基于CUDA加速的多模態膝關節圖像配準
2022-06-27 08:29:10蒲云潔王學淵
制造業自動化 2022年3期
蒲云潔,王學淵
(西南科技大學 信息工程學院,綿陽 621000)
0 引言
隨著社會醫療技術的發展,使用計算機影像輔助醫生進行外科手術已經逐漸成為趨勢,而這其中最重要的一環就是圖像的配準。醫學圖像以模態劃分可以分成多種:CT,MRI,PET,X光,內窺鏡圖像等,以圖像維度劃分可以分為二維圖像和三維圖像。二維圖像較三維圖像缺乏很多有用的空間信息,因此將這兩種模態的圖像進行信息配準融合,從而定位患者手術過程中的靶區,顯得尤為重要。本文研究的內容就是CT斷層圖像和X光圖像之間的配準,這是一種多模態配準模式,也是一種2D/3D配準模式。目前常用的2D/3D配準方法主要分為以下3種:
1)基于圖像灰度的配準算法[1],該方法一般是先用DRR算法模擬X光圖像的生成,從患者術前采集的三維體數據中得出多幅DRR圖像來和術中采集的X光照片進行相似性判定配準,此算法精度高,但耗費的時間較長,適用于剛體之間的配準。
2)基于圖像特征的配準算法[2],該方法依賴在病人身上提前做好的標記點或者人體內固有的標記點進行定位,計算出相應的空間變換,進而計算出待配準圖像中對應標記點的最短特征距離,從而達到配準的目的,此方法的配準速度雖然很快,但是精度與標記點的選取有很大的關聯,魯棒性也比較差。
3)基于以上兩類方法結合的配準算法,即既需要計算出待配準圖像對應標記點的空間變換和最短特征距離,也需要利用相似性原理進行配準,配準速度快精度也好,但此方法捕捉范圍較小,魯棒性較差。
本文根據以上三種配準方法提出一種基于CUDA加速的多模態配準方法,該方法基于圖像灰度,在DRR圖像生成上采用光線投射算法,先進行剛體變換粗配準,再采用梯度方向(Gradient orientation,GO)測度進行相似性測度,進而精配準,在參數優化上采用自適應協方差矩陣進化算法(CMA-ES),并且在DRR圖像生成和相似性測度這兩個耗時最大的過程采用支持CUDA架構的GPU處理器進行加速,最大化的減少配準時間。
1 DRR圖像生成
DRR(Digitally Reconstructed Radiograph)數字影像重建技術是2D/3D醫學圖像配準的關鍵技術,也是最耗時最影響配準精度的步驟,它最終目的是為了從三維體數據中獲取一系列模擬的二維X射線圖像。獲取DRR圖像的算法主要有:拋雪球法(Splatting)、光線投射法(Ray-Casting)、剪切變形法(Shear-Warp)等。本文使用的是光線投射算法。
1.1 光線投射算法
光線投射算法是模擬X射線穿透三維體數據元(本文用的數據是CT體數據),經過衰減和吸收后投影到DRR平面,就形成了一張DRR圖像,形成過程如圖1所示。

圖1 光線投影示意圖
光線投射算法生成DRR圖像具體過程如下:當虛擬X光源發出射線以一定的步長穿透3D體數據時,沿著其行進方向采集CT值,再把得到的CT值轉化成相應的衰減系數μj,累加此方向上的衰減系數,從而計算得到射線到達DRR平面上的電子強度I,最后形成DRR圖像。
DRR圖像生成過程中,若入射光線電子強度Ii,它與穿過3D體數據后到達DRR平面上的電子強度Io關系如式(1)所示:

式(1)中μ(x)是對應組織的衰減系數,0和d分別是光線經過3D數據的穿入和穿出點。然而由于人體的組織不是均勻的,因而μ(x)是不連續的,所以式(1)可以改寫成:
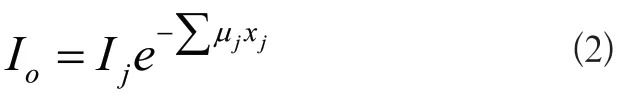
式(2)中μj是光線穿過不同組織的衰減系數,xj是穿過這種組織的有效長度。而衰減系數μ與CT值之間又有如下的轉換關系:

式(3)中μw是純水的衰減系數,通常是定值,HU是組織的CT值。最后將CT值再轉化成灰度值就可以完成DRR圖像的生成。
1.2 DRR圖像和X射線圖像之間的剛體變換
對于膝關節圖像,無論是DRR圖像還是X射線圖像,這兩者之間的配準可以看成是剛體之間的配準,則兩者之間的變換就是剛體變換。剛體變換進一步可以分解為旋轉變換和平移變換,從而可以使用六參數矢量來表示,其中θx,θy,θz分別表示物體圍繞x,y,z軸的旋轉變換,tx,ty,tz表示物體沿著x,y,z軸的平移變換。進一步將旋轉變換和平移變換寫成矩陣的形式:


則剛體變換矩陣為:
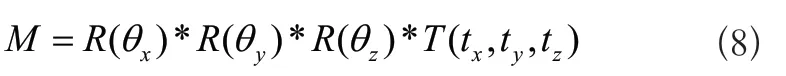
2 相似性測度
圖像配準的相似度測度是指通過幾何空間變換如剛體變換之后的兩幅圖像相似程度,常用的相似性測度方法有:互信息[3](Mutual Information,MI)、絕對誤差和[4](Sum of Absolute Differences,SAD)、歸一化互相關[5](Normalized Cross Correlation,NCC),梯度相關[6](Gradient Correlation,GC)、模式強度[7](Pattern Intensity,PI)等。
梯度方向[8]測度已經被應用于特征匹配[9],物體檢測[10]和圖像配準[11],但是傳統的梯度方向測度可能會在具有低梯度幅度的區域中受到噪聲的影響,從而影響配準的成功率與精度。本文提出一種改進方式:預先對待配準的兩幅圖像分別設定兩個閾值,在計算梯度方向測度時,只計算這兩幅圖像中大于設定閾值的像素,這兩個閾值可以設定為對應圖像所有梯度的中值,這樣就消除了50%的包含低梯度幅度的像素,減少像素遍歷數,從而降低了算法復雜度和減小了配準中噪聲的影響。梯度方向測度函數如式(9)、式(10)所示:
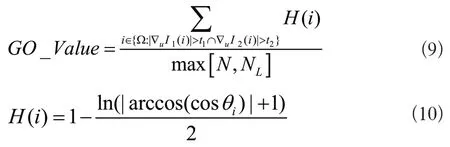
式中,N是圖像總像素,NL是人為規定的像素總數下界,以補償像素數低于NL的損失,?u是梯度算子,I1,I2是待配準的兩幅圖像,t1,t2是設定的梯度閾值,等于對應圖像梯度的中值,θi是?uI1(i)和?uI2(i)之間的夾角。最后計算的GO_Value值越接近1配準效果越好。
3 參數優化
參數優化是醫學圖像配準的重要過程,其實質就是相似性測度目標函數進行不斷迭代優化來尋找最佳的變換參數,以達到配準成功的目的。常用的優化算法[3]有模擬退火算法,Powell算法,梯度下降算法,遺傳算法等。本文采用的是自適應協方差矩陣進化算法(CMA-ES)。
CMA-ES算法是Nikolaus Hansen等人[12]在2006年提出的一種模擬生物進化過程的算法。該算法的特點是假設不論基因發生何種變化,產生的結果(性狀)總遵循這零均值,某一方差的高斯分布。CMA-ES算法實現簡單,對目標函數要求寬松,適用于解決高維度復雜的優化問題。在實際操作中,CMA-ES算法需要先初始化參數,設置種群的相關參數:種群中心點(期望)、步長、進化路徑、子代數量、協方差矩陣、最大迭代次數以及一些自適應參數。算法步驟[13]如下:
1)種群采樣操作:是指在目標函數的解空間中隨機選擇一個解,并以此為中心生產正態分布種群。以式(10)進行采樣并產生新解。
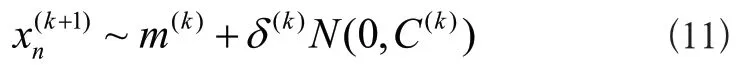
式中k=1,2,...λ,~表示式子兩邊服從相同分布,表示第k+1代的第n個后代,m(k)表示第k代搜索分布的均值,δ(k)表示第k代的步長,N(0,C(k))表示均值為0,協方差矩陣為C(k)的正態分布。第k代的協方差矩陣為C(k),C(0)=In*n,I是單位矩陣。協方差矩陣是CMA-ES算法進化策略的關鍵。
2)選擇和重組操作:是指在生成的總群中選擇最優子群。當前新的最優子群通過加權重組得到新的期望:
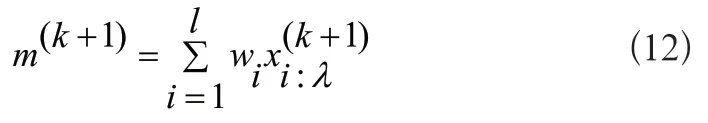
3)更新操作:從一代代的種群中估計協方差矩陣并且更新步長。估計第代協方差矩陣的公式如下所示:
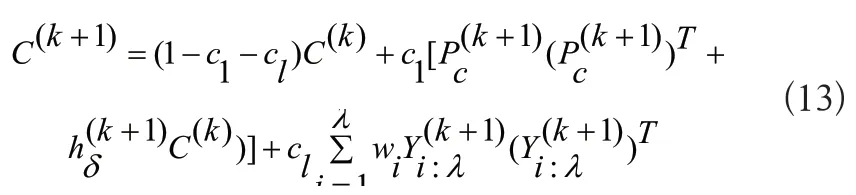
其中,c1≤1是協方差矩陣進化路徑Pc的學習率,T表示矩陣轉置。hδ表示Heaviside函數,它的作用是控制進化路徑Pc的過大增長。通常用平滑指數來構造進化路徑:

步長δ更新函數:
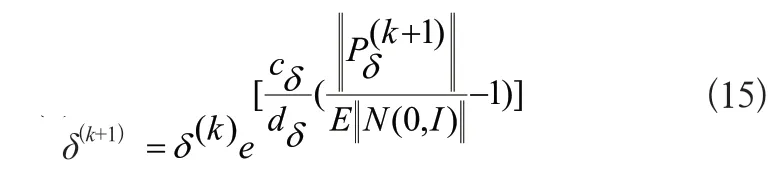
式中,e為自然底數,cδ表示步長學習率,dδ為步長更新的阻尼系數。E||N(0,I)||表示進化路徑歸一化后的期望模長,I為單位矩陣。
CMA-ES算法通過以上三個步驟的循環迭代,直到找到全局最優解。
4 基于CUDA加速的多模態圖像配準
傳統的圖像配準方法通常是基于軟件層面的,耗時非常大。因此,采取基于支持CUDA架構的GPU處理器進行硬件加速,彌補傳統配準方法在耗時上面的不足,大大提高配準的速度。本文的配準算法流程如圖2所示。

圖2 本文算法流程圖
5 結語
本文實驗數據來源為佛山市中醫院提供的4名患者膝關節CT斷層體數據,單層圖像大小為512×512,配套有同一患者的X射線圖像。硬件配置為Intel(R) Core(TM) i7-8700K CPU,主機頻率為3.7GHz,顯卡是NVIDIA公司的GeForce GTX1060 6GB,軟件配置為Win10下的Visual Studio 2015+Python 3.6+CUDA 9.0。實驗以裁剪后的感興趣區域X射線圖像為參考圖像,CT體數據生成的DRR圖像為浮動圖像,在Python環境下調用VS2015和CUDA生成的動態鏈接庫完成配準,結果如圖3~圖6所示:
患者1:
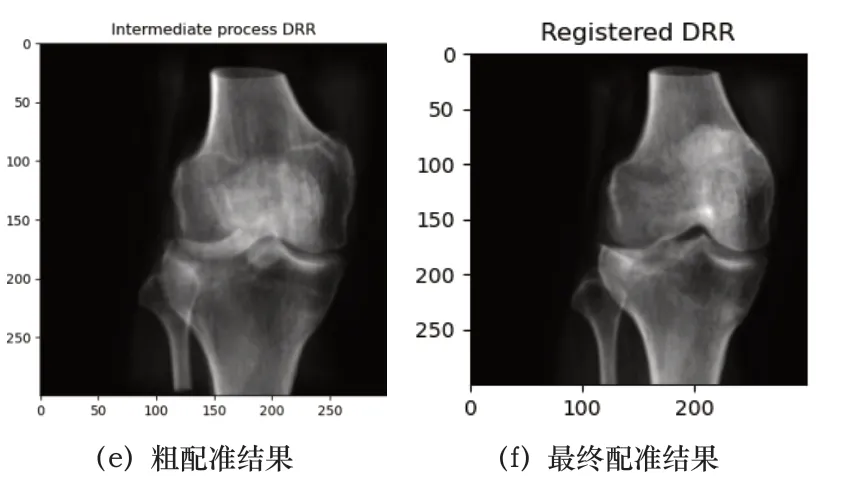
圖3 患者1配準圖
患者2:
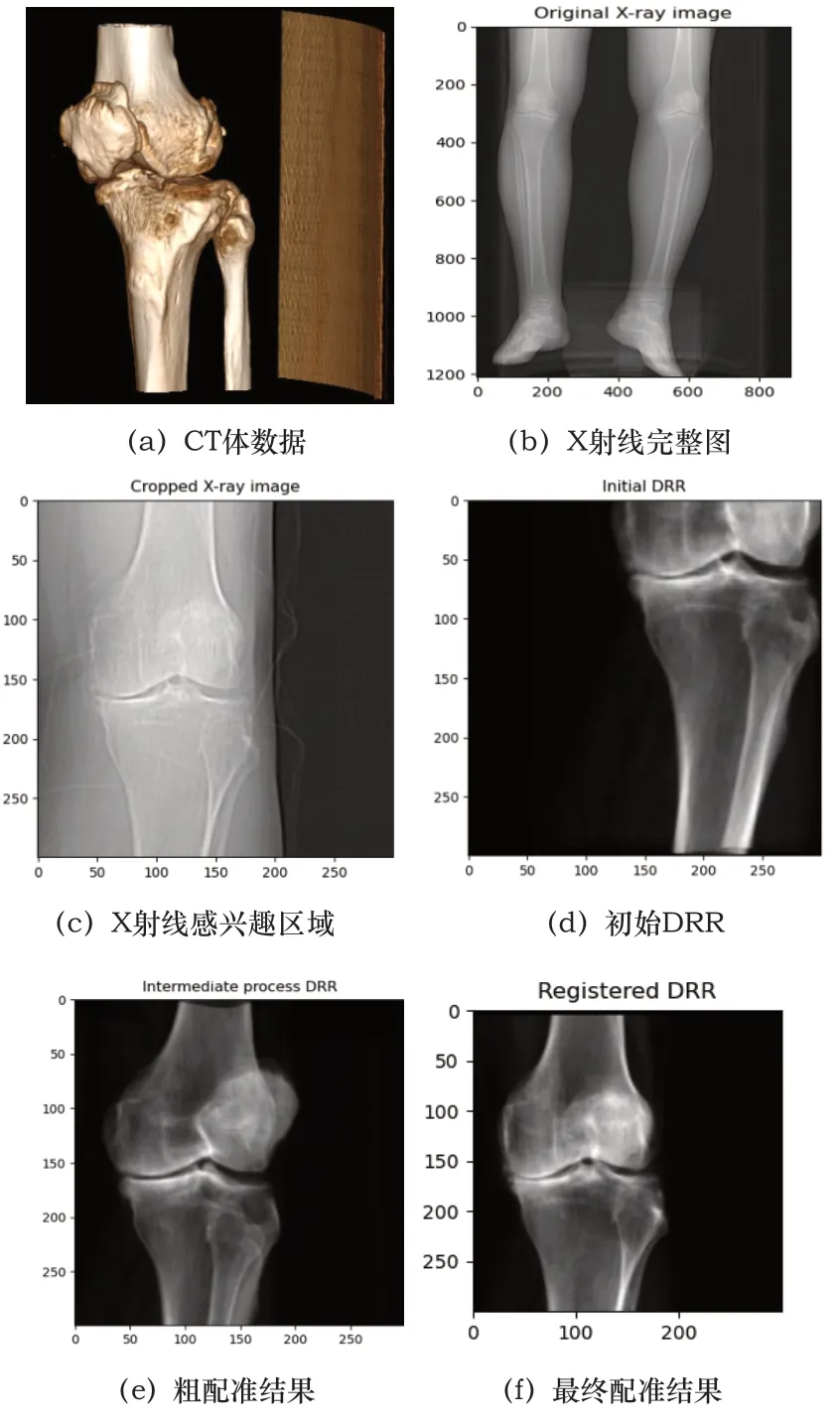
圖4 患者2配準圖
患者3:
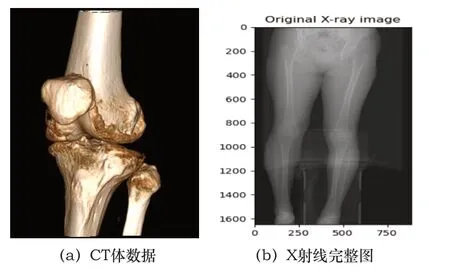
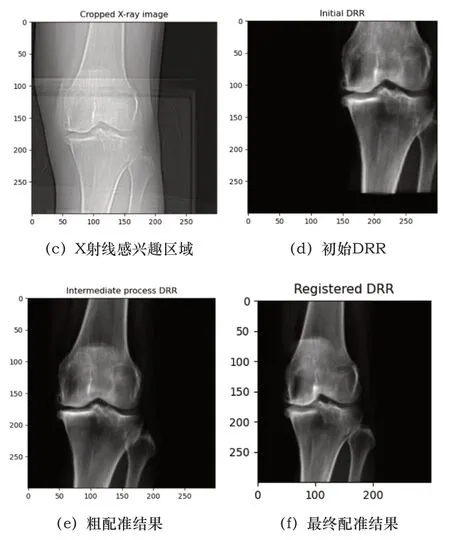
圖5 患者3配準圖
患者4:
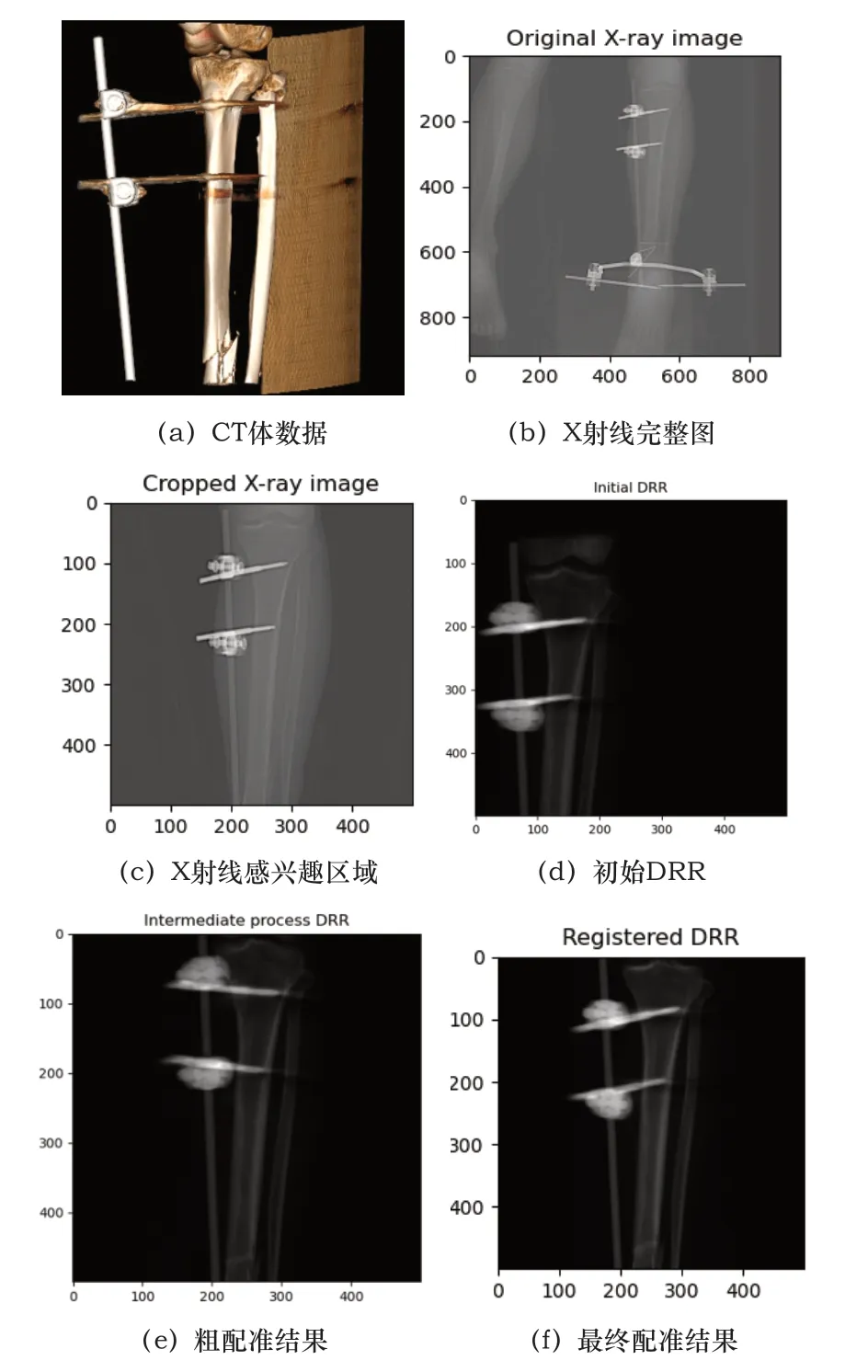
圖6 患者4配準圖
表1數據是每例患者數據均配準50次之后取的平均值,從4組數據的配準結果圖來說,也可以看出本文算法對于即使擁有噪聲(如患者3的X射線圖像)或者有其他干擾物的情況下(如患者4)仍然能夠取得很好的配準結果,這證明了本文算法具有高配準率和魯棒性,利用CUDA進行加速處理后配準速度也有了質的飛躍,為臨床應用提供了時效性。

表1 GPU與CPU配準對比
