基于深度學習的三維目標檢測方法研究綜述
2022-05-12 09:40:26張冬冬
機電工程技術 2022年4期
張冬冬,郭 杰,陳 陽
(陸軍工程大學野戰工程學院,南京 210007)
0 引言
目標檢測,作為三維數據處理與分析的基礎技術、基礎算法,是計算機視覺當前熱門研究方向之一。數據是研究的基礎,目前主流的三維數據表示方法主要有深度圖、三角網格、體素和點云。其中,點云是最簡單的一種三維數據表示方法,具有獲取簡單、易于存儲、可視性強、結構描述精細等優點,而且能夠方便地與深度圖、體素等其他數據格式相互轉換,已成為三維重建、三維目標檢測、SLAM(即時定位與地圖構建)等研究領域最基本的數據格式。點云定義為同一空間坐標系下表達目標空間分布和目標表面光譜特性的海量離散點集合,每個點包含特定的位置信息和其他屬性信息,如顏色、激光反射強度等。與傳統的二維圖像相比,點云在分辨率、精度、紋理信息等方面有了很大提升,具有多屬性、可量測、高精度、高穿透、受環境和天氣因素影響小等特點,已在許多重大工程和典型領域得到廣泛應用,如機器人與自動駕駛、軍事目標偵察、森林資源調查、電力走廊安全巡檢、文物三維數字化、臨床醫學輔助診斷和治療等[1]。
早期對點云場景的目標檢測主要是基于三維特征的識別,即利用點云的幾何空間結構提取物體的特征信息,然后與已有的特征信息進行比對進而完成檢測。特征比對主要是利用支持向量機(SVM)、隨機森林(Random Forest)及Adaboost等已經訓練好的分類器,因此只能對分類器已經學習到的物體進行識別,且特征提取、數據處理仍依托人工操作,方法較為繁瑣復雜。隨著深度學習的迅速發展和廣泛應用,研究人員提出了大量基于深度學習的三維目標檢測方法,點云的特征提取與數據處理才漸漸變得智能自主而無需人工干預,并且與傳統方法相比,此類模型性能得到顯著提升,達到了更高的基準。
目前已有一些基于深度學習的三維目標檢測綜述性研究[2-5],本文在前人工作基礎上進行了豐富和完善,總結了基于圖像視錐、基于數據降維、基于原始點云3類三維目標檢測方法,比較了每類方法的優缺點,提煉了每類方法的工作原理和主要創新點,最后對三維目標檢測未來研究方向進行了展望。
1 深度學習應用于點云面臨的挑戰
隨著深度學習在二維目標檢測的迅速發展和優異表現,越來越多的研究人員嘗試將其應用于點云的目標檢測。然而,點云本身具有稀疏性、離散性、無序性和旋轉平移不變性等,二維目標檢測的成熟技術無法直接應用于點云,對點云數據的處理仍面臨較大挑戰。
1.1 稀疏性
激光雷達在采集點云數據時,近處物體反射的點較多、遠處物體反射的點較少,因此采集到的點云會呈現“近密遠疏”的特點,如圖1所示。并且,采集過程中通常還會伴有一定環境噪聲,會造成采集到的點云存在很多干擾點。此外,還會因為障礙物遮擋、物體之間相互遮擋、高反射物體等情況導致部分物體點云不完整或空洞缺失。

圖1 Velodyne HDL-64E激光雷達采集的點云數據Fig.1 Point clouds scanned by Velodyne HDL-64E LiDAR
在應用深度學習對點云進行目標檢測時,首先需要提取點云的特征。二維目標檢測中一般利用卷積核和卷積神經網絡遍歷整個圖像提取特征,借鑒二維目標檢測的方法,采用三維卷積核和單純的三維卷積方法遍歷整個點云提取特征,會帶來兩個問題:一是消耗非常巨大,因為點云廣泛分布在三維空間內,遍歷整個點云會帶來巨大的內存和時間消耗;二是大部分卷積為無效特征提取,因為點云的稀疏性,大部分空間不存在點,會導致無效空卷積。
1.2 離散性
點云的離散性主要表現在兩個方面:(1)空間分布離散,點云中每個點都是獨立掃描相互獨立的,不依賴于其他點而單獨存在,從整體上看,點云是一個離散的、非結構化的點集合,不定義在某個區域內,相鄰點之間的距離也不固定,因此建立點與點之間的關系較難;(2)組織結構離散,簡而言之就是不同數量的點云可以表示同一物體,點云通過其整體幾何結構信息來描述物體,而不依賴點的數量,因此描述一個物體的點云其數量是不確定的。如圖2所示,描述同一架飛機的點云稀疏稠密不同,左圖能夠描述飛機的更多細節,但右圖也可判斷出物體的類別。雖然人眼能清晰地分辨出二者不同,并判斷其均屬于飛機類別,但神經網絡卻無法簡單實現這一點。

圖2 不規則離散分布在空間中的三維點云Fig.2 Irregularly and discretely distributed point cloudsin space
1.3 無序性
點云本質上是空間中一群點的集合,每個點包含了大量屬性信息。從數學的角度或數據結構的角度,點云應當由“集合”來描述,集合中一個元素代表點云中一個點。集合中每個元素的地位是相同的,元素之間是無序的。同樣地,點云中每個點的地位也都是相同的,點與點之間是無序的,存儲在集合中點的先后順序對于集合而言無關緊要,也不會因為點存儲的先后順序改變點云的性質特征。然而,神經網絡卻對輸入數據的排序非常敏感,點的存儲順序直接影響神經網絡的理解學習。如圖3所示,假設一個物體的點云數據由7個點組成,左圖將其表示為[P1,P2,P3,P4,P5,P6,P7],右圖將其表示為[P4,P6,P5,P7,P3,P1,P2],顯然不論張量中點的順序如何變化,映射回三維空間中仍然表示的是同一個物體。然而,以左圖張量為輸入訓練出來的神經網絡模型很可能無法對右圖張量做出正確預測。
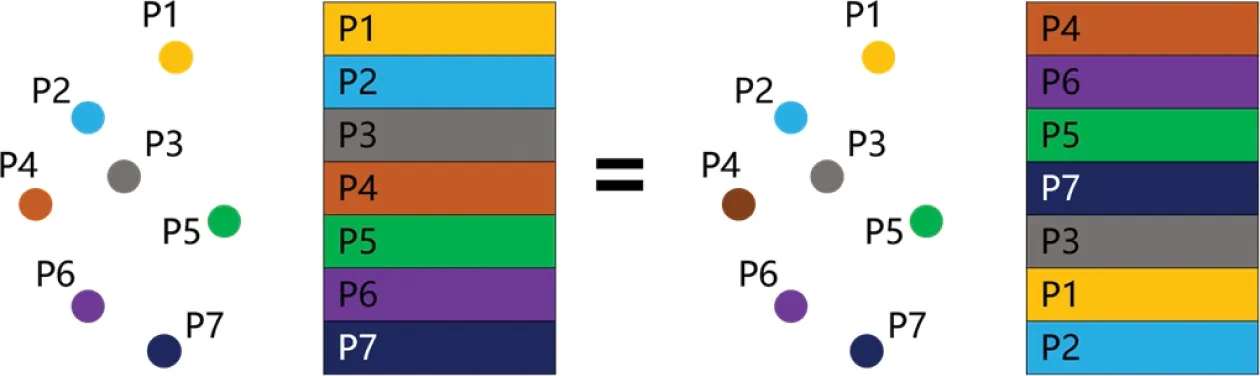
圖3 同一點云的不同張量表達Fig.3 Different tensor expressions of the same point clouds
1.4 旋轉平移不變性
對于點云而言,無論如何旋轉或平移,點與點的相對位置始終保持不變,點云所表示物體的形狀和大小也不會發生任何變化,如圖4所示,它是一種剛體變換。然而,當對點云進行旋轉或平移時,點云中的點的坐標會發生相應變化。因此,旋轉或平移雖然并未改變物體的空間結構,但卻改變了表達其空間結構的三維坐標。神經網絡需要適應點云的這種旋轉平移不變性質,無論如何旋轉或平移,無論參考坐標系怎樣變化,均應輸出一致結果。

圖4 點云的旋轉平移不變性Fig.4 Rotation and translation invariance of point clouds
2 基于深度學習的三維目標檢測
2.1 基于圖像視錐的方法
基于圖像視錐的方法,結合了二維圖像的高分辨率優勢和三維點云的精確位置信息優勢來進行目標檢測,其主要思想是利用現有成熟的二維目標檢測算法,首先從二維圖像中獲得目標的2D邊界框,然后利用二維圖像與三維點云的對應關系,將該2D邊界框映射到三維點云中得到一個3D錐體候選區域,再從該區域提取目標的3D包圍盒。此類方法的典型代表為Frustum PointNets[6],后續的基于圖像視錐的研究工作大多是在此基礎上進行改進的,其工作原理如圖5所示,給定一個RGB-D數據,首先使用卷積神經網絡在RGB圖像中生成目標的2D邊界框,然后從點云中獲得其對應的3D視錐,最后利用PointNet++[7]來學習各個3D視錐的點云特征,從而提取目標的3D包圍盒。
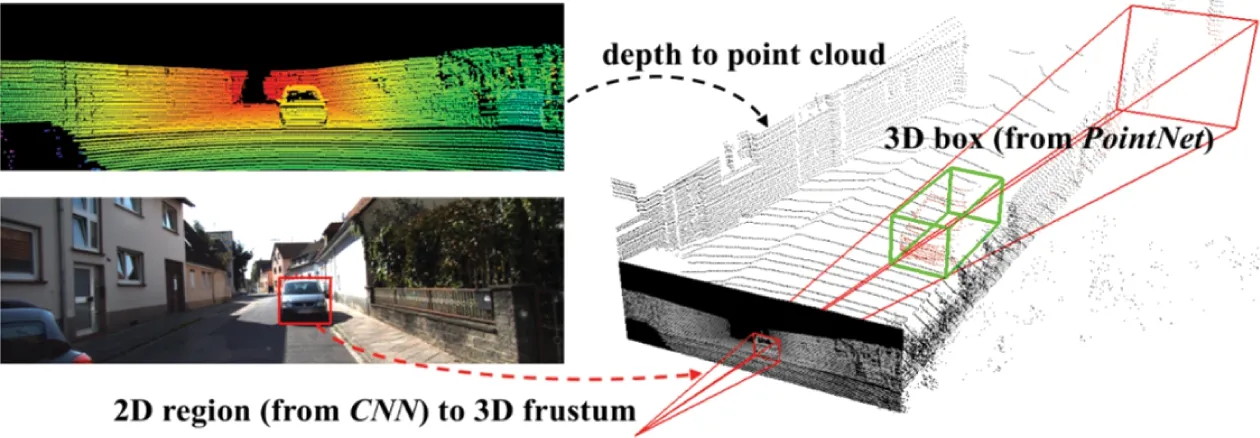
圖5 Frustum PointNets三維目標檢測原理Fig.5 Frustum PointNets 3Dobject detection principle
由于Frustum PointNets僅利用了圖像中的位置信息,并沒有使用其顏色信息,PointFusion[8]對其進行了改進,首先通過ResNet提取2D邊界框內圖像的特征(包括位置信息和顏色信息),然后與3D視錐點云特征進行融合。
SIFRNet[9]隨后對Frustum PointNets再次進行了改進,如圖6所示,提出了一種尺度不變和特征重加權網絡(Scale Invariant and Feature Reweighting Network),包含Point-UNet、T-Net、Point-SENet三個模塊,Point-UNet模塊主要是對3D視錐點云進行分割,捕獲點云的不同朝向信息以及強魯棒性的形狀尺度;T-Net模塊主要是對物體3D包圍盒中心進行估計;Point-SENet模塊預測輸出最終的3D包圍盒。
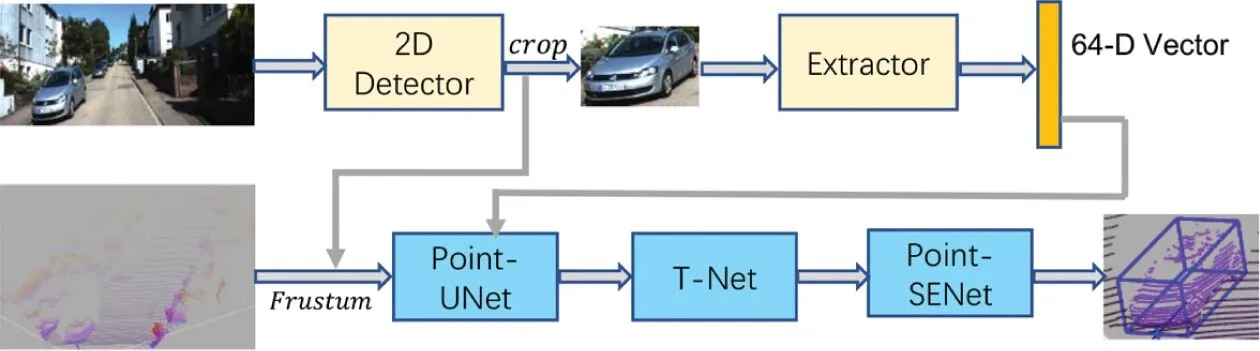
圖6 SIFRNet目標檢測流程意圖Fig.6 Thepipelineof SIFRNet for 3Dobject detection
Shin等[10]提出了RoarNet,解決了2D邊界框投影到3D空間中LiDAR和相機兩個傳感器同步的問題。F-Con?vNet[11]在Frustum PointNets網絡的基礎上,改進了視錐區域點云的特征提取方式,如圖7所示,具體就是在錐體軸上產生一系列的錐體,然后提取各個錐體內點云的特征,將點云的逐點特征轉為視錐體級特征,進而利用全卷積網絡(FCN)回歸3D包圍盒,這樣不僅可以避免大范圍遍歷點云,提升檢測效率,還可以在回歸時減少對稀疏前景點的過度依賴,提高檢測性能。
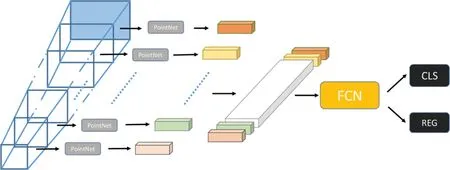
圖7 F-ConvNet視錐特征提取Fig.7 F-Convnet frustumfeatureextraction
2.2 基于數據降維的方法
基于數據降維的方法,核心思想就是將不規則、稀疏無序、數據量巨大的點云數據降維轉化后再進行處理,以節約內存和降低時間消耗。數據降維的處理方法有多種,較為典型的主要有以下3類。
(1)基于偽圖片的方法,即將三維點云轉化為二維偽圖片數據,然后再運用已經相對成熟的二維目標檢測技術進行檢測。該方法的典型代表是PointPillars[12]和CenterPoint[13]。PointPillars能夠在保證一定精度的同時實現較快的檢測速度,其網絡結構如圖8所示,包含3個部分:Pillar Feature Net將三維點云轉化為二維偽圖片(Pseudo image),首先根據點云的X軸、Y軸坐標將點云劃分到一個個Pillar(柱體)中,然后提取Stacked Pillars(堆疊柱體)的特征,并對Pillar所在維度進行Max Pool?ing(最大池化)操作得到Learned Features(學得特征),最后將其轉化為二維偽圖片;Backbone利用二維卷積對偽圖片進行特征提取,Detection Head主要利用SSD回歸物體的3D包圍盒。CenterPoint主要從原始點云中學習生成表征目標中心位置的鳥瞰熱力圖(表示為M∈?W×H×F),然后利用二維卷積找到物體的大致中心點(熱力圖的峰值位置),并使用中心特征回歸物體的位置和方向。
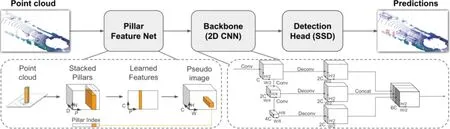
圖8 PointPillars網絡結構Fig.8 Network framework of PointPillars
(2)基于多視圖的方法,主要從前視、俯視等不同視角將三維點云數據進行二維化處理,得到激光雷達前視圖、鳥瞰圖(BEV)等特征圖,然后對這些特征進行融合,再應用2D目標檢測器進行檢測,典型的方法有BirdNet[14]、MV3D[15]和AVOD[16]等。BirdNet將點云投影轉化為高度、強度和密度的三通道BEV特征圖(其中密度進行歸一化預處理),然后在BEV特征圖上應用2D目標檢測器,結合高度信息(將物體的最大高度減去地面估計高度)最后得到3D包圍盒。BirdNet的重要貢獻是提出密度歸一化操作,使得高分辨率點云中訓練的模型可以在較低分辨率的點云上使用。MV3D首先從多通道特征圖(由高度、密度和反射強度組成)中計算候選區域,然后將候選區域映射回鳥瞰圖(BV)、前視圖(FV)和圖片(RGB)3個視圖中,如圖9所示,利用3個視圖的ROI區域進行ROI pooling獲得3個視圖特征并融合,最后進行目標分類和3D包圍盒回歸。AVOD對MV3D進行了改進,舍棄了MV3D中前視圖(FV)特征輸入,僅使用鳥瞰圖(BV)和圖片(RGB),使用裁剪、調整特征圖尺寸大小和按位均值融合代替了MV3D的ROIpool?ing進行多模態特征融合,并且進行了兩輪RPN區域建議,提高了小物體(如行人)的檢測效果。
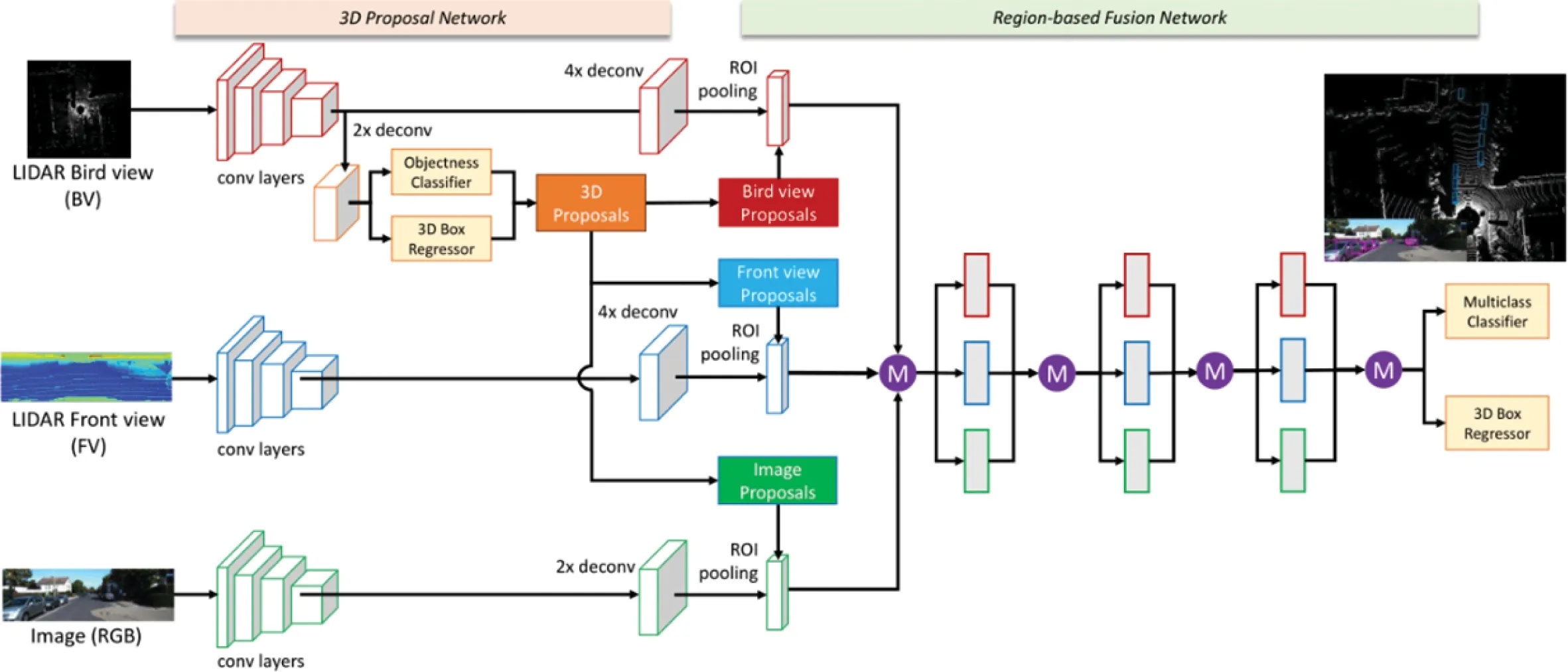
圖9 MV3D網絡結構Fig.9 Network framework of MV3D
(3)基于體素網格的方法,首先將三維點云降維轉化為一個個堆疊的、相同大小的規則體素網格,然后應用3D卷積對體素網格進行特征學習提取,最后回歸預測物體的類別和位置,典型的方法有VoxelNet[17]、SEC?OND[18]等。VoxelNet網絡結構如圖10所示,首先將點云劃分為等間距體素,利用VFE層(voxel feature encoding layer)提取體素特征,然后將得到的體素特征降維成2D鳥瞰圖,最后使用RPN網絡輸出檢測結果。SECOND對其進行了改進,使用稀疏3D卷積替換了普通3D卷積,大大提高了推理效率。目前,稀疏3D卷積已成為體素點云特征提取的主要范式。
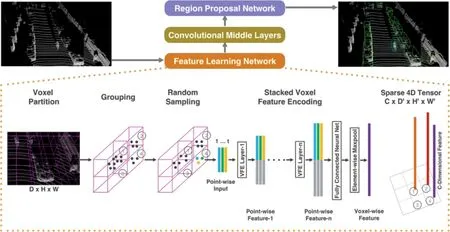
圖10 VoxelNet網絡結構Fig.10 Network framework of VoxelNet
2.3 基于原始點云的方法
基于原始點云的方法,直接作用于原始三維點云提取點云的特征,然后回歸物體的3D包圍盒,無需借助2D圖像邊界框獲得3D點云視錐,也無需進行多視圖投影或體素化等數據降維操作。典型的方法有Poin?tRCNN[19]、VoteNet[20]和3DSSD[21]等。
PointRCNN是一種兩階段網絡,其網絡結構如圖11所示,第一階段進行前景點和背景點分割,生成少量高質量初始檢測盒,首先利用PointNet++對原始點云進行特征提取,然后進行Foreground Point Segmentation(前景點分割),同時額外增加一個Bin-based 3D Box Genera?tion(基于Bin損失的3D包圍盒生成網絡)來輸出3D proposals(候選建議),Bin損失方法核心思想是將復雜困難的3D包圍盒回歸任務轉化為簡單容易的分類加回歸任務;第二階段對初始3D包圍盒進行細化精修,首先利用Point Cloud Region Pooling(點云區域池化)對上述獲得的3Dproposals進行局部特征提取,并將該局部特征進行Canonical Transformation(規范變換),即對每個pro?posal建立一個獨立坐標系,坐標系的中心點為proposal的中心,X軸指向物體朝向,然后將其送入MLP獲得新特征,并與全局語義特征堆疊融合,最后利用融合特征進行3D包圍盒優化和置信度預測。
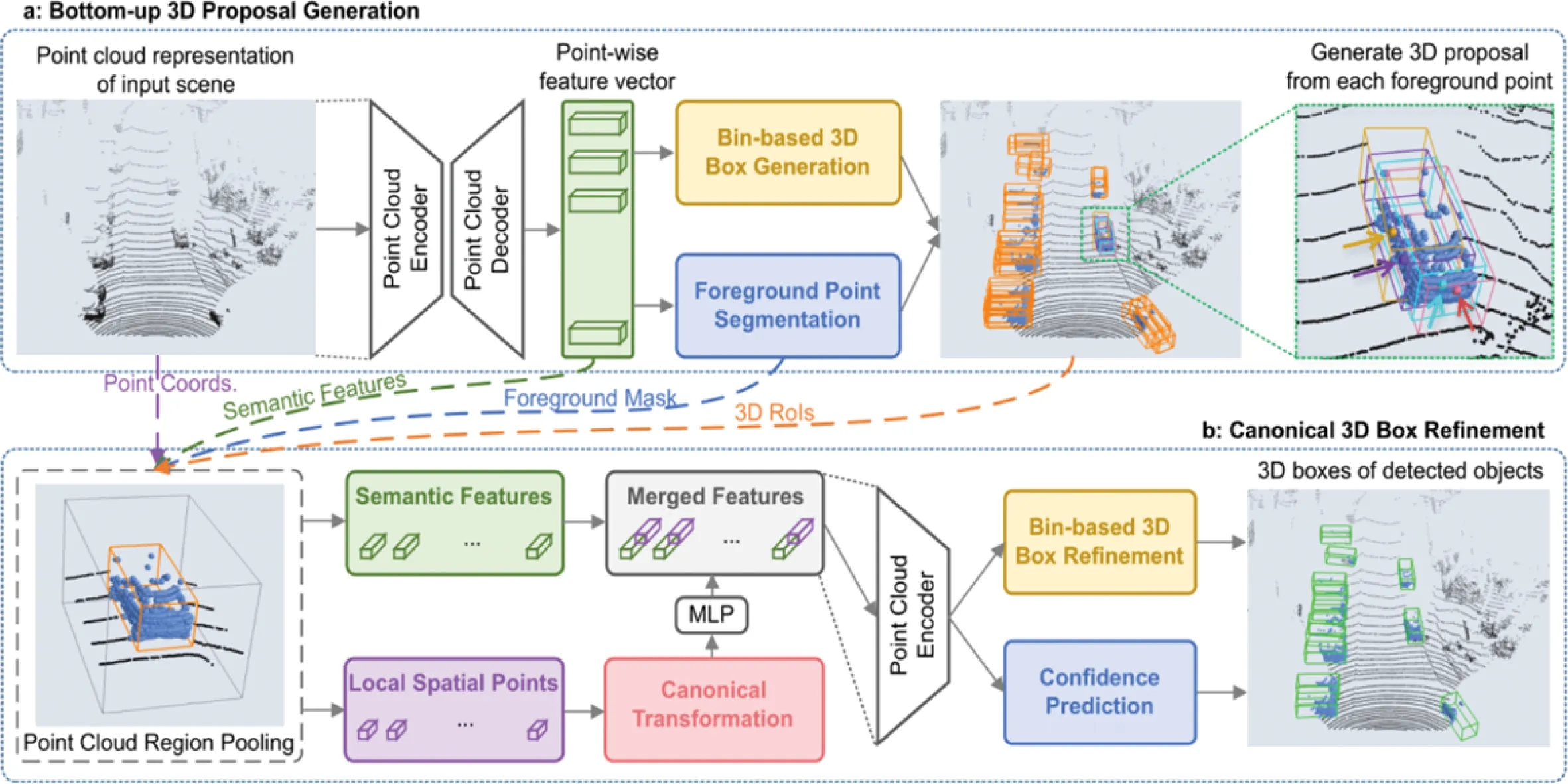
圖11 PointRCNN網絡結構Fig.11 Network framework of PointRCNN
VoteNet是一個基于深度點集網絡和霍夫投票的端到端3D目標檢測網絡,如圖12所示,整個網絡分為兩部分:第一部分處理現有的點云以生成Votes(投票),首先利用Point cloud feature learning backbone(點云特征學習骨干網絡)提取原始點云(N×3)的特征,生成Seeds(種子點),然后利用Hough voting with deep networks(霍夫投票深度網絡)為每個Seed學習一個3D空間的偏置和特征空間上的偏置以生成Votes(一些靠近3D物體質心的虛擬點);第二部分利用Votes來預測物體類別和3D包圍盒,首先使用FPS(最遠點采樣)以及ball query(球查詢)的方式采樣聚合Votes得到K個Vote clusters(投票群集),然后經過兩層MLP輸出預測結果。
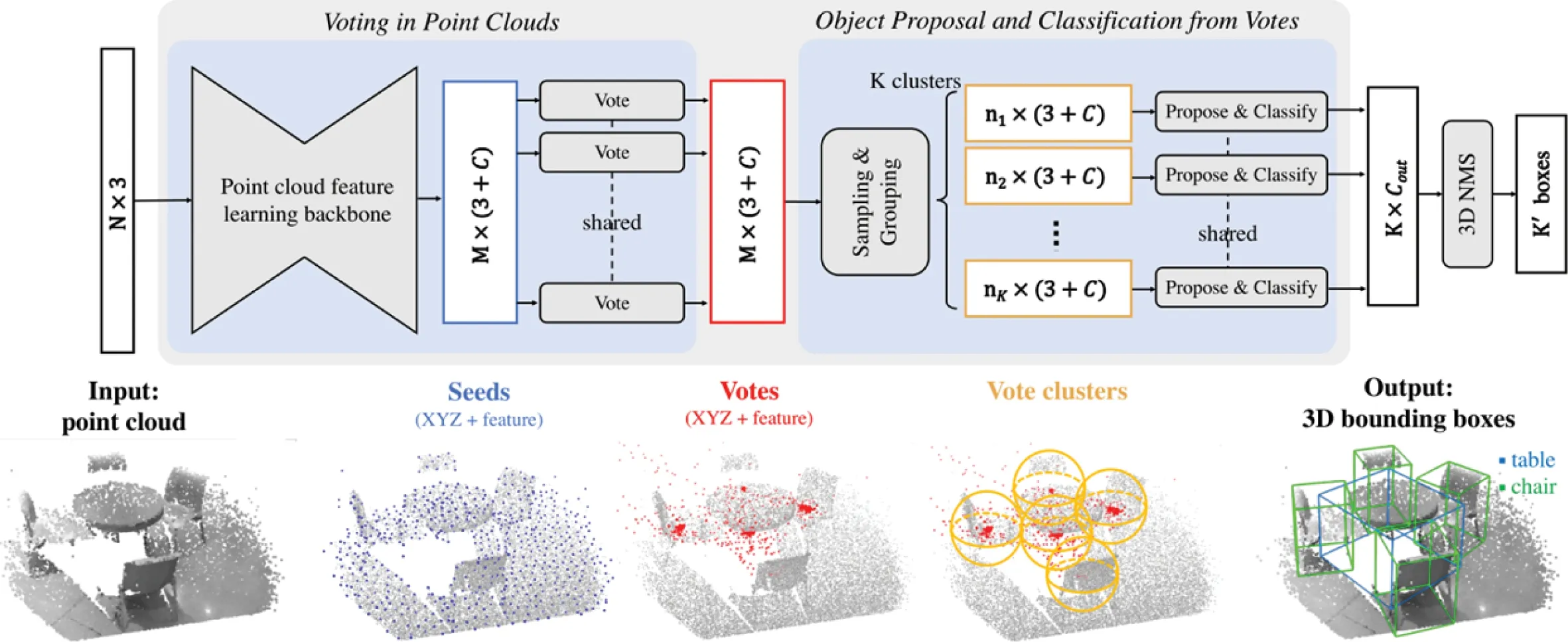
圖12 VoteNet網絡結構Fig.12 Network framework of VoteNet
3DSSD主要有3點貢獻:一是開創性地將單階段目標檢測網絡結構引入到三維目標檢測中,在保證性能與兩階段檢測器相當的情況下大幅度提高了檢測效率;二是提出了一種融合空間距離與語義特征距離為度量新的采樣方法F-FPS,并與距離最遠點采樣方法D-FPS、融合采樣策略(F-FPS和D-FPS結合)進行了對比實驗;三是提出了Candidate Generation Layer(候選點生成層),將采樣初始點坐標向其對應實例的中心點進行偏移修正,提高了3D包圍盒質量。
2.4 三類方法比較
表1匯總了本文提及的三維目標檢測各方法模型的提出年份、輸入數據類型、關鍵技術、在KITTI測試集汽車類別上的3D檢測性能和檢測時間。
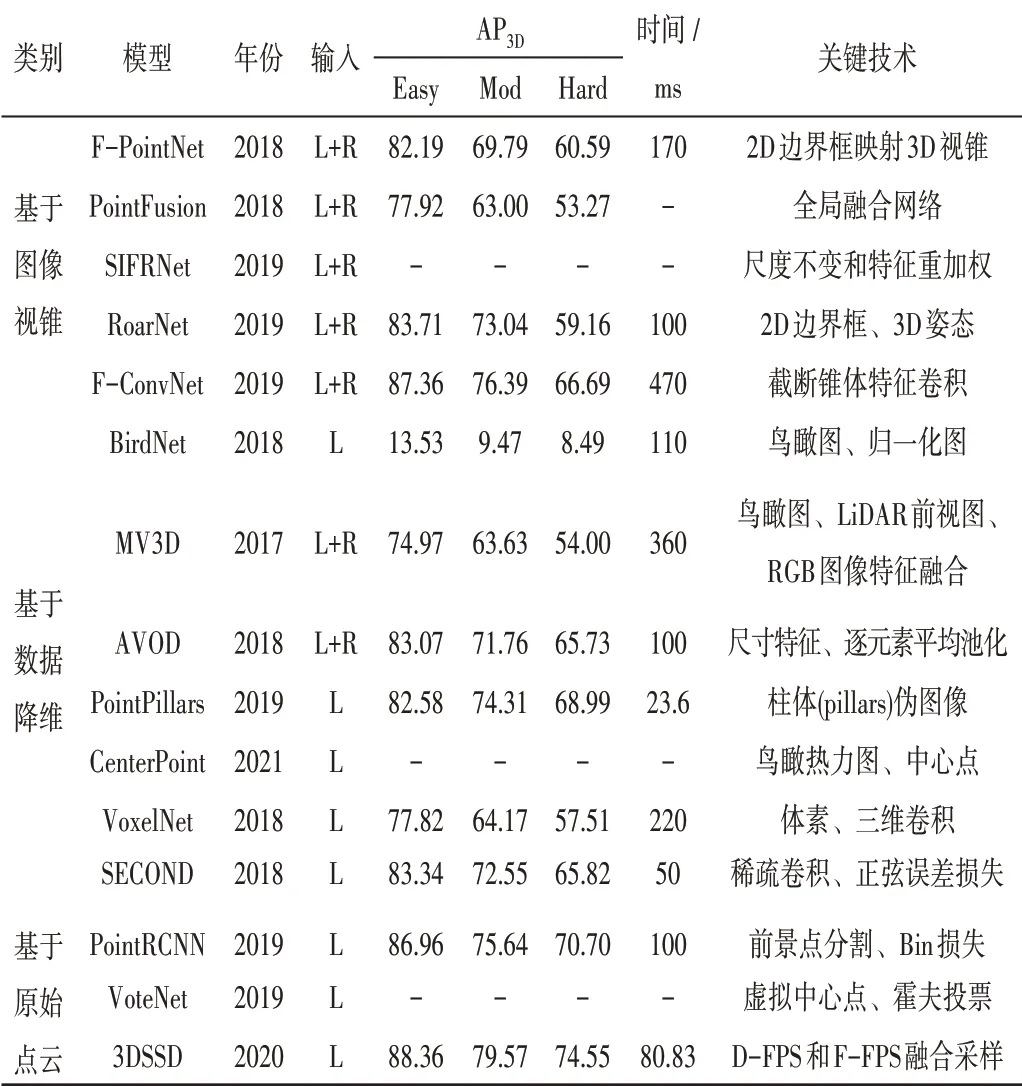
表1 基于深度學習的三維目標檢測方法歸納與總結Tab.1 Induction and summary of 3D object detection methods based on deep learning
基于圖像視錐的方法,將目標鎖定到2D邊界框對應的3D視錐范圍中,相對于從整個三維點云中搜索目標而言,僅需從3D視錐區域內搜索目標,大大縮小了搜索空間,提高了搜索效率和檢測精度。但是,順序的操作流程也導致其性能受到二維圖像檢測器的限制。基于數據降維的方法,將三維點云降維轉化成偽圖片、多視圖、體素后再進行目標檢測,能夠較好地利用成熟的2D目標檢測技術,并且可以擁有較高的檢測速度。但是,數據降維會導致點云數據信息隱性丟失。基于原始點云的方法,直接對原始的三維點云進行處理,保留了點云的原始數據特征,但同樣不可避免存在一些問題:一是難以有效進行特征提取,二是難以處理大規模點云。
3 結束語
現有的三維目標檢測方法達到了較高的精度和速度,但仍存在一定局限性。基于前述內容,對三維目標檢測展望如下。
(1)隨著傳感器技術的發展和傳感器成本的降低,未來的三維目標檢測數據來源不僅僅是相機采集的圖片和LiDAR采集的點云,還可能包括視頻、radar等多模態數據,多模態數據融合的目標檢測方法可能會是未來發展趨勢。
(2)現有的三維目標檢測模型對距離較近、尺寸較大、點云稠密的目標檢測效果較好,但對距離較遠、尺寸較小、點云稀疏以及存在遮擋重疊情況的目標檢測效果較差。實際應用中的目標檢測情況十分復雜,所以針對這一問題的解決方案非常值得挖掘和探索。
(3)三維數據標注成本較高,所以現有的目標檢測模型大多是在標注充分的公開數據集訓練和實驗的。對于特定需求場景下的點云目標檢測,由于缺乏標注數據集大多無法展開。弱監督或無監督的目標檢測技術能夠有效解決此問題,可能會是未來的一個重要研究方向。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
