基于BP神經網絡的語音情感識別系統分析與設計
2022-05-30 15:43:24鄔卓恒趙嘉熙時小芳
電腦知識與技術 2022年10期
鄔卓恒 趙嘉熙 時小芳







摘要:語音情感識別是人工智能的重要研究領域之一。文章基于神經網絡算法分析與設計語音情感識別系統。系統分為前端和后端兩個模塊:前端部署在移動終端上,實現接收語音,上傳語音文件,顯示識別結果等功能;后端部署在服務器上,實現語音降噪、特征提取、語音情感模型訓練、情感識別、個人語音庫創建等功能。
關鍵詞:語音情感識別;BP神經網絡;個人語音庫
中圖分類號:TP181? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)10-0076-04
通常意義上的語音識別是指機器自動的識別語音的文本信息。語音的文本含義識別技術出現較早,1952年開發出簡單的語音識別數字系統,從此正式開啟了語音識別的進程。語音情感識別也是語音識別的重要部分。語音情感識別領域是一項綜合性的研究領域,包括生物技術、心理認知、腦科學、統計學、計算機科學等學科。情感可以通過孤立的跳躍式、離散的數據描述,也可以采用二維、三維或多維空間的連續值數據描述。本文設計的情感識別系統采用離散描述的情感模型,即將人類的情感分為6類:悲傷(Sa) 、害怕(F) 、驚奇(Su) 、生氣(A) 、高興(J) 和討厭(D) [1]。語音以波的形式在介質中傳播,在計算機處理語音信息要進行采樣、連量、編碼后存儲使用。識別語音中包含人的情感,需要提取聲音的特征。聲音的提取特征方式較多,本系統采用MFCC[2-3]作為語音情感識別的特征。在語音情感識別技術發展的過程中出現了很多算法,其中傳統的機器學習算法、深度學習算法應用較為廣泛。系統使用BP神經網絡算法訓練語音情感模型,刻畫語音特征與情感的關系。
1 需求分析
語音情感識別系統包括兩個主要功能:識別用戶上傳的語音的情感、建立并不斷優化情感識別模型。用戶和管理員是語音識別系統的兩類參與者。用戶使用的核心功能是通過移動終端的客戶端發送語音,等待系統反饋,系統識別說話人聲音中包含的情感狀態。
管理員需要創建并維護公共語音數據庫、調用訓練算法、建立用戶個人語音庫、訓練用戶個人情感識別模型。在系統運行的早期,語音識別系統使用的語音數據特征是從公開數據庫中獲得,并使用公開語音數據庫中的數據訓練語音識別模型。系統運行一段時間后,積累一部分用戶語音數據,系統將新增加數據與公共數據聯合訓練模型,提升模型識別的準確率。系統運行較長一段時間后,積累大量的用戶語音數據,為用戶建立用戶個人語音庫。系統建立個人語音數據庫并訓練模型,該模型為該用戶服務,能提升用戶情感識別的準確度。
2 語音情感識別系統框架
語音情感系統分為兩部分如圖1語音情感識別系統框架圖所示:第一部分為前端,使用App安裝在用戶的移動終端中。第二部分為后端,以Web的形式部署在服務器上鏈接公共聲音數據庫和用戶聲音個人數據庫。兩部通過網絡進行鏈接。前端的主要功能是錄音、播放、上傳、顯示情感狀態、反饋識別正確程度。后端主要功能有三部分:語音情感模型的訓練、語音狀態的識別、用戶個人語音數據庫的構建。
3 語音情感識別系統概要設計
語音情感識別系統結構如圖2所示。后端模塊中三個模塊為語音情感識別模型訓練模塊、語音情感識別模塊、用戶個人語音數據庫構建模塊。其中情感識別模型訓練模塊、語音情感識別模塊是系統的核心內容。這兩個模塊共同調用預處理模塊,語音在產生和傳播的過程中會混入噪音,在語音進行降噪后提取語音中的特征。進行模型訓練時,將每段語音的特征值作為BP神經網絡的輸入[X]向量,語音的6種離散情感值作為[Y]值訓練模型。在訓練模型時,會用到大量語音數據,將語音數據進行批量的預處理,將預處理后的數據存儲在數據庫中,訓練時,可以從數據庫中直接讀取特征值和標簽。語音情感識別模塊是從前端接收語音數據后,進行語音預處理得到語音特征,將語音特征帶入模型,識別出語音的語音狀態,然后將結果發送給用戶。用戶收到結果后將做出判斷,并給出自己認為的情感狀態,模塊將使用用戶的語音信息和結果寫入用戶個人語音數據庫中。
系統的核心業務流程有兩個:第一是語音情感識別模型創建,語音情感識別模型是系統的核心基礎,系統識別的準確率取決于情感識別模型,語音情感模型創建的流程如圖3所示。第二是用戶情感識別,情感識別是系統的重要應用。用戶語音情感識別流程如圖4所示。
語音情感模型創建,首先選取公共語音數據庫,選取公共數據庫要注意兩點:第一根據軟件使用的用戶人群,確定語種。要選取同語種的公共數據庫。也可根據軟件使用的區域不同,選擇不同的公共數據庫。第二,情感模型可以是連續描述也可以是離散描述。每種描述又有多種類型。要根據系統情感模型選擇合適的數據庫。本系統采用離散情感標注的中文語音公共數據作為模型訓練源。
從數據庫中提取數據進行一系列處理后得到每段語音數據的特征和標簽。將這些特征和標簽存入數據庫。將所有語音特征劃分成兩部分,一部分語音的特征訓練模型,另外一部分語音的特征測試模型。數據集的劃分方法根據你數據量的大小來確定。若有海量語音數據,取2000~10000條數據作為測試集即可,每個數據集中不同標簽的樣本要均等出現。若數據量較少,可以采用7∶3的比例劃分或采用交叉方法選擇[4]。
確定初始參數后,啟動神經網絡算法。經過多次迭代算法收斂或大于最大迭代次數后,得到初步的情感識別模型。將測試集的語音特征和標簽數據帶入情感識別模型驗證準確率。假設訓練集的準確率為[p1],測試集的準確率為[p2]。此時會出現兩種情況需要調整參數,第一若[p1]大于標準且[p1>p2],表明模型過度地刻畫了語音特征和情感之間的關系,該模型實際應用能力較差。第二若[p1]不達標準,該模型識別情感狀態能力較弱,為欠擬合現象。可以根據不同的現象調整參數再次訓練模型。直到滿足準確率的要求,將模型存儲到數據庫,供用戶情感數據識別使用。
若在實際應用中模型效果較好,可以用該模型支持系統運行,直到更新大量語音數據。若應用效果較差,可以調整訓練集和優化模型訓練算法再次訓練模型。
用戶通過智能終端的App提交語音,在服務器上識別語音狀態,將結果通過網絡傳輸到App。用戶收到結果后,可以為此次判斷評價。若識別正確,則點擊確定,若識別錯誤,用戶提交情感狀態。
用戶上傳的數據是在非絕對安靜情況下的錄音,所以語音的降噪處理十分重要。降噪處理后,提取語音特征。將特征作為輸入項帶入情感識別,得到識別結果。系統將此條語音數據和其包含的狀態存入用戶個人語音庫,以待以后使用。當用戶個人語音庫積累到一定數量后就可以訓練語音情感識別模型,此模型將用于該用戶的語音情感識別。
4 語音情感識別系統詳細設計
4.1 語音預處理
語音數據預處理是系統的重要模塊,該模塊會被語音情感識別模型訓練模塊和用戶語音情感識別模塊調用。它很大程度上影響系統情感識別的準確性。在本系統中該模塊有兩部分:語音降噪和特征處理。
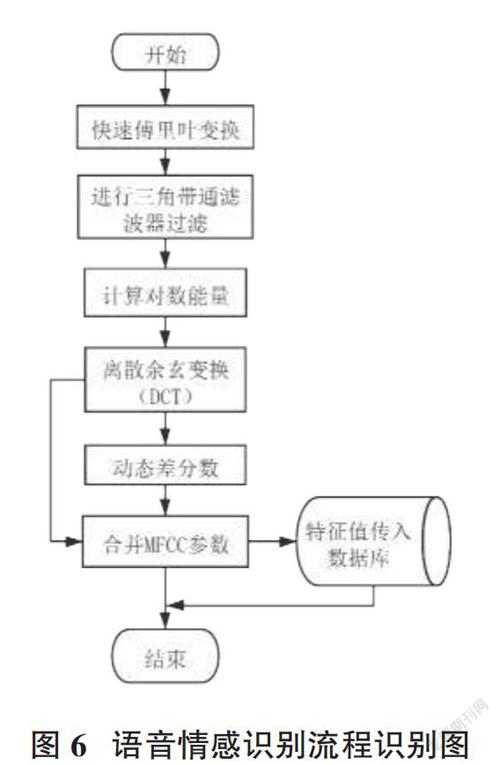
系統語音降噪過程如圖5所示。該部分包括四步,原始的語音信號通過這四步的處理后才能準確地提取語音特征。語音數據以.wav文件輸入,從文件中讀出數據按照圖6的順序執行,最后得到一個[N×M]二維數組,其中[N]為幀的個數,[M]為每個幀的采點的個數,該數組可以作為下一步特征提取的輸入。
人的聲音并不是在錄音的開始的0時刻出現的,人說話也不是連續不斷的,中間會有停頓。端點檢測的主要目的是識別一段語音中,人聲的出現和結束位置。可以根據端點檢測出來的開始點和結束點截取語音,提升聲音特征提取的準確性,可以采用基于閾值的方法檢測端點,低于閾值是沒有聲音,高于閾值是有聲音。
聲音產生后,在傳輸的過程中經過人的口腔和嘴唇,這兩部分對聲音產生輻射阻抗。通過預加重,降低人體這兩部分對語音信號的影響[5-6]。預加重,就是對聲音信號進行濾波處理。濾波器的傳遞函數為[H(z)=1-μz-1],其中[μ∈0.9,1.0]。聲音經過濾波后的公式為:[ft=x(t)-μ(t-1)]其中[μ]是經驗值,取0.98。
語音是隨時間變化的連續量,但是在短時間內(毫秒級) 語音的特征不會改變。為了后面的處理方便,將語音按照15ms為單元進行分割,15ms內這一段稱為一個幀。為了讓聲音更平滑,幀與幀之間要重疊一部,這部分被稱之為幀移。假設有一段語音它時間為[T=50ms],每幀的時間間隔為[t=15ms],幀移大小[l=5ms]該段語音將會被分為5份。
將每幀數據分別進行處理時,由于幀時截取的進行傅里葉變換時會出現大量空白,造成能量泄露。通過加窗處理可以改善這種缺點,窗的種類很多,選擇不同窗也帶來不同處理的結果。最常使用的就是漢明窗[6-7],其公式如下:
[w(n)=0.54-0.46cos2πn/N-1,0≤n≤N0,其他]? ? ? ? ? ?(1)
將一段語音進行降噪處理,獲得[N×M]二維數組后,將此二維數組為基礎進行語音特征的提取,具體過程如圖6所示,若此段語音不是用戶識別語音,需要將得到的二維特征數組存入數據庫,以備語音情感識別模型訓練算法的使用。此部分用到的方法都是庫函數,按照流程圖的順序進行調用。
4.2 語音情感識別模型訓練與應用
本系統選用BP神經網絡[8-10]作為模型訓練算法,它通過訓練集和測試集數據訓練模型,在算法收斂后,固定各個神經元之間的權值即可得到語音情感識別模型。要輸入的一段語音的特征值與標簽用[(X,Y)]二元組表示,其中[X]是一個[N×M]的二維數組,[N]表示這段語音的幀的個數,[M]表示特征個數,該神經網絡的輸入層節點個數為[N×M]。例如一段語音特征值提取為[125×39]的二維數組,那么需要4875個輸入節點。通常而言,語音的特征值是一個很大的二維數組,所以輸入節點個數較多。
隱藏層的節點個數通過參數確定。系統選用六個離散數值描述情感,選用[{0,1,2,3,4,5}]表示6種情感狀態,所以該神經網絡輸出層需要6個節點。
訓練流程如圖7所示。首先從數據庫中提取語音特征值與標簽。將其分成兩部分:訓練集、測試集,六種情感的語音特征數據要等比例存在每個數據集中。然后配置神經網絡的初始參數,參數包括訓練的最大迭代次數、隱藏節點數、最低準確率、兩個學習率。初始參數根據算法應用的領域及數據集的特點確定,是經驗數值。當算法收斂到一個正確率或超過最大迭代次數時我們終止訓練,得到初始的語音情感識別模型。如果模型在訓練集和測試集的識別正確率低于要求數值,調節參數繼續訓練。如果模型識別正確率符合要求,就將該模型保存在數據庫中,以備識別使用。
用戶的語音情感識別過程是模型訓練過程的簡化版本。用戶上傳語音文件后進行標準化和降噪處理,然后提出特征值得到一個[N×M]的二維數組,該二維數組是語音情感識別模型的輸入值。從數據庫中取出該模型各個節點的權重值,運行模型將特征值輸入語音情感識別模型即可得到該段語音中包含的情感狀態,然后顯示到用戶的App上。
4.3 個人語音庫
個人語音庫是系統拓展模塊,主要收集用戶的個人語音數據。語音情感識別應用領域問題之一是模型訓練數據和模型使用的數據不一致。語音和情感是極具個人特色和地域特色,識別語音中包含的情感也極具個人和地域特色。系統識別的每段語音都是訓練數據集的積累。系統早期使用公共數據庫訓練模型,系統后期可根據用戶的個人語音庫訓練模型。也可以根據用戶的地域不同將個人語音數據庫合并成地域語音庫,使用該數據庫訓練的模型應用到該地域用戶的初始情感識別。
語音庫的建立過程:系統將用戶長傳的語音識別出來后顯示給用戶。用戶可以根據識別出的狀態做出自己的判斷,若正確就點擊確定,若錯誤就從6個情感狀態中選擇一個點擊確定。系統根據用戶的反饋,系統可以評價模型在現實應用中的識別正確率,然后將用戶的語音數據和標簽傳入用戶專屬的語音庫中,以備以后使用。
5 總結與展望
本系統采用離散數據描述情感,使用MFCC特征簡化語音信息,并使用BP神經網絡訓練情感識別模型,建立個人語音庫。語音包含文本信息和情感信息,情感是一個很復雜的感念,現在可以通過離散的數據或連續的數據描述情感。但是人是一個復雜的情感載體,一段語音中情感可能是多種情感狀態疊加的,單純地做離散描述不能真實地反映人的感受,若使用離散描述,可以在一段語音中劃分出主次情感。連續的描述方式更能體現情感的變化的規律,但是現在并沒有一套實用的連續描述規則。
本系統采用了一個經典算法,做成獨立模塊。系統更新算法時,可以直接替代該模塊。情感在哪些語音特征中被表征出來并沒有正確的理論認識,現在特征的選取主要依賴于經驗。情感和特征的關系是情感識別研究領域一個重要的方向。
語音情感識別沒有語音文本識別發展迅速,但是語音情感識別是人工智能發展中不可替代的一環,其應用領域也十分廣泛,比如居家養老、情感陪護、機器人語音交互、娛樂、刑偵、醫療等。
參考文獻:
[1] Grimm M, Kroschel K. Evaluation of natural emotions using self assessment manikins. In: Proc. of the 2005 ASRU. Cancun, 2005: 381?385.
[2] Barpanda S S,Majhi B,Sa P K,et al.Iris feature extraction through wavelet mel-frequency cepstrum coefficients[J].Optics & Laser Technology,2019,110:13-23.
[3] 韓文靜,李海峰,阮華斌,等.語音情感識別研究進展綜述[J].軟件學報,2014,25(1):37-50.
[4] 朱龍珠,盛妍,劉鯤鵬.基于深度學習的海量語音數據識別及分類方法研究[J].電子設計工程,2021,29(9):116-120.
[5] 孫曉虎,李洪均.語音情感識別綜述[J].計算機工程與應用,2020,56(11):1-9.
[6] 詹永照,曹鵬.語音情感特征提取和識別的研究與實現[J].江蘇大學學報(自然科學版),2005,26(1):72-75.
[7] 高慶吉,趙志華,徐達,等.語音情感識別研究綜述[J].智能系統學報,2020,15(1):1-13.
[8] 陳闖,Ryad Chellali,邢尹.改進遺傳算法優化BP神經網絡的語音情感識別[J].計算機應用研究,2019,36(2):344-346,361.
[9] Sadeghi B H M.A BP-neural network predictor model for plastic injection molding process[J].Journal of Materials Processing Technology,2000,103(3):411-416.
[10] 余華,黃程韋,金赟,等.基于粒子群優化神經網絡的語音情感識別[J].數據采集與處理,2011,26(1):57-62.
【通聯編輯:梁書】
收稿日期:2021-12-19
基金項目:本篇文章受項目支持,廣東理工學院科技項目:項目名稱:基于深度學習的語音情感識別技術研究(項目編號2019GKJZK017) ;廣東理工學院教育教學改革 ,應用型本科高校混合式教學模式探索——以“Java 程序設計”為例(項目編號:JXGG202056)
作者簡介:鄔卓恒(1993—) ,男,山東曹縣人,計算機應用技術碩士,廣東理工學院講師,CCF專業會員,會員編號62368M,研究方向為機器學習、數據安全;趙嘉熙(2001—) ,男,本科生,CCF學生會員NO.I7960G,研究方向為信息安全,圖像識別,深度學習;時小芳(1991—) ,碩士研究生,河南濮陽人,廣東理工學院講師,主要研究方向軟件測試、大數據、商務智能等。
