基于模糊專家系統(tǒng)與IDE算法的UCAV逃逸機(jī)動(dòng)決策
2022-05-23 09:15:24譚目來(lái)丁達(dá)理呂丞輝
系統(tǒng)工程與電子技術(shù) 2022年6期
關(guān)鍵詞:動(dòng)作
譚目來(lái), 丁達(dá)理, 謝 磊, 丁 維, 呂丞輝
(空軍工程大學(xué)航空工程學(xué)院, 陜西 西安 710038)
0 引 言
隨著現(xiàn)代戰(zhàn)爭(zhēng)中無(wú)人機(jī)的廣泛運(yùn)用,未來(lái)戰(zhàn)場(chǎng)使用無(wú)人機(jī)進(jìn)行制空權(quán)作戰(zhàn)成為可能。為提高無(wú)人作戰(zhàn)飛機(jī)(unmanned combat air vehicle, UCAV)空戰(zhàn)效能,對(duì)UCAV的自主空戰(zhàn)機(jī)動(dòng)決策顯得尤為重要。當(dāng)前,自主空戰(zhàn)決策方法主要可分為3類:基于機(jī)動(dòng)動(dòng)作庫(kù)的博弈論方法;基于優(yōu)化理論的機(jī)動(dòng)決策方法;基于人工智能的機(jī)動(dòng)決策方法。
基于機(jī)動(dòng)動(dòng)作庫(kù)的博弈論方法通過(guò)建立機(jī)動(dòng)評(píng)價(jià)函數(shù),得到機(jī)動(dòng)動(dòng)作得分博弈矩陣,從而選出最優(yōu)機(jī)動(dòng)動(dòng)作,但其機(jī)動(dòng)動(dòng)作固化,很難做到對(duì)當(dāng)前空戰(zhàn)狀態(tài)自適應(yīng)。
基于優(yōu)化理論的機(jī)動(dòng)決策方法包括動(dòng)態(tài)規(guī)劃算法、智能優(yōu)化算法、統(tǒng)計(jì)理論等。但基于優(yōu)化理論的機(jī)動(dòng)決策方法得到的機(jī)動(dòng)軌跡戰(zhàn)術(shù)性較差,軌跡不易被認(rèn)同。
基于人工智能的機(jī)動(dòng)決策方法主要包括神經(jīng)網(wǎng)絡(luò)法和強(qiáng)化學(xué)習(xí)法。神經(jīng)網(wǎng)絡(luò)法決策實(shí)時(shí)性好,但需要大量樣本訓(xùn)練,樣本數(shù)據(jù)的產(chǎn)生不夠真實(shí)。強(qiáng)化學(xué)習(xí)法需要樣本少,但訓(xùn)練時(shí)間長(zhǎng)。
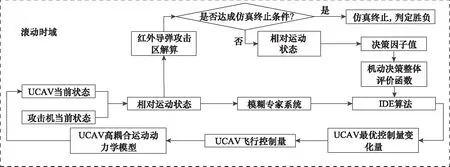
為同時(shí)具備機(jī)動(dòng)軌跡戰(zhàn)術(shù)性和對(duì)空戰(zhàn)狀態(tài)自適應(yīng),本文提出一種基于模糊專家系統(tǒng)與改進(jìn)差分進(jìn)化算法(improved differential evolution, IDE)相結(jié)合的UCAV逃逸機(jī)動(dòng)決策方法,其框架如圖1所示。最為關(guān)鍵的機(jī)動(dòng)決策過(guò)程為:首先,根據(jù)飛行員空戰(zhàn)知識(shí)提取,根據(jù)雙方態(tài)勢(shì)建立模糊專家系統(tǒng),輸出模糊機(jī)動(dòng)動(dòng)作,根據(jù)要達(dá)到的模糊動(dòng)作,對(duì)當(dāng)前控制量的變化量的取值區(qū)間進(jìn)行約束,在取值區(qū)間內(nèi)根據(jù)雙策略競(jìng)爭(zhēng)的可選外部存檔差分進(jìn)化算法(external archiving differential evolution algorithm with dual strategy competition, DSC-JADE)進(jìn)行尋優(yōu),得到下一時(shí)刻的控制量。其中,機(jī)動(dòng)決策整體評(píng)價(jià)函數(shù)為通過(guò)非參量法建立的指標(biāo)函數(shù)。此方法能縮小尋優(yōu)范圍,提高機(jī)動(dòng)決策的實(shí)時(shí)性,并且得到的飛行軌跡可用空戰(zhàn)知識(shí)解釋。
1 滾動(dòng)時(shí)域機(jī)動(dòng)決策模型
1.1 基于滾動(dòng)時(shí)域的最優(yōu)控制模型
滾動(dòng)時(shí)域控制(receding horizon control, RHC)是20世紀(jì)70年代提出來(lái)的一種控制方法,滾動(dòng)優(yōu)化把整個(gè)RHC任務(wù)過(guò)程分為一個(gè)個(gè)相互重疊(單步預(yù)測(cè)時(shí)是不重疊的)但不斷向前推進(jìn)的優(yōu)化區(qū)間,稱為滾動(dòng)時(shí)域。在某一滾動(dòng)時(shí)域的開(kāi)始,用系統(tǒng)的當(dāng)前狀態(tài)作為初始條件,在線求解該有限時(shí)域開(kāi)環(huán)最優(yōu)控制問(wèn)題,得到最優(yōu)控制序列。RHC原理如圖1所示。
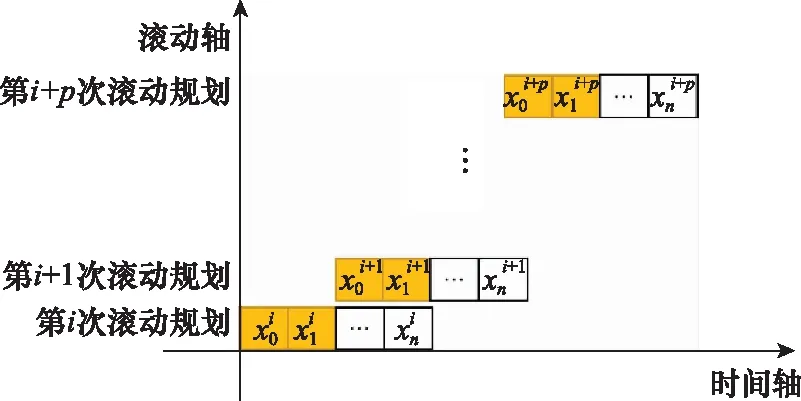
圖1 RHC原理
將機(jī)動(dòng)決策問(wèn)題采用滾動(dòng)時(shí)域控制離散化后得到其數(shù)學(xué)描述為
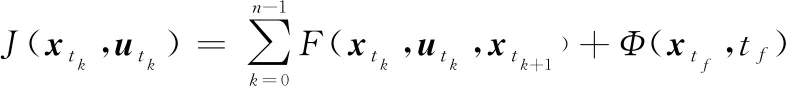
(1)
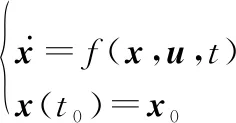
(2)
()∈
(3)
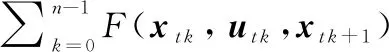
1.2 系統(tǒng)狀態(tài)方程描述
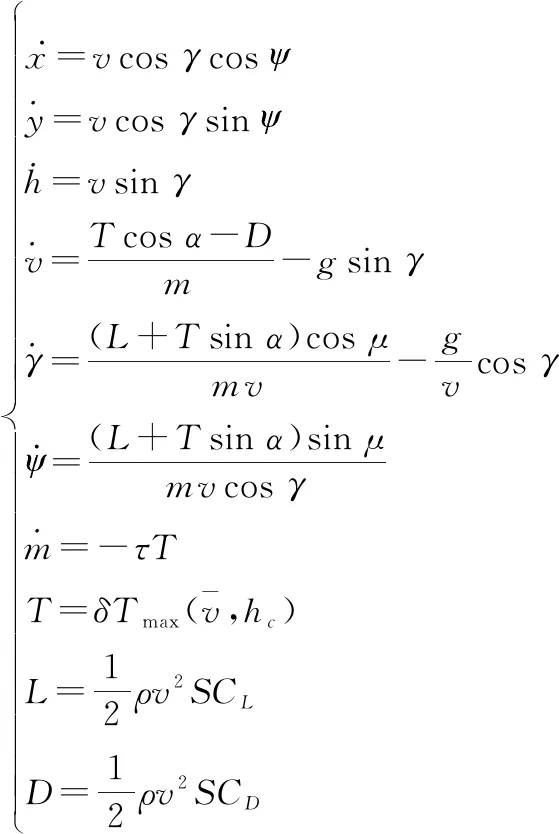
(4)
式中:為重力加速度;,,分別表示發(fā)動(dòng)機(jī)推力、空氣阻力、升力;=1225-9300為空氣密度;為UCAV參考截面積;,分別表示升力系數(shù)和阻力系數(shù);為燃料消耗系數(shù);為發(fā)動(dòng)機(jī)最大推力。
控制量:=[,,],,,分別表示迎角、航跡滾轉(zhuǎn)角和油門(mén)設(shè)置。

為區(qū)別追擊機(jī)與UCAV,分別以下標(biāo)和表示雙方。
本文采用F-4“鬼怪式”戰(zhàn)斗機(jī)的相關(guān)參數(shù)及氣動(dòng)數(shù)據(jù),以保證決策的真實(shí)性和高可靠性。
在文獻(xiàn)[14]中,采用了以、、即切向過(guò)載、法向過(guò)載和滾轉(zhuǎn)角為控制量的三自由度模型,其相較于=[,,]為控制量的模型而言,首先后者更貼近飛行員對(duì)飛機(jī)的控制,是相對(duì)于過(guò)載模型更底層的控制輸入,其次過(guò)載模型難以對(duì)過(guò)載變化進(jìn)行合理的約束,即過(guò)載變化約束不僅和=[,,]等有關(guān),且與推力、升力、阻力等因素有關(guān),不是固定不變的值,因此難以設(shè)置過(guò)載變化率約束,相比較而言,=[,,]模型的變化率Δ=[Δ,Δ,Δ]的約束可設(shè)置為定值。
1.3 指標(biāo)函數(shù)建立
在本文中,由于討論的是逃逸機(jī)動(dòng)決策,因此只討論在不利被尾追態(tài)勢(shì)初始條件下,且UCAV以逃逸為主要目的情況下決策因子指標(biāo)函數(shù)的建立。
如果使用以往建立的態(tài)勢(shì)決策因子,會(huì)導(dǎo)引UCAV完成對(duì)攻擊機(jī)的攻擊占位,主動(dòng)接近敵機(jī),達(dá)不到逃逸的目的。因此,需要建立全新的態(tài)勢(shì)決策因子計(jì)算公式,使UCAV盡量保持在導(dǎo)彈攻擊區(qū)外,且盡量遠(yuǎn)離攻擊機(jī)。
131 角度態(tài)勢(shì)決策因子
根據(jù)文獻(xiàn)[15]可知,在以空空導(dǎo)彈為機(jī)載武器的情況下,若UCAV處于雷達(dá)掃描探測(cè)區(qū)中心區(qū)域時(shí),常使用直線規(guī)避機(jī)動(dòng)。若UCAV處于攻擊機(jī)雷達(dá)掃描探測(cè)區(qū)側(cè)翼時(shí),常采用正切規(guī)避機(jī)動(dòng)。
據(jù)此對(duì)追擊機(jī)的雷達(dá)天線調(diào)整角進(jìn)行劃分,圖2為UCAV與追擊機(jī)相對(duì)態(tài)勢(shì)圖,當(dāng)≤30°時(shí),UCAV采用直線規(guī)避機(jī)動(dòng)最優(yōu),當(dāng)>30°時(shí),UCAV采用正切規(guī)避機(jī)動(dòng)最優(yōu)。由于正切規(guī)避機(jī)動(dòng)未考慮攻擊機(jī)速度方向,因此對(duì)其做出改進(jìn),使UCAV速度方向垂直于攻擊機(jī)速度方向時(shí)為UCAV最優(yōu)機(jī)動(dòng)方向。
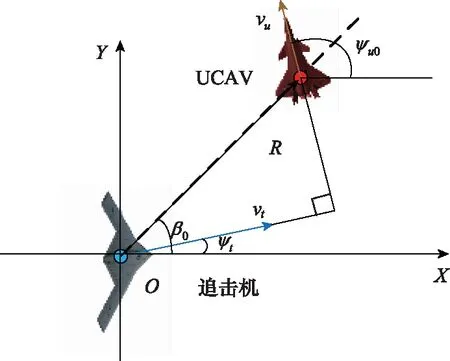
圖2 qt>30°時(shí)UCAV水平面最優(yōu)航跡偏角示意圖
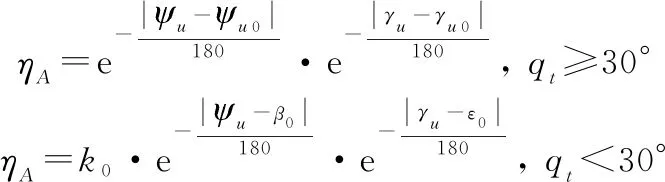
(5)
式中:為目標(biāo)線矢量的航跡偏角;為目標(biāo)線矢量的航跡傾角;為壓縮系數(shù),即UCAV處于雷達(dá)掃描探測(cè)區(qū)中心區(qū)域的角度態(tài)勢(shì)值應(yīng)小于在側(cè)翼的態(tài)勢(shì)值。
132 距離態(tài)勢(shì)決策因子
取UCAV在導(dǎo)彈攻擊范圍內(nèi)時(shí),距離態(tài)勢(shì)決策因子值為0,距離大于導(dǎo)彈最大發(fā)射距離時(shí)越遠(yuǎn)值越大,距離小于導(dǎo)彈最小發(fā)射距離時(shí)越靠近追擊機(jī)值越大。

(6)
其中,導(dǎo)彈攻擊距離解算由文獻(xiàn)[16]確定,即
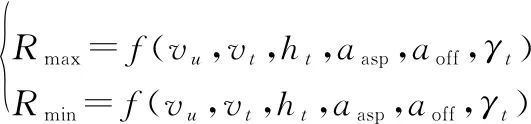
(7)
式中:和為UCAV相對(duì)追擊機(jī)的離軸方位角和進(jìn)入角。
133 高度態(tài)勢(shì)決策因子
根據(jù)以紅外空空導(dǎo)彈為武器的空戰(zhàn)形式,UCAV應(yīng)盡量避免處于追擊機(jī)最佳攻擊高度差附近,同時(shí),UCAV應(yīng)保持一定的飛行高度,據(jù)此建立高度態(tài)勢(shì)決策因子計(jì)算函數(shù):
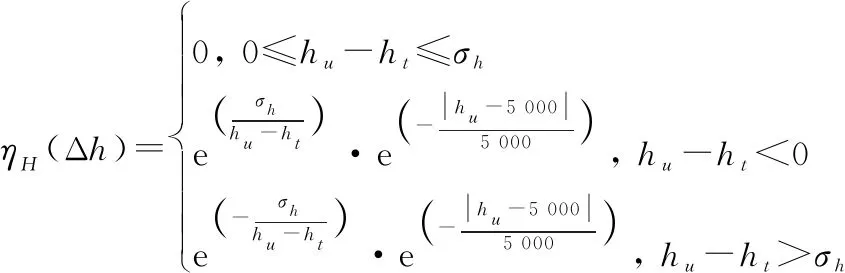
(8)
式中:為追擊機(jī)攻擊目標(biāo)最優(yōu)高度差。
134 速度態(tài)勢(shì)決策因子
在UCAV處于逃逸態(tài)勢(shì)下,其速度要盡可能大于追擊機(jī),據(jù)此建立速度態(tài)勢(shì)決策因子計(jì)算函數(shù):
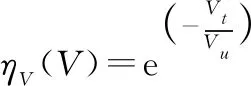
(9)
135 機(jī)動(dòng)決策整體評(píng)價(jià)函數(shù)
=[04,04,01,01]·[,,,]
(10)
其中,系數(shù)由文獻(xiàn)[17]中的不利態(tài)勢(shì)確定。
假設(shè)每一次決策之間的時(shí)間是固定的,對(duì)于每一次決策,則其任意時(shí)刻機(jī)動(dòng)決策求解變?yōu)?/p>
(,,+1)=(+1)-()=
(,+1,,)-(,,,)=
((,,+Δ,),,)-(,,,)
(11)
式中:(+1)為+1時(shí)UCAV的態(tài)勢(shì)值;()為時(shí)UCAV的態(tài)勢(shì)值。由于+1時(shí)刻UCAV態(tài)勢(shì)值由UCAV狀態(tài),+1和追擊機(jī)狀態(tài),計(jì)算得到,而,+1由狀態(tài)方程(,,+Δ,)計(jì)算得出,因此決策過(guò)程即為對(duì)控制量變化率Δ的求解。整個(gè)決策過(guò)程要使性能指標(biāo)( , )最大,即為求解控制量變化率序列Δ=[Δ,Δ,Δ](=0,1,…,-1),使其最大。
2 模糊專家系統(tǒng)
2.1 機(jī)動(dòng)動(dòng)作庫(kù)
本文采用文獻(xiàn)[20]中對(duì)基本機(jī)動(dòng)動(dòng)作庫(kù)進(jìn)行拓展之后的拓展機(jī)動(dòng)動(dòng)作庫(kù),如圖3所示。由于本文采用的模型與其不同,因此不能應(yīng)用其建立的控制算法,而是將控制變量和飛行動(dòng)作之間進(jìn)行解耦,再根據(jù)當(dāng)前狀態(tài)確定控制量變化率的正負(fù),達(dá)到對(duì)尋優(yōu)范圍的約束,從而能夠飛出想要的機(jī)動(dòng)動(dòng)作。由于篇幅有限,在此不加以贅述。
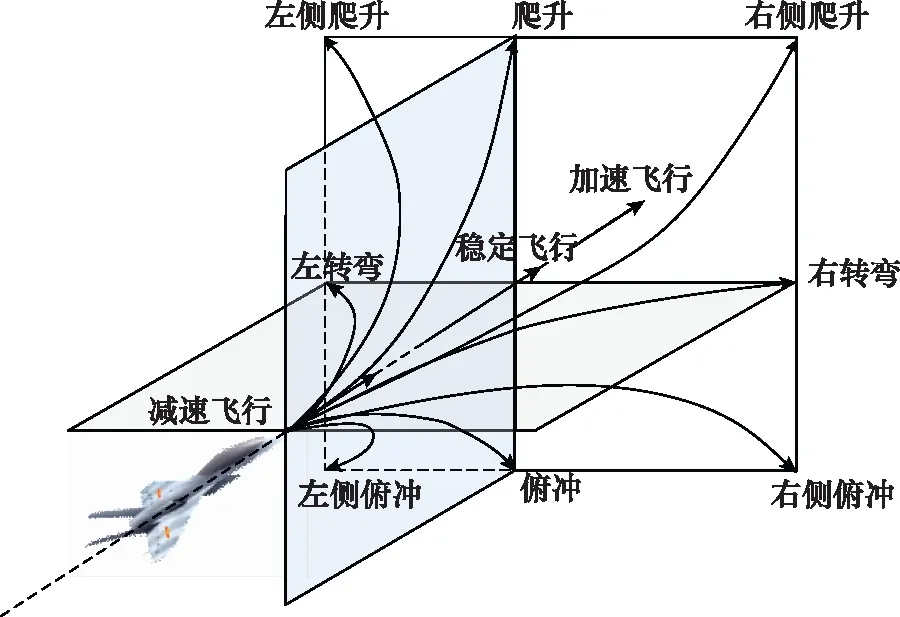
圖3 拓展機(jī)動(dòng)動(dòng)作庫(kù)
2.2 基于模糊推理的專家系統(tǒng)
當(dāng)前專家系統(tǒng)主要應(yīng)用于故障檢測(cè)方面,而在機(jī)動(dòng)決策方面有關(guān)文獻(xiàn)較少,且對(duì)于專家系統(tǒng)的建立也語(yǔ)焉不詳,在文獻(xiàn)[10]中,采用滾動(dòng)時(shí)域決策作為專家系統(tǒng)失效時(shí)的補(bǔ)充,但對(duì)于機(jī)動(dòng)決策的專家系統(tǒng)知識(shí)庫(kù)的建立沒(méi)有說(shuō)明,而是簡(jiǎn)單搭建了框架。在本文中對(duì)于知識(shí)庫(kù)的建立給予詳細(xì)說(shuō)明。
221 模糊專家系統(tǒng)整體結(jié)構(gòu)
根據(jù)在專家系統(tǒng)中知識(shí)表達(dá)方式的不同,目前的專家系統(tǒng)大致可以分為基于規(guī)則的專家系統(tǒng)、基于框架的專家系統(tǒng)、基于模型的專家系統(tǒng)3種情況。
產(chǎn)生式規(guī)則是專家系統(tǒng)中常用的知識(shí)表示方法,又稱為規(guī)則表示法,通常用于表示具有因果關(guān)系的知識(shí),其基本形式如下:If P, then Q,或者可表示為 P→Q。其中,P代表?xiàng)l件,即前件,如前提、原因等;而Q代表結(jié)果,即后件,如結(jié)論、后果等,其含意為如果前提P被滿足,則可以推出結(jié)論Q。亦稱為If-Then規(guī)則。
文獻(xiàn)[22]一文指出,對(duì)于復(fù)雜系統(tǒng)難以用結(jié)構(gòu)化數(shù)據(jù)來(lái)表達(dá),如果全部用規(guī)則的形式來(lái)表達(dá),不僅提煉規(guī)則相當(dāng)困難,并且規(guī)則庫(kù)也相當(dāng)龐大和復(fù)雜,容易產(chǎn)生組合爆炸。針對(duì)這一情況,引入模糊數(shù)學(xué),首先對(duì)輸入?yún)?shù)進(jìn)行模糊處理,同時(shí)將單一專家系統(tǒng)解耦為多個(gè)小規(guī)模專家系統(tǒng),建立了如圖4所示的基于模糊推理的專家系統(tǒng)結(jié)構(gòu)圖。
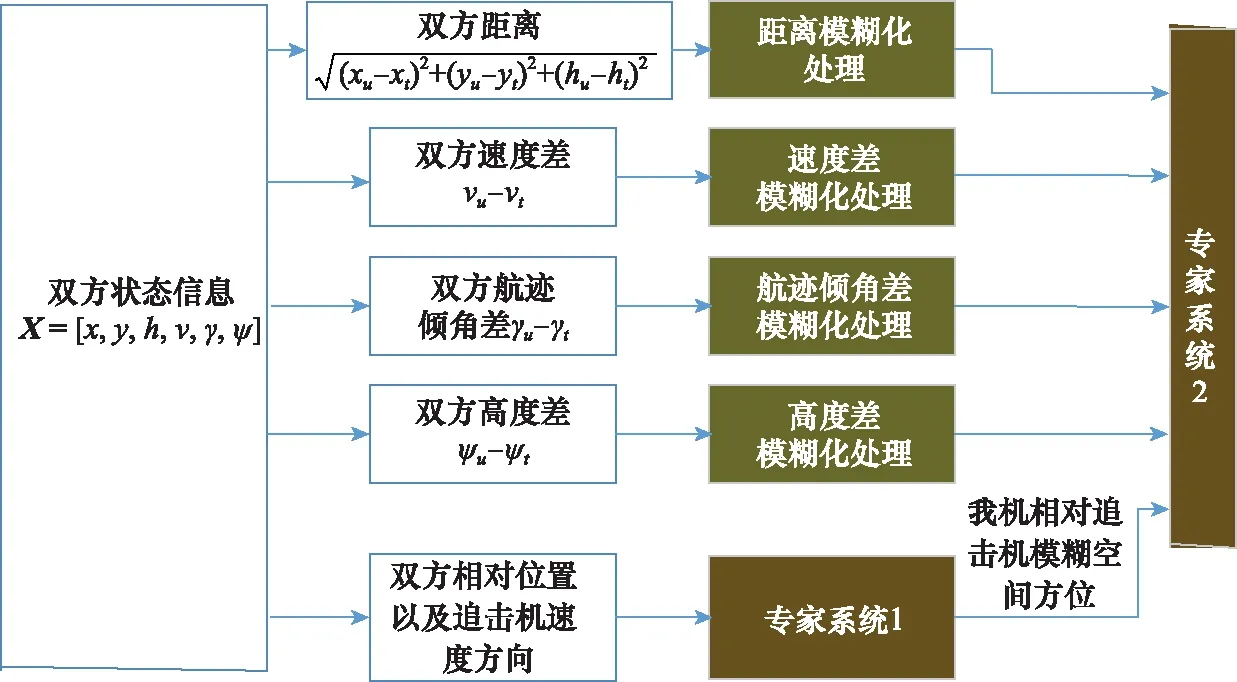
圖4 基于模糊推理的專家系統(tǒng)結(jié)構(gòu)圖
其中,專家系統(tǒng)1用于根據(jù)雙方坐標(biāo)以及追擊機(jī)航向確定我機(jī)相對(duì)于敵方模糊的方位。考慮到我機(jī)相對(duì)敵機(jī)處于不利態(tài)勢(shì),模糊輸出分為正前方、左前方、右前方、正上方、左上方、右上方、正下方、左下方、右下方。首先需要計(jì)算追擊機(jī)與我機(jī)之間的視線角,具體的設(shè)計(jì)如表1所示。

表1 專家系統(tǒng)1設(shè)計(jì)
2.2.2 基于飛行經(jīng)驗(yàn)的知識(shí)庫(kù)建立
在當(dāng)前的機(jī)動(dòng)決策方法中,少有對(duì)飛行員空戰(zhàn)戰(zhàn)術(shù)知識(shí)的利用,這也導(dǎo)致機(jī)動(dòng)決策的結(jié)果不能被飛行員所認(rèn)可和解釋,對(duì)此,通過(guò)對(duì)公開(kāi)的戰(zhàn)術(shù)書(shū)籍和項(xiàng)目學(xué)習(xí)以及和與飛行員現(xiàn)場(chǎng)交流,建立基于飛行員空戰(zhàn)戰(zhàn)術(shù)知識(shí)的知識(shí)庫(kù),在當(dāng)前空戰(zhàn)態(tài)勢(shì)滿足If-Then規(guī)則時(shí),輸出將要采取的機(jī)動(dòng)動(dòng)作。
(1) 輸入輸出變量確定
專家系統(tǒng)2的輸入變量為模糊化后得到的速度差、航跡傾角差、高度差和模糊空間方位,即:IL={LR、Lv、Lγ、Lh、LW},其中LR、Lv、Lγ、Lh的模糊語(yǔ)言為[S、M、L],分別表示輸入的小、中、大,LW的模糊語(yǔ)言為[1,2,3,4,5,6,7,8,9],分別表示我機(jī)相對(duì)敵機(jī)所處的空間方位序號(hào)。
輸出變量為OL={DZ},DZ為機(jī)動(dòng)決策得到的機(jī)動(dòng)動(dòng)作,模糊語(yǔ)言為[1,2,3,4,5,6,7,8,9,10,11],分別代表所選機(jī)動(dòng)動(dòng)作序號(hào)。
(2) 典型戰(zhàn)術(shù)知識(shí)獲取
典型空戰(zhàn)戰(zhàn)術(shù)描述:盤(pán)旋爬升俯沖反擊。
使用時(shí)機(jī):我機(jī)處于能量?jī)?yōu)勢(shì),追擊機(jī)處于角度優(yōu)勢(shì),雙方距離較近。
基本方法:在初始處于角度劣勢(shì)時(shí),將己方能量?jī)?yōu)勢(shì)轉(zhuǎn)化為高度優(yōu)勢(shì),采取盤(pán)旋爬升的方式(時(shí)刻1),當(dāng)盤(pán)旋到比較陡直的時(shí)候,追擊機(jī)的角度增加速度緩慢,爬升角也穩(wěn)定下來(lái)(時(shí)刻2),此時(shí)采取躍升的方式,而追擊機(jī)可以調(diào)整航跡偏角和滾轉(zhuǎn)角,使我機(jī)處于其前上方(時(shí)刻3),如果此時(shí)追擊機(jī)仍然使它的機(jī)頭向上并持續(xù)轉(zhuǎn)彎,我機(jī)可繼續(xù)爬升以取得最大限度的高度優(yōu)勢(shì),并盡可能減小過(guò)載,到達(dá)躍升頂端時(shí),機(jī)頭向下俯沖,直接指向目標(biāo)并開(kāi)火射擊(時(shí)刻4)。如圖5所示。
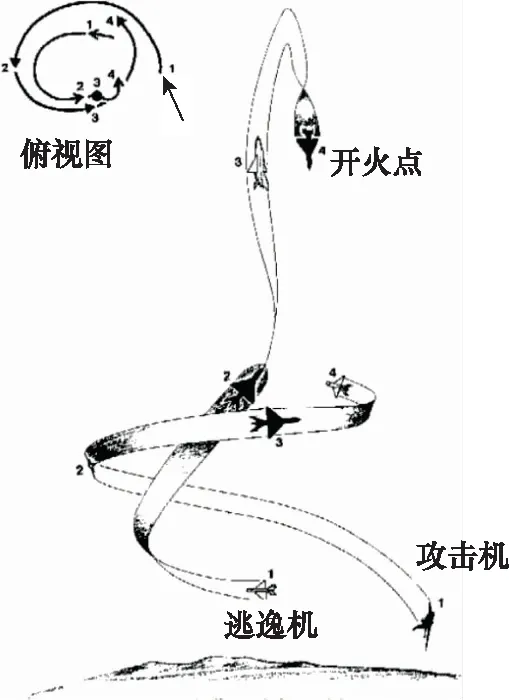
圖5 典型空戰(zhàn)戰(zhàn)術(shù)圖
If-Then規(guī)則獲取如表2所示。

表2 If-Then規(guī)則獲取表
通過(guò)對(duì)典型戰(zhàn)術(shù)知識(shí)的規(guī)則提取,即可建立完備的專家系統(tǒng)。
3 基于DSC-JADE算法的機(jī)動(dòng)決策
帶邊界約束的優(yōu)化問(wèn)題在現(xiàn)實(shí)世界是非常普遍的,在文獻(xiàn)[26]中指出其普遍形式如下所示:
(),=(,,…,)

(12)

3.1 原始標(biāo)準(zhǔn)算法
初始化。和其余群智能優(yōu)化算法一樣,首先初始化種群:
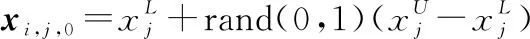
(13)
式中:,,0是第0代第個(gè)個(gè)體的第個(gè)元素,=1,2,…,NP,=1,2,…,,NP為初始種群數(shù),為變量的維度。
變異操作。對(duì)于種群中每個(gè)個(gè)體,差分進(jìn)化算法的變異向量的產(chǎn)生方法表示為DE。其中,表示當(dāng)前被變異的向量是隨機(jī)的還是最優(yōu)的,表示差向量的個(gè)數(shù)。
DE/rand1:,+1=1,+(2,-3,)
(14)
式中:1、2和3在種群中隨機(jī)選擇且1≠2≠3;縮放因子用于控制偏差的放大作用,且0≤≤2。
除此之外,偏差向量還可以由其他的方式產(chǎn)生。
DE/best1:,+1=best,+(1,-2,)
DE/current-to-best/1:
,+1=,+(best,-,)+(1,-2,)
DE/best2:,+1=best,+(1,-2,+3,-4,)
DE/rand/2:,+1=5,+(1,-2,+3,-4,)
(15)
交叉操作:交叉因子CR用于控制交叉概率。

(16)
選擇操作。差分進(jìn)化算法按照貪婪策略,從實(shí)驗(yàn)種群中選擇個(gè)體作為下一代種群中的個(gè)體,具體的選擇方式為

(17)
3.2 雙策略競(jìng)爭(zhēng)的JADE算法
JADE算法是2009年由Zhang等提出的一種DE算法的變體,近年來(lái)優(yōu)秀的算法都是以JADE為基礎(chǔ)改進(jìn)的,其相對(duì)于原始DE算法的優(yōu)勢(shì)如下:
(1) JADE算法最大的優(yōu)勢(shì)在于通過(guò)使用可選的外部存檔實(shí)施新的變異策略DE/current-to-pbest,外部存檔利用歷史數(shù)據(jù)提供進(jìn)度方向信息。
無(wú)外部存檔的變異策略:
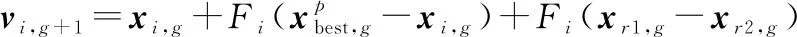
(18)
有外部存檔的變異策略:
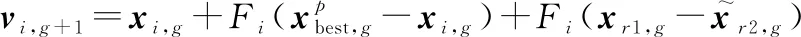
(19)
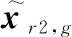
為平衡初期算法的全局搜索能力,本文加入另一變異策略進(jìn)行競(jìng)爭(zhēng):

(20)
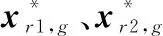
在文獻(xiàn)[29]中提出了策略競(jìng)爭(zhēng)的機(jī)制,初始時(shí)刻策略選擇的概率和概率相同,之后根據(jù)策略是否成功來(lái)更新選擇概率,交叉后生成的個(gè)體比原個(gè)體更優(yōu)即為策略成功。
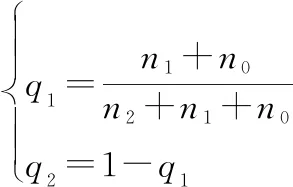
(21)
式中:為策略1成功次數(shù);為策略2成功次數(shù);為正常數(shù),防止選擇概率的顯著變化。為避免搜索過(guò)程退化,若這兩個(gè)選擇概率低于閾值,則重置為初始值。
(2) 以自適應(yīng)方式更新控制參數(shù),CR來(lái)提高優(yōu)化性能。
CR根據(jù)均值為,標(biāo)準(zhǔn)差為01的正態(tài)分布產(chǎn)生,根據(jù)均值為,標(biāo)準(zhǔn)差為01的柯西分布產(chǎn)生。初始設(shè)置為05,初始也設(shè)置為05。
將每一代成功的個(gè)體的CR值存儲(chǔ)起來(lái),即為,同樣的將每一代成功的個(gè)體的值存儲(chǔ)起來(lái),即為。
在每一次迭代后,更新和的值為

(22)
式中:是權(quán)值,設(shè)置為0.5;mean指計(jì)算算術(shù)平均數(shù)。mean的定義如下:
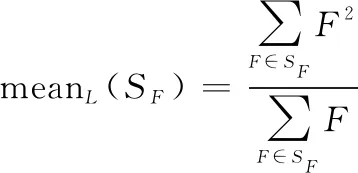
(23)
DSC-JADE偽代碼如算法1所示。

算法 1DSC-JADE算法偽碼1.Begin2.μCR=0.5,μF=0.5,A=?,q1=0.5,q2=0.53. 初始化種群4. While G≤Gmax do5. SCR=?,SF=?6. for i=1 to NP do7. CRi=rand ni(μCR,0.1),Fi=rand ci(μF,0.1)8. 根據(jù)q1,q2的值選擇變異策略生成vi,g+19. for j=1 to D do

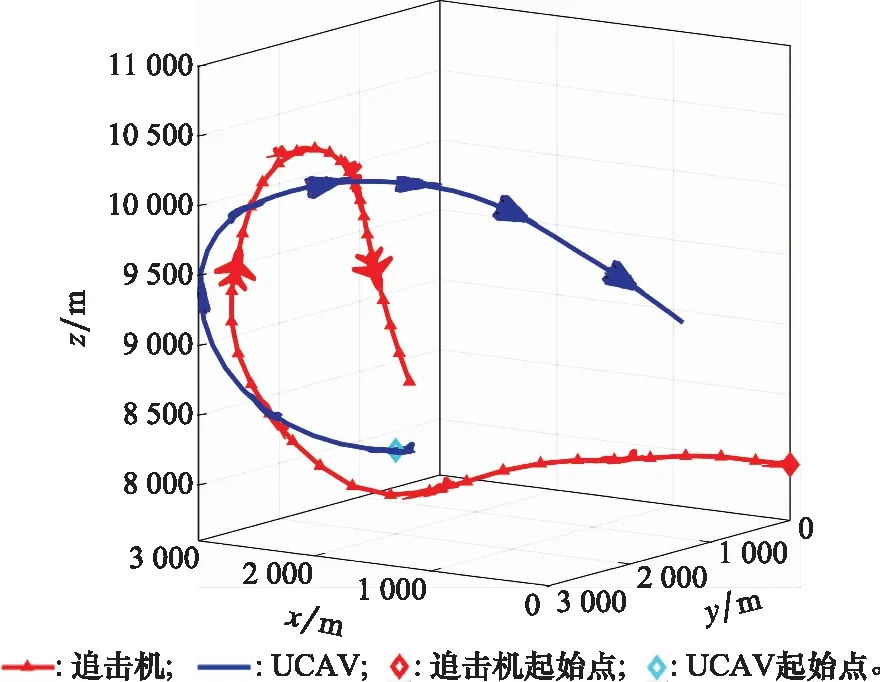
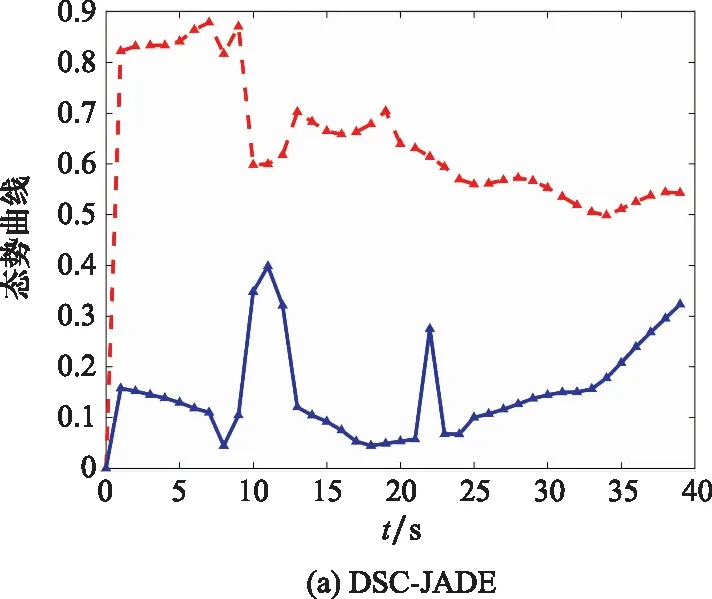
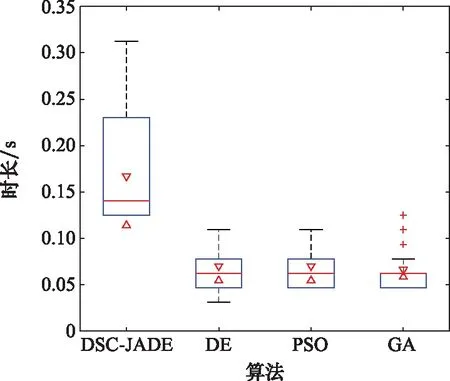
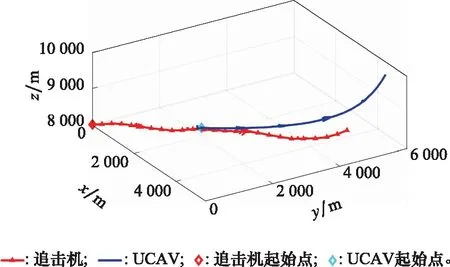
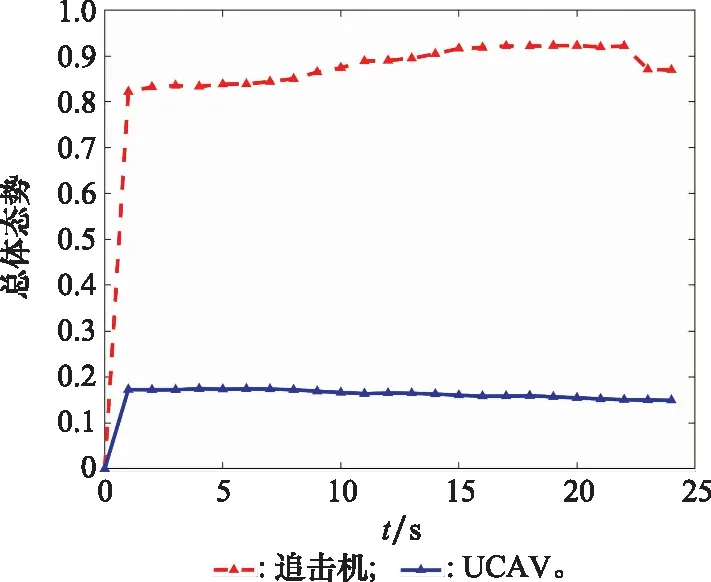
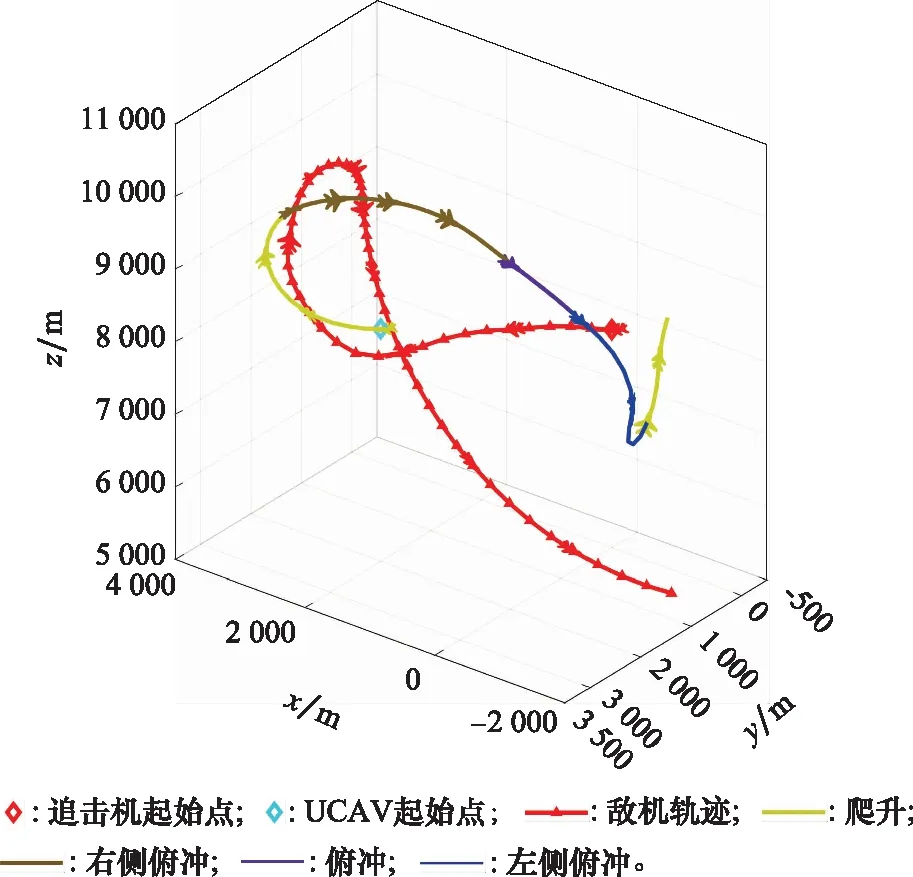
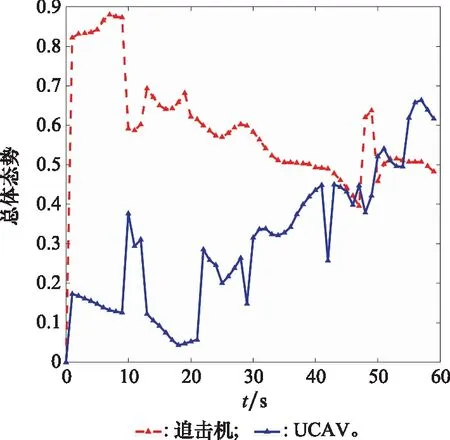
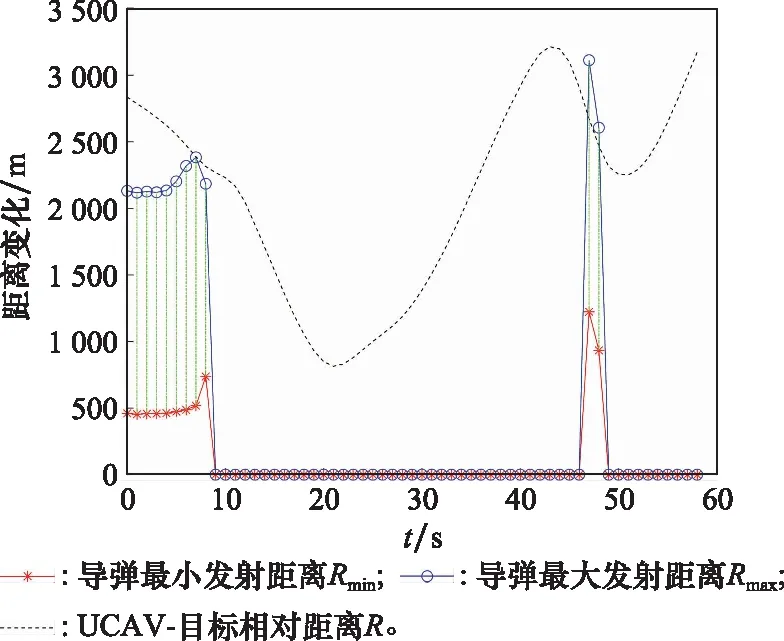
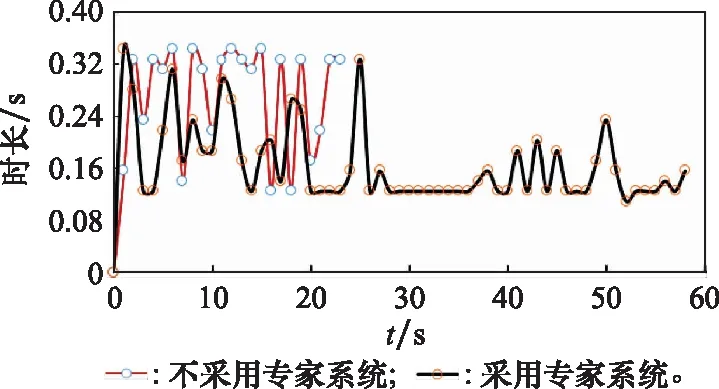
10. if rand [Δmax,Δmax,Δmax]=[5°,30°,05] [Δmin,Δmin,Δmin]=[-5°,-30°,-05] 雙方控制量限制范圍為 [,,]=[34°,180°,1] [,,]=[-15°,-180°,015] 我機(jī)與追擊機(jī)初始控制量都是[,,]=[0,0,05],仿真每步時(shí)長(zhǎng)設(shè)置為1 s,追擊機(jī)采用文獻(xiàn)[30]中的試探機(jī)動(dòng)決策的方法,由于本文篇幅原因,在此不加以贅述。 本文建立的機(jī)動(dòng)決策框如圖6所示。 圖6 基于模糊專家系統(tǒng)與DSC-JADE算法相結(jié)合的UCAV逃逸機(jī)動(dòng)決策框圖 為驗(yàn)證采用的DSC-JADE算法在求解控制量變化率問(wèn)題上的實(shí)時(shí)性,以時(shí)刻機(jī)動(dòng)對(duì)抗雙方狀態(tài)為條件,對(duì)專家系統(tǒng)決策后輸出的機(jī)動(dòng)動(dòng)作對(duì)應(yīng)的控制量變化率范圍為尋優(yōu)范圍,進(jìn)行尋優(yōu)比較,尋找使得目標(biāo)函數(shù)值最大的控制量變化率,并與蟻群算法(ant colony optimization, ACO), 粒子群優(yōu)化(particle swarm optimization, PSO)算法、遺傳算法(genetic algorithm, GA)、DE等算法進(jìn)行性能比較,最大迭代次數(shù)都為50,種群規(guī)模NP都為100,其余各算法參數(shù)設(shè)置如表3所示,仿真步長(zhǎng)為40,得到40次尋優(yōu)算法所用時(shí)間以及雙方機(jī)動(dòng)軌跡和態(tài)勢(shì)曲線如圖7和圖8所示。 表3 算法參數(shù)設(shè)置表 圖7 采用DSC-JADE算法機(jī)動(dòng)決策雙方機(jī)動(dòng)軌跡圖 圖8 采用DES-JADE、DE、PSO、GA算法得到的雙方總體態(tài)勢(shì)變化曲線 ACO中,為信息素的相對(duì)重要程度,為啟發(fā)式因子的相對(duì)重要程度,為信息素?fù)]發(fā)系數(shù);PSO中,為粒子的個(gè)體學(xué)習(xí)因子,為粒子的社會(huì)學(xué)習(xí)因子,為慣性因子;GA中,為交叉概率,為變異概率。 從仿真結(jié)果(見(jiàn)圖9)來(lái)看,經(jīng)過(guò)40個(gè)步長(zhǎng)的仿真,采用DSC-JADE算法的UCAV最終態(tài)勢(shì)值相較于其余算法最大,為0.323 1,比較來(lái)看DSC-JADE算法明顯具備更好的尋優(yōu)性能。從算法使用時(shí)間來(lái)看,DSC-JADE算法每步尋優(yōu)所用時(shí)間中位數(shù)為0.141 2 s;相較于其余算法尋優(yōu)所用時(shí)間略長(zhǎng),但相較于1 s的決策周期而言是可接受的,且能更好地尋找到全局最優(yōu)點(diǎn),避免陷入局部最優(yōu)。 圖9 算法所用時(shí)長(zhǎng)箱線圖 為體現(xiàn)所建立專家系統(tǒng)的有效性,將逃逸機(jī)采用專家系統(tǒng)其逃逸機(jī)不采用專家系統(tǒng)進(jìn)行對(duì)比,為體現(xiàn)一般性,進(jìn)行100次蒙特卡羅仿真,對(duì)比優(yōu)勝率,同時(shí)文中各選取其中一組具有代表性的仿真實(shí)驗(yàn)進(jìn)行描述。 仿真終止條件:由于真實(shí)近距空戰(zhàn)對(duì)抗訓(xùn)練中,對(duì)于追擊科目而言,通常會(huì)設(shè)置時(shí)間限制,因此設(shè)定時(shí)間大于60 s時(shí)仿真終止,宣布逃逸機(jī)逃逸成功;若攻擊機(jī)連續(xù)3 s位于導(dǎo)彈攻擊區(qū)內(nèi),判定UCAV被攻擊機(jī)發(fā)射的紅外空空導(dǎo)彈擊中,宣布追擊機(jī)勝利;設(shè)定空戰(zhàn)區(qū)域高度大于1 000 m,飛行高度小于1 000 m時(shí)超出空戰(zhàn)范圍,仿真結(jié)束。 (1) 包含決策過(guò)程的追擊機(jī)對(duì)抗不含專家系統(tǒng)的UCAV如圖10~圖12所示。 圖10 包含決策過(guò)程的追擊機(jī)對(duì)抗不含專家系統(tǒng)的UCAV機(jī)動(dòng)軌跡圖 圖11 追擊機(jī)對(duì)抗不含專家系統(tǒng)的UCAV雙方總體態(tài)勢(shì)變化曲線 圖12 追擊機(jī)與不含專家系統(tǒng)相對(duì)距離和導(dǎo)彈可發(fā)射距離變化曲線 可以看到,當(dāng)UCAV不采用專家系統(tǒng)時(shí),其決策出的機(jī)動(dòng)為爬升機(jī)動(dòng),但由于尋優(yōu)范圍過(guò)大,容易陷入局部最優(yōu),導(dǎo)致沒(méi)有采用最大過(guò)載進(jìn)行爬升,在21~24 s時(shí)在追擊機(jī)導(dǎo)彈發(fā)射區(qū)域內(nèi),導(dǎo)致被追擊機(jī)擊中。 (2) 包含決策過(guò)程的追擊機(jī)對(duì)抗含專家系統(tǒng)的UCAV如圖13~圖15所示。 圖13 包含決策過(guò)程的追擊機(jī)對(duì)抗含專家系統(tǒng)的UCAV機(jī)動(dòng)軌跡圖 圖14 追擊機(jī)對(duì)抗含專家系統(tǒng)的UCAV雙方總體態(tài)勢(shì)變化曲線 圖15 追擊機(jī)與含專家系統(tǒng)的UCAV相對(duì)距離和導(dǎo)彈可發(fā)射距離變化曲線 從圖13~圖15中可以看出,UCAV一開(kāi)始采用專家系統(tǒng)決策得到的機(jī)動(dòng)動(dòng)作也是爬升機(jī)動(dòng),但由于其尋優(yōu)范圍較小,尋優(yōu)得到的過(guò)載值更大,因此在第8 s時(shí)躲過(guò)了追擊機(jī)導(dǎo)彈鎖定,并在之后決策得到右側(cè)俯沖、俯沖、左側(cè)俯沖、爬升等一系列機(jī)動(dòng)動(dòng)作,使得UCAV形成較優(yōu)的態(tài)勢(shì),經(jīng)過(guò)60 s,追擊機(jī)沒(méi)有擊中UCAV,UCAV完成逃逸。 圖16中,從每步?jīng)Q策所用時(shí)長(zhǎng)的數(shù)據(jù)來(lái)看,不采用專家系統(tǒng)限制尋優(yōu)范圍,每步時(shí)長(zhǎng)決策平均值為0.275 1 s,標(biāo)準(zhǔn)差為0.078 4;采用專家系統(tǒng)限制尋優(yōu)范圍,每步?jīng)Q策時(shí)長(zhǎng)平均值為0.168 4 s,標(biāo)準(zhǔn)差為0.059 8。從表4結(jié)果來(lái)看,采用專家系統(tǒng),平均每步?jīng)Q策時(shí)長(zhǎng)減少約33.4%,且穩(wěn)定性更好。 圖16 采用專家系統(tǒng)與不采用專家系統(tǒng)每步?jīng)Q策所用時(shí)長(zhǎng)變化曲線 表4 100次蒙特卡羅空戰(zhàn)仿真實(shí)驗(yàn)結(jié)果統(tǒng)計(jì) 本文針對(duì)UCAV處于不利態(tài)勢(shì)時(shí)的逃逸機(jī)動(dòng)決策問(wèn)題,將DSC-JADE算法引入模糊專家系統(tǒng)進(jìn)行逃逸機(jī)動(dòng)決策,建立了基于滾動(dòng)時(shí)域的控制量變化率尋優(yōu)的機(jī)動(dòng)決策模型,相較而言更為貼近UCAV的真實(shí)控制,且改進(jìn)算法相對(duì)其余群智能算法能迅速完成控制量變化率尋優(yōu),在全局最優(yōu)的搜索能力上有所提升;為將空戰(zhàn)知識(shí)運(yùn)用到機(jī)動(dòng)逃逸中去,將尋優(yōu)范圍運(yùn)用專家系統(tǒng)進(jìn)行限制,以達(dá)到想要的機(jī)動(dòng)動(dòng)作,并大大提高決策的實(shí)時(shí)性。最后仿真結(jié)果顯示用專家系統(tǒng)決策實(shí)時(shí)性提升約33.4%,逃逸成功率提升29%,且得到的機(jī)動(dòng)軌跡更符合戰(zhàn)術(shù)知識(shí)。4 仿真分析
4.1 算法的性能比較

4.2 對(duì)比實(shí)驗(yàn)


5 結(jié) 論
猜你喜歡
作文周刊·小學(xué)一年級(jí)版(2022年16期)2022-05-07 11:28:30
作文周刊·小學(xué)一年級(jí)版(2021年8期)2021-07-07 11:00:47
動(dòng)漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學(xué)低年級(jí)(2017年4期)2017-06-09 16:22:28
作文周刊·小學(xué)一年級(jí)版(2016年28期)2017-06-03 00:28:49
作文評(píng)點(diǎn)報(bào)·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 20:56:37
電影故事(2015年30期)2015-02-27 09:03:12
七彩語(yǔ)文·低年級(jí)(2014年10期)2015-01-14 14:46:27
