基于空間域注意力機(jī)制的車間人員檢測方法
2022-05-25 08:16:22李成嚴(yán)馬金濤趙帥
哈爾濱理工大學(xué)學(xué)報 2022年2期
李成嚴(yán) 馬金濤 趙帥





摘要:車間人員檢測是指使用目標(biāo)檢測技術(shù)對工廠生產(chǎn)車間內(nèi)相應(yīng)區(qū)域進(jìn)行人員檢測,保障生產(chǎn)車間內(nèi)人員生命健康安全。車間內(nèi)人員檢測存在圖像模糊、檢測效率低、實時性要求高等問題,將改進(jìn)的暗通道優(yōu)先處理策略用于圖像增強(qiáng)、用空間域注意力機(jī)制相結(jié)合的SSD(Single Shot MultiBox Detector)網(wǎng)絡(luò)提高檢測效率,同時保障實時性要求,并在本文測試集及VOC2012數(shù)據(jù)集上進(jìn)行驗證,結(jié)果顯示出較好的定位效果及檢測率。
關(guān)鍵詞:車間人員檢測;SSDSN網(wǎng)絡(luò);空間注意力機(jī)制;暗通道優(yōu)先策略;區(qū)域劃分
DOI:10.15938/j.jhust.2022.02.012
中圖分類號: TP399
文獻(xiàn)標(biāo)志碼: A
文章編號: 1007-2683(2022)02-0092-07
Workshop Staff Detection Method Based on Spatial
Domain Attention Mechanism
LI Cheng-yan,MA Jin-tao,ZHAO Shuai
(School of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150080, China)
Abstract:Workshop staff detection is to use the target detection technology to detect the staff in the corresponding area of the factory production workshop, to ensue the life, health and safety of the staff in the production workshop. In this paper, the improved dark channel priority processing strategy is applied to image enhancement and SSD (single shot multibox detector) which combines spatial attention mechanism detector (detector) network improves the detection efficiency while ensuring the real-time requirements. It is verified on the test set and VOC data set in this paper, and the results show that the positioning effect and detection rate are better.
Keywords:workshop staff detection; SSDSN network; spatial domain attention mechanism; dark channel priority strategy; regional division
0引言
車間人員安全是工業(yè)生產(chǎn)活動中的重要問題。傳統(tǒng)的安全監(jiān)測機(jī)制與系統(tǒng)功能的不足,導(dǎo)致頻繁發(fā)生人身安全事故。車間內(nèi)人員安全問題需要迫切得到解決。目前,通常采取視頻監(jiān)控的方式監(jiān)控車間內(nèi)人員安全情況,由人工進(jìn)行實時查看,但人工監(jiān)
測費時、費力、反應(yīng)慢、成本高、收益低。隨著計算機(jī)技術(shù)的發(fā)展,傳統(tǒng)行業(yè)也逐漸走向智能化。車間人員檢測是基于智能信息處理的目標(biāo)檢測,具有實時性、準(zhǔn)確性、低成本的優(yōu)點,采用智能監(jiān)測的方法實時檢測監(jiān)控視頻,一旦發(fā)生意外立即報警,采取相應(yīng)措施,避免事故的發(fā)生。因此,車間人員檢測具有重要研究價值。
目標(biāo)檢測[19-20]已經(jīng)從傳統(tǒng)的目標(biāo)檢測過渡到基于深度學(xué)習(xí)的目標(biāo)檢測。傳統(tǒng)的目標(biāo)檢測采用人工特征提取方法獲得目標(biāo)的特征描述,并輸入到分類器中學(xué)習(xí)分類規(guī)則,如VJ檢測器[1]、HOG檢測器[2]、DPM[3]等,這些方法時間復(fù)雜度高,窗口冗余,手工設(shè)計的特征魯棒性差。隨著深度學(xué)習(xí)概念的提出[4],目標(biāo)檢測可以從原始數(shù)據(jù)中獲取特征信息,避免了傳統(tǒng)目標(biāo)檢測中繁瑣的特征工程步驟,如文[5-9]等。
基于深度學(xué)習(xí)的目標(biāo)檢測被廣泛應(yīng)用,文[10]將目標(biāo)檢測用于非法流動攤販檢測,但其對圖像像素要求較高,像素較低時檢測效果不佳。文[11]提出了一種車輛目標(biāo)檢測方法,對圖像特征進(jìn)行規(guī)格化和并行的回歸計算,檢測效果較好,但檢測速度低,影響實時性。文[12]提出結(jié)合語義信息的行人檢測方法,圖像像素較低時也可識別,但準(zhǔn)確率、召回率較低。
車間人員檢測包括從車間的監(jiān)控視頻中檢測和定位人員兩部分。檢測速度應(yīng)滿足實時性要求;煙霧、粉塵、光照等因素導(dǎo)致檢測圖像質(zhì)量較差,影響檢測率與準(zhǔn)確率,檢測準(zhǔn)確率有待提高;由于車間內(nèi)區(qū)域復(fù)雜,需對車間內(nèi)區(qū)域進(jìn)行劃分,并判斷車間人員所在區(qū)域。
SSD(single shotMultiBox detector)是單階段的目標(biāo)檢測網(wǎng)絡(luò),檢測速度較快,本文將SSD作為車間人員檢測的基礎(chǔ)網(wǎng)絡(luò)。在圖像質(zhì)量較差時,暗通道優(yōu)先的圖像處理方法效果顯著,如文[13]使用暗通道進(jìn)行圖像去霧。為提高目標(biāo)檢測的定位能力及準(zhǔn)確性,文[14]利用注意力機(jī)制提高檢測精度。文[15]使用注意力機(jī)制來提高目標(biāo)的定位能力。注意力機(jī)制關(guān)注圖像中輔助判斷的信息,忽略不相關(guān)的信息[16],可從大量信息中篩選出高價值信息,極大地提高信息處理的效率與準(zhǔn)確性,提升目標(biāo)檢測定位能力。
本文提出一種基于空間域注意力機(jī)制的車間人員檢測方法。該方法將改進(jìn)的暗通道優(yōu)先處理策略用于圖像增強(qiáng);用與空間域注意力機(jī)制[17]相結(jié)合的SSD網(wǎng)絡(luò)提高檢測精度,提出SSDSN(SSD Spatial attention mechanism network)車間人員檢測網(wǎng)絡(luò);使用區(qū)域劃分方法解決車間區(qū)域復(fù)雜問題。
1車間人員檢測系統(tǒng)結(jié)構(gòu)
1.1區(qū)域劃分與判別
將整個生產(chǎn)作業(yè)區(qū)域劃分為安全區(qū)、報警區(qū)和危險區(qū)三類。安全區(qū)是指車間內(nèi)車間人員正常工作的區(qū)域,報警區(qū)是有一定危險,應(yīng)提示注意的區(qū)域,危險區(qū)是指可能對車間人員造成傷害的區(qū)域。
通過車間內(nèi)監(jiān)控攝像頭獲取該區(qū)域?qū)嶋H布局圖,并對此區(qū)域進(jìn)行劃分。圖1為某運輸皮帶車間實例,其中(a)為車間實際布局,包括中間的行人通廊,兩側(cè)的護(hù)欄及兩條運輸皮帶;(b)為區(qū)域劃分圖,即呈現(xiàn)在顯示屏中(a)與(c)的疊加效果。(c)為設(shè)定的背景圖,圖1(c)中間黑色區(qū)域為安全區(qū),對應(yīng)(b)中的行人通廊,(c)中的白色區(qū)域為報警區(qū),對應(yīng)(b)護(hù)欄區(qū)域,(c)中的灰色區(qū)域為危險區(qū),對應(yīng)(b)運輸皮帶區(qū)域。
通過目標(biāo)檢測網(wǎng)絡(luò)輸出車間人員位置中心點坐標(biāo),與各區(qū)域邊界坐標(biāo)對比,判斷車間人員位置,若處于報警區(qū)內(nèi)則通過聲光報警提醒,若車處于危險區(qū)則控制設(shè)備停機(jī),以保障車間人員安全。
1.2改進(jìn)的暗通道優(yōu)先圖像降噪策略
受煙霧、粉塵、光照等因素影響,車間圖像質(zhì)量較差,導(dǎo)致檢測率與準(zhǔn)確率不高。
暗通道優(yōu)先圖像處理策略將暗通道有關(guān)結(jié)論當(dāng)作先驗條件使用,在圖像增強(qiáng)和圖像修復(fù)方面存在一定優(yōu)勢。
暗通道優(yōu)先圖像處理策略公式為
其中:J(x)為降噪后的圖片;B為車間背景光;t(x)
為x處的透射率;t為一個閾值,當(dāng)投射圖的值較小時,會導(dǎo)致J值偏大,使圖像向白場過度,因此當(dāng)投射圖的值小于t時,令其等于t,令t=0.1,B通過暗通道圖從原圖中獲得,在暗通道圖中按照亮度大小取最亮的前0.1%像素,在原圖中找對應(yīng)位置上的最高亮度的點的值,以此點的色素值為B值。
根據(jù)暗通道理論建立車間光照成像模型:
由于車間內(nèi)光照原因,導(dǎo)致圖像亮度差異較大,式(1)中B值是原始像素中的某一個點的像素,如果取一個點,各通道的B值很有可能全部很接近255,這會造成處理后的圖像偏色和出現(xiàn)大量色斑。
為避免上述問題,對車間內(nèi)背景光重新計算,取暗通道圖像各通道灰度值最大的前0.1%的像素點的灰度平均值作為B值。
根據(jù)式(6)和式(7),可以得到最后的透射率為
式(10)中X是閾值,根據(jù)噪聲強(qiáng)度對X進(jìn)行取值,用于調(diào)節(jié)B值。若噪聲較大,可適當(dāng)增大X的值,通過調(diào)整X值,可獲得一個較好降噪效果,改進(jìn)的暗通道優(yōu)先處理策略效果如圖2所示。其中(a)為原始圖,(b)為暗通道優(yōu)先圖像處理策略處理的降噪圖,(c)為改進(jìn)的暗通道優(yōu)先圖像處理策略處理的降噪圖。
1.3系統(tǒng)框架
結(jié)合空間注意力機(jī)制改進(jìn)SSD目標(biāo)檢測網(wǎng)絡(luò),為保障對車間人員的檢測能力,用監(jiān)控圖片數(shù)據(jù)作為訓(xùn)練集,并對訓(xùn)練集進(jìn)行降噪處理、人工標(biāo)注,通過訓(xùn)練得到網(wǎng)絡(luò)模型。為保障檢測實時性,采用RTSP獲取實時視頻流。為保障檢測的準(zhǔn)確性,將幀圖片降噪后,再傳入檢測網(wǎng)絡(luò)中檢測,若檢測到有人員,則通過矩形框框出人員輪廓,并通過矩形框邊界估算人員位置坐標(biāo),通過檢測算法返回車間人員位置坐標(biāo)與劃分的區(qū)域坐標(biāo)比較,判斷車間人員所處區(qū)域,通過警報提醒車間人員及監(jiān)控人員,并輸出相應(yīng)的報警、危險狀態(tài)標(biāo)志。該狀態(tài)標(biāo)志采用串口通訊的方式發(fā)送信息報文至報警控制器,由報警控制器將信息報文解析后發(fā)送相應(yīng)控制指令至PLC(programmable logic controller)控制系統(tǒng)。現(xiàn)場PLC控制系統(tǒng)則依據(jù)控制指令分別進(jìn)行聲光報警或停機(jī)操作,確保車間人員安全。具體框架如圖3所示。
2車間人員檢測方法
2.1基于空間域注意力機(jī)制的SSDSN網(wǎng)絡(luò)
空間域注意力機(jī)制是將原始圖像中的空間信息變換到另一個空間中并保留關(guān)鍵信息的一種方法,將圖像中的空間域信息進(jìn)行空間變換,把關(guān)鍵的信息提取出來,找出圖像信息中被關(guān)注的區(qū)域,同時又具有平移不變性、旋轉(zhuǎn)不變性及縮放不變性等強(qiáng)大的性能。
本文將空間域注意力機(jī)制與SSD算法結(jié)合,提高人員檢測的準(zhǔn)確率與定位能力。在SSDSN車間人員網(wǎng)絡(luò)中,空間網(wǎng)絡(luò)變換模塊使分類的準(zhǔn)確性得到提升。
SSDSN網(wǎng)絡(luò)在SSD基礎(chǔ)網(wǎng)絡(luò)的圖像輸入層即Cov1_2之后引入空間域注意力機(jī)制。此模塊共有兩個作用,其一為數(shù)據(jù)增強(qiáng),將網(wǎng)絡(luò)的注意力放在圖像中的目標(biāo)區(qū)域,并進(jìn)行縮放操作,增強(qiáng)后的圖像進(jìn)入下層網(wǎng)絡(luò)進(jìn)行特征提取;其二為根據(jù)輸入的特征圖回歸空間轉(zhuǎn)換的參數(shù),使用這個參數(shù)去生成一個采樣的網(wǎng)格,根據(jù)這個網(wǎng)格及輸入的特征圖得到經(jīng)過空間變換的特征圖,作為SSDSN網(wǎng)絡(luò)用于檢測的特征圖,加上Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2共提取了7個特征圖用于檢測,空間轉(zhuǎn)換模塊增強(qiáng)數(shù)據(jù)、采用卷積對不同的特征圖進(jìn)行提取檢測結(jié)果、將不同特征圖獲得的預(yù)測框結(jié)合起來、經(jīng)過非極大值抑制方法抑制掉一部分重疊或者不正確的框,生成最終的框集合,即檢測結(jié)果。SSDSN網(wǎng)絡(luò)結(jié)構(gòu)如上圖4所示。
2.2SSDSn網(wǎng)絡(luò)特征提取
SSDSN利用不同尺度、不同層級的特征圖進(jìn)行人員目標(biāo)框檢測,各層特征信息由上層特征信息決定,每層特征圖只負(fù)責(zé)對應(yīng)尺度的檢測,因此,對于SSDSN每層特征足夠復(fù)雜才能更精確地檢測目標(biāo)。特征圖應(yīng)具有足夠的分辨率以表達(dá)細(xì)節(jié)特征,足夠深的網(wǎng)絡(luò)提取得到更抽象特征,低層特征對應(yīng)于細(xì)節(jié)信息,高層特征對應(yīng)于抽象的語義信息。空間域注意力機(jī)制將網(wǎng)絡(luò)的注意力放在車間人員上。由于空間注意力機(jī)制對圖像所有的通道信息進(jìn)行統(tǒng)一處理,在圖像輸入層之后加入空間域注意力機(jī)制可以更充分提取圖像中的信息,每一個卷積核產(chǎn)生相應(yīng)通道信息,含有的信息量及重要程度得到提升。
SSDSN網(wǎng)絡(luò)中低層網(wǎng)絡(luò)結(jié)合VGG16的前4層及空間域注意力機(jī)制,其中空間域注意力機(jī)制中的定位網(wǎng)絡(luò)用來回歸變換參數(shù)θ,生成仿射變換系數(shù),輸入是C×H×W維的圖像,輸出是一個空間變換系數(shù)。參數(shù)θ的大小根據(jù)要學(xué)習(xí)的變換類型而定,本文中主要用到的變換類型為縮放,則是一個4維向量,然后經(jīng)過一系列全連接或卷積,再加一個回歸層,輸出空間變換參數(shù)。采樣網(wǎng)絡(luò)依據(jù)變換參數(shù)來構(gòu)建一個采樣網(wǎng)格,輸入圖像中的點經(jīng)過采樣變換生成一個采樣信號,采樣網(wǎng)絡(luò)得到的是一種映射關(guān)系T(G),利用采樣網(wǎng)格和輸入的特征圖或圖像同時作為輸入產(chǎn)生輸出,得到經(jīng)過變換之后的特征圖,即提取到圖像的關(guān)鍵信息。
SSDSN為提高低層網(wǎng)絡(luò)的語義信息、提高網(wǎng)絡(luò)的特征提取能力,對輸入圖像進(jìn)行數(shù)據(jù)增強(qiáng)。輸入為圖像,輸出為特征圖,利用注意力機(jī)制中的定位網(wǎng)絡(luò)學(xué)習(xí)到一組參數(shù)θ,這組參數(shù)作為采樣網(wǎng)絡(luò)的參數(shù),生成采樣信號,采樣信號是一個變換矩陣,與原始圖片相乘之后,可以得到變換之后的變換矩陣,也就是變換之后的圖像特征。經(jīng)以上操作,目標(biāo)區(qū)域得到縮放,目標(biāo)區(qū)域得到關(guān)注。坐標(biāo)矩陣變換關(guān)系如下式所示:
θ矩陣就是對應(yīng)的采樣矩陣,是一個可以微分的矩陣,每一個目標(biāo)點的信息是所有源點信息的一個線性組合。
圖像基本的三通道或經(jīng)過卷積層之后,不同卷積核都會產(chǎn)生不同的通道信息,目標(biāo)圖像在原圖像上采樣,每次從原圖像的不同坐標(biāo)上采集像素到目標(biāo)圖像上,把目標(biāo)圖像貼滿,每次目標(biāo)圖像的坐標(biāo)都遍歷一遍,是固定的,而采集的原圖像的坐標(biāo)是不固定的,因此可提取出關(guān)鍵信息。
SSDSN主要利用低層細(xì)節(jié)特征檢測小占比目標(biāo),高層抽象特征檢測中等占比目標(biāo)和大目標(biāo)。用于車間人員檢測的低層卷積層為空間域注意力機(jī)制中的子網(wǎng)絡(luò)和Conv4_3,空間域注意力機(jī)制中的定位網(wǎng)絡(luò)增強(qiáng)了特征表達(dá)能力,注重細(xì)節(jié)信息,提取的語義信息更加充分,低層網(wǎng)絡(luò)特征提取能力更強(qiáng),對小目標(biāo)提取有較大提升。高層卷積層包含5層,網(wǎng)絡(luò)更加關(guān)注于目標(biāo)區(qū)域,特征提取更加充分、準(zhǔn)確,特征信息經(jīng)過卷積、池化等操作生成最終的檢測結(jié)果,檢測的準(zhǔn)確率得到較大提升。
3實驗結(jié)果及對比分析
3.1實驗環(huán)境及應(yīng)用案例
硬件環(huán)境:1臺服務(wù)器,配置為3T硬盤,128G物理內(nèi)存,第六代Intel處理器。顯卡為RTX 2080Ti,顯卡驅(qū)動為Nvidia-410。
軟件環(huán)境:操作系統(tǒng)為Ubuntu16.04,CUDA 10.0,cuDNN10.0,Opencv 3.3.1,python 2.7,MySQL5.7。
某生產(chǎn)車間,工人作業(yè)時,易發(fā)生人員傷亡事故且受煙霧、粉塵光照等噪聲影響,人員檢測受到較大干擾。應(yīng)用本文提出的基于空間域注意力機(jī)制的車間人員檢測方法驗證本文提出方法的性能。
3.2實驗數(shù)據(jù)
本文數(shù)據(jù)集由兩部分組成,98%的數(shù)據(jù)集來自某生產(chǎn)車間內(nèi)的監(jiān)控視頻,大小為70GB,視頻格式為MP4。其中50G視頻被裁剪成像素為1080×720的圖片,選取具有車間人員的圖片數(shù)量為30138張,背景圖片數(shù)量為18975張,用于SSDSN車間人員檢測網(wǎng)絡(luò)模型的訓(xùn)練,其余20G視頻作為測試集;2%數(shù)據(jù)集來自Pascal VOC2012中的圖片,Pascal VOC2012是目標(biāo)檢測、圖像分割網(wǎng)絡(luò)對比試驗與模型評估中的基準(zhǔn)數(shù)據(jù)之一,為公開數(shù)據(jù)集,被廣泛使用。其中圖片中有人的圖片數(shù)量為2000張,用于SSDSN車間人員檢測模型的訓(xùn)練,增大訓(xùn)練集豐富性,防止訓(xùn)練過程中出現(xiàn)過擬合。
3.3車間人員檢測對比試驗
3.3.1各算法在VOC2012數(shù)據(jù)集上的比較
本文使用VOC2012數(shù)據(jù)集和車間圖片數(shù)據(jù)集對各類目標(biāo)檢測算法及本文提出的算法進(jìn)行車間人員檢測,對各類目標(biāo)檢測網(wǎng)絡(luò)使用相同訓(xùn)練集做訓(xùn)練。
將VOC2012數(shù)據(jù)集分為訓(xùn)練集和測試集,分別用于網(wǎng)絡(luò)訓(xùn)練和得到測試結(jié)果。Faster R-CNN[6]、SSD[8]、YOLOV2[18]、YOLOV3[7]、Mask RCNN[22]、YOLOV5[21]及本文算法,使用VOC2012訓(xùn)練集訓(xùn)練,找出各網(wǎng)絡(luò)生成的最優(yōu)模型,驗證算法準(zhǔn)確率與召回率。結(jié)果如表1所示,在VOC2012測試集上本文算法的準(zhǔn)確率和召回率較其它算法有所提升,以及采用FPS(frames per second),即畫面每秒傳輸幀數(shù)評估模型的檢測速率,來進(jìn)行速度對比。
3.3.2各算法在車間數(shù)據(jù)集上的比較
選取車間內(nèi)不同位置的攝像頭進(jìn)行分場景測試,測試時長為8 h,期間車間人員正常通行。檢測的幀圖片總數(shù)為3456000張,其中約2160000張圖片為車間人員圖片,剩余1296000張圖片均為背景圖片。測試本文算法的效果,結(jié)果如表2所示,數(shù)據(jù)統(tǒng)計由數(shù)據(jù)庫中的幀圖像計數(shù)得到。
由表2分析得到,本文算法的平均準(zhǔn)確率為準(zhǔn)確率取平均值,計算得平均準(zhǔn)確率為95.0%,其平均召回率為召回率取平均值,計算得平均召回率為93.1%,據(jù)計算本文算法的平均誤檢率較低,約為3.3%,但存在漏檢情況,平均漏檢率約為5.5%,本算法已經(jīng)具備了較強(qiáng)的車間人員檢測能力。
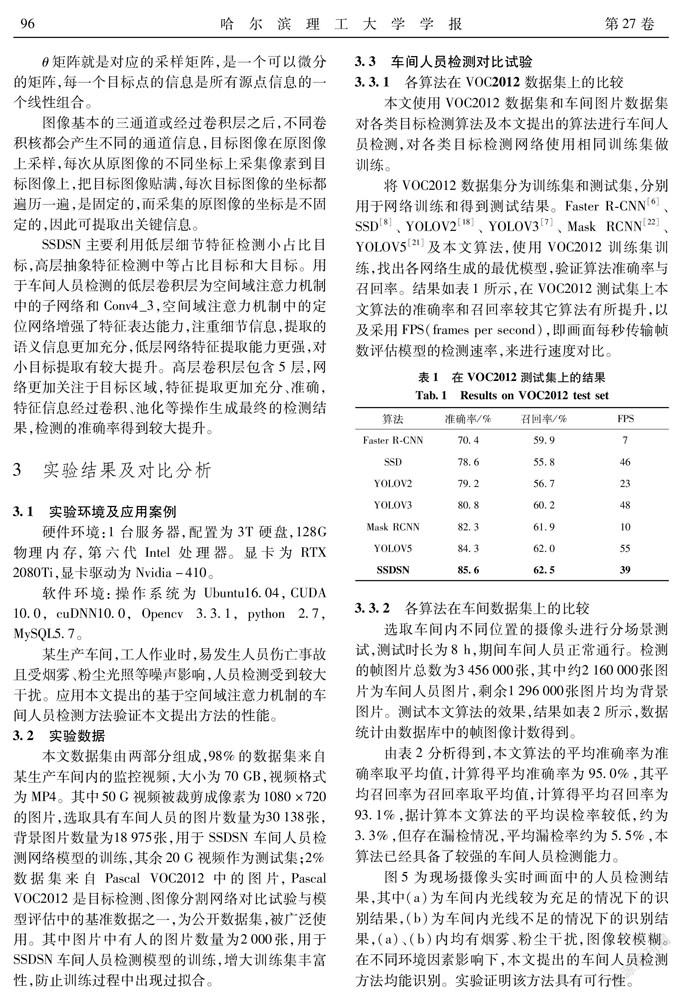
圖5為現(xiàn)場攝像頭實時畫面中的人員檢測結(jié)果,其中(a)為車間內(nèi)光線較為充足的情況下的識別結(jié)果,(b)為車間內(nèi)光線不足的情況下的識別結(jié)果,(a)、(b)內(nèi)均有煙霧、粉塵干擾,圖像較模糊。在不同環(huán)境因素影響下,本文提出的車間人員檢測方法均能識別。實驗證明該方法具有可行性。
各算法使用車間視頻切分的幀圖片作為訓(xùn)練集,準(zhǔn)確率與召回率如表3所示。由于各算法的此時的檢測類別都為車間人員,其它均視為背景,且訓(xùn)練集經(jīng)過降噪處理,此時各算法準(zhǔn)確率均有所提高。但由于車間的環(huán)境因素,車間內(nèi)可見度較低,檢測過程中存在大量目標(biāo)漏檢、誤檢,F(xiàn)aster R-CNN、
SSD、YOLOV2、YOLOV3、Mask RCNN、YOLOV5等算法準(zhǔn)確率變化不大。本文算法由于使用圖像降噪策略及空間域注意力機(jī)制,降低了車間人員檢測在煙霧、粉塵等環(huán)境下的干擾因素,噪聲對車間人員檢測過程中的影響近乎消失,同時,由于SSDSN網(wǎng)絡(luò)低層語義的增強(qiáng),使其具有對小目標(biāo)識別的能力,漏檢、誤檢也大大降低,故本文算法檢測準(zhǔn)確率提升較大,召回率較高。
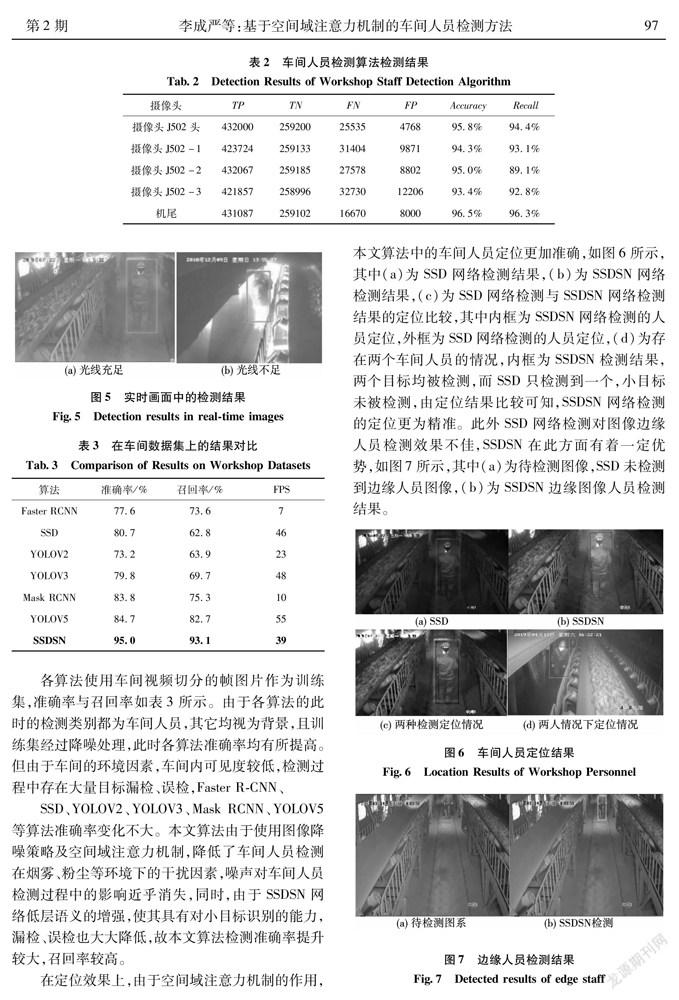
在定位效果上,由于空間域注意力機(jī)制的作用,本文算法中的車間人員定位更加準(zhǔn)確,如圖6所示,其中(a)為SSD網(wǎng)絡(luò)檢測結(jié)果,(b)為SSDSN網(wǎng)絡(luò)檢測結(jié)果,(c)為SSD網(wǎng)絡(luò)檢測與SSDSN網(wǎng)絡(luò)檢測結(jié)果的定位比較,其中內(nèi)框為SSDSN網(wǎng)絡(luò)檢測的人員定位,外框為SSD網(wǎng)絡(luò)檢測的人員定位,(d)為存在兩個車間人員的情況,內(nèi)框為SSDSN檢測結(jié)果,兩個目標(biāo)均被檢測,而SSD只檢測到一個,小目標(biāo)未被檢測,由定位結(jié)果比較可知,SSDSN網(wǎng)絡(luò)檢測的定位更為精準(zhǔn)。此外SSD網(wǎng)絡(luò)檢測對圖像邊緣人員檢測效果不佳,SSDSN在此方面有著一定優(yōu)勢,如圖7所示,其中(a)為待檢測圖像,SSD未檢測到邊緣人員圖像,(b)為SSDSN邊緣圖像人員檢測結(jié)果。
4結(jié)論
本文使用深度學(xué)習(xí)方法來解決車間安全監(jiān)測問題,提出基于空間域注意力機(jī)制的車間人員檢測方法。SSDSN車間人員檢測網(wǎng)絡(luò)保障了車間人員檢測的實時性,為提高檢測準(zhǔn)確率和召回率,改進(jìn)暗通道優(yōu)先處理策略,降低車間內(nèi)煙霧、粉塵、光照等因素對檢測的影響。用區(qū)域劃分方法解決車間區(qū)域復(fù)雜問題,實際應(yīng)用證明,本文算法檢測網(wǎng)絡(luò)準(zhǔn)確率較高,為車間安全管理提供支持,具有廣泛的應(yīng)用前景。下一步將考慮檢測過程中目標(biāo)遮擋問題。
參 考 文 獻(xiàn):
[1]VIOLA P, JONES M J. Robust Real-Time Face Detection[J]. International Journal of Computer Vision, 2004, 57(2):137.
[2]DALAL N, TRIGGS B, SCHMID C. Human Detection Using Oriented Histograms of Flow and Appearance[C]// European Conference on Computer Vision. 2006:428.
[3]FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D. Cascade Object Detection with Deformable Part Models[C]// 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2010: 328.
[4]HINTON G E, OSINDERO S, TEH Y W. A Fast Learning Algorithm for Deep Belief Nets[J]. Neural Computation, 2014, 18(7):1527.
[5]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580.
[6]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(6): 1137.
[7]PANG L, LIU H, CHEN Y, et al. Real-time Concealed Object Detection from Passive Millimeter Wave Images Based on the YOLOv3 Algorithm[J]. Sensors, 2020, 20(6):1678.
[8]SUN X, WU P, HOI S. Face Detection Using Deep Learning: An Improved Faster RCNN Approach[J]. Neurocomputing, 2018, 299(19):42.
[9]CHANG T, HSIEH J W, CHANG T C, et al. EMT: Elegantly Measured Tanner for Key-Value Store on SSD[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2021(99):1.
[10]陳晉音, 王楨, 鄭海斌. 基于深度學(xué)習(xí)模型的非法流動攤販檢測方法研究[J]. 小型微型計算機(jī)系統(tǒng), 2019, 40(7):72.CHEN Jinyin, WANG Zhen, ZHENG Haibin. Research on Detection Method of Illegal Mobile Vendors Based on Deep Learning Model[J]. Mini Computer System, 2019, 40(7): 72.
[11]曹詩雨, 劉躍虎, 李辛昭. 基于Fast R-CNN的車輛目標(biāo)檢測[J]. 中國圖象圖形學(xué)報. 2017,80(5):56.CAO Shiyu, LIU Yuehu, LI Xinzhao. Vehicle Target Detection Based on Fast R-cnn [J]. Chinese Journal of Image and Graphics, 2017,80 (5): 56.
[12]劉丹,馬同偉.結(jié)合語義信息的行人檢測方法[J].電子測量與儀器學(xué)報.2019,33(1):54.LIU Dan, MA Tongwei. Pedestrian Detection Method Combined with Semantic Information[J]. Journal of Electronic Measurement and Instrumentation,2019,33 (1): 54.
[13]HE K, JIAN S, FELLOW, et al. Single Image Haze Removal Using Dark Channel Prior[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(12):2341.
[14]儲岳中, 黃勇, 張學(xué)鋒, 等. 基于自注意力的SSD圖像目標(biāo)檢測算法[J]. 華中科技大學(xué)學(xué)報(自然科學(xué)版), 2020,453(9):75.CHU Yuezhong, HUANG Yong, ZHANG Xuefeng, et al. SSD Image Target Detection Algorithm Based on Self Attention[J]. Journal of Huazhong University of Science and Technology (NATURAL SCIENCE EDITION), 2020,453 (9): 75.
[15]李紅艷,李春庚,安居白,等.注意力機(jī)制改進(jìn)卷積神經(jīng)網(wǎng)絡(luò)的遙感圖像目標(biāo)檢測[J].中國圖象圖形學(xué)報,2019,24(8):1400.LI Hongyan, LI Chungeng, AN jubai, et al. Remote Sensing Image Target Detection Based on Improved Convolutional Neural Network with Attention Mechanism[J]. Chinese Journal of Image Graphics, 2019,24 (8): 1400.
[16]XU K, BA J, KIROS R, et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention[J]. Computer Science, 2015,37(1):2048.
[17]JADERBERG M, SIMONYAN K, ZISSERMAN A, et al. Spatial Transformer Networks[J]. 2015,25(2):156.
[18]REDMON J, FARHADI A. YOLO9000: Better,F(xiàn)aster,Stronger[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2017:6517.
[19]GAMAGE S, SAMARABANDU J. Deep Learning Methods in Network Intrusion Detection: A Survey and an Objective Comparison[J]. Journal of Network and Computer Applications, 2020, 169(2):102767.
[20]LIU Y, SUN P, WERGELES N, et al. A Survey and Performance Evaluation of Deep Learning Methods for Small Object Detection[J]. Expert Systems with Applications, 2021, 172(4):114602.
[21]LIU W, WANG Z, ZHOU B, et al. Real-time Signal Light Detection Based on Yolov5 for Railway[J]. IOP Conference Series: Earth and Environmental Science, 2021, 769(4):42.
[22]YU Y, ZHANG K, YANG L, et al. Fruit Detection for Strawberry Harvesting Robot in Non-structural Environment Based on Mask-RCNN[J]. Computers and Electronics in Agriculture, 2019, 163(10): 46.
(編輯:王萍)
