基于詞匯特征與語法模式的漢語二語寫作質量動態發展研究
2022-06-06 13:24:46王浩學程勇胡曉清
華文教學與研究 2022年2期
王浩學 程勇 胡曉清


[關鍵詞] 寫作質量;詞匯多樣性;詞匯復雜性;語法多樣性;語法復雜性;語料庫
[摘? 要] 本研究以韓國在華學習者漢語中介語語料庫3個年級596名學生共6789條有效作文語料為研究對象,以詞匯特征及語法模式為測量指標考察韓國學習者漢語作文水平的動態變化。詞匯特征指標包含詞匯多樣性、詞匯復雜性兩個維度,共8個指標;語法模式指標包含語法多樣性、語法復雜性兩個維度,共12個指標。本文創新性地將《國際漢語教學通用課程大綱》(修訂版)248條各級語法模式轉化為正則表達式,使用SPSS等軟件對作文語料進行大規模精細考察與分析。研究結果表明,詞匯特征指標中,詞匯多樣性2(詞種數)及詞匯復雜性2(高級詞種數)與年級分布具有最高的相關性。語法模式指標中,語法多樣性2(語法項種數)和語法復雜性2(高級語法項種數)與年級分布具有最高的相關性。本文進一步分析了詞匯與語法各指標的相關關系,討論了詞匯緊密性與語法松散性的特征及修辭化表達對指標的影響,并對未來漢語二語詞匯及語法教學提出反思和建議。
[中圖分類號]H195.3? [文獻標識碼]A? [文章編號]1674-8174(2022)02-0020-12
1. 引言
近年來,對于漢語二語寫作質量的語言特征定量研究逐漸引起了學者的重視。作文語言特征的考察指標主要可以分為詞匯類指標和句法類指標。在詞匯類指標方面,常用的測量方式有詞匯豐富度(lexical richness,LR)、詞匯密度(lexical density,LD)、詞匯復雜度(lexical sophistication,LS)、詞匯獨特性(lexical originality,LO)、詞匯多樣性(lexical variation,LV)、詞匯正確性(lexical accuracy,LA)等。吳繼峰(2016)發現詞匯變化性、詞匯復雜性、詞匯密度、詞匯錯誤率四個自變量構成的組合能解釋英語母語者二語漢語寫作成績總變異的46.2%。王藝璇(2017)發現詞種數、詞匯錯誤比重和常用詞數三個參項可以解釋作文成績92.8%的變異。張娟娟(2019)發現,詞匯豐富性可以解釋漢語二語作文成績71.4%的變異。在句法類指標層面,Jiang(2013)考察了T單位長度、無誤T單位長度和無誤T單位百分比三個指標測量英語母語者漢語二語寫作水平的效度,發現只有無誤T單位百分比可以有效區分出不同漢語水平。吳繼峰(2016)發現T單位數量、T單位長度、T單位分句數和話題鏈長度不是測量英語母語者漢語二語寫作句法復雜性發展的有效指標,而話題鏈數量、話題鏈分句數和零形成分數量才是有效指標,吳繼峰(2019)進一步對韓語母語者的研究表明,話題鏈數量、話題鏈分句總數、零形成分數量、T單位長度等4個指標既能有效區分韓國學生的漢語水平,也能有效預測其寫作質量。Yu(2020)進一步豐富了話題鏈特征,包括話題鏈單元、話題鏈、復雜話題鏈。朱慧敏(2021)回顧了句法復雜性指標的發展進程,指出“二語書面語句法復雜性測量指標研究由單純的粗粒度指標向粗細粒度指標結合的發展趨勢,且對細粒度指標的研究日益細化和深入”。吳繼峰(2021)對比了不同顆粒度的句法復雜度指標對寫作質量的關系,將話題鏈數量、話題鏈分句總數和零形成分數量作為粗粒度指標,將復雜名詞短語比率、復雜名詞短語總個數、名詞前復雜修飾語總長度作為細粒度指標,其中復雜名詞短語比率可以解釋記敘文寫作成績總變異23. 3%,名詞前復雜修飾語總長度可以解釋議論文寫作成績總變異的18. 8%,該研究結論證明了名詞短語復雜度細粒度指標是預測記敘文和議論文寫作成績的有效指標。
以上研究均為漢語二語教學作文質量的指標優化作出了探索性貢獻,但是仍存在一些可待優化的方向:一是所研究的學生語料樣本數量有待進一步擴充,語料內容有待進一步豐富。在漢語二語教學作文質量相關研究中,往往只對少量作文樣本進行分析,且作文主題有限;二是漢語二語作文質量的歷時考察十分缺乏,漢語二語學習過程中的動態變化應當被進一步重視;三是作文質量指標有待進一步精細化、本土化、數字化。在大多數研究中,T單位、話題鏈等粗粒度指標只是從一個較為模糊的宏觀角度去分析作文質量,后來出現的細粒化指標,如短語比率等,雖較之前的粗粒度指標具有更細化的考察標準,但仍不能精細化考察漢語學習者究竟掌握了哪些具體的知識點,掌握的具體程度如何,缺乏與漢語二語語法教學具體內容的聯系。
針對上述不足,在語料選取方面,本研究以韓國在華學習者漢語中介語語料庫為語料來源。本研究充分發揮該語料庫優勢,用龐大的作文語料數量提高結論的可靠性,用年級分類的歷時性作文語料考察學生在漢語二語學習過程中的動態變化。在指標選取方面,本研究創新性地構建語法搭配模式正則代碼庫,精細化考察語法模式的多樣性與復雜性。漢語缺乏形態變化,主要語法手段是語序和虛詞。基于漢語的此種特點,漢語語法可以歸納為眾多的語法搭配模式,《國際漢語教學通用課程大綱》(修訂版)(2014,以下簡稱《大綱》)的常用漢語語法分級表將語法項進行了歸納和總結,在漢語二語教學實踐中,教學的目的正是讓學生掌握眾多具體的詞匯知識點與語法知識點并應用于交際。作文中具體語法項的精細考察具有很大意義,但大部分漢語作文質量指標研究往往忽略了對于具體知識點的考察與分析,采取較為籠統的指標,如T單位、話題鏈等,缺乏符合漢語語法特點的本土化研究指標。為了彌補此方面的空白,本研究基于《大綱》常用漢語語法分級及詞匯分級表的結構形式,利用計算機正則表達式進行轉化并構建一個語法搭配模式正則代碼庫。通過編程對作文語料中出現的語法項進行檢索統計,將學生所掌握的語法點模式進行量化分析。
2. 研究設計
2.1 研究問題
(1)“詞匯特征”和“語法模式”的測量指標有哪些?哪一些指標能夠有效反映學生的學習效果?
(2)隨著學生年級的增長,哪些指標變化幅度最大?它們與年級的相關性如何?
(3)詞匯特征各指標與語法模式各指標之間有無相關性?呈現怎樣的關系?
(4)學生對于具體難度等級的詞匯和語法的實際掌握情況如何?每一等級的詞匯和語法呈現怎樣的變化趨勢?
2.2 語料來源
本研究語料來源于“國別化漢語中介語語料庫庫群”中的“韓國在華學習者漢語中介語語料庫”(胡曉清,2018a、2018b)。該語料庫主要有以下幾大特點:語料層次分明、遞進性強,分為初級、中級、高級三個大層級;語料控制嚴,真實性強。真實性包括兩層含義,一是文字的真實性,即收錄的語料忠實原來的語言文字面貌,對收錄語料基本遵從“就錯錄錯”原則,全面反映學生實際語言表現。二是水平的真實性,即收集的語料是學習者真實語言水平的反映;語料采集具有連續性,動態性強。語料庫既可以對同學段學習者的語料做橫向跟蹤,也可以對同一學生、同一學習群體在不同學段、不同年級做縱向跟蹤。優化后的語料庫基礎數據如下表:
2.3 基于正則的語法模式庫構建及語料預處理
語法模式庫由《大綱》中的語法項轉化而成,語法項分為六個難度級別,共248條語法項。語法模式涵蓋了《大綱》中所要求漢語二語學習者掌握的基本語法知識,語法項轉化為正則代碼的示例如下:
在對所有語法項進行正則轉化后,可以劃分出生語料語法模式庫與熟語料語法模式庫。生語料語法模式庫中的語法知識不需要包含詞性信息,可直接在生語料庫中檢索,如上表中并列復句的正則表達式。熟語料語法模式庫的語法知識包含詞性信息,需要在分詞標注的語料庫中檢索,如上表中程度副詞的正則表達式。語法模式正則代碼庫將具體的語法知識進行形式化表示,可以直接追蹤某一個、某一級語法點在學習過程中的動態變化,對考察學生的學習效果具有極大意義。
在語料的預處理上,本研究采用“機注人校”方法,首先使用北京大學分詞與詞性標注工具包進行詞性標注處理,再進行人工校對與修正。人工修正的主要內容是對標注詞性差異格式的修改,使其與正則代碼庫標注規范保持一致。在生熟語料處理后,設計相關算法,將學生語料寫入相關文件,包含每條語料的姓名、年級、字數、字種數、詞數、詞種數等基礎信息,并基于《新漢語水平考試(HSK)詞匯》(修訂版,2012)及本研究所構建的語法搭配模式正則表達庫加入詞匯與語法等相關信息。根據前人研究,語料字數長度會對各指標產生較大影響。本研究首先利用SPSS 26.0軟件對字數按照3個標準差篩選數據,以減少文本長度對各指標的影響程度,最終得到3個年級共6789篇有效作文語料。之后使用SPSS軟件進行數據計算得出詞匯特征與語法模式的相關指標,并進行相關的統計分析。
2.4 測量指標及相關操作定義
2.4.1 詞匯特征指標
詞匯多樣性(lexical variation)是指文本中詞匯的使用范圍。在二語習得作文質量的相關研究中,作文總詞數和總詞種數因其操作性強、效度高在詞匯特征測量中非常多見(Lu,2012),而最常用的詞匯多樣性測量工具是類符形符比(TTR,type-token ratio),但這個指標極易受樣本長度影響,文本越長,類符形符比就會降低(Malvern等,2004:3-14)。為了彌補這個缺陷,不同學者對TTR指標進行進一步優化,Guiraud(1960)提出了RTTR(Root Type Token Ratio),利用G值計算詞匯多樣性。Carroll(1967)提出了平方根類符形符號比CTTR(Corrected Type Token Ratio),將分母轉化為兩倍形符的平方根。對數類符形符比(LogTTR,Bilogarithmic TTR)和優博指數(Uber Index)也具備較好的測量效果。Lu(2012)對比了20種詞匯多樣性測量手段,發現總詞種數和平方根TTR(總詞種數/[總詞數])是信度最高的手段,而優博指數是國內英語和漢語二語詞匯多樣性較為常用的詞匯多樣性測量手段(鮑貴, 2008; 王海華, 2012; 吳繼峰, 2016)。本文采用四種詞匯多樣性測量手段:
詞匯多樣性1 = 總詞數
詞匯多樣性2 = 總詞種數
詞匯多樣性3 (RTTR) =[總詞種數總詞數]
詞匯多樣性4 (Uber? ?index )=(log總詞數)2/(log總詞數-log總詞種數)
詞匯復雜性(leixcal sophistication,LS),用于測量“學習者言語產出中相對少見和高級詞匯所占的比例”(Read,2000:203)。《新漢語水平考試(HSK)詞匯》(修訂版,2012)將漢語二語學習者所需要掌握的詞匯依據難度水平劃分為六級,本研究基于此分級詞表,將四到六級詞匯作為高級詞匯,分析以下四個指標:
詞匯復雜性1 = 高級詞數
詞匯復雜性2 = 高級詞種數
詞匯復雜性3 = 高級詞數/詞總數
詞匯復雜性4 = 高級詞種數/詞總種數
2.4.2 語法模式指標
在語法指標的選取方面,本研究并未采用以往大量使用的粗粒度指標。典型的粗粒度指標如Hunt(1996)提出的T單位,Wolfe-Quintero K等(1998)指出比率方式對句子復雜性測量最具有效性,并建議使用其它基于T單位的子句比率等指標來衡量句法復雜性。上述粗粒度指標在漢語二語作文質量研究中較大范圍應用與發展,但此類指標具有明顯的局限性,雖然可對句法復雜性進行整體性測量,但缺乏對語言使用細節的具體考察,精度較低,對指標結果解釋較為模糊,難以與二語教學過程緊密關聯。近期具有較細顆粒度的測量指標開始涌現,測量指標逐漸精細至短語層面,Crossley (2014)、Paquot (2019)、吳繼峰(2021)等研究均表明復雜短語層面的細粒度指標在測量二語寫作質量和區分學習者語言水平上具有較好效果,但復雜短語的考察方式也過于泛化,難以精準契合漢語的語法特點,從而難以對二語教學實踐進行具體指導。本文創新性地采用基于漢語語法模式庫的細粒度指標,將語法模式指標分為語法多樣性與語法復雜性,將語法多樣性(grammatical variation)定義為文本中所使用的語法模式的范圍。語法多樣性越高,表明文本包含更多樣的語法結構,具備更豐富的語法知識。本研究中語法多樣性以具體的語法知識點的匹配數目及種數進行精細考察,該指標的匹配邏輯與詞匯指標相近,均是對具體的語言知識進行檢索與統計。前人研究中未有采用此種模式考察語法多樣性的先例,本文類比詞匯多樣性指標,將RTTR、Uber index等計算方式用于語法多樣性的考察,采用以下8種語法多樣性測量指標:
語法多樣性1 = 總語法項數
語法多樣性2 = 總語法項種數
語法多樣性3(RTTR)= 總語法項種數[總語法項數 ]
語法多樣性4(Uber index)=(log總語法項數)2/(log總語法項數-log總語法項種數)
語法多樣性5= 總語法項數/總字數
語法多樣性6= 總語法項數/總詞數
語法多樣性7= 總語法項數/總分句數
語法多樣性8= 總語法項數/總整句數
與詞匯復雜性的定義與操作類似,本文中語法復雜性(grammatical sophistication)指文本中相對少見和高級的語法項所占的比例,語法復雜性越高,表明該篇語料使用的高級語法項越多,語法知識難度更高。《新漢語水平考試(HSK)詞匯》(修訂版,2012)將漢語二學習者所需要掌握的語法項依據難度水平劃分為六級,本文將其中4-6級語法項作為高級語法模式,分析以下四個語法復雜性指標:
語法復雜性 1 = 高級語法項數
語法復雜性 2 = 高級語法項種數
語法復雜性 3 = 高級語法項數/語法項總數
語法復雜性 4 = 高級語法項種數/語法項總種數
3. 研究結果
3.1 分級詞匯與語法項歷時性描述
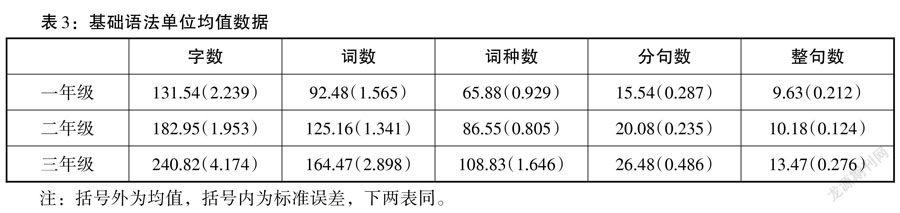
對韓國在華學習者漢語中介語語料庫進行數據預處理,得到6789條作文語料,使用SPSS 26.0進行基礎數據描述性統計,所得結果如下表:
由表3可知,五種語法單位均值均隨著年級的升高而增加,字數變化幅度最大,整句變化幅度最小。這種現象也與各級語法單位的構成大小與層級特點有關,隨著年級的升高,學生作文的字數、詞數、句數都呈增長趨勢,這也符合學生學習過程的客觀事實與規律。
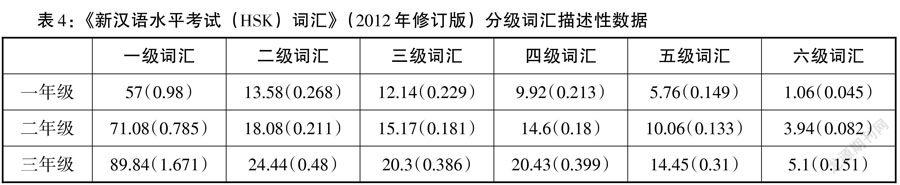
《新漢語水平考試(HSK)詞匯》(修訂版,2012)將漢語二學習者所需要掌握的詞匯依據難度水平劃分為六級,本研究基于此分級詞表,對每條語料進行檢索統計,見表4。由表格橫向對比得,在同一年級的水平下,詞匯用量總是呈現一級向六級遞減的趨勢,一級詞匯使用次數最多,六級詞匯使用最少。由表格縱向對比得,同一詞匯等級的情況中,詞匯用量總是呈現一年級到三年級遞增的趨勢,一年級使用次數最少,三年級使用次數最多。
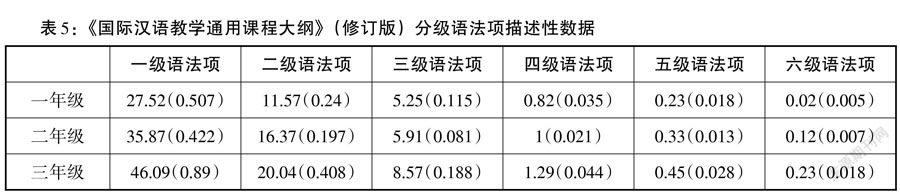
《國際漢語教學通用課程大綱》(修訂版)將漢語二語學習者所要掌握的語法項依據難度水平劃分為六級,本研究基于此分級語法項,將其轉化為形式化規則,對每條語料進行檢索統計,見表5。該表格規律與表4所示詞匯規律類似,由表格橫向對比得,在同一年級的水平下,語法項用量總是呈現一級向六級遞減的趨勢,一級語法項使用次數最多,六級語法項使用最少。由表格縱向對比得,同一語法等級的情況中,語法項用量總是呈現一年級到三年級遞增的趨勢,一年級使用次數最少,三年級使用次數最多。
3.2 詞匯特征各指標分析結果
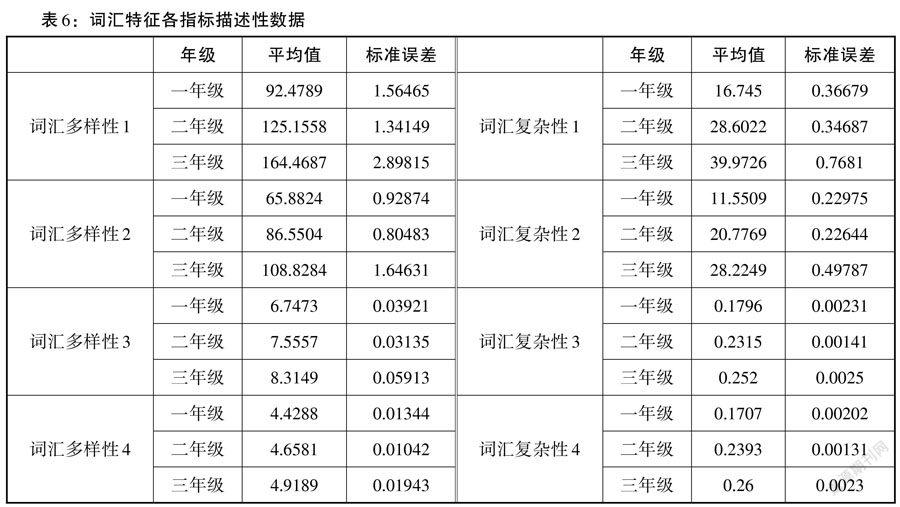
詞匯特征分為詞匯多樣性與詞匯復雜性兩個維度,各分四個測量指標,測量結果的描述性數據見表6。
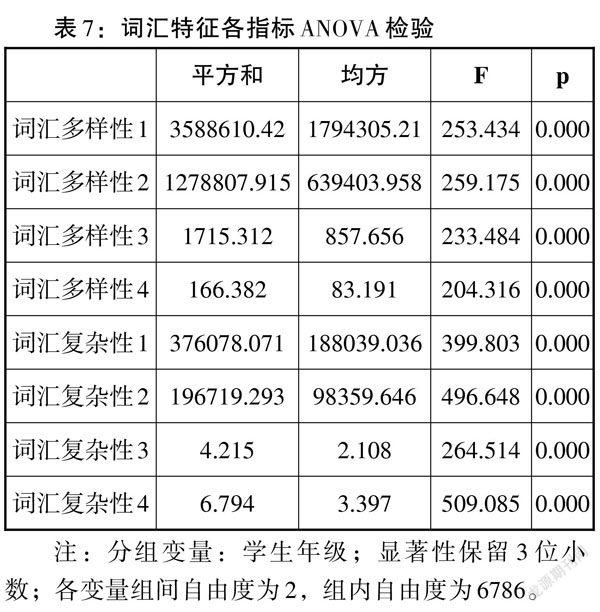
我們結合數據并利用直方圖、P-P圖、散點圖進行正態性檢驗、線性檢驗、方差齊性檢驗,結果顯示詞匯特征各指標數據接近正態分布,并滿足方差齊性,可以進行方差分析、相關分析等統計檢驗。我們將學生年級作為分組變量,將詞匯特征的8種指標的測量結果作為因變量,進行單因素方差分析、經分析得,學生的年級分布對8種指標的影響均極其顯著(p < 0.001),如表7所示。
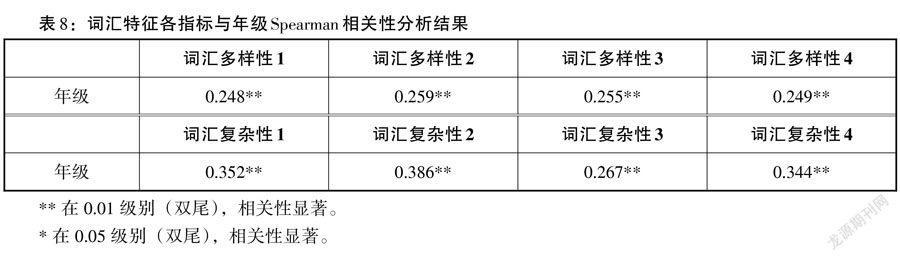
由此可見,詞匯特征的8個測量指標均能有效區分出不同年級的詞匯多樣性與復雜性情況,并且由事后多重比較的結果得,8個指標也可以顯著區分一年級與二年級、一年級與三年級、二年級與三年級的詞匯水平。在此基礎上,本研究進一步研究各指標與年級的具體相關性,詳見表8。
由Spearman相關分析得,詞匯特征8個指標與學生年級的相關性均極其顯著(p < 0.001),且均為正相關關系。在詞匯多樣性指標中,Spearman相關系數排序為0.259 > 0.255 > 0.249 > 0.248(詞匯多樣性2 > 詞匯多樣性3 > 詞匯多樣性4 > 詞匯多樣性1),詞匯多樣性2指標(總詞種數)具有最高的相關性(r = 0.259),可以作為詞匯多樣性的最優指標,四種指標系數相近且均具有極強顯著性(p < 0.001),均可作為詞匯多樣性的檢測指標。在詞匯復雜性指標中,Spearman相關系數排序為0.386 > 0.352 > 0.344 > 0.267(詞匯復雜性2 > 詞匯復雜性1 > 詞匯復雜性4 > 詞匯復雜性3),詞匯復雜性2(高級詞種數)具有最高的相關性(r = 0.386),可以作為詞匯復雜性的最優指標。
3.3 語法模式各指標分析結果
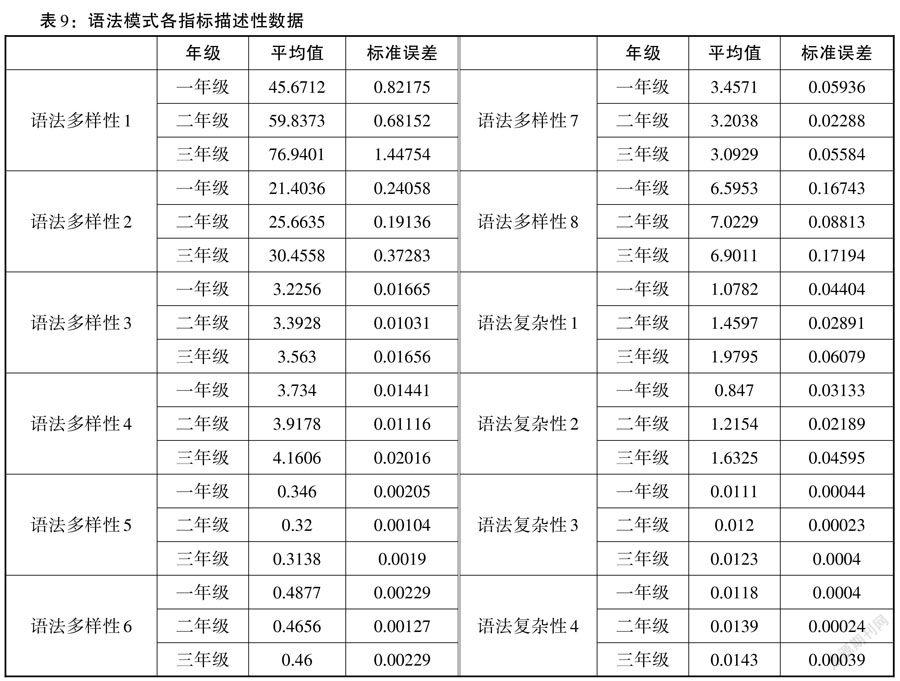
語法模式分為語法多樣性和語法復雜性兩個維度,其中語法多樣性有8個測量指標,語法復雜性有4個指標,測量結果的描述性數據如表9所示。
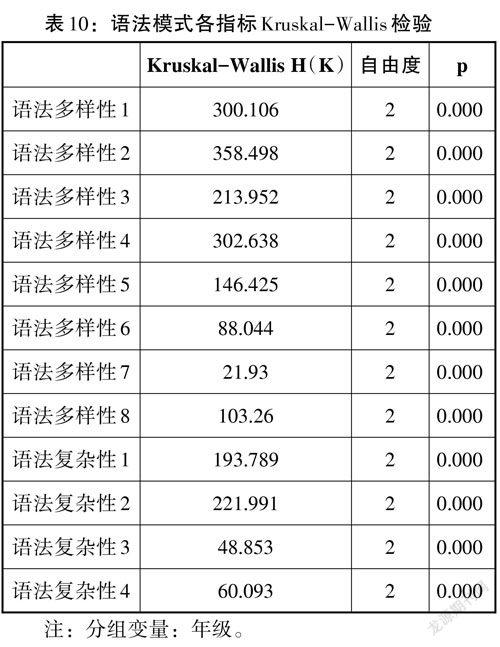
該數據不滿足方差齊性,故進行Kruskal-Wallis檢驗,以學生年級作為分組變量,語法模式的12種指標的測量結果作為因變量,經分析得,語法模式各指標在不同年級之間的差異均極其顯著(p < 0.001),如表10所示。
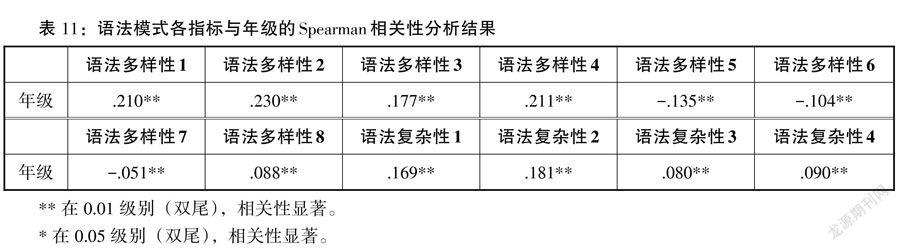
由此可見,語法特征的12個測量指標均能有效區分出不同年級的語法多樣性和復雜性情況,并且由事后多重比較的結果得,12個指標也可以顯著區分一年級與二年級、一年級與三年級、二年級與三年級的詞匯水平。在此基礎上,本研究進一步研究各指標與年級的具體相關性,見表11。
由Spearman相關分析得,語法模式的12個指標均與學生年級的相關性均極其顯著(p < 0.001)。在語法多樣性指標中,除語法多樣性5-7外,其余指標均為正相關。語法多樣性各指標Spearman相關系數排序為:0.230 > 0.211 > 0.210 > 0.177 > |-0.135| > |-0.104| > 0.088 > |-0.051|(語法多樣性2 > 語法多樣性4 > 語法多樣性1 > 語法多樣性3 > 語法多樣性5 > 語法多樣性6 > 語法多樣性8 > 語法多樣性7),各指標均與年級存在顯著相關性(p < 0.001),但Spearman相關系數差異較大,其中語法多樣性2指標(總語法項種數)具有最高的相關性(r = 0.230),可作為檢測語法多樣性的最優指標。在語法復雜性指標中,Spearman相關系數排序為0.181 > 0.169 > 0.090 > 0.080(語法復雜性2 > 語法復雜性1 > 語法復雜性4 > 語法復雜性3),語法復雜性2(高級語法項種數)具有最高的相關性(r = 0.181,p<0.001),是檢測語法復雜性的最優指標。
3.4 詞匯特征與語法模式各指標相關性分析
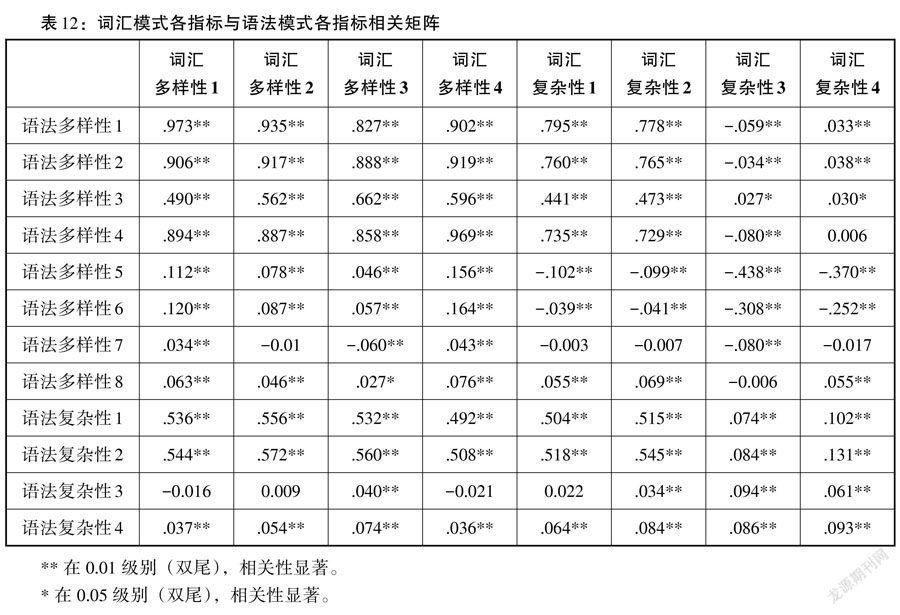
在完成詞匯特征與語法模式各指標與年級分布的歷時性分析后,本研究繼續探究詞匯特征與語法模式各指標的相關性關系。由Pearson相關系數分析得詞匯特征與語法模式各指標相關矩陣見表12。
由表可知,詞匯各指標與語法各指標絕大部分相關性顯著,極小部分相關性不顯著,如語法復雜性3分別與詞匯多樣性1,詞匯多樣性2,詞匯多樣性4,詞匯復雜性1的關系均不顯著。在顯著相關的指標中,詞匯多樣性1與語法多樣性1具有最高的相關性(r = 0.973,p < 0.001),這兩種指標均比較簡單,均以個數為計算指標,不要求限制語法單位,即一篇作文中詞匯的個數越多,語法項數目也出現的越多。這種情況符合我們對于語言習得的普遍認知。詞匯各指標與語法各指標大部分呈正相關,小部分呈負相關。負相關大多出現在詞匯復雜性與語法多樣性指標的相關關系中,出現這種現象的原因,我們將在后文展開討論。
4. 討論與分析
4.1 詞匯特征與語法模式的有效指標
通過前文對詞匯特征及語法模式共20個指標的分析,我們可以得出以下結論:在詞匯特征方面,詞匯多樣性與詞匯復雜性的所有指標與年級的相關性均極其顯著。在詞匯多樣性指標中,詞匯多樣性2(總詞種數)與年級具有最高的相關性(r = 0.259);在詞匯復雜性指標中,詞匯復雜性2(高級詞種數)與年級具有最高的相關性(r = 0.386)。在語法模式方面,語法多樣性與語法復雜性的所有指標與年級的相關性均極其顯著。在語法多樣性指標中,語法多樣性2(總語法項種數)與年級具有最高的相關性(r = 0.230);在語法復雜性指標中,語法復雜性2(高級語法項種數)與年級具有最高的相關性(r = 0.181)。
從實驗結果可以看出,種數指標總是具有最高的相關性,可以作為考察漢語二語學習者詞匯與語法掌握程度的最佳指標。雖然種數具有最高的相關性,但在詞匯方面,各指標相關系數差異不大,也均可作為測量指標;在語法方面,各指標相關系數則差異較大,并且部分指標與年級呈現負相關關系,這一情況將在后文中討論。
4.2 詞匯緊密性、語法松散性及修辭化表達
語言習得是一個多層次、多維度不斷互動的動態系統,詞匯習得和語法習得是其重要的子系統。動態系統理論(dynamical system theory)的一個重點探討問題是子系統的發展規律及它們之間的關系,因此,Van? Geert(1994)把同步增長的變量稱為“共同增長因子”(connected grower),其它的則是相互競爭的關系(competitor)。通過前文的分析結果可以看出,在歷時的二語習得過程中,詞匯習得與語法習得兩個子系統在指定長度的語法單位中并非共同增長,而是相互競爭,形成了詞匯緊密性和語法松散性的兩種相反趨勢。我們已經得知,年級分布與各指標均存在顯著相關性,但引人注意的一點是,詞匯多樣性與詞匯復雜性的所有指標、語法復雜性的所有指標及語法多樣性的前四個指標均與年級呈正相關,但是語法多樣性5-7三個指標與年級分布呈負相關。我們繼續對詞匯指標與語法指標進行相關性分析,發現所有指標中,只有語法多樣性5-7指標與年級分布呈負相關,這種現象的原因是因為隨著漢語二語學生年級的提高,其作文呈現詞匯緊密性與語法松散性兩種趨勢。由前文的指標介紹可知,語法多樣性5-7的計算方式如下:
語法多樣性5 = 總語法項數/總字數
語法多樣性6 = 總語法項數/總詞數
語法多樣性7 = 總語法項數/總分句數
以上三種指標均是以某類語法單位作為分母,分別指平均每個語法單位里會出現的語法項的數目。隨著學生年級的升高,語法單位的增長速度和語法項的增長速度是不同步的,前者速度遠遠高于后者,這就是詞匯緊密性與語法松散性。以作文字數為例,隨著年級升高,學生作文的字數迅速增加,在本研究的語料庫中,平均每升高一個年級,字數增加54.64,但是語法項并沒有如此大的增長量。此種特點對語法多樣性5(以字數為分母)的影響最大,導致其呈現顯著的負相關。同理,以詞、分句作為指標分母的原理與此相同,但這幾種語法單位之間也具有差異,顯然字、詞、分句的增長速度也是遞減的,字數增加的最快,詞數次之,到了由前者組成的句子層面增長速度就趨于緩慢,所以這三種指標的負相關系數也呈現遞減。同時,當分母單位為整句時(語法多樣性8),指標與年級分布呈現微弱正相關(r = 0.88,p < 0.05),這也是由差異的增長速度所決定的。
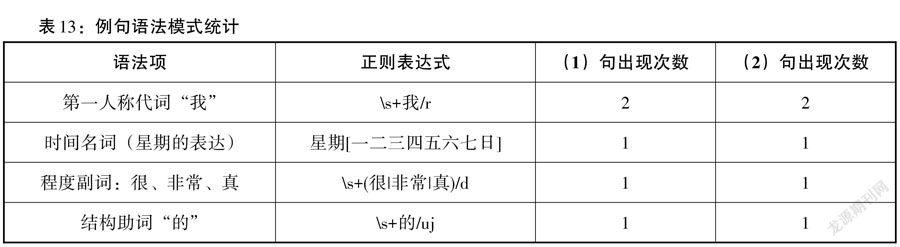
詞匯緊密性與語法松散性的本質,是組合關系與聚合關系,詞匯是語法聚合中的可更替材料,可以無限填充而句子語法結構始終穩定。本研究中以具體的語法項作為匹配對象,其本身就是一種聚合關系。以語料庫的兩個句子為例:
(1)星期五/t ,/w 敬愛/v 的/uj 老師/n 讓/v 我/rr 寫/v 作文/n ,/w 我/rr 很/d 開心/a. /w
(2)星期五/t 美麗/a 善良/a 的/uj 老師/n 讓/v 我/rr 寫/v 作文/n,/w 我/rr 感到/v 很/d 開心/a. /w
根據前文的算法進行檢索與統計,可以得到第一句中共17個字,11個詞,3個分句,1個整句。第二句共21個字,13個詞,2個分句,1個整句。雖然語法單位的特征有所差異,但是兩個句子包含的語法項是完全相同的,如下表所示:
僅從語法項數目來看,兩句話所包含的語法點完全相同,每句共出現5次語法項,但因其語法單位長度不等,所以會影響語法多樣性的部分指標。以語法多樣性5為例,第一句的計算結果為0.294,第二句的計算結果為0.238。兩式的分子均為5(語法項數),分母分別為17和21(字數),由此導致了隨著作文長度的增加出現語法模式稀疏的現象。同理,語法多樣性6與語法多樣性7也出現類似情況。
文本長度的增加為何沒有促進語法模式的增加呢?通過觀察與分析,我們可以看出,兩句的差別主要在于修辭的差異,同樣修飾“老師”這個詞,第一句用“敬愛”,第二句用“美麗善良”;同樣表示開心,第一句用“我很開心”,第二句用“我感到很開心”。而這些搭配差異是不在《大綱》所規定的語法項之列的,所以無法檢測為語法模式。這也解釋了采用語法多樣性5-7的指標會出現與年級呈現負相關的原因,隨著年級增長,學生會采用更多樣化的文字表達,這些文字表達已經超出了語法模式的范疇,但又不斷增加著文本的長度,語法模式的數量幾乎停止增長,但語法聚合中的可更替的詞匯材料可以無限填充而句子語法結構始終穩定,如果某一個學生用“美麗善良又受人尊敬”作為“老師”的修飾語,那么對這種指標的干擾作用會更大。這種加強語言表現效果的語言形式不屬于固定的語法模式,是一種修辭模式。這要求我們在研究漢語二語習得的量化分析中,要著重研究學生的修辭化表達應該如何設立檢測標準、如何將修辭模式也納入檢測指標等問題。換一個角度思考,暫時不論漢語作為第二語言的情況,僅對于漢語母語作者的文本,我們是如何評價一篇文章好壞的?這里面有深層次的認知因素,但在語言表達的形式層面,修辭化表達是一個不可缺少的考察維度。漢語二語習得的過程也是如此,修辭化表達是高階寫作的必經之路,根據本文語法模式構建方式,漢語修辭模式也可以通過計算機進行形式化表示,構建修辭模式庫并設計指標進行量化分析,這方面的研究有待繼續深化。
4.3 高級詞匯與語法知識的漢語二語教學啟示
通過前文分析,我們發現高級詞匯與語法項始終只占學生詞匯和語法項總數的很小一部分。從詞匯方面看,一年級平均高級詞匯占比為16.83%,二年級平均高級詞匯占比為21.52%,三年級平均高級詞匯占比22.90%。這也與吳繼峰(2016)的結論“英語母語者的漢語產出性詞匯量嚴重不足,即使到了高級階段,寫作仍以甲、乙級詞為主”相類似,雖然漢語二語學習者處于高級學段,但高級的詞匯知識并未取得較好的學習效果。從語法方面看,一年級平均高級語法項占比2.36%,二年級平均高級語法項占比2.43%;三年級平均高級語法項占比2.57%。相比于高級詞匯,高級語法項占比很低,增長速度也極低,表明學習者在學習過程中對高級的語法知識的掌握程度處于停滯狀態。
對于這種現象,我們一方面要從標準制定的角度反思,一方面要從標準貫徹的角度反思。從標準制定的角度來看,詞匯特征的分級標準來源于《新漢語水平考試(HSK)詞匯》(2012),語法模式的分級標準來源于《大綱》(2014),這兩個分級標準均來自于權威機構,但僅從本文的研究來看,高級詞匯的使用量較少,即使是高年級學生,平均每篇作文也僅使用5.1個六級詞匯。高級語法項的使用量則更少,高年級學生平均每篇作文僅能出現0.23個六級語法項,這表明絕大多數學生在寫作中不會采用六級語法項。由此可見,學生對于《大綱》所要求的高級詞匯和語法知識掌握程度較低,漢語二語習得過程中語法知識的標準制定應當更加貼合漢語二語教學的實際狀況,不斷完善漢語二語詞匯及語法知識的難度分級標準。
從標準貫徹的角度來看,漢語二語教學者應當更加關注高級詞匯與語法的教學效果,讓學生在掌握了初級詞匯語法知識的基礎上,加大高級詞匯語法知識的教學力度,采用有效的教學方式,讓學生突破初、高級之間的“瓶頸”,真正掌握高級的詞匯、語法知識。不能只讓學生的作文水平僅僅停留在能夠傳遞信息的初級層面,而要緊扣大綱要求,擴展相應的知識,不斷提升學生的漢語水平。
5. 結語
本文是基于“國別化漢語中介語語料庫庫群”中的“韓國在華學習者漢語中介語語料庫”的實證性研究,以詞匯特征及語法模式兩個方面考察韓國漢語學習者漢語作文水平的動態變化。本文創新性地將各級語法模式轉化為正則表達式,使用SPSS等軟件對作文語料進行大規模精細考察與分析。研究結果表明:詞匯特征指標中,詞匯多樣性2(詞種數)及詞匯復雜性2(高級詞種數)與年級分布具有最高的相關性。語法模式指標中,語法多樣性2(語法項種數)和語法復雜性2(高級語法項種數)與年級分布具有最高的相關性,并且兩個維度的各指標之間大部分具有顯著相關性。大部分指標與年級分布呈正相關,小部分呈負相關。本文對于負相關指標進一步分析,討論了詞匯緊密性與語法松散性的兩種趨勢,并對漢語二語作文質量指標的完善提出建議。
未來的漢語二語研究還需要學界對作文質量指標進行進一步拓展。本文所使用的語法模式庫是符合漢語特點的細粒度指標,具有本土化與精細化的特點,有助于對具體的語法知識進行追蹤考察,對于學生寫作質量的分析與漢語二語教學的效果反饋具有很大意義。通過語法模式各指標的分析,發現修辭化表達也是寫作質量不可忽略的因素之一,而現在修辭化表達的定量分析研究較為缺乏,于此提出了修辭模式的范疇,在下一步的研究工作中應進一步對其進行研究和分析。
[參考文獻]
鮑 貴 2008 二語學習者作文詞匯豐富性發展多緯度研究[J].外語電化教學(5).
段勝峰,李 森 2014 對外漢語二語教學研究的進展與述評[J].西南大學學報(社會科學版)(6).
胡曉清 2018a 國別化漢語中介語動態語料庫建設理念、實踐與前瞻[J].山東師范大學學報(人文社會科學版)(5).
——— 2018b 國別化漢語中介語動態語料庫建設與研究[M]. 北京:中國社會科學出版社.
孔子學院總部,國家漢辦 2012 新漢語水平考試(HSK) 詞匯修訂版[EB/OL]http://www.chinesetest.cn/godownload.do#/.
孔子學院總部,國家漢辦 2014 國際漢語教學通用課程大綱[M]. 北京語言大學出版社.
商務印書館, 國家漢辦/孔子學院總部 2010 新漢語水平考試大綱[M].
王海華,周 祥 2012 非英語專業大學生寫作中詞匯豐富性變化的歷時研究[J]. 外語與外語教學(2).
王藝璇 2017 漢語二語者詞匯豐富性與寫作成績的相關性——兼論測量寫作質量的多元線性回歸模型及方程[J]. 語言文字應用(2).
吳繼峰 2016 英語母語者漢語寫作中的詞匯豐富性發展研究[J].世界漢語教學(1).
吳繼峰,陸小飛 2021 不同顆粒度句法復雜度指標與寫作質量關系對比研究[J].語言文字應用(1).
吳繼峰,周 蔚,盧達威 2019 韓語母語者漢語二語寫作質量評估研究——以語言特征和內容質量為測量維度[J].世界漢語教學(1).
張娟娟 2019 東南亞留學生記敘文詞匯豐富性發展研究[J].云南師范大學學報(對外漢語教學與研究版)(1).
鄭詠滟 2011 動態系統理論在二語習得研究中的應用——以二語詞匯發展研究為例[J]. 現代外語(3).
朱慧敏,唐建華 2021 句法復雜性測量指標研究:回顧、反思與展望[J].山東理工大學學報(社會科學版)(1).
Carroll, J. B. 1967 Foreign language proficiency levels attained by language majors near graduation from college[J]. Foreign Language Annals 1(2).
Crossley, S. A. & McNamara, D. S. 2014 Does writing development equal writing quality? A computational investigation of syntactic complexity in L2 learners[J]. Journal of Second Language Writing 26.
Guiraud, P. 1959 Problèmes et Méthodes de la Statistique Linguistique[M]. D. Reidel.
Hunt, K. W. 1966 Recent measures in syntactic development[J]. Elementary English 43(7).
Jiang, W. 2013 Measurements of development in L2 written production: The case of L2 Chinese[J]. Applied Linguistics 34(1).
Jin, H. G. 2007 Syntactic maturity in second language writings: A case of Chinese as a foreign language (CFL)[J]. Journal-Chinese Language Teachers Association 42(1).
Lu, X. 2012 The relationship of lexical richness to the quality of ESL learners oral narratives[J]. The Modern Language Journal 96(2).
Malvern, D., Richards, B., Chipere, N., & Durán, P. 2004 Lexical Diversity and Language Development[M]. New York: Palgrave Macmillan.
ODell, F., Read, J. & McCarthy, M. 2000 Assessing Vocabulary[M]. Cambridge university press.
Paquot, M. 2019 The phraseological dimension in interlanguage complexity research[J]. Second language research 35(1).
Reed, J. 2004 Plumbing the Depths: How Should the Construct of Vocabulary Knowledge be Defined[J]. Vocabulary in a Second Language 209-227.
Van Geert, P. 1994 Dynamic Systems of Development: Change between Complexity and Chaos[M]. Harvester Wheatsheaf.
Wolfe-Quintero, K., Inagaki, S. & Kim, H. Y. 1998 Second Language Development in Writing: Measures of
Fluency, Accuracy, & Complexity[M]. University of Hawaii Press.
A dynamic development study of CSL writing quality based on lexical features and grammatical patterns
WANG Haoxue, CHENG Yong, HU Xiaoqing
(School of Liberal Arts, Ludong University, Yantai, Shandong 264001, China)
Key words: writing quality; lexical diversity; grammatical sophistication; grammatical variation; grammatical sophistication; corpus
Abstract: This study takes 6,789 valid compositions of 596 students in 3 grades of Korean students from the Chinese Interlanguage Corpus for Korean Learners in China, and examines the dynamic changes of Korean studentsChinese composition levels with vocabulary characteristics and grammar modes as the measurement indicators. Lexical indexes include two dimensions: lexical variation and lexical sophistication, with a total of 8 indicators; grammatical pattern index contains two dimensions: grammatical variation and grammatical sophistication, with a total of 12 indicators. This study innovatively transforms 248 grammatical patterns listed in International Curriculum for Chinese Language Education into regular expressions, and uses SPSS and other softwares to investigate and analyze the composition corpus on a large scale. The results show that the lexical variation 2 (type)? and lexical sophistication 2 (advanced type)? have the highest correlation with the grade distribution. As for the grammar index, grammatical variation 2? (grammatical type)? ?and grammatical sophistication 2? (advanced grammatical type)? have the highest correlation with the grade distribution. We further analyze the correlation between words and grammar, discuss the characteristics of lexical compactness? and grammatical looseness,? and put forward advice for future Chinese vocabulary and grammar teaching.
【責任編輯 劉文輝】
[收稿日期] 2021-04-26
[作者簡介] 王浩學,男,魯東大學文學院,主要研究方向為應用語言學。電子郵箱: wanghx@m.ldu.edu.cn。程勇,男,魯東大學文學院講師,碩士生導師,主要研究方向為計 算語言學,電子郵箱:chengokyong@126.com。胡曉清,女,魯東大學文學院教授,碩士生導師, 主要從事漢語詞匯研究、漢語作為第二語言習得研究、漢語中介語研究、語料庫語言學研究, 電子郵箱:xiaoqingytyt@126.com。
[基金項目] 山東省教育科學規劃課題“面向分級閱讀的中小學閱讀材料易讀性研究” (2021QZD004);漢語辭書研究中心規劃課題“面向融媒體辭書編纂的多源例句分級檢索 系統構建研究”(CSZX-YB-202004)
