 17:56:08張浪張星錢佳怡楊霜玲
計算機應用文摘 2022年19期
張浪 張星 錢佳怡 楊霜玲

摘要:通過對kaggle官網關于乳腺癌的相關數據集的分析,文章選取了數據集中相關性較強的10個指標,對各個指標進行數據處理,使用隨機森林、XGBoost、相關性分析進行模型建立分析。通過機器學習,得到相關結果以及準確率、精準率、召回率和F1,并通過比較不同算法之間準確率、精確率的差異,得出最優的預測研究方案機制。通過模型對比評價,XGBoost算法的準確率、精確率等均在93.5%以上,隨機森林算法的準確率、精確率等均為92.4%。相比之下,XGBoost模型預測效果較佳。利用機器學習研究乳腺癌的預防預測,并應用于實踐,對乳腺癌早期診斷有著十分重要的意義。
關鍵詞:機器學習;乳腺癌;隨機森林;XGBoost;相關性
中圖法分類號:TP181文獻標識碼:A
Breast cancer prediction research based on machine learning
ZHANG Lang,ZHANGXing,QIANJiayi,YANGShuangling
(Guizhou Medical University,Guiyang 550025,China)
Abstract:Based on the analysis of the data set related to breast cancer on kaggle official website,10 indicators with strong correlation in the data set were selected for data processing.Random forest, XGBoost and correlation analysis were used for model establishment and analysis.Relevant results, accuracy,accuracy,recall and F1 were obtained through machine learning,andtheoptimal prediction research scheme mechanism was obtained by comparingthe difference of accuracy and accuracy among different algorithms. According to the evaluation of model comparison,the accuracy and accuracy of XGBoost algorithm are above 93.5%,and those of random forest algorithm are both 92.4%.XGBoost model has better prediction effect in comparison.It is of great significance for the early diagnosis of breast cancer to study the prevention and prediction of breast cancer with machine learnig and apply it into practice.
Key words: machine learning, breast cancer,randomforests,XGBoost,dependency
1 研究背景
乳腺癌是乳腺細胞在內外環境因素影響下發生了異常細胞增殖反應而最終失控導致癌變的臨床現象。其病變初期常表現出的癥狀為出現乳房腫塊、乳頭溢液、腋窩淋巴結的明顯充血腫大或壓痛感等各種局部癥狀,晚期患者也可能因淋巴結被癌細胞直接感染,導致發生了腫瘤及遠處組織淋巴性轉移,出現了乳腺周圍多部位淋巴器官良性增生及病變,甚至可能威脅乳腺患者的生命[1]。根據醫療數據顯示,全球乳腺癌的發病率逐年升高,這對社會經濟發展造成嚴重影響,乳腺癌的早期診斷,尤其是當病灶尚不能被觸及時,若能及時發現,可以明顯改善預后。人工智能的發展可以協助醫生工作,幫助組織、理順和簡化診斷程序或其他醫療決策過程。利用數學模型以及統計方法分析數據資料,能夠依據乳腺癌的相關特征對乳腺癌進行細致分類,從而應用于臨床,實現對不同個體的診斷和預測。機器學習算法在乳腺癌預測的應用,有利于乳腺癌的風險評估,從而幫助患者了解自身疾病特征,達到預防疾病的目的;對乳腺癌進行分級診斷,從而根據特征施行相對應的治療方案,這對乳腺癌的“對癥下藥”、分級診斷和預防有著特別重要的意義。
2 研究現狀
在以計算機學科為研究對象的背景下,很多學者應用理論與技術的結合,以提高乳腺癌預測的檢測水平。乳腺癌是乳腺上皮細胞在多種致病因子的作用下,發生增殖失控的現象。劉宇等[2]將聚類算法與XGBoost算法結合在一起,應用K?means算法對所收集的數據按照其各自的特征進行了區分,并且利用XGBoost算法對乳腺癌進行了預測和分析。國內外專家學者針對乳腺癌的研究已經取得了一定的成果,隨著醫療信息化的發展,人們開始使用信息技術解決乳腺癌診斷治療中的問題,目前利用特征因素對乳腺癌進行預測是該領域研究的熱門。并且,隨著乳腺癌研究的深入,人們意識到單一的生理指標并不能對乳腺癌做出很好的預測,所以開始基于大量數據來分析、挖掘各種指標之間的聯系以及對結果的影響,從而建立起一些常見的乳腺癌的預警模型[3]。比如,DL 模型幫助患者提前五年預測乳腺癌,實現及早確診、及早治療;我國自主研發的治療乳腺癌抗 HER2單抗創新藥伊尼妥單抗打破進口藥壟斷。
3 數據及可視化
本文數據來源于kaggle官網關于乳腺癌的公開數據。樣本數據共569條,包括10類影響指標,即半徑、紋理、細胞核周長、細胞核面積、平滑程度、緊密度、凹度、凹點、對稱性、分形維數。通過對不同類型數據的整理,使用機器學習算法對數據進行定量和定類分析及訓練。數據變量如表1所列。
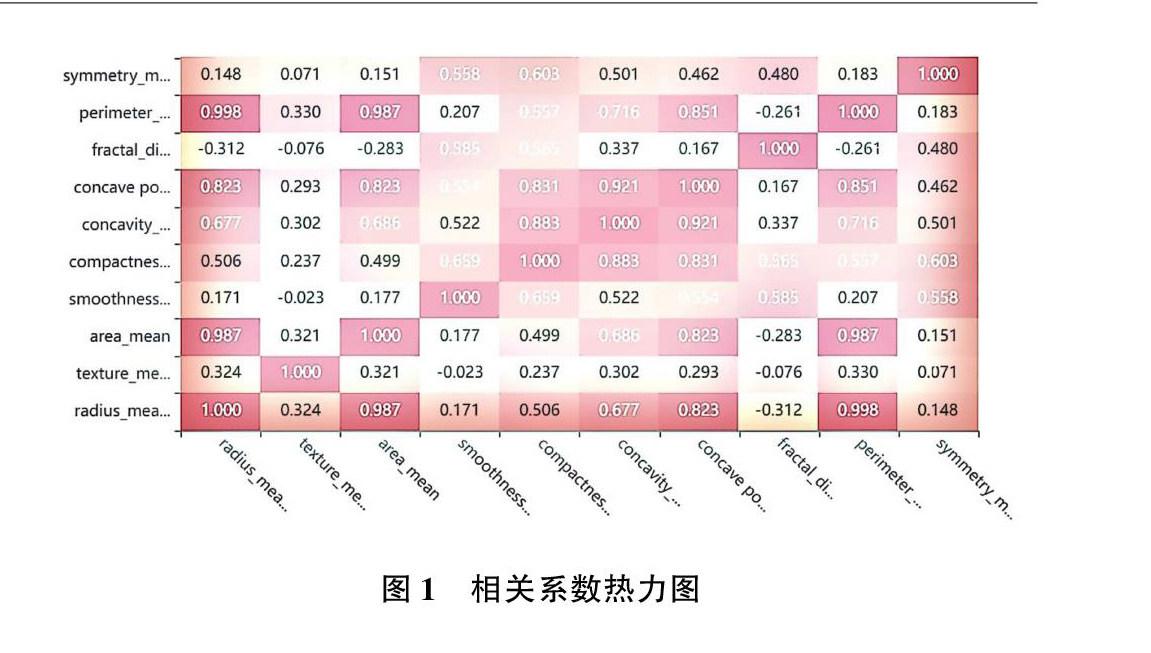
圖1為利用各類指標數據構建相的關系數熱力圖,樣本呈現正太分布狀態。組織核的平均面積與半徑和參數的均值呈強正相關;一些參數中度正相關( r 在0.5~0.75之間)的是凹度和面積,凹度和周長等;同樣,可以看到 fractal_ dimension 與半徑、紋理、參數平均值之間存在一些強烈的負相關。由此可以推斷,乳腺腫塊的細針抽吸物(FNA)半徑、周長、面積、緊密度、凹度和凹點的平均值可用于癌癥的分類。這些參數的較大值傾向于顯示與惡性腫瘤的相關性。質地、平滑度、對稱性或分維數的平均值并未顯示出較好的診斷偏好。
4 實驗過程和結果分析
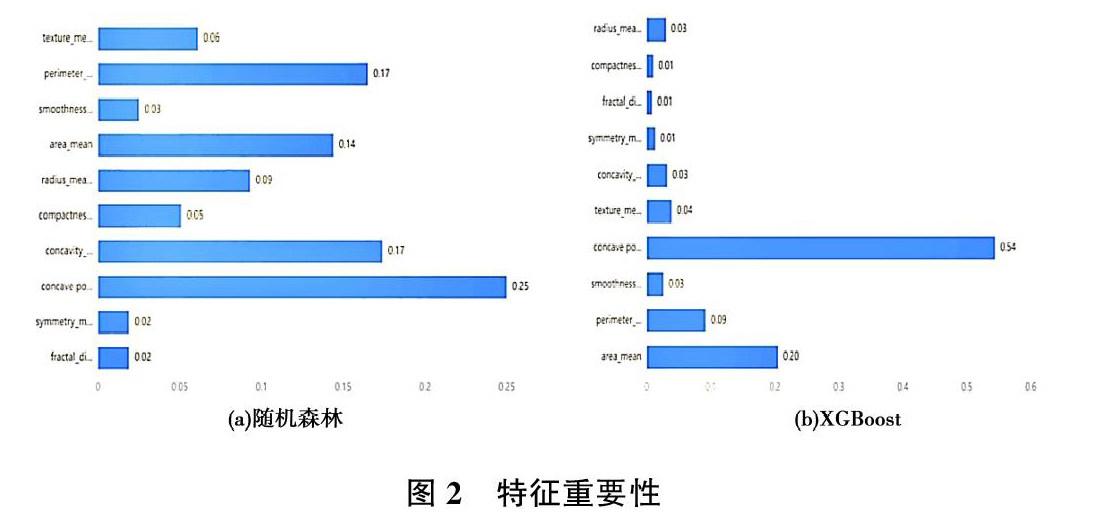
本文選取相關性分析、隨機森林、XGBoost三種機器學習方法對乳腺癌吸針抽物相關特征進行對比分析,以實現對乳腺癌的早期預測。通過統計產品與服務解決方案軟件 SPSS 進行算法分析,建立測試集和訓練集;以預測分析結果中的預測準確度、精確率、召回率、F1為主要評判參考指標;同時,通過建立混淆矩陣,對預測分析模型中的實際可用于預測對象的預測能力水平等進行綜合量化與評判。通過統計產品與服務解決方案軟件 SPSS 進行算法分析可得隨機森林和XGBoost特征重要性的結果分析,結果如圖2所示。
圖2展示了各特征(自變量)的重要性比例。通常情況下,特征越多分類效果就越好。但是,使用過多的特征會大幅增加模型運算量和模型運算的時間、費用等成本,降低整個模型的平均運算效率。因此,本文對相關數據進行了特征選擇,隨機森林和XGBoost按照數值大小呈正比,表現出重要性程度高低,計算出特征重要性。通過隨機森林特征重要性排名進行結果比較,對特征進行分析可知,面積、周長、半徑能夠較為直接衡量細胞核的相關特征,同時凹縫、凹度也屬于重要的特征值,有較強的區分度;對比XGBoost特征可知,凹度、周長、半徑能夠較為直接衡量細胞核的相關特征,同時凹縫、面積也屬于重要的特征值,有較強的區分度。對特征值取平均值,在統計上平均值反映出的是更加普遍的情況,具有更強的可用性。
訓練數據集是指構建模型時使用的樣本集,而測試數據集是指對最終模型進行性能評估的數據集,通過矩陣工廠 MATLAB、統計產品與服務解決方案 SPSS 進行混淆矩陣熱力圖分析。
混淆矩陣利用了準確率 A( Accuracy)、精確率 P (Precision)、召回率 R(Recall)和 F1四個評價指標來進行定量和評估分類器系統的分類效果與性能。準確率表示分類正確的樣本數在整個樣本中所占的比例,準確率越高,則預測越準確;精確率表示分類正確的正類樣本數占分類為正類樣本總數的比例;召回率表示分類正確的正類樣本數占原正類樣本數的比例; F1是精確率和召回率之間的折中,F1測度值越高,則分類效果越好。各指標的計算公式如表2所列。
其中,TP =真正例,TN =真負例,FP =假正例,FN =假負例,ncorrect=TP+TN,ntotal=TP+TN+FP+FN
由表3可知,在相同的數據集下,XGBoost分類的準確率為93.6%,而隨機森林的準確率為92.4%,其準確率越高說明算法越好。由此可見,XGBoost算法比隨機森林精準。F1值綜合了精確率與靈敏度的大小,由表3可知,在 F1值方面,XGBoost分類模型的 F1高于隨機森林分類模型1.2%,精確率高1.1%,召回率高1.2%。本文認為,通過對準確率、F1值、召回率、精確率的對比,XGBoost分類模型比隨機森林分類模型有所提高,因此可以認為該模型對輔助醫生診斷乳腺癌,對乳腺癌分類預測研究具有較大的意義,有較強的可行性。
5 結論
本文著重對乳腺癌的分類預測進行研究,通過對數據的處理,建立相關預測模型,并對模型準確度進行對比評價。模型顯示,乳腺吸針抽物的凹度、周長、半徑、面積對乳腺癌早期監測有較好的指標作用,這對如何實現低成本、檢測快、無副作用的乳腺癌患者的分類預測非常重要。同時,對于慢性疾病管理也具有重要意義,但是由于收集資料和時間有限,未來的研究中,需要從以下方向進行改進:(1)慢性疾病是一類疾病的總稱,本文僅構建了乳腺癌疾病預測和預測系統,接下來可以對其他慢性疾病的預測進行研究:在建模時選取 UCI 公開數據庫里相關數據,一方面在區域性和時限性存在缺陷,另一方面數據量有限,在建立模型時可能導致模型欠擬合,未來可以采用不同的數據集對模型進行修正,以提高預測的準確性;(2)對于慢性疾病患者而言,做好康復和護理是必不可少的一步,這也是醫護人員所關注的重點之一,所以未來可以在該系統上進行功能完善,建立“醫護康”一體化信息平臺,實現對慢性疾病患者的全生命周期管理。
參考文獻:
[1] 祝江濤.分析乳腺癌患者術后睡眠質量及相關影響因素[J].世界睡眠醫學雜志,2021,8(8):1330?1331.
[2]劉宇,喬木.基于聚類和XGboost算法的心臟病預測[J].計算機系統應用,2019,28(1):228?232.
[3]劉亮.機器學習算法在疾病診斷中的應用研究[ D].貴陽:貴州大學,2020.
作者簡介:
張浪(2001—),本科,研究方向:數據分析與圖像處理。
張星(2001—),本科,研究方向:XGBoost與相關性分析。
錢佳怡(2003—),本科,研究方向:隨機森林。
楊霜玲(2001—),本科,研究方向:數據挖掘。
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
中國生殖健康(2019年2期)2019-08-23 08:11:42
中國生殖健康(2019年6期)2019-01-06 09:20:12
祝您健康(2018年5期)2018-05-16 17:10:16
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科技視界(2016年21期)2016-10-17 17:37:34
中國實用醫藥(2016年24期)2016-10-17 04:31:12
中國實用醫藥(2016年24期)2016-10-17 03:37:40
中國實用醫藥(2016年24期)2016-10-17 03:35:06
