近紅外高光譜大米典型特征提取分類識別
2022-07-07 01:50:08張瀚文鄧志吉
吉林大學學報(理學版) 2022年3期
張瀚文, 李 野, 江 晟, 鄧志吉
(1. 長春理工大學 物理學院, 長春 130022; 2. 浙江大華技術股份有限公司, 杭州 310051)
傳統大米品質檢測以凱氏定氮法、 高效液相色譜法等化學方法為主, 不僅要求專業技術人員技術水平高[1], 且具有操作流程復雜、 檢測周期長并損耗大量稻米樣本等弊端[2]. 高光譜成像檢測技術是基于連續密集波段下的二維灰度圖像和一維光譜圖像構成的三維數據立方體, 探測載體目標的幾何空間信息和多維光譜信息, 獲取目標高分辨率、 高質量成像數據. 目前, 提取高光譜感興趣區域(region of interest, ROI)方法很多, 吳瓊[3]和曹崴[4]利用ENVI軟件獲取高光譜ROI區域譜段信息是應用最廣泛的方法, 但其提取速度較慢, 人工操作頻繁, 易導致新誤差. 圖像分割作為模式識別的重要方法已廣泛應用于數字圖像預處理, Chala等[5]利用卷積神經網絡提出了一種視網膜圖像自動分割編/解碼器結構方法; Triki等[6]提出了一種Mask-RCNN圖像分割算法致力于氣候變換與植被演變研究. 能量泛函活動輪廓波算法是經典的圖像分割方法之一, 該方法可獲得閾值分割最優圖像控制點, 實現目標圖像的精準分割. 計算機視覺在識別圖像典型特征時, 圖像背景噪聲對分割圖像特征區域存在一定干擾, Zuo等[7]利用非局部均值化和自適應性, 提出了一種小波閾值圖像去噪方法, 豐富重復的特征圖像. 圖像降噪有助于全面檢測特征區域, 增強圖像清晰度與信噪比[8], 更好地實現高光譜成像多維信息處理, 實現健康大米(healthy rice, HR)、 陳化大米(aged rice, AR)和霉變大米(moldy rice, MR)的快速分類識別. 針對上述問題, 本文提出一種自動獲取近紅外高光譜典型特征的模式識別算法, 保證高光譜有效信息不缺失, 并對比分析了3種品質、 4個地區大米的ROI區域和幾何形心點(geometric centroid point, GCP)品質分類效果.
1 實驗環境與化學對照建立
1.1 樣本來源
樣本采用黑龍江省五常市大米, 吉林省柳河縣合十貢米、 江蘇省宜興市小町米及河北省承德市小町米.
1.2 儀器設備
使用Hyperspec Ⅲ近紅外高光譜成像系統(美國Headwall公司)采集樣本, 設備工作波段為885~1 701 nm, 共172個波段. 應用該系統采集高光譜信息前經若干次對比預實驗調整光通量、 物距和移動速度等多個參數. 近紅外高光譜成像系統結構如圖1所示.
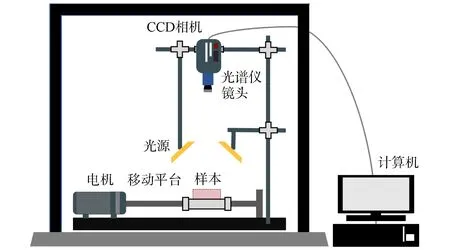
圖1 近紅外高光譜成像系統Fig.1 Near infrared hyperspectral imaging system
為驗證不同品質大米典型特征識別的有效性, 選擇MATLAB2017進行數據分析, 實驗環境為Intel Core i7-10700 CPU, 16 GB內存, Windows10專業版操作系統, 實驗技術路線如圖2所示.

圖2 實驗技術路線Fig.2 Experimental technical route
采集HR,AR和MR大米近紅外高光譜圖像(near infrared hyperspectral imaging, NIR-HSI), 將大米樣本約按5∶1分為訓練集和預測集, 其中訓練集1 200粒大米, 泛化預測集252粒大米, 分別對大米形態ROI與GCP區域建立識別模型, 對比分析大米不同典型特征品質分類效果, 選擇更適合本文算法的大米典型特征區域預測大米品質.
1.3 化學定性對照
為驗證不同品質大米樣本, 用化學試劑進行大米品質定性對比. 化學實驗效果如圖3(A),(B)所示, 其中HR樣本液為綠色, AR樣本液為橙色; HR與AR測試卡呈陰性雙紅色線條, MR呈陽性單紅色線條, 如圖3(C),(D)所示.

圖3 HR,AR,MR化學定性對比Fig.3 Chemical qualitative comparison of HR,AR and MR
2 掩膜能量泛函活動輪廓波的高光譜圖像預處理
2.1 掩膜能量泛函活動輪廓波
本文任意選取高光譜第40維作為初始表征圖像進行大米NIR-HSI圖像預處理, 在表征圖像上進行掩膜泛函能量活動輪廓(Mask-Snake)運算處理, 利用一個掩膜矩陣重新計算圖像中的像素值[9], 再根據表征圖像中的能量梯度確立米粒的基本ROI區域限界. 其閾值分割算法模型為
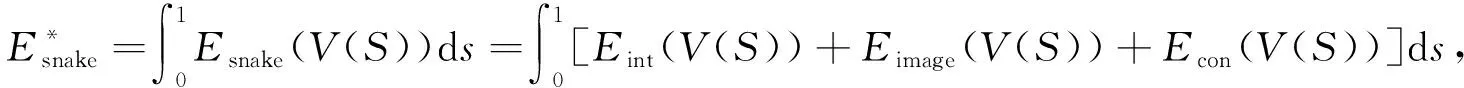
(1)
其中:Eint=V(S)表示米粒ROI輪廓內的自身能量, 稱為米粒內部能量;Eimage(V(S))表示米粒ROI輪廓邊界對應像素點的能量, 稱為米粒外部能量;Econ(V(S))表示米粒內、 外部能量的方差相關項. 內部能量由彈性能量和彎曲能量兩部分構成.
2.2 腐蝕與膨脹
經Mask-Snake高光譜成像預處理后, 表征圖像已初具米粒基本形態與邊界, 但圖像中仍存在少量分布不均勻的背景噪點. 通過腐蝕膨脹運算使目標圖像的輪廓變得更光滑清晰, 其具體作用為斷開較窄的狹頸并消除細突出物, 使米粒形態的邊界變得銳利可見. 將降噪后的表征分割圖像應用八聯通域相接, 且逐個標記樣本. 降噪結構元B對集合A進行腐蝕膨脹降噪運算, 模型定義為
A°B=(A!B)⊕B,
(2)
先令B對A進行腐蝕, 然后用B對結果進行膨脹.A°B的邊界由B中點建立, 當B在A的邊界內側滾動時,B所能到達A邊界的最遠點, 即為降噪區域.其中A為表征圖像全域,B為腐蝕膨脹模塊.
2.3 高光譜典型特征區域信息提取
目標樣本初始表征圖像經Mask-Snake與降噪預處理, 可得到一顆純凈的大米形態學區域, 但每張NIR-HSI圖像中包含多粒樣本, 不同米粒典型特征區域光譜信息不同, 在MATLAB仿真平臺中實現樣本大米數據典型特征屬性可視化.
基于Mask-Snake連通域確定每粒大米表征圖像的典型特征形態學區域, 對每粒樣本的高光譜成像數據進行相同位置區域的172維全譜段形態覆蓋, 以確保每一維度上的高光譜圖像形態信息相同, 如圖4所示. 圖4中白色區域為大米形態ROI區域, 大米高光譜形態ROI典型特征需計算白色區域內的全譜段平均光譜反射值, 繪制大米ROI區域原始光譜圖像; 紅色虛線為大米形態邊界自適應畫出的矩形錨框, 根據矩形錨框的尺寸計算出大米GCP區域; 大米高光譜集合形心點典型特征需計算圖中藍色“*”號像素點的全譜段光譜反射值, 繪制大米GCP區域原始光譜圖像.

圖4 大米典型特征區域Fig.4 Typical characteristic area of rice
為提高大米品質識別的精確率, 對兩種典型特征區域的大米反射光譜值進行多元散射校正(multivariate scattering correction, MSC)預處理, 該方法可有效消除由于散射水平不同帶來的光譜差異, 增強光譜曲線與數據之間的相關性, 以此作為分類器輸入數據進行大米典型特征區域對比分析, 為大米品質分類提供一個較好的數據預處理狀態. 光譜校正模型為
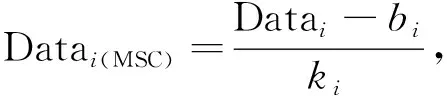
(3)
其中Datai為光譜平均值,bi為基線平移量,ki為基線偏移量.
2.4 支持向量機
支持向量機(support vector machine, SVM)是數據集在二維/三維空間下至少存在一種分割超平面的分類算法, 可避免機器學習中的維數災難現象[10]. 如圖5所示, 在二維/三維空間下, 其決策方程對應空間中存在一個分割超平面, 將數據線性區分.
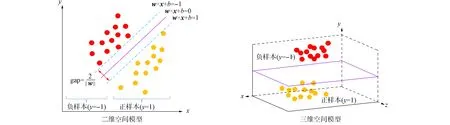
圖5 支持向量機空間結構示意圖Fig.5 Spatial structure diagram of support vector machine
當存在低維可區分時, 目標函數為
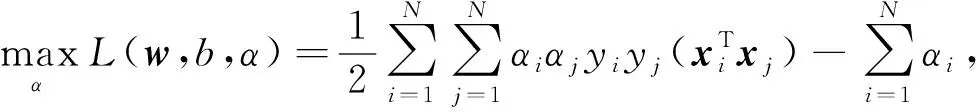
(4)
當存在低維不可分時, 通過核變換進行三維空間映射分類, 其目標函數為
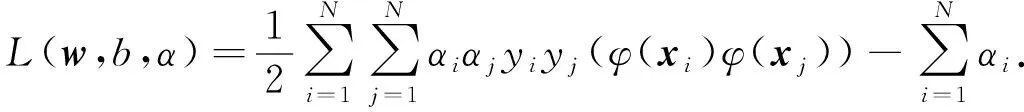
(5)
NIR-HSI成像數據為空間非線性關系. 如式(4), 在低維空間下目標函數較難進行大米品質線性區分, 故將原始光譜數據映射至式(5)的三維空間目標函數中進行非線性數據分類. 每個產地的3種品質大米數據在高維空間中進行兩次SVM運算, 兩兩區分后得到大米品質可視化判別結果.
3 實驗對比與分析
3.1 大米NIR-HSI典型特征區域信息提取
以吉林省柳河縣合十貢米為例, HR,AR,MR典型特征提取分別如圖6~圖8所示. 由圖6和圖8可見, HR與MR樣本經Mask-Snake運算閾值分割后獲取了精度較高的ROI區域. 由圖7可見, AR樣本質地松脆, 細微顆粒脫落在實驗背板中, 圖像分割后不能完全將樣本微屑產生的噪聲去除, 需用腐蝕與膨脹運算進行降噪, 得到較高信噪比的分割圖像.

圖6 HR典型特征提取Fig.6 Typical feature extraction of HR

圖7 AR典型特征提取Fig.7 Typical feature extraction of AR

圖8 MR典型特征提取Fig.8 Typical feature extraction of MR
由圖6~圖8可見, 每粒大米的形態ROI與GCP區域經NIR-HSI圖像預處理后, 其表征圖像大米顆粒邊界精確、 分割形態飽滿, 所選樣本大米的ROI與GCP區域可較可靠地獲取每粒大米樣本的NIR-HSI典型特征區域信息. 相比于ENVI軟件手動獲取高光譜ROI和GCP區域信息, 其操作流程繁瑣、 耗時也相對較長, 不便于高數量級高光譜成像典型特征區域的光譜信息提取, 而基于Mask-Snake高光譜圖像自適應典型特征區域分割算法, 其獲取高光譜多維信息速度更快, 算法流程更高效, 整體技術路線更穩定.
分別計算出HR,AR和MR樣本的形態ROI與GCP區域的原始光譜圖像, 對所獲取的各品質大米原始反射光譜進行MSC預處理, 結果如圖9~圖11所示. 由圖9~圖11可見, 基于大米樣本ROI區域的原始光譜反射曲線整體較光滑, 離散域較集中在一定幅值內, 經MSC預處理的光譜反射曲線, 其非線性關系更集中, 趨向形成一條非線性擬合帶. 樣本GCP區域的原始光譜反射曲線, 每條非線性光譜反射值呈小幅度鋸齒狀, 離散域較ROI區域幅度更大, GCP原始光譜經MSC預處理后在一定程度上擬合了各光譜反射值之間的散射差異, 但效果并不理想. 總之, 大米樣本形態ROI區域光譜反射信息較平滑, 光譜反射率相對集中; 而大米GCP區域光譜反射值則呈現小范圍波動前進趨勢, 光譜反射率相對離散. 此外, HR與AR光譜反射趨勢大致相同, 約在1 150,1 215,1 330,1 380,1 460 nm處出現波峰波谷, 但HR與AR的光譜反射率幅值存在一定差異; 而MR樣本受黃曲霉毒素B1侵染影響, 約在1 215,1 380,1 460 nm處后的光譜反射趨勢較HR與AR發生較大變化.
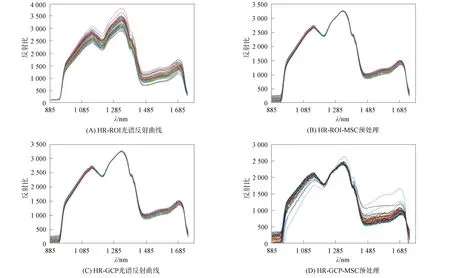
圖9 HR光譜圖像Fig.9 Spectral images of HR
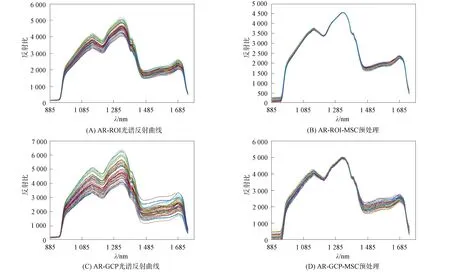
圖10 AR光譜圖像Fig.10 Spectral images of AR
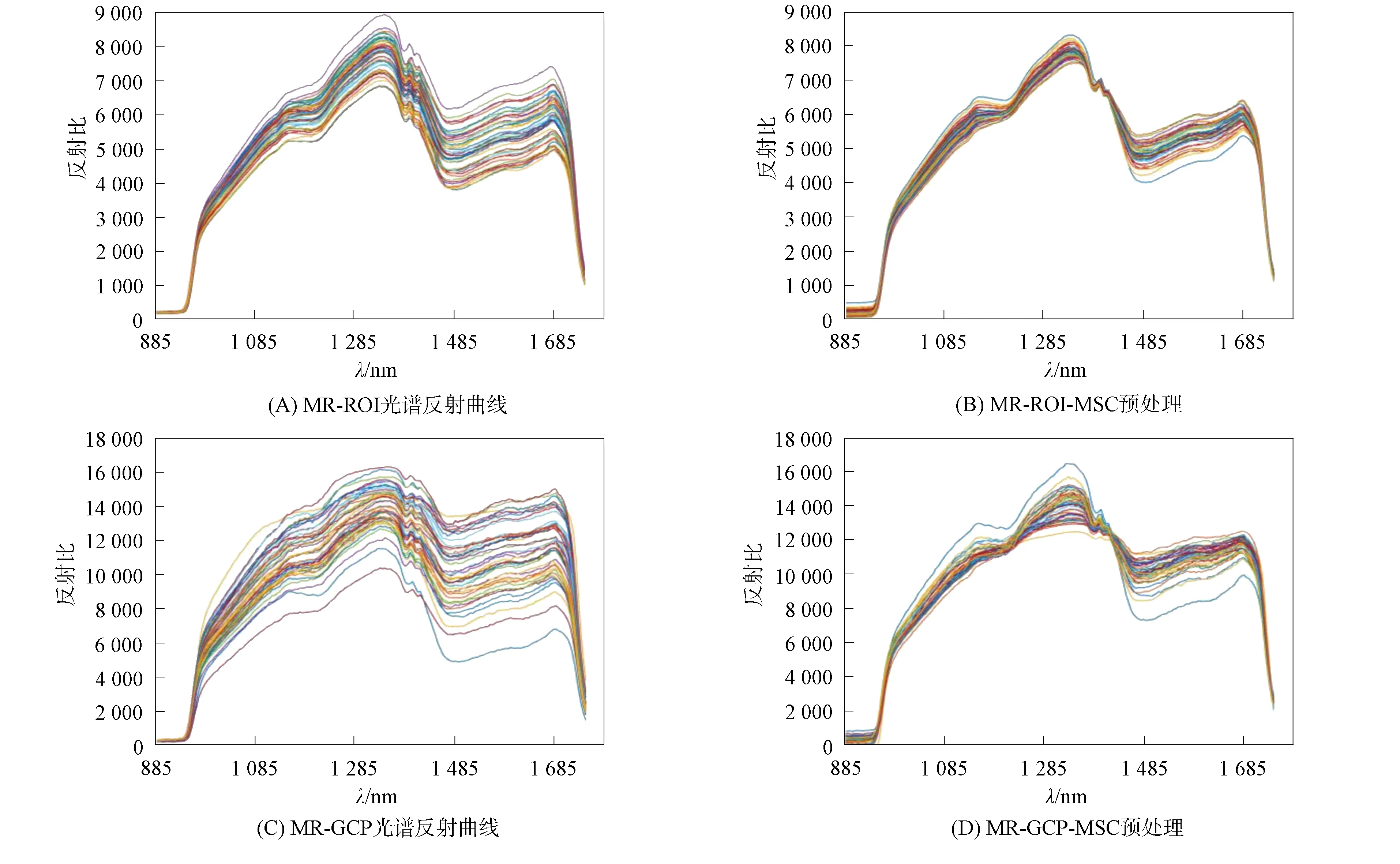
圖11 MR光譜圖像Fig.11 Spectral images of MR
3.2 大米典型特征區域映射模型對比分析
本文以SVM為空間映射分類模型, 分別建立大米NIR-HSI典型特征區域的Mask-Snake-MSC-SVM映射分類模型. 將來自黑龍江省五常市的大米(HLJWC)、 吉林省柳河縣的合十貢米(JLLH)、 江蘇省宜興市的小町米(JSYX)以及河北省承德市小町米(HBCD)的HR,AR和MR共1 200粒大米樣本作為訓練集, 識別率列于表1; 將4個產地的HR,AR和MR亂序排布并采集NIR-HSI數據, 共252粒大米作為泛化預測集, 識別率列于表2.
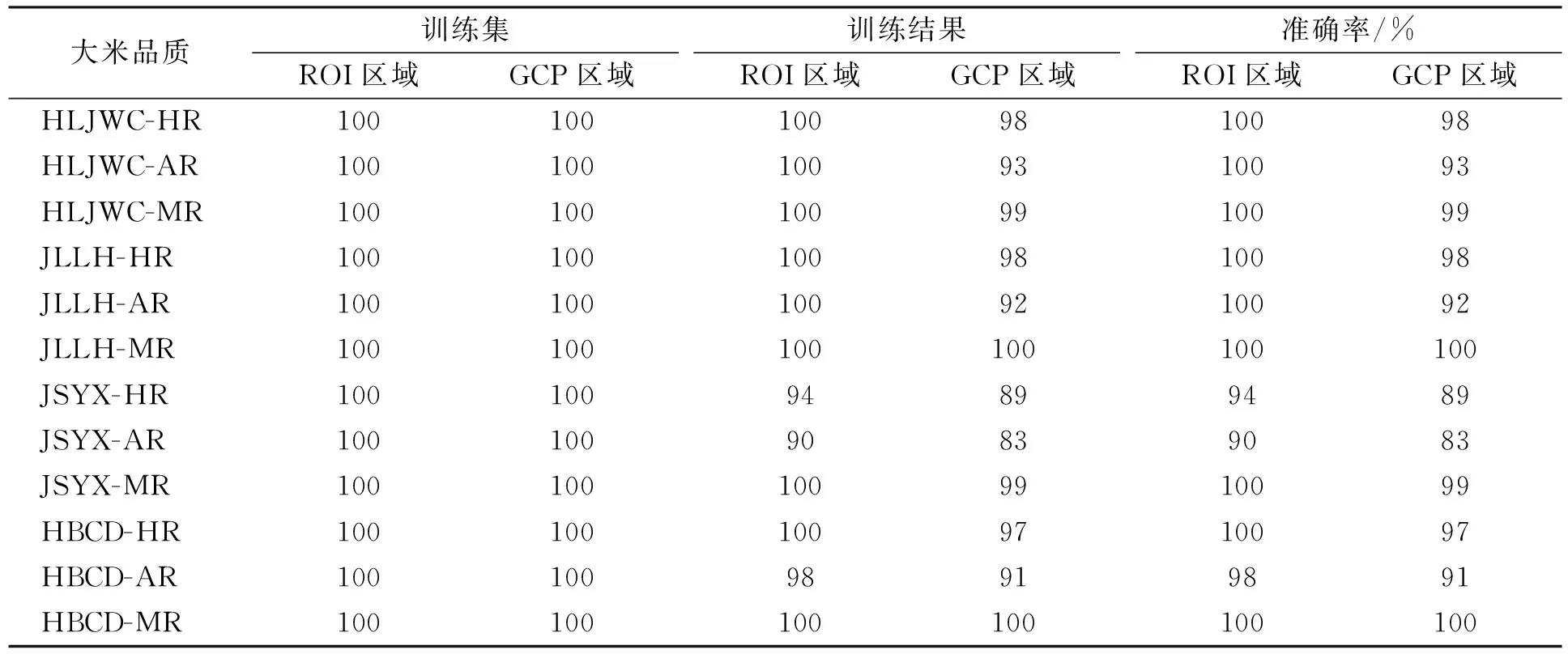
表1 大米典型特征訓練集識別率
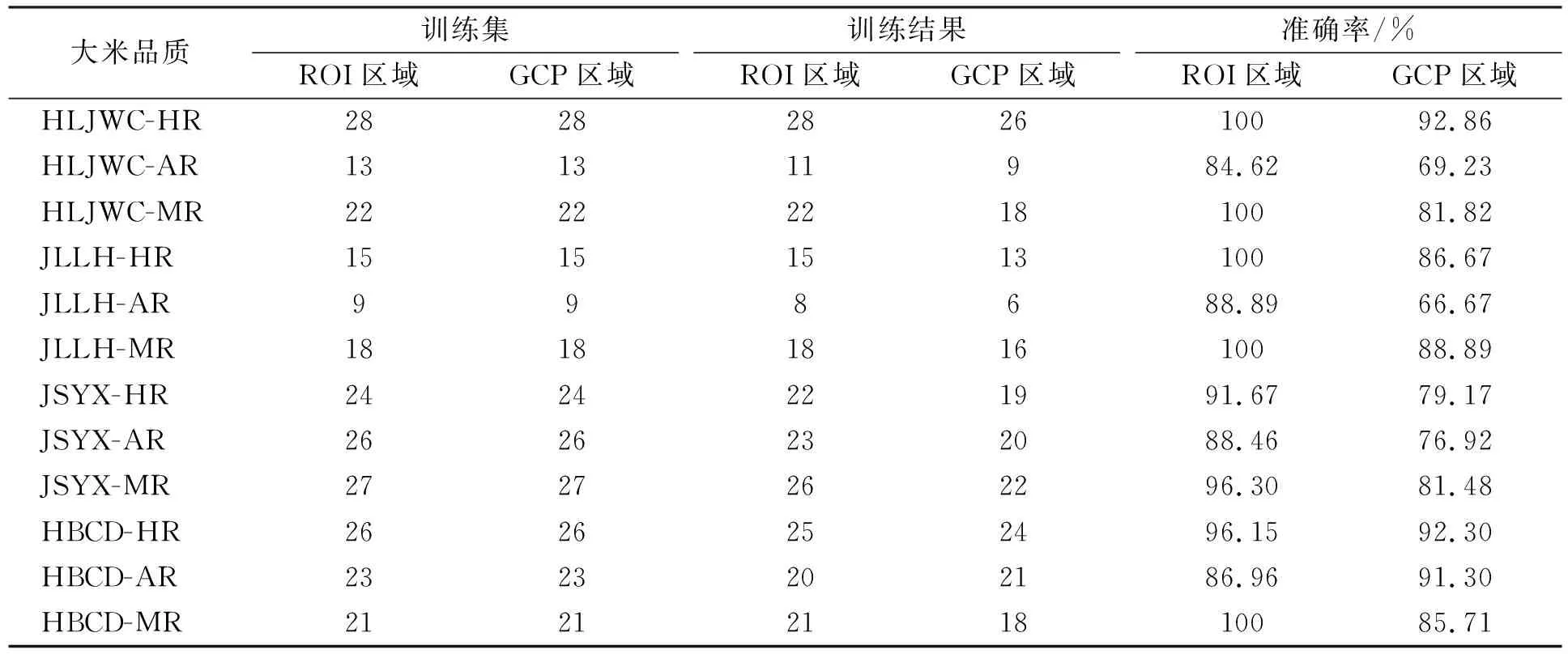
表2 大米典型特征泛化預測集識別率
首先, 將大米NIR-HSI數據的訓練集進行Mask-Snake圖像預處理, 分別獲取大米ROI與GCP區域的原始光譜反射信息; 其次, 將兩組原始光譜信息分別進行MSC光譜預處理; 最后, 將兩組原始光譜信息分別載入至SVM映射分類模型中.
由表1可見, 訓練集大米ROI區域光譜信息識別準確率總體為98.50%, 大米GCP區域光譜信息識別準確率總體為94.92%, 前者較后者識別精度略高3.58%. 由表2可見, 泛化預測集大米ROI區域光譜信息識別準確率總體為94.84%, 除HBCD-AR等4種品質大米識別準確率在90%以下外, 其他產地的大米品質識別準確率均在90%以上; 大米GCP區域光譜信息識別準確率總體為84.13%, 僅HLJWC-HR,HBCD-HR和HBCD-AR的模型識別精度在90%以上, 其余產地的大米品質識別準確率均在90%以下; 泛化預測集ROI較GCP識別精度高10.71%. 基于大米ROI區域光譜信息的泛化預測集比訓練集識別精度降低3.66%; 而大米GCP區域光譜信息的泛化預測集比訓練集識別精度降低了10.79%, 下降幅度較大.
在NIR-HSI目標樣本數據處理技術路線一致的前提下, 基于GCP區域光譜信息的建模精度略低, 原因是受NIR-HSI空間信息限制, 所提取的原始光譜信息僅能表示單一像素點譜段信息, 并不能完全代表一粒完整大米的全部多維度高光譜信息, 單一GCP區域未能更好地利用高光譜豐富的空間信息, 導致大米GCP區域信息識別精度較低. 而大米ROI區域利用了高光譜豐富的多元像素、 多維空間信息, 所提取原始平均光譜信息更具有NIR-HSI大米樣本整體代表性, 檢測精度更高. 因此, 大米形態ROI區域比GCP區域建模更適合Mask-Snake-MSC-SVM大米品質鑒別算法.
圖12為大米品質可視化判別結果, 以JLLH為例, 3種品質大米呈不同姿態亂序分布, 為大米品質識別模型增加泛化性與普適性, 圖12中綠框為HR, 藍框為AR, 紅框為MR. 與文獻[11]中大米產地溯源分類識別相比, 本文分類準確率更高. 文獻[11]方法用ENVI4.8版本手動提取大米感興趣區域, 將該區域內像素點平均光譜值作為后續的分類信息, 綜合分類準確率為79%, 該方法人為提取高光譜典型特征, 其主觀因素較強.

圖12 JLLH三種品質大米可視化分類識別結果Fig.12 Visual classification and recognition results of three kinds of quality rice in JLLH
綜上所述, 本文針對大米近紅外高光譜特征輪廓不清導致有效信息損失與有損化品質檢測的問題, 提出了一種基于掩膜下能量泛函活動輪廓波的大米高光譜典型特征區域提取算法組合模型. 采用能量泛函活動輪廓波圖像分割算法自適應獲取大米典型特征區域, 使二維形態表征信息覆蓋高光譜多維度信息, 快速提取高光譜大米典型特征區域內的光譜信息, 優化了大米高光譜典型特征區域提取算法. 基于Msak-Snake對原始NIR-HSI數據進行圖像預處理, 提取大米ROI與GCP區域的譜段信息, 分別建立SVM大米品質特征映射模型, 對比分析了高光譜大米典型特征選取對映射模型識別精度的影響, 與ENVI提取高光譜感興趣區域方法相比, 本文方法自適應捕獲大米形態ROI區域, 識別精度更優. 實驗結果表明, 對4個產地、 3種品質大米樣本進行NIR-HSI形態ROI區域與GCP區域的光譜信息自適應提取, 分別建立兩種NIR-HSI典型特征區域的Mask-Snake-MSC-SVM分類映射模型, 經對比分析后, 訓練集大米形態ROI區域識別精度為98.50%, GCP區域識別精度為94.92%; 泛化性預測集形態ROI區域識別精度為94.84%, GCP區域識別精度為84.13%, 大米形態ROI區域更適合整套大米品質鑒別算法模型. 本文Mask-Snake-MSC-SVM大米品質識別仿真模型可視化判別精度較高, 能有效解決大米品質無損化快速檢測問題, 泛化性預測集使模型具有較強的實用性與泛化性.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
