數據結構課程中算法復雜度的教學實踐研究
2022-06-15 04:51:02馮翱朱燁李莉麗
教育現代化 2022年22期
馮翱,朱燁,李莉麗
(成都信息工程大學 計算機學院,四川 成都)
一 引言
《數據結構》是計算機學科的核心課程之一,在ACM-IEEE 課程體系中一般被編號為CS2,是在CS1(基礎程序設計語言)之后的第二門專業課程。數據結構作為培養程序設計能力的核心專業課程,在問題理解、抽象、設計和實現這個流程中對于計算思維的形成起到關鍵性作用[1]。由于該課程概念多,并且通常講解方式較為抽象,如果不能有效地與工程應用結合,對于部分學生來說理解難度較大[2]。
數據結構課程中算法復雜度是最重要的知識點之一[3],通常在教材的第一章作為基礎內容和方法出現。算法復雜度包含時間復雜度和空間復雜度兩個概念,分別衡量在一定規模的輸入數據下,程序運行時間和額外占用空間相對于問題規模n 的漸近復雜度。前者判斷在問題規模較大時,是否能夠以比較高的時間效率完成確定性算法的執行,而后者決定算法運行過程中的臨時數據是否能夠同時在處理效率較高的物理介質中進行操作。通常在數據結構的教學過程中不涉及規模過大的數據集,而且多數算法不會用到超過多項式級別的空間復雜度。除了外部排序(在數據結構課程中一般是選學內容)之外,基本不會發生頻繁的內外存數據交換,因此在提到算法復雜度的時候,大多數情況下重點關注的是時間復雜度。
對于算法復雜度分析的應用貫穿于整門課程的教學過程中。后續章節通常是以一類數據結構為核心,講解其類型定義、在不同存儲結構下的實現以及在具體場景中的應用。對于每種物理實現(如順序或鏈式存儲)下的具體操作,都需要進行時間和空間復雜度分析,一方面是加深學生對于算法過程和資源需求的理解,另一方面復雜度分析決定了在資源受限場景下數據結構和算法選擇的優先級和可行性。從某個層面上來說,對于算法復雜度的正確分析決定了學生是否能夠真正理解問題的困難程度,并在真實場景中選擇適當的算法對其進行合理應用。
二 問題分析
在數據結構課程的教學過程中,算法復雜度的內容相對來說是掌握情況較差的。對于特定邏輯結構下的指定算法,例如標準的內部排序,經過反復的講解和練習后,大多數學生能夠掌握其算法思路,并能在標準化場景下進行應用。但如果要求學生對于特定算法的復雜度進行獨立分析,很大一部分的學生不能給出清晰的推導過程和結果,歷次考試中算法復雜度分析的題目得分率普遍在50%之下。經過與多屆學生的反復溝通,這個知識點掌握困難的主要原因包括概念的抽象性、課程教學中問題規模過小和缺少真實應用案例三方面。
(一) 算法復雜度概念理解上的抽象性
算法復雜度的形式定義是使用數學中的漸近上下界來描述的,以漸近上界的定義為例:
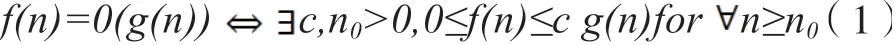
雖然計算機類專業的學生在學習數據結構之前一般都完成了高等數學課程的內容,要求他們用數學的方式閱讀并對該公式進行解釋,對于絕大多數的學生有很大的困難[4]。相對來說,采用圖1 所示的方式直觀性地加以解說,對于有一定數學基礎的學生來說基本都能夠接受。
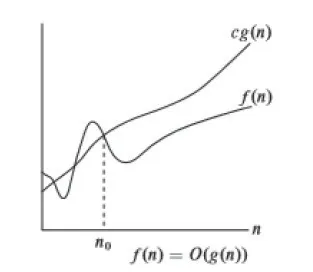
圖1 算法復雜度知識點中漸近上界的圖形化說明
對于漸近下界Ω()和漸近緊確界Θ()的講解也有類似的情況。從大多數數據結構教材的內容中可以觀察到,雖然多數基本算法在進行復雜度分析時嘗試找到的是漸近緊確界,為了降低學生的理解難度,描述復雜度時通常都使用漸近上界符號O()。
(二) 課程教學中的問題規模
時間復雜度的變化會帶來算法運行時間的較大差異,但這個差異一般要在輸入數據的大小達到一定規模時才能夠被明顯觀察到。出于教學演示的需求,無論是教材和課件中用到的例子,以DSDemo[5]為代表的算法演示系統,還是課程中設計的實驗環節,輸入數據集的大小通常不超過20。在這樣的小規模數據集上,具有不同運行效率的同類算法在運行時間上沒有明顯的區別。以內部排序算法為例,雖然我們知道簡單排序算法中的冒泡排序具有較高的時間復雜度,而復雜排序算法中的快速排序、堆排序等的平均時間復雜度為,對于實驗中用到的小規模數據,實際執行時間都在毫秒級。如果嚴格執行計時程序,經常會出現簡單算法運行更快的結果,這是因為它們單次執行的指令更少,在執行次數差別不大的前提下總的運行時間可能更短。如果在不加限制的條件下要求學生實現一個排序算法,大多數學生毫不猶豫地選擇了冒泡排序,主要原因是實現簡單。在小規模數據場景下這樣的判斷并沒有錯,但在他們畢業進入正式的工程應用環境后,冒泡排序顯然不是一個好的默認選項。
(三) 真實工程應用場景的缺失
作為對于真實工程需求的一個介紹,在數據結構課程教學中引入了TeraSort 的例子,這是一個Hadoop 時代的典型案例。隨著計算機軟硬件的不斷發展,Jim Gray 建立的Sort Benchmark 上這個任務已經被MinuteSort 取代,2016 年騰訊的紀錄就已經達到一分鐘排序37TB(非定制化算法)或55TB(定制優化)數據的水平。但這樣規模的數據對于課程教學環節來說,是大大超出學生理解范圍的。在類似數據規模下的任何算法問題,對于時間復雜度都會有很高的敏感度。假定單臺計算設備有足夠的內存,并且編譯器支持分配TB 級的內存空間(多數高校的教學設備應該滿足不了這些條件),對于不同排序算法的運算時間估計是一個很有意思的問題,而這樣來自于真實工程需求的問題對于他們加深對算法復雜度的理解,乃至考慮類似工程問題的算法設計思路都是很有幫助的。在我們的課程教學中,明顯缺失了這一部分內容,而這恰恰是學生從書本知識過渡到真實工程需求中欠缺的關鍵環節。
三 教學環節設計與實施
針對數據結構課程中學生對于算法復雜度理解困難的現狀,課程組使用外部數據源和開源框架引入真實數據集,讓學生對于大規模問題有直觀的感受和更高的參與興趣,并面向不同層次的學生嘗試多種形式、不同規模的項目實踐活動,收集了學生的直觀反饋,以指導相關知識點教學過程的持續改進。
(一) 外部數據導入
為了在教學環節中讓學生有機會接觸到更大規模的真實數據,課程組對高校教學領域現有的數據源和訪問框架進行了調研。BRIDGES[6]為數據結構課程提供了訪問多個真實數據集的簡單接口,目前已經包含Twitter、Facebook 等多個數據源,同時為了對于數據有直觀的認知,還包含了數據可視化的功能。RealTimeWeb[7]在計算機課程的教學中使用了實時更新的在線數據集,在不接觸太多實現細節的前提下讓學生熟悉數據處理的基本原理。在計算機領域之外,CORGIS[8]涵蓋了歷史、政治、醫藥、教育等多個領域的40 多個數據集。經過對這些框架的調研和比較,選擇了最適合相關課程的BRIDGES 框架,經過移植和封裝后提供了使用樣例和說明文檔,供后續項目和其他教學環節使用。
(二) 實踐項目設計
數據結構的課程項目設計中給出了一個算法復雜度分析的題目,要求在較大規模的數據集上實現至少一種時間復雜度為和一種復雜度為的排序算法,并且用實驗的方法確定其復雜度。為了體現不同復雜度階次算法之間的性能差異,數據規模要求在10 萬條以上,這有效地避免了因為數據量過小導致使用復雜度的簡單排序算法運行效率更高的情況。此外,題目要求對于算法真實運行時間或者基本操作執行次數進行記錄,讓學生能夠更直觀地感覺到算法選擇對于執行效率的影響。雖然這只是一個小規模的實踐項目,相對傳統課堂上的“小”數據,這是一個更接近于真實工程應用規模的虛擬場景。從提交的結果看來,這個項目一方面對于線性回歸、最小二乘法等數學知識提供了額外的學習機會,更有價值的收獲是“不僅學會了多種排序算法,更對時間復雜度的概念有了深刻的理解,還把數學知識和編程、算法,聯系到了一起,對未來的編程道路有一定的啟發作用”。學生從計時結果上真實感受了較大數據規模下時間復雜度算法的明顯優勢,并有更高積極性去深入分析兩類算法的機制差異,嘗試理解產生這個復雜度變化的原因。
(三) 算法時間復雜度分析系統
由于數據結構課程在大二上學期設置,學生的數學基礎、程序設計能力和對工程問題的理解還比較有限,設計和實現一個具有更高通用性的復雜度分析系統對于這個階段的學生有一定難度。在本科畢業設計階段,將《算法時間復雜度分析系統的設計與實現》作為備選題目之一,并提出了更高的要求。增加的主要功能包括:
(1) 對于不同格式、不同來源的輸入數據進行讀取和清洗,去掉異常數據;
(2) 對于自定義算法,在滿足輸入輸出接口一致的前提下,能夠支持復雜度分析功能;
(3) 有效地去除擬合結果中的噪聲,得到算法對應復雜度公式中最主要的函數項,該結果在不同設備上具有較好的一致性。
在算法復雜度分析中,對指令/ 代碼進行計數是比較常用的方法,但該方法通常只適用于固定代碼,對于自定義算法來說難以實現。如果采用運行計時的方法,對于設備的各種參數和運行時負載情況又比較敏感。為了得到跨設備一致的分析結果,學生設計了一段包含主要運算操作的基準代碼,用同一設備上算法運行時間和基準代碼運行時間的比值作為相對復雜度,這樣在一定程度上排除了軟硬件環境對于運行時間的影響。針對離群點影響最終擬合結果的情況,又引入了基于M 估計的最小二乘法,保證擬合曲線與實驗數據有較好的一致性,系統展示的擬合結果如圖2 所示。
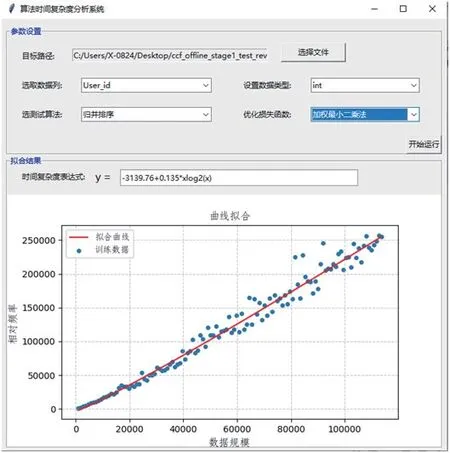
圖2 歸并排序算法在有較多離群點時的擬合結果
學生在對于該系統的總結中提到:“完成的系統表現出良好的擬合效果,得到的曲線與訓練數據樣本高度重合,并表現出良好的穩定性與可靠性。該系統提供可視化交互式界面,可以對外界的真實數據進行操作,這有利于學生在學習數據結構課程時將教材內容與真實問題接軌,提高學生的學習積極性與參與度。”這與系統的設計目標一致。
四 問題分析與課程改進
從已經實施的教學環節中可以看到,教學過程中的小數據依然是制約學生對算法復雜度深入理解的主要障礙。而要解決這個數據結構課程教學中的共有問題,主要考慮從真實數據、實踐案例和師資水平三方面加以改進。
在很多學生的反饋中都提到,當數據規模較小時,不同算法的運行時間差別并不明顯,甚至會出現理論復雜度低的算法運行時間更長的情況。當達到一定數據規模之后,不同類別算法的運行時間就明顯展示出了增長速度的差異。這也展現了課堂教學和工程應用中的場景特征。在教學環節,如果我們繼續使用小規模的“偽”數據,對于學生來說如何用最簡單的代碼實現要求的功能就會成為他們進行方案選擇的第一優先。而在真實工程技術場景下,對于大規模數據進行處理的運行效率直接決定實現方案的可用性。為了彌合二者之間的差異,引入大規模的外部數據,尤其是現實應用中的真實數據,是提高學生工程應用能力的必要環節。
從現在已經嘗試的工作來看,算法復雜度至少對于本科低年級學生來說是一個具有一定難度的概念,其原因除了講解方式較為抽象以外,缺少具有足夠規模的真實問題,讓他們感受不到復雜度差異對于運行效率的影響,是現有教學過程中不足之處。現階段工程技術教育逐漸融入到高校教學過程中,這是一個良好的改進契機。不少高校的培養方案中將工程實踐、企業實習等納入本科必修的教學環節,在工程實踐教學過程中,可以適當地引入來自企業或者社會的真實數據,并提供將教材所學數據結構和算法應用于真實需求中的實踐案例。這對于學生來說,一方面能夠更早接觸行業需求,了解自己應該學什么,另一方面解決真實問題的成就感遠遠超過完成教材上的幾道習題,對于學習興趣和動力也會有更大的促進。
對于相關課程的任課教師來說,從校園到校園的純學術型人才已經不能滿足信息學科發展的需求了。獲取行業實踐經驗,根據經濟和社會需求相應調整課程教學的內容和手段,也是持續提高教學水平、教學效果和個人能力的需要。此外,在與企業的聯合培養過程中引入更多的工程技術型校外導師,也是對于現有以學術型人才為主的高校師資的重要補充。
五 結語
算法復雜度問題在很長一段時間之內都會是數據結構課程的重點和難點之一,主要原因包括漸近復雜度概念的抽象化、課程中使用數據規模過小,以及真實工程應用場景在課程教學環節中的缺失。對于這個概念內涵理解的不夠深入使得在課程各階段的考核中學生的得分率偏低,同時在需要根據問題規模進行算法選擇時,很多情況下學生傾向于實現最簡單的高復雜度算法,這些都是算法復雜度部分教學效果不佳的直觀體現。
為解決這些問題,在本科數據結構課程和畢業論文等幾個階段通過課程項目和畢業設計等方式進行了一些教學模式的實踐和研究。從執行情況來看,選擇這些項目的學生會有意識地對相關算法、數學基礎和算法復雜度分析的方法進行學習,并通過一定規模下的實驗真實體會不同復雜度對于算法運行效率的影響。從教師的教學觀察和參與學生的直接反饋得知,參與這些教學環節使得學生對于相關概念和方法的理解有一定提高。
基于現有問題和教學研究已取得的成果,為了更為全面地改善數據結構課程中對于復雜度的理解,提高教學效果和在后續工程實踐場景中的有意識應用,下一步主要計劃從以下幾個方面對于培養過程進行改進。
(1) 引入真實外部數據,以增強學習興趣,并理解真實大數據場景下復雜度對于算法選擇和運行效率的影響;
(2) 聯合相關企業構建工程實踐環節,讓學生理解行業真實需求,并有意識地進行按需學習;
(3) 引入具有豐富實踐經驗的企業導師,并在高校中通過多種方式培養更多的雙師型教師,提高整體師資水平,給學生書本知識之外的全方面培養。
算法復雜度只是現有教學模式下暴露出來的一個知識難點,而對應的改進方案也不僅僅是為了解決這一個問題,其核心思路是將學校的培養過程與行業發展和企業所需的知識體系結合,培育面向市場需求的高素質綜合型人才。
致謝感謝王維寬提供基于BRIDGES 的外部數據引入代碼和文檔,感謝在數據結構課程項目中選擇算法復雜度題目的吳晶、王奧等同學,感謝李杏作為畢業設計項目完成的算法復雜度分析系統。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
內蒙古教育(2021年20期)2021-03-08 01:09:14
甘肅教育(2020年14期)2020-09-11 07:57:50
計算機教育(2020年5期)2020-07-24 08:53:38
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
家庭影院技術(2019年11期)2019-12-09 09:14:30
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
東方教育(2017年19期)2017-12-05 15:14:48
唐山文學(2016年2期)2017-01-15 14:03:59
