老年2型糖尿病患者血糖趨勢預測模型構建初探
2022-05-07 03:37:52曠小羿徐巧玲徐偉張海峰耿新玲侯惠如
中國臨床保健雜志 2022年2期
曠小羿,徐巧玲,徐偉,張海峰,耿新玲,侯惠如
1.中國人民解放軍醫學院,北京 100853;2.中央軍委聯合參謀部警衛局衛生保健處;3.中國人民解放軍第三〇五醫院藥局;4.首都醫科大學生物醫學工程學院;5.中國人民解放軍總醫院第二醫學中心護理部
我國糖尿病患者人數龐大,已成為主要的公共衛生負擔[1],其中2型糖尿病(T2DM)占90%以上[2-3]。生活方式的自我管理(飲食攝入、體力活動、用藥情況、血糖監控等)是優化血糖的關鍵[4-6]。對于患者而言,堅持持續有效的自我管理比較困難[7-8]。建立血糖趨勢預測模型[9]可實現血糖水平的短期預測(15、30、45、60 min),利于患者積極采取干預措施,達到優化血糖的目的。動態血糖監測(CGM)設備能提供較為完整的血糖圖譜[10],促進了人工智能模型的構建[11]。支持向量回歸(SVR)是使用較早且較為普及的模型構建方法[12],而基于長短期記憶(LSTM)單元的遞歸神經網絡(RNN)是目前較為前沿且使用最多的人工智能算法[13]。因此,本研究采用SVR與LSTM-RNN這2種方式構建老年T2DM患者血糖趨勢預測模型,并對比模型表現。
1 對象與方法
1.1 研究對象 選擇2020年11月至2021年5月于中央軍委聯合參謀部警衛局保健處門診部就診且符合納入標準的T2DM患者12例。2例因無法堅持記錄生活數據而退出,1例因記錄的數據質量不合格而剔除,最終獲得9例數據(回收率75%)。其中女5例,男4例,年齡(68.4±6.7)歲,糖尿病病程1~21(7.0±2.2)年,體重指數(BMI)21.89~26.35(23.85±1.82)kg/m2。8例口服降糖藥,1例接受胰島素治療,糖化血紅蛋白(HbA1c) 4.8%~9.8%(6.77%±1.76%),CGM值為(7.17±2.05)mmol/L。納入標準:①具有一定的閱讀能力,自愿參與并簽署知情同意書;②符合2020年版《中國2型糖尿病防治指南》[1]診斷;③年齡≥60且<80歲;④交流無障礙;⑤具有基本運動能力者;⑥未患有精神疾病,具備學習能力者;⑦能按時提交連續血糖監測期間的個人飲食、運動等數據;⑧能做到遵醫囑按時服藥。排除標準:①合并嚴重心、腦、腎、眼、足及其他限制活動的致殘性疾病;②基本運動能力差,生活不能自理者;③未能按時服藥者;④課題組認為不適合入組的其他情形。
1.2 研究方法
1.2.1 數據收集 使用9例各14 d的數據組成數據庫。包括個人血糖數據及生活數據。血糖數據的收集采用雅培輔理善瞬感(Abbott Free Style Libre),每名患者連續監測14 d,設備以15 min的時間間隔自行記錄血糖值。血糖監測期間的生活數據由患者根據課題組發放的數據采集表自行記錄,分為:飲食、運動、用藥及睡眠。飲食數據根據《中國食物成分表標準版(第6版)》,依照食物種類及量,采用各供能營養素(蛋白質、脂肪、碳水化合物)克重量乘以相應的能量轉換系數,再求和而得,能量單位為kJ。運動數據根據薄荷健康運動卡路里計算器,將受試對象記錄的運動內容轉換為消耗的熱量值(kJ)。睡眠數據根據睡眠時長,轉換為時間數據(單位:s)。用藥數據為時間點的有或無(1或0)。運用python軟件構建數據轉換程序,將血糖與生活數據轉為可用于機器學習的,以15 min為時間戳的五維數據。數據不做平滑處理,均為原始數據納入模型。
1.2.2 模型構建 采用LSTM-RNN與SVR兩種方法構建模型。模型的數據納入中,CGM結合飲食簡寫為CGM+D,CGM結合飲食、運動簡寫為CGM+D+E。在此次模型構建中,為減少數據類型的復雜度及噪聲,睡眠及用藥數據僅作為患者個體的特征體現,不進行相應的納入對比。LSTM-RNN中,采用遷移學習(TL)策略[14],以縮減時間,并提高預測患者的準確性,即先使用所有患者的數據創建遷移學習數據集,用于預訓練全局LSTM 模型。然后根據每個患者的個人記錄,對全局模型進行個性化處理。模型均采用過去60 min的數據來預測未來血糖水平,預測范圍(PH)為15、30、45、60 min。

2 結果
2.1 數據基本情況描述 數據總量為15 678條,其中CGM數據12 382條(占比79%),飲食記錄數據2 521條(占比16%),藥物數據359條(占比2.4%),運動數據290條(占比1.8%),睡眠數據126條(占比0.8%)。
2.2 模型表現
2.2.1 模型預測評價 SVR構建血糖預測模型,在相同數據輸入下,模型表現隨著PH的延長而下降,差異有統計學意義(P<0.05)。在相同PH下,PH=30 min時,3種數據輸入模式其RMSE值差異有統計學意義(P<0.05),其中CGM+D的RMSE值最低(見表1);組間比較顯示飲食與運動數據的加入提升模型表現,差異有統計學意義(P<0.05);而飲食與運動數據之間的比較,差異無統計學意義(見表2)。
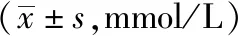
表1 SVR模型不同組別及PH的血糖預測結果比較
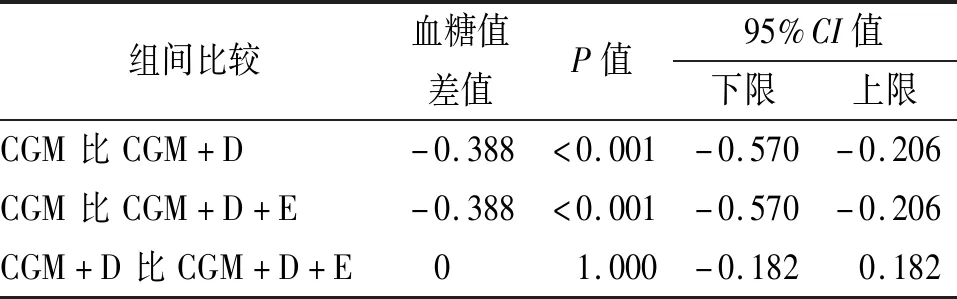
表2 SVR模型PH=30 min時不同數據輸入的結果比較
神經網絡技術復雜,結構層次多,對數據量的要求更大,因此本研究LSTM-RNN模型在預測60 min時無法收斂,只預測到未來45 min。該算法的模型呈現更具復雜性,整體而言,隨著PH的延長,模型表現差異無統計學意義(見表3)。
表3 LSTM-RNN模型不同組別及PH的血糖預測結果比較
在相同PH下,PH=45 min時,飲食數據的加入提升了模型表現,差異有統計學意義(P<0.05),而運動數據的加入對模型的影響差異無統計學意義(見表4)。
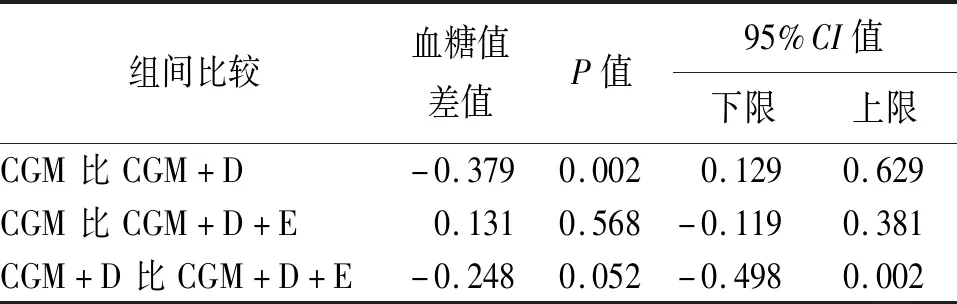
表4 LSTM-RNN模型PH=45 min時不同數據輸入的結果比較
比較這兩種模型,PH=15 min時,SVR優于LSTM-RNN,差異有統計學意義(P<0.05);PH=30 min時,模型表現差異無統計學意義;而隨著PH的延長,到SVR(45/60 min)與LSTM-RNN(45 min)時,LSTM-RNN的模型表現提升,差異有統計學意義(P<0.05)(見表5)。

表5 SVR與LSTM-RNN模型性能比較
2.2.2 Clarke誤差網絡分析結果(EGA) 兩種模型均表現出個體化的高度匹配,以血糖波動最大的4號患者為例。在SVR模型下,PH=60 min時的CGM+D+E數據輸入EGA表現為:A(91.12%),B(7.23%);PH=15 min時,LSTM-RNN模型下的CGM+D+E數據輸入EGA表現為:A(93.82%),B(6.18%),模型預測結果均達到臨床可接受度(見圖1)。
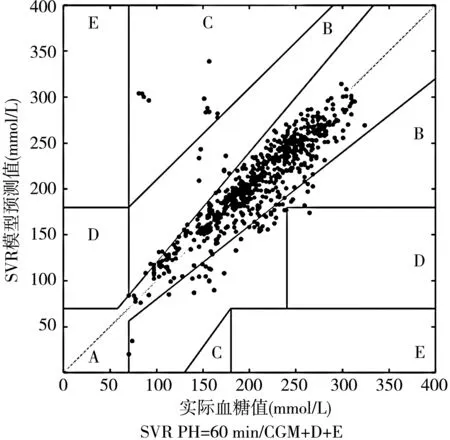
圖1 4號患者2種構建模型下的Clarke-EGA表現圖
3 討論
我國糖尿病患者血糖控制達標率僅45.8%~58.4%,且年齡越大達標率越低[15-16],與2025年糖尿病患者規范管理率需達到70%[17]的國家目標相比,還有不小的差距。血糖預測模型的構建能提升醫護人員血糖管理效率并幫助患者更直觀地理解生活方式如何影響血糖水平,并以此促進生活方式的持續有效管理[18],減少因血糖不良波動而導致的危害[19]。血糖預測模型的研究中,絕大多數是針對T1DM患者[13],與其對胰島素的絕對依賴、人工胰腺的使用和使用CGM設備的普及性有關。而目前針對老年T2DM患者的個體化血糖趨勢預測模型的研究仍鮮有報道。因此本課題組根據保健工作實際需要,研究針對老年T2DM患者的血糖預測模型。
本研究構建的血糖預測模型能反映出不同個體基于個體特征,對熱量值(攝入為正值,運動消耗為負值)的不同反應。該模型能解決兩個問題:一是在當前時刻(t0)預測未來一定時間內的血糖值,二是預測攝入一定熱量值時,個體后續時段(t0+n)的血糖反應。這兩個功能,將有利于醫護人員對患者血糖趨勢的預判及熱量相關措施的選擇,使得精準化保健工作成為一種可能。模型表現RMSE及Clarke誤差分析證實了模型的可實用性。
從模型表現來看,在當前研究人群中,飲食是血糖的主要影響因素。2種模型在加入飲食數據后,模型表現均提升,且優于運動數據。這與運動方式效率不夠,對血糖的影響小,在模型里影響輕微,甚至拉低了部分模型表現。回看患者的運動記錄,大部分為散步,該方式效率低,既耗時又能量消耗小。對于老年人而言,該運動方式較為和緩且單一,對血糖調控力差,在后續的生活方式指導中,應該調整該類人群安全、有效的運動方式。SVR模型短時表現優于LSTM-RNN,但LSTM-RNN表現出更為復雜的特性,隨著PH的延長,模型表現提升且優于SVR算法,這與神經網絡算法擅長處理各輸入數據與血糖水平之間的高度異質且非線性關系有關[13]。隨著患者記錄的數據越來越多,該模型將變得更加個體化,從而在預測血糖方面達到更高的準確性[20]。在此次研究中,SVR的60 min/CGM+D+E與LSTM-RNN的45 min/CGM+D+E,其模型表現均是臨床可接受。
綜上所述,飲食是該類人群主要的影響因素,運動方式有待改善。模型可對患者進行有效的熱量相關指導。課題組會在數據的深度(延長CGM設備佩戴周期)和廣度(增加受試對象)2個方面進行擴充,進一步提升血糖趨勢預測模型性能,達到有效輔助醫護人員管理老年T2DM患者血糖,促進其健康、有效的生活方式,優化血糖水平的目的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
保健醫苑(2022年6期)2022-07-08 01:26:34
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭醫學(下半月)(2020年1期)2020-05-11 02:05:44
媽媽寶寶(2017年3期)2017-02-21 01:22:30
飼料與畜牧(規模養豬)(2016年5期)2016-12-01 03:48:40
光學精密工程(2016年6期)2016-11-07 09:07:19
人人健康(2016年13期)2016-07-22 10:34:06
