基于多標(biāo)簽零樣本學(xué)習(xí)的滾動(dòng)軸承故障診斷
2022-06-17 03:03:42張永宏趙曉平王麗華呂凱揚(yáng)張中洋
振動(dòng)與沖擊 2022年11期
張永宏, 邵 凡, 趙曉平, 王麗華, 呂凱揚(yáng), 張中洋
(1.南京信息工程大學(xué) 自動(dòng)化學(xué)院,南京 210044;2.南京信息工程大學(xué) 計(jì)算機(jī)與軟件學(xué)院,南京 210044;3.南京信息工程大學(xué) 江蘇省網(wǎng)絡(luò)監(jiān)控中心,南京 210044)
滾動(dòng)軸承是旋轉(zhuǎn)機(jī)械中的重要部件,隨著現(xiàn)代機(jī)械儀器、設(shè)備向高速和精密方向發(fā)展,對(duì)滾動(dòng)軸承的可靠性要求愈來(lái)愈高。但實(shí)際工業(yè)場(chǎng)景中,滾動(dòng)軸承因載荷大、沖擊強(qiáng)等惡劣工況,極易產(chǎn)生故障。相較于實(shí)驗(yàn)室流程操作所產(chǎn)生的固定故障類型,工業(yè)場(chǎng)景下滾動(dòng)軸承的故障類型復(fù)雜多樣[1]。利用已有的狀態(tài)監(jiān)控?cái)?shù)據(jù),如何識(shí)別無(wú)歷史記錄的故障類型(即未見類故障)、提高未見類故障識(shí)別的準(zhǔn)確性成為研究難點(diǎn),具有顯著的工程應(yīng)用價(jià)值和需求。
本文重點(diǎn)關(guān)注在不停機(jī)檢查的情況下,依靠現(xiàn)有類型固定的故障數(shù)據(jù),完成工業(yè)場(chǎng)景中未見類軸承故障的識(shí)別。這種故障診斷方式在沒(méi)有目標(biāo)故障類型樣本的條件下完成,擺脫了對(duì)共享故障類型的依賴,因此零樣本故障診斷更接近工程應(yīng)用場(chǎng)景的實(shí)際情況。由于實(shí)際應(yīng)用場(chǎng)景的制約,與一般的故障識(shí)別相比,零樣本故障識(shí)別具有以下特點(diǎn):①參與測(cè)試的目標(biāo)故障(未見類故障)和參與模型訓(xùn)練的故障(可見類故障)在故障類型上沒(méi)有交集;②識(shí)別結(jié)果具有較好的泛化性,能夠真正擴(kuò)展到實(shí)際工業(yè)場(chǎng)景中;③識(shí)別模型適用場(chǎng)景廣泛,且無(wú)需反復(fù)進(jìn)行模型參數(shù)重設(shè)和模型優(yōu)化。
此外,本文還關(guān)注高效的模型設(shè)計(jì),在減少模型參數(shù)的同時(shí)保持其性能,即模型輕量化。卷積核分解是一種常用的輕量化方法,如GhostNet[2]使用Ghost模塊替換卷積層,減少了計(jì)算成本,Xception[3]、MobileNet[4]和MBDS-CNN[5]均使用深度可分離卷積代替標(biāo)準(zhǔn)卷積以實(shí)現(xiàn)輕量化。模型輕量化具有以下優(yōu)勢(shì):①模型對(duì)內(nèi)存和處理器性能的要求低;②分布式訓(xùn)練中的數(shù)據(jù)交換少;③適應(yīng)更廣泛的嵌入式、移動(dòng)端設(shè)備。
當(dāng)前,數(shù)據(jù)驅(qū)動(dòng)的故障診斷方法已經(jīng)成功運(yùn)用于機(jī)械故障診斷[6],包括自動(dòng)編碼器[7-8]、卷積神經(jīng)網(wǎng)絡(luò)[9-10]和深度置信網(wǎng)絡(luò)[11]等。但是,上述方法依賴于大量訓(xùn)練數(shù)據(jù)以優(yōu)化模型,而實(shí)際工程場(chǎng)景中的帶標(biāo)簽數(shù)據(jù)難以獲取。近年來(lái),為了克服實(shí)際工程場(chǎng)景中故障樣本采集的困難,基于深度遷移學(xué)習(xí)的方法被廣泛應(yīng)用,其基本流程是從易獲取的故障數(shù)據(jù)(源域)中學(xué)習(xí)知識(shí),幫助識(shí)別難以采集或采集代價(jià)高昂的故障(目標(biāo)域)[12-13]。雷亞國(guó)等[14]將殘差網(wǎng)絡(luò)與最大均值差異項(xiàng)、偽標(biāo)記學(xué)習(xí)結(jié)合,提出了一種無(wú)需目標(biāo)故障樣本標(biāo)記信息的高精度遷移學(xué)習(xí)方法。Lu等[15]提出域自適應(yīng)模型,完成了變工況下的滾動(dòng)軸承診斷任務(wù)。此外,還有學(xué)者構(gòu)建了基于生成對(duì)抗思想[16-17]和實(shí)例[18]的遷移學(xué)習(xí)模型。盡管深度遷移學(xué)習(xí)方法不需要來(lái)自目標(biāo)域的帶標(biāo)簽樣本,但其重點(diǎn)解決的是源域和目標(biāo)域的域偏移問(wèn)題,前提是源域與目標(biāo)域具有標(biāo)簽相同的故障。然而本文考慮的零樣本問(wèn)題在源域和目標(biāo)域沒(méi)有標(biāo)簽上的交集,因此,深度遷移學(xué)習(xí)不符合零樣本的要求。
綜合上述分析,本文引入零樣本學(xué)習(xí)(zero-shot learning, ZSL)方法以解決零樣本條件下未見類故障的識(shí)別問(wèn)題。ZSL方法僅將可見類樣本用作訓(xùn)練數(shù)據(jù),實(shí)現(xiàn)對(duì)未見類的分類。Lampert等[19]首次提出ZSL的概念,對(duì)毫無(wú)關(guān)聯(lián)的訓(xùn)練集和測(cè)試集完成了對(duì)象檢測(cè),提出了直接屬性預(yù)測(cè)(direct attribute prediction, DAP)方法,利用非線性支持向量機(jī)來(lái)學(xué)習(xí)屬性,再使用訓(xùn)練好的支持向量機(jī)預(yù)測(cè)未見類樣本的屬性。此外,Lampert等[20]還提出了間接從標(biāo)簽中學(xué)習(xí)屬性的間接屬性預(yù)測(cè)(indirect attribute prediction, IAP)方法。為了將可見類中學(xué)習(xí)到的投影函數(shù)更好地推廣到未見類中,Kodirov等[21]提出了語(yǔ)義自編碼器(semantic autoencoder, SAE),編碼器將全局視覺特征向量投影到語(yǔ)義空間中,通過(guò)優(yōu)化解碼器重構(gòu)原始視覺特征給網(wǎng)絡(luò)施加約束,提升了識(shí)別精度。在故障診斷領(lǐng)域,GAO等[22]提出了基于壓縮堆疊自編碼器的零樣本學(xué)習(xí)方法,使用已知工況下的數(shù)據(jù)訓(xùn)練模型,成功診斷出未知工作負(fù)載下的軸承故障。但該方法未能將故障信號(hào)的特征投影到高維屬性空間,本質(zhì)上沒(méi)有突破類別邊界,不符合零樣本的要求。FENG等[23]針對(duì)零樣本條件下的工業(yè)故障診斷任務(wù),定義了有別于圖像識(shí)別領(lǐng)域的輔助信息即故障屬性(故障的原因、位置、影響等),其試驗(yàn)結(jié)果驗(yàn)證了零樣本條件下故障診斷的可行性,但該方法未考慮各故障屬性之間的相關(guān)性。
針對(duì)以上不足,為了實(shí)現(xiàn)零樣本條件下未見類軸承故障的診斷,本文提出了MLZSL故障診斷方法。首先,對(duì)振動(dòng)信號(hào)做短時(shí)傅里葉變換并劃分訓(xùn)練集(可見類)和測(cè)試集(未見類);其次,構(gòu)建輕量化特征提取模型RDSCNN,提取可見類和未見類各樣本的特征;然后將可見類樣本的特征用于訓(xùn)練多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò),再識(shí)別未見類樣本的屬性;最后計(jì)算屬性向量與各屬性標(biāo)簽的余弦距離,完成對(duì)未見類軸承故障的診斷。試驗(yàn)顯示,MLZSL方法相較于經(jīng)典的零樣本方法(DAP、IAP、SAE)取得了更準(zhǔn)確的診斷結(jié)果。
1 相關(guān)理論介紹
RDSCNN特征提取模型中結(jié)合了殘差學(xué)習(xí)機(jī)制和深度可分離卷積層,相關(guān)理論介紹如下。
1.1 殘差學(xué)習(xí)
在深度神經(jīng)網(wǎng)絡(luò)中,理論上網(wǎng)絡(luò)的層數(shù)越深,其輸出的特征表示能力越強(qiáng)。但隨著深度的不斷增加,網(wǎng)絡(luò)會(huì)發(fā)生退化,準(zhǔn)確率也隨之下降。He等[24]所提出的殘差卷積神經(jīng)網(wǎng)絡(luò)(residual neural network, ResNet)引入殘差模塊解決了網(wǎng)絡(luò)退化問(wèn)題,殘差學(xué)習(xí)模塊的結(jié)構(gòu)如圖1所示。
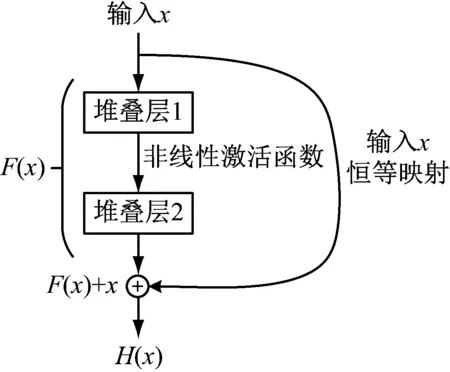
圖1 殘差學(xué)習(xí)模塊結(jié)構(gòu)Fig.1 Structure of residual learning module
殘差模塊在從輸入到輸出的單一映射基礎(chǔ)上添加了來(lái)自輸入的跳躍連接[25],將淺層的輸出加到深層的輸出上,最終輸出如下
H(x)=F(x)+x
(1)
式中:x為上一層的輸出;H(x)為殘差模塊的輸出;F(x)為對(duì)x的線性或非線性調(diào)整。若淺層輸出x已經(jīng)提供足夠完備的特征,以致對(duì)特征x的任意改變都會(huì)增加損失時(shí),F(xiàn)(x)將不做任何學(xué)習(xí),整個(gè)模塊相當(dāng)于恒等映射,由此改變網(wǎng)絡(luò)的前向和后向傳遞方式,對(duì)網(wǎng)絡(luò)加深起到優(yōu)化作用。
1.2 深度可分離卷積
深度可分離卷積由深度卷積和逐點(diǎn)卷積兩個(gè)過(guò)程組成。在深度卷積過(guò)程中,每次卷積只在單個(gè)通道上進(jìn)行,輸出與輸入具有相同通道數(shù)量的特征圖;在逐點(diǎn)卷積過(guò)程中,對(duì)深度卷積過(guò)程輸出的特征圖做1×1卷積,重復(fù)該過(guò)程n次即可增加輸出通道數(shù)至n層,其具體操作如圖2所示。

圖2 深度可分離卷積結(jié)構(gòu)Fig.2 Structure of depthwise separable convolution
假設(shè)輸入圖片大小為m×m×3,欲輸出通道為n的特征圖,使用傳統(tǒng)卷積需要n個(gè)k×k×3的卷積核移動(dòng)(m-k+1)2次,總體運(yùn)算次數(shù)如下
3nk2(m-k+1)2
(2)
使用深度可分離卷積進(jìn)行運(yùn)算時(shí),在深度卷積過(guò)
程中3個(gè)k×k×1的卷積核移動(dòng)(m-k+1)2次;在逐點(diǎn)卷積過(guò)程中n個(gè)1×1×3的卷積核移動(dòng)(m-k+1)2次。深度可分離卷積總體運(yùn)算次數(shù)如下
3(k2+n)(m-k+1)2
(3)
2 MLZSL故障診斷方法
整體而言,本文所提出的MLZSL方法包括特征提取和屬性學(xué)習(xí)兩個(gè)階段。其中,特征提取階段的核心任務(wù)是RDSCNN模型的構(gòu)建和使用;屬性學(xué)習(xí)階段通過(guò)搭建多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò),直接從樣本特征中學(xué)習(xí)故障屬性并完成未見類樣本的診斷。
2.1 特征提取階段
深度神經(jīng)網(wǎng)絡(luò)能夠提取海量數(shù)據(jù)中的抽象特征,為了充分發(fā)揮深度神經(jīng)網(wǎng)絡(luò)的特征提取能力,同時(shí)加速模型收斂和避免網(wǎng)絡(luò)退化問(wèn)題,本文提出了RDSCNN模型。模型主要由深度可分離卷積層、卷積層、最大池化層、平均池化層、全連接層以及殘差連接組成,如圖3所示。RDSCNN模型以三通道的時(shí)頻圖像作為輸入,通過(guò)卷積層和深度可分離卷積層不斷優(yōu)化特征,加入殘差連接減少特征損失,設(shè)置卷積層和池化層步長(zhǎng)以下采樣方式減小空間維度,最終由全連接層輸出一維特征。模型采用Relu作為非線性激活函數(shù),加快模型訓(xùn)練速度。 為了防止模型出現(xiàn)梯度消失的問(wèn)題,對(duì)每一層卷積運(yùn)算的結(jié)果做批量歸一化處理,使其符合標(biāo)準(zhǔn)的正態(tài)分布,消除層與層之間的量級(jí)差異。
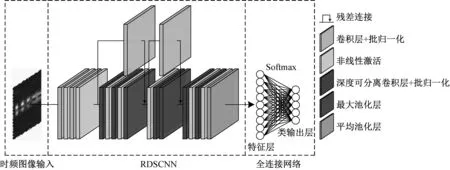
圖3 特征提取網(wǎng)絡(luò)Fig.3 Feature extraction network
RDSCNN模型在試驗(yàn)中分為模型訓(xùn)練和特征提取兩個(gè)階段。在模型訓(xùn)練階段,首先將模型與Softmax函數(shù)組合,訓(xùn)練集數(shù)據(jù)由正向傳播經(jīng)過(guò)模型各層和Softmax函數(shù)運(yùn)算到達(dá)類輸出層,然后將輸出結(jié)果代入交叉熵?fù)p失函數(shù)如式(4)所示。
(4)

在特征提取階段,采用已經(jīng)訓(xùn)練好的RDSCNN模型對(duì)整個(gè)數(shù)據(jù)集進(jìn)行特征提取,在特征層得到數(shù)據(jù)的低維特征向量表示。
總體而言,RDSCNN模型具有輕量化的網(wǎng)絡(luò)結(jié)構(gòu),模型結(jié)合了深度可分離卷積、非線性激活函數(shù)Relu和殘差學(xué)習(xí)機(jī)制等,使得參數(shù)量大大降低、收斂速度更快、訓(xùn)練時(shí)間更短,在保留特征信息的同時(shí)降低了數(shù)據(jù)維度,加速了后續(xù)的屬性學(xué)習(xí)過(guò)程。
2.2 屬性學(xué)習(xí)階段
本文提出的多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)旨在學(xué)習(xí)樣本特征中的故障屬性,構(gòu)造可見類和未見類故障特征在高維屬性空間的嵌入,最終實(shí)現(xiàn)故障的診斷。
本文提供了滾動(dòng)軸承故障的細(xì)粒度屬性描述,其主要基于滾動(dòng)軸承故障的損傷程度(7 mil、14 mil、21 mil)、工作負(fù)載(0、1 hp、2 hp)和損傷位置(滾子B、內(nèi)圈IR、外圈OR),如表1所示。依據(jù)故障類別yi是否擁有各個(gè)細(xì)粒度屬性可以得到一個(gè)與之對(duì)應(yīng)的9維二值屬性矢量Ai。

表1 滾動(dòng)軸承故障屬性Tab.1 Rolling bearing fault attributes
每個(gè)故障特征xi對(duì)應(yīng)一個(gè)9維的屬性矢量Ai,即一個(gè)實(shí)例樣本擁有多個(gè)標(biāo)簽,因此,本文將屬性矢量的學(xué)習(xí)過(guò)程看作一個(gè)具有9個(gè)標(biāo)簽的多標(biāo)簽分類問(wèn)題,其多標(biāo)簽屬性空間為29。為了應(yīng)對(duì)輸出空間復(fù)雜度的指數(shù)性增長(zhǎng),本文挖掘了標(biāo)簽之間的相關(guān)性,將屬性矢量A依據(jù)屬性描述的類別作互斥屬性切分,得到三個(gè)細(xì)分屬性矢量a、b、c,與屬性描述對(duì)應(yīng),即原屬性矢量A=concat(a,b,c),將輸出空間減少為3×23,大大降低了屬性學(xué)習(xí)難度。
多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)有監(jiān)督地為每個(gè)細(xì)分屬性矢量構(gòu)造一個(gè)屬性學(xué)習(xí)器,分別記為F1,F(xiàn)2和F3。在測(cè)試階段,使用這些屬性學(xué)習(xí)器對(duì)每一個(gè)未見類樣本預(yù)測(cè)細(xì)分屬性矢量。三個(gè)屬性學(xué)習(xí)器的映射關(guān)系如圖4所示。
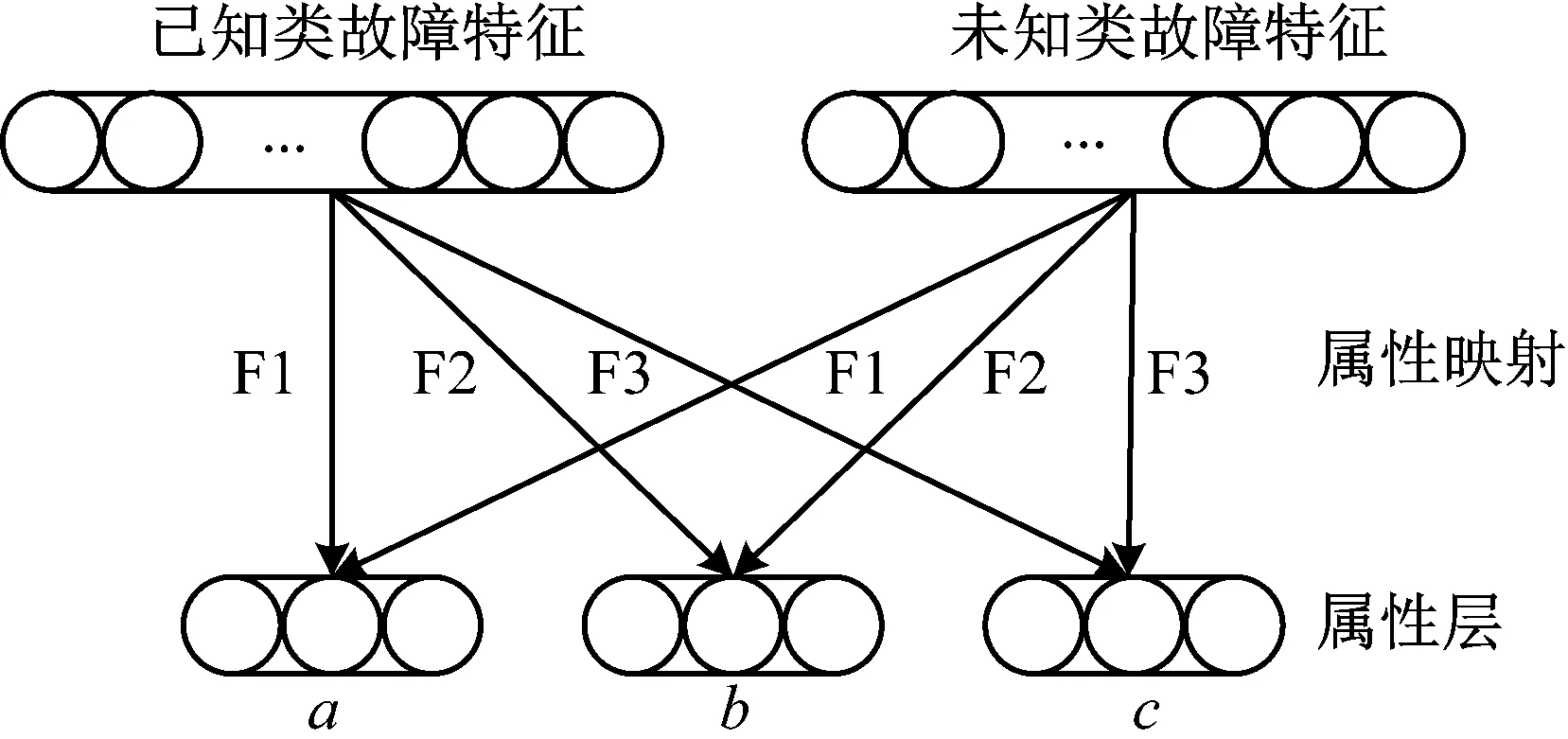
圖4 屬性學(xué)習(xí)器映射關(guān)系Fig.4 Mapping of attribute learners
以屬性學(xué)習(xí)器F1為例,從故障特征xi到細(xì)分屬性矢量ai的推理過(guò)程可表示為f:xi→ai,本文通過(guò)搭建全連接神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)該推理過(guò)程,網(wǎng)絡(luò)結(jié)構(gòu)如圖5所示。
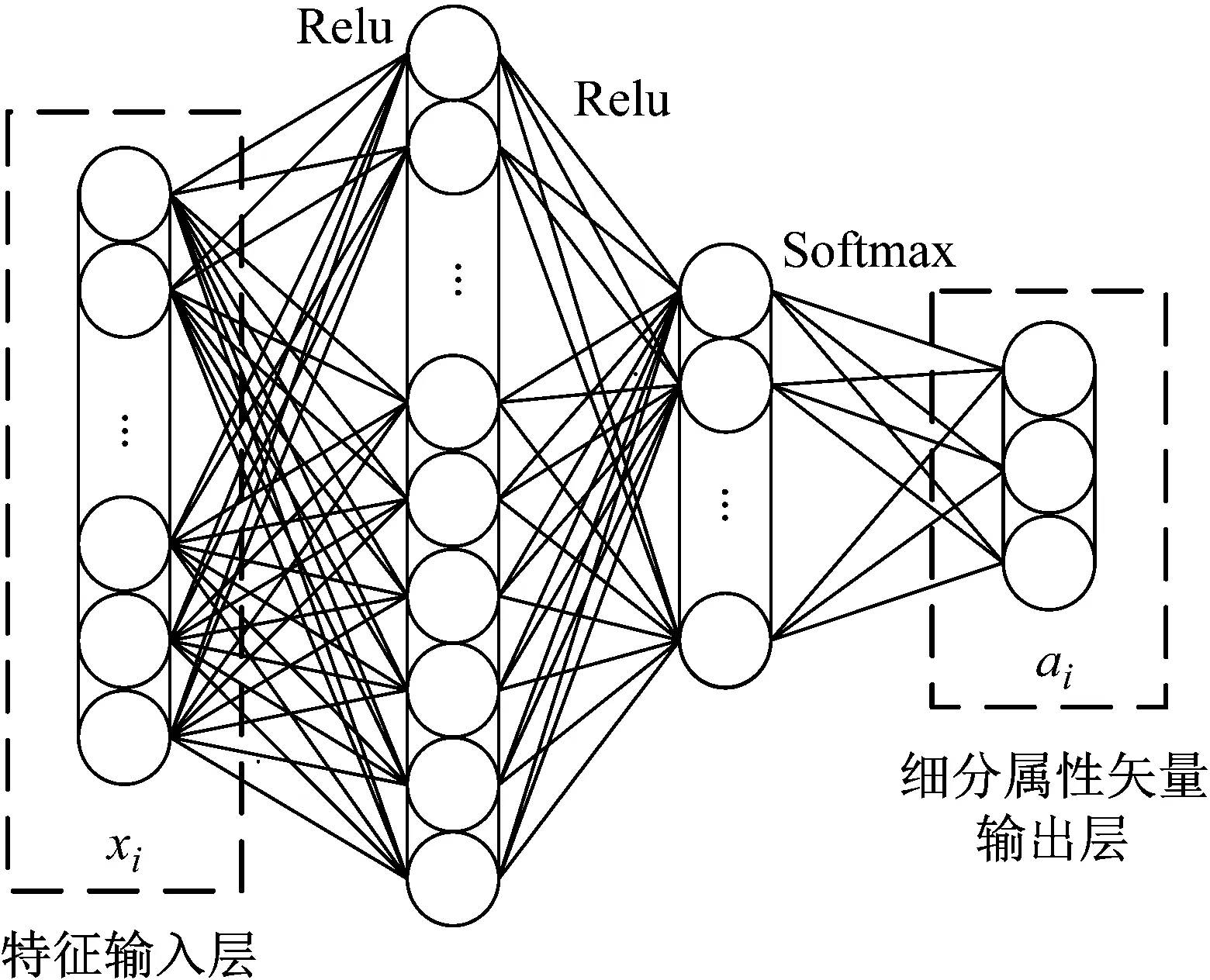
圖5 屬性學(xué)習(xí)器F1網(wǎng)絡(luò)結(jié)構(gòu)Fig.5 Architecture of attribute learner F1
(5)
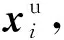
(6)
對(duì)得到的細(xì)分屬性矢量完成拼接,計(jì)算其與各故障屬性標(biāo)簽的余弦距離如式(7)所示,最終取距離最近的故障標(biāo)簽作為其預(yù)測(cè)標(biāo)簽yu。
(7)
整體上,多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)由三個(gè)屬性學(xué)習(xí)器F1、F2和F3組成,各屬性學(xué)習(xí)器分別學(xué)習(xí)一組細(xì)分屬性矢量,組合得到樣本的預(yù)測(cè)屬性標(biāo)簽,最終推導(dǎo)得出樣本的故障類別。
2.3 MLZSL故障診斷流程
基于MLZSL方法的故障診斷流程如圖6所示,主要包含故障信號(hào)預(yù)處理、特征提取和屬性學(xué)習(xí)三個(gè)階段,各階段的具體步驟如下。
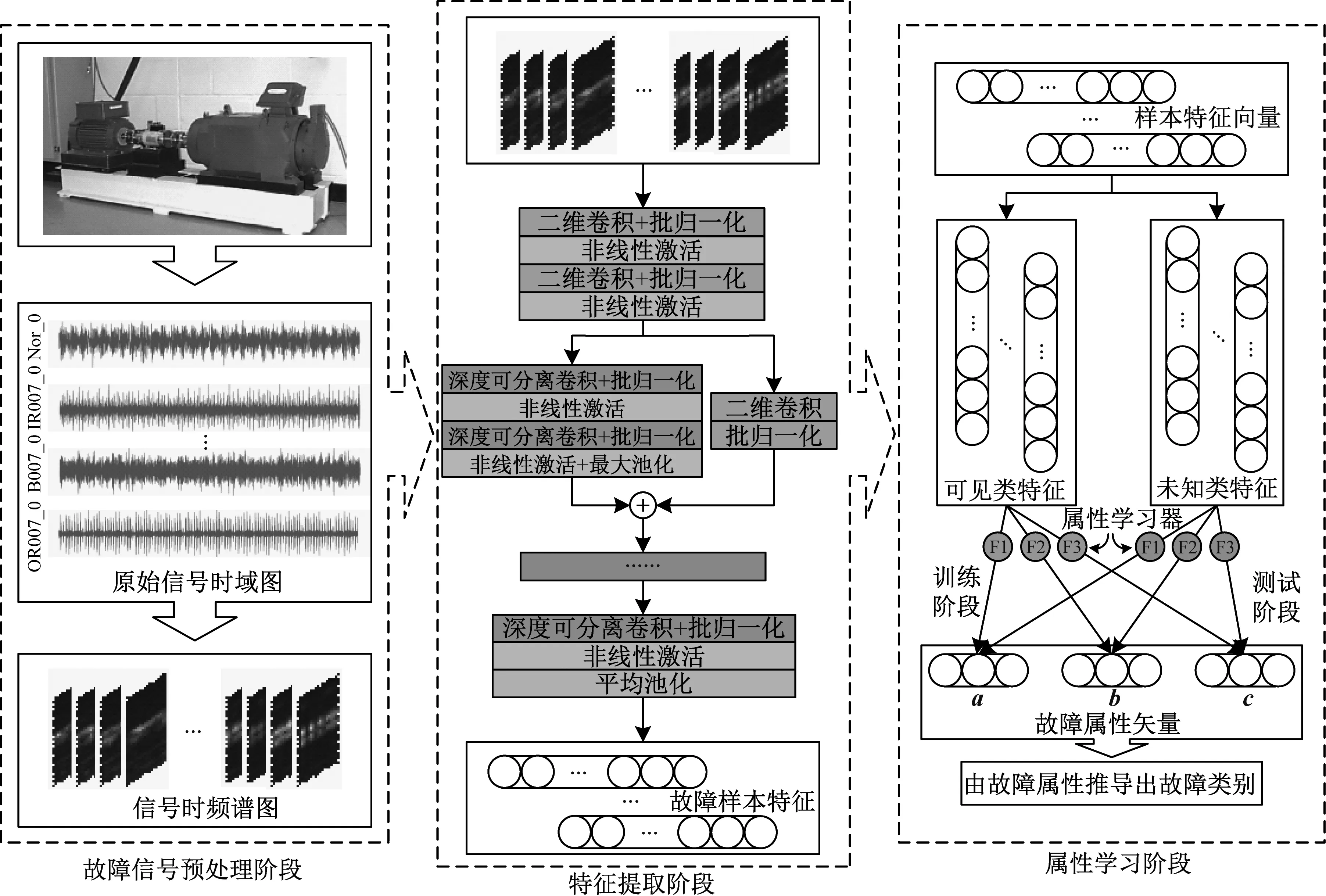
圖6 MLZSL故障診斷流程Fig.6 MLZSL fault diagnosis process
故障信號(hào)預(yù)處理階段:對(duì)采集得到的故障信號(hào)數(shù)據(jù)做預(yù)處理。首先將每一類的信號(hào)序列數(shù)據(jù)切分成一定數(shù)量的樣本;然后對(duì)所有信號(hào)樣本做短時(shí)傅里葉變換,得到維數(shù)為64×64×3的時(shí)頻圖數(shù)據(jù)集;最后按照數(shù)據(jù)的類別標(biāo)簽將其劃分為訓(xùn)練集(可見類)和測(cè)試集(未見類)。
特征提取階段:構(gòu)建RDSCNN模型對(duì)所有樣本完成特征提取。首先組合RDSCNN模型和Softmax層,將訓(xùn)練集作為輸入調(diào)整模型參數(shù);然后保存訓(xùn)練好的RDSCNN模型的各層參數(shù);最后加載保存的參數(shù),借助模型降低輸入時(shí)頻圖數(shù)據(jù)的維度,得到可見類和未見類的故障特征向量。
屬性學(xué)習(xí)階段:使用屬性學(xué)習(xí)網(wǎng)絡(luò)預(yù)測(cè)樣本屬性并推導(dǎo)其標(biāo)簽。首先,以可見類樣本特征作為輸入,訓(xùn)練屬性學(xué)習(xí)網(wǎng)絡(luò)中的各屬性學(xué)習(xí)器;然后使用屬性學(xué)習(xí)器預(yù)測(cè)未見類樣本的細(xì)分屬性矢量,拼接得到完整屬性向量;最終計(jì)算其與各故障屬性標(biāo)簽的余弦距離,完成未見類故障樣本的診斷。
3 試驗(yàn)與結(jié)果分析
3.1 試驗(yàn)數(shù)據(jù)
試驗(yàn)數(shù)據(jù)采用的是凱斯西儲(chǔ)大學(xué)提供的軸承故障數(shù)據(jù)集[26],試驗(yàn)臺(tái)由電動(dòng)機(jī)、扭矩傳感器、測(cè)力計(jì)和控制電子設(shè)備組成。本文從采樣頻率為12 kHz的驅(qū)動(dòng)端數(shù)據(jù)中,依據(jù)不同的工作負(fù)載、損傷位置和損傷程度選取了共30類數(shù)據(jù)進(jìn)行試驗(yàn)。其中包括健康數(shù)據(jù)3類,故障數(shù)據(jù)27類,所選取數(shù)據(jù)的類別組成如表2所示。
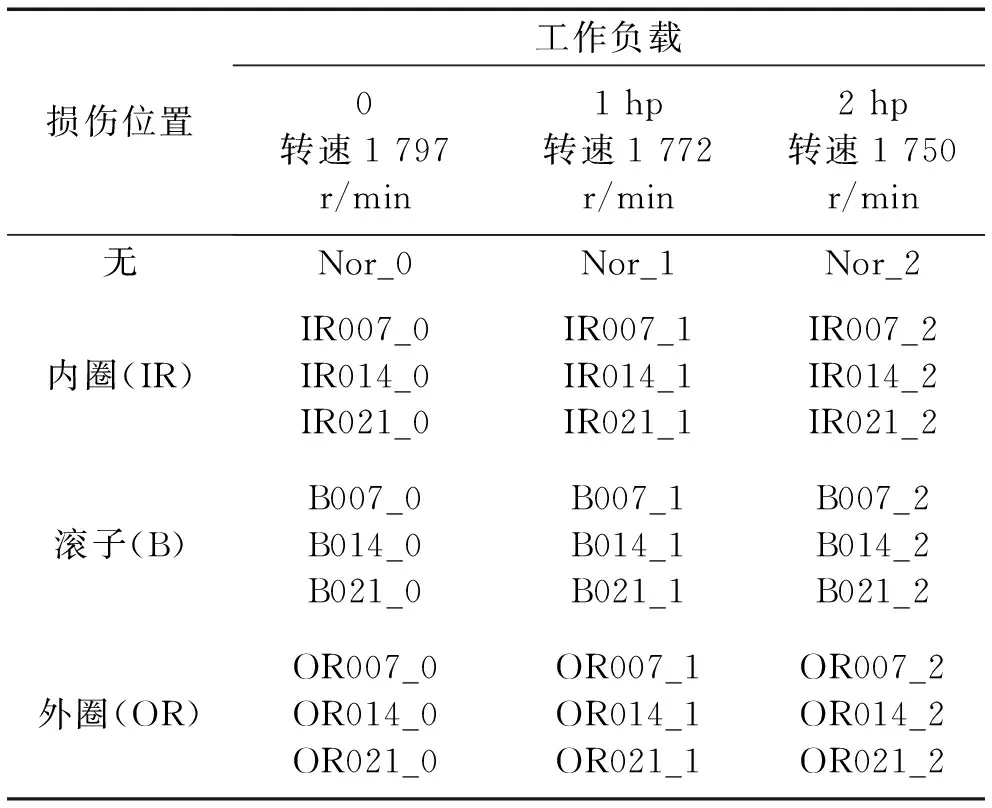
表2 試驗(yàn)數(shù)據(jù)種類Tab.2 Kinds of test data
滾動(dòng)軸承故障信號(hào)的三種損傷位置分別為內(nèi)圈(IR)、滾子(B)和外圈(OR),三種工作負(fù)載分別為0(1 hp=746 W)、1 hp和2 hp,三種損傷程度分別為7 mil(1 mil=0.025 4 mm)、14 mil和21 mil。表2中滾動(dòng)軸承故障的具體類別,例如‘IR007_0’中‘IR’代表該故障的故障位置是內(nèi)圈,‘007’表示該類故障的損傷程度為7 mil,‘_0’表示其工作負(fù)載為0。表中各類別試驗(yàn)數(shù)據(jù)的采樣頻率為12 kHz,每一類數(shù)據(jù)取連續(xù)102 912點(diǎn),窗口滑動(dòng)截取1 024個(gè)點(diǎn)作為樣本,窗重疊50%,每一類數(shù)據(jù)得到200個(gè)樣本,最終共獲取6 000個(gè)樣本。
試驗(yàn)前對(duì)原始數(shù)據(jù)進(jìn)行短時(shí)傅里葉變換,以獲得數(shù)據(jù)中隨時(shí)間變化的頻譜信息,使用Hanmming窗作為窗函數(shù)并預(yù)設(shè)了窗函數(shù)長(zhǎng)度為120,窗重疊度為50%,最終獲得30類數(shù)據(jù)的共6 000張時(shí)頻圖樣本。
依據(jù)零樣本的原則對(duì)數(shù)據(jù)集進(jìn)行劃分,在27類故障數(shù)據(jù)中隨機(jī)選取6類故障樣本作為測(cè)試集(未見類),剩余數(shù)據(jù)類別組成訓(xùn)練集(可見類)。總共進(jìn)行四次隨機(jī)選取,在四種數(shù)據(jù)集劃分方式下得到數(shù)據(jù)集A、B、C、D,表3展示了各數(shù)據(jù)集下的測(cè)試類別。在每一種數(shù)據(jù)劃分方式下,數(shù)據(jù)集中的訓(xùn)練樣本數(shù)為4 800,測(cè)試樣本數(shù)為1 200。

表3 試驗(yàn)數(shù)據(jù)集Tab.3 The test data sets
3.2 試驗(yàn)過(guò)程與結(jié)果分析
試驗(yàn)首先由RDSCNN模型從時(shí)頻圖樣本中提取易于學(xué)習(xí)屬性的特征向量,再將特征向量輸入到多標(biāo)簽屬性學(xué)習(xí)器,識(shí)別故障的屬性,最后計(jì)算與標(biāo)簽屬性之間的余弦距離得到故障類別。
(1) 特征提取試驗(yàn)與結(jié)果分析
根據(jù)第2.1節(jié)所述的RDSCNN模型結(jié)構(gòu)搭建網(wǎng)絡(luò),通過(guò)反復(fù)試驗(yàn)最終確定RDSCNN模型的相關(guān)超參數(shù)如表4所示。按照輸出特征圖的大小,表4將整個(gè)網(wǎng)絡(luò)劃分為五個(gè)模塊,模塊一輸入大小為64×64×3的時(shí)頻圖樣本,從模塊一至模塊四,依次減小特征圖大小,最終輸出大小為1×128的特征向量。

表4 RDSCNN模型超參數(shù)設(shè)置Tab.4 Hyper-parameters of RDSCNN
RDSCNN模型在特征提取階段為使用較大感受野,模塊一中殘差連接卷積核設(shè)置為3×3。為了保留局部細(xì)節(jié),模塊二和模塊三中跳躍連接卷積核設(shè)置為1×1,模塊四中最后池化層為降低輸出維數(shù)將池化窗口設(shè)置為8×8,其余模塊主干網(wǎng)絡(luò)中卷積核和池化窗口均設(shè)置為3×3。整個(gè)網(wǎng)絡(luò)的卷積核數(shù)量遞增以充分映射特征,各卷積層中卷積核的數(shù)目與輸出的第三個(gè)維度一致,在降低特征圖大小的同時(shí)增加特征深度。
RDSCNN模型在訓(xùn)練階段使用交叉熵?fù)p失函數(shù),并采用指數(shù)衰減法自動(dòng)調(diào)整學(xué)習(xí)率,設(shè)置初始學(xué)習(xí)率為0.02,衰減步長(zhǎng)為40,衰減率為0.97,設(shè)置單批次樣本數(shù)為100個(gè)。
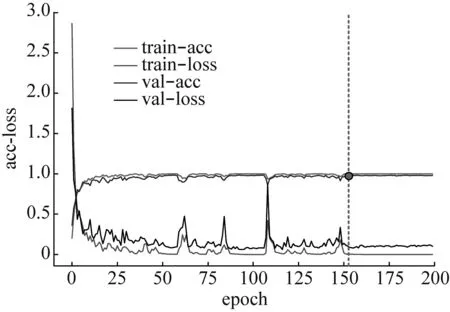
為了驗(yàn)證RDSCNN模型相比當(dāng)前主流的特征提取模型在特征提取效率和性能上的優(yōu)越性,本文將其與ResNet50、VGG16和CNN(由5層卷積層和3層全連接層組成)模型進(jìn)行對(duì)比。表5顯示了RDSCNN、ResNet50、VGG16和CNN四種不同模型的總參數(shù)量、收斂穩(wěn)定所需要epoch(所有訓(xùn)練樣本在模型中完成了一次正向傳遞和一次反向傳遞)的數(shù)目和訓(xùn)練200個(gè)epoch所用的時(shí)長(zhǎng)。各模型在訓(xùn)練過(guò)程中準(zhǔn)確率和損失的變化情況如圖7所示,為提高對(duì)比效果,僅截取前200個(gè)epoch進(jìn)行展示。

表5 特征提取模型訓(xùn)練情況對(duì)比Tab.5 Comparison of feature extraction models

(a) RDSCNN模型
(b) ResNet50模型
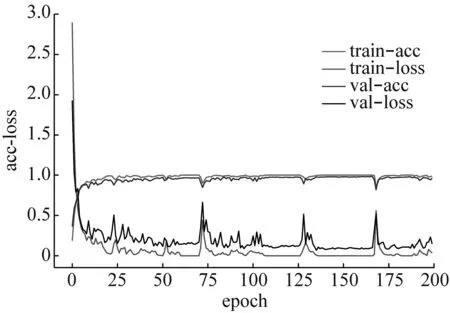
(c) VGG16模型

(d) CNN模型圖7 不同特征提取模型的準(zhǔn)確率和損失變化情況Fig.7 Accuracy and loss of different feature extraction models
通過(guò)表5可以知道,RDSCNN模型的參數(shù)量?jī)H為924 064,CNN模型的參數(shù)量為其十倍左右,而ResNet50和VGG16模型的參數(shù)量均在其十倍以上;其次,RDSCNN模型訓(xùn)練200個(gè)epoch所用的時(shí)間僅為223.2 s,較其他三種模型更短;此外,RDSCNN模型在訓(xùn)練125epoch時(shí)已經(jīng)收斂穩(wěn)定,ResNet50模型在訓(xùn)練150epoch時(shí)收斂穩(wěn)定,如圖7中虛線處所示,而VGG16和CNN模型在訓(xùn)練200epoch時(shí)仍未穩(wěn)定收斂。除此之外,從圖7中還可以看出,借助卷積網(wǎng)絡(luò)在自適應(yīng)特征學(xué)習(xí)上的優(yōu)勢(shì),各模型的訓(xùn)練準(zhǔn)確率都很高,但是在VGG16和CNN模型的訓(xùn)練過(guò)程中存在一定的過(guò)擬合,其驗(yàn)證集的準(zhǔn)確率均低于訓(xùn)練集的準(zhǔn)確率。綜上所述,相較于其他三種特征提取模型,RDSCNN模型在模型參數(shù)量、收斂速度和訓(xùn)練效果等方面具有明顯優(yōu)勢(shì)。
為進(jìn)一步驗(yàn)證RDSCNN模型的特征提取能力,采用t-SNE降維算法將原始輸入和所提取特征按相似度投影到2維空間中進(jìn)行分析。在RDSCNN、ResNet50、VGG16和CNN四種特征提取模型中,VGG16和CNN模型的訓(xùn)練效果較差,ResNet50模型的訓(xùn)練效果更接近RDSCNN模型,因此選擇ResNet50模型與RDSCNN模型進(jìn)行特征降維對(duì)比。以數(shù)據(jù)集C為例,將測(cè)試集樣本作為RDSCNN模型和ResNet50模型的輸入,學(xué)習(xí)得到樣本的特征。對(duì)原始輸入和兩個(gè)模型輸出的樣本特征分別進(jìn)行t-SNE降維可視化,可視化結(jié)果如圖8所示。
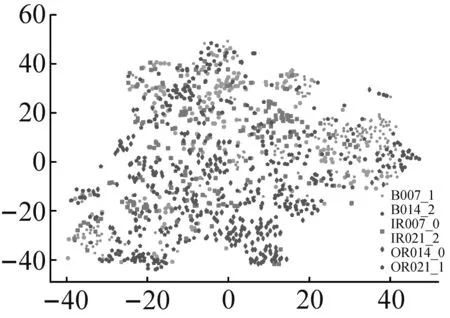
(a) 原始樣本輸入
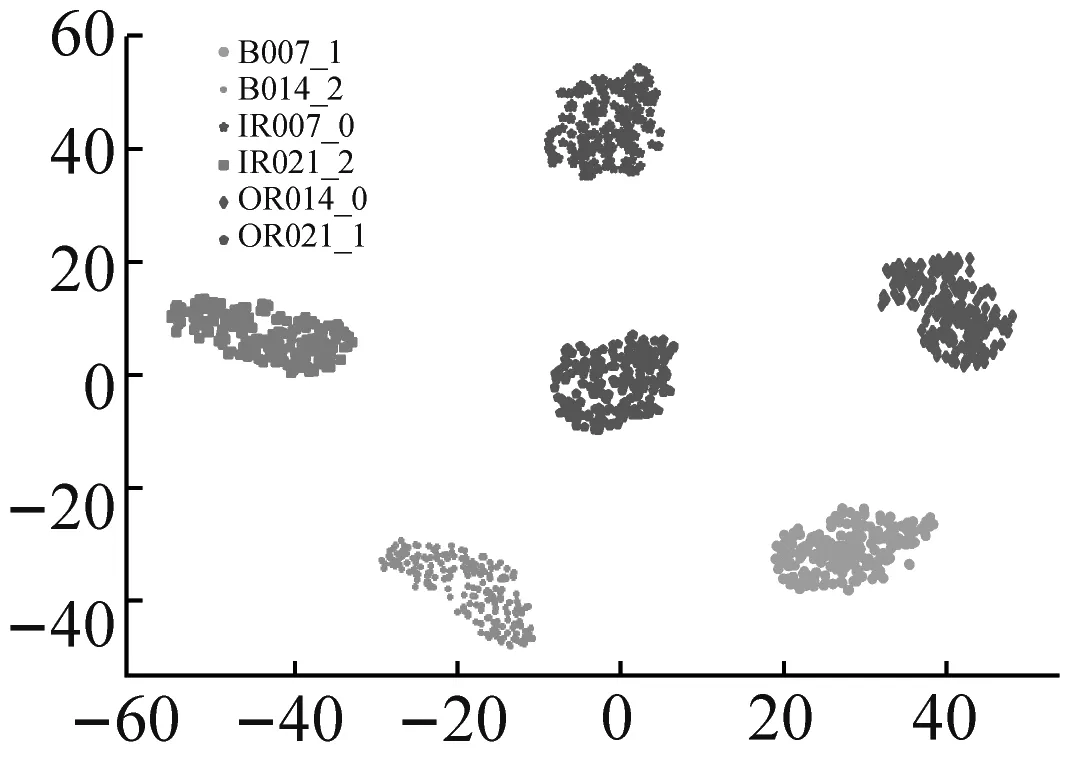
(b) RDSCNN模型輸出
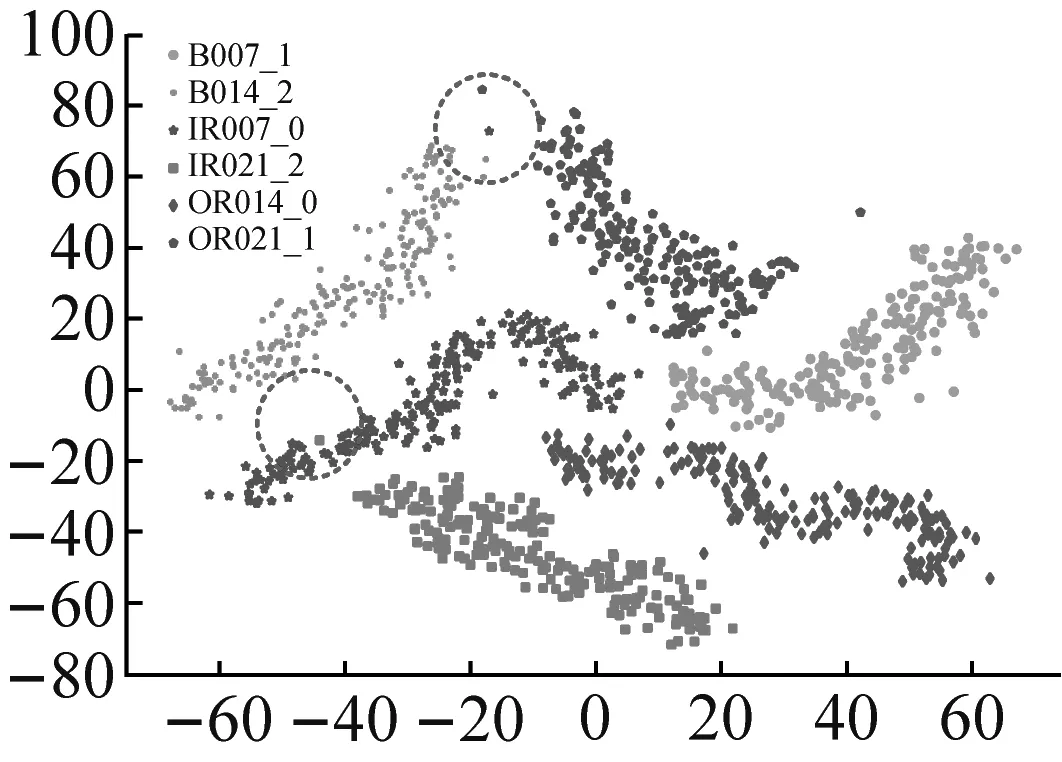
(c) ResNet50模型輸出圖8 原始輸入和不同模型的輸出特征可視化Fig.8 Visualization of original input and different models’ output characteristics
圖8(a)為原始輸入的可視化結(jié)果,可以看出原始輸入包含很多冗余信息,難以區(qū)分各類樣本。圖8(b)為RDSCNN模型輸出特征的可視化結(jié)果,經(jīng)過(guò)RDSCNN模型提取特征后,6類故障樣本之間界限清晰,完全被區(qū)分開,且不同標(biāo)簽的樣本在2維空間中分布很集中,沒(méi)有錯(cuò)分的異類樣本。圖8(c)為ResNet50模型輸出特征的可視化結(jié)果,圖中各類樣本之間有一定的區(qū)分性,但界限不清晰,紅色虛線圈中部分還存在錯(cuò)分現(xiàn)象。對(duì)比圖8(b)和圖8(c)可知,RDSCNN模型所提取的特征在相同標(biāo)簽下聚合得更集中,可分性更好。
為驗(yàn)證所提取特征的有效性,本文對(duì)所提取的特征進(jìn)行了分類效果的對(duì)比。表6展示了基于同一數(shù)據(jù)集,使用RDSCNN、MLDAM[27]、CNN-RF[28]、1DRCAE方法進(jìn)行分類試驗(yàn)的精度。可以看出,RDSCNN模型的分類準(zhǔn)確率為99.93%,優(yōu)于其他方法。

表6 各先進(jìn)識(shí)別器的分類精度Tab.6 Classification accuracy of advanced recognizers %
總體而言,RDSCNN模型在參數(shù)量最少的情況下,模型的訓(xùn)練速度更快,具有更好的特征提取能力。
(2) 多標(biāo)簽屬性學(xué)習(xí)試驗(yàn)與結(jié)果分析
試驗(yàn)按照2.2節(jié)中的屬性設(shè)置原則,為每種滾動(dòng)軸承故障定義了9維的屬性矢量Ai∈R9,以提供故障特征在屬性空間映射的對(duì)象。該屬性矢量由滾動(dòng)軸承故障的細(xì)粒度屬性描述推理得到,屬性描述基于滾動(dòng)軸承故障的損傷程度、工作負(fù)載和損傷位置。基于屬性之間的相關(guān)性對(duì)互斥屬性進(jìn)行切分,得到三個(gè)細(xì)分屬性矢量a、b、c,三個(gè)細(xì)分屬性矢量均屬于實(shí)向量空間R3。試驗(yàn)采用熱獨(dú)編碼的方式對(duì)與故障標(biāo)簽yi對(duì)應(yīng)的細(xì)分屬性矢量ai、bi、ci進(jìn)行編碼,編碼維度為3,得到向量映射onehot(ai)、onehot(bi)、onehot(ci),則與故障標(biāo)簽yi對(duì)應(yīng)的屬性矢量編碼為Ai=concat(onehot(ai,bi,ci)),例如B007_1的損傷程度為7 mil、工作負(fù)載為1 hp、損傷位置為滾子,其屬性矢量編碼為‘100 010 100’。依據(jù)此原則,試驗(yàn)為所有滾動(dòng)軸承健康狀況定義了對(duì)應(yīng)的屬性矢量。
本試驗(yàn)的屬性學(xué)習(xí)網(wǎng)絡(luò)由三個(gè)結(jié)構(gòu)參數(shù)相同的屬性學(xué)習(xí)器構(gòu)成,其超參數(shù)設(shè)置如表7所示。屬性學(xué)習(xí)網(wǎng)絡(luò)將特征提取網(wǎng)絡(luò)輸出的特征映射到屬性空間,單個(gè)屬性學(xué)習(xí)器由三層全連接層組成,前兩層使用Relu作為激活函數(shù),提高收斂效率,最后一層使用Softmax輸出分類結(jié)果,選取Adam作為優(yōu)化器,學(xué)習(xí)率設(shè)置為1×10-4。為防止屬性學(xué)習(xí)器過(guò)擬合,在前兩層中引入dropout,并分別設(shè)置keep_prob分別為0.5和0.7。
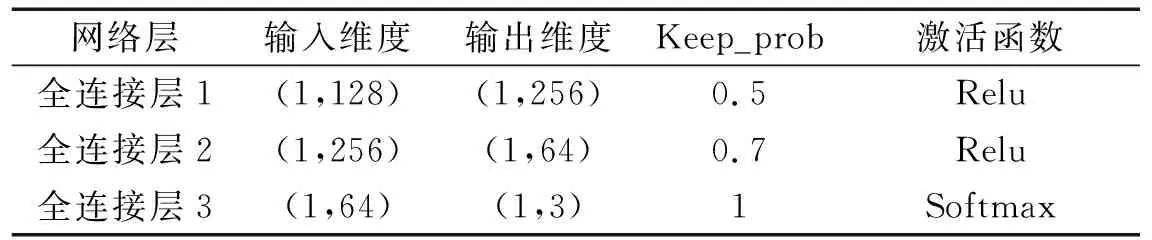
表7 屬性學(xué)習(xí)器超參數(shù)設(shè)置Tab.7 Hyper-parameters of attribute learner
在表3中的四種數(shù)據(jù)集下,使用屬性學(xué)習(xí)網(wǎng)絡(luò)識(shí)別訓(xùn)練集(可見類)和測(cè)試集(未見類)的各個(gè)屬性,試驗(yàn)結(jié)果中各屬性的平均識(shí)別準(zhǔn)確率如圖9所示。
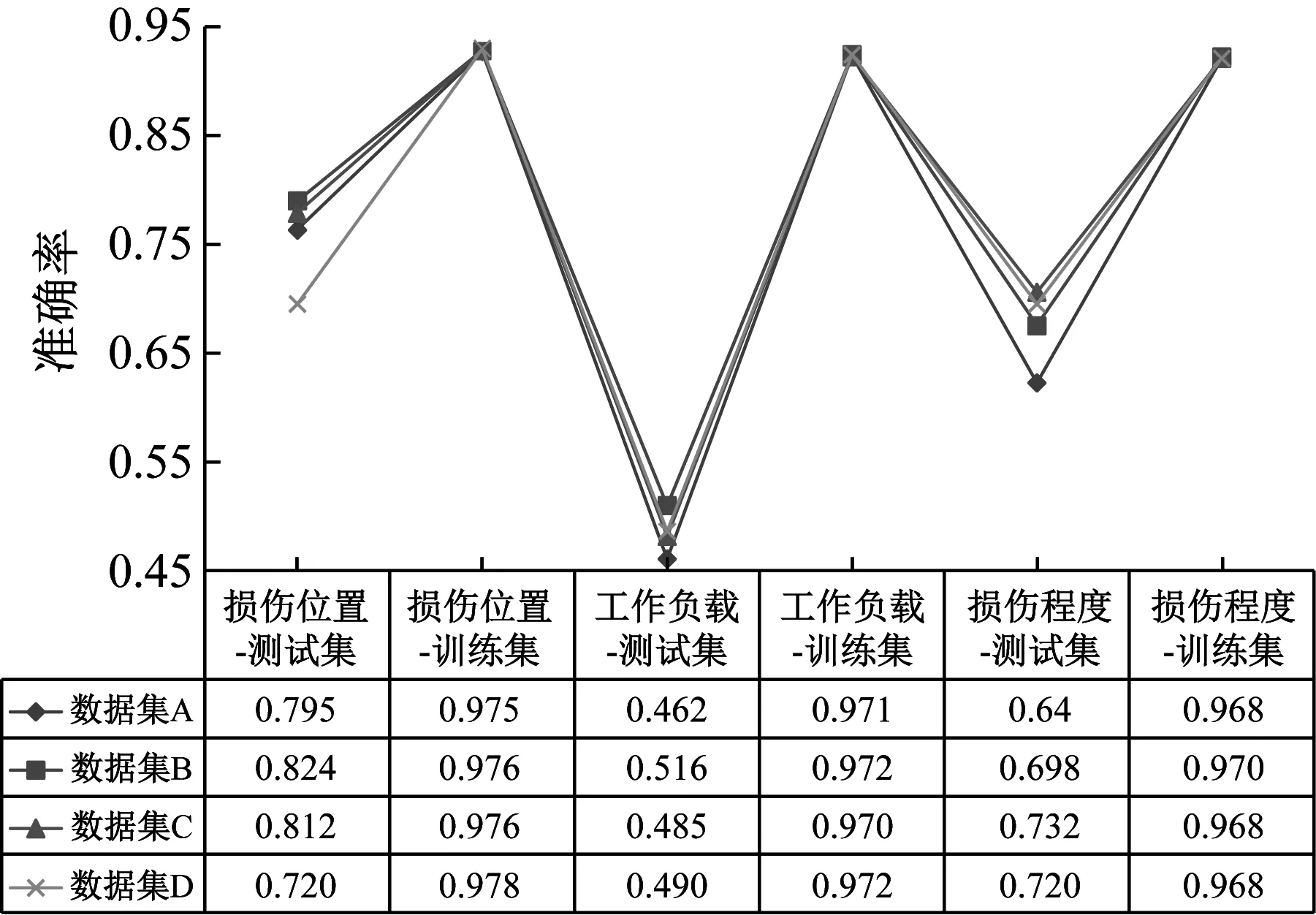
圖9 不同數(shù)據(jù)集劃分方式下的屬性識(shí)別準(zhǔn)確率Fig.9 Attribute recognition accuracy under different data set partition methods
橫向?qū)Ρ葓D9中多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)對(duì)四種數(shù)據(jù)集的識(shí)別準(zhǔn)確率,可知各類識(shí)別精度受數(shù)據(jù)集劃分方式的影響不大,平均準(zhǔn)確率波動(dòng)在±4%左右,具有較強(qiáng)的泛化性。多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)對(duì)各屬性的識(shí)別精度均高于33.3%的隨機(jī)水平,以數(shù)據(jù)集A為例,多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)對(duì)測(cè)試集在損傷位置、工作負(fù)載和損傷程度上的屬性識(shí)別準(zhǔn)確率分別為79.5%、46.2%和64%,對(duì)訓(xùn)練集的識(shí)別準(zhǔn)確率分別為97.5%、97.1%和96.8%,如圖9中折線所示。因?yàn)樵囼?yàn)遵循零樣本設(shè)置,所有的測(cè)試集樣本均未參與訓(xùn)練,且參與訓(xùn)練的測(cè)試集與訓(xùn)練集樣本沒(méi)有標(biāo)簽上的交集,因此測(cè)試集和訓(xùn)練集的識(shí)別準(zhǔn)確率無(wú)法進(jìn)行比較。試驗(yàn)結(jié)果證明所提出的屬性學(xué)習(xí)網(wǎng)絡(luò)可以有效學(xué)習(xí)故障屬性。
由多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)得到測(cè)試集樣本對(duì)應(yīng)的屬性矢量后,通過(guò)計(jì)算各樣本屬性矢量與各類故障屬性編碼之間的余弦距離,最終確定故障類別。在四種數(shù)據(jù)集下,對(duì)比MLZSL方法與其他零樣本學(xué)習(xí)方法的識(shí)別準(zhǔn)確率,如表8所示。
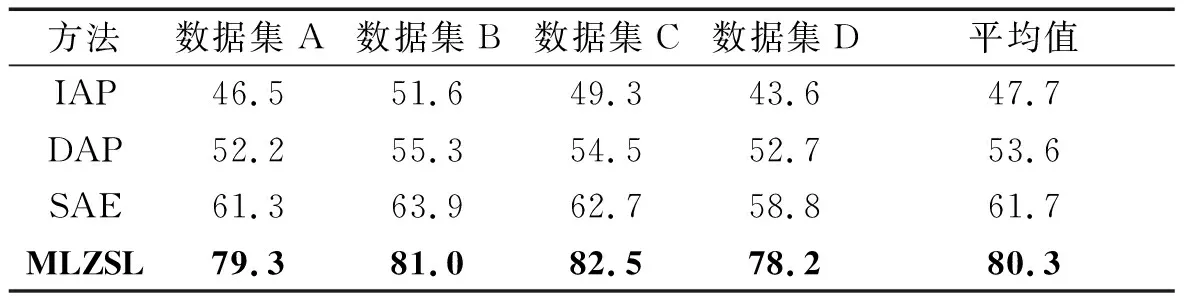
表8 軸承狀態(tài)的識(shí)別準(zhǔn)確率Tab.8 Identification accuracy of bearing states
IAP方法將屬性層置于訓(xùn)練集標(biāo)簽層與測(cè)試集標(biāo)簽層之間,通過(guò)遷移訓(xùn)練集樣本的標(biāo)簽與屬性信息來(lái)預(yù)測(cè)測(cè)試集樣本的標(biāo)簽,識(shí)別效果較差,平均識(shí)別準(zhǔn)確率最低,僅為47.7%。DAP方法引入了中間層,從訓(xùn)練集樣本中學(xué)習(xí)屬性分類器,直接預(yù)測(cè)測(cè)試集樣本的屬性,但DAP沒(méi)有學(xué)習(xí)到屬性之間的關(guān)系,其平均識(shí)別準(zhǔn)確率為53.6%,略高于IAP方法。SAE方法使用了自編碼器的結(jié)構(gòu),要求特征輸入映射到屬性層后,能夠重新映射回原來(lái)的特征,通過(guò)這一結(jié)構(gòu)盡可能保留特征信息,擁有較高的準(zhǔn)確率,平均識(shí)別準(zhǔn)確率為61.7%。MLZSL方法通過(guò)有監(jiān)督的神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)與屬性相關(guān)的特征,多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)從特征中預(yù)測(cè)測(cè)試集樣本的屬性,同時(shí)考慮了屬性之間的關(guān)系,其平均診斷準(zhǔn)確率為80.3%,高于其他三種方法,如表8所示。
為了更清晰地展示MLZSL方法對(duì)測(cè)試集故障的識(shí)別效果,將其與準(zhǔn)確率較高的SAE方法進(jìn)行對(duì)比,以數(shù)據(jù)集C為例,繪制了兩種方法屬性識(shí)別結(jié)果的混淆矩陣,如圖10所示。
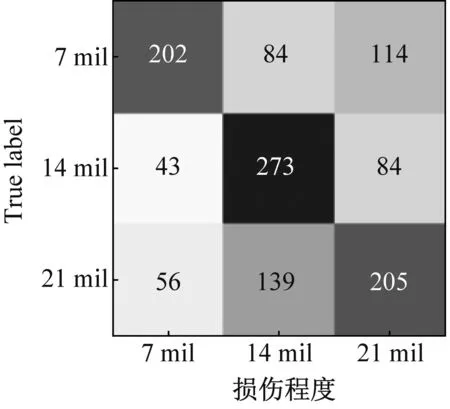
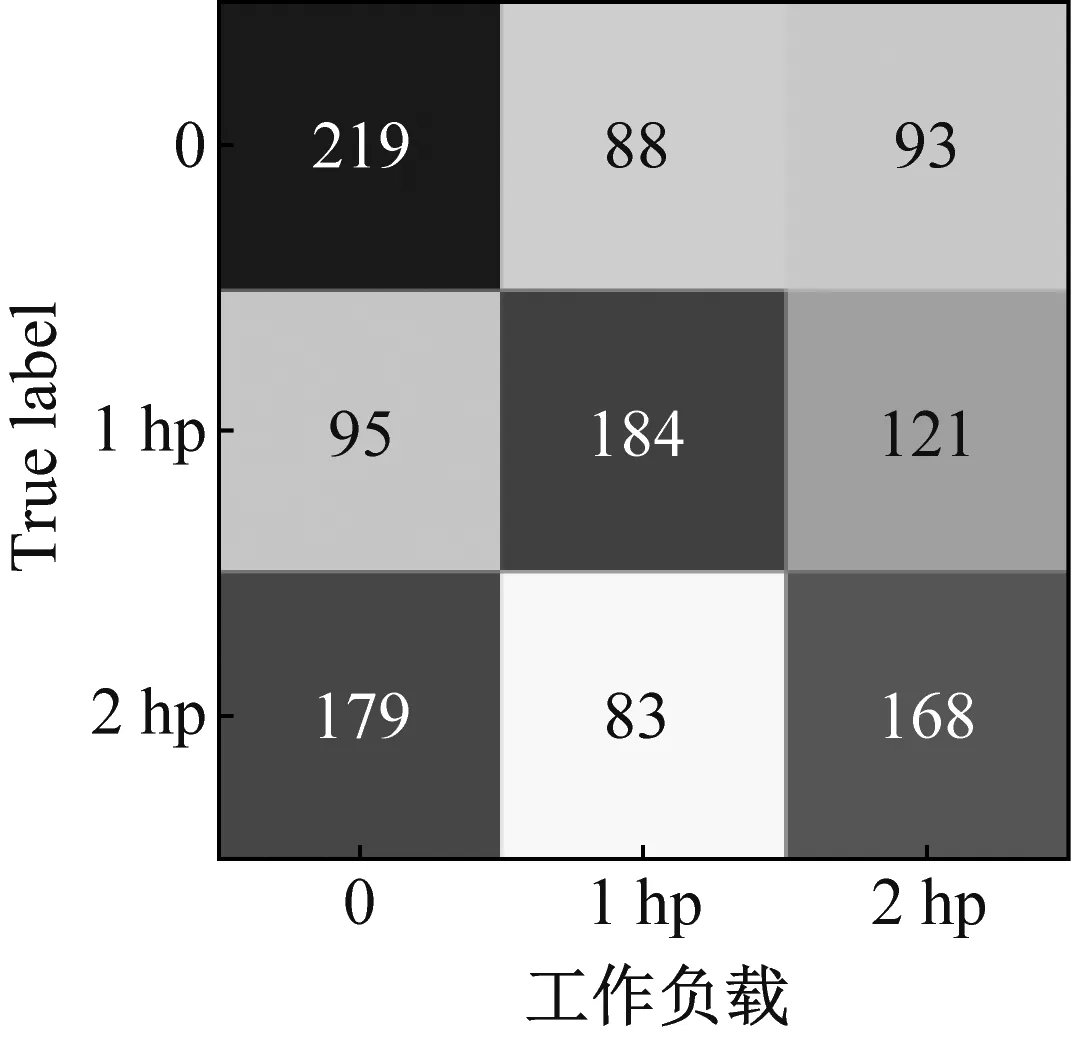
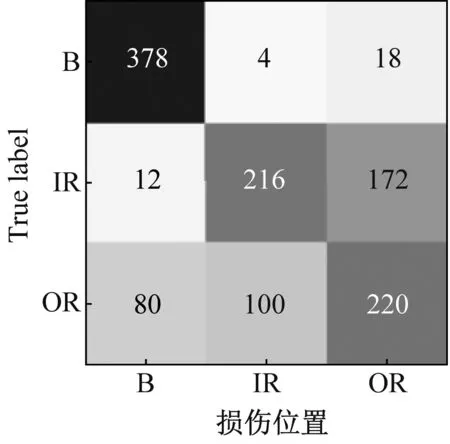
(a) SAE方法

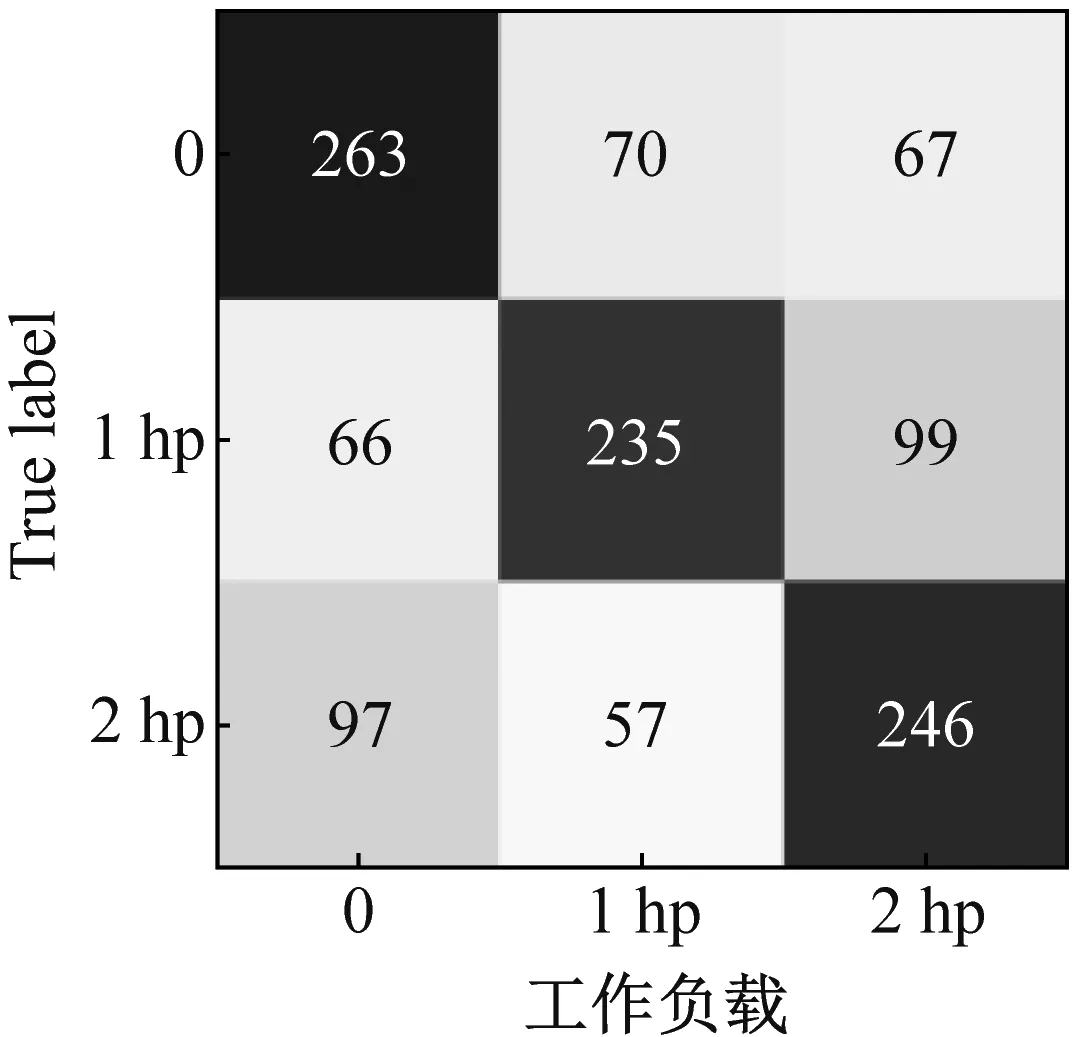

(b) MLZSL方法圖10 MLZSL方法和SAE方法的屬性預(yù)測(cè)混淆矩陣Fig.10 Attribute prediction confusion matrix of MLZSL and SAE
圖10(a)和圖10(b)中,從左至右依次是損傷程度、工作負(fù)載和損傷位置的屬性識(shí)別混淆矩陣,橫坐標(biāo)表示屬性的預(yù)測(cè)類別,縱坐標(biāo)表示屬性的真實(shí)類別。對(duì)比SAE方法和MLZSL方法對(duì)損傷程度、工作負(fù)載和損傷位置的屬性識(shí)別混淆矩陣可知:(1)對(duì)于故障樣本的損傷程度,用SAE方法識(shí)別屬性時(shí),三種損傷程度屬性均有大量樣本被錯(cuò)分,例如圖10(a)中,損傷程度為7 mil的故障樣本僅有202個(gè)被準(zhǔn)確識(shí)別;而采用MLZSL方法后,對(duì)損傷程度的預(yù)測(cè)準(zhǔn)確率大大提升,例如在圖10(b)中,損傷程度為7 mil的樣本有296個(gè)被準(zhǔn)確識(shí)別,比SAE方法增加了94個(gè)。(2)使用SAE方法識(shí)別故障樣本的工作負(fù)載屬性時(shí),三種工作負(fù)載的預(yù)測(cè)情況很差,例如圖10(a)中,工作負(fù)載1 hp和2 hp分別只有184和168個(gè)樣本被準(zhǔn)確識(shí)別;采用MLZSL方法后,工作負(fù)載預(yù)測(cè)準(zhǔn)確率得到很大改善,例如圖10(b)中,工作負(fù)載1 hp和2 hp中被正確識(shí)別的樣本數(shù)分別增加了51和78個(gè)。(3)在預(yù)測(cè)樣本的損傷位置屬性時(shí),SAE方法僅對(duì)損傷位置B的預(yù)測(cè)結(jié)果較好,其余屬性均存在不同程度的錯(cuò)分,例如圖10(a)中,損傷位置IR有172個(gè)樣本被錯(cuò)分為OR;而使用MLZSL方法識(shí)別損傷位置IR時(shí),如圖10(b)所示,總共僅有77個(gè)樣本被錯(cuò)分,其余屬性被準(zhǔn)確識(shí)別的樣本也顯著增多。綜上可知,MLZSL方法在各個(gè)屬性上的誤判數(shù)目均低于SAE方法,對(duì)各屬性的識(shí)別能力更優(yōu)秀,且具有較高的診斷準(zhǔn)確率。
綜合上述試驗(yàn)驗(yàn)證,MLZSL方法在零樣本條件下,能夠更準(zhǔn)確的學(xué)習(xí)屬性并預(yù)測(cè)故障類別,且具有較好的泛化性。
4 結(jié) 論
本文提出的MLZSL方法由RDSCNN特征提取模型和多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)組成。MLZSL方法實(shí)現(xiàn)了故障特征空間到故障屬性空間的映射,將可見類的故障屬性遷移到未見類,有效地診斷了未見類故障,試驗(yàn)結(jié)果表明:
(1) 與常用的特征提取模型相比,RDSCNN模型參數(shù)量少、收斂速度快、訓(xùn)練耗時(shí)短。該模型提取的特征具有更好的可分性,從所提取的特征中能夠更有效的學(xué)習(xí)與屬性相關(guān)的信息。
(2) 多標(biāo)簽屬性學(xué)習(xí)網(wǎng)絡(luò)可以同時(shí)映射多個(gè)互斥屬性,降低了模型復(fù)雜度,同時(shí)提升了診斷的準(zhǔn)確率,在不同的測(cè)試數(shù)據(jù)集中都能夠診斷未見類樣本,泛化性較好。
(3) 所提出的MLZSL故障診斷方法為每一類故障提供了由屬性組成的故障輔助標(biāo)簽,這一屬性層介于故障特征層和故障類別層之間。所定義的屬性跨越了故障類別界限,不同類別的故障可以共享這些屬性。
MLZSL故障診斷方法能夠在零樣本條件下識(shí)別未見類故障,適用范圍更廣,其輕量化的模型結(jié)構(gòu)使其診斷結(jié)果具有很高的時(shí)效性,為零樣本條件下的軸承故障診斷提供了解決方法。
猜你喜歡
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維護(hù)與修理(2015年2期)2015-02-28 12:15:39
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
