國內外科學數據重用理論研究與實踐進展
2022-05-07 11:24:34尹文辰
山東圖書館學刊 2022年2期
尹文辰
(上海大學文化遺產與信息管理學院,上海 200444)
1 引言
近些年來,伴隨著科學技術、社會經濟的發展,學者們對于大數據的研究方興未艾。隨著科學研究的不斷深入,科學數據也在不斷產生和利用,科學數據的重用行為(下文簡稱“數據重用”)也開始逐漸興起。從科學數據的開放到數據的重用,其中可能涉及到數據共享、數據組織、數據存儲等等各個流程。每個流程之間環環相扣,其最終目的是實現數據資源的開放與最大化的利用[1]。并且數據資源往往可以通過廣泛的社會服務,發揮其潛在價值,進而可以減少國家的重復投資,提升科研投資的效率[2]。但是,由于每一類、每一領域的科學數據都具有自身的特征,或是體現在收集難易程度上,或是在數據的表現形式上,因此,人們逐漸意識到科學數據重用的研究價值,針對科學數據重用的研究也日益豐富,并且不少機構數據庫也對數據重用發布了相關說明與規定。
因此,本文通過搜集國內外有關科學數據重用的文獻,總結出過去及當下學者們研究的側重點,并發現數據重用在當下研究的未普及之處與理論不足,再結合有關政府、機構、數據庫等實際的工作進展,作出相應的總結與思考,以便未來學者們做進一步研究。
2 文獻來源
首先,本文通過CNKI、WOS、BING、EBSCO、Elsevier等國內外數據庫,以“數據重用”“數據復用”“date reuse”為主題詞做精準搜索,篩選出符合本研究領域文獻54篇。其次,在參考了J.Webster等學者們給予文獻綜述的建議[3]:可以從檢索出文獻的引文中篩選出符合研究主題的相關文獻,共獲得有效文獻33篇。再者,通過閱讀以上相關文獻后筆者發現,“數據重用”“數據共享”“數據引用”等關鍵詞經常共同出現,所以為了更全面了解“數據重用”,筆者又以上述關鍵詞及其英文表達作了精準檢索,鑒于本文研究以“科學數據重用”為主,因而只選擇了部分引用量較多的代表性文獻。最后,在實踐層面,筆者又去NIH、NASA、NSR、ESRC、Scientific Data、中國自然科學基金、中國科學院情報文獻數據中心等國內外知名數據庫網站查閱了“數據重用”的相關實際政策及實踐工作的開展情況,并進行了歸納總結。
3 有關科學數據重用概念的研究
對于科學數據重用的研究,可以追溯到上個世紀。起初,學者們對于科學數據重用的研究側重點還在該行為的意義和目的方面。Martin ME、King[4][5]等人率先提出數據共享和重用這一行為概念,指明其目的是讓研究再現、增加創新的可能性、提升數據的價值。1997年,國際科學委員會再次強調了數據的價值在于它們的共享和重復利用[6],而這也為之后開放科學的建立打下了基礎。
進入21世紀后,學界對于數據重用的研究重點有了些許的變化,由注重意義、結果和價值影響方面,轉變為開始討論“科學數據重用”行為本身的問題。如Karast[7]等人就發表了自己的看法,認為數據重用是指那些沒有收集數據的人使用數據,其關注的重點為是否使用他人數據而非能產生什么結果。數據重用在這一時期往往被界定為數據的二次使用,并且這些數據的意義已經不由其原始的目的所決定,而是旨在解決新的問題。
隨著開放科學的不斷發展,我們也逐漸步入大數據的時代,越來越多的學者注意到科學數據對于研究成果的重要性。面對大數據時代海量的數據,如何去做好數據管理就成了當下的研究熱題,因而有關數據共享、引用、重用等方面的研究此起彼伏。
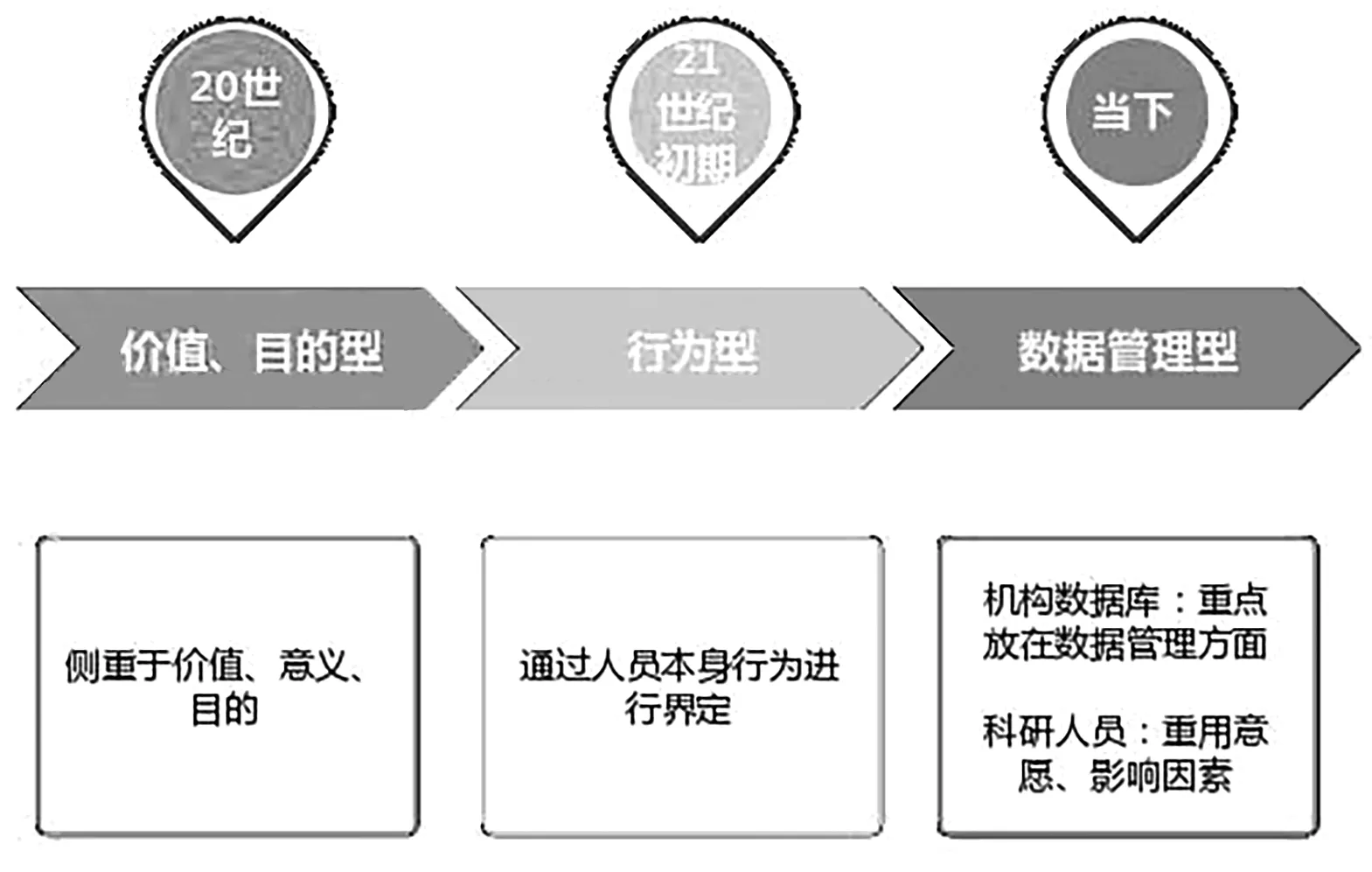
圖1 科學數據重用定義發展歷程
通過觀查數據重用研究的發展歷程可以從以下三點著手定義:數據重用目的確認、數據重用行為界定、數據重用相近概念辨析。對于數據重用目的,多數學者們表現出較大一致性,認為重用他人的數據可以降低自己研究的成本,并且還可從原有數據中激發靈感。對于數據重用行為界定,可以分為直接使用與間接使用。直接使用則主要包括對原數據的獲取、設立數據鏈接(引用)、進行數據挖掘等行為,將原數據直接用于的新研究;間接使用則主要表現為對原數據或數據集進行修改、刪減、合并等,獲得衍生數據,再以衍生數據作為支持新研究的關鍵。對于數據重用相關概念,文獻調研顯示術語“數據重用”與“數據共享”“數據引用”經常共同出現,而且容易混淆,三者有聯系但概念又不是完全一致。數據共享可以認為是數據重用的前提,只有數據先被創造者通過某些渠道發表共享,其他人才可能接觸到這些數據,才可能發生重用行為[8]。數據引用作為實現數據共享的重要手段[9],本身則是數據重用的一種表現形式。數據在被共享以后不一定會發生重用行為,但數據重用則往往伴隨著數據的共享。
綜上所述,本文暫且將數據重用的概念定義為:借助一定的手段,通過公開的數據庫、平臺或個人、研究小組等,搜集曾經為了研究一個問題而產生的數據,直接作為一個新的問題的研究基礎,或衍生出新的數據(集),使原數據的價值擴大化,并以數據支持研究的行為。
4 有關科學數據重用行為偏好及影響因素的研究
4.1 科研人員數據重用行為偏好的研究
4.1.1 以科研人員為中心的研究
此研究的重點則在于將研究人員按照不同的標準進行劃分,這類研究的數量相對較多。常見的劃分標準有科研人員年齡[10]、所屬科學研究領域等等[11][12]。
在年齡方面,研究發現[13]低年齡(小于40周歲)的研究人員更傾向于數據共享和重用,但同時他們也要求研究由自己主導,并且希望研究成果被發表;中年齡段(40-49周歲)的研究人員更傾向于在科研小組中共享重用數據,并致力于從這些共享數據的重用中創新開發新的數據,但他們對于一些數據管理組織的認同感較低;高年齡段(50周歲及以上)的研究者聲稱他們共享的數據比其他年齡段的人都多,但在其他年齡段的研究者想要獲取這些數據時卻遭到不少的限制,即高年齡階段的科研人員數據共享重用意愿與行為呈現脫節狀態。
在學科領域方面,自然科學領域和人文社科領域對數據的使用率均呈現較高水準,部分細分的學科領域數據使用率甚至高達100%,但重復使用率在不同領域則表現出較大的差異性[14]。有研究表明85%的重用行為主要發生在三個具有數據密集型特征的領域[15]。它們是農業和生物科學(55.9%)、環境科學(16%)和醫學(13.6%)。究其原因,根據一些調研文獻表示,最初數據共享被認為是始于這三個研究領域,是發展基礎設施、資源和政策以促進數據共享的先驅,因而導致這些研究領域重復使用的數據數量也遠大于其他研究領域。
隨著調研的深入,又有學者發現無論是自然學科還是人文社科,即使是部分數據使用率較高的領域如醫藥衛生技術和社會科學Ⅱ兩個領域,重復使用率也保持較低水平[16]。這可能是由于學科差異的影響,不同學科科研人員的思維方式不同,并且在缺乏規范的數據重用規則、缺少便捷的數據獲取渠道等多方位因素的環境下,造成這些領域的數據重用實踐發展較為緩慢。
另一方面,即便在數據重用率較高的一些領域,科研人員的數據重用行為仍存在些許差異,其中較為明顯的是數據來源和原因差異、重用動機差異。a.數據來源和原因方面,經濟學領域的科研人員傾向于重用規范性的數據庫和統計年鑒的數據,因為他們更在意數據的完備性、適用性和數據量的大小[17];管理學領域數據來源以政府和商業數據庫居多,個人或團體數據偏少,因為這些數據庫更具有準確性,且易獲得[18];生物科學領域的科研人員在理論突破、學術研究方面傾向于重用文獻中的數據,在遺傳學和腫瘤學等實踐性較強的學科研究中傾向于重用已有的數據集或小組數據[19],因為重用自己的數據或在產生數據的同一研究小組中的數據可以有效避免數據權限和隱私問題,并且由于對該數據的熟悉,也使得重用起來更易于解釋和可信,進而使研究更具有權威性[20]。整體上來說各學科領域之很難表現出較大一致性,這種現象很大程度上源于不同學科領域的科研人員思考問題的方式不同、研究問題的類型不同、解決問題的手段也不同,因此在解決實際問題如制定重用規范時,應根據具體領域的特點,因“域”制宜。b.在重用動機方面,相對而言學科間的統一性會顯著一些。以管理學、經濟學為代表的人文社科領域科研人員數據重用往往是為了滿足他們的信息需求[21],隨著信息化的發展,此類需求的數量也在不斷上升,因而促進了科研人員數據重用;而以生物學、醫學為代表的自然學科領域科研人員數據重用往往是因為他們學科領域的數據具有一定的不可復制性[22][23],若不進行數據重用,則很可能會加大研究的難度,并且新獲得的數據也很有可能受到外界質疑,因此他們選擇重用科學數據進而很好地規避這些風險。
4.1.2 以科學數據為中心的研究
這類研究重點則在于將科學數據進行不同種類的區分,而這些區分的標準相比較于科研人員而言,就比較能凸顯出較大的差異性。其中較為常見的劃分標準為數據的類型、數據的使用方式、使用數據的目的、數據的搜集手段等,此外還有學者按照數據的導出格式規范進行劃分并開展了相應的研究[24][25]。調查發現,不同研究將數據按照不同標準劃分,總能發現不同類型數據的重用行為差異性,因此此類研究難以得出概括性結論。
4.2 影響科研人員數據重用因素的研究
此類研究學者們也是按照不同標準先將人員或者數據劃分為不同的群體,然后再探究不同群體之間的差異性。整體而言,在借鑒了部分學者們的分類標準的基礎之上[26],本文將這些影響因素歸納為個人因素、技術或環境因素兩大類。
個人因素方面,科研人員對科研數據重用生態系統的態度與感知對其重用行為具有重要影響[27],數據重用的感知效能、感知重要性、數據質量更能促進科研人員數據重用行為[28],數據重用的感知努力、感知風險會對科研人員數據重用行為有負面影響[29]。在眾多研究結果中,與常理較違背的是對重用數據缺乏信任并不會導致科研人員停止使用該重用數據,可能是科研人員會想方設法攻克這些問題,具體原因還可進一步探究。另外,根據文獻調研結果,此類因素的研究數量是整體研究數量中最多的,可能原因是此類研究方法較為成熟、模型應用較為廣泛、調研數據較為易得。但也因此導致研究的結果可能會具有一些局限性,因為此類研究往往是基于問卷調查,問題的設計往往具有一定主觀性,且不同的研究人員設置的變量差異性較大,收集的數據也僅僅是為自身研究量身定制的。
技術或環境方面,數據的完整性、可訪問性、可獲取性、易操作性、數據平臺可信度以及科研人員知識背景和數據模型都將影響數據重用行為[30-34],但具體到某個點的影響力度或者定量分析方面還欠缺一些研究。多數學者們都在強調數據重用規范則會較大程度影響科研人員數據重用行為,但在具體實施規范方面,相應的研究數量則較少。另一方面,雖然規范的數據管理和可靠準確的數據是科研人員愿意利用數據的前提[35],但是對那些已經采用成熟的數據管理方法的人來說,這些外來的規范幾乎沒有影響甚至有負影響[36]。這也從另一個方面說明數據重用規范的制定可能并不一定都是有利的,因此需要進一步深究。
5 有關科學數據重用所遇到問題的研究
5.1 針對數據本身問題的研究
根據中國科學院情報文獻中心[37]的定義,指出科學數據應以實際應用為主,因此如何解決數據的使用以及儲存問題就成為關鍵。首先,最直觀的問題便是數據的可用性問題以及去文本化問題(去除在原有研究中特定的環境含義)[38]。由于科學數據多數是在一定的科研環境中形成,其或多或少會帶有一定的環境特征,這些特征往往體現在數據的記錄形式及其注釋上,而對此卻缺乏完善的規范體系[39],這就可能導致他人理解該數據的難度大大增加,從而限制了比較分析,阻礙了數據共享與重用[40]。
其次,科學數據的版權問題也不容忽視。隨著我國法治社會體系的發展,公民們的版權意識也在不斷提高,對于數據版權的討論也日益增多[41]。但相比較于國外,國內關于數據版權的研究就相對較少,且分析力度不足。受版權的影響,其他人可能難以接觸到這些已經成形的數據或數據集,數據重用則更加困難。
第三,數據的丟失也會嚴重影響數據重用。由于期刊或書籍版面的限制,就有可能導致原數據的部分或全部丟失[42],而殘缺的數據很可能難以反映原有研究的結果,甚至會得出截然相反的結論[43]。因此,數據的丟失可能比其他因素更能影響數據重用的效果,因為文章一旦發布,就成為靜態實體,無法修改[44],而他人在重用這些數據時可能并不知道這些數據是殘缺的。
5.2 針對數據搜集過程中遇到問題的探究
在自然科學領域,有學者提出了小數據概念[45],即在大數據的環境下用于研究特定領域的小型數據集。小型數據集可能很難找到,因為它們很少存放在存儲庫中,更多是儲存在調查員的本地硬盤驅動器或實驗室服務器上。在這些小的研究中,積極保存數據及其附帶文件很少是一個正式的過程。因此,自然科學研究人員數據重用在獲取數據難度上還是比較大的。這就導致自然科學領域關于數據搜集的研究相對較少,相比之下,在該領域以數據共享、數據引用作為研究重點的文獻就涉及較多。
相比較于自然科學領域,社會科學領域的數據在獲取難度上相對較低,因而研究方面也較為廣泛,遇到的問題也較多。有研究就發現該領域的研究人員獲取的數據往往就比較帶有一定的主觀性,因為他們獲得數據的來源往往是個人、小規模的形式[46]。這就導致重用這些數據而得出來的結果與客觀事實會有一定的偏差,對該結果的質疑之聲也相對較高。此外,許多社會科學數據是有價值且敏感的,以至于幾乎不允許外部研究人員訪問[47]。甚至即使該數據最初是由研究人員創造的,隱私問題有時會要求這些人員在研究完成后銷毀這些數據。這一做法顯然使科學數據重用變得更加困難,甚至會增加欺詐性出版物[48][49]。
5.3 針對科研人員自身問題的探究
整體來說,學者們對科研人員自身影響數據重用的研究切入點可分為科研人員的重用意愿與科研人員自身所具備的技能兩大方面。
一方面,有研究表明不同的人群對于數據重用的態度不一樣,一些科研人員會從自身利益角度出發會拒絕數據重用[50]。亦或者,他們會制定一些個人的標準限制他人的重用行為[51]。這是因為研究人員會認為在存儲庫中共享數據與他們的工作無關,特別是在存儲庫中共享數據可能是一個耗時的過程,并且認為這對正在進行共享的研究人員來說回報很少[52]。因此雖然大多數人都表示把數據共享到數據庫進行重用是有意義的[53][54],但少有人去這樣做。這類研究往往是基于問卷調研或者走訪的形式,相對而言樣本可能具有獨特性,所以研究結果可以作為參考,在解決具體問題時可以繼續作有針對性的研究。
另一方面,數據重用被學者們證實又需要科研人員具備專門的知識和其他人員的信任[55]。有研究發現即使是那些直接獲得所有研究文件或者本身就是原始研究人員的調查人員,仍然難以理解他們得到的數據[56],而科研人員對數據的理解則會很大程度上影響其對數據的使用行為。此外,部分研究人員也表示他們缺乏在公共存儲庫中共享數據的時間、渠道和技術,也沒有相應的激勵機制[57]。從某種程度上講,基礎設施的短缺也將導致科研人員放棄研究數據的共享與重用。此類研究常常是基于某種特定的場所,如政府部門、研究所或某個學科領域等較為封閉或獨特的領域,并且以發現問題為主要研究,在提出解決方案時論證相對不足,仍需要進一步探索。
6 對科學數據重用所遇到問題的解決方式——重用規范的研究與實踐進展
6.1 針對制定重用規范的主體的研究
針對數據重用存在的一些問題,無論國內外都有眾多學者們表示應該建立數據重用標準規范[58][59],并且他們還表示數據共享、重用的利益相關者有責任去制定關于數據共享和重用的規范[60],這樣做的目的是鼓勵那些利益相關者進行數據共享,并可以更好地衡量研究人員數據重用的效果[61]。同時,也有人表示不同的利益相關者也可以根據自身利益制定不同的行為規范[62][63]。對此,Federer L[64]就總結出了數據共享、重用的利益相關者,不僅包括重用和度量數據標準的創造者、出版商、數據庫、資助者和機構,還包括了引用管理軟件的創建者、研究人員、受訓人員、圖書管理員等等。雖然當下已經有許多研究指出了制定重用規范的主體及其義務,但具體每個主體應該如何實踐操作等問題方面研究較為空缺,也沒有較好的范例可以借鑒,因此還需要投入更多的精力思考。
6.2 針對重用規范制定的研究與進展
6.2.1 學術界研究
國外有學者根據數據共享的標準[65],創造了一種新的度量標準Meloda[66]。它允許對信息進行評級并評估其重用程度,其中還包括了一些具體重用數據時的操作規范。同時,Missier P[67]也提供了一個基于W3C PROV數據模型的DTS的理論模型,其最終目的是基于數據重用直接度量的信用模型為數據發布者提供共享數據的激勵。
在我國,也有學者則將共享數據協議按嚴格程度分為了五個等級[68],不同的數據利益相關者可根據不同的需求,選擇合適的標準規范數據重用行為。除此之外,還有學者認為在未來設計數據文件時,重要的是將它們與出版物聯系起來[69]。
雖然到目前為止,尚未有很多研究定義學術界各個領域中數據重用的規范具體是什么,但是有些領域已經具備更積極的數據重用文化,如生物醫藥領域。無論是否有強大的數據重用規范,進一步探索各學科中的數據重用行為都將有助于更好地理解主觀規范在數據重用中的影響,有助于更好地理解和幫助科研社區創建數據重用文化。
6.2.2 組織機構實踐進展
(1)Scientific Data、OECD與FAIR數據原則
起初,期刊Scientific Data在2000年就制定了《網絡時代的科學原則》[70],其中就指明了數據的發布是科學研究和知識傳播的基礎。經濟合作與發展組織(OECD)也于2006年頒布了《公共資金資助的研究數據獲取原則與指南》[71],明確了共享數據的十三種特性。這兩個原則都特別關注知識產權問題,都意識到科學數據共享與重用過程中必然產生利益均衡問題,需要通過法律手段予以解決[72]。在此基礎上,歐盟FORCE11工作組又結合了2013年G8科技部長關于開放科學數據的聲明[73],發表了FAIR數據原則(FAIR Data Principles)[74],其著重強調了開放數據的可發現、可獲取、互操作和可重用特點[75],并且具體規定了數據重用的一些操作[76]。
當下,Scientific Data[77]已將數據重用作為構建數據庫的六大基本原則之一,并且明確規定了數據標準化和詳細的說明使研究數據更易于查找和重用。這其中就包括一些數據描述符用于提供解釋、重用和再現數據所需的信息,確保鏈接到存儲數據文件、代碼或工作流的一個或多個受信任的數據存儲庫,從而較大程度上滿足資助者數據管理要求,特別是通過演示過程來促進研究數據的重用潛力。
由此可見,Scientific Data在數據重用規范方面還是涉及較早,并且有一定發展年限,在某些具體的細則上作出了詳細的規定,因而在該行業內可作為典型案例參考學習。
(2)NIH
美國國立衛生研究院(NIH)[78]宣布了最終的基因組數據共享(GDS)政策,對于屬于GDS政策范圍內的研究,通過其機構審查委員會(IRB),隱私委員會或同等機構提交機構,應審查知情同意材料,以確定是否屬于適用于共享數據以供二次研究使用。并且,NIH不鼓勵使用專利來防止他人使用數據。
該研究院雖然并未明文規定所共享的數據該如何重用,但從其字里行間可以明確感受到其對數據重用的重視性。從目前的來看,其工作的重點尚且停留在數據重用的前提——數據共享方面,在未來不排除NIH會對數據重用作更詳細的明文規定。
(3)英國社會科學研究社區
《2013-2018年英國社會和經濟研究數據資源戰略》(NDS)[79]為英國社會科學研究社區提出了戰略方法,并致力于數據資源的重大發展。該戰略探討了如何使研究人員能夠充分利用新的和現有的數據資源,制定公共參與戰略,并與公眾就可能識別個人或組織的數據重用或組織之間的聯系進行溝通。相比較于上述二者,該研究社區對數據重用的規定就顯得較為滯后,暫且停留在戰略層面,并且最近幾年未能發現有相關的明文規定。
(4)加拿大聯邦政府
在加拿大,聯邦政府一直在通過開放政府和開放科學倡議來增加其對研究數據管理和共享的興趣和支持[80]。2014年,加拿大科學、技術和創新戰略就通過促進“開放獲取聯邦資助研究產生的出版物和相關數據以加速研究、推動創新和造福經濟”來促進開放科學。2015年,各機構宣布了一項新的“三機構出版物開放獲取政策”,要求公開提供由公共基金資助的研究出版物,以獲得整個社區的利益,并且在之后很長一段時期內評估如何在這個更廣泛的政策背景下繼續推進研究數據管理,其中就包括制定Research Data Management and Sharing(RDM)準則[81]。該準則詳細規定了調查人員在提供、共享、使用數據時應盡的義務,其中個別條例涉及到了數據重用前提——數據共享的內容,如調查人員必須以某種形式共享數據,但此后有關政策頒布工作進展較少。整體而言,加拿大聯邦政府在數據重用方面的工作僅僅初具苗頭,甚至未進入戰略層面。
(5)中華人民共和國國務院辦公廳
2018年,中華人民共和國國務院辦公廳頒發了《科學數據管理辦法》[82](簡稱辦法),該辦法從政府角度出發,明確了政府機關、法人單位及其他主管部門對科學數據管理的工作職能。其中,對于數據的共享與重用,該辦法提出應對科學數據進行分級分類管理,并鼓勵有關部門對數據進行共享,鼓勵機構或個人對共享數據進行二次加工、分析、創造新的價值。此外,辦法還強調了數據安全問題,對于重用的數據要注明引用,必要時可提供一定報酬。此辦法的頒布與實施,填補了我國數據管理政策上的空白,明確了各個人員和機構的工作職責,使科學數據的共享、儲存、重用每一個步驟都有相應的規范約束,對于促進我國科學數據管理水平具有劃時代意義。
(6)其他
除以上機構組織外,筆者還調研了NSR、ESRC等眾多知名數據庫,但可惜的是在筆者調研這些數據庫時并未發現任何有關于數據重用的明文規定,甚至關于數據共享、數據引用等規定也只字未提。因此,未來各大機構數據庫關于數據重用的工作任重而道遠。
7 總結與展望
統觀前文有關科學數據重用的研究與實踐進展,深入剖析這些研究與規定可以發現以下幾點:
一是針對科學數據重用行為的定義,目前的研究與規定都或多或少地涉及,但又沒有很明確表達,現有的表達也多停留在重用的目的、意義、人員上,相比較而言針對重用技術、方法、過程、結果上的界定較為模糊。相比之下數據重用的臨近概念,如數據引用,已被多數學者在實踐效果、學術規范、影響因素[83]等方面做了較多的研究,并且形成了一定的規范準則[84],甚至針對這些引用規范又有學者做了更加深入的內容分析與特點分析[85][86],相對而言研究較為全面,因而可作為一定參考;
二是針對科學數據重用行為的研究,更多集中在科研人員科學數據重用中遇到的問題與其行為偏好上,學者們使用的研究方法眾多,研究切入點也較為廣泛,呈百花爭艷現象,然而當涉及到數據重用所遇到問題的解決方法時,雖然多數學者認為制定相應的規范有助于解決問題,但對于如何具體規范科學數據重用行為,如何落實該項規定,從目前的研究來看相對還比較匱乏;
三是在應用方面,針對科學數據重用的前提——數據共享方面,不少學者、研究員與一些出版商、組織機構都做了較為詳細的研究與有關政策的制定,其側重點往往放在激勵機制、共享規范、流程制定、共享意義、數據存儲等方面,尚可形成較為系統的體系。但另一邊,科學數據重用的制定相對而言進展較緩,部分知名數據庫、組織機構也僅僅是將其作為一項構建原則或者網頁說明一筆帶過,尚未形成科學的管理體系以及定量或定性評價標準,甚至有更多的數據庫網站以及政府機關對科學數據重用未提出只字片語。
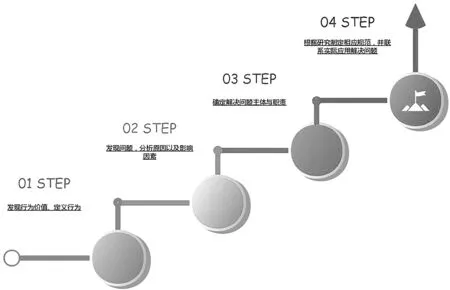
圖2 數據重用理論與實踐進展
從目前的研究來看,在理論方面對于數據重用行為定義的研究往往被忽略,而對于數據重用的價值、存在問題、影響因素、確定解決問題主體與職責等方面的研究此起彼伏、細致入微,但到了具體制定相應規范、評價標準時,多數研究者未曾作為重點研究,僅停留在思考與建議層面。原因可能在于此類研究操作難度上較大,以至于在實踐層面呈現脫節狀態。無論是國內外的數據庫機構或者政府部門,已經制定的重用規范未能很好地發現與先前理論研究的較大關聯性,更有多數機構或部門未曾制定重用規范。希望未來學者們與有關工作人員可以結合理論研究來彌補此項缺口,尤其是針對不同數據庫的個性化重用規范。
猜你喜歡
北部灣大學學報(2022年1期)2022-06-22 04:58:38
北部灣大學學報(2022年2期)2022-06-21 11:44:36
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
現代儀器與醫療(2021年4期)2021-11-05 08:25:08
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
北部灣大學學報(2021年4期)2021-04-28 08:01:04
科技傳播(2019年22期)2020-01-14 03:06:54
小小藝術家(2019年6期)2019-06-24 17:39:44
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
今古傳奇·故事版(2016年15期)2016-09-07 06:57:32
