無需打開“黑箱”的反事實解釋:自動化決策和《通用數據保護條例》*
2022-07-11 15:00:34桑德拉沃切特布倫特米特爾斯塔德克里斯拉塞爾陳宇超
國外社會科學前沿 2022年7期
桑德拉·沃切特 布倫特·米特爾斯塔德 克里斯·拉塞爾/文 陳宇超/譯
一、引言
關于歐盟《通用數據保護條例》(以下簡稱GDPR)中是否存在“解釋權”及其優缺點,已經有了很多討論。通過打開“黑箱”以深入了解算法內部的決策過程來行使解釋權的辦法,面臨四個主要的法律和技術障礙。第一,GDPR中不存在具有法律約束力的解釋權。第二,即使解釋權具有法律約束力,該權利也僅適用于有限的情況(例如當一個消極決策是完全自動化作出的,且其具有法律效力或其他類似的重大影響)。第三,解釋復雜算法決策系統的功能和其在特定情況下的基本原理是一個技術上具有挑戰性的問題。解釋同樣可能無法為數據主體提供有意義的信息,從而引發對其價值的質疑。第四,數據控制者傾向于不共享其算法的詳細信息,以避免泄露商業秘密、侵犯他人的權利和自由(例如隱私)或使得數據主體(數據正在被收集和評估的自然人)刻意操縱決策系統。
雖然存在這些困難,但向受影響的數據主體提供解釋的社會價值和道德義務(或許還有法律責任)始終存在。這項討論忽略了一個重點,對自動化決策的解釋,無論是GDPR所設想的還是一般意義上的,都不必然取決于公眾如何理解算法系統的運作。雖然這種可解釋性非常重要并且應該被跟進落實,但原則上可以在不打開“黑箱”的情況下提供解釋。將解釋視為幫助數據主體采取行動,而不僅僅是幫助理解的一種手段,則數據控制者可以根據他們預定支持的特定目標或行動來衡量解釋的范圍和內容。
解釋可以用于許多目標。為了明確解釋的潛在范圍,從數據主體的角度出發似乎是合理的。我們提出了三個幫助數據主體的解釋目標:(1)告知并幫助數據主體理解為什么作出特定決策;(2)為質疑不利的決策提供理由;(3)基于當前的決策模型,了解改變什么可以在未來獲得預期的結果。正如我們所展示的,GDPR幾乎沒有為實現任一上述目標提供支持。同時,上述目標無一取決于自動化決策系統內部邏輯的解釋。
建立信任對于提高社會對算法決策的接受度至關重要。為了彌補目前破壞數據控制者和數據主體之間信任的透明度和問責制缺口,我們建議超越GDPR的限制。我們認為,反事實應該作為對自動化決策提供解釋的重要手段。
應該對積極和消極的自動化決策給出“無條件的反事實解釋”,無論這些決策是完全(與“主要地”相對)自動化作出的,還是產生了法律或其他重大影響。這種方法為數據主體提供了有意義的解釋,用以理解特定的決策、知曉質疑決策的理由,以及建議數據主體如何改變其行為或情況以便在未來可能獲得所需決策(例如貸款批準),而這些無需面對GDPR關于自動化決策定義所強加的嚴重性適用限制。
在本文中,我們將“無條件反事實解釋”的概念作為一種新型的自動化決策解釋機制,其克服了有關算法可解釋性和問責制的許多問題。通過將反事實理論置于分析哲學史中,以及長久以來對機器學習領域可解釋性和公平性的研究中,基于反事實解釋為數據主體提供的潛在優勢,我們將評估它們與GDPR中關于自動化決策眾多規定的一致性。具體而言,我們核查GDPR是否支持旨在幫助數據主體了解自動化決策范圍、特定決策基本原理的解釋,質疑決策的解釋以及指導數據主體改變行為以獲得預期結果的解釋。我們得出的結論是,無條件的反事實解釋可以彌合數據主體和數據控制者之間的利益差距,否則這種利益差距就會成為行使具有法律約束力解釋權的障礙。
二、反事實
反事實解釋采用與陳述句類似的形式:
你被拒絕貸款,因為你的年收入為30000英鎊。如果你的收入是40000英鎊,你就能獲得貸款。
上述決策之后是一個反事實陳述,或者說情景必須如何改變才能發生理想結果的陳述。反事實可能有多個,因為可以存在多個理想結果,并且可能有多種方法來實現其中的任何一個。“最接近可能情景”的概念或為獲得理想結果而對情景做出的最小改變,是整個反事實理論討論的關鍵。在很多情況下,提供涵蓋對應息息相關或信息豐富的“相近可能情景”的一系列反事實解釋,比起提供對應“最接近可能情景”的反事實解釋可能更有幫助。同時,了解一個變量或一組變量的最小可能變化以達到不同的結果可能并不總是最有用的反事實類型。相反,相關性還取決于其他的特定情況因素,例如變量的可變性或現實情景的變化概率。
在現有文獻中,“解釋”通常是指試圖傳達導致決策結果算法的內部狀態或邏輯。相反,反事實依賴于導致決策的外部事實,這是一個關鍵的區別。在現代機器學習中,算法的內部狀態可以由數百萬個變量組成,這些變量交織成了一個關于決定性行為的龐大網絡。如果允許數據主體推理算法的行為,以這種方式將(算法內部)狀態傳達給非專業人士是極具挑戰性的。
什么是解釋?機器學習領域和法律領域對此的觀點都相對有限。機器學習領域主要關注調適和傳達算法的近似值,程序員或研究人員可以使用這些結果來理解哪些特征是重要的。而法律和倫理學者更關心了解決策的內在邏輯,以此作為評估決策合法性(例如防止歧視性結果)、質疑決策、普遍增加問責制和澄清責任的一種手段。
因此,這里提出的將反事實作為解釋的提議不屬于先前在機器學習、法律和倫理領域的文獻中提出的解釋分類法。相比之下,正如我們在下一節中討論的那樣,分析哲學對知識以及如何將反事實用于信念的理由采取了更廣泛的觀點。
(一)歷史背景與知識問題
分析哲學在分析命題知識的必要條件方面有著悠久的歷史。這種類型的表達式“S了解P”構成了知識,S指了解主體,P指已知的命題。傳統方法將知識視為“有正當理由的真實信念”,認為構成知識有三個必要條件:事實、信念和理由。根據這種三要素方法,為知道某件事,僅僅相信某事是真的是不夠的,相反,你還必須有充分的理由相信這件事。這種方法的相關性來自這樣一種觀點:即這種對信念進行辯護的形式可以作為一種解釋,因為它是持有信念的根本原因,因此可以作為問題的答案,“你為什么相信X?”理解這些理由可以采取不同形式,為比以前在可解釋性研究中遇到的更廣泛的解釋類別打開了大門。
盡管具有廣泛的影響力,但“有正當理由的真實信念”已經面臨很多批評,并且激發了對修改這種三要素方法的實質性分析,以及對構成知識命題的額外必要條件的建議。模態條件,包括安全性和敏感性,已經被提議作為建立在反事實關系中三要素的必要補充。
歐內斯特·索薩(Ernest Sosa)、喬納森·市川(Jonathan Ichikawa)1Ernest Sosa,How to Defeat Opposition to Moore,Philosophical Perspectives,vol.13,Epistemology,1999.和馬蒂亞斯·斯托普(Matthias Steup)2Jonathan Ichikawa and Matthias Steup,The Analysis of Knowledge,in Stanford Encyclopedia of Philosophy Archives,https://plato.stanford.edu/archives/fa/entries/knowledge-analysis.將敏感性定義為:
如果P是假的,S將不相信P。
其中,“如果P是假的”的陳述是一個反事實,其定義了一個接近“P是真的”的情景的“可能情況”。敏感性條件表明:“在非P的最接近的可能情景中,主體(S)不相信P。”我們的反事實解釋概念取決于相關概念:
如果Q是假的,S將不相信P。
我們認為在這種情形中,Q作為S對于P信念的一個解釋,因為S只在Q為真時才相信P,且改變了Q也將會引起S對P的信念變化。關鍵是這樣的陳述只描述了S的信念,而不需要反映現實。如此,可以在不知道任何Q和P之間因果關系的情況下做出這些陳述。
我們將反事實解釋定義為采用以下形式的陳述:
返回得分為P,因為變量V(v1,v2……)具有與其相關聯的值。如果V的值改變為(v1’,v2’……),并且所有其他變量都保持不變,返回得分為P’。
雖然可能有許多這樣的解釋,但理想的反事實解釋將盡可能少地改變數值,并代表一個最接近的情景,在該情景下返回值為P’而不是P。因此,“最接近可能情景”的概念隱含在我們的定義中。
通過識別變量的變化,我們的反事實版本可能最類似于執行中的結構方程方法。無論如何,我們的方法不依賴于對情景因果結構的了解,或者認為使用上下文相關的情景間的距離度量來建立因果關系更可取。在許多情況下,多樣化的反事實解釋將提供更大的信息量,對應于附近可能情景的不同選擇,這些情景提供了反事實成立或首選結果,而不是理論上根據首選距離度量來描述“最接近的可能情景”的理想反事實。具體案例的考慮因素將與距離度量的選擇以及一組“充分”和“相關”的反事實解釋有關。此類考慮因素可能包括有關個人的能力、敏感性、決策中涉及的變量的可變性以及披露的道德或法律要求。
類似地,可以提供描述模型內多個變量變化的反事實。這些反事實將代表因個人情況的變化而可能帶來的未來。例如,收入變化的影響可以與職業變化結合計算,從而確保反事實代表一個現實的可能情景。
(二)在人工智能和機器學習領域的解釋
人工智能領域中,大部分對由專家作出或是基于規則系統作出的決策進行解釋的早期機制,重點在于與反事實密切相關的解釋類別。例如,雪莉·格雷戈爾(Shirley Gregor)和伊扎克·本巴薩特(Izak Benbasat)1Shirley Gregor and Izak Benbasat,Explanations from Intelligent Systems:Theoretical Foundations and Implications for Practice,MIS Quarterly,vol.23,no.4,Dec.1999.提供了被他們稱為“1型”的解釋例子:
Q:為什么減稅是合適的?
A:因為減稅的先決條件是高通脹和貿易逆差,而當前的情況表明了這些因素。
布魯斯·布坎南(Bruce Buchannan)和愛德華·肖特里菲(Edward Shortliffe)2Bruce G.Buchanan and Edward D.Shortliffe,Rule-based Expert Systems:The Mycin Experiments of the Stanford Heuristic Programming Project 344,1984.提供了一個類似的例子:
規則009,如果:
1)生物體的革蘭氏染色為革蘭氏陰性,并且
2)生物體形態為球菌。
那么,有明顯的指向性證據表明該生物為奈瑟菌。
正如早期人工智能中的典型情況,也是我們現在認為很難解決的問題,“我們如何確定通貨膨脹是否嚴重?”或“為什么這些是減稅的先決條件?”過去解決的辦法是假設這些問題假定已被人類解決,并且不作為解釋的一部分進行討論。因此,這些解釋并不能洞察機器學習中黑箱分類器的內部邏輯。相反,第一個例子可以改寫為兩種不同的反事實陳述:
如果通脹低,減稅政策將不會受到推崇。
如果沒有貿易逆差,減稅政策將不會受到推崇。
以及第二個例子與反事實密切相關:
如果生物體的革蘭氏染色為陰性或形態不是球菌,則該算法不會確信其是奈瑟菌。
這些早期方法與反事實方法之間最重要的區別在于,反事實方法以端到端的集成方法持續發揮作用。如果上述示例中的革蘭氏染色和形態學也由算法確定,反事實將自動返回具有不同分類的近似樣本,而這些早期方法無法應用于此類涉及的場景。
隨著焦點已從人工智能和基于邏輯的系統轉向機器學習,例如圖像識別,解釋的概念開始指深入了解算法內部狀態,或是指人類可理解的算法近似值。因此,與我們最相關的機器學習機制是由大衛·馬頓斯(David Martens)和福斯特·普羅沃斯(Foster Provost)完成的。3David Martens and Foster Provost,Explaining Data-Driven Document Classifications,MIS Quarterly,vol.38,2014.在機器學習的其他工作中,他們的工作與我們一樣,對進行干預以改變分類器響應的結果有著共同的興趣。
機器學習中關于解釋和解釋模型的大部分機制都與生成簡單模型作為決策的局部近似值有關。通常,這個想法是創建一個普通人可理解的決策算法近似值,該算法可以對當前輸入的給定決策進行準確建模,但如果改變輸入的決策,可能會出現武斷的糟糕結果。然而,將這些方法作為面向適合數據主體的解釋方法存在許多困難。
一般而言,尚不清楚這些模型是否可由非專業人員解釋。他們在近似值的質量、函數的易理解性和近似值有效的域的大小之間進行了三方權衡。即使在單變量的簡單場景中,這些局部模型也可能對變量的重要性產生大相徑庭的估量,這使得推斷函數如何隨著輸入的變量而變化變得極其困難。此外,這些方法在專業程序員調試的模型之外的效用尚不清楚。關于如何讓非專業受眾理解這些方法的各種局限性和不可靠性,以便他們能夠使用這些解釋機制,尚待進行研究。
相比之下,反事實解釋是刻意被限制的。它們創設了一種方式,即提供能夠改變決策的最少量信息,并且數據主體不需要了解模型的任何內部邏輯就可使用它。這樣做的缺點是個別反事實可能過于嚴格。一個反事實可能表明決策是如何基于某些數據作出的,這些數據雖然正確但無法在未來決策之前被數據主體更改,即使存在可以被修改以獲得有利結果的可能。這個問題可以通過向數據主體提供多種不同的反事實解釋來解決。
(三)對抗性擾動和反事實解釋
用于在深度網絡(例如殘差網絡ResNet)上生成反事實解釋的機制已經在機器學習的文獻中以“對抗性擾動”為名進行了廣泛研究。在這些機制中,能夠計算反事實的算法用于混淆現有分類器,通過生成與現有分類器接近的合成數據點,從而使新合成的數據點與原先的數據點歸入不同的分類。
反事實的一個優勢在于,它們可以通過標準機制甚至前沿架構進行高效和有效的計算。一些最大和最深的神經網絡被用于計算機視覺領域,特別是在ImageNet等圖像標記任務中。這些類型的分類器已被證明特別容易受到對抗性擾動的攻擊,對給定圖像的微小改動可能導致圖像被分配到完全不同的類別。例如,DeepFool將給定分類器的圖像X的不利擾動定義為X的最小變化,從而使其分類發生改變。從本質上講,這是一個不同名稱的反事實。在距離函數的正確選擇下,找到一個最接近X的可能情景,使得分類變化與找到X的最小變化相同。
重要的是,對抗性擾動的標準機制都沒有使用適當的距離函數,并且大多數此類方法傾向于對許多變量進行微小的更改,而不是提供僅修改少數變量的人工可解釋解決方案。盡管如此,由于最先進的算法是可微分的,因此可以有效計算反事實和對抗性擾動。對抗性擾動的文獻中提出的許多優化機制可以直接適用于這個問題,使得反事實生成有效。
對抗性擾動中更具挑戰性的方面是,針對圖像的這些微小變化幾乎是人類無法察覺的,但會導致截然不同的分類器響應結果。非正式地說,這似乎是因為新生成的圖像并不位于“真實圖像空間”中,而是稍微超出了它的范圍。這種現象是一個重要提醒,當通過搜索接近的可能情景計算反事實時,找到的解決方案來自“可能的情景”至少與它接近起始示例一樣重要。在反事實可以可靠地成為高維度和高度結構化空間(例如自然圖像)的解釋之前,需要進一步研究如何表征來自這些空間的數據。
(四)因果關系與公平
一些研究已經通過使用因果推理和反事實解決了保證算法公平的問題,即它們不表現出對特定種族、性別或其他受保護群體的偏見。馬特·庫斯納(Matt J.Kusner)等人在考慮主體屬于不同種族或性別的反事實,并要求在這種反事實下作出的決策保持不變,以使其被認為是公平的。相反,我們考慮決策與當前狀態不同的反事實。
許多研究表明,透明度可能是強制執行公平的一個有用工具。雖然尚不清楚如何將反事實用于此目的,但同樣也不清楚任何形式的解釋對個人決策是否實際上有幫助。尼卡·格爾吉奇-赫拉卡(Nica Grgic-Hlaca)等人展示了可理解的模型很容易誤導我們的直覺,并且主要使用人們認為公平的特征會略微增加算法表現出的種族主義傾向,并且降低準確性。1Nina Grgic-Hlaca et al.,The Case for Process Fairness in Learning:Feature Selection for Fair Decision Making,in NIPS Symposium on Machine Learning and the Law,2016.一般而言,揭示系統性偏見的最佳工具可能是基于大規模統計分析,而不是基于對個人決策的解釋。
話雖如此,反事實可以提供證據,證明算法決策受到受保護變量(例如種族)的影響,因此可能被認為具有歧視性。對于下一節中提及的距離函數類型,如果得出的反事實改變了某人的種族,則證明對該人的處理取決于其種族。然而,相反的說法是不正確的,不修改受保護屬性的反事實不能用作該屬性與決策無關的證據。這是因為反事實僅描述了特定決策與特定外部事實之間的一些依賴關系,這將在下文中詳細闡述,即為特定分類器提出的反事實包含“黑人”改變他們的種族,而不是“白人”的種族應該多樣化。
三、生成反事實
在這部分中,我們將舉例說明如何輕松計算得出有意義的反事實。許多機器學習的標準分類器(包括神經網絡、支持向量機和回歸器)都是通過找到最優權重ω來訓練的,這些權重最小化了一組訓練數據上的目標:
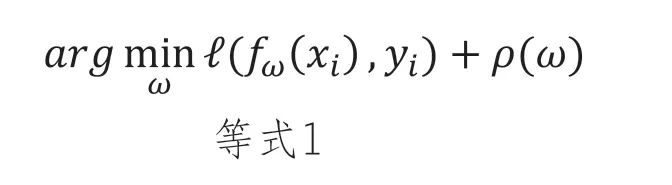
Yi是數據點Xi的標簽,ρ(·)是權重的正則化器。我們希望找到一個反事實X’,其盡可能地接近原始點Xi,使得fw(X’)等于新的目標Y’。我們可以通過保持ω固定并最小化相關目標來找到x′

其中 d(.,.)是一個距離函數,用于測量反事實 x' 和原始數據點 x 之間的距離。在實踐中,X 上的最大化是通過迭代求解 x',并增加 X 直到找到足夠接近的解來完成的。
這些問題的優化器選擇相對不重要。在實踐中,任何能夠在等式1下訓練分類器的優化器似乎同樣有效,我們在所有實驗中都使用ADAM。由于局部最小值是一個問題,我們用不同的隨機值初始化每個運行的x'并選擇等式2的最佳最小值作為我們的反事實。這些不同的最小值可以用作多種反事實的集合。
特別重要的是選擇距離函數,用于確定哪個合成數據點 x' 最接近原始數據點 xi。
作為明智的第一選擇,應該根據主題和任務的特定要求進行改進,我們建議使用L1范數或曼哈頓距離:由逆中位數絕對偏差加權。這被寫成 MADk 表示特征 k 在點集 P 上的中位數絕對偏差:
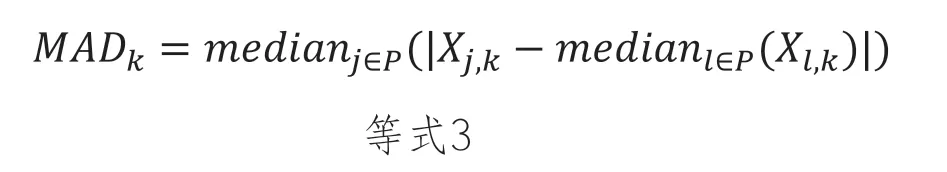
我們選擇D(·,·)作為:
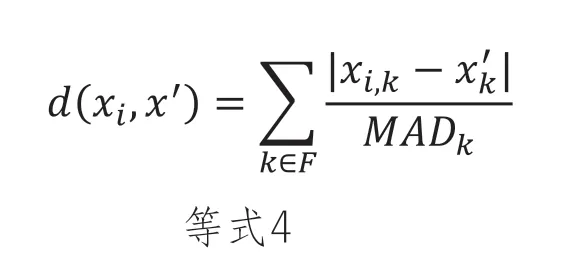
這個距離度量有幾個理想的特性。首先,它捕獲了空間的一些內在波動性,這意味著如果特征K在整個數據集中變化很大,合成點X’也可能會改變該特征,同時在距離度量方面保持接近Xi。使用中位數絕對偏差,而不是更常見的標準差也使該距離度量面對異常值更穩健。同樣重要的是L1范數的稀疏誘導特性。L1范數在數學和機器學習領域中得到廣泛認可,因為它傾向于在與適當的成本函數配對時產生大多數條目為零的稀疏解。
在計算人類可理解的反事實時,此屬性非常可取,因為它對應于只有少量變量發生變化,且大部分變量保持不變的反事實,從而使反事實更易于交流和理解。該距離度量在我們展示的示例中同樣適用。
為了證明距離函數選擇的重要性,我們在下面說明了變化D(·,·)對LSAT數據集的影響。另一個挑戰在于確保合成反事實X’對應于有效數據點。我們說明了一些在計算反事實時處理離散特征的陷阱和補救措施。1限于篇幅,略過反事實生成的論證過程。——譯者注
四、反事實解釋的優勢
反事實解釋與機器學習領域和法律領域中的現有提議明顯不同(特別是關于GDPR的“解釋權”),同時其具有幾項優點。原則上,反事實繞過了解釋機器學習系統內部復雜工作的重大挑戰,這種解釋即使技術上可行,對數據主體也可能沒有什么實際價值。相比之下,反事實解釋為數據主體提供的信息既易于理解,又可實際用于理解決策原因、質疑決策和改變未來行為以獲得更好的結果。
反事實解釋對于減輕監管負擔也具有重大意義。當前最先進的機器學習方法是基于深度網絡做出決策,這些網絡將程序進行1000多次的組合,并有超過1000萬個參數控制它們的行為。由于人類的記憶機制只能包含大約7個不同的項目,因此關于特定決策所涉邏輯的“人類可理解的有意義信息”是否存在尚不清楚,更不用說這些信息是否可以有意義地傳達給非專業人士。因此,需要向非專業受眾傳達有關內部邏輯的有意義信息的法規可能會禁止使用許多標準方法。相比之下,反事實解釋并不試圖傳達所涉及的邏輯,并且如上文所述,其計算和傳達都很簡單。
這種提供有關算法決策系統內部邏輯信息的期望最近已經初見端倪,與GDPR相關,尤其是“解釋權”。GDPR包含許多規定,要求將有關自動化決策的信息傳達給個人。法律和機器學習領域就GDPR在這方面的具體要求和限制進行了大量討論,特別是如何提供有關高度復雜的自動化系統做出的決策的信息。由于反事實提供了一種方法來解釋自動化決策的一些基本原理,同時避免可解釋性的陷阱或打開“黑箱”的難度,因此它們可能被證明是一種非常有用的機制,可以滿足GDPR的明確要求和背景目標。
五、反事實解釋和GDPR
盡管GDPR的“解釋權”不具有法律約束力,但它仍然將數據保護法的討論與如何向專家和受決策影響的普通人士提供解釋算法決策的長期問題聯系起來。回答這個問題很大程度上取決于解釋的預期目標:所提供的信息必須在結構、復雜性和內容方面進行調整,并考慮到特定的目標。不幸的是,GDPR 沒有明確定義自動化決策的解釋要求,并且幾乎沒有提示關于自動化決策解釋的預期目的。GDPR的Recital(背景陳述)第71條是一項不具有法律約束力的條款,其指出應實施針對自動化決策的適當保障措施,并且“應包括向數據主體提供的特定信息以及獲得人工干預的權利、表達個人觀點的權利、獲得根據此類評估達成決策的解釋的權利以及質疑該決策的權利”。
這是GDPR唯一一次提到解釋,這讓讀者幾乎不能了解其打算進行何種類型的解釋或解釋是為了什么目的。根據條約文本,唯一明確的跡象是立法者鼓勵:在決策作出后可以自愿提供某種類型的解釋。這可以看作是Recital第71條將應在決策作出前提供的“特定信息”與決策作出后適用的保障措施(“對此類評估后達成的決策解釋”)分開。條文未對此類事后解釋的預期內容進一步說明。
解釋的內容必須反映其預期目標。鑒于GDPR中缺乏指導性文本,許多解釋的目的是可行的。為了體現GDPR對個人權利保護的強調,我們從數據主體的角度審查解釋的潛在目的。我們提出了自動化決策解釋的三個可能目的:加強對自動化決策范圍和特定決策原因的理解,幫助質疑決策以及提供改變未來行為以期獲得理想結果的方案。這不是解釋的潛在目標的詳盡列表,而是反映了自動化決策(與任何類型的決策一樣)的受眾,可能希望了解決策的范圍、影響和基本原理,以及他們應當如何采取行動來應對的愿望。下文中,我們將評估這三個目的如何在GDPR中體現,以及論證反事實解釋符合并超過了GDPR要求的程度。
(一)幫助理解決策的解釋
解釋的一個潛在目的是讓數據主體了解自動化決策的范圍,以及導致特定決策的原因。GDPR中的一些條款可以支持數據主體對自動化決策的理解,盡管必須共享的信息類型往往會加強對自動化決策系統的擴大化理解,而不是特定決策的基本原理。因此,GDPR似乎不需要打開“黑箱”向數據主體解釋決策系統的內部邏輯。考慮到這一點,反事實可以提供符合GDPR各種要求的信息,同時還可以深入了解導致特定決策的原因。因此,反事實可以符合并超過GDPR的要求。
Recital第71條中對于解釋的描述不包括打開“黑箱”的要求,了解算法決策系統內部邏輯未被明確要求。在其他部分,GDPR涵蓋了透明度機制、通知義務和訪問權,所有上述內容都創設了有關自動化決策的信息要求。第13至15條描述了在收集數據時需要提供哪些類型的信息,包括在向數據主體收集時立即提供;在從第三方收集后的一個月內提供;或者在數據主體要求時隨時提供。除其他事項外,第12條解釋了應當如何傳達此信息(由第13至14條所定義)。第12至14條表明必須向數據主體提供“對預期處理有意義的概述”,包括“自動化決策的存在和第22(1)和(4)條提到的分析。以及至少在這些情況下需要包含所涉邏輯的有意義信息,以及這種處理對數據主體的重要性和設想的后果”,而不是在決策作出后提供一個關于系統內部邏輯的詳細解釋。相反,它們旨在提供預期處理活動的籠統概述,從而加強數據主體對自動化決策范圍和目的的理解。
第12(7)條闡明了第13至14條的目的是提供“以一種易見、可理解和清晰易讀的方式,針對預期處理的有意義概述”。有兩點要求值得注意:(1)提供的信息必須對其接收者有意義且范圍廣泛(即“meaningful overview”);(2)通知要在處理之前發出(即“intended processing”)。
若要了解意義的概述由什么構成,設想的披露媒介是有益處的。需要的似乎是廣泛適用的信息,而不是個性化的披露。法律學者建議可以通過更新現有的隱私聲明或通知來滿足通知義務(例如,在網站上顯示或使用二維碼)。該要求不因數據收集的形式而改變。當從第三方收集數據時,發送給數據主體的電子郵件能夠鏈接到數據控制者的隱私聲明就足夠了。這同樣適用于涉及隱私聲明的個性化鏈接。可以想象,類似于目前使用的符合第14條要求的工具,這些工具使得用戶能夠了解cookie的使用情況或者購物行為的監控,從而數據主體可以立刻知曉數據正在被收集。詳細信息似乎不是必需的,因為第12(7)條規定所需信息可以與標準化圖標一起提供。在歐盟的三方會談中,歐洲議會提出了幾個標準化圖標(最終未被采用)。盡管如此,所提議的圖標體現了監管機構傾向簡單、易于理解的信息的初衷。
這些示例表明第13至14條旨在向所有涉及的數據主體(例如Twitter的所有用戶)提供有意義數據處理的籠統概述。受制群體更有可能是普通大眾或用戶群,而不是個人用戶。這種披露形式表明,通知應該對具有簡單專業知識和背景知識的一般受眾是容易理解。一個“未受過教育的外行”,可能是披露的預期受眾。這與第12(1)條的一般概念一致,即與數據主體交流的所有信息和通信都必須采用“簡潔、透明、易懂且易于訪問的形式”,這表明深度技術信息和“法律術語”(legalese)是不合適的。至少,每條規定都表明信息披露需要針對其受眾進行定制,預期受眾包括兒童和未受過教育的外行。
縱觀“有意義的概述”,有關自動化決策制定的通知面臨特定限制。根據第29條工作組(The article 29 Data Protection Working Party),英國信息專員辦公室要求,以一種非常簡單的方式告知數據主體“自動化決策的重要性和預期結果”,包括“分析可能會如何影響數據主體,而不是關于特定決策的信息”就已經足夠。例如,解釋信用評級低如何影響支付選擇,解釋怎樣的預期數據處理會導致信用申請或工作申請被拒絕,以及解釋駕駛行為怎樣影響保險費,這樣就足夠了。類似地,“涉及邏輯的有意義信息”據說只需要“澄清:用于創建配置文件的數據類別、數據來源,以及為什么這些數據會被認為是相關的”,而不是澄清“關于算法或機器學習如何工作的詳細技術描述”。
這一觀點在第29條工作組關于自動化決策的指導方針中得到了回應。首先,“解釋權”在指南中僅提及一次,而且沒有任何關于范圍或目的的進一步細節。這一“權利”與第 22(3)條中具有法律約束力的保障措施明顯分開,這意味著第29條工作組認為Recital和具有法律約束力的條款的法律地位存在差異。事實上,指南甚至沒有在他們“良好實踐建議”的部分列入解釋權。數據控制者“參與此類活動”,即自動化決策,這一事實的透明度至關重要,同時也是第13和14條的主要目標。因此,這些條款的主要目的是提供事前信息。這一點也很明顯,因為該指南指出,“重要性”和“設想的后果”兩詞意味著“必須提供有關未來或未來的處理情況,以及自動化決策可能會如何影響數據主體”。此外,“(數據)控制者應該找到簡單的方法來告訴數據主體背后的原理,或者達成決策所依賴的標準。GDPR要求(數據)控制者提供有關所涉邏輯的有意義信息,而不一定是對所用算法的復雜解釋或是對完整算法的披露。”然而,必須指出的是,這一要求盡管是依據決策作出的原理提出的,但其似乎是指一般系統功能,而不是對個別決策的解釋。指南指出,第15(1)(h)條[似乎提供了和第13(2)(f)條和第14(2)(g)條相同的信息]要求數據控制者“向數據主體提供關于處理的設想結果的信息,而不是關于特定決策的解釋。”
總之,根據第29條工作組,第13至15條的目的是展示自動化流程如何幫助數據控制者做出更準確、無偏見和負責任的決策,并說明所使用的數據、特征和方法如何適合實現這一目的。如果在處理或決策之前沒有通知,數據主體只能在事后對決策提出異議。這可能會耗費大量的時間和成本,并可能導致無法挽回的經濟或聲譽損失。因此,第13至14條的目的之一是讓數據主體了解未來的處理,并允許他們決定是否同意處理他們的數據、基于成員國法律或協議評估合法性以及行使GDPR中規定的其他權利。
1.訪問權的更廣泛可能性
處理前通知的要求僅適用于通知義務。相比之下,數據主體可以隨時援引訪問權,從而打開了在作出決策后提供可用信息的可能性(即特定決策的原因)。然而,有學者認為,通過通知義務提供的信息與訪問權在很大程度上是相同的,意味著訪問權同樣受限于“關于所涉邏輯,重要性和預期結果的有意義信息”。因此,通過用來通知以及回應訪問請求的工具(例如,通用圖表、隱私聲明)或通用模板,可以很大程度上提供信息。
狹義的解釋似乎是正確的。第29條工作組支持這種觀點,其認為第12(2)(f)條、第14(2)(g)條和第15(1)(h)的信息要求是相同的,盡管第15(1)(h)條要求“(數據)控制者應當向數據主體提供關于處理的預期結果的信息,而不是特定決策的解釋”。英國信息專員辦公室(ICO,Information Commissioner’s Office)提出了一種類似的觀點,第13至15條的目的是“提供關于分析大體上將如何影響數據主體的解釋,而不是關于一個特定決策的解釋”。此外,與第13至14條相比,GDPR表明了訪問權的限制范圍,即不得披露其他數據主體的個人數據,因為這可能會侵犯他們的隱私。訪問請求也有可能違反關于商業秘密和知識產權的條款(第15(4)條和Recital第63條),這意味著必須在數據主體和(數據)控制者的利益之間取得適當的平衡。
2.通過反事實理解決策
反事實解釋符合且超過GDPR透明度機制、通知義務、訪問權的目標和要求,其向數據主體提供信息以便理解自動化決策的范圍。正如上述論證,Recital第71條沒有明確說明其目的或解釋內容,包括是否必須解釋算法的內部邏輯。通過提供簡單的“if-then(如果…那么…)”陳述,反事實符合以“簡潔、透明、易懂且易于獲得的形式”向數據主體傳達信息的要求。它們同時更深入地洞察了數據主體的個人情況和相關自動化決策背后的原因,而不是為一般受眾定制的概述。反事實也不太可能侵犯商業秘密或個人隱私,因為根據訪問權的限制,不需要披露其他數據主體的數據或關于算法的詳細信息。
也許最重要的是,反事實提供了對特定自動化決策的一些基本原理的解釋,而無需解釋如何作出決策的內部邏輯。此類信息符合第29條工作組和英國ICO的指南。雖然法律不要求打開黑箱,但必須提供一些有關“自動化決策中涉及邏輯”的信息。數據保護指令中規定的訪問權,通常不需要公開算法源代碼、公式、權重、全套變量和有關參考組的信息。GDPR中規定的訪問權很可能會提出類似的要求。反事實在很大程度上遵循這一先例,僅披露選定的外部事實和變量對特定決策的影響。盡管第13(2)(f)條、第14(2)(g)條和第15(1)(h)條不要求提供特定決策的信息,反事實代表了一種最小形式的披露,即告知數據主體特定決策中的“所涉邏輯”。通過這種形式的披露,數據控制者的監管負擔被最小化,因為解決可解釋性的技術困難或向非專業人士解釋復雜系統的內部邏輯并不需要計算和傳達反事實解釋。因此,我們推薦反事實作為一種負擔和破壞性都最小的技術,幫助數據主體理解特定決策的基本原理,而這也超出了第13(2)(f)條、第14(2)(g)條和第15(1)(h)條規定的明確法律要求。
(二)有助質疑決策
解釋的另一個可能目的是,當收到不利或其他不合意的決策時,提供質疑自動化決策的信息。根據第22(3)條的規定,質疑決策的權利是對抗自動化決策的保障措施。
質疑決策旨在撤銷決策或使決策無效并返回到未作出決策的狀態,或者改變結果并獲得另一個決策。如果產生決策的原因需要解釋,受影響的當事人可以評估這些原因是否合法,并根據要求對評估提出異議。
如何質疑決策取決于第22(3)條中的保障措施(即獲得人工干預、表達意見和質疑決策的權利)是被解釋為必須同時援引的單元,還是被解釋為可以單獨援引或在任何可能的組合中援引的個人權利。根據解釋的目的來衡量解釋的范圍,需要評估用于質疑自動化決策的各種可能模型。
有四種模型是可能的。如果保障措施是一個單元并且必須一起援引,則作出新決策可能需要一些人工參與。這可能是人類在沒有任何算法幫助的情況下作出的決策,因此新結果是人工決策,而不是自動化決策。或者,可以要求個人在考慮算法評估和/或數據主體的反對意見的情況下作出決策,這將是具有算法元素的人工評估。在這兩種情況下,數據主體都將失去對后續決策的保障措施,因為這兩種類型的決策都不是“僅基于自動處理”,因此不符合第22(1)條中自動化個人決策的定義。另一種可能性是,一個人可能需要監視數據輸入和處理過程(例如,基于數據主體的反對意見),而新的決策完全由算法系統作出。在這種情況下,第22(3)條規定的保障措施仍然適用于新決策。最后,如果保障措施可以單獨適用,并且數據主體可以在不援引其獲得人為干預或表達意見權利的情況下,援引其質疑決策權利,則可以在沒有人為參與的情況下作出新的決策。根據第22(3)條,這一決策可能會再次受到質疑。目前尚不清楚在GDPR實施后,這些模型中的哪一個將會是首選。
問題仍然是哪些解釋將有助于質疑決策,這取決于質疑模型。第一個模型,人類作出新的決策并完全無視算法的建議,對原始決策基本原理的解釋則具有信息價值,但實際上這種解釋不會影響完全由人類決策者作出的新決策。對于每個預設算法參與的其他模型,對決策原理的解釋可能有助于確定潛在的質疑理由,例如輸入數據不準確、有問題的推論或算法推理的其他缺陷。
即使對決策理由的解釋可能有助于質疑決策,但這并不意味著解釋是GDPR所要求的,或者是無法律約束力的解釋權的預期目標。Recital第71條沒有具體說明權利的目的或應該披露什么信息,也沒有明確要求解釋算法的內部邏輯。GDPR中沒有明確說明解釋權和質疑權之間的聯系,其中前者將提供援引后者所必需的信息。此外,沒有理由可以假設:第22(3)條中的保障措施必須同時實施,而不是彼此獨立實施。因此,Recital第71條規定的解釋并不是質疑不利決策的必要先決條件,即使其可能會有所幫助。
同樣地,也未明確說明質疑權、透明度機制、通知義務、訪問權之間的聯系,這意味著無需明確制定通過這些權利和義務提供的信息,來幫助數據主體成功地質疑決策。
盡管如此,第12至15條提供的信息可能對質疑決策結果有所幫助。通知義務旨在促進GDPR中其他權利的行使,以增加個人對數據處理的控制,這一事實得到了明顯的支持。為了達到這一目的,第13(2)(b)條、第14(2)(c)條和第15(1)(e)條規定,數據控制者在收集數據時,從第三方獲得的一個月內或在數據主體要求的任何時間內,有義務向數據主體通知他們第15至21條項下的權利。然而,第22條似乎并沒有列入上述規定,因為第22條第(1)款和第(4)款所提到的告知“存在包括分析的自動化決策”義務的措辭很奇怪,并且至少在這些情況下,應當告知關于邏輯的有意義的資料以及這種處理對數據主體的意義和預期后果。
正如上述論證,第13至15條將向普通受眾提供關于自動化決策的有意義概述。從表面上看,這樣的概述對于質疑決策并不能立即產生幫助,因為沒有提供關于個人決策基本原理的信息。在描述有關自動化決策的信息時,僅在第22(1)和(4)條中明確提及。因此,數據主體不需要被告知針對自動化決策的保護措施,例如競爭權。這種限制是有說服力的。如果第13至15條的目的是通過提供有用的、個人級別的信息來促進質疑決策,那么人們會希望明確探討質疑權或第22(3)條。同樣,第13至15條似乎并不要求告知數據主體他們有權不受自動化決策的約束,從中可以推斷出質疑決策的權利。事實上,在GDPR的早期草案中,有人建議信息權應當整體規定在第20條中。最終,這種方法未被采用,這表明對質疑決策有用信息的缺位是有意為之。
在許多方面,缺乏對于自動化決策保障措施的明確聯系并不令人意外。第12至15條旨在通知數據主體行使他們在GDPR中享有的權利,以及促進他們行使這些權利。然而,這并不意味著要求(數據)控制者提供幫助數據主體行使其權利的其他信息。相反,只需要告知數據主體其權利的存在,并提供行使(權利)必要的基礎設施(例如,投訴門戶網站),包括消除不必要的繁文縟節,保證第12(3)條規定的回復查詢、申請的合理時間以及與有權改變決策并進行交流的機會。但是,數據主體仍然有責任獨立行使其權利。不幸的是,Recital第60條含糊地指出,“考慮到處理個人數據的具體情況和背景,確保公平和透明處理所需的任何進一步信息”應當提供給數據主體,而這并沒有向數據主體提供額外的幫助。在歐盟的三方會談期間,這一規定被有意移至不具法律約束力的Recital中。因此,數據控制者沒有法律義務向數據主體提供對行使其他權利特別有用的信息。
最后一項值得注意的類似限制是關于第16條,數據主體糾正不準確個人數據的權利。數據控制者無需指出哪些記錄對特定自動化決策的影響最大,這對于試圖找出不準確之處以作為質疑決策理由的數據主體非常有幫助。如果數據主體要擁有大量個人數據,則其可能必須檢查數以萬計的項目是否準確。
1.通過反事實質疑決策
因此,第13至15條很少強化數據主體質疑自動化決策的能力。第22(3)條不提供關于保障措施的信息(例如質疑權)。似乎無需通知數據主體不受自動化決策約束的權利,這本身可能意味著有權質疑令人反感的自動化決策。類似地,Recital第71條沒有規定質疑決策與理解黑箱之間的明確聯系。盡管解釋可能會有所幫助,但它們似乎并不是質疑決策的先決條件。如果解釋是質疑決策的先決條件,它們將出現在具有法律約束力的文本中。為了向數據主體提供更大的保護,應消除這些信息缺口,這意味著數據控制者應告知不受自動化決策約束的權利及享有保障措施的權利。
反事實可能有助于質疑決策,從而為數據主體提供比GDPR更好的保護。無論解釋權的法律地位如何,質疑權都是具有法律約束力的保障。通過提供關于促成特定決策的外部因素和關鍵變量的信息,反事實可以為數據主體行使其質疑權提供有價值的信息。這也符合第29條工作組的指南,該準則敦促理解決策和了解其法律基礎對質疑決策至關重要,而不一定與打開黑箱有關。例如,低收入導致貸款申請被拒絕的解釋可以幫助數據主體以其財務狀況不準確或數據不完整為由對結果進行質疑。理解使得收入在決策中作為相關變量的系統的內部邏輯,這需要技術性解釋而不是反事實解釋,雖然就其本身而言可能是可取的,但質疑基于該變量的決策并非絕對有必要。反事實通過向數據主體提供有關決策原因的信息,而無需打開黑箱,為質疑決策提供了解決方案和支持。盡管GDPR第16條給予數據主體改正用于作出決策的不準確數據的權利,但無需告知數據主體決策是基于哪項數據作出的。在收集了大量數據的情況下,不知道哪些數據與特定決策相關或對特定決策最有影響的人被迫審查所有數據。這種信息的缺位增加了尋求另一種結果的數據主體的負擔。反事實提供了一種緊湊且簡單的方式來傳達這些依賴關系(例如,哪項數據是有影響力的),并且有助于提出有效主張——決策是基于不正確的數據作出的,并對該決策提出異議。
(三)改變未來決策的解釋
從數據主體的角度來看,除了理解和質疑決策外,解釋也可以用于指明未來可以更改哪些內容以獲得預期結果。此目的不一定與質疑權有關。準確的決策可能會對數據主體產生不利的結果。在某些情況下,成功質疑決策的概率也很低,或者所需的成本太高。在這些情況下,數據主體可能更愿意通過調整自己的行為來改變其處境的各個方面,并在具備更有利的條件時要求作出新決策。
GDPR沒有直接闡明使用解釋作為改變行為以獲得所需自動化決策結果的指南。然而,這不會消滅數據主體從自動化決策系統獲得預期結果的興趣。例如,如果受試者因收入不足而被拒絕貸款,反事實解釋將表明在立即加薪的情況下重新申請是否合理。然而,試圖提供關于自動化決策的“所涉邏輯的有意義信息,以及重要性和預期后果”的技術解釋不能保證在這種情況下有用。
因此,反事實可用于對未來決策進行有利于數據主體改變。通過提供可以導致不同決策的關鍵變量和“接近的可能情景”的信息,數據主體可以了解更改哪些因素可以獲得所需結果。對于決策模型和隨時間變化較小的環境,或為個人“人工停滯”時間的模型(即未來的決策將采用與個人原始決策相同的模型),這些信息可以幫助數據主體改變他的行為或情況,以在未來獲得他想要的結果。同樣,如果在特定時間段內滿足給定的反事實條款,數據控制者可以根據合同向數據主體提供首選結果。
話雖如此,有意改變的屬性與其他變量(例如職業變化導致的收入增加)之間未料及的互相依賴性可能會破壞反事實作為未來行為指南的效用。然而,反事實解釋可以同時解決針對一個模型輸出的多個變量變化的影響。更甚者,無論反事實作為未來行為指南的效用如何,仍然不影響他們幫助個人了解哪些數據和變量對特定先前決策產生了影響。
猜你喜歡
南大法學(2021年3期)2021-08-13 09:22:32
阿來研究(2021年1期)2021-07-31 07:39:04
中國自行車(2018年9期)2018-10-13 06:17:10
中華手工(2017年2期)2017-06-06 23:00:31
金色年華(2016年13期)2016-02-28 01:43:27
山西大同大學學報(社會科學版)(2015年6期)2015-01-22 07:22:22
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年3期)2011-01-22 03:42:30
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
